Last active
March 31, 2021 14:59
-
-
Save Odomontois/7e310e95199327e496b86d36b5f96754 to your computer and use it in GitHub Desktop.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| [ | |
| { | |
| "id": 725581, | |
| "title": "[Python] 2 Pointers O(n^2) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/3sum", | |
| "post": { | |
| "id": 1337818, | |
| "content": "This problem is similar to **2Sum** problem, but here we need to find sums of three elements. We can use similar idea with hash-tables, but the problem here is that we can have duplicates, and it is a bit painful to deal with them, using hash-tables, we need to count frequencies, make sure, we did not use the same elements and so on.\\n\\nAnother approach is to use **2 Pointers** approach. Let us sort our data first and choose element number `i`. What we need to find now is some elements with indexes `beg` and `end`, such that `i \u003c beg \u003c end` and `nums[beg] + nums[end] = target = -nums[i]`. Here times come to use our **2 Pointers** approach: we start from `beg, end = i + 1, n - 1`, and move `beg` to the right and `end` to the left, comparing `nums[beg] + nums[end]` with our target. If it is equal to `target`, we add it to our result, and move two pointers. However, because we can have equal numbers in `nums`, we still need to check, that we return unique triples, so we apply `set` in the end.\\n\\n**Complexity**: time complexity is `O(n log n + n^2) = O(n^2)`, because we sorted our data, and then we have loop with `n` iterations, inside each of them we use 2 pointers approach with `O(n)` complexity (inside `while beg \u003c end:` each time distance between our pointers reduced by at least `1`). Space complexity is potentially `O(n^2)`, because there can be potentially `O(n^2)` solutions: \\n\\nlet `nums = [-n,-n+1,..., n-1, n]` with `2n+1 = O(n)` numbers, then there will be solutions:\\n`1 2 -3`, `1 3 -4`, ... , `1 n-1 -n`\\n`2 3 -5`, `2 4 -6`, ... , `2 n-2 -n`\\n\\nin first group there will be `n-2` solutions, in second `n-4` and so on.\\nSum of arithmetic progression `n-2 + n-4 + ... ` is approximately equalt to `n^2/4`.\\nWe also have more solutions, but we already showed that there is `O(n^2)`.\\n\\n```\\nclass Solution:\\n def threeSum(self, nums):\\n nums.sort()\\n n, result = len(nums), []\\n\\n for i in range(n):\\n if i \u003e 0 and nums[i] == nums[i-1]: continue\\n\\n target = -nums[i]\\n beg, end = i + 1, n - 1\\n\\n while beg \u003c end:\\n if nums[beg] + nums[end] \u003c target:\\n beg += 1\\n elif nums[beg] + nums[end] \u003e target:\\n end -= 1\\n else:\\n result.append((nums[i], nums[beg], nums[end]))\\n beg += 1\\n end -= 1\\n\\n return set(result)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594236516, | |
| "creationDate": 1594209005 | |
| } | |
| }, | |
| { | |
| "id": 995249, | |
| "title": "[Python] increasing stack, explained", | |
| "taskUrl": "https://leetcode.com/problems/largest-rectangle-in-histogram", | |
| "post": { | |
| "id": 1803116, | |
| "content": "**Key insight**: for given bar `i` with value `h`, how to find the biggest rectangle, which is ending with this bar? We need to find the previous smallest place, where value is less or equal than `h`: that is smallest `j`, such that `j \u003c i` and `heights[j] \u003e= heights[i]`. Ideal data structure for these type of problems is monostack: stack which has the following invariant: elements inside will be always in increasing order. To be more clear let us consired the following histogram `[1,4,2,5,6,3,2,6,6,5,2,1,3]`. Let us go element by element and understand what is going on.\\n\\n1. Stack is empty, so just put first bar of our histogram into stack: so we have `stack = [1]`. (actually what we put inside are indexes of bars, not values, but here we look at values for simplicity).\\n2. Next we put bar `4`, and we have `[1, 4]` now. \\n3. Next, we have bar `2`, which is less than `4`. So, first we evaluate When we evaluate `H` and `W`: width and height rectangle we can construct, using last element of stack as height: they equal to `4` and `1`. Next, we extract `4` and add `2` to stack, so we have `[1, 2]` bars in stack now.\\n4. Next bar is bigger than `2`, so just add it and we have `[1, 2, 5]`\\n5. Next bar is bigger than `5`, so just add it and we have `[1, 2, 5, 6]`\\n6. Next bar is `3`, so we need to extract some stuff from our stack, until it becomes increasing one. We extract `6`, evaluate `(H, W) = (6, 1)` and extract `5` and evaluate `(H, W) = (5, 2)`. Now we have `[1, 2, 3]` in our stack.\\n7. Next bar is `2`, it is smaller than `stack[-1]`, so we again need to extract some stuff: we extract `3` and have `(H, W) = (3, 3)` and also we extract `2` and have `(H, W) = (2, 5)`. Note here, why exactly we have `W = 5`: because we keep in stack indexes of our bars, and we can evaluate width as `i - stack[-1] - 1`. Now, we have `stack = [1, 2]`\\n8. Next bar is `6`, so just put it to stack and we have `stack = [1, 2, 6]`.\\n9. Next bar is `6` also, and we need to extract one last element from stack and put this new `6` to stack. `(H, W) = (6, 1)`. Note, that we have in stack `[1, 2, 6]` again, but it is values, for indexes last index was increased by one.\\n10. Next bar is `5`, we extract last element from stack, have `(H, W) = (6, 2)` and put it to stack, so we have `[1, 2, 5]` now.\\n11. Next bar is `2`, so we again start to pop elements to keep increasing order: `(H, W) = (5, 3)` for fisrt step and `(H, W) = (2, 9)` for second step, now `stack = [1, 2]`.\\n12. Next bar is `1`, so we have `(H, W) = (2, 10)` and then `(H, W) = (1, 11)` and `stack = [1]`.\\n13. Next bar is `3`, so we just put it to stack and have `[1, 3]` in stack.\\n14. Next bar is `0` (we added it to process border cases), so we have `(H, W) = (3, 1)` and `(H, W) = (1, 13)` and finally stack is empty.\\n\\n**Complexity** is `O(n)`, where `n` is number of bars, space complexity is `O(n)` as well.\\n\\n```\\nclass Solution:\\n def largestRectangleArea(self, heights):\\n stack, ans = [], 0\\n for i, h in enumerate(heights + [0]):\\n while stack and heights[stack[-1]] \u003e= h:\\n H = heights[stack.pop()]\\n W = i if not stack else i-stack[-1]-1\\n ans = max(ans, H*W)\\n stack.append(i)\\n return ans\\n```\\n\\nSee also similar problems with monostack idea:\\n\\n**239.** Sliding Window Maximum https://leetcode.com/problems/sliding-window-maximum/discuss/951683/Python-Decreasing-deque-short-explained\\n**496.** Next Greater Element I\\n**739.** Daily Temperatures\\n**862.** Shortest Subarray with Sum at Least K\\n**901.** Online Stock Span\\n**907.** Sum of Subarray Minimums\\n**1687.** Delivering Boxes from Storage to Ports\\n\\n**Please let me know if you know more problems with this idea**\\n\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1609419687, | |
| "creationDate": 1609410242 | |
| } | |
| }, | |
| { | |
| "id": 679918, | |
| "title": "[Python] 2 Solutions: Oneliner and Classical BS explained", | |
| "taskUrl": "https://leetcode.com/problems/search-insert-position", | |
| "post": { | |
| "id": 1256834, | |
| "content": "### Solution 1: bisect\\nIt is not said in the problem statement not to use any libraries, so why not use `bisect_left` function, so conviniently provided by python? Why we use `bisect_left`? Because for `[1,3,5,6]` and number `5` we need to return index `2`: if element is already present in array, the insertion point will be before (to the left of) any existing entries.\\n\\n**Complexity** is classical for binary search: `O(log n)`\\n\\n```\\nclass Solution:\\n def searchInsert(self, nums, target):\\n return bisect.bisect_left(nums, target)\\n```\\n\\n### Solution 2: Classical binary search\\n\\nClassical binary search problem, where we need to return `beg` in the end, because we are looking for left place to insert our symbol.\\n\\n```\\nclass Solution:\\n def searchInsert(self, nums, target):\\n beg, end = 0, len(nums)\\n while beg \u003c end:\\n mid = (beg + end)//2\\n if nums[mid] \u003e= target:\\n end = mid\\n else:\\n beg = mid + 1\\n return beg\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591773941, | |
| "creationDate": 1591772871 | |
| } | |
| }, | |
| { | |
| "id": 875097, | |
| "title": "[Python] bactracking solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/combination-sum", | |
| "post": { | |
| "id": 1596327, | |
| "content": "This is classical backtracking problem, so let us use `BackTr(target, curr_sol, k)` function, where:\\n\\n1. `target` is target we need to build, if we get some number, we subtract if from target.\\n2. `curr_sol` is current solution built so far.\\n3. `k` is index in our `candidates`: each new number we take should have number more or equal than `k`.\\n\\nSo, no in algorighm we do:\\n1. If `target == 0`, it means we found solution, which is kept in `curr_sol`, so we add it to `self.sol` list of all found solutions.\\n2. If `target` if negative or `k` is more than number of candidates, we need to go back.\\n3. Finally, for each candidate index in `k,...`, we run our function recursively with updated parameters.\\n\\n**Complexity**: TBD\\n\\n```\\nclass Solution:\\n def combinationSum(self, candidates, target):\\n def BackTr(target, curr_sol, k): \\n if target == 0:\\n self.sol.append(curr_sol)\\n\\n if target \u003c 0 or k \u003e= len(candidates):\\n return\\n\\n for i in range(k, len(candidates)):\\n BackTr(target - candidates[i], curr_sol + [candidates[i]], i)\\n \\n self.sol = []\\n BackTr(target, [], 0) \\n return self.sol\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601639005, | |
| "creationDate": 1601639005 | |
| } | |
| }, | |
| { | |
| "id": 871665, | |
| "title": "[Python] O(n) solution without additional memory, explained", | |
| "taskUrl": "https://leetcode.com/problems/first-missing-positive", | |
| "post": { | |
| "id": 1590556, | |
| "content": "Notice, that first missinig positive will always be in range `1,2,...n,n+1`, where `n` is length of `nums`. Let us rearrange numbers, putting each number on its place: number `i` on place `i-1` (because indexes start with `0`): let us iterate over our numbers and change two numbers if one of them not on its place: we break if number not in range `1,...,n` or if we are trying to put number on the place, which is already occupied with this place (because we have infinite loop in this case)\\n\\nWhen we iterate all numbers we find for number which is not on its place, using `i == nums[i] - 1`. It can happen that all numbers between `1` and `n` are here, so I add `[0]` to the end. Finally, I found index of `False` in this array: it will be our number.\\n\\n**Complexity**: even though we have `while` loop inside `for` loop, complexity will be `O(n)`: on each step we put at least one number to its proper place. Additional space complexity is `O(1)`, however we modify our `nums`.\\n\\nThis solution is very similar to problem **442. Find All Duplicates in an Array**, see my detailed solution here https://leetcode.com/problems/find-all-duplicates-in-an-array/discuss/775738/Python-2-solutions-with-O(n)-timeO(1)-space-explained\\n\\n```\\nclass Solution:\\n def firstMissingPositive(self, nums):\\n n = len(nums)\\n for i in range(n):\\n while nums[i]-1 in range(n) and nums[i] != nums[nums[i]-1]:\\n nums[nums[i]-1], nums[i] = nums[i], nums[nums[i]-1]\\n \\n return next((i + 1 for i, num in enumerate(nums) if num != i + 1), n + 1) \\n```\\n\\nThanks to **QwerMike** for pointing out that my last line were using `O(n)` memory and he kindly suggested to use iterators instead, code is corrected now.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601495664, | |
| "creationDate": 1601453965 | |
| } | |
| }, | |
| { | |
| "id": 932924, | |
| "title": "[Python] simple dfs/backtracking explained", | |
| "taskUrl": "https://leetcode.com/problems/permutations-ii", | |
| "post": { | |
| "id": 1697332, | |
| "content": "Another classical backtracking problem. Let us try to built our sequence element by element, inserting new element in different places. Imagine, that we have `[1,3,1,2]`. Then our building process will look like:\\n\\n1. `[1]` on the first step we have not choice, so here we have only one option.\\n2. Now, we need to insert next element somewhere, and we have two options: before and after, so we have `[1,3]` and `[3,1]` options here.\\n3. Now we need to insert new element `1`. The problem here is that when we insert it, we can have repeating answers, so the rule is: insert in only before the already existing occurrences of this element. So, in `[1,3]` we can only insert it before `1` and get `[1,1,3]` and in `[3,1]` we have two places to insert and we have `[1,3,1]` and `[3,1,1]`.\\n4. Finally, we want to insert `2` to the each of existing answers, and we have: `[2,1,1,3]`, `[1,2,1,3]`, `[1,1,2,3]`, `[1,1,3,2]`, `[2,1,3,1]`, `[1,2,3,1]`, `[1,3,2,1]`, `[1,3,1,2]`, `[2,3,1,1]`, `[3,2,1,1]`, `[3,1,2,1]`, `[3,1,1,2]` \\n\\n**Complexity**: Time complexity is `O(Q n)`, where `Q` is number of desired permutations and `n` is length of `nums`, because every time we build our sequence we write it in our final answer, that is there will be no dead-ends. `Q` can be evaluated, using multinomial coefficients https://en.wikipedia.org/wiki/Multinomial_theorem. Space complexity is the same. \\n\\n```\\nclass Solution:\\n def permuteUnique(self, nums):\\n def dfs(ind, built):\\n if ind == len(nums):\\n ans.append(built)\\n return\\n\\n stop = built.index(nums[ind]) if nums[ind] in built else ind\\n \\n for i in range(stop+1):\\n dfs(ind+1, built[:i]+[nums[ind]]+built[i:])\\n\\n ans = []\\n dfs(0, []) \\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605257705, | |
| "creationDate": 1605173780 | |
| } | |
| }, | |
| { | |
| "id": 738830, | |
| "title": "[Python] recursive O(log n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/powx-n", | |
| "post": { | |
| "id": 1360812, | |
| "content": "This problem has in my opinion a bit strange statement: it is not specified that we can not use already existing power or logarithm function, but I will consider, that we can not use them. Also in python numbers potentially can be very big or very close to zero, what should we do in these cases? You should ask you interviewer. \\n\\nThe main idea of solution is to use as much multiplications as possible, for example how can we evaluate `x^20`? We can just multiply `x` in loop `20` times, but we also can evaluate `x^10` and multiply it by itself! Similarly, `x^10 = x^5 * x^5`. Now we have odd power, but it is not a problem, we evaluate `x^5 = x^2 * x^2 * x`. We also need to deal with some border cases, here is the full algorithm:\\n\\n1. If we have very small value of `x` we can directly return `0`, the smallest value of float is `1.175494 \\xD7 10^(-38)`.\\n2. If we have `n = 0`, return `1`.\\n3. If we have negative power, return positive power of `1/x`.\\n4. Now, we have two cases: for even and for odd `n`, where we evaluate power `n//2`.\\n\\n**Complexity**: time complexity is `O(log n)`, space complexity for this recursive algorithm is also `O(log n)`, which can be reduced to `O(1)`, if we use iterative approach instead.\\n```\\nclass Solution:\\n def myPow(self, x, n):\\n if abs(x) \u003c 1e-40: return 0 \\n if n == 0: return 1\\n if n \u003c 0: return self.myPow(1/x, -n)\\n lower = self.myPow(x, n//2)\\n if n % 2 == 0: return lower*lower\\n if n % 2 == 1: return lower*lower*x\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594885274, | |
| "creationDate": 1594885016 | |
| } | |
| }, | |
| { | |
| "id": 939998, | |
| "title": "[Python] Sort and traverse, explained", | |
| "taskUrl": "https://leetcode.com/problems/merge-intervals", | |
| "post": { | |
| "id": 1709600, | |
| "content": "Let us sort our intervals by its starts and then iterate them one by one: we can have two options:\\n\\n1. The current ending point in our `ans` is less than `beg` of new interval: it means that we have a gap and we need to add new interval to our answer.\\n2. In the opposite case our intervals are overlapping, so we need to update the end for last interval we created.\\n\\n**Complexity:** time complexity is `O(n log n)` to sort intervals and space complexity is `O(n)` to keep sorted intervals and answer.\\n\\n```\\nclass Solution:\\n def merge(self, intervals):\\n ans = []\\n \\n for beg, end in sorted(intervals):\\n if not ans or ans[-1][1] \u003c beg:\\n ans += [[beg, end]]\\n else:\\n ans[-1][1] = max(ans[-1][1], end)\\n\\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605689322, | |
| "creationDate": 1605689322 | |
| } | |
| }, | |
| { | |
| "id": 844494, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/insert-interval", | |
| "post": { | |
| "id": 1542486, | |
| "content": "I am not sure, why this problem is marked as hard, because we do not use any smart ideas to solve it: just do what is asked: traverse our intervals and merge them. Let us consider the case: `intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]` and go through our code:\\n\\n1. Interval `[1,2]` is before `[4,8]`, that is `y \u003c I[0]`, so we just add it to our `res`.\\n2. Interval `[3,5]` is not before `[4,8]` but not after also, so it is the third case and we need to update `I`: `I = [3,8]` now.\\n3. Interval `[6,7]`: the same logic, update `I = [3,8]` now (it did not change though)\\n4. Interval `[8,10]`: still condition number `3`, so `I = [3,10]` now.\\n5. Interval `[12,16]`: it is after our `I`, so this is condition number `2` and we `break` from our loop: `i = 3` now.\\n6. Outside loop we combine `res = [1,2]`, `I = [3,10]` and `intervals[4:] = [12,16]`.\\n\\nWhy we use `i -= 1` inside our loop, before `break`? It can happen, that we did not visit this part and it means, that our suffix `intervals[i+1:]` should be empty.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(n)` as well and additional space complexity (if we do not count our output) is `O(1)`.\\n\\n**Note**: that intstead of traversing our intervals with linear search, we can use binary search, however it will not reduce the overall complexity of algorithm, our result will have in average `O(n)` elements.\\n\\n```\\nclass Solution:\\n def insert(self, intervals, I):\\n res, i = [], -1\\n for i, (x, y) in enumerate(intervals):\\n if y \u003c I[0]:\\n res.append([x, y])\\n elif I[1] \u003c x:\\n i -= 1\\n break\\n else:\\n I[0] = min(I[0], x)\\n I[1] = max(I[1], y)\\n \\n return res + [I] + intervals[i+1:]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600067706, | |
| "creationDate": 1599985489 | |
| } | |
| }, | |
| { | |
| "id": 847535, | |
| "title": "[Python] solution without split, explained", | |
| "taskUrl": "https://leetcode.com/problems/length-of-last-word", | |
| "post": { | |
| "id": 1548118, | |
| "content": "We can just split our string, remove all extra spaces and return length of the last word, however we need to spend `O(n)` time for this, where `n` is length of our string. There is a simple optimization: let us traverse string from the end and:\\n1. find the last element of last word: traverse from the end and find first non-space symbol.\\n2. continue traverse and find first space symbol (or beginning of string)\\n3. return `end` - `beg`.\\n\\n**Complexity**: is `O(m)`, where `m` is length of part from first symbol of last word to the end. Space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def lengthOfLastWord(self, s):\\n end = len(s) - 1\\n while end \u003e 0 and s[end] == \" \": end -= 1\\n beg = end\\n while beg \u003e= 0 and s[beg] != \" \": beg -= 1\\n return end - beg\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600156428, | |
| "creationDate": 1600156428 | |
| } | |
| }, | |
| { | |
| "id": 963128, | |
| "title": "[Python] rotate, when need, explained", | |
| "taskUrl": "https://leetcode.com/problems/spiral-matrix-ii", | |
| "post": { | |
| "id": 1749551, | |
| "content": "Let us notice one clue property about our spiral matrix: first we need to go to the right and rotate clockwise 90 degrees, then we go down and again when we reached bottom, we rotate 90 degrees clockwise and so on. So, all we need to do is to rotate 90 degrees clockwise when we need:\\n1. When we reached border of our matrix\\n2. When we reached cell which is already filled.\\n\\nLet `x, y` be coordinates on our `grid` and `dx, dy` is current direction we need to move. In geometrical sense, rotate by `90` degrees clockwise is written as `dx, dy = -dy, dx`.\\n\\nNote, that `matrix[y][x]` is cell with coordinates `(x,y)`, which is not completely obvious.\\n\\n**Complexity**: time complexity is `O(n^2)`, we process each element once. Space complexity is `O(n^2)` as well.\\n\\n```\\nclass Solution:\\n def generateMatrix(self, n):\\n matrix = [[0] * n for _ in range(n)]\\n x, y, dx, dy = 0, 0, 1, 0\\n for i in range(n*n):\\n matrix[y][x] = i + 1\\n if not 0 \u003c= x + dx \u003c n or not 0 \u003c= y + dy \u003c n or matrix[y+dy][x+dx] != 0:\\n dx, dy = -dy, dx\\n x, y = x + dx, y + dy\\n return matrix\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607331959, | |
| "creationDate": 1607331725 | |
| } | |
| }, | |
| { | |
| "id": 696390, | |
| "title": "[Python] Math solution + Oneliner, both O(n^2), expained", | |
| "taskUrl": "https://leetcode.com/problems/permutation-sequence", | |
| "post": { | |
| "id": 1286700, | |
| "content": "The simplest way to solve this problem is use backtracking, where you just generate all sequences, with complexity `O(k) = O(n!)`. We can do better. Let us consider an example: `n=6`, `k=314`. How we can find the first digit? There are `5! = 120` permutations, which start with `1`, there are also `120` permutations, which start with `2`, and so on. `314 \u003e 2*120` and `314 \u003c 3*120`, so it means, that the fist digit we need to take is `3`. So we build first digit of our number, remove it from list of all digits `digits` and continue:\\n\\n1. `k = 314-2*5! = 74`, `n - 1 = 5`, `d = 3`, build number so far `3`, `digits = [1,2,4,5,6]`\\n2. `k = 74-3*4! = 2`, `n - 1 = 4`, `d = 0`, build number so far `35`, `digits = [1,2,4,6]`\\n3. `k = 2-0*3! = 2`, `n - 1 = 3`, `d = 0`, build number so far `351`, `digits = [2,4,6]`\\n4. `k = 2-1*2! = 0`, `n - 1 = 2`, `d = 2`, build number so far `3512`, `digits = [4,6]`\\n5. `k = 0-1*1! = 0`, `n - 1 = 1`, `d = 2`, build number so far `35126`, `digits = [4]`\\n6. Finally, we have only one digit left, output is `351264`.\\n\\n**Complexity**. I keep list of `n` digits, and then delete them one by one. Complexity of one deletion is `O(n)`, so overall complexity is `O(n^2)`. Note, that it can be improved to `O(n log n)` if we use SortedList, but it just not worth it, `n` is too small.\\n\\n```\\nclass Solution:\\n def getPermutation(self, n, k):\\n numbers = list(range(1,n+1))\\n answer = \"\"\\n \\n for n_it in range(n,0,-1):\\n d = (k-1)//factorial(n_it-1)\\n k -= d*factorial(n_it-1)\\n answer += str(numbers[d])\\n numbers.remove(numbers[d])\\n \\n return answer\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**\\n\\n### Oneliner\\nHere it is, with `O(n^2)` complexity!\\n\\n```\\nreturn reduce(lambda s,n:(s[0]+s[2][(d:=s[1]//(f:=factorial(n)))],s[1]%f,s[2][:d]+s[2][d+1:]),range(n-1,-1,-1),(\\'\\',k-1,\\'123456789\\'))[0]\\n```", | |
| "updationDate": 1592670530, | |
| "creationDate": 1592638917 | |
| } | |
| }, | |
| { | |
| "id": 883252, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/rotate-list", | |
| "post": { | |
| "id": 1610277, | |
| "content": "What we need to do in this problem is to find `k`-th element from the end, cut list in two parts and put second part after the first one. Let us do in it several steps:\\n\\n1. Find `n`, length of our list, just traverse it until we reached end.\\n2. If `k % n == 0`, we do not need to rotate list, so return it as it is.\\n3. Find element where we need to cut our list: it has number `n - k%n`, but we need to cut previous connection, so we stop one element earlier.\\n4. Finally, put new head as `middle.next`, make connection between head and tail of original ist and remove connection between `middle` and its next, return new head.\\n\\n**Complexity** is `O(n)` for time: we traverse our list twice at most; space complexity is `O(1)`, we did not use any additional space.\\n\\n```\\nclass Solution:\\n def rotateRight(self, head, k):\\n if not head or not head.next: return head\\n \\n last, n = head, 1\\n while last.next:\\n last = last.next\\n n += 1\\n \\n if k % n == 0: return head\\n \\n middle = head\\n for i in range(n - k%n-1):\\n middle = middle.next\\n \\n new_head = middle.next\\n last.next = head\\n middle.next = None\\n return new_head\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602062136, | |
| "creationDate": 1602062136 | |
| } | |
| }, | |
| { | |
| "id": 711190, | |
| "title": "[Python] 2 solutions: dp and oneliner math, explained", | |
| "taskUrl": "https://leetcode.com/problems/unique-paths", | |
| "post": { | |
| "id": 1312281, | |
| "content": "### 1. Dynamic programming solution\\nOne way to solve this problem is to use **dynamic programming**: define by `dp[i][j]` number of ways to reach point `(i,j)`. How can we reach it, there are two options:\\n1. We can reach it from above `(i, j-1)`.\\n2. We can reach it from the left: `(i-1, j)`.\\n\\nThat is all! We just evaluate `dp[i][j] = dp[i-1][j] + dp[i][j-1]`\\n**Complexity**: time comlexity is `O(mn)`, space complexity is `O(mn)`, which can be improved to `O(min(m,n))`.\\n\\n```\\nclass Solution:\\n def uniquePaths(self, m, n):\\n dp = [[1] * n for _ in range(m)]\\n for i,j in product(range(1,m),range(1,n)):\\n dp[i][j] = dp[i-1][j] + dp[i][j-1] \\n return dp[-1][-1]\\n```\\n\\n### 2. Math solution\\n\\nNote, that we need to make overall `n + m - 2` steps, and exactly `m - 1` of them need to be right moves and `n - 1` down steps. By definition this is numbef of combinations to choose `n - 1` elements from `n + m - 2`.\\n\\n**Complexity**: time complexity is `O(m+n)`, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def uniquePaths(self, m, n):\\n return factorial(m+n-2)//factorial(m-1)//factorial(n-1)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593415206, | |
| "creationDate": 1593415206 | |
| } | |
| }, | |
| { | |
| "id": 722211, | |
| "title": "[Python] Find maximum number of 9 in the end, explained", | |
| "taskUrl": "https://leetcode.com/problems/plus-one", | |
| "post": { | |
| "id": 1331935, | |
| "content": "How we can add `1` to given number? We need to find the biggest number of `9` in the end of our number, for example for number `5123521999235123999`, there will be three `9` in the end. `512352199923512`**3999**` + 1 = 512352199923512`**4000**: so we need to increase previous symbol by one and change all `9` after to `0`. Now, the steps of algorithm are to following:\\n\\n1. Let us add one `0` before our data to handle cases like `9`, `99`, `999`, ... \\n2. Find maximum number of `9`, starting from the end and moving to the left.\\n3. Change all found `9` in the end to `0` and previous digit increasy by `1`.\\n4. Handle border cases: if we have leading zero, remove it.\\n\\n**Complexity** time complexity is `O(n)`, where `n` is length of list. Additional space complexity is `O(1)`, because we edit input data directly.\\n\\n```\\nclass Solution:\\n def plusOne(self, digits):\\n digits = [0] + digits\\n \\n end = len(digits) - 1\\n while digits[end] == 9:\\n end -= 1\\n \\n digits[end] += 1\\n digits[end+1:] = [0] * (len(digits)-1-end)\\n \\n return digits if digits[0] != 0 else digits[1:] \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594024345, | |
| "creationDate": 1594020548 | |
| } | |
| }, | |
| { | |
| "id": 743698, | |
| "title": "[Python] 8 Lines neat solution, Explained", | |
| "taskUrl": "https://leetcode.com/problems/add-binary", | |
| "post": { | |
| "id": 1369283, | |
| "content": "What we need to do in this problem is just add two numbers given in binary representation. How we can do it? Using usual schoolbook \\u0441olumnar addition of course! So, we need to start from the last column and add two digits and also not to forget about `carry`. We need to stop when we reached beginning of both numbers. `d1` and `d2` are current processed digits. We form `summ` string, adding element to the end and in the end we reverse it.\\n\\n**Complexity**: time complexity is `O(n + m)`, where `n` and `m` are lengths of numbers, space complexity is `O(max(m,n))`, because result will have this length.\\n\\n```\\nclass Solution:\\n def addBinary(self, a, b):\\n i, j, summ, carry = len(a) - 1, len(b) - 1, \"\", 0\\n while i \u003e= 0 or j \u003e= 0 or carry:\\n d1 = int(a[i]) if i \u003e= 0 else 0\\n d2 = int(b[j]) if j \u003e= 0 else 0\\n summ += str((d1 + d2 + carry) % 2)\\n carry = (d1 + d2 + carry) // 2\\n i, j = i-1, j-1 \\n return summ[::-1]\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595146591, | |
| "creationDate": 1595146591 | |
| } | |
| }, | |
| { | |
| "id": 764847, | |
| "title": "[Python] 2 solution: dp + Fibonacci math, explained", | |
| "taskUrl": "https://leetcode.com/problems/climbing-stairs", | |
| "post": { | |
| "id": 1405149, | |
| "content": "### Solution 1:\\n\\nWe can climb either `1` or `2` steps, and we are interested how many ways to climb ladder with `n` stairs. How can we reach step number `n`:\\n1. Making step with size `1`, so from step with number `n-1`\\n2. Making step with size `2`, so from step with number `n-2`.\\n\\nSo, if we denote `F[n]` numbers of ways to reach step number `n`, we can write equation: `F[n] = F[n-1] + F[n-2]`. But it is not enough, we also need to define starting cases: `F[1] = 1` and `F[2] = 2`. Or we can say, that `F[0] = 1` and `F[1] = 1`.\\n\\nNow, everything is ready to write our dynamic programming problem.\\n\\n**Complexity**: time complexity is `O(n)` and space complexity is `O(1)`.\\n\\n\\n\\n```\\nclass Solution:\\n def climbStairs(self, n):\\n dp = (1, 1)\\n for i in range(n-1):\\n dp = (dp[1], dp[0] + dp[1])\\n return dp[1]\\n```\\n\\n### Solution 2\\n\\nIf we look carefully at equation `F[n] = F[n-1] + F[n-2]` and starting points, we can see, that we have nothing else, than Fibonacci sequence:\\n\\n`1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ...`\\n\\nNote however, that it is shifted by one position. So, what we need to do is to use Binet formula: https://en.wikipedia.org/wiki/Fibonacci_number#Binet\\'s_formula, where we use computation by rounding.\\n\\n**Complexity**: both time and memory is `O(1)` if we assume that number in `int32` range and if we assume complexity of `**` as `O(1)`.\\n\\n```\\nreturn round((0.5+sqrt(5)/2)**(n+1)/sqrt(5))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596185715, | |
| "creationDate": 1596184487 | |
| } | |
| }, | |
| { | |
| "id": 662395, | |
| "title": "[Python] Classical DP, O(mn) explained", | |
| "taskUrl": "https://leetcode.com/problems/edit-distance", | |
| "post": { | |
| "id": 1226919, | |
| "content": "This is very classical dynamic programming problem (there is even wikipedia page https://en.wikipedia.org/wiki/Edit_distance), which I think can not be solved without it. If I am wrong, please let me know!\\n\\nLet `dp[i_1][i_2]` be the edit distance for words `dp[:i_1]` and `dp[:i_2]`. Then there can be 4 options: we can insert symbol on position `i_1` in the first word, insert symbol on position `i_2` in the second word, replace symbol `i_1` in first word with `i_2` if these symbols are different and look into `dp[i_1-1][i_2-1]` if these two symbols are the same.\\n\\n**Complexity**: time complexity is `O(mn)`, and space comlexity as well. Space complexity can be improved to `O(m+n)` if we keep only current row or column.\\n\\nWe add stopsymbols in the beggining of words to deal with border cases in simpler way.\\n\\n```\\nclass Solution:\\n def minDistance(self, word1, word2):\\n word1, word2 = \"!\" + word1, \"!\" + word2\\n n_1, n_2 = len(word1), len(word2)\\n dp = [[0] * n_2 for _ in range(n_1)]\\n\\n for i_1 in range(n_1): dp[i_1][0] = i_1\\n for i_2 in range(n_2): dp[0][i_2] = i_2\\n\\n for i_1 in range(1, n_1):\\n for i_2 in range(1,n_2):\\n Cost = (word1[i_1] != word2[i_2])\\n dp[i_1][i_2] = min(dp[i_1-1][i_2] + 1, dp[i_1][i_2-1] + 1, dp[i_1-1][i_2-1] + Cost)\\n\\n return int(dp[-1][-1])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!I**", | |
| "updationDate": 1590914064, | |
| "creationDate": 1590914064 | |
| } | |
| }, | |
| { | |
| "id": 896821, | |
| "title": "[Python] Simple binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/search-a-2d-matrix", | |
| "post": { | |
| "id": 1633769, | |
| "content": "What we have in this problem is matrix, which is sorted and what we use to find element in sorted structure? Correct, this is binary search. Imagine, that we have matrix\\n\\n`10 11 12 13`\\n`14 15 16 17`\\n`18 19 20 21`\\n\\nLet us flatten this matrix, so now we have `10 11 12 13 14 15 16 17 18 19 20 21` and do binary search in this list. However if you do it, we will have `O(mn)` complexity, so we will use **virtual** flatten: we do not do it for all matrix, but only for elements we need: if we need element number `i` from our flattened list, it coresponds to element `matrix[i//m][i%m]` in our matrix.\\n\\n**Complexity**: time complexity is `O(log mn)`, space complexity is `O(1)`.\\n\\n\\n```\\nclass Solution:\\n def searchMatrix(self, matrix, target):\\n if not matrix or not matrix[0]: return False\\n m, n = len(matrix[0]), len(matrix)\\n beg, end = 0, m*n - 1\\n while beg \u003c end:\\n mid = (beg + end)//2\\n if matrix[mid//m][mid%m] \u003c target:\\n beg = mid + 1\\n else:\\n end = mid\\n return matrix[beg//m][beg%m] == target\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602836638, | |
| "creationDate": 1602836638 | |
| } | |
| }, | |
| { | |
| "id": 681526, | |
| "title": "[Python] O(n) 3 pointers in-place approach explained", | |
| "taskUrl": "https://leetcode.com/problems/sort-colors", | |
| "post": { | |
| "id": 1259795, | |
| "content": "This problem is called Dutch national flag problem: https://en.wikipedia.org/wiki/Dutch_national_flag_problem\\n\\nThe idea here is the following: we keep 3 pointers: for each of colors (numbers). I called them\\n`beg = 0`, `mid = 0`, `end = len(nums) - 1`. The **idea** here is to put sorted `0` and `1` to the **beginning** and sorted `2`s to the **end**. Then we iterate over all elements and process each new element in the following way. Imagine, that we already sorted some of the elements, our invariant will be `00...0011...11......22....22`, where we already put some `0` and `1` in the beggining and some `2` to the end. Then there are 3 possible optinos for new element `?`:\\n\\n1. `00...0011...11?......22....22`, where `? = 1`, then we do not need to change any elements, just move `mid` pointer by `1` to the right.\\n2. `00...0011...11?......22....22`, where `? = 2`, then we need to put this element befor the first already sorted `2`, so we change these elements and then move pointer `end` by `1` to the left.\\n3. `00...0011...11?......22....22`, where `? = 0`, then we need to swap this element with the last sorted `0` and also move two pointers `mid` and `beg` by 1.\\n\\nWe can see it this way, that pointers `beg`, `mid` and `end` always point at elements just `after` the last `0`, `after` the last `1` and `before` the first `2`.\\n\\n**Complexity**: Time complexity is `O(n)`, because each moment of time we move at least one of the pointers. Additional space complexity is `O(1)`: to keep only 3 variables: `beg`, `mid` and `end`.\\n\\n```\\nclass Solution:\\n def sortColors(self, nums):\\n beg, mid, end = 0, 0, len(nums) - 1\\n \\n while mid \u003c= end:\\n if nums[mid] == 0:\\n nums[beg], nums[mid] = nums[mid], nums[beg]\\n mid += 1\\n beg += 1\\n elif nums[mid] == 2:\\n nums[mid], nums[end] = nums[end], nums[mid]\\n end -= 1\\n else: #nums[mid] == 1:\\n mid += 1\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591886999, | |
| "creationDate": 1591859673 | |
| } | |
| }, | |
| { | |
| "id": 729842, | |
| "title": "[Python] 3 Solutions: Backtracking + 2 oneliners, explained", | |
| "taskUrl": "https://leetcode.com/problems/subsets", | |
| "post": { | |
| "id": 1345332, | |
| "content": "In this problem we need to return all posible subsets of given set, and there are a big number of them: `2^n`. It usually means, that we need to use some backtracking approach to do it.\\nLet us have function `dfs(self, current, nums)`, with parameters:\\n1. `current` is set of indexes choosen number: we always choose indexes in increasing order. \\n2. `nums` are our original numbers (we can make it global varialbe as well).\\n\\nAlso I start with dummy variable index `-1`, and when we add subset to final answer, we remove this element. Then we recursively run `dfs` with new added number `i`.\\n\\n**Complexity**: both time ans space is `O(2^n*n)`, because we have `2^n` subsets with n/2 elements in average.\\n\\n```\\nclass Solution:\\n def subsets(self, nums):\\n self.out = []\\n self.dfs([-1],nums)\\n return self.out\\n\\n def dfs(self, current, nums):\\n self.out.append([nums[s] for s in current][1:])\\n for i in range(current[-1] + 1, len(nums)):\\n self.dfs(current + [i], nums)\\n```\\n\\n**Oneliners**\\nFirst one is to use `combinations` library from python, and we itarate over all possible number of elements. Second one uses binary masks.\\n\\n```\\nreturn chain.from_iterable(combinations(nums, i) for i in range(len(nums)+1))\\n\\nreturn [[nums[j] for j in range(len(nums)) if (i\u0026(1\u003c\u003cj))] for i in range(1\u003c\u003clen(nums))]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594480330, | |
| "creationDate": 1594452488 | |
| } | |
| }, | |
| { | |
| "id": 747144, | |
| "title": "[Python] dfs backtracking solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/word-search", | |
| "post": { | |
| "id": 1375176, | |
| "content": "In general I think this problem do not have polynomial solution, so we need to check a lot of possible options. What should we use in this case: it is bruteforce, with backtracking. Let `dfs(ind, i, j)` be our backtracking function, where `i` and `j` are coordinates of cell we are currently in and `ind` is index of letter in `word` we currently in. Then our `dfs` algorithm will look like:\\n1. First, we have `self.Found` variable, which helps us to finish earlier if we already found solution.\\n2. Now, we check if `ind` is equal to `k` - number of symbols in `word`. If we reach this point, it means we found `word`, so we put `self.Found` to `True` and return back.\\n3. If we go outside our board, we return back.\\n4. If symbol we are currently on in `words` is not equal to symbol in table, we also return back.\\n5. Then we visit all neibours, putting `board[i][j] = \"#\"` before - we say in this way, that this cell was visited and changing it back after.\\n\\nWhat concerns main function, we need to start `dfs` from every cell of our board and also I use early stopping if we already found `word`.\\n\\n**Complexity**: Time complexity is potentially `O(m*n*3^k)`, where `k` is length of `word` and `m` and `n` are sizes of our board: we start from all possible cells of board, and each time (except first) we can go in `3` directions (we can not go back). In practice however this number will be usually much smaller, because we have a lot of dead-ends. Space complexity is `O(k)` - potential size of our recursion stack. If you think this analysis can be improved, please let me know!\\n\\n```\\nclass Solution:\\n def exist(self, board, word):\\n def dfs(ind, i, j):\\n if self.Found: return #early stop if word is found\\n\\n if ind == k:\\n self.Found = True #for early stopping\\n return \\n\\n if i \u003c 0 or i \u003e= m or j \u003c 0 or j \u003e= n: return \\n tmp = board[i][j]\\n if tmp != word[ind]: return\\n\\n board[i][j] = \"#\"\\n for x, y in [[0,-1], [0,1], [1,0], [-1,0]]:\\n dfs(ind + 1, i+x, j+y)\\n board[i][j] = tmp\\n \\n self.Found = False\\n m, n, k = len(board), len(board[0]), len(word)\\n \\n for i, j in product(range(m), range(n)):\\n if self.Found: return True #early stop if word is found\\n dfs(0, i, j)\\n return self.Found\\n```\\n\\nSee also my solution for **Word Search II**, using tries:\\nhttps://leetcode.com/problems/word-search-ii/discuss/712733/Python-Trie-solution-with-dfs-explained\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595324981, | |
| "creationDate": 1595320631 | |
| } | |
| }, | |
| { | |
| "id": 967951, | |
| "title": "[Python] Two pointers approach, explained", | |
| "taskUrl": "https://leetcode.com/problems/remove-duplicates-from-sorted-array-ii", | |
| "post": { | |
| "id": 1757803, | |
| "content": "Let us use two pointers approach here: `slow` pointer and `fast` pointer, where slow will always be less or equal to fast. We are asked to remove duplicates only if we have more `2` of them, so we start with `slow` and `fast` equal to `2`.\\n\\nThen we iterate through our data and check if `nums[slow - 2] == nums[fast]`: what does it mean? It means, that in fact `nums[slow-2] = ... = nums[fast]` and that we already have group of `3` or more equal elements: it this case we understand, that `slow` place should be rewritten with something else from future, so we do not move it. In other case, we have group of `2` or smaller, so we need to move `slow` pointer to right. In any case we move `fast` pointer one place to the right.\\n\\n**Complexity**: time complexity is `O(n)`, we move our two pointers only in one direction. Space complexity is `O(1)`: we do it in-place as asked.\\n\\nNote also, that this can be easily adjacted if you asked to have not `2` duplicates, but `k`: in this case we just need to change all 3 occurences of `2` to `k`.\\n\\n```\\nclass Solution:\\n def removeDuplicates(self, nums):\\n\\t\\tif len(nums) \u003c 2: return len(nums)\\n slow, fast = 2, 2\\n\\n while fast \u003c len(nums):\\n if nums[slow - 2] != nums[fast]:\\n nums[slow] = nums[fast]\\n slow += 1\\n fast += 1\\n return slow\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607703731, | |
| "creationDate": 1607675055 | |
| } | |
| }, | |
| { | |
| "id": 942575, | |
| "title": "[Python] Binary search + dfs, explained with diagram", | |
| "taskUrl": "https://leetcode.com/problems/search-in-rotated-sorted-array-ii", | |
| "post": { | |
| "id": 1713853, | |
| "content": "The idea here is to use both binary search and dfs: each time we compare `nums[mid]` and `nums[end]` and we can have several options:\\n1. `nums[mid] \u003e nums[end]`, for example data can look like `3,4,5,6,7,1,2`. Then we need to check conditions:\\na. If `nums[end] \u003c target \u003c= nums[mid]`, then it means, that we need to look in the left half of our data: see region `1` on the left image.\\nb. Else means, that we need to look in the right half of data.\\n2. `nums[mid] \u003c nums[end]`, for example data can look like `6,7,1,2,3,4,5`. Then we need to check conditions:\\na. `if nums[mid] \u003c target \u003c= nums[end]`, then it means, that we need to look in the right half of our data: see region `1` on the right image.\\nb. Else means, that we need to look in the left half of data.\\n3. In this problem it can happen, that `nums[mid] == nums[end]`, and in this case we do not know where to find our number, so we just look for it in both halves.\\n\\n**Complexity**: if we do not have any duplicates, it is for sure `O(log n)`. If we have any, it can be potentially `O(n)` for cases like `111111111111121111`: where we do not know the place of `2` and we basically need to traverse all elements to find it.\\n\\n\\n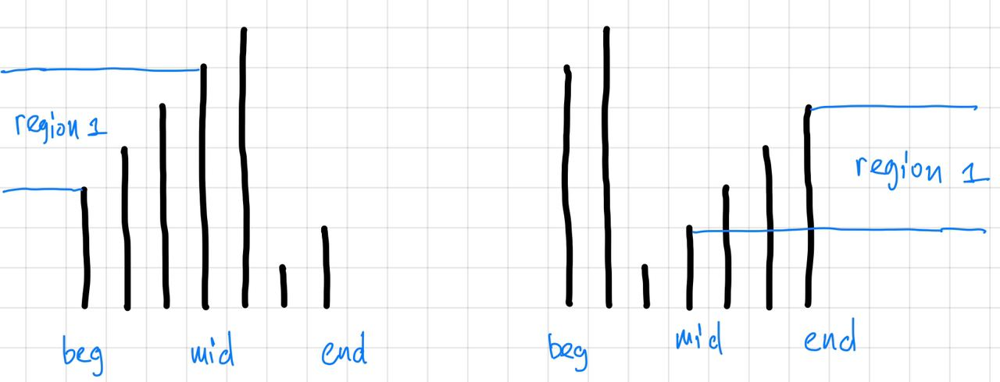\\n\\n\\n\\n```\\nclass Solution:\\n def search(self, nums, target):\\n def dfs(beg, end):\\n if end - beg \u003c= 1: return target in nums[beg: end+1]\\n \\n mid = (beg + end)//2\\n if nums[mid] \u003e nums[end]: # eg. 3,4,5,6,7,1,2\\n if nums[end] \u003c target \u003c= nums[mid]:\\n return dfs(beg, mid)\\n else:\\n return dfs(mid + 1, end)\\n elif nums[mid] \u003c nums[end]: # eg. 6,7,1,2,3,4,5\\n if nums[mid] \u003c target \u003c= nums[end]:\\n return dfs(mid + 1, end)\\n else:\\n return dfs(beg, mid)\\n else:\\n return dfs(mid+1, end) or dfs(beg, mid)\\n \\n return dfs(0, len(nums)-1)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605901495, | |
| "creationDate": 1605864568 | |
| } | |
| }, | |
| { | |
| "id": 987013, | |
| "title": "[Python] O(n) time/O(1) space dp, explained", | |
| "taskUrl": "https://leetcode.com/problems/decode-ways", | |
| "post": { | |
| "id": 1789614, | |
| "content": "Let us use dynamic programming for this problem, where we keep `3` values on each step:\\n\\n1. `dp[0]` is total numbers to decode number `s[:i]`.\\n2. `dp[1]` is number of ways to decode number `s[:i]`, if it ends with `1` and last digit is **part of 2-digit number**. This is important point.\\n3. `dp[2]` is number of ways to decode number `s[:i]`, if it ends with `2` and last digit is **part of 2-digit number**.\\n\\nNow, we need to understand how to update our numbers:\\n1. For `dp_new[0]` we can have `3` options: if last digit is more than `0`, than we can take it as `1-digit number` (by definition each part is number between 1 and 26). Also, we can take last number as 2-digit number if it starts with `1`: this is exactly `dp[1]`. and if it starts with `2` and last digit is less or equal to `6`.\\n2. For `dp_new[1]` we have only one option: we need to have last symbol equal to `1`. \\n3. Similar for `dp_new[2]`, we need to have last symbol equal to `2`.\\n\\n**Complexity**: time complexity is `O(n)`: we iterate over each symbol once. Space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def numDecodings(self, s):\\n dp = [1, 0, 0]\\n for c in s:\\n dp_new = [0,0,0]\\n dp_new[0] = (c \u003e \\'0\\') * dp[0] + dp[1] + (c \u003c= \\'6\\') * dp[2]\\n dp_new[1] = (c == \\'1\\') * dp[0]\\n dp_new[2] = (c == \\'2\\') * dp[0]\\n dp = dp_new\\n return dp[0]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1609059513, | |
| "creationDate": 1608974042 | |
| } | |
| }, | |
| { | |
| "id": 703049, | |
| "title": "[Python] Math oneliner O(n), using Catalan number, explained", | |
| "taskUrl": "https://leetcode.com/problems/unique-binary-search-trees", | |
| "post": { | |
| "id": 1298240, | |
| "content": "In this problem we are asked to get number of trees and not necceseraly to return all trees, only **number**. Here we can use the idea of **dynamic programming**, let `dp[n]` be the number of unique Binary Search Trees with `n` nodes. How can we evaluate them: we need to choose number of nodes in the left subtree and number of nodes in the right subtree, for example `n=5`, then we have options:\\n1. left subtree has 0 nodes, root = 1, and right subtree has 4 nodes, number of options `f[0]*f[4]`\\n2. left subtree has 1 nodes, root = 2, and right subtree has 3 nodes, number of options `f[1]*f[3]`\\n3. left subtree has 2 nodes, root = 3, and right subtree has 2 nodes, number of options `f[2]*f[2]`\\n4. left subtree has 3 nodes, root = 4, and right subtree has 1 nodes, number of options `f[3]*f[1]`\\n5. left subtree has 4 nodes, root = 5, and right subtree has 0 nodes, number of options `f[4]*f[0]`\\n\\nSo, in total `f[5] = f[0]*f[4] + f[1]*f[3] + f[2]*f[2] + f[3]*f[1] + f[4]*f[0]`, and in general:\\n`f[n] = f[0]*f[n-1] + f[1]*f[n-2] + ... + f[n-2]*f[1] + f[n-1]*f[0]`.\\n\\nWe can solve this in classical **dynamic programming** way with `O(n^2)` complexity. However we can recognize in this formula **Catalan Numbers**: https://en.wikipedia.org/wiki/Catalan_number and there is direct formula to evaluate them:\\n`f[n] = (2n)!/(n! * n! * (n+1))`.\\n\\n**Complexity**: time complexity is `O(n)` to evaluate all factorials, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def numTrees(self, n):\\n return factorial(2*n)//factorial(n)//factorial(n)//(n+1)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592994064, | |
| "creationDate": 1592983002 | |
| } | |
| }, | |
| { | |
| "id": 974185, | |
| "title": "[Python] simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/validate-binary-search-tree", | |
| "post": { | |
| "id": 1768786, | |
| "content": "We need to check that some property holds for every node of our tree, so as usual any recursion method should work here. Let us use function `dfs(node, low, high)`, where:\\n1. `node` is node we are currently in\\n2. `low` and `high` are bounds we expect to value of this node be in.\\n\\nNow, let us go to the main algorithm:\\n1. If we have `None` node, we are happy: empty tree is BST\\n2. Next we check if `low \u003c node.val \u003c high` and if it is not true, we can immedietly return `False`.\\n3. Finally, we check conditions for left children: its value should be in `(low, node.val)` and for right children: `(node.val, high)`. If one of this `dfs` return False, we need to return False.\\n\\n**Complexity**: time complexity is `O(n)` to traverse every node of our tree. Space complexity is `O(h)`, where `h` is height of our tree.\\n\\n```\\nclass Solution:\\n def isValidBST(self, root):\\n def dfs(node, low, high):\\n if not node: return True\\n if not low \u003c node.val \u003c high: return False\\n return dfs(node.left, low, node.val) and dfs(node.right, node.val, high)\\n \\n return dfs(root, -float(\"inf\"), float(\"inf\"))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608108557, | |
| "creationDate": 1608108557 | |
| } | |
| }, | |
| { | |
| "id": 917430, | |
| "title": "[Python] O(n)/O(1) Morris traversal, explained", | |
| "taskUrl": "https://leetcode.com/problems/recover-binary-search-tree", | |
| "post": { | |
| "id": 1670148, | |
| "content": "If we want to traverse our tree and do not use any additional memory, than as far as I know, Morris traversal is the only way how to do it. \\n\\nFor more details about Morris traversal, you can look at oficial solution of problem 94: Binary Tree Inorder Traversal: https://leetcode.com/problems/binary-tree-inorder-traversal/solution/.\\n\\nAlso, here we need to use variation of traversal, which keep the original structure of tree.\\n\\nLet us use this traversal and use `node` is current node we are in and `cands` are candidates for our swapped nodes. We will look at oddities in inorder traversal: in BST all numbers will always increase. So, if in inorder traversal some value is less than previous, we need to keep and eye on this node. There can be two main cases:\\n\\n1. We have `1, 2, 3, 4, 5` and swapped nodes are adjacent, for example `1, 2, 4, 3, 5`. In this case, we have only one oddity: `4` and `3`: and we save them to our `cands` list. And we need to change values for the first and for the last nodes in our `cands`.\\n2. We have `1, 2, 3, 4, 5` and swapped nodes are not adjacent, for example `1, 2, 5, 4, 3`. In this case we have two oddities: `5` and `4`; `4` and `3`. In this case we again need to swap the first and the last nodes.\\n\\nSo, in both cases it is enough to run `cands[0].val, cands[-1].val = cands[-1].val, cands[0].val` to swap our nodes.\\n\\n**Complexity**: time complexity is `O(n)`: because we basically do Morris traverasal plus some additional `O(n)` operations. Space complexity is `O(1)`, becauswe we again do Morris traversal and also we have `node` and `cands`, where `cands` can have maximum size `4`.\\n\\n```\\nclass Solution:\\n def recoverTree(self, root):\\n cur, node, cands = root, TreeNode(-float(\"inf\")), []\\n while cur:\\n if cur.left:\\n pre = cur.left\\n while pre.right and pre.right != cur:\\n pre = pre.right\\n if not pre.right:\\n pre.right = cur\\n cur = cur.left\\n else:\\n pre.right = None\\n if cur.val \u003c node.val:\\n cands += [node, cur]\\n node = cur\\n cur = cur.right\\n else:\\n if cur.val \u003c node.val:\\n cands += [node, cur]\\n node = cur\\n cur = cur.right\\n \\n cands[0].val, cands[-1].val = cands[-1].val, cands[0].val\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604143985, | |
| "creationDate": 1604143985 | |
| } | |
| }, | |
| { | |
| "id": 733783, | |
| "title": "[Python] 3 lines recursion explained", | |
| "taskUrl": "https://leetcode.com/problems/same-tree", | |
| "post": { | |
| "id": 1352356, | |
| "content": "As it given in problem statement: two binary trees are considered the same if they are structurally identical and the nodes have the same value. So all we need to do is to check this condition recursively:\\n\\nIf we reached node `p` in one tree and `q` in another tree (we allow to reach `None` nodes), we need to consider 3 cases:\\n\\n1. If one of them do not exist and another exist, we return `False`.\\n2. If two of them are equal to `None`, we return `True`.\\n3. If none of two above condition holds, we look at children and return `True` only if values of nodes are equal and if `True` holds for left and right subtrees.\\n\\n**Complexity**: time complexity is `O(n)`, because we traverse all tree. Space complexity is `O(h)` to keep recursion stack. Time complexity can be imporved a bit, if we use helper function and directly return `False` if we found difference between trees. \\n\\n```\\nclass Solution:\\n def isSameTree(self, p, q):\\n if p and not q or q and not p: return False\\n if not p and not q: return True\\n return p.val == q.val and self.isSameTree(p.left, q.left) and self.isSameTree(p.right, q.right)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594712761, | |
| "creationDate": 1594624882 | |
| } | |
| }, | |
| { | |
| "id": 749036, | |
| "title": "[Python] Clean BFS solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/binary-tree-zigzag-level-order-traversal", | |
| "post": { | |
| "id": 1378353, | |
| "content": "In this problem we need to traverse binary tree level by level. When we see levels in binary tree, we need to think about **bfs**, because it is its logic: it first traverse all neighbors, before we go deeper. Here we also need to change direction on each level as well. So, algorithm is the following:\\n\\n1. We create **queue**, where we first put our root.\\n2. `result` is to keep final result and `direction`, equal to `1` or `-1` is direction of traverse.\\n3. Then we start to traverse level by level: if we have `k` elements in queue currently, we remove them all and put their children instead. We continue to do this until our queue is empty. Meanwile we form `level` list and then add it to `result`, using correct direction and change direction after.\\n\\n**Complexity**: time complexity is `O(n)`, where `n` is number of nodes in our binary tree. Space complexity is also `O(n)`, because our `result` has this size in the end. If we do not count output as additional space, then it will be `O(w)`, where `w` is width of tree. It can be reduces to `O(1)` I think if we traverse levels in different order directly, but it is just not worth it.\\n\\n```\\nclass Solution:\\n def zigzagLevelOrder(self, root):\\n if not root: return []\\n queue = deque([root])\\n result, direction = [], 1\\n \\n while queue:\\n level = []\\n for i in range(len(queue)):\\n node = queue.popleft()\\n level.append(node.val)\\n if node.left: queue.append(node.left)\\n if node.right: queue.append(node.right)\\n result.append(level[::direction])\\n direction *= (-1)\\n return result\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595414850, | |
| "creationDate": 1595414850 | |
| } | |
| }, | |
| { | |
| "id": 955641, | |
| "title": "[Python] 2 lines dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/maximum-depth-of-binary-tree", | |
| "post": { | |
| "id": 1737144, | |
| "content": "This is classical problem about tree traversal and there are as usual 2 different approach how you can do it (bfs and dfs) and we can choose whatever you want. Recursive dfs will provide us with the shortest code, so I chose this one.\\n\\n1. If we reached `None` node, it means we need to return depth equal to `0`.\\n2. In other case, we check depths of left and right subtrees and return maximum of them plus one.\\n\\n\\n**Complexity**: As for usual dfs approach, time complexity is `O(n)` and space complexity is `O(h)`, where `h` is height of our tree.\\n\\n```\\nclass Solution:\\n def maxDepth(self, root):\\n if not root: return 0\\n return max(self.maxDepth(root.left), self.maxDepth(root.right)) + 1\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606811068, | |
| "creationDate": 1606811068 | |
| } | |
| }, | |
| { | |
| "id": 758662, | |
| "title": "[Python] O(n) recursion, explained with diagram", | |
| "taskUrl": "https://leetcode.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal", | |
| "post": { | |
| "id": 1394376, | |
| "content": "To solve this problem we need to understand, what is `inorder` and what is `postorder` traversal of tree. Let me remind you:\\n\\n1. `inorder` traversal is when you visit `left, root, right`, where `left` is left subtree, `root` is root node and `right` is right subtree.\\n2. `postorder` traversal is when you visit `left, right, root`.\\n\\nWe can see that in `postorder` traverasl `root` will be in the end, so we take this element and we need to find it in `inorder` array. Then we need to call function recursively on the `left` subtree and `right` subtree. It is easier said that done, so let us introduce function `helper(post_beg, post_end, in_beg, in_end)`, which has `4` parameters:\\n1. `post_beg` and `post_end` are indices in original `postorder` array of current window. Note, that we use python notation, so `post_end` points to one element after the end.\\n2. `in_beg` and `in_end` are indices in original `inorder` array of current window. We again use python notation, where `in_end` points to one element after the end.\\n\\nThen what we need to do is to find indices of left part and right part. First of all, evaluate `ind = dic[postorder[post_end-1]]`, where we create `dic = {elem: it for it, elem in enumerate(inorder)}` for fast access to elements. Now, look at the next two images:\\n\\nOn the first one `1, 2, 3, 4` in circles are equal to `post_beg, post_beg + ind - in_beg, in_beg, ind`. Why? `1` should point to beginning of `left` in postorder, so it is equal to `post_beg`. `2` should point to one element after the end of `left`, so we need to know the length of `left`, we can find it from `inorder` array, it is `ind - in_beg`. So, finally, point `2` is equal to `post_beg + ind - in_beg`. Point `3` should point to start of `left` in `inorder` array, that is `in_beg` and point `4` should point to element after the end of `left` in `inorder` array, that is `ind`.\\n\\nOn the second one `1, 2, 3, 4` in circles are equal to `post_end - in_end + ind, post_end - 1, ind + 1, in_end`. The logic is similar as for `left` parts, but here we look into `right` arrays.\\n\\n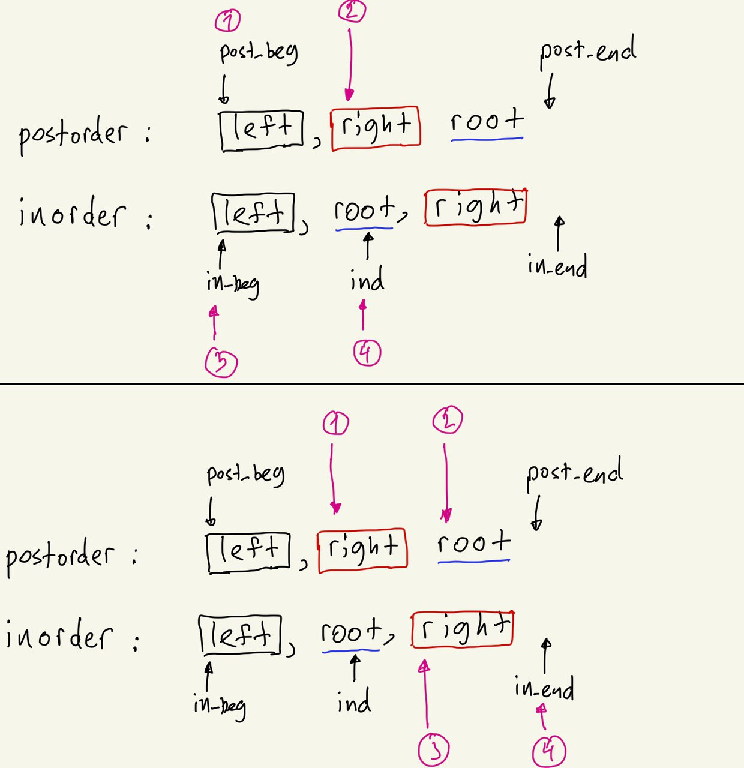\\n\\n**Complexity**: Time complexity is `O(n)`, because we traverse each element only once and we have `O(1)` complexity to find element in `dic`. Space complexity is also `O(n)`, because we keep additional `dic` with this size.\\n\\n```\\nclass Solution:\\n def buildTree(self, inorder, postorder):\\n def helper(post_beg, post_end, in_beg, in_end):\\n if post_end - post_beg \u003c= 0: return None\\n ind = dic[postorder[post_end-1]]\\n\\n root = TreeNode(inorder[ind]) \\n root.left = helper(post_beg, post_beg + ind - in_beg, in_beg, ind)\\n root.right = helper(post_end - in_end + ind, post_end - 1, ind + 1, in_end)\\n return root\\n \\n dic = {elem: it for it, elem in enumerate(inorder)} \\n return helper(0, len(postorder), 0, len(inorder))\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595852594, | |
| "creationDate": 1595849307 | |
| } | |
| }, | |
| { | |
| "id": 715874, | |
| "title": "[Python] Classical BFS, level traversal with queue, explained", | |
| "taskUrl": "https://leetcode.com/problems/binary-tree-level-order-traversal-ii", | |
| "post": { | |
| "id": 1320366, | |
| "content": "Not the most optimal way, but for me the most intuitive is to use **bfs** traversal of our graph, put all information into some auxilary list, and then traverse this list and reconstruct output. Let us consider the following example in more details:\\n\\n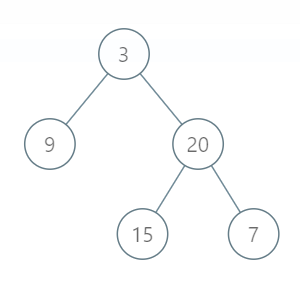\\n\\n1. `Out_temp` is temporary list with pairs: first element in pair is value of node and the second is level of this node. We use **bfs** with queue to traverse our tree and in the end we have\\n`Out_temp = [[3, 0], [9, 1], [20, 1], [15, 2], [7, 2]]`.\\n2. The second step is to reconstruct level by level `Out` list: we traverse our `Out_temp` and if level of new element is not the same as previous, we create new sublist.\\n\\n**Complexity** is `O(V)`, where `V` is number of nodes in our tree, because we use bfs traversal and then we have one more `O(V)` postprosessing of our data. Space complexity is also `O(V)`.\\n\\n\\n```\\nclass Solution:\\n def levelOrderBottom(self, root):\\n if not root: return []\\n \\n Out_temp, deq = [], deque([[root, 0]])\\n \\n while deq:\\n elem = deq.popleft()\\n Out_temp.append([elem[0].val, elem[1]])\\n if elem[0].left:\\n deq.append([elem[0].left, elem[1] + 1])\\n if elem[0].right:\\n deq.append([elem[0].right, elem[1] + 1])\\n\\n Out = [[Out_temp[0][0]]]\\n for i in range(1, len(Out_temp)):\\n if Out_temp[i][1] == Out_temp[i-1][1]:\\n Out[Out_temp[i][1]].append(Out_temp[i][0])\\n else:\\n Out.append([Out_temp[i][0]])\\n\\n return Out[::-1]\\n```\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593675882, | |
| "creationDate": 1593674748 | |
| } | |
| }, | |
| { | |
| "id": 981648, | |
| "title": "[Python] simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/balanced-binary-tree", | |
| "post": { | |
| "id": 1781118, | |
| "content": "What we need to do here is just to traverse our tree, using for example dfs and check balance for every node.\\n\\n`dfs(node)` here returns depth of subtree with root in `node`. If it is `None`, depths is equal to `0`. We evaluate depths of left and right subtee and return maximum of them plus one. Also we check balance and if absolute difference is more than `1`, we can mark variable `self.Bal` as False: we can state now that tree is not balanced.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(h)` as any classical dfs have.\\n\\n```\\nclass Solution:\\n def isBalanced(self, root):\\n self.Bal = True\\n \\n def dfs(node):\\n if not node: return 0\\n lft, rgh = dfs(node.left), dfs(node.right)\\n if abs(lft - rgh) \u003e 1: self.Bal = False\\n return max(lft, rgh) + 1\\n \\n dfs(root)\\n return self.Bal\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608628889, | |
| "creationDate": 1608628889 | |
| } | |
| }, | |
| { | |
| "id": 905643, | |
| "title": "[Python] Simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-depth-of-binary-tree", | |
| "post": { | |
| "id": 1649644, | |
| "content": "All we need to do in this problem is traverse our graph with dfs or bfs and collect information about nodes depths. Let us use axuilary function `dfs` and:\\n\\n1. If we reached `None`, then we return infinity.\\n2. If we reached leaf, then we return `1`, depth of our leaf\\n3. Finally, for node we return minumum of its children depths plus `1`. Note, that if one of the children is not exist, then is value for its depth will be infinity, so in fact we consider only existing children.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(h)`. \\n\\n**PS** Do not be afraid, that this code is only faster than `5%` of submissions: the reason is that tests were updated resently and results of time distributions are not relevant.\\n\\n```\\nclass Solution:\\n def minDepth(self, root):\\n def dfs(node):\\n if not node: return float(\"inf\")\\n if not node.left and not node.right: return 1\\n return min(dfs(node.left), dfs(node.right)) + 1\\n \\n res = dfs(root)\\n return res if res != float(\"inf\") else 0\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603363088, | |
| "creationDate": 1603363088 | |
| } | |
| }, | |
| { | |
| "id": 934066, | |
| "title": "[Python] O(n) time/ O(log n) space recursion, explained", | |
| "taskUrl": "https://leetcode.com/problems/populating-next-right-pointers-in-each-node", | |
| "post": { | |
| "id": 1699309, | |
| "content": "In this problem we are given that our tree is perfect binary tree, which will help us a lot. Let us use recursion: imagine, that for left and right subtees we already make all connections, what we need to connect now? See the image and it will become very clear: we need to connect just `O(log n)` pairs now: we go the the left and to the right children. Then from left children we go as right as possible and from right children we go as left as possible.\\n\\n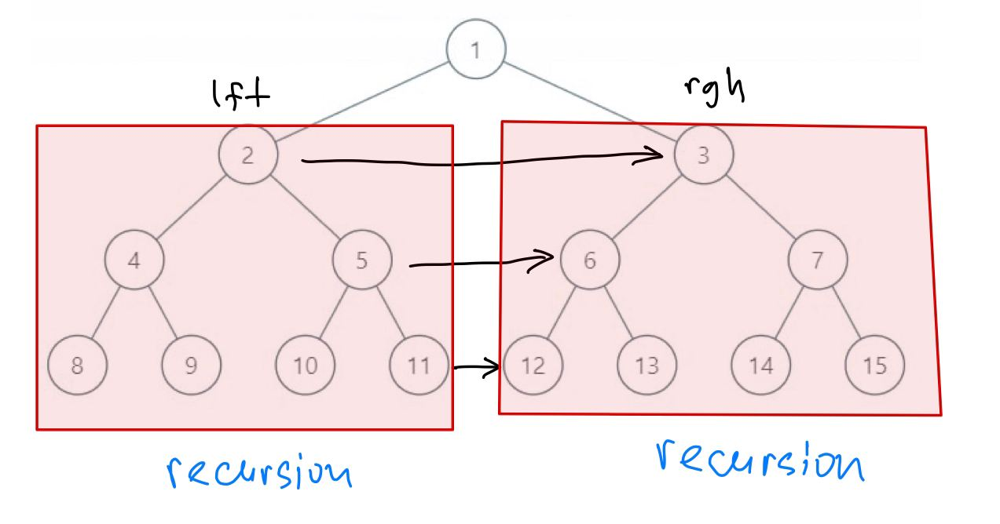\\n\\n\\n**Complexity**: time complexity can be found, using Master theorem: `F(n) = 2*F(n/2) + log n`, from here `F(n) = O(n)`. Space complexity is `O(log n)`, because we use recursion. Note, that space complexity can be reduced to `O(1)`, because we know the structure of our tree!\\n\\n```\\nclass Solution:\\n def connect(self, root):\\n if not root or not root.left: return root\\n \\n self.connect(root.left)\\n self.connect(root.right)\\n \\n lft = root.left\\n rgh = root.right\\n lft.next = rgh\\n\\n while lft.right: \\n lft = lft.right\\n rgh = rgh.left\\n lft.next = rgh\\n \\n return root\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605257718, | |
| "creationDate": 1605257718 | |
| } | |
| }, | |
| { | |
| "id": 961868, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/populating-next-right-pointers-in-each-node-ii", | |
| "post": { | |
| "id": 1747450, | |
| "content": "I spend some time for this problem, because my solution for problem **116** is quite different and can not be applied here (https://leetcode.com/problems/populating-next-right-pointers-in-each-node/discuss/934066/Python-O(n)-time-O(log-n)-space-recursion-explained). So, we need to think of something different here.\\n\\nThe main idea is to go level by level and use already existing `.next` connections: if you will not do it, problem will be quite painful. So, idea is the following:\\n1. We will keep two nodes: `node` and `curr`: first one is for parent level and `curr` for next level.\\n2. We check if we have `node.left` and if we have, we create connection `curr.next = node.left` and also move our `curr` to the right, so it always will be the rightest visited node in level.\\n3. In similar way we check if we have `node.right` and do the same for it.\\n4. When we finished with `node`, we move it to right: `node = node.next`.\\n5. Finally, we need to go to the next level: we update `node = dummy.next`.\\n\\nNote, that in this place we will have some extra connections from dummy variables to left side of our tree, but there is no way testing system can detect it, because it is one-way connections. If you want to be completely honest, you need to add just one more line `dummy.next = None` after the line `node = dummy.next`.\\n\\n**Complexity**: time complexity is `O(n)`: we visit each node of our tree only once. Space complexity is `O(1)`\\n\\n```\\nclass Solution:\\n def connect(self, root):\\n node = root\\n while node:\\n curr = dummy = Node(0)\\n while node:\\n if node.left:\\n curr.next = node.left\\n curr = curr.next\\n if node.right:\\n curr.next = node.right\\n curr = curr.next\\n node = node.next\\n node = dummy.next\\n \\n return root\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607246375, | |
| "creationDate": 1607246375 | |
| } | |
| }, | |
| { | |
| "id": 787212, | |
| "title": "[Python] Two O(k) memory Oneliners, explained", | |
| "taskUrl": "https://leetcode.com/problems/pascals-triangle-ii", | |
| "post": { | |
| "id": 1442881, | |
| "content": "### Solution 1\\n\\nWhat we need to do in this problem is to follow definition. Let us generate row `r` and do `k` iterations until we reached desired `k`-tho row. How we generate next row, using current? We need:\\n1. Add `1` to the beginning of new row.\\n2. Evaluate sums of elements with indexes differ by `1`.\\n3. Add `1` to the end of new row.\\n\\nThis can be written as `[1]+[r[j]+r[j+1] for j in range(len(r)-1)]+[1]`.\\n\\nWhat we need to do now is to repeat this `k` times and this is all, we can use `reduce` function to do it.\\n\\n**Complexity**: space complexity as it asked is only `O(k)`, each moment of time we have only one(two) rows. Time complexity is `O(k^2)` because for each row we do `k` iterations. Theoretically time complexity can be reduced to `O(k)` if we use direct formulas for elements of pascal triangle, but `k` is very small and there will no be difference in this problem.\\n\\n```\\nclass Solution:\\n def getRow(self, rowIndex):\\n return reduce(lambda r,_:[1]+[r[j]+r[j+1] for j in range(len(r)-1)]+[1], range(rowIndex),[1])\\n```\\n\\n### Solution 2\\n\\nLet us note, that `1001^5 = 1 005 010 010 005 001`, so if we want to find row of Pascal triangle for small numbers `k`, then we can just use power of number `1000...001` and then split it into parts. For thes problem it is enough to take `10000000001` and then split by blocks with size `10`. \\n\\n**Complexity**: Space complexity is also `O(k)`, but more like `O(10k)`, because we have string of length `10k` in the end. Time complexity is more difficult to compute, I think it is `O(k)` also.\\n\\n```\\nclass Solution:\\n def getRow(self, k):\\n return [1] + [int(str((10**10+1)**k)[-10*(i+1):-10*i]) for i in range(1,k+1)]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597236362, | |
| "creationDate": 1597217151 | |
| } | |
| }, | |
| { | |
| "id": 851941, | |
| "title": "[Python] O(n) dynamic programming solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/best-time-to-buy-and-sell-stock", | |
| "post": { | |
| "id": 1556036, | |
| "content": "Classical dynamic programming problem. Let `dp[i]` be a maximum profit we can have if we sell stock at `i`-th moment of time. Then we can get, that `dp[i+1] = max(dp[i] + q, q)`, where `q = nums[i+1] - nums[i]`, we have two choices, either we just buy and immeditely sell and get `q` gain, or we use `dp[i] + q` to merge two transactions. \\n\\nNote now, that we do not really need to keep all `dp` array, but we can keep only last state.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def maxProfit(self, nums):\\n ans, dp = 0, 0\\n for i in range(0, len(nums)-1):\\n q = nums[i+1] - nums[i]\\n dp = max(dp + q, q)\\n ans = max(ans, dp)\\n return ans\\n```\\n\\n**PS** Look also my solutions to similar problems: \\nBest Time to Buy and Sell Stock III\\nhttps://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/discuss/794633/Python-O(n)-solution-with-optimization-explained\\nBest Time to Buy and Sell Stock with Cooldown\\nhttps://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/discuss/761720/Python-dp-O(n)-solution-using-differences-explained\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600413367, | |
| "creationDate": 1600413367 | |
| } | |
| }, | |
| { | |
| "id": 794633, | |
| "title": "[Python] O(n) solution with optimization, explained", | |
| "taskUrl": "https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii", | |
| "post": { | |
| "id": 1455525, | |
| "content": "This problem is a special case of problem **188. Best Time to Buy and Sell Stock IV**. The following solution works for both problems. The only difference is that here we have `k = 2` transactions and in problem 188 we can have different `k`.\\n\\nMy way to solve this problem is to first evaluate matrix `B` of differences and then what is asked is to find the maximum sum of **two(k)** contiguous subarrays. We can also make optimization `if k \u003e len(prices)//2: return sum(x for x in B if x \u003e 0)`, which will help us, if `k` is big (in this problem it is equal to `2`, so you can remove this line, but you need it for problem 188). If `k` is more than half of length of `prices`, we can just choose all positive elements, we will have enough trancastions to do it.\\n\\nLet us create `dp` array with size `k+1` by `n-1`, where `dp[i][j]` is the maximum gain, where already made `j` transactions, that is choose `j` contiguous subarrays and used all elements before our equal number `i`. Also, `mp[i][j] = max(dp[0][j], ..., dp[i][j])`. We take `k+1` size, because we start with `0` transactions, which will be filled with zeros. We take `n-1` size, because original size is `n`, and size of differences is `n-1`. Also we start with `dp[0][1] = B[0]`, because we need to choose one contiguous subarray which ends with element `B[0]`, which is `B[0]` itself. Also we put `mp[0][1] = B[0]` for the same logic.\\n\\nNow, about updates: we iterate over all `i` from `1` to `n-2` inclusive and `j` from `1` to `k` inclusive and:\\n1. Update `dp[i][j] = max(mp[i-1][j-1], dp[i-1][j]) + B[i]`. By definition we need to take `B[i]`. We can either say, that we add it to the last contiguous subarray: `dp[i-1][j] + B[i]`, or we say that it is new contiguous subarray: `mp[i-1][j-1] + B[i]`. Note, here we use `mp`, because we actually have `max(dp[0][j-1], ... , dp[i-1][j-1])`.\\n2. Update `mp[i][j] = max(dp[i][j], mp[i-1][j])`.\\n3. Finally, return maximum from the `mp[-1]`, we need to choose maximum, because optimal solution can be with less than `k` transactions.\\n\\n**Complexity**: Time complexity is `O(nk) = O(n)`, because here `k = 2`. Space complexity is also `O(nk) = O(n)`.\\n\\n```\\nclass Solution:\\n def maxProfit(self, prices):\\n if len(prices) \u003c= 1: return 0\\n n, k = len(prices), 2\\n\\n B = [prices[i+1] - prices[i] for i in range(len(prices) - 1)]\\n if k \u003e len(prices)//2: return sum(x for x in B if x \u003e 0)\\n \\n dp = [[0]*(k+1) for _ in range(n-1)] \\n mp = [[0]*(k+1) for _ in range(n-1)] \\n\\n dp[0][1], mp[0][1] = B[0], B[0]\\n\\n for i in range(1, n-1):\\n for j in range(1, k+1):\\n dp[i][j] = max(mp[i-1][j-1], dp[i-1][j]) + B[i]\\n mp[i][j] = max(dp[i][j], mp[i-1][j])\\n\\n return max(mp[-1])\\n```\\n\\n### Optimization:\\n\\nNote, that if we have array like `[1,5,7, -7, -4, -3, 10, 2, 7, -4, -8, 13, 15]`, then we can work in fact with smaller array `[1+5+7, -7-4-3, 10+2+7, -4-8, 13+15] = [13,-14,19,-12,28]`. So, instead of `B = [prices[i+1] - prices[i] for i in range(len(prices) - 1)]`, we can evaluate:\\n\\n```\\ndelta = [prices[i+1]-prices[i] for i in range (len(prices)-1)]\\nB=[sum(delta) for _, delta in groupby(delta, key=lambda x: x \u003c 0)]\\nn, k = len(B) + 1, 2\\n```\\nWhen used this code, I have `132ms` to `64`ms improvement (which is faster than 99%).\\nThanks `user2349` for providing shorter version of code!\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597598044, | |
| "creationDate": 1597564782 | |
| } | |
| }, | |
| { | |
| "id": 770465, | |
| "title": "[Python] Two pointers, O(n) time \u0026 O(1) space, explained", | |
| "taskUrl": "https://leetcode.com/problems/valid-palindrome", | |
| "post": { | |
| "id": 1414687, | |
| "content": "One way to solve this problem is to create new string with only alphanumeric symbols and then check if it is palindrome. However we need `O(n)` space for this. There is more subtle approach, using **Two Pointers** technique.\\n\\n1. Start with `beg = 0` and `end = len(s) - 1`, the first and the last symbols of string `s`.\\n2. Now, we are going to move iterator `beg` only to the right and iterator `end` only to the left. Let us move them, until we reach alphanumeric symbols, using `isalnum()` function.\\n3. Compare these two symbols. We are happy, if they are equal, or it is the same letter in different capitalization, for example `q` and `Q`. How to check this case? Make both symbols capitalized, using `.upper()` and compare them.\\n4. In opposite case, immidietly return `False`.\\n5. If we reached the end of or program and we did not return `False`, then we need to return `True`.\\n\\n**Complexity**: Time complexity is `O(n)`, because we move `beg` only to the right and `end` only to the left, until they meet. Space complexity is `O(1)`, we just use a couple of additional variables.\\n\\n```\\nclass Solution:\\n def isPalindrome(self, s):\\n beg, end = 0, len(s) - 1\\n while beg \u003c= end:\\n while not s[beg].isalnum() and beg \u003c end: beg += 1\\n while not s[end].isalnum() and beg \u003c end: end -= 1\\n if s[beg] == s[end] or s[beg].upper() == s[end].upper():\\n beg, end = beg + 1, end - 1\\n else:\\n return False\\n return True\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596442087, | |
| "creationDate": 1596442087 | |
| } | |
| }, | |
| { | |
| "id": 705994, | |
| "title": "[Python] dfs O(n) with explanations", | |
| "taskUrl": "https://leetcode.com/problems/sum-root-to-leaf-numbers", | |
| "post": { | |
| "id": 1303510, | |
| "content": "The idea is traverse our tree, using any tree traversal algorighm. I choose dfs, and also I directly change the values of our tree.\\n\\n1. If we reach non-existing node (None), we just return back.\\n2. If we reached leaf, that is it do not have any children, return value of this node.\\n3. Update values for left and right children if they exist.\\n4. Finally, call function recursively for left and right children and return sum of results for left and right.\\n\\n\\n\\nWe start traverse from root, and we replace its children `9` and `0` with `49` and `40`.\\nThen for `49` we replace its children `5` and `1` with `495` and `491`.\\nFinally, we evaluate sum of all leafs: `40 + 495 + 491`.\\n\\n**Complexity**: time complexity can be potentially `O(nh)`, where `n` is number of nodes and `h` is number of levels, because at each step our numbers become bigger and bigger. If we assume that number we met will always be in `32int` range, then can say that complexity is `O(n)`. Space complexity is `O(h)` to keep the stack of recursion.\\n\\n```\\nclass Solution:\\n def sumNumbers(self, root):\\n if not root: return 0\\n \\n if not root.left and not root.right:\\n return int(root.val)\\n \\n if root.left: root.left.val = 10*root.val + root.left.val\\n if root.right: root.right.val = 10*root.val + root.right.val\\n \\n return self.sumNumbers(root.left) + self.sumNumbers(root.right)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593159066, | |
| "creationDate": 1593156385 | |
| } | |
| }, | |
| { | |
| "id": 691646, | |
| "title": "[Python] O(mn), 3 colors dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/surrounded-regions", | |
| "post": { | |
| "id": 1277527, | |
| "content": "In this problem we need to understand, what exactly surrouned by `\\'X\\'` means. It actually means that if we start from `\\'O\\'` at the border, and we traverse only `\\'O\\'`, only those `\\'O\\'` are **not surrouned** by `\\'X\\'`. So the plan is the following:\\n\\n1. Start dfs or bfs from all `\\'O\\'`, which are on the border.\\n2. When we traverse them, let us color them as `\\'T\\'`, temporary color.\\n3. Now, when we traverse all we wanted, all colors which are not `\\'T\\'` need to renamed to `\\'X\\'` and all colors which are `\\'T\\'` need to be renamed to `\\'O\\'`, and that is all!\\n\\n**Compexity**: time complextiy is `O(mn)`, where `m` and `n` are sizes of our board. Additional space complexity can also go upto `O(mn)` to keep stack of recursion.\\n\\n```\\nclass Solution:\\n def dfs(self, i, j):\\n if i\u003c0 or j\u003c0 or i\u003e=self.M or j\u003e=self.N or self.board[i][j] != \"O\":\\n return\\n self.board[i][j] = \\'T\\'\\n neib_list = [[i+1,j],[i-1,j],[i,j-1],[i,j+1]]\\n for x, y in neib_list:\\n self.dfs(x, y)\\n \\n def solve(self, board):\\n if not board: return 0\\n self.board, self.M, self.N = board, len(board), len(board[0])\\n \\n for i in range(0, self.M):\\n self.dfs(i,0)\\n self.dfs(i,self.N-1)\\n \\n for j in range(0, self.N):\\n self.dfs(0,j)\\n self.dfs(self.M-1,j)\\n \\n for i,j in product(range(self.M), range(self.N)):\\n board[i][j] = \"X\" if board[i][j] != \"T\" else \"O\"\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592390308, | |
| "creationDate": 1592379928 | |
| } | |
| }, | |
| { | |
| "id": 971898, | |
| "title": "[Python] dp/dfs solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/palindrome-partitioning", | |
| "post": { | |
| "id": 1764888, | |
| "content": "First thing we need to see when we look at problem description, that `n` is pretty small, no more than `15`, and it is done for reason: we will see in our complexity analysis why. Let us use function `find_all_palindromes`, where:\\n\\n1. `s` is input string, imagine `abacc`.\\n2. Output is lengths of biggest palindromes for each of the `2n-1` possible middles. Why there is `2n-1`? Because it can be either letter or in between letters.\\n3. Here I use very simple way to find all palindromes: just consider every possible substring, there will be `O(n^2)` of them and check in `O(n)` if it is palindrome. Total complexity of this step is `O(n^3)`, but we do not care here: complexity of the next step will be much bigger.\\n\\nNow, let us `dp[i+1]` be solution for `s[:i]`. How we can find `dp[i+1]`? We need to iterate over all `k in range (0, N)`: possible starts of last palindrome and check `if B[2*i-k+1] \u003e= k`: this condition means that `s[i-k: i+1]` is palindrome: so now we just iterate over all solutions for `dp[i-k]` and add this string to the end of solutions. Why I prefer here `dp` solution, not backtracking, because it is more universal and you can solve **132. Palindrome Partitioning II** just changing code a bit.\\n\\n**Comlexity**: as we discussed, complexity of finding all palindromes is `O(n^3)`. Now, imagine we have string `aaa...aa` with length `n`. Then there will be exactly `2^(n-1)` ways to split this string in palindromes: we can cut it in any of `n-1` places. So, there will be `O(2^n* n)` time and space to keep solution for `s`. Also we keep solution for all prefixes of `s`, but we have `O(2^n * n + 2^(n-1)*(n-1) + ...)` which is still `O(2^n * n)`. Space complexity is the same: we need this amount of memory just to keep answer.\\n\\n**Remark** I ran this code 6 months ago and it was around 60-70ms, now it is 600-700ms, this means, that leetcode added new tests and histogram is not relevant at the moment. Do not be discouraged whey you see something like faster than 10%, it is not true.\\n\\n**Remark2** Note again, that `find_all_palindromes(s)` has complexity `O(n^3)` here, and there is `O(n^2)` and even `O(n)` algorithms for this. But if you change this part, difference will be negligible: you can try and will see.\\n\\n```\\nclass Solution:\\n def partition(self, s):\\n def find_all_palindromes(s):\\n B = [0] * (2*n)\\n for i, j in combinations_with_replacement(range(n), 2):\\n if s[i:j+1] == s[i:j+1][::-1]:\\n B[i+j+1] = max(B[i+j+1], j-i+1)\\n return B\\n \\n n = len(s)\\n B = find_all_palindromes(s)\\n \\n dp = [[] for _ in range(n+1)]\\n dp[0] = [[]]\\n for i in range(0, n):\\n for k in range(0, i+1):\\n if B[2*i-k+1] \u003e= k:\\n for elem in dp[i-k]:\\n dp[i + 1].append(elem + [s[i-k:i+1]])\\n\\n return dp[-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607938537, | |
| "creationDate": 1607938373 | |
| } | |
| }, | |
| { | |
| "id": 902767, | |
| "title": "[Python] dfs recursive solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/clone-graph", | |
| "post": { | |
| "id": 1644447, | |
| "content": "When you see the problem about graph, the first thing you need to think about is some classical graph traversal: dfs or bfs. Usually, there are `3` options with same complexities you can choose from:\\n\\n1. Iterative dfs, that is dfs with stack\\n2. Recursive dfs, which is a bit simpler to code, but be careful if you have very deep graphs.\\n3. bfs - only iterative, there is no recursion version, because we use queue, not stack here.\\n\\nHere I choose method number 2 (because it is easy to code of course)\\n\\nLet us create global dictionary `mapping`, which will connect nodes from old graph with nodes from new graph and use recursive `dfs` function to construct these connections:\\n1. First, add connection `mapping[node] = Node(node.val)`\\n2. Traverse all neighbors of node and if node is not traversed, that is it is not in our `mapping`, then we run `dfs` for this neighbor. Also we add connection in new graph (we add it even if node is visited!)\\n\\n**Complexity**: time complexity is `O(E)`: this number of iterations we need for full dfs traversal. Space complexity is `O(E+V) = O(E)` for connected graph.\\n\\n```\\nclass Solution:\\n def cloneGraph(self, node):\\n def dfs(node):\\n mapping[node] = Node(node.val)\\n for neigh in node.neighbors:\\n if neigh not in mapping: dfs(neigh)\\n mapping[node].neighbors += [mapping[neigh]]\\n \\n if not node: return node\\n mapping = {}\\n dfs(node)\\n return mapping[node]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603183254, | |
| "creationDate": 1603183254 | |
| } | |
| }, | |
| { | |
| "id": 860396, | |
| "title": "[Python] O(n) greedy solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/gas-station", | |
| "post": { | |
| "id": 1570885, | |
| "content": "Let us first evaluate differences between our `gas` and `cost`, because this is what we need in the end. Now, let us start from first place and check if we can fulfill problem conditions: it means that all **cumulative** sums should be not negative. If we get negative cumulative sum, it means, that we can not succeed using current starting index, so we need to take next starting index. In fact we can do better: imagine, we have `i` as starging index and at some moment we have cumulative sum which is negative:\\n\\n`d_i + ... _ d_j \u003c 0`.\\n\\nNote also, that it is the first time we have this sum negative. But it means, that if we consider any `k`, such that `i+1 \u003c=k \u003c j`, then sum `d_k + ... + d_j` also will be negatie, because sum `d_i + ... d_{k-1}` will be positive. It means, that the next candidate for starting index should be `j+1`. \\n\\nImagine example `-2 -2 -2 3 3`. Note, that our gas stations are on circle, so let us use duplication trick and traverse `-2 -2 -2 3 3 -2 -2 -2 3 3`. If we apply our logic, we will find `-2 -2 -2` **3 3 -2 -2 -2 3 3**: it means if we have solution, starting index will be before first `n`.\\n\\nIf we have `-2 -2 -2 3 2`, then we have `-2 -2 -2 3 2 -2 -2 -2` **3 2**, so starting index is not before first `n`.\\n\\n**Complexity**: Time complexity is `O(n)`, because we have two passes over our data and space complexity is also `O(n)`, because I evaluate `diffs` (it can be easily reduced to `O(1)`).\\n\\n```\\nclass Solution:\\n def canCompleteCircuit(self, gas, cost):\\n diffs = [a-b for a,b in zip(gas, cost)]\\n n = len(diffs)\\n cumsum, out = 0, 0\\n for i in range(2*n):\\n cumsum += diffs[i%n]\\n if cumsum \u003c 0:\\n cumsum = 0\\n out = i + 1\\n \\n return -1 if out \u003e n else out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600850323, | |
| "creationDate": 1600850323 | |
| } | |
| }, | |
| { | |
| "id": 699889, | |
| "title": "[Python] Bit Manipulation, O(32n), but easy, exaplained", | |
| "taskUrl": "https://leetcode.com/problems/single-number-ii", | |
| "post": { | |
| "id": 1292875, | |
| "content": "There are several `\\'magical\\'` solutions for this problem I saw in comments, done in `O(n)`, which I really enjoed to read, however I doubt if you never saw this problem you can suceed in real interview. That is why I suggest maybe not the fastest, but much more easier to come up solution. The idea is similar to problem **Single Number**, but here we need to count each bit modulo `3`. So, we\\n1. Iterate over all possible `32` bits and for each `num` check if this `num` has non-zero bit on position `i` with `num \u0026 (1\u003c\u003ci) == (1\u003c\u003ci)` formula.\\n2. We evaluate this sum modulo `3`. Note, that in the end for each bit we can have either `0` or `1` and never `2`.\\n3. Next, update our answer `single` with evaluated bit.\\n4. Finally, we need to deal with overflow cases in python: maximum value for `int32` is `2^31 - 1`, so if we get number more than this value we have negative answer in fact.\\n\\n**Complexity**: time complexity is `O(32n)`, which may be not fully honest linear, but is fine for the purpose of this problem. If we want just `O(n)` complexity, I think problem becomes not medium but hard. Space complexity here is `O(1)`.\\n\\n```\\nclass Solution:\\n def singleNumber(self, nums):\\n single = 0\\n for i in range(32):\\n count = 0\\n for num in nums:\\n if num \u0026 (1\u003c\u003ci) == (1\u003c\u003ci): count += 1\\n single |= (count%3) \u003c\u003c i\\n \\n return single if single \u003c (1\u003c\u003c31) else single - (1\u003c\u003c32) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592815427, | |
| "creationDate": 1592812745 | |
| } | |
| }, | |
| { | |
| "id": 870102, | |
| "title": "[Pyhon] dfs, using lru_cache, explained", | |
| "taskUrl": "https://leetcode.com/problems/word-break", | |
| "post": { | |
| "id": 1587868, | |
| "content": "Let `dfs(k)` be a possibility to split string `s[k:]` into words from `wordSet`. Then to check if word `s[k:]` can be splitted, we need to check if for some `i` word `s[k:i]` in our `wordSet` and if `s[i:]` can be splitted, which is `dfs(i)`.\\n\\n**Complexity**: let `T` be the maximum length of word in our `wordSet`. Then we need `O(T)` time to check if word in our set, so we have overall `O(n^2T)` complexity. Space complexity is `O(n +Tn)` : to keep our cache and to keep our set of `wordSet`\\n\\n```\\nclass Solution:\\n def wordBreak(self, s, wordDict):\\n wordSet = set(wordDict)\\n n = len(s)\\n \\n @lru_cache(None)\\n def dfs(k):\\n if k == n: return True\\n for i in range(k + 1, n + 1):\\n if s[k:i] in wordSet and dfs(i):\\n return True \\n return False\\n \\n return dfs(0)\\n```\\n\\n**Further discussion**: Another approach is to use KMP for each of the `m` words and create `n x n` table `Mem`, where `Mem[i][j]` is equal to `1` if `s[i:j]` is in our dictionary. The complexity to generate `Mem` table is `O(mn)` and `O(n^2)` to update `dp`. Finally, we have `O(n^2 + nm)` time and `O(n^2)` memory.\\n\\nOne more approach is to use Tries to preprocess our dictionary with `O(mk)` time, where `k` is the average length of words. Then we can fill `dp` table in `O(n^2)` time (CHECK, I am not 100 percent sure). Finally, we have `O(mk + n^2)` time and `O(mk)` memory.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601364748, | |
| "creationDate": 1601364748 | |
| } | |
| }, | |
| { | |
| "id": 763221, | |
| "title": "[Python] dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/word-break-ii", | |
| "post": { | |
| "id": 1402306, | |
| "content": "First of all, this problem is extention of problem 139. Word Break, where we need just to check if word can be broken into other words. Here we need to give all possible splits. Let us first put all words into `set` and create two lists:\\n\\n1. `dp_solution[i]` is all possible splits for first `i` symbols of `s`\\n2. `dp[i]` is indicator if we can split word or not.\\n\\nAlso we create this two lists with size `(n+1)` to handle border cases, in `dp[-1]` we will keep result for empty string `\"\"`.\\n\\n1. First step is to check if our string can be splitted at all, using problem 139. We need to do it, to candle strings like `aaaaa...aaab`, with `wordDict = [a, aa, aaa, ..., aa..aa]`. In this case answer will be `no`, but if we try to build solution directly we will get MLE. Try to remove this lines of code from solution and you will see.\\n2. Now, we do one more pass over data and start to build solutions: if we found that `s[j: k + 1] in wordSet`, then for every already built solution `sol in dp_solution[j-1]` we can add it to `dp_solution[k]`. \\n3. Finally, we have some extraspaces in the beginning of each solution, and instead of last element `[-1]` we need to return previous `[-2]`, so we return return `[s[1:] for s in dp_solution[-2]]`\\n\\n**Complexity**: to create `dp` we need `O(n^2m)` time, where `m` is average length of word and `O(n^2)` space. However for `dp_solution` part we can have potentially exponential number of solutions, for example even for `s = aa.....aa`, `wordDict = [a, aa]`. I think leetcode just will not give you tests, where memory will exceed some limit.\\n\\n```\\nclass Solution:\\n def wordBreak(self, s, wordDict):\\n wordSet = set(wordDict)\\n n = len(s)\\n dp_solution = [[] for _ in range(n)] + [[\"\"]]\\n dp = [0] * n + [1]\\n \\n for k in range(n):\\n for j in range(k,-1,-1):\\n if s[j: k + 1] in wordSet:\\n dp[k] = max(dp[k], dp[j-1])\\n\\n if dp[-2] == 0: return []\\n\\n for k in range(n):\\n for j in range(k,-1,-1):\\n if s[j: k + 1] in wordSet:\\n for sol in dp_solution[j-1]:\\n dp_solution[k].append(sol + \" \" + s[j: k + 1])\\n \\n return [s[1:] for s in dp_solution[-2]]\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1596095198, | |
| "creationDate": 1596095198 | |
| } | |
| }, | |
| { | |
| "id": 912276, | |
| "title": "[Python] 2 pointers approach, explained", | |
| "taskUrl": "https://leetcode.com/problems/linked-list-cycle-ii", | |
| "post": { | |
| "id": 1661367, | |
| "content": "This is very classical problem for two pointers approach: we use slow and fast pointers: slow which moves one step at a time and fast, which moves two times at a time. To find the place where loop started, we need to do it in two iterations: first we wait until fast pointer gains slow pointer and then we move slow pointer to the start and run them with the same speed and wait until they concide.\\n\\n**Complexity**: time complexity is `O(n)`, because we traverse our linked list twice, space complexity is `O(1)`, because we do not create any additional variables.\\n\\n```\\nclass Solution:\\n def detectCycle(self, head):\\n slow = fast = head\\n while fast and fast.next:\\n fast = fast.next.next\\n slow = slow.next\\n if slow == fast: break\\n \\n if not fast or not fast.next: return None\\n slow = head\\n while slow != fast:\\n slow = slow.next\\n fast = fast.next\\n return slow\\n```\\n\\n**PS** see also Problem 287. Find the Duplicate Number: https://leetcode.com/problems/find-the-duplicate-number/discuss/704693/Python-2-solutions%3A-Linked-List-Cycle-O(n)-and-BS-O(n-log-n)-explained which uses the same idea.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603793467, | |
| "creationDate": 1603793467 | |
| } | |
| }, | |
| { | |
| "id": 801883, | |
| "title": "[Python] 3 steps to success, explained", | |
| "taskUrl": "https://leetcode.com/problems/reorder-list", | |
| "post": { | |
| "id": 1468623, | |
| "content": "If you never solved singly linked lists problems before, or you do not have a lot of experience, this problem can be quite difficult. However if you already know all the tricks, it is not difficult at all. Let us first try to understand what we need to do. For list `[1,2,3,4,5,6,7]` we need to return `[1,7,2,6,3,5,4]`. We can note, that it is actually two lists `[1,2,3,4]` and `[7,6,5]`, where elements are interchange. So, to succeed we need to do the following steps:\\n1. Find the middle of or list - be careful, it needs to work properly both for even and for odd number of nodes. For this we can either just count number of elements and then divide it by to, and do two traversals of list. Or we can use `slow/fast` iterators trick, where `slow` moves with speed `1` and `fast` moves with speed `2`. Then when `fast` reches the end, `slow` will be in the middle, as we need.\\n2. Reverse the second part of linked list. Again, if you never done it before, it can be quite painful, please read oficial solution to problem **206. Reverse Linked List**. The idea is to keep **three** pointers: `prev, curr, nextt` stand for previous, current and next and change connections in place. Do not forget to use `slow.next = None`, in opposite case you will have list with loop.\\n3. Finally, we need to merge two lists, given its heads. These heads are denoted by `head` and `prev`, so for simplisity I created `head1` and `head2` variables. What we need to do now is to interchange nodes: we put `head2` as next element of `head1` and then say that `head1` is now `head2` and `head2` is previous `head1.next`. In this way we do one step for one of the lists and rename lists, so next time we will take element from `head2`, then rename again and so on.\\n\\n**Complexity**: Time complexity is `O(n)`, because we first do `O(n)` iterations to find middle, then we do `O(n)` iterations to reverse second half and finally we do `O(n)` iterations to merge lists. Space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def reorderList(self, head):\\n #step 1: find middle\\n if not head: return []\\n slow, fast = head, head\\n while fast.next and fast.next.next:\\n slow = slow.next\\n fast = fast.next.next\\n \\n #step 2: reverse second half\\n prev, curr = None, slow.next\\n while curr:\\n nextt = curr.next\\n curr.next = prev\\n prev = curr\\n curr = nextt \\n slow.next = None\\n \\n #step 3: merge lists\\n head1, head2 = head, prev\\n while head2:\\n nextt = head1.next\\n head1.next = head2\\n head1 = head2\\n head2 = nextt\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597912072, | |
| "creationDate": 1597912072 | |
| } | |
| }, | |
| { | |
| "id": 920371, | |
| "title": "[Python] Insertion Sort, explained", | |
| "taskUrl": "https://leetcode.com/problems/insertion-sort-list", | |
| "post": { | |
| "id": 1675521, | |
| "content": "In this problem we are asked to implement insertion sort on singly-linked list data structure. And we do not really have a choice how to do it: we just need to apply definition of Insertion Sort. Imagine, that we already sorted some part of data, and we have something like:\\n`1 2 3 7` **4** `6`,\\nwhere by bold **4** I denoted element we need to insert on current step. How we can do it? We need to iterate over our list and find the place, where it should be inserted. Classical way to do it is to use **two pointers**: `prv` and `nxt`, stands for previous and next and stop, when value of `nxt` is greater than value of node we want ot insert. Then we insert this element into correct place, doing `curr.next = next, prv.next = curr`. Also, now we need to update our `curr` element: for that reason in the beginning of the loop we defined `curr_next = curr.next`, so we can update it now.\\n\\n**Complexity**: time complexity is `O(n^2)`, as Insertion sort should be: we take `O(n)` loops with `O(n)` loop inside. Space complexity is `O(1)`, because what we do is only change connections between our nodes, and do not create new data.\\n\\n```\\nclass Solution:\\n def insertionSortList(self, head):\\n dummy = ListNode(-1)\\n curr = head\\n while curr:\\n curr_next = curr.next\\n prv, nxt = dummy, dummy.next\\n while nxt:\\n if nxt.val \u003e curr.val: break\\n prv = nxt\\n nxt = nxt.next\\n \\n curr.next = nxt\\n prv.next = curr\\n curr = curr_next\\n \\n return dummy.next\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604306970, | |
| "creationDate": 1604306970 | |
| } | |
| }, | |
| { | |
| "id": 892759, | |
| "title": "[Python] O(n log n/ log n) merge sort, explained", | |
| "taskUrl": "https://leetcode.com/problems/sort-list", | |
| "post": { | |
| "id": 1626678, | |
| "content": "This is pretty straightforward question, if you know how to use merge sort. All we need to do is to split our list into two parts, sort the first half, then sort the second half and finally merge this two parts. Here I use two axuilary function:\\n\\n1. `getMid(head)`, which will find the middle of list with given `head` and cut it into two smaller lists. We use the idea of slow and fast pointers here to find middle efficiently.\\n2. `merge(head1, head2)` will merge two lists with given heads. To make it more readible and to avoid corner cases, it is good idea to use dummy sentinel node in the beginning of list. We iterate over two lists, using two pointers and add them one by one. When we out of nodes, we attach the rest of on of the lists to the end, we return the start of our new list.\\n3. `sortList(head)`: it is our original function: if list has length `0` or `1`, we do not do anything, it is corner case of our recursion. If it is not the case, we find `mid = self.getMid(head)`, which will cut our list into two smaller lists and return the start of the second list. Finally, we apply `sortList()` to `head` and to `mid` and merge two parts.\\n\\n**Complexity**: Time complexity is `O(n log n)`, because it is classical complexity of merge sort. Space complexity is `O(log n)`, because we use recursion which can be `log n` deep.\\n\\n```\\nclass Solution:\\n def sortList(self, head):\\n if not head or not head.next: return head\\n mid = self.getMid(head)\\n left = self.sortList(head)\\n right = self.sortList(mid)\\n return self.merge(left, right)\\n \\n def getMid(self, head):\\n slow, fast = head, head\\n while fast.next and fast.next.next:\\n slow = slow.next\\n fast = fast.next.next\\n mid = slow.next\\n slow.next = None\\n return mid\\n \\n def merge(self, head1, head2):\\n dummy = tail = ListNode(None)\\n while head1 and head2:\\n if head1.val \u003c head2.val:\\n tail.next, tail, head1 = head1, head1, head1.next\\n else:\\n tail.next, tail, head2 = head2, head2, head2.next\\n \\n tail.next = head1 or head2\\n return dummy.next\\n```\\n\\n**Follow up** question askes us to do it in `O(1)` memory, and it is possible to do it, using bottom-up merge sort, which is much more difficult to implement during interview limits. What I expect that if you just explain the idea, without implementing this will be already quite good. So, idea is the following: imagine, that we have list `a1, a2, a3, a4, a5, a6, a7, a8`. Let us first sort values in pairs:\\n`(a1, a2)`, `(a3, a4)`, `(a5, a6)`, `(a7, a8)`. \\nthen we sort values in groups by `4`, mergin our pairs:\\n`(a1, a2, a3, a4)`, `(a5, a6, a7, a8)`.\\nAnd finally we merge them in one group of `9`. It is more difficult to implement and I will add code later.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602591943, | |
| "creationDate": 1602591943 | |
| } | |
| }, | |
| { | |
| "id": 737124, | |
| "title": "[Python] 2 Solutions: Oneliner + Inplace for list of chars, explained", | |
| "taskUrl": "https://leetcode.com/problems/reverse-words-in-a-string", | |
| "post": { | |
| "id": 1357906, | |
| "content": "If you use python, this problem becomes not medium, but rather easy: all you need to do is to `split()` you data and take elements in negative order. `split()` is smart enough to ignore several spaces in a row as well as extra spaces in the begin and in the end.\\n\\n**Complexity**: both time and memory complexity is `O(n)`, because we traverse all string and we create new with size `O(n)`.\\n\\n```\\nclass Solution:\\n def reverseWords(self, s):\\n return \" \".join(s.split()[::-1]) \\n```\\n\\n**Futher discussion**: We can not do better than `O(n)` space in python, because strings are immutable. However if we are given not string, but array of symbols, we can remove all extra spaces, using **Two pointers** approach, reverse full string and then reverse each word. Time complexity will be `O(n)` and space will be `O(1)`.\\n\\nHere is the python code:\\n1. We traverse `chars` with two pointers and rewrite symbols in the beginning.\\n2. Cut our `chars`, removing last elements (in my code it is not really inplace, but you can use `del` to do it in place)\\n3. Reverse list using `chars.reverse()`.\\n4. Use two pointers to reverse each word.\\n\\n```\\nclass Solution:\\n def reverseWords(self, s): \\n chars = [t for t in s]\\n slow, n = 0, len(s)\\n for fast in range(n):\\n if chars[fast] != \" \" or (fast \u003e 0 and chars[fast] == \" \" and chars[fast-1] != \" \"):\\n chars[slow] = chars[fast]\\n slow += 1\\n \\n if slow == 0: return \"\" \\n chars = chars[:slow-1] if chars[-1] == \" \" else chars[:slow]\\n chars.reverse()\\n \\n slow, m = 0, len(chars)\\n for fast in range(m + 1):\\n if fast == m or chars[fast] == \" \":\\n chars[slow:fast] = chars[slow:fast][::-1]\\n slow = fast + 1\\n \\n return \"\".join(chars)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594827155, | |
| "creationDate": 1594797463 | |
| } | |
| }, | |
| { | |
| "id": 841176, | |
| "title": "[Python] dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/maximum-product-subarray", | |
| "post": { | |
| "id": 1536445, | |
| "content": "Let `dp1[i]` be the maximum product which ends with `i`-th index and `dp2[i]` be the minimum product which ends with `i`-the index. Why we need both maximum and minimum? Because we can have big negative number, which then multiplied by negative will give big positive number.\\n\\nSo, let us traverse all numbers and update our `dp1` and `dp2`:\\n1. If `nums[k] \u003e 0`, then biggest number `dp1[k]` can be found as maximum of `dp1[k-1] * nums[k]` and `nums[k]`. The smallest number `dp2[k]` is equal to minimum of `dp2[k-1] * nums[k] and nums[k]`\\n2. If `nums[k] \u003c= 0`, then the biggest number is maximum of `dp2[k-1] * nums[k]` and `nums[k]` and the smalles number `dp2[k]` is minimum of `dp1[k-1] * nums[k]` and `nums[k]`\\n3. Finally, we return maximum of `dp1`.\\n\\n**Complexity**: both time and space is `O(n)`. Space complexity can be improved to `O(1)`, because we always use only previous elements in our `dp1` and `dp2` tables.\\n\\n```\\nclass Solution:\\n def maxProduct(self, nums):\\n N = len(nums)\\n dp1 = [0] * N\\n dp2 = [0] * N\\n dp1[0] = dp2[0] = nums[0]\\n \\n for k in range(1, N):\\n if nums[k] \u003e 0:\\n dp1[k] = max(dp1[k-1] * nums[k], nums[k])\\n dp2[k] = min(dp2[k-1] * nums[k], nums[k])\\n else:\\n dp1[k] = max(dp2[k-1] * nums[k], nums[k])\\n dp2[k] = min(dp1[k-1] * nums[k], nums[k])\\n \\n return max(dp1) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600067666, | |
| "creationDate": 1599811240 | |
| } | |
| }, | |
| { | |
| "id": 754100, | |
| "title": "[Python] dfs + binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/find-minimum-in-rotated-sorted-array-ii", | |
| "post": { | |
| "id": 1386741, | |
| "content": "The idea is to use Binary Search, but here we can have equal numbers, so sometimes we need to find our minimum not in one half, but in two halves. Let us consider several possible cases of values `start`, `mid` and `end`.\\n\\n1. `nums[start]` \u003c `nums[mid]` \u003c `nums[end]`, for example `0, 10, 20`. In this case we need to search only in left half, data is not shifted.\\n2. `nums[mid]` \u003c `nums[end]` \u003c `nums[start]`, for example `20, 0, 10`. In this case data is shifted and we need to search in left half.\\n3. `nums[end]` \u003c `nums[start]` \u003c `nums[mid]`, for example `10, 20, 0`. In this case data is shifted and we need to search in right half.\\n4. `nums[end]` = `nums[mid]`, it this case we need to check the value of `nums[start]`, and strictly speaking we not always need to search in two halves, but I check in both for simplicity of code.\\n\\n**Complexity**: time complexity is `O(log n)` if there are no duplicates in `nums`. If there are duplicates, then complexity can be potentially `O(n)`, for cases like `1,1,1,...,1,2,1,1,....1,1`. Additional space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def findMin(self, nums):\\n def bin_dfs(start, end):\\n if end - start \u003c= 1:\\n self.Min = min(nums[start], nums[end], self.Min)\\n return\\n\\n mid = (start + end)//2\\n if nums[end] \u003c= nums[mid]:\\n bin_dfs(mid + 1, end)\\n if nums[end] \u003e= nums[mid]:\\n bin_dfs(start, mid)\\n \\n self.Min = float(\"inf\")\\n bin_dfs(0, len(nums) - 1)\\n return self.Min\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595664276, | |
| "creationDate": 1595664276 | |
| } | |
| }, | |
| { | |
| "id": 837727, | |
| "title": "[Python] easy split solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/compare-version-numbers", | |
| "post": { | |
| "id": 1530555, | |
| "content": "In python it is more like easy than medium problem, there is not a lot of cases we need to handle.\\n\\n1. First step is to split our strings using `.` and change type from string to int.\\n2. Now, if we have lists of different length, let us add zeros to the end of short list.\\n3. Finally, we need to compare `s1` and `s2` as lists. There is not `cmp()` function in python3, but we can use `(s1 \u003e s2) - (s1 \u003c s2)` trick: if `s1 \u003e s2` then we have `1-0 = 1`, if `s1 = s2`, then we have `0-0 = 0`, if we have `s1\u003c s2`, then `0-1 = -1`.\\n\\n**Complexity**: time complexity is `O(n+m)`, where `n` and `m` are lengths of our strings, space complexity `O(n+m)` as well.\\n\\n```\\nclass Solution:\\n def compareVersion(self, version1, version2):\\n s1 = [int(i) for i in version1.split(\".\")]\\n s2 = [int(i) for i in version2.split(\".\")]\\n \\n l1, l2 = len(s1), len(s2)\\n if l1 \u003c l2: s1 += [0]*(l2-l1) \\n else: s2 += [0]*(l1 - l2)\\n \\n return (s1 \u003e s2) - (s1 \u003c s2)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599639118, | |
| "creationDate": 1599639118 | |
| } | |
| }, | |
| { | |
| "id": 783383, | |
| "title": "[Python] Oneliner, base 26 numeral system, explained", | |
| "taskUrl": "https://leetcode.com/problems/excel-sheet-column-number", | |
| "post": { | |
| "id": 1436480, | |
| "content": "Note, that all depends on the place we have some symbol, for example:\\nfor `s = DACB`:\\n1. We have symbol `B` on the last place, with stands for `2`\\n2. We have symbol `C` on the previous place, which stands for `3*26`.\\n3. We have symbol `A` on the previous place, which stands for `1*26*26`.\\n4. Finally, we have symbol `D` on the first place, which stands for `4*26*26*26`.\\n5. What we need to return in this case is `2+3*26+1*26*26+4*26*26*26`.\\n\\nNote, that is it very similar to base `26` numeral system, but not exactly it, here we do not have zeros. All this can be written as oneliner.\\n\\n**Complexity**: Time complexity of this oneliner is `O(n log n)`, where `n` is length of string. We need to iterate over all string and use `26**i`. Time complexity can be easily reduced to `O(n)`. Space complexity is `O(n)`, which also can be reduced to `O(1)`. But in this problem `n` is very small: `n\u003c=7`, so it will not make a lot of difference\\n\\n```\\nclass Solution:\\n def titleToNumber(self, s):\\n return sum([(ord(T)-ord(\"A\")+1)*26**i for i,T in enumerate(s[::-1])])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597044143, | |
| "creationDate": 1597044143 | |
| } | |
| }, | |
| { | |
| "id": 965565, | |
| "title": "[Python] Stack solution + follow-up, explained", | |
| "taskUrl": "https://leetcode.com/problems/binary-search-tree-iterator", | |
| "post": { | |
| "id": 1753762, | |
| "content": "In this question we are asked to perform Iterator, using inorder traversal, so let us just use inorder traversal, using stack: we will keep two global variables:\\n1. `self.stack`: our explicit stack, where we keep our visited nodes.\\n2. `self.curr`: current node we want to return during our traversal.\\n\\nNext, what we do is perform usual iterative inorder traversal: we go als left as possible until we can and add nodes to stack. Then we remove node from stack and go to right children if it is possible. Also we save our `out` node, because we need to return it as output of `next` function. Finally, howe we can understand if we have next Node or not? If stack is not empty, we have it, also if current node is not `None`, we also have it, in other cases we are done.\\n\\n**Complexity**: amortized time complexity of `next` function is `O(1)`: we spend `O(n)` time to visit all `n` nodes. Note, that amortized time means, that we spend `O(1)` in average, it is exactly what we need in follow-up. Also space complexity for this solution is `O(h)`: our stack will never be longer than height of our tree.\\n\\n```\\nclass BSTIterator:\\n def __init__(self, root):\\n self.stack = []\\n self.curr = root\\n \\n def next(self):\\n while self.curr:\\n self.stack.append(self.curr)\\n self.curr = self.curr.left\\n self.curr = self.stack.pop()\\n out = self.curr.val\\n self.curr = self.curr.right\\n return out\\n\\n def hasNext(self):\\n return self.stack or self.curr\\n```\\n\\nNote also, that there is Morris Traversal with `O(1)` time in average and `O(1)` space.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607502900, | |
| "creationDate": 1607502900 | |
| } | |
| }, | |
| { | |
| "id": 698271, | |
| "title": "[Python] Short DP, 7 lines, O(mn), top-down, explained", | |
| "taskUrl": "https://leetcode.com/problems/dungeon-game", | |
| "post": { | |
| "id": 1290003, | |
| "content": "Probably when you see this problem and you have some experience in this type of problems you can guess, that this is **dynamic programming** problem. However even if you understand this, it is not easy to solve it. Let us use top-down dp, that is `Let dp[i][j]` be the minimum **hp** we need to reach the **princess** if we start from point `(i,j)`. Let us consider the following example:\\n\\n| -2 | -3 | +3 |\\n|---------|---------|--------|\\n| **-5** | **-10** | **+1** |\\n| **+10** | **+30** | **-5** |\\n\\nLet us add bottom dummy row and right dummy column to handle border cases more easy. We fill it with infinities, except two ones - neibours of our princess. I will explain it a bit later.\\n\\nHow we can evaluate `dp[i][j]`? We need to look at two cells: `dp[i+1][j]` and `dp[i][j+1]` and evaluate two possible candidates: `dp[i+1][j]-dungeon[i][j]` and `dp[i][j+1]-dungeon[i][j]`.\\n1. If at least one of these two numbers is negative, it means that we can survive just with `1` hp: (look at number `+30` in our table for example)\\n2. If both this numbers are positive, we need to take the mimumum of them, see for example number `-10` in our table: to survive we need either `5- -10 = 15` if we go right and `1- -10 = 11` if we go down, of course we choose `11`.\\n3. This conditions can be written in one a bit ugly line: `dp[i][j] = max(min(dp[i+1][j],dp[i][j+1])-dungeon[i][j],1)`.\\n4. Finally, why I put `1` to two neibors of princess? To make this formula valid for princess cell: if we have negative number like `-5` in this cell, we need `6` hp to survive, if we have non-negative number in this cell, we need `1` hp to survive.\\n\\n| 7 | 5 | 2 | inf |\\n|---------|---------|-------|---------|\\n| **6** | **11** | **5** | **inf** |\\n| **1** | **1** | **6** | **1** |\\n| **inf** | **inf** | **1** | **#** |\\n\\n**Complexity**: both time and space is `O(mn)`. Space complexity can be reduced to `O(min(m,n))` as usual, because we look only to neibour cells. However code becomes a bit more difficult to follow.\\n\\n```\\nclass Solution:\\n def calculateMinimumHP(self, dungeon):\\n m, n = len(dungeon), len(dungeon[0])\\n dp = [[float(\"inf\")]*(n+1) for _ in range(m+1)]\\n dp[m-1][n], dp[m][n-1] = 1, 1\\n \\n for i in range(m-1,-1,-1):\\n for j in range(n-1,-1,-1):\\n dp[i][j] = max(min(dp[i+1][j],dp[i][j+1])-dungeon[i][j],1)\\n \\n return dp[0][0]\\n```\\n\\n**Further discussion** It is possible to do it with down-top dp as well, howerer in this case you need to use **binary search**, because you do not know in advance if you survive starting say `1000` hp or not. Complexity will be `O(nm log(MAX_INT))` in this case.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592750795, | |
| "creationDate": 1592727038 | |
| } | |
| }, | |
| { | |
| "id": 863489, | |
| "title": "[Python] 2 lines solution, using sort, explained", | |
| "taskUrl": "https://leetcode.com/problems/largest-number", | |
| "post": { | |
| "id": 1576394, | |
| "content": "Note, that we need to somehow sort our data, but be carefull about it: if we have `3`, `32` and `31`, then we need to choose `3` as the first element. However if we have `3`, `34` and `32`, then we need to chose `34` as the first element. So, let us for each two numbers `x` and `y` decide which one is better: we need to compare `xy` and `yx` and choose the best one: we work with `x` and `y` as with strings: for example for `x = 3` and `y = 32`, we need to compare `xy = 332` and `yx = 323`. Also it can be shown that if `xy \u003e= yx` and `yz \u003e= zy`, then `xz \u003e= zx`, this means that we have transitivity property, and this is enough to ensure that our sort is consistent: https://en.wikipedia.org/wiki/Comparison_sort \\n\\n**Complexity**: time complexity is `O(n log n)`, if we assume that we can make comparison in constant time. In practise, we use strings and compare them, so complexity will be ineed `O(1)`. Space complexity is `O(n)` to keep sorted numbers.\\n\\n**Note** I use `cmp_to_key` function from `functools` library, which is imported in leetcode already. Also in the end we can have results like `00`, which we need to make `0`, so we use `str(int(...))` trick.\\n\\n```\\nclass Solution:\\n def largestNumber(self, nums):\\n compare = lambda a, b: -1 if a+b \u003e b+a else 1 if a+b \u003c b+a else 0\\n return str(int(\"\".join(sorted(map(str, nums), key = cmp_to_key(compare)))))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601024523, | |
| "creationDate": 1601024523 | |
| } | |
| }, | |
| { | |
| "id": 898299, | |
| "title": "[Python] 2 lines solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/repeated-dna-sequences", | |
| "post": { | |
| "id": 1636121, | |
| "content": "Let us just put all sequences of length `10` into list, then apply counter: count how many times each element is present and finally return elements with frequency more than `1`.\\n\\n**Complexity**: Time and space complexity is `O(10n)`: ther will be `O(n)` substrings of length `10`.\\n\\n```\\nclass Solution:\\n def findRepeatedDnaSequences(self, s):\\n Count = Counter(s[i-10:i] for i in range(10, len(s) + 1))\\n return [key for key in Count if Count[key] \u003e 1] \\n```\\n\\n**Remark** When I saw this problem, my first idea was to use rolling hash, which potentially can give us `O(n)` instead of `O(10n)` complexity. However we need not only evaluate how many repeated substrings of length `10` we have, but also return them all. This potentially can spend `O(n)` time: imagine example:\\n`TT`, where `T` is string of length `n/2`. Then if all substring in `T` are different, we have `O(n/2)` different substings, we need to return, which gives us `O(5n)` space complexity of output.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602935949, | |
| "creationDate": 1602923386 | |
| } | |
| }, | |
| { | |
| "id": 900151, | |
| "title": "[Python] O(nk) dynamic programming, explained", | |
| "taskUrl": "https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv", | |
| "post": { | |
| "id": 1639726, | |
| "content": "This problem is just extension of problem **123. Best Time to Buy and Sell Stock III**\\n\\nExplanations are exactly the same as problem 123: https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/discuss/794633/Python-O(n)-solution-with-optimization-explained\\n\\n**Complexity**: time and space complexity is `O(nk)`, space comlexity can be improved to `O(k)`\\n\\n```\\nclass Solution:\\n def maxProfit(self, k, prices):\\n if len(prices) \u003c= 1 or k == 0: return 0\\n \\n delta = [prices[i+1]-prices[i] for i in range (len(prices)-1)]\\n B=[sum(delta) for _, delta in groupby(delta, key=lambda x: x \u003c 0)]\\n n = len(B) + 1\\n\\n if k \u003e len(prices)//2: return sum(x for x in B if x \u003e 0)\\n \\n dp = [[0]*(k+1) for _ in range(n-1)] \\n mp = [[0]*(k+1) for _ in range(n-1)] \\n\\n dp[0][1], mp[0][1] = B[0], B[0]\\n\\n for i in range(1, n-1):\\n for j in range(1, k+1):\\n dp[i][j] = max(mp[i-1][j-1], dp[i-1][j]) + B[i]\\n mp[i][j] = max(dp[i][j], mp[i-1][j])\\n\\n return max(mp[-1])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603024885, | |
| "creationDate": 1603024885 | |
| } | |
| }, | |
| { | |
| "id": 895412, | |
| "title": "[Python] O(n) inplace solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/rotate-array", | |
| "post": { | |
| "id": 1631349, | |
| "content": "Very nice and interesting problem if we are asked to do it in place in linear time. \\nImagine, that we have number `[1,2,3,4,5,6,7,8]` and we have `k = 3`, then what is expected from us is `[6,7,8,1,2,3,4,5]`. Let us note, that a lot of structure in our list kept the same. Let us reverse list and try to find some patterns:\\n`[6,7,8,1,2,3,4,5]`\\n`[8,7,6,5,4,3,2,1]`\\nYou see it? What we need to do know is reverse first `3` elements and to reverst last `5` elements and this is all! It seems very easy, but in fact if you never used similar trick, it is very difficult to think, why we need to inverse arrays in the first place.\\n\\n**Complexity**: time complexity is `O(n)`, because in whole we change elements `2n` times. Space complexity is `O(1)`, because we do it in place.\\n\\n```\\nclass Solution:\\n def rotate(self, nums: List[int], k: int) -\u003e None:\\n def inverse(i, j):\\n while i \u003c j:\\n nums[i], nums[j] = nums[j], nums[i]\\n i, j = i + 1, j - 1\\n \\n n = len(nums)\\n k = k % n\\n inverse(0, n-1)\\n inverse(0, k-1)\\n inverse(k, n-1)\\n return nums\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602750981, | |
| "creationDate": 1602750981 | |
| } | |
| }, | |
| { | |
| "id": 732138, | |
| "title": "[Python] O(32) simple solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/reverse-bits", | |
| "post": { | |
| "id": 1349411, | |
| "content": "We are asked to reverse bits in our number. What is the most logical way to do it? Create number `out`, process original number bit by bit from end and add this bit to the end of our `out` number, and that is all! Why it is works? \\n1. `out = (out \u003c\u003c 1)^(n \u0026 1)` adds last bit of `n` to `out`\\n2. `n \u003e\u003e= 1` removes last bit from `n`.\\n\\nImagine number `n = 11011010`, and `out = 0`\\n1. `out = 0`, `n = 1101101`\\n2. `out = 01`, `n = 110110`\\n3. `out = 010`, `n = 11011`\\n4. `out = 0101`, `n = 1101`\\n5. `out = 01011`, `n = 110`\\n6. `out = 010110`, `n = 11`\\n7. `out = 0101101`, `n = 1`\\n8. `out = 01011011`, `n = 0` \\n\\n**Compexity**: time complexity is `O(32)`, space complexity is `O(1)`.\\n\\n**Follow up** There is `O(5)` smart solution which quite impressive, see the most voted post in discussion by @tworuler. We also can hash some `8`-bits parts, so we can inverse `4` parts on the fly, with time complexity `O(4)` and memory complexity `O(256)` (and preprocessing `O(256)` as well).\\n\\n\\n\\n```\\nclass Solution:\\n def reverseBits(self, n):\\n out = 0\\n for i in range(32):\\n out = (out \u003c\u003c 1)^(n \u0026 1)\\n n \u003e\u003e= 1\\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594542614, | |
| "creationDate": 1594542614 | |
| } | |
| }, | |
| { | |
| "id": 846004, | |
| "title": "[Python] 4 lines easy dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/house-robber", | |
| "post": { | |
| "id": 1545296, | |
| "content": "Nice and easy dynamic programming problem! Let `dp1` be maximum gain we can get, using last `i-1` houses and `dp2` maximum gain we can get, using `i` houses. How we need to update these numbers if we go from `i` to `i+1`? So `dp1` and `dp2` should mean gain for `i` and `i+1` houses.\\n\\n1. `dp1 = dp2`, gain to rob `i+1-1` houses is gain to rob `i` houses.\\n2. `dp2 = max(dp1 + num, dp2)`: we have 2 choices: either rob house number `i+1`, then we can rob `i`th house, so we have total gain `dp1 + num`, or we do not rob `i+1`th house, then we can gain `dp2`.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def rob(self, nums):\\n dp1, dp2 = 0, 0\\n for num in nums:\\n dp1, dp2 = dp2, max(dp1 + num, dp2) \\n return dp2 \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600068430, | |
| "creationDate": 1600068430 | |
| } | |
| }, | |
| { | |
| "id": 745470, | |
| "title": "[Python] One pass O(n) time, O(1) memory, explained", | |
| "taskUrl": "https://leetcode.com/problems/remove-linked-list-elements", | |
| "post": { | |
| "id": 1372269, | |
| "content": "Easy linked list traversal problem, without any smart ideas: just traverse list and do what is asked. Two small things which helps to simplify code:\\n1. When traverse, always look at the next element in list, because if we already at element with value equal to `val`, we can not delete it, we need to go back somehow.\\n2. Use dummy head to deal with case when head is equal to `val`.\\n\\nSo, basically our algorithm looks like this: we traverse our list and if value of next element is equal to `val`, we need to delete it, so we do `start.next = start.next.next`. Note, that in this case we do not move our pointers, because there can be more element equal to `val`. If value is not equal to `val`, we move to the next element.\\n\\n**Complexity**: time complexity is `O(n)` with only one pass, space complexity is `O(1)`, because we do not use any additional memory except couple of variable.\\n\\n```\\nclass Solution:\\n def removeElements(self, head, val):\\n dummy = ListNode(-1)\\n dummy.next = head\\n start = dummy\\n while start.next:\\n if start.next.val == val:\\n start.next = start.next.next\\n else:\\n start = start.next \\n return dummy.next \\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595234077, | |
| "creationDate": 1595234077 | |
| } | |
| }, | |
| { | |
| "id": 658297, | |
| "title": "[Python] Topological sort with recurcive dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/course-schedule", | |
| "post": { | |
| "id": 1220060, | |
| "content": "This is the classical problem about **topological sort**: (for more details you can look https://en.wikipedia.org/wiki/Topological_sorting). The basic idea of topological for directed graphs is to check if there cycle in this graph. For example if you have in your schedule dependencies like `0 -\u003e 5, 5-\u003e 3` and `3 -\u003e 0`, then we say, that **cycle** exists and in this case we need to return `False`.\\n\\nThere are different ways to do topological sort, I prefer to use dfs. The idea is to use classical `dfs` traversal, but color our nodes into `3` different colors, `0 (white)` for node which is not visited yet, `1 (gray)` for node which is in process of visiting (not all its neibours are processed), and `2 (black)` for node which is fully visited (all its neibours are already processed). The proof can be found for example in classical Cormen book. \\n\\nSo, basically we have two variables: `self.Visited = [0] * numCourses` where we keep our colors and define `self.FoundCycle = 0`, we keep it for early stopping, if we found cycle we do not need to continue and we can iterrurupt earlier. Not, that graph is not necessarily connected, so we need to start our dfs from all nodes. \\n\\n**Comlexity.** We use classical dfs, so time comlexity is `O(E+V)`, where `E` is number of edges and `V` is number of vertices. Space complexity is also `O(E+V)` because we work with adjacency lists.\\n\\n```\\nclass Solution:\\n def canFinish(self, numCourses, prerequisites):\\n self.adj_dict = defaultdict(set)\\n for i, j in prerequisites:\\n self.adj_dict[i].add(j)\\n\\n self.Visited = [0] * numCourses\\n self.FoundCycle = 0\\n\\n for i in range(numCourses):\\n if self.FoundCycle == 1: break # early stop if the loop is found\\n if self.Visited[i] == 0:\\n self.DFS(i)\\n\\n return self.FoundCycle == 0\\n\\n def DFS(self, start):\\n if self.FoundCycle == 1: return # early stop if the loop is found \\n if self.Visited[start] == 1:\\n self.FoundCycle = 1 # loop is found\\n if self.Visited[start] == 0: # node is not visited yet, visit it\\n self.Visited[start] = 1 # color current node as gray\\n for neib in self.adj_dict[start]: # visit all its neibours\\n self.DFS(neib)\\n self.Visited[start] = 2 # color current node as black\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote**!", | |
| "updationDate": 1590737566, | |
| "creationDate": 1590737385 | |
| } | |
| }, | |
| { | |
| "id": 741784, | |
| "title": "[Python] Topological sort with recurcive dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/course-schedule-ii", | |
| "post": { | |
| "id": 1365771, | |
| "content": "This is the classical problem about **topological sort**: (for more details you can look https://en.wikipedia.org/wiki/Topological_sorting). The basic idea of topological for directed graphs is to check if there cycle in this graph. For example if you have in your schedule dependencies like `0 -\u003e 5`, `5-\u003e 3` and `3 -\u003e 0`, then we say, that cycle exists and in this case we need to return `False`.\\n\\nThere are different ways to do topological sort, I prefer to use `dfs`. The idea is to use classical `dfs` traversal, but color our nodes into `3` different colors, `0 (white)` for node which is not visited yet, `1 (gray)` for node which is in process of visiting (not all its neibours are processed), and `2 (black)` for node which is fully visited (all its neibours are already processed). The proof can be found for example in classical Cormen book (note, that here we have slightly different notation with inversed edges, so we do not need to reverse list in the end).\\n\\nSo, basically we have three variables: `self.Visited = [0] * numCourses` where we keep our colors, define `self.FoundCycle = 0`, we keep it for early stopping, if we found cycle we do not need to continue and we can iterrurupt earlier and `Ans` is the list we need to return of fully visited nodes. Note, that graph can be not necessarily connected, so we need to start our `dfs` from all nodes.\\n\\n**Comlexity.** We use classical dfs, so time comlexity is `O(E+V)`, where `E` is number of edges and `V` is number of vertices. Space complexity is also `O(E+V)` because we work with adjacency lists.\\n\\n```\\nclass Solution:\\n def findOrder(self, numCourses, prerequisites):\\n self.adj_dict = defaultdict(set)\\n for i, j in prerequisites:\\n self.adj_dict[i].add(j)\\n\\n self.Visited = [0] * numCourses\\n self.Ans, self.FoundCycle = [], 0\\n \\n for i in range(numCourses):\\n if self.FoundCycle == 1: break # early stop if the loop is found\\n if self.Visited[i] == 0:\\n self.dfs(i)\\n \\n return [] if self.FoundCycle == 1 else self.Ans\\n\\n def dfs(self, start):\\n if self.FoundCycle == 1: return # early stop if the loop is found \\n if self.Visited[start] == 1:\\n self.FoundCycle = 1 # loop is found\\n if self.Visited[start] == 0: # node is not visited yet, visit it\\n self.Visited[start] = 1 # color current node as gray\\n for neib in self.adj_dict[start]: # visit all its neibours\\n self.dfs(neib)\\n self.Visited[start] = 2 # color current node as black\\n self.Ans.append(start) # add node to answer\\n```\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595084493, | |
| "creationDate": 1595057557 | |
| } | |
| }, | |
| { | |
| "id": 774530, | |
| "title": "[Python] Trie solution with dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/add-and-search-word-data-structure-design", | |
| "post": { | |
| "id": 1421496, | |
| "content": "In this problem, we need to use **Trie** data structure. For more details go to the problem **208. Implement Trie (Prefix Tree)**. \\n\\nSo, what we have here? \\n1. `TrieNode` class with two values: dictionary of children and flag, if this node is end of some word.\\n2. Now, we need to implement `addWord(self, word)` function: we add symbol by symbol, and go deepere and deeper in our Trie. In the end we note our node as end node.\\n3. Now, about `search(self, word)` function. Here we use `dfs(node, i)` with backtracking, because we can have symbol `.` in our word (here `node` is link to Trie node and `i` is index of letter in `word`). So we need to check all options: we go to all possible children and call `dfs` recursively. If we found not `.`, but just some letter, we check if we have this letter as children, and if we have, we go deeper. If we are out of letters, that is `i == len(word)`, we return `True` if current `end_node` is equal to `1` and false in opposite case. Finally, we return `False` if we can not go deeper, but we still have letters.\\n4. Now, we just return `dfs(self.root, 0)`.\\n\\n**Complexity**: Easy part is space complexity, it is `O(M)`, where `M` is sum of lengths of all words in our Trie. This is upper bound: in practice it will be less than `M` and it depends, how much words are intersected. The worst time complexity is also `O(M)`, potentially we can visit all our Trie, if we have pattern like `.....`. For words without `.`, time complexity will be `O(h)`, where `h` is height of Trie. For words with several letters and several `.`, we have something in the middle.\\n\\n```\\nclass TrieNode:\\n def __init__(self):\\n self.children = {}\\n self.end_node = 0\\n \\nclass WordDictionary:\\n def __init__(self):\\n self.root = TrieNode() \\n\\n def addWord(self, word):\\n root = self.root\\n for symbol in word:\\n root = root.children.setdefault(symbol, TrieNode())\\n root.end_node = 1\\n \\n def search(self, word):\\n def dfs(node, i):\\n if i == len(word): return node.end_node\\n \\n if word[i] == \".\":\\n for child in node.children:\\n if dfs(node.children[child], i+1): return True\\n \\n if word[i] in node.children:\\n return dfs(node.children[word[i]], i+1)\\n \\n return False\\n \\n return dfs(self.root, 0)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596631569, | |
| "creationDate": 1596631569 | |
| } | |
| }, | |
| { | |
| "id": 712733, | |
| "title": "[Python] Trie solution with dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/word-search-ii", | |
| "post": { | |
| "id": 1314919, | |
| "content": "One of the efficient ways to solve this problem is to use **Trie**. For more details please look https://en.wikipedia.org/wiki/Trie. In two words, it is a special data structure, similar to trees, but which has letters inside and used to quick search of patterns in strings. For implementation of Trie, please visit problem **208. Implement Trie** (however I put my code here as well)\\n\\nOutline of algorithm:\\n1. For each `word` in our `words` insert it in our Trie.\\n2. Starting with each symbol in our board, start `dfs` (backtracking) which are looking for words in our Trie.\\n\\n**Variables**: \\n`self.num_words` is total number of words we still need to find, in the beginning it is equal to total number of words. \\n`res` is our result, where we keep found words. \\n`trie` is our trie.\\n\\nNow, how our `dfs(self, board, node, i, j, path, res)` works?\\n\\n0. `board` is our original board, `node` is current node of `trie`, `i` and `j` are current coordinates we are it, `path` is word build so far and `res` is global variable for found words.\\n1. First, we check if we still need to look for words, if not, return\\n2. Check if the node we are in currently is **end_node**: it means, that some word was found! We add it to our `res`, mark `node.end_node` as False (we do not want to search it once again) and decrease number of words we still need to find by `1`.\\n3. If we out of border or we inside border, but we can not traverse our `trie` we again do nothing.\\n4. Now, we mark `(i,j)` position in our board as visited: `#`, call our dfs for all neibours, and then restore value ofr `(i,j)` position. (the reason is in pyton if we give list as parameter of recursive method, it will deal as global variable, so we need to fix it when we returned from our recursion).\\n\\n**Complexity**. This is difficult question, space complexity is needed to keep our `trie`, which is `O(k)`, where `k` is sum of length of all words. Time complexity is `O(mn*3^T)`, where `m` and `n` are sizes of our board and `T` is the length of the longest word in `words`. Why? Because we start our `dfs` from all points of our board and do not stop until we make sure that the longest word is checked: if we are not lucky and this word can not be found on board we need to check potentialy to the length `T`. Why `3^T`? Because each time we can choose one of three directions, except the one we came from.\\n\\n```\\nclass TrieNode:\\n def __init__(self):\\n self.children = {}\\n self.end_node = 0\\n\\nclass Trie:\\n def __init__(self):\\n self.root = TrieNode()\\n\\n def insert(self, word):\\n root = self.root\\n for symbol in word:\\n root = root.children.setdefault(symbol, TrieNode())\\n root.end_node = 1\\n\\nclass Solution:\\n def findWords(self, board, words):\\n self.num_words = len(words)\\n res, trie = [], Trie()\\n for word in words: trie.insert(word) \\n\\n for i in range(len(board)):\\n for j in range(len(board[0])):\\n self.dfs(board, trie.root, i, j, \"\", res)\\n return res\\n\\n def dfs(self, board, node, i, j, path, res):\\n if self.num_words == 0: return\\n\\n if node.end_node:\\n res.append(path)\\n node.end_node = False\\n self.num_words -= 1\\n\\n if i \u003c 0 or i \u003e= len(board) or j \u003c 0 or j \u003e= len(board[0]): return \\n tmp = board[i][j]\\n if tmp not in node.children: return\\n\\n board[i][j] = \"#\"\\n for x,y in [[0,-1], [0,1], [1,0], [-1,0]]:\\n self.dfs(board, node.children[tmp], i+x, j+y, path+tmp, res)\\n board[i][j] = tmp\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593588678, | |
| "creationDate": 1593503071 | |
| } | |
| }, | |
| { | |
| "id": 893957, | |
| "title": "[Python] Just use House Robber twice", | |
| "taskUrl": "https://leetcode.com/problems/house-robber-ii", | |
| "post": { | |
| "id": 1628811, | |
| "content": "This problem can be seen as follow-up question for problem **198. House Robber**. Imagine, that we can already solve this problem: for more detailes please see my post:\\nhttps://leetcode.com/problems/house-robber/discuss/846004/Python-4-lines-easy-dp-solution-explained\\n\\nNow, what we have here is circular pattern. Imagine, that we have `10` houses: `a0, a1, a2, a3, ... a9`: Then we have two possible options:\\n1. Rob house `a0`, then we can not rob `a0` or `a9` and we have `a2, a3, ..., a8` range to rob\\n2. Do not rob house `a0`, then we have `a1, a2, ... a9` range to rob.\\n\\nThen we just choose maximum of these two options and we are done!\\n\\n**Complexity**: time complexity is `O(n)`, because we use `dp` problem with complexity `O(n)` twice. Space complexity is `O(1)`, because in python lists passed by reference and space complexity of House Robber problem is `O(1)`.\\n\\n```\\nclass Solution:\\n def rob(self, nums):\\n def rob_helper(nums):\\n dp1, dp2 = 0, 0\\n for num in nums:\\n dp1, dp2 = dp2, max(dp1 + num, dp2) \\n return dp2\\n \\n return max(nums[0] + rob_helper(nums[2:-1]), rob_helper(nums[1:]))\\n ```\\n \\n If you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602665763, | |
| "creationDate": 1602664254 | |
| } | |
| }, | |
| { | |
| "id": 842764, | |
| "title": "[Python] backtrack solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/combination-sum-iii", | |
| "post": { | |
| "id": 1539269, | |
| "content": "If in problem we need to return all possible options with some property, usually it means that we need to do backtracking. Let us use `BackTr` function with parameters:\\n\\n1. `k` is number of numbers we need to take to build our number.\\n2. `n` is number we need to build\\n3. `curr_sol` built solution so far.\\n\\nThen if `n\u003c0` of `k\u003c0` we need to go back; if `n==0` and `k==0` means that we found solution, so we add it to our `self.sol`. Then we just run our `BackTr` with parameters: `k-1`: we need to take one less number, `n-i`, where `i` is the last digit we added: it is either starts with `1` or with `curr_sol[-1] + 1` and `curr_sol + [i]` will be our built solution so far.\\n\\nFinally, we run ` self.BackTr(k, n, [])` and return `self.sol`.\\n\\n**Comlexity**: For first digit we have not more than `9` options, for second one no more than `8` and so on, so there will be `9*8*...*(9-k+1)` possible options, for each of which we need `O(k)`. We can improve this bound if we take into account that there is 2^9 possible combinations at all, so complexity is `O(2^9*k)`, because of all dead-ends we can have. Space complexity is `O(k)`, if we do not take into account output solution.\\n\\n```\\nclass Solution:\\n def combinationSum3(self, k, n):\\n self.sol = []\\n self.BackTr(k, n, [])\\n return self.sol\\n \\n def BackTr(self, k, n, curr_sol):\\n if n \u003c 0 or k \u003c 0: return\\n if n == 0 and k == 0:\\n self.sol.append(curr_sol)\\n \\n start = curr_sol[-1] + 1 if curr_sol else 1\\n \\n for i in range(start, 10):\\n self.BackTr(k - 1, n - i, curr_sol + [i])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600067684, | |
| "creationDate": 1599901213 | |
| } | |
| }, | |
| { | |
| "id": 954585, | |
| "title": "[Python] O(n log n) solution, using heap, explained", | |
| "taskUrl": "https://leetcode.com/problems/the-skyline-problem", | |
| "post": { | |
| "id": 1735350, | |
| "content": "For me it was quite painful problem. I realized quite fast the main idea how you can solve it, but I spend like 2 hours to handling with all corner cases you can have here. So, the idea is the following: let us traverse our buildings from left to right and at each moment of time we decide what is height of current point. Howe we can do it? We need to keep two pieces of information:\\n\\n1. So-called `active` set: what buildings we currently have in given point.\\n2. Also, we need to quickly determine the highest building in given point. We will use heap for this purpuse, and if we need to add new building to heap, it is not a problem, it can be done in `O(log n)`. However, we can not easlily delete element from heap (in python you can do it with SortedList, quite powerful data structure), so we perform so-called **lazy** deletions from heap: it this way our heap can have buildings which already ended, but it does not matter.\\n\\nNow, let us go the the main algorithm:\\n1. For each building, put two tuples of information to `points`: for left upper corner, we put `x, y` and also `-1`, meaning it is starting point and `i`: index of our building. For right upper corner we put exactly the same, but `1` instead of `-1`.\\n2. Next, we sort our point by `x` coordinate. If it is equal, we sort them by height multiplied by `-1` for left point and by `1` for right point. Why so strange: the reason, that we first want to process starts, from bigger to smaller, and then ends from smaller to bigger.\\n3. Also, we put dummy element in our heap and set.\\n4. Now, let us iterate through our `points` and: if we meet beginning of some building, we add it to active set, if we meet end, we remove it from active set\\n5. If we meet left corner of building and also it is higher than we alredy met so far, that is `h \u003e -heap[0][0]`, then we add this element to `ans`. Also we add `(-h, ind)` to our heap (in python heaps are minimum heaps, so we need to keep negative heigth).\\n6. If we meet right corner of building and it is less than highest current building, we do nothing with our heap: (actually, what we need to do is to say, that current building is not active any more and we already did this). Corner of building can not be more than than current highest building, because it is ending point. Finally, if `h == -heap[0][0]`, it means, that we need to pop some element from our heap. How many? Here we have our **lazy** updates: we look if building is active or not and if it is not, we remove and continue, until we have highest building which is active. Finally, if new point we want to add has different height from what we have as the last element of our `ans`, we add new point to `ans`: `[x, -heap[0][0]]`: note, that we add point with height **after** we removed all inactive elements from heap.\\n7. Just return our `ans`.\\n\\n**Complexity**: it is `O(n log n)`, because for every corner we put and remove it from our heap only once, with time `O(log n)`. Space complexity is potentially `O(n)`.\\n\\n\\n\\n```\\nclass Solution:\\n def getSkyline(self, buildings):\\n points = [(l,h,-1,i) for i, (l,r,h) in enumerate(buildings)]\\n points += [(r,h,1,i) for i, (l,r,h) in enumerate(buildings)]\\n points.sort(key = lambda x: (x[0], x[1]*x[2]))\\n heap, active, ans = [(0,-1)], set([-1]), []\\n \\n for x, h, lr, ind in points:\\n if lr == -1: active.add(ind)\\n else: active.remove(ind)\\n \\n if lr == -1:\\n if h \u003e -heap[0][0]: \\n ans.append([x, h])\\n heappush(heap, (-h, ind))\\n else:\\n if h == -heap[0][0]: \\n while heap and heap[0][1] not in active: heappop(heap)\\n if -heap[0][0] != ans[-1][1]: \\n ans.append([x, -heap[0][0]])\\n \\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606748571, | |
| "creationDate": 1606736784 | |
| } | |
| }, | |
| { | |
| "id": 824603, | |
| "title": "[Python] SortedList O(n log k) solution, explained.", | |
| "taskUrl": "https://leetcode.com/problems/contains-duplicate-iii", | |
| "post": { | |
| "id": 1508518, | |
| "content": "In my opinion it is more like **hard** problem, because brute-force solution will get you TLE and all other solutions uses some not easy trick: either heaps or BST or bucket sort. If you know some other solution without these ideas, please let me know!\\n\\nIn this problem we need to iterate over window of size `k+1` and check if there is numbers with difference `\u003c=t` in this window. What we need to do efficiently is to add and remove elements from our window, and my choice of data structure is BST, which is implemented in `SortedList` in python. So on each step we have sorted list of elements in this window. Imagine the case:\\n\\n`[1, 3, 7, 12]` and new number we need to insert is `10`, and `t = 2`. Then we need to consider range `[8,12]` and check if we have numbers in our `SList` in this range. We can do two binary searches here: `bisect_left` for left boundary and `bisect_right` for right boundary. Also we need to check if `pos1 != len(SList)`, if this is the case, it means that new number is bigger than bigges number in list + `t`, so in this case we just put it directly to our list. If `pos1 != pos2`, this means, that we found some number i our `[nums[i] - t, nums[i] + t]` range, so we immediatly return `True`.\\n\\n**Complexity**: time complexity is `O(n log k)`, because we do `n` steps, each one with `O(log k)` complexity to do binary search, remove and add elements. Space complexity is `O(k)` to keep our `SortedList` updated.\\n\\n```\\nfrom sortedcontainers import SortedList\\n\\nclass Solution:\\n def containsNearbyAlmostDuplicate(self, nums, k, t):\\n SList = SortedList()\\n for i in range(len(nums)):\\n if i \u003e k: SList.remove(nums[i-k-1]) \\n pos1 = SortedList.bisect_left(SList, nums[i] - t)\\n pos2 = SortedList.bisect_right(SList, nums[i] + t)\\n \\n if pos1 != pos2 and pos1 != len(SList): return True\\n \\n SList.add(nums[i])\\n \\n return False\\n```\\n\\n**PS** because of time complexity `O(n log k)`, this solution will not be on top, there is `O(n)` bucket sort solution, but in my opinion it is for certain hard level.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599219144, | |
| "creationDate": 1599037700 | |
| } | |
| }, | |
| { | |
| "id": 701466, | |
| "title": "[Python] O(log n * log n) solution with Binary Search, explained", | |
| "taskUrl": "https://leetcode.com/problems/count-complete-tree-nodes", | |
| "post": { | |
| "id": 1295583, | |
| "content": "Here we are given, that our tree is **complete** and we need to use this property to make it faster. Let us consider the following tree:\\n\\n\\n\\n1. I denoted values for nodes in the way of how we are going to count them, note that it does not matter in fact what is inside.\\n2. First step is to find the number of levels in our tree, you can see, that levels with depth `0,1,2` are full levels and level with `depth = 3` is not full here.\\n3. So, when we found that `depth = 3`, we know, that there can be between `8` and `15` nodes when we fill the last layer.\\n4. How we can find the number of elements in last layer? We use **binary search**, because we know, that elements go from left to right in complete binary tree. To reach the last layer we use binary decoding, for example for number `10`, we write it as `1010` in binary, remove first element (it always will be `1` and we not interested in it), and now we need to take `3` steps: `010`, which means `left, right, left`.\\n\\n**Complexity.** To find number of layers we need `O(log n)`. We also need `O(log n)` iterations for binary search, on each of them we reach the bottom layer in `O(log n)`. So, overall time complexity is `O(log n * log n)`. Space complexity is `O(log n)`.\\n\\n**Code** I use auxiliary funcion `Path`, which returns True if it found node with given number and False in opposite case. In main function we first evaluate depth, and then start binary search with interval `2^depth, 2^{depth+1} - 1`. We also need to process one border case, where last layer is full.\\n\\n```\\nclass Solution:\\n def Path(self, root, num):\\n for s in bin(num)[3:]:\\n if s == \"0\": \\n root = root.left\\n else:\\n root = root.right\\n if not root: return False\\n return True\\n \\n def countNodes(self, root):\\n if not root: return 0\\n \\n left, depth = root, 0\\n while left.left:\\n left, depth = left.left, depth + 1\\n\\n begin, end = (1\u003c\u003cdepth), (1\u003c\u003c(depth+1)) - 1\\n if self.Path(root,end): return end\\n \\n while begin + 1 \u003c end:\\n mid = (begin + end)//2\\n if self.Path(root, mid):\\n begin = mid\\n else:\\n end = mid\\n return begin\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592899217, | |
| "creationDate": 1592898386 | |
| } | |
| }, | |
| { | |
| "id": 664122, | |
| "title": "[Python] 3 Lines recursion expained", | |
| "taskUrl": "https://leetcode.com/problems/invert-binary-tree", | |
| "post": { | |
| "id": 1229882, | |
| "content": "Here what we need to do is just use definition of **inverted** tree. We go from top to bottom of our tree and if we reached the leaf, we do not do anything. If current subtree is not a leaf, we recursively call our function for both its children, first inverting them.\\n\\n**Complexity** is `O(h)`, where `h` is the height of our tree.\\n\\n```\\nclass Solution:\\n def invertTree(self, root):\\n if not root: return None\\n root.left, root.right = self.invertTree(root.right), self.invertTree(root.left)\\n\\n return root\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1590995643, | |
| "creationDate": 1590995204 | |
| } | |
| }, | |
| { | |
| "id": 658480, | |
| "title": "[Python] Basic Calculator I, II, III easy solution, detailed explanation", | |
| "taskUrl": "https://leetcode.com/problems/basic-calculator-ii", | |
| "post": { | |
| "id": 1220340, | |
| "content": "This algorithm works for `Basic Calculator (BC I)` problem, where we can have only `+ - ( )` operations, for `Basic Calculator II (BC II)`, where we can have only `+ - * /` operations and also for `Basic Calculator III (BC III)`, where we can have all `+ - * / ( )` operations.\\n\\n### Stack of monomials\\nThe idea is to use both stack and recursion (which can be seen as 2 stack, because recursion use implicit stack). First, let us consider, that we do not have any brackets. Then let us keep the stack of monomial, consider the example `s = 1*2 - 3\\\\4*5 + 6`. Then we want our stack to be equal to `[1*2, -3\\\\4*5, 6]`, let us do it step by step:\\n1. Put 1 into stack, we have `stack = [1]`.\\n2. We can see that operation is equal to `*`, so we pop the last element from our stack and put new element: `1*2`, now `stack = [1*2]`.\\n3. Now, operation is equal to `-`, so we put `-3` to stack and we have `stack = [1*2, -3]` now\\n4. Now, operation is equal to `\\\\`, so we pop the last element from stack and put `-3\\\\4` instead, `stack = [1*2, -3\\\\4]`\\n5. Now, operation is equal to `*`, so we pop last element from stack and put `-3\\\\4*5` instead, `stack = [1*2, -3\\\\4*5]`.\\n6. Finally, operation is equal to `+`, so we put `6` to stack: `stack = [1*2, -3\\\\4*5, 6]`\\n\\nNow, all we need to do is to return sum of all elements in stack.\\n\\n### How to deal with brackets\\nIf we want to be able to process the brackets properly, all we need to do is to call our calculator recursively! When we see the open bracket `(`, we call calculator with the rest of our string, and when we see closed bracket \\')\\', we give back the value of expression inside brackets and the place where we need to start when we go out of recursion.\\n\\n\\n### Complexity\\nEven though we have stack and also have recursion, we process every element only once, so time complexity is `O(n)`. Space complexity is also potentially `O(n)`, because we need to keep stacks, but each element not more than once.\\n\\n``` \\nclass Solution:\\n def calculate(self, s):\\n def update(op, v):\\n if op == \"+\": stack.append(v)\\n if op == \"-\": stack.append(-v)\\n if op == \"*\": stack.append(stack.pop() * v) #for BC II and BC III\\n if op == \"/\": stack.append(int(stack.pop() / v)) #for BC II and BC III\\n \\n it, num, stack, sign = 0, 0, [], \"+\"\\n \\n while it \u003c len(s):\\n if s[it].isdigit():\\n num = num * 10 + int(s[it])\\n elif s[it] in \"+-*/\":\\n update(sign, num)\\n num, sign = 0, s[it]\\n elif s[it] == \"(\": # For BC I and BC III\\n num, j = self.calculate(s[it + 1:])\\n it = it + j\\n elif s[it] == \")\": # For BC I and BC III\\n update(sign, num)\\n return sum(stack), it + 1\\n it += 1\\n update(sign, num)\\n return sum(stack)\\n```", | |
| "updationDate": 1590748294, | |
| "creationDate": 1590748197 | |
| } | |
| }, | |
| { | |
| "id": 913432, | |
| "title": "[Python] Two pointers O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/summary-ranges", | |
| "post": { | |
| "id": 1663420, | |
| "content": "What we need to in this problem is just traverse our data and create our ranges. Like if we have `1,2,3,4,5,7`, we see at `1`, `2`, `3`, `4` and `5`, and then we need to stop and start new range. We use two pointers approach with `beg` and `end` pointers. We increase our `end` pointers until next number is not equal to current + 1. Also we need to check if we have range with only one number of with more than one.\\n\\n**Complexity**: time complexity is `O(n)`, because we pass only once over our data. Space complexity is also potentially `O(n)`, because it can be the size of our answer.\\n\\n```\\nclass Solution:\\n def summaryRanges(self, nums):\\n i, result, N = 0, [], len(nums)\\n \\n while i \u003c N:\\n beg = end = i\\n while end \u003c N - 1 and nums[end] + 1 == nums[end + 1]: end += 1\\n result.append(str(nums[beg]) + (\"-\u003e\" + str(nums[end])) *(beg != end)) \\n i = end + 1\\n \\n return result\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603876826, | |
| "creationDate": 1603876826 | |
| } | |
| }, | |
| { | |
| "id": 858872, | |
| "title": "[Python] Voting O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/majority-element-ii", | |
| "post": { | |
| "id": 1568152, | |
| "content": "Let us iterate through our data and at each moment of time keep at most `2` candidates with the highest score, let us consider example `1 2 3 3 3 2 2 2 4 2`.\\n\\n1. On first step we add `1` to our candidates, frequency `1`, so we have `1: 1`\\n2. Now we add `2` to our candidates, frequency `1`, so we have `1:1, 2:1`.\\n3. Now we add `3` to our candidates and we have `1:1, 2:1, 3:1`. Now we subtract `1` from all frequencies, because it will not change anything.\\n4. Now we add `3`, so we have `3:1`.\\n5. Now we add `3`, so we have `3:2`.\\n6. Now we add `2`, so we have `3:2, 2:1`.\\n7. Now we add `2`, so we have `3:2, 2:2`.\\n8. Now we add `2`, so we have `3:2, 2:3`.\\n9. Now we add `4`, so we have `3:2, 2:3, 4:1`, subtract `1` from all, and we have `3:1, 2:2`.\\n10. Finally we add `2`, so we have `3:1, 2:3`.\\n\\nFirst stage of our algorithm is finished, we have no more than two candidates. Now we need to make sure, that these candidates indeed has frequence more than `[n/3]`. So we iterate through our data once again and count them. In our case `2` is true candidate and `3` need to be removed, its frequency is not big enough.\\n\\n**Complexity**: Time complexity is `O(n)`, because we traverse our `nums` twice: on first run we process each number at most twice: when we add it to counter and when remove. Second run, where we evaluate frequencies of candidates is also linear. Space complexity is `O(1)`, because our counter always have no more than `3` elements.\\n\\n```\\nclass Solution:\\n def majorityElement(self, nums):\\n count = Counter()\\n for num in nums:\\n count[num] += 1\\n if len(count) == 3:\\n new_count = Counter()\\n for elem, freq in count.items(): \\n if freq != 1: new_count[elem] = freq - 1\\n count = new_count\\n \\n cands = Counter(num for num in nums if num in count) \\n return [num for num in cands if cands[num] \u003e len(nums)/3]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600777996, | |
| "creationDate": 1600762379 | |
| } | |
| }, | |
| { | |
| "id": 676737, | |
| "title": "[Python] Oneliner O(1) bit manipulation trick explained", | |
| "taskUrl": "https://leetcode.com/problems/power-of-two", | |
| "post": { | |
| "id": 1251411, | |
| "content": "This is classical bit manipulation problem for `n \u0026 (n-1)` trick, which removes the last non-zero bit from our number\\n\\n**example**: \\n1.`n = 100000`, then `n - 1 = 011111` and `n \u0026 (n-1) = 000000`, so if it is power of two, result is zero\\n2.`n = 101110`, then `n - 1 = 101101` and `n \u0026 (n-1) = 101100`, number is not power of two and result is not zero.\\n\\n```\\nclass Solution:\\n def isPowerOfTwo(self, n):\\n return n \u003e 0 and not (n \u0026 n-1)\\n```\\n\\n**Update** there is another `O(1)` solution using math: number is power of `2` if it is divisor of the biggest possible power of `2`:\\n\\n```return n \u003e 0 and (1\u003c\u003c32) % n == 0```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591623929, | |
| "creationDate": 1591600054 | |
| } | |
| }, | |
| { | |
| "id": 665803, | |
| "title": "[Python] 2 lines easy, modify values in your list", | |
| "taskUrl": "https://leetcode.com/problems/delete-node-in-a-linked-list", | |
| "post": { | |
| "id": 1232719, | |
| "content": "If you never saw this problem it can seems quite difficult, how you can delete node, if you are given only access to that node? You need to find previous node first? No, the trick is a modification of values in our list! If you have this type of quesitions on real interview, it is the first question you must ask your interviewer. If we can modify data, solution becomes very easy, only two lines: change value of node with value of next node and then change next element for next of next element.\\n\\n**Complexity.** Both time and space comlexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def deleteNode(self, node):\\n node.val = node.next.val\\n node.next = node.next.next\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591082688, | |
| "creationDate": 1591081685 | |
| } | |
| }, | |
| { | |
| "id": 951683, | |
| "title": "[Python] Decreasing deque, short, explained", | |
| "taskUrl": "https://leetcode.com/problems/sliding-window-maximum", | |
| "post": { | |
| "id": 1730038, | |
| "content": "There are a big variety of different algorithms for this problem. The most difficult, but most efficient uses idea of decreasing deque: on each moment of time we will keep only decreasing numbers in it. Let us consider the following example: `nums = [1,3,-1,-3,5,3,6,7], k = 3`. Let us process numbers one by one: (I will print numbers, however we will keep **indexes** in our stack):\\n\\n1. We put `1` into emtpy deque: `[1]`.\\n2. New element is bigger, than previous, so we remove previous element and put new one: `[3]`.\\n3. Next element is smaller than previous, put it to the end of deque: `[3, -1]`.\\n4. Similar to previous step: `[3, -1, -3]`.\\n5. Now, let us look at the first element `3`, it has index **1** in our data, what does it mean? It was to far ago, and we need to delete it: so we `popleft` it. So, now we have `[-1, -3]`. Then we check that new element is bigger than the top of our deque, so we remove two elements and have `[5]` in the end.\\n6. New element is smaller than previous, just add it to the end: `[5, 3]`.\\n7. New element is bigger, remove elements from end, until we can put it: `[6]`.\\n8. New element is bigger, remove elements from end, until we can put it: `[7]`.\\n\\nSo, once again we have the following rules:\\n1. Elements in deque are always in decreasing order.\\n2. They are always elements from last sliding window of `k` elements.\\n3. It follows from here, that biggest element in current sliding window will be the `0`-th element in it.\\n\\n**Complexity**: time complexity is `O(n)`, because we iterate over our elements and for each element it can be put inside and outside of our deque only once. Space complexity is `O(k)`, the maximum size of our deque.\\n\\n\\n```\\nclass Solution:\\n def maxSlidingWindow(self, nums, k):\\n deq, n, ans = deque([0]), len(nums), []\\n\\n for i in range (n):\\n while deq and deq[0] \u003c= i - k:\\n deq.popleft()\\n while deq and nums[i] \u003e= nums[deq[-1]] :\\n deq.pop()\\n deq.append(i)\\n \\n ans.append(nums[deq[0]])\\n \\n return ans[k-1:]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606554414, | |
| "creationDate": 1606554414 | |
| } | |
| }, | |
| { | |
| "id": 756533, | |
| "title": "[Python] Math O(1) oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/add-digits", | |
| "post": { | |
| "id": 1390913, | |
| "content": "Straightforward solution of this problem is to do exactly what is asked, until we get only one digit. However, there is smarter mathematical solution, using property of division by `9`. Let us condiser first example and then formulate result for general case:\\n\\nLet `n = 18102`. Then numbers `n` and `sum(n)` (where by `sum(n)` we denote sum of digits of number `n`) have the same remainder if we divide them by `9`. Why so? To prove, that two numbers have the same remainder is equivalent to prove, that difference of these two numbers is divisible by `9`. Indeed:\\n`18102 - sum(18102) =10000 + 8*1000 + 1*100 + 0*10 + 2 - (1 + 8 + 1 + 0 + 2) = 9999 + 8*999 + 1*99 + 0*9 + 0` is divisible by `9`, because each term is divisible by `9`. So, now, we can state theorem:\\n\\n**Theorem** For any natural number `n`: numbers `n` and `sum(n)` have the same remainder if we divide them by `9`.\\n**Proof**: let `n = a_n ... a_2 a_1 a_0`, then `n - sum(n) = a_n* 99...9 + ... + a_2 * 99 + a_1*9 + 0`, which is divisible by `9`.\\n\\nNow, let us go back to our problem: we evaluate sum of digits of our number several times, until we reached `1`-digit number. On each iteration remainder of divition by `9` is the same. So in the very end it also be the same! So, what we need to do is just return this reminder? Almost, there are two cases we need to hanlde:\\n1. If `n = 0`, then we return `0`.\\n2. If `n \u003e 1` and `n` is divisible by `9`, then reminder is equal to `0`. However we can not reach `0`, and the answer will be another digit with reminder equal to `0`, which is `9`. \\n\\n**Complexity**: time and space complexity is `O(1)`.\\n\\nFinally, it can be written as oneliner:\\n\\n```\\nclass Solution:\\n def addDigits(self, num):\\n return 0 if num == 0 else (num - 1) % 9 + 1\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595754215, | |
| "creationDate": 1595754215 | |
| } | |
| }, | |
| { | |
| "id": 750622, | |
| "title": "[Python] 4 Lines, O(n) time, O(1) space, explained", | |
| "taskUrl": "https://leetcode.com/problems/single-number-iii", | |
| "post": { | |
| "id": 1381004, | |
| "content": "I think it is rather hard problem than medium. If you solved Single Number I or II problems you probably can immediately say, that this problem is about bit manipulations. So, the first step is to evaluate `XOR` of all numbers, but what is next? It is indeed very difficult question, if we are not allowed to use extra memory and we want to stay with `O(n)` iterations. So, what exactly we get, when we evaluate `XOR` of all numbers? We will have `num1 ^ num2`, where `num1` and `num2` are desired numbers. We need to use all the imformation given in statement, and so these numbers are different, and it means there will be at least one `bit`, where they differ, it means one number of `num1` and `num2` have this bit equal to `0` and other to `1` . Let us remember this bit and traverse data once again: making `XOR` of numbers, where this bit is equal to `1`. Then we get exactly one of our desired numbers. Finally, we can find other number, using `num2 = s^num1`, where `s` is `XOR` of all numbers.\\n\\n1. Evaluate `s` - `XOR` of all numbers.\\n2. `nz` is non-zero bit. `s\u0026(s-1)` trick is used to remove last `1`: for example for number `s = 110100`, the value `s\u0026(s-1) = 110000`, and `s \u0026 (s-1) ^ s = 110000 ^ 110100 = 000100`.\\n3. We evaluate `num1`, using only numbers, where this bit is not absent.\\n4. Finally, we evaluate `num2 = s ^ num` and return answer.\\n\\n**Complexity**: time complexity is `O(n)`, where we do `2` passes over data. Additional space complexity is `O(1)`, we use just several additional variables.\\n\\n```\\nclass Solution:\\n def singleNumber(self, nums):\\n s = reduce(xor, nums)\\n nz = s \u0026 (s-1) ^ s\\n num1 = reduce(xor, filter(lambda n: n \u0026 nz, nums))\\n return(num1, s ^ num1)\\n```\\n\\n**Update** Thanks @rkmd for pointing out nicer ways to use `reduce` function!\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595498416, | |
| "creationDate": 1595492857 | |
| } | |
| }, | |
| { | |
| "id": 718879, | |
| "title": "[Python] O(n) universal dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/ugly-number-ii", | |
| "post": { | |
| "id": 1325931, | |
| "content": "Let us solve this problem for general case: that is not only for `2,3,5` divisors, but for any of them and any number of them. `factors = [2,3,5]` and `k=3` in our case.\\nLet `Numbers` be an array, where we keep all our **ugly** numbers. Also, note, that any ugly number is some other ugly number, multiplied by `2`, `3` or `5`. So, let `starts` be the indexes of ugly numbers, that when multiplied by `2`, `3` or `5` respectively, produces the smallest ugly number that is larger than the current overall maximum ugly number.. Let us do several first steps to understand it better:\\n\\n1. `starts = [0,0,0]` for numbers `2,3,5`, so `new_num = min(1*2,1*3,1*5) = 2`, and now `starts = [1,0,0]`, `Numbers = [1,2]`.\\n2. `starts = [1,0,0]`, so `new_num = min(2*2,1*3,1*5) = 3`, and now `starts = [1,1,0]`, `Numbers = [1,2,3]`.\\n3. `starts = [1,1,0]`, so `new_num = min(2*2,2*3,1*5) = 4`, so now `starts = [2,1,0]`, `Numbers = [1,2,3,4]`.\\n4. `starts = [2,1,0]`, so `new_num = min(3*2,2*3,1*5) = 5`, so now `starts = [2,1,1]`, `Numbers = [1,2,3,4,5]`.\\n5. `starts = [2,1,1]`, so `new_num = min(3*2,2*3,2*5) = 6`, so let us be carefull in this case: we need to increase two numbers from `start`, because our new number `6` can be divided both by `2` and `3`, so now `starts = [3,2,1]`, `Numbers = [1,2,3,4,5,6]`.\\n6. `starts = [3,2,1]`, so `new_num = min(4*2,3*3,2*5) = 8`, so now `starts = [4,2,1]`, `Numbers = [1,2,3,4,5,6,8]`\\n7. `starts = [4,2,1]`, so `new_num = min(5*2,3*3,2*5) = 9`, so now `starts = [4,3,1]`, `Numbers = [1,2,3,4,5,6,8,9]`.\\n8. `starts = [4,3,1]`, so `new_num = min(5*2,4*3,2*5) = 10`, so we need to update two elements from `starts` and now `starts = [5,3,2]`, `Numbers = [1,2,3,4,5,6,8,9,10]`\\n9. `starts = [5,3,2]`, so `new_num = min(6*2,4*3,3*5) = 12`, we again need to update two elements from `starts`, and now `starts = [6,4,2]`, `Numbers = [1,2,3,4,5,6,8,9,10,12]`.\\n10. `starts = [6,4,2]`, so `new_num = min(8*2,5*3,3*5) = 15`, we again need to update two elements from `starts`, and now `starts = [6,5,3]`, `Numbers = [1,2,3,4,5,6,8,9,10,12,15]`.\\n\\n**Complexity**: time complexity is `O(n)` to find ugly number with number `n`, because on each step we check `3` possible candidates. Space complexity is `O(n)` as well. Note, that it can be easily generalized for different amount of divisors with time complexity `O(nk)`, where `k` is total number of divisors.\\n\\n```\\nclass Solution:\\n def nthUglyNumber(self, n):\\n factors, k = [2,3,5], 3\\n starts, Numbers = [0] * k, [1]\\n for i in range(n-1):\\n candidates = [factors[i]*Numbers[starts[i]] for i in range(k)]\\n new_num = min(candidates)\\n Numbers.append(new_num)\\n starts = [starts[i] + (candidates[i] == new_num) for i in range(k)]\\n return Numbers[-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593892115, | |
| "creationDate": 1593848658 | |
| } | |
| }, | |
| { | |
| "id": 656820, | |
| "title": "[Python] Short O(n) time\u0026space, explained", | |
| "taskUrl": "https://leetcode.com/problems/h-index", | |
| "post": { | |
| "id": 1217637, | |
| "content": "### Explanations\\nThe main trick is to count for each possible number of citations, how many times we see this number in our `citations`. Note, that if number of citations is more than total number of papers `N`, we can reduce this numer to `N` and nothing will change. Let me explain my solutoin given test example `[3,0,6,1,5]`.\\n1. We create array, which I called `buckets = [1, 1, 0, 1, 0, 2]`, where `buckets[i]` is number of papers with `i` citations if `i \u003c N` and `bucket[N]` is number of papers with `\u003e=N` citations.\\n2. Now, we create `accum` array, where `accum[0]` is number of papers with `\u003e=1` citation, `accum[1]` is number of papers with `\u003e=2` citations and so on. When we evaluate it for our example we can see, that it is equal to `accum = [4,3,3,2,2]`. Note, that we start with 1 citation, not with zero, that is why we need to use `accum[1:]` in our code.\\n3. Finally, we need to go through this array and find the bigest number `i`, for which `accum[i] \u003e= i + 1` and return `i + 1`, in our example it is equal to `3`.\\n\\n### Complexity\\nComplexity is O(n), though we traverse our data 4 times, and it is not the optimal solution. We can evaluate cumulative sums in place, and compare them in place with `i + 1` and keep the index of maximum reached so far, and interrupt when inequality `accum[i] \u003e= i + 1` does not hold anymore. Howerer I like cumulative sums and code is more clean in my way.\\n\\n### Code\\n\\n```\\nclass Solution:\\n def hIndex(self, citations):\\n N = len(citations)\\n buckets = [0] * (N + 1)\\n \\n for elem in citations:\\n buckets[min(elem, N)] += 1\\n \\n accum = list(accumulate(buckets[1:][::-1]))[::-1] \\n compar = [accum[i] \u003e= i + 1 for i in range(N)] \\n return (compar + [0]).index(0) \\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote**!", | |
| "updationDate": 1597139118, | |
| "creationDate": 1590665829 | |
| } | |
| }, | |
| { | |
| "id": 656820, | |
| "title": "[Python] Short O(n) time\u0026space, explained", | |
| "taskUrl": "https://leetcode.com/problems/h-index", | |
| "post": { | |
| "id": 1217637, | |
| "content": "### Explanations\\nThe main trick is to count for each possible number of citations, how many times we see this number in our `citations`. Note, that if number of citations is more than total number of papers `N`, we can reduce this numer to `N` and nothing will change. Let me explain my solutoin given test example `[3,0,6,1,5]`.\\n1. We create array, which I called `buckets = [1, 1, 0, 1, 0, 2]`, where `buckets[i]` is number of papers with `i` citations if `i \u003c N` and `bucket[N]` is number of papers with `\u003e=N` citations.\\n2. Now, we create `accum` array, where `accum[0]` is number of papers with `\u003e=1` citation, `accum[1]` is number of papers with `\u003e=2` citations and so on. When we evaluate it for our example we can see, that it is equal to `accum = [4,3,3,2,2]`. Note, that we start with 1 citation, not with zero, that is why we need to use `accum[1:]` in our code.\\n3. Finally, we need to go through this array and find the bigest number `i`, for which `accum[i] \u003e= i + 1` and return `i + 1`, in our example it is equal to `3`.\\n\\n### Complexity\\nComplexity is O(n), though we traverse our data 4 times, and it is not the optimal solution. We can evaluate cumulative sums in place, and compare them in place with `i + 1` and keep the index of maximum reached so far, and interrupt when inequality `accum[i] \u003e= i + 1` does not hold anymore. Howerer I like cumulative sums and code is more clean in my way.\\n\\n### Code\\n\\n```\\nclass Solution:\\n def hIndex(self, citations):\\n N = len(citations)\\n buckets = [0] * (N + 1)\\n \\n for elem in citations:\\n buckets[min(elem, N)] += 1\\n \\n accum = list(accumulate(buckets[1:][::-1]))[::-1] \\n compar = [accum[i] \u003e= i + 1 for i in range(N)] \\n return (compar + [0]).index(0) \\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote**!", | |
| "updationDate": 1597139118, | |
| "creationDate": 1590665829 | |
| } | |
| }, | |
| { | |
| "id": 693380, | |
| "title": "[Python] 2 Solutions: binary search O(log n) and Oneliner O(n), explained", | |
| "taskUrl": "https://leetcode.com/problems/h-index-ii", | |
| "post": { | |
| "id": 1281073, | |
| "content": "### Binary search\\nIn this problem data is already sorted for you, so we should take advantage of it. What you think what you need to search in sorted data? The answer is **binary search**. Of course you can not apply it like this, you need to adapt it to our problem. Let us start with example `[1,3,3,3,4,4,7]` and then consider general case. \\n\\n`......X`\\n`......X`\\n`......X`\\n`....XXX`\\n`.XXXXXX`\\n`.XXXXXX`\\n`XXXXXXX`\\n\\nWhat is the answer fo this data? It is `3`, because there is `3` publications with at least `3` citations:\\n\\n`......X`\\n`......X`\\n`......X`\\n`....XXX`\\n`.XXXOOO`\\n`.XXXOOO`\\n`XXXXOOO`\\n\\nI denoted found elements as `O`. We can see, that what we actually need to find, is the size of biggest **square** which is inside our sorted data. Mathematically speaking, we look for smallest index `i`, such that `i + citations[i] \u003e= n` and then we return `n-i`. In our example `n=7`, `i = 4` and answer is `7 - 4 = 3`. How we find this smallest index `i`? Using **binary search** of course, because sequence `i + citations[i]` is non-decreasing.\\n\\nWe can not use `bisect` library here, because for this we need to calculate `i + citations[i]` for every `i`, which can be done only in `O(n)`, so we need to apply vanila binary search by hands.\\n\\n**Complexity**: time complexity is `O(log n)` and additional space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def hIndex(self, citations):\\n if not citations: return 0\\n n = len(citations)\\n beg, end = 0, n - 1\\n while beg \u003c= end:\\n mid = (beg + end)//2\\n if mid + citations[mid] \u003e= n:\\n end = mid - 1\\n else:\\n beg = mid + 1 \\n return n - beg\\n```\\n\\n### Oneliner \\n\\nIf we do not use binary search, we can solve problem in one line, using linear search. We need to add `[0]` in the end to handle some border cases.\\n\\n```\\nclass Solution:\\n def hIndex(self, c):\\n return ([i+j\u003e=len(c) for i,j in enumerate(c)][::-1]+[0]).index(0)\\n```\\n\\nSee also my solution of **254** problem **H-Index**:\\nhttps://leetcode.com/problems/h-index/discuss/656820/Python-O(n)-timeandspace-with-explanation\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592513904, | |
| "creationDate": 1592465823 | |
| } | |
| }, | |
| { | |
| "id": 707526, | |
| "title": "[Python] Fastest O(sqrt(n)) solution with math, explanied.", | |
| "taskUrl": "https://leetcode.com/problems/perfect-squares", | |
| "post": { | |
| "id": 1305985, | |
| "content": "First of all, there is a statement that any number can be represented as sum of 4 squares:\\nhttps://en.wikipedia.org/wiki/Lagrange%27s_four-square_theorem. So, answer always will be 4? No, when we talk about `4` squares, it means that some of them can be equal to zero. So, we have `4` options: either `1`, `2`, `3` or `4` squares and we need to choose one of these numbers.\\n\\n1. How to check if number is full square? Just compare square of integer part of root and this number. Complexity of this part is `O(1)`.\\n2. How to check if number is sum of `2` squares: `n = i*i + j*j`? iterate ovell all `i \u003c sqrt(n)` and check that `n - i*i` is full square. Complexity of this part is `O(sqrt(n))`.\\n3. How to check that number is sum of `4` squares? In the same link for wikipedia: \\n` by proving that a positive integer can be expressed as the sum of three squares if and only if it is not of the form 4^k(8m+7) for integers k and m`. So, what we need to do is to check this condition and return true if it fulfilled. Complexity is `O(log n)`\\n4. Do we need to check anything else? No, because we have only one options left: `3` squares.\\n\\n**Complexity**: time complexity is `O(sqrt(n))` and space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def numSquares(self, n):\\n if int(sqrt(n))**2 == n: return 1\\n for j in range(int(sqrt(n)) + 1):\\n if int(sqrt(n - j*j))**2 == n - j*j: return 2\\n \\n while n % 4 == 0: \\n n \u003e\u003e= 2\\n if n % 8 == 7: return 4\\n return 3\\n```\\n\\n**Further discussion**. What if you do not know this `4^k(8m+7)` formula on real interview? Then you need to check if number is sum of `3` squares by hands: `n = i*i + j*j + k*k` with complexity `O(n)`: we check all pairs `i,j \u003c sqrt(n)`. What if we do not know, that each number is sum of `4` squares? Then we need to check also possible sums of `4` squares with complexity `O(n sqrt(n))`.\\n\\nWe can handle our problem as **dynamic programming** one, where `dp[i]` is minumum numer of squares to get `i`. Then to evaluate `dp[i]` we need to look at all `j`, such that `j*j \u003c= i`. Complexity of this approach is `O(n sqrt(n))`.\\n\\nNote, that there is also a way to check if `n` is sum of two squares, https://en.wikipedia.org/wiki/Sum_of_two_squares_theorem, each odd prive divisor should have a form `4k + 1`, but this is a bit more difficult to check and complexity will be also `O(sqrt(n))`.\\n\\n Open question, is there solution with comlexity better than `O(sqrt(n))`. If you have ideas, let me know!\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593267168, | |
| "creationDate": 1593243154 | |
| } | |
| }, | |
| { | |
| "id": 704693, | |
| "title": "[Python] 2 solutions: Linked List Cycle, O(n) and BS, O(n log n), explained", | |
| "taskUrl": "https://leetcode.com/problems/find-the-duplicate-number", | |
| "post": { | |
| "id": 1301003, | |
| "content": "For me the main difficulty was that given tests are not clear at all: both of them have only one duplicate, however there can be examples like `2,2,2,2,3`. \\nWhy there always will be duplicate? Because of Pigeonhole principle! Actually, it can be proven very easily: let us assume that it not correct: it means, that each number between `1` and `n` can have frequency only `0` of `1`. It means, that there will be `\u003c= n` numbers, but we need to have `n+1`. Contradiction: so, our assumption is correct: there will be at least one duplicate number.\\n\\nOne way to handle this problem is to sort data with `O(n log n)` time and `O(n)` memory or use hash table. Howerer it violates the conditions of problem: we can not use extra memory. There is smarter way and we need to use the fact that each integer is **between 1 and n**, which we did not use in sort.\\n\\nLet us deal our list as linked list, where `i` is connected with `nums[i]`.\\nConsider example `6, 2, 4, 1, 3, 2, 5, 2`. Then we have the following singly-linked list:\\n`0 -\u003e 6 -\u003e 5 -\u003e` **2** `-\u003e 4 -\u003e 3 -\u003e 1 -\u003e` **2** `-\u003e ...` \\nWe start with index **0**, look what is inside? it is number `6`, so we look at index number **6**, what is inside? Number **5** and so on. Look at the image below for better understanding.\\nSo the goal is to find loop in this linkes list. Why there will be always loop? Because `nums[1] = nums[5]` in our case, and similarly there will be always duplicate, and it is given that it is only one.\\n\\n\\n\\n\\n\\n\\n\\nSo now, the problem is to find the starting point of loop in singly-linked list (**problem 142**), which has a classical solution with two pointers: slow which moves one step at a time and fast, which moves two times at a time. To find this place we need to do it in two iterations: first we wait until fast pointer gains slow pointer and then we move slow pointer to the start and run them with the same speed and wait until they concide.\\n\\n**Complexity**: Time complexity is `O(n)`, because we potentially can traverse all list. Space complexity is `O(1)`, because we actually do not use any extra space: our linked list is **virtual**.\\n\\n```\\nclass Solution:\\n def findDuplicate(self, nums):\\n slow, fast = nums[0], nums[0]\\n while True:\\n slow, fast = nums[slow], nums[nums[fast]]\\n if slow == fast: break\\n \\n slow = nums[0];\\n while slow != fast:\\n slow, fast = nums[slow], nums[fast]\\n return slow\\n```\\n\\n### Binary search solution\\n\\nThere is **Binary Search** solution with time complexity `O(n log n)` and space complexity `O(1)`. We have numbers from `1` to `n`. Let us choose middle element `m = n//2` and count number of elements in list, which are less or equal than `m`. If we have `m+1` of them it means we need to search for duplicate in `[1,m]` range, else in `[m+1,n]` range. Each time we reduce searching range twice, but each time we go over **all** data. So overall complexity is `O(n log n)`. \\n\\n```\\nclass Solution(object):\\n def findDuplicate(self, nums):\\n beg, end = 1, len(nums)-1\\n \\n while beg + 1 \u003c= end:\\n mid, count = (beg + end)//2, 0\\n for num in nums:\\n if num \u003c= mid: count += 1 \\n if count \u003c= mid:\\n beg = mid + 1\\n else:\\n end = mid\\n return end\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593102882, | |
| "creationDate": 1593070725 | |
| } | |
| }, | |
| { | |
| "id": 833961, | |
| "title": "[Python] 2 hash-tables, explained", | |
| "taskUrl": "https://leetcode.com/problems/word-pattern", | |
| "post": { | |
| "id": 1524214, | |
| "content": "Pretty straightforward problem, where we need to just try to do what is asked. We need to check if our strings follow the pattern, so let us try to create this pattern and make sure that we do not have conflicts.\\n\\n1. Split our string into `words`, so now we have list of words.\\n2. Check if length of `words` is equal to length of `pattern` and if not, immediatly return `False`.\\n3. Now, iterate one by one elements from `pattern` and `words`: let us keep two dictionaries: one is for correspondences `word -\u003e letter` and another for `letter -\u003e word`. Check if we already have `symb` in `d_symb`:\\n\\ta. If we do not have it, but it happen that our `word` is already occupied, we return `False`, we have a conflict.\\n\\tb. If word is not occupied, we create two connections: one for `d_symb` and one for `d_word`.\\n\\tc. Finally, if `symb` is already in our `d_symb`, but `word` is not the one we expect to see, we return `False`.\\n4. If we reached the end and did not return `False`, it means that we did not have any conflicts, so we need to return `True`.\\n\\n**Complexity**: time complexity is `O(n + m)`, where `n` is number of symbols in `pattern` and `m` is total number of symbols in `s`. Space complexity is `O(k)`, where `k` is total length of all unique words.\\n\\n```\\nclass Solution:\\n def wordPattern(self, pattern, s):\\n d_symb, d_word, words = {}, {}, s.split()\\n if len(words) != len(pattern): return False\\n for symb, word in zip(pattern, words):\\n if symb not in d_symb:\\n if word in d_word: return False\\n else:\\n d_symb[symb] = word\\n d_word[word] = symb\\n elif d_symb[symb] != word: return False\\n return True\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599465133, | |
| "creationDate": 1599465133 | |
| } | |
| }, | |
| { | |
| "id": 839444, | |
| "title": "[Python] Simple solution with counters, explained", | |
| "taskUrl": "https://leetcode.com/problems/bulls-and-cows", | |
| "post": { | |
| "id": 1533400, | |
| "content": "Easy, but interesting problem, because it can be solved in different ways.\\n\\n1. Let us first evaluate number of bulls `B`: by definition it is number of places with the same digit in `secret` and `guess`: so let us just traverse our strings and count it.\\n2. Now, let us evaluate both number of cows and bulls: `B_C`: we need to count each digit in `secret` and in `guess` and choose the smallest of these two numbers. Evaluate sum for each digit.\\n3. Finally, number of cows will be `B_C - B`, so we just return return the answer!\\n\\n**Complexity**: both time and space complexity is `O(1)`. Imagine, that we have not `4` lengths, but `n`, then we have `O(n)` time complexity and `O(10)` space complexity to keep our counters.\\n\\n```\\nclass Solution:\\n def getHint(self, secret, guess):\\n B = sum([x==y for x,y in zip(secret, guess)])\\n\\t\\tCount_sec = Counter(secret)\\n Count_gue = Counter(guess)\\n B_C = sum([min(Count_sec[elem], Count_gue[elem]) for elem in Count_sec])\\n return str(B) + \"A\" + str(B_C-B) + \"B\"\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599722262, | |
| "creationDate": 1599722262 | |
| } | |
| }, | |
| { | |
| "id": 667975, | |
| "title": "[Python] 3 Lines, dp with binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/longest-increasing-subsequence", | |
| "post": { | |
| "id": 1236295, | |
| "content": "Let us keep in table `dp[i]` the minumum value so far, which is the end of increasing sequence of length `i + 1`. It can be not easy to digest, so let us go through example `nums = [100, 9, 2, 9, 3, 7, 101, 6]`.\\n1. `dp = [100]`, because `dp` was empty, and there is nothig we can compare with.\\n2. `dp = [9]` now, why? Because so far we found ony increasing subsequences with length 1 and we update `dp[0]`.\\n3. `dp = [2]` for the same reason.\\n4. `dp = [2, 9]`, because new element is **greater** than the last element in our table, it means we can create increasing sequence of length 2.\\n5. `dp = [2, 3]`, because new element is 3, and we are looking for the smallest index in our table, such that value is more than `3`, so we update `9` to `3`: we found increasing subsequence of size 2, which ends with 3 \u003c 9.\\n6. `dp = [2, 3, 7]`, because new element is more than the last element.\\n7. `dp = [2, 3, 7, 101]`, the same reason.\\n8. `dp = [2, 3, 6, 101]`, because for new element 6 we looking for the smallest index in our table, such that value is more than `6`, so we change element with value 7 to value 6.\\n\\nFinally, answer is equal to 4, the length of `dp`. (note, that `2, 3, 6, 101` **is not** increasing subsequence, this values mean, that `2` is the minimum value for increasing subsequence of lentgh 1, `3` is the minumum value for increasing subsequence of length 2 and so on)\\n\\n**Complexity** is `O(n log n)`, because for each new element we need to do binary search in `O(log n)`, and we do `n` steps.\\n\\n\\n**Code.** Here is staightforward code, which does exactly what I explained before.\\n\\n```\\nclass Solution:\\n def lengthOfLIS(self, nums):\\n dp = []\\n for elem in nums:\\n ind = bisect_left(dp, elem)\\n if ind == len(dp):\\n dp.append(elem)\\n else:\\n dp[ind] = elem\\n return len(dp)\\n```\\n\\n**3 lines code**: we can prefill our `dp` table with big numbers, in this way, we can directly update index and not being afraid to out-of-bounds indexes\\n\\n```\\nclass Solution:\\n def lengthOfLIS(self, nums):\\n dp = [10**10] * (len(nums) + 1)\\n for elem in nums: dp[bisect_left(dp, elem)] = elem \\n return dp.index(10**10)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591178517, | |
| "creationDate": 1591178517 | |
| } | |
| }, | |
| { | |
| "id": 761720, | |
| "title": "[Python] dp O(n) solution, using differences, explained", | |
| "taskUrl": "https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown", | |
| "post": { | |
| "id": 1399650, | |
| "content": "For all this buy and sell stocks problems I prefer to use **differences** array. For example, if you have `[1,2,3,1,4]`, then we have `[1, 1, -2, 3]` differences. Then the goal is to take as many of subarrays (with adjacent elements) with biggest sum, such that there is not gap with size `1`. For example, for given differences, we **can not** take `[1,1]` and `[3]`, but we can take `[1]` and `[3]`, so the answer will be `4`.\\n\\nLet `n` be number of elements in `prices`, than there will be `n-1` elements in `diff` array. Let us create `dp` and `dp_max` arrays with `n+1` elements, that is two extra elements, such that \\n\\n1. `dp[i]` is maximum gain for first `i` elements of `diff`, where we use `i`-th element\\n2. `dp_max[i]` is maximum gain for first `i` elements of `diff` (we can use `i` and we can not use it).\\n\\nNow, we can do the following steps:\\n\\n1. `dp[i] = diff[i] + max(dp_max[i-3], dp[i-1])`, because, first of all we need to use `i`, so we take `diff[i]`. Now we have two options: skip `2` elements and take `dp_max[i-3]`, or do not skip anything and take `dp[i-1]`.\\n2. Update `dp_max[i] = max(dp_max[i-1], dp[i])`, standard way to update maximum.\\n3. Finally, we added `2` extra elements to `dp` and `dp_max`, so instead of `dp_max[-1]` we need to return `dp_max[-3]`.\\n\\n**Complexity**: both time and space complexity is `O(n)`. Space complexity can be improved to `O(1)`, because we look only `3` elements to the back.\\n\\n```\\nclass Solution:\\n def maxProfit(self, prices):\\n n = len(prices)\\n if n \u003c= 1: return 0\\n \\n diff = [prices[i+1] - prices[i] for i in range(n-1)]\\n dp, dp_max = [0]*(n + 1), [0]*(n + 1)\\n for i in range(n-1):\\n dp[i] = diff[i] + max(dp_max[i-3], dp[i-1])\\n dp_max[i] = max(dp_max[i-1], dp[i])\\n \\n return dp_max[-3]\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1596008137, | |
| "creationDate": 1596008052 | |
| } | |
| }, | |
| { | |
| "id": 923071, | |
| "title": "[Python] Find diameter, using 2 dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-height-trees", | |
| "post": { | |
| "id": 1680157, | |
| "content": "Actually, what we need to find in this problem is diameter of our tree: two nodes, that have the biggest distance between them. How we can do it? There is two-stage dfs algorighm to do it:\\n\\n1. Start from any node and run `dfs`, which calculate distances for all other nodes from this node as well as create parent for each node. What our fucntion will return in the end is the index of farthest node (there can be more than one and it is OK for us).\\n2. Now, we need to start our `dfs` all over again from this node (that is why we use `dfs_helper` function - we need to clean our distances and parents arrays. When we run our dfs second time, we again find the farthest node.\\n3. Finally, we create path between the first node we found and the second and it will be our diameter: if it has even number of nodes, we return `2` middle nodes, in other case we return `1` middle node.\\n\\n**Complexity**: time complexity is `O(n)`, because we use our `dfs` twice. Space complexity is `O(n)` as well.\\n\\n```\\nclass Solution:\\n def findMinHeightTrees(self, n, edges):\\n def dfs_helper(start, n):\\n self.dist, self.parent = [-1]*n, [-1]*n\\n self.dist[start] = 0\\n dfs(start)\\n return self.dist.index(max(self.dist))\\n \\n def dfs(start):\\n for neib in Graph[start]:\\n if self.dist[neib] == -1:\\n self.dist[neib] = self.dist[start] + 1\\n self.parent[neib] = start\\n dfs(neib)\\n \\n Graph = defaultdict(set)\\n for a,b in edges:\\n Graph[a].add(b)\\n Graph[b].add(a)\\n \\n ind = dfs_helper(0,n)\\n ind2 = dfs_helper(ind, n)\\n \\n path = []\\n while ind2 != -1:\\n path.append(ind2) #backtracking to create path\\n ind2 = self.parent[ind2]\\n \\n Q = len(path)\\n return list(set([path[Q//2], path[(Q-1)//2]]))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604481778, | |
| "creationDate": 1604481778 | |
| } | |
| }, | |
| { | |
| "id": 970727, | |
| "title": "[Python] 5 lines dp, explained", | |
| "taskUrl": "https://leetcode.com/problems/burst-balloons", | |
| "post": { | |
| "id": 1762722, | |
| "content": "This is quite difficult problem! Let us consider `dp[i][j]` the maximum number of coins we can get, popping balls from `i` to `j`, **not including** `i` and `j`. Why it is enough to keep these values? Let us look at the **last** popped balloon with number `k`. Then our balloons are separated into two groups: to the left of this balloon and the the right and we can write:\\n \\n`dp[i][j] = max(nums[i] * nums[k] * nums[j] + dp[i][k] + dp[k][j]) for k in (i+1,j)`, \\n\\nwhere `k` is the index of the last balloon burst in `(i, j)`. \\n\\n**Complexity**: time complexity is `O(n^3)` and space complexity is `O(n^2)`.\\n\\nYou can see that code is very short, but it is in my opinion very diffucult to find this solution. How you can think in problems like this? First of all we are given, that `n\u003c500`, which is quite small and we can try to understand what complexity we can expect. It is for sure not `2^500`, so what is rest some polynomials and/or logarithms. So what we can expect is either `O(n^2)` or `O(n^3)`, but no more than this. So at this moment we usually have `2` choises: either greedy or dp. It is not obvious how to do greedy for me, so the choise is dp. Now we can think that repeating subproblem is what is the answer on range `(i, j)`. However the last step is something you can not invent quickly if you do not have experience in these type of problems. I can give you only intuition here: it is good idea to look at some **extremal** characteristic here: by this word I mean some object, which is either first/last, biggest/smallest and so on. Here our characteristic is **last** popped ballon on range, not the **first** we expect in simpler dp problems. Once you understand this logic, some other problems similar to this will be slightly simpler.\\n\\n**664** Strange Printer\\n**546** Remove Boxes\\n**1000** Minimum Cost to Merge Stones\\n\\n```\\nclass Solution:\\n def maxCoins(self, nums):\\n A = [1] + nums + [1]\\n \\n @lru_cache(None)\\n def dfs(i, j):\\n return max([A[i]*A[k]*A[j] + dfs(i,k) + dfs(k,j) for k in range(i+1, j)] or [0])\\n \\n return dfs(0, len(A) - 1)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607853008, | |
| "creationDate": 1607853008 | |
| } | |
| }, | |
| { | |
| "id": 889477, | |
| "title": "[Python] O(n) greedy with stack, explained", | |
| "taskUrl": "https://leetcode.com/problems/remove-duplicate-letters", | |
| "post": { | |
| "id": 1621107, | |
| "content": "Let us try to build our answer in greedy way: we take letter by letter and put them into stack: if we have next letter which decreased lexicographical order of string, we remove it from stack and put new letter. However we need to be careful: if we remove some letter from stack and it was the last occurence, then we failed: we can not finish this process. So, we need to do the following:\\n\\n1. Find `last_occ`: last occurences for each letter in our string\\n2. Initialize our `stack` either as empty or with symbol, which is less than any letter (\\'!\\' in my case), so we do not need to deal with the case of empty stack. Also initialize `Visited` as empty set.\\n3. Iterate over our string and if we already have symbol in `Visited`, we just continue.\\n4. Then, we try to remove elements from the top of our stack: we do it, if new symbol is less than previous and also if last occurence of last symbol is more than `i`: it means that we have removed symbol later in our string, so if we remove it we will not fail to constract full string.\\n5. Append new symbol to our stack and mark it as visited.\\n6. Finally, return string built from our stack.\\n\\n**Complexity**: Time complexity is `O(n)`, because we iterate our string once. Space complexity is `O(26)`, because it will be the longest size of our stack and answer.\\n\\n```\\nclass Solution:\\n def removeDuplicateLetters(self, s):\\n last_occ = {c: i for i, c in enumerate(s)}\\n stack = [\"!\"]\\n Visited = set()\\n \\n for i, symbol in enumerate(s):\\n if symbol in Visited: continue\\n \\n while (symbol \u003c stack[-1] and last_occ[stack[-1]] \u003e i):\\n Visited.remove(stack.pop())\\n \\n stack.append(symbol)\\n Visited.add(symbol) \\n return \"\".join(stack)[1:]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602404699, | |
| "creationDate": 1602404699 | |
| } | |
| }, | |
| { | |
| "id": 709590, | |
| "title": "[Python] Short, Euler Path Finding, O(E log E), explained.", | |
| "taskUrl": "https://leetcode.com/problems/reconstruct-itinerary", | |
| "post": { | |
| "id": 1309529, | |
| "content": "Actually, in this problem we are asked to find Euler path, smallest lexically. There is classical algorithm with complexity `O(E)`. Starting from the starting vertex `v`, we build a path by adding at each step an edge that has not yet been passed and is adjacent to the current vertex. The vertices of the path are accumulated in stack `S`. When the moment comes when for the current node `w` all the incident edges have already passed, we write the vertices from `S` in output until we meet the node where the incident has not passed yet edges. Then we continue our traversal of the unattended edges. It can be written both with recursion or with stack, recursion version is shorter.\\n\\nHere is a link, where you can plunge deeper into this:\\nhttp://www.graph-magics.com/articles/euler.php\\n\\nIf you neves saw this problem and even if you know what **Euler path** is, I think it is almost impossible to invent this algorighm by yourself, and this problem should be marked as **hard**.\\n\\n**Complexity**: time and space complexity of usual Euler Path Finding algorighm is `O(E+V) = O(E)`, because we traverse each edge only once and number of edges is more than number of vertixes - 1 in Eulerian graph. However as @ainkartik203 mentioned, here we sort our list for every node, so complexity will be `O(E log E)`.\\n\\n```\\nclass Solution:\\n def dfs(self, airport):\\n while self.adj_list[airport]:\\n candidate = self.adj_list[airport].pop()\\n self.dfs(candidate)\\n self.route.append(airport)\\n \\n def findItinerary(self, tickets):\\n self.route = []\\n self.adj_list = defaultdict(list)\\n for i,j in tickets:\\n self.adj_list[i].append(j)\\n for key in self.adj_list: \\n self.adj_list[key] = sorted(self.adj_list[key], reverse=True)\\n \\n self.dfs(\"JFK\")\\n return self.route[::-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593341657, | |
| "creationDate": 1593331860 | |
| } | |
| }, | |
| { | |
| "id": 976393, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/increasing-triplet-subsequence", | |
| "post": { | |
| "id": 1772544, | |
| "content": "This problem is special case of problem **300 Longest Increasing Subsequence**, but here we are asked if this length is more or equal to `3`. Let us use the same logic here: we keep two-elements array `a`, where:\\n1. `a[0]` is the smallest end among all increasing subsequences of length `1`.\\n2. `a[1]` is smallest end among all increasing subsequences of length `2`. Note, that `a[1] \u003e= a[0]` always.\\n\\nWe iterate over `nums` and check conditions: if `elem \u003c a[0]`, we can create `1` elements increasing subsecuense with smaller end. If `a[0] \u003c elem \u003c a[1]`, we can update increasing subsequence of size `2`. In other case we found subsequnce of length `3` and we can return `True`.\\n\\n**Complexity**: time complexity is `O(n)`: we iterate over our data once. Space complexity is `O(1)`.\\n\\n**Remark**: see my solution of problem **300 Longest Increasing Subsequence**: https://leetcode.com/problems/longest-increasing-subsequence/discuss/667975/Python-3-Lines-dp-with-binary-search-explained\\n\\n```\\nclass Solution:\\n def increasingTriplet(self, nums):\\n a = [float(\"inf\")]*2\\n for elem in nums:\\n if elem \u003c a[0] : a[0] = elem\\n if elem \u003c a[1] and elem \u003e a[0]: a[1] = elem\\n if elem \u003e a[1] : return True\\n return False\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608284330, | |
| "creationDate": 1608284330 | |
| } | |
| }, | |
| { | |
| "id": 946176, | |
| "title": "[Python] very short dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/house-robber-iii", | |
| "post": { | |
| "id": 1720207, | |
| "content": "If you already solved House Robber I or II, you probably aware, that this problem is about dp. However, let us look at it from a bit different point of view, it will be much easier to digest: let us use dfs and for each node we will keep two values:\\n1. Maximum gain we can get if we already visited all subtree given node, if we rob given node.\\n2. Maximum gain, we can get if we already visited all subtree given node, if we do not rob given node.\\n\\nHow we can find it, using recursion now?\\nImagine, that we have `node` and `L` and `R` are left and right children. Then:\\n1. If we rob given node, than we can not rob children, so answer will be `node.val + L[1] + R[1]`\\n2. If we do not rob house, we have two options for `L` and two options for `R`, and we choose the best ones, so we have `max(L) + max(R)`.\\n\\n**Complexity**: time complexity is `O(n)`, because we visit all our tree. Space complexity is `O(h)`, because we use recursion.\\n\\n```\\nclass Solution:\\n def rob(self, root):\\n def dfs(node):\\n if not node: return [0, 0]\\n L = dfs(node.left)\\n R = dfs(node.right)\\n return [node.val + L[1] + R[1], max(L) + max(R)]\\n \\n return max(dfs(root))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606137600, | |
| "creationDate": 1606119638 | |
| } | |
| }, | |
| { | |
| "id": 656539, | |
| "title": "[Python] Clean dp solution O(n), beats 99% with explanations.", | |
| "taskUrl": "https://leetcode.com/problems/counting-bits", | |
| "post": { | |
| "id": 1217158, | |
| "content": "This problem is to combine dynamic programming and bit manipulations.\\nLet us consider the example of `n = 13`. First create `dp` table and fill it with zeros. Then:\\n1. Number `1 = 1` we can say, that it have 1 non-zero bit. \\n2. Numbers `2 = 10, 3 = 11` have two digits in binary representation and first of them is equal to `1`, so to count number of non-zero bits in this numbers, we subtract `2` from them and look into cells `0 = 00` and `1 = 01` of our table.\\n3. Numbers `4 = 100, 5 = 101, 6 = 110, 7 = 111` have three digits in binary representation, so we need to look into cells `0 = 000, 1 = 001, 2 = 010` and `3 = 001`.\\n4. Finally for numbers `8 = 1000, 9 = 1001, 10 = 1010, 11 = 1011, 12 = 1100, 13 = 1101` we look into cells `0 = 0000, 1 = 0001, 2 = 0010, 3 = 0011, 4 = 0100, 5 = 0101`. Note, that we need to interrupt earlier here, because we reached the end of our list.\\n\\n**Complexity** We build our table in such way, that we do it in `O(1)` for each cell. So, both time and memory is `O(n)`.\\n\\n```\\nclass Solution:\\n def countBits(self, num):\\n dp = [0] * (num + 1)\\n for pow in range(0, 32):\\n start, end = 1\u003c\u003cpow, 1\u003c\u003c(pow + 1)\\n if start \u003e num: break\\n\\n for j in range(start, min(num+1,end)):\\n dp[j] = dp[j-start] + 1\\n return dp \\n```", | |
| "updationDate": 1590652889, | |
| "creationDate": 1590651414 | |
| } | |
| }, | |
| { | |
| "id": 772269, | |
| "title": "[Python] O(1) oneliner solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/power-of-four", | |
| "post": { | |
| "id": 1417703, | |
| "content": "How we can check that number is power of `4`? Straightforward algorithm is to try to divide it by `4` and check if we have `1` after several divisions, but complexity of this approach will be `O(log n)`. There is smarter way. To check that number is power of `4`, we need to check `3` conditions:\\n\\n1. Number is positive.\\n2. Number is power of `2`.\\n3. This power of `2` is even power.\\n\\nFirst condition is trivial. For the second condition we can use `x\u0026(x-1)` trick, which removes the last significant bit of binary representation, for example `11010 \u0026 11001 = 11000`. Number is power of two if it have only one significant bit, that is after this operation it must be equal to zero.\\n\\nThe last part is a bit tricky. Hopefully if reached this step, we already know, that number is a power of `2`, so we have not a lot of options left: `1`, `10`, `100`, `1000`, ... How we can distinguish one half of them (odd powers) from another half? The trick is to use binary mask `m = 1010101010101010101010101010101`. For even powers of `2` we have for example `m\u0026100 = 100`, if we use odd power, for example `m\u00261000 = 0`.\\n\\n**Complexity**: both time and space is `O(1)`, and this is honest `O(1)`, not `O(32)` or `O(16)`.\\n\\n```\\nclass Solution:\\n def isPowerOfFour(self, num):\\n return num \u003e 0 and num \u0026 (num-1) == 0 and 0b1010101010101010101010101010101 \u0026 num == num \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596530324, | |
| "creationDate": 1596525712 | |
| } | |
| }, | |
| { | |
| "id": 669571, | |
| "title": "[Python] Oneliner, two pointers explained", | |
| "taskUrl": "https://leetcode.com/problems/reverse-string", | |
| "post": { | |
| "id": 1238939, | |
| "content": "It is very tempting in Python just to use `reverse()` function, but I think it is not fully honest solution. \\nInstead, we go from the start and the end of the string and swap pair of elements. One thing, that we need to do is to stop at the middle of our string. We can see this as simplified version of **two points** approach, because each step we increase one of them and decrease another.\\n\\n**Complexity**: Time complexity is `O(n)` and additional space is `O(1)`.\\n\\n```\\nclass Solution:\\n def reverseString(self, s):\\n for i in range(len(s)//2): s[i], s[-i-1] = s[-i-1], s[i]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591255147, | |
| "creationDate": 1591254825 | |
| } | |
| }, | |
| { | |
| "id": 740374, | |
| "title": "[Python] 5 lines O(n) buckets solution, explained.", | |
| "taskUrl": "https://leetcode.com/problems/top-k-frequent-elements", | |
| "post": { | |
| "id": 1363413, | |
| "content": "There are solution, using quickselect with `O(n)` complexity in average, but I think they are overcomplicated: actually, there is `O(n)` solution, using **bucket sort**. The idea, is that frequency of any element can not be more than `n`. So, the plan is the following:\\n\\n1. Create list of empty lists for bucktes: for frequencies `1`, `2`, ..., `n`.\\n2. Use `Counter` to count frequencies of elements in `nums`\\n3. Iterate over our Counter and add elements to corresponding buckets.\\n4. `buckets` is list of lists now, create one big list out of it.\\n5. Finally, take the `k` last elements from this list, these elements will be top K frequent elements.\\n\\n**Complexity**: time complexity is `O(n)`, because we first iterate over `nums` once and create buckets, then we flatten list of lists with total number of elements `O(n)` and finally we return last `k` elements. Space complexity is also `O(n)`.\\n\\n```\\nclass Solution:\\n def topKFrequent(self, nums, k):\\n bucket = [[] for _ in range(len(nums) + 1)]\\n Count = Counter(nums).items() \\n for num, freq in Count: bucket[freq].append(num) \\n flat_list = list(chain(*bucket))\\n return flat_list[::-1][:k]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594970975, | |
| "creationDate": 1594970975 | |
| } | |
| }, | |
| { | |
| "id": 684738, | |
| "title": "[Python] Short DP with O(n^2) explained (update)", | |
| "taskUrl": "https://leetcode.com/problems/largest-divisible-subset", | |
| "post": { | |
| "id": 1265115, | |
| "content": "First of all, notice, that if we need to find `3` numbers given properties, than if we put then in decreasing order `a \u003e b \u003e c`, than it is sufficient and enough that `a%b = 0` and `b%c=0`, then it is automatically `a%c=0`. \\n\\nLet us know sort our number and in `sol[i]` list keep the best solution, where the biggest number is equal to `nums[i]`. How can we find it? Look at all smaller numbers and if `nums[i]` is divisible by this smaller number, we can update solution. Let us go through example: `nums = [4,5,8,12,16,20].`\\n1. `sol[0] = [4]`, the biggest divisible subset has size `1`.\\n2. `sol[1] = [5]`, because `5 % 4 != 0`.\\n3. `sol[2] = [4,8]`, because `8 % 4 = 0`.\\n4. `sol[3] = [4,12]`, because `12 % 4 = 0`. \\n5. `sol[4] = [4,8,16]`, because `16 % 8 = 0` and `16 % 4 = 0` and we choose `8`, because it has longer set.\\n6. `sol[5] = [4,20]` (or `[5,20]` in fact, but it does not matter). We take `[4,20]`, because it has the biggest length and when we see `5`, we do not update it.\\n7. Finally, answer is `[4,8,16]`.\\n\\n\\n**Complexity**: time complexity is `O(n^2)`, because we fist sort our numbers and then we have double loop. Space complexity also potentially `O(n^2)`, but for big `n`, length of the longest subset will not be more than `32`: (each time you new number will be at least twice bigger than previous, so there will be maximum 32 numbers in our set) so so we can say it is `O(32n)`.\\n\\n### Possible improvements\\nNote similarity of this problem with problem **300 Longest Increasing Subsequence**, however it is different, and we can not apply `O(n log n)` algorighm here directly, when we add new number we can not use binary search.\\nThere is idea by **@yanrucheng** with comlexity `O(nlogn + n*sqrt(V))`, where `V` is the biggest number. I am interested, if there is `O(n log n)` solution here? If you know such method please let me know!\\n\\n\\n```\\nclass Solution:\\n def largestDivisibleSubset(self, nums):\\n if len(nums) == 0: return []\\n nums.sort()\\n sol = [[num] for num in nums]\\n for i in range(len(nums)):\\n for j in range(i):\\n if nums[i] % nums[j] == 0 and len(sol[i]) \u003c len(sol[j]) + 1:\\n sol[i] = sol[j] + [nums[i]]\\n return max(sol, key=len)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592053018, | |
| "creationDate": 1592034168 | |
| } | |
| }, | |
| { | |
| "id": 683267, | |
| "title": "[Python] O(1) using two hash-tables, beats 97% explained", | |
| "taskUrl": "https://leetcode.com/problems/insert-delete-getrandom-o1", | |
| "post": { | |
| "id": 1262725, | |
| "content": "My idea for this problem to achieve `O(1)` complexity for all three operation is to use 2 dictionaries: I called them direct dictionary `dic_direct` and inverse dictionary `dic_invert`.\\n1. In direct dictionary we keep indexes and corresponding values: for example: `0:3`, `1:4`, `2:1` means, that we have `3` values in our dictionary: `[3,4,1]`.\\n2. In invert dictionary we keep the opposite correspondences: `3:0`, `4:1`, `1:2`. Why we need to keep two dictionaries? Because we want to search quickly both by keys and by values.\\n3. `num_elem` is to count number of elements in our set (you can avoid it, but code becomes a bit more readible).\\n\\n**Insert**. When we do insert, we first check if element is already in our invert dictionary, because we are looking for value. We do it in `O(1)`. If element is not here, we just add it to the \"end\" of our dictionaries, by this I mean, we add it with biggest existing index in dicionary, increased by `1`. For example if we want to add new element `10` into `0:3`, `1:4`, `2:1`, then we have `0:3`, `1:4`, `2:1`, `3:10`.\\n\\n**Remove:** this one is a bit more complicated. Imagine, that we want to remove element `4` from `0:3`, `1:4`, `2:1`, `3:10`. What we need to do in this case? We find it and delete first, but now we have **gap** in our indexes: `0:3`, `2:1`, `3:10`. We can easily fix it, let us take the last element and put it into our gap, so we have `0:3`, `1:10`, `2:1` now. If we do not have **gap**, that is we removed the last element, then we do not need to do this action. In any case we have `O(1)` complexity.\\n\\n**getRandom** This one is easy, we just generate random number, uniformly distributed between `0` and `1`, multiply it by number of all elements in set and evaluate `floor` function. For example if we have 5 elements, and we generated number `0.7`, then we need to choose element number `3`. Complexity is `O(1)`.\\n\\n```\\nclass RandomizedSet:\\n def __init__(self):\\n self.dic_direct = {}\\n self.dic_invert = {}\\n self.num_elem = 0\\n \\n def insert(self, val: int) -\u003e bool:\\n if val in self.dic_invert:\\n return False\\n else:\\n self.dic_invert[val] = self.num_elem\\n self.dic_direct[self.num_elem] = val\\n self.num_elem += 1\\n return True\\n \\n def remove(self, val):\\n if val not in self.dic_invert:\\n return False\\n else:\\n ind = self.dic_invert.pop(val)\\n self.dic_direct.pop(ind)\\n if ind != self.num_elem - 1:\\n self.dic_direct[ind] = self.dic_direct[self.num_elem - 1]\\n self.dic_invert[self.dic_direct[self.num_elem - 1]] = ind\\n self.dic_direct.pop(self.num_elem - 1)\\n self.num_elem -= 1\\n return True\\n \\n def getRandom(self):\\n index = floor(random.random()*self.num_elem)\\n return self.dic_direct[index]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591955553, | |
| "creationDate": 1591951950 | |
| } | |
| }, | |
| { | |
| "id": 956872, | |
| "title": "[Python] Reservoir sampling (follow-up), explained", | |
| "taskUrl": "https://leetcode.com/problems/linked-list-random-node", | |
| "post": { | |
| "id": 1739191, | |
| "content": "Let us solve this question for follow-up question: we do not want to use additional memory here. There is specific method for this, whith is called **reservoir sampling** (actually, special case of it), which I am going to explain now. Imagine, that we have only `3` nodes in our linked list, then we do the following logic:\\n1. On the first step we either stay in first node with probability `1/2` or go to the next one also with probability `1/2`.\\n2. On the second step, we do the following: if we are in node number **1**, then we stay in this node with probability `2/3` and go to node number **2** with probability `1/3`. If we in node number **2**, then we stay in it with probability `1/3` and go to node number **3** with probability `2/3`. Why everything will be OK? There is only one way, how you can stay in node **1**, and probability is `1/2 * 2/3`. There are two cases, how you can go to node number **2**: stay on first step and go on second and go on first step and stay on second: probability will be `1/2*1/3 + 1/2*1/3 = 1/3`. Finally, probability to be in node **3** is also `1/3`.\\n\\nNow, imagine, that we already covered `n` nodes and we have probabilites: `1/n, 1/n, ..., 1/n`. Then we need to make one more step and have probabilites `1/(n+1), 1/(n+1), ... , 1/(n+1)`. How we can do it?\\n 1. If we are in the first node, we stay in it with probability `n/(n+1)` and go next with probability `1/(n+1)`.\\n\\n 2. If we are in the second node, we stay in it with probability `(n-1)/(n+1)` and go next with probability `2/(n+1)`.\\n\\n n. If we are in node `n`, we stai in it with probability `1/(n+1)` and go next with probability `n/(n+1)`.\\n\\nWhy it is working? There is only one way how you can be in node **1**: with probability `1/n* n/(n+1) = 1/(n+1)`. There is two options for node **2**, with probability `1/n*(n-1)/(n+1) + 1/n* 1/(n+1) = 1/(n+1)` and so on.\\n\\nFinally, let us go to the code: we keep `n` and `k` values: `n` is number of nodes we count in list so far and `k` is current node we are in. Each moment of time we decide if we go to next node or rest in current. If we go to next, we increase `k` by one and change our `ans` node. Increase `n` in any case.\\n\\n**Complexity**: time compexity is `O(n)` and you can not really do anything with if you are not allowed to use extra memory. Space complexity however only `O(1)`, if we do not count our input.\\n\\n```\\nclass Solution:\\n def __init__(self, head):\\n self.head = head\\n\\n def getRandom(self):\\n n, k = 1, 1\\n head, ans = self.head, self.head\\n while head.next:\\n n += 1\\n head = head.next\\n if random.random() \u003c k/n:\\n ans = ans.next\\n k += 1\\n \\n return ans.val\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606901335, | |
| "creationDate": 1606900745 | |
| } | |
| }, | |
| { | |
| "id": 678389, | |
| "title": "[Python] 3 Solutions: DP, 2 pointers \u0026 follow-up BS explained", | |
| "taskUrl": "https://leetcode.com/problems/is-subsequence", | |
| "post": { | |
| "id": 1254199, | |
| "content": "### Solution 1: dynamic programming \\nThe first solution I think when I see this problem is dynamic programming. Let `dp[i][j] = 1` if `s[:j]` is substring of `t[:i]`. How can we find it:\\n1. If `s[j] == t[i]`, then we need to search string `s[:j-1]` in `t[:i-1]`\\n2. If `s[j] != t[i]`, then we need to search string `s[:j]` in `t[:i-1]`\\n\\nHere we use also `s = \"!\" + s` trick which allows as to handle border cases with empty strings.\\n\\n**Complexity**: time and space complexity is `O(nm)`, because we need to iterate over all table once.\\n\\n```\\nclass Solution:\\n def isSubsequence(self, s, t):\\n s, t = \"!\" + s, \"!\" + t\\n m, n = len(s), len(t)\\n dp = [[0] * m for _ in range(n)] \\n for i in range(n): dp[i][0] = 1\\n \\n for i,j in product(range(1, n), range(1, m)):\\n if s[j] == t[i]:\\n dp[i][j] = dp[i-1][j-1]\\n else:\\n dp[i][j] = dp[i-1][j]\\n \\n return dp[-1][-1]\\n```\\n\\n### Solution 2: two pointers\\nYou can notice, that actually we update only one element in each row of or `dp` table, so we do a lot of job which is not neccesary. Each moment of time we need to keep only two pointers: one for stirng `s` and one for string `t`. Then if we found new symbol in string `t`, which is equal to symbol in `s`, we move two pointers by one. If we did not found, then we move onle pointer for `t`.\\n\\n**Complexity** is now only `O(n + m) = O(n)`, because we traverse both strings only once. \\n\\n```\\nclass Solution:\\n def isSubsequence(self, s, t):\\n s_i, t_i = 0, 0\\n \\n while s_i \u003c len(s) and t_i \u003c len(t):\\n s_i, t_i = s_i + (s[s_i] == t[t_i]), t_i + 1\\n \\n return s_i == len(s)\\n```\\n\\n### Solution 3: binary search for follow-up question.\\n\\nIf we have a lot strings `S1, S2, ... , Sk`, where `k` is big number we want to find faster method. Let us create for each symbol sorted list of indexes for this symbol.\\n\\n**Complexity**, both time and space of preprocessing is `O(n)`, we iterate once over our list. \\n\\n**Complexity** of one search for string `S_i` is `O(m_i)*log(n)`, where `m_i` is length of string and we have `log(n)` factor, because we potentially can have list of indexes with length `n`. So if `m` is the longest length of `S_i`, we have complexity `O(k m log n)`, when two-pointer approach has `O(k n)` complexity. So, if length of original string `n` is big and `m` is small, it is worth to use this method.\\n\\n```\\nclass Solution:\\n def isSubsequence(self, s, t):\\n places = defaultdict(list)\\n for i, symbol in enumerate(t):\\n places[symbol].append(i)\\n \\n current_place = 0\\n for symbol in s:\\n current_ind = bisect.bisect_left(places[symbol], current_place)\\n if current_ind \u003e= len(places[symbol]):\\n return False\\n current_place = places[symbol][current_ind] + 1\\n \\n return True\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591720201, | |
| "creationDate": 1591688701 | |
| } | |
| }, | |
| { | |
| "id": 941309, | |
| "title": "[Python] Stack solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/decode-string", | |
| "post": { | |
| "id": 1711744, | |
| "content": "For me it was not medium problem, more like hard, I am not very good at all these parser problems. However if you spend some time on this problem, logic will be not very difficult. The idea is to read symbol by symbol and check options:\\n\\n1. If we see digit, it means that we need to form number, so just do it: multiply already formed number by `10` and add this digit.\\n2. If we see open bracket `[`, it means, that we just right before finished to form our number: so we put it into our stack. Also we put in our stack empty string.\\n3. If we have close bracket `]`, it means that we just finished `[...]` block and what we have in our stack: on the top it is solution for what we have inside bracktes, before we have number of repetitions of this string `rep` and finally, before we have string built previously: so we concatenate `str2` and `str1 * rep`.\\n4. Finally, if we have some other symbol, that is letter, we add it the the last element of our stack.\\n\\nFor better understanding the process, let us consider example `s = 3[a5[c]]4[b]`:\\n1. `[\\'\\']` at first we have stack with empty string.\\n2. `[\\'\\', 3, \\'\\']`, open bracket: now we have stack with 3 elements: empty string, number `3` and empty string.\\n3. `[\\'\\', 3, \\'a\\']`: build our string\\n4. `[\\'\\', 3, \\'a\\', 5, \\'\\']`, open bracket: add number and empty string\\n5. `[\\'\\', 3, \\'a\\', 5, \\'c\\']` build string\\n6. `[\\'\\', 3, \\'accccc\\']` : now we have closing bracket, so we remove last `3` elements and put `accccc` into our stack\\n7. `[\\'acccccacccccaccccc\\']` we again have closing bracket, so we remove last `3` elements and put new one.\\n8. `[\\'acccccacccccaccccc\\', 4, \\'\\']`: open bracket, add number and empty string to stack\\n9. `[\\'acccccacccccaccccc\\', 4, \\'b\\']` build string\\n10. `[\\'acccccacccccacccccbbbb\\']` closing bracket: remove last 3 elements and put one new.\\n\\nFinally, return joined strings from our stack.\\n\\n**Complexity**: we can say, that time and space complexity is `O(m)`, where `m` is size of our answer. Potentially it can be very big, for strings like `999999999999999[a]`, but I do not think leetcode will have such tests.\\n\\n\\n```\\nclass Solution:\\n def decodeString(self, s):\\n it, num, stack = 0, 0, [\"\"]\\n while it \u003c len(s):\\n if s[it].isdigit():\\n num = num * 10 + int(s[it])\\n elif s[it] == \"[\":\\n stack.append(num)\\n num = 0\\n stack.append(\"\")\\n elif s[it] == \"]\":\\n str1 = stack.pop()\\n rep = stack.pop()\\n str2 = stack.pop()\\n stack.append(str2 + str1 * rep)\\n else:\\n stack[-1] += s[it] \\n it += 1 \\n return \"\".join(stack)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605776752, | |
| "creationDate": 1605776752 | |
| } | |
| }, | |
| { | |
| "id": 949552, | |
| "title": "[Python] sliding window solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/longest-substring-with-at-least-k-repeating-characters", | |
| "post": { | |
| "id": 1726341, | |
| "content": "First of all, be careful with this problem formulation: Given a string s and an integer k, return the length of the longest substring of s such that the frequency of each character in this substring \u003cdel\u003e**is less than or equal to k** \u003c/del\u003e: this is not correct statement, what you actually asked is **is more than or equal to k**. I spend some time figuring it out.\\n\\nNow, we will use sliding window approach to find the window of biggest length. However, it is not that easy. Imagine, that we have `s = aabbb...` and `k = 3`, what should we do when we reached window `aabbb`: should we expand it to the right hoping that we will meet another `a`? Or should we start to move left side of our window? One way to handle this problem is to do several sliding windows passes, where we fix `T` number of different symbols we must have in our substring. So, we check all posible `T = 1, ... 26` (if fact, not 26, but `len(Counter(s)) + 1)`) and do sliding window pass:\\n\\n1. Initialize `beg = 0`, `end = 0`, `Found = 0`: number of elements with frequency more or equal than `k`, `freq` is array of frequencies `= [0]*26` and `MoreEqK = 0`, which count number of non-zero frequencies in our `freq` array.\\n2. Now, we check if `MoreEqK \u003c=T` or not, that is we have `T` or less different symbols in our window: then we can add element to to right part of our sliding window: we increase its frequency, if this symbol is new, that is frequency become equal to `1`, we increment `MoreEqK`. Also, if frequency become equal to `k`, we increment `Found`.\\n3. In opposite case it means, that we already have `T+1` or more different symbols in or window, so we need to move left side of our sliding window. Again, we check if frequency was equal to `k` and if it was, we decrease `Found` by one, if frequency become equal to zero, we decrease `MoreEqK`.\\n4. Finally, if we have exactly `T` non-zero frequencies and all `T` of them more or equal than `k`, we update our `result`.\\n\\n**Complexity**: time complexity is `O(26n)`, because we can potentially have `26` passes over our data. Space complexity is `O(26)`. Yes, I understand, that `O(26n) = O(n)`, but here I want to stress that constant is quite big.\\n\\n```\\nclass Solution:\\n def longestSubstring(self, s, k):\\n result = 0\\n for T in range(1, len(Counter(s))+1):\\n beg, end, Found, freq, MoreEqK = 0, 0, 0, [0]*26, 0\\n while end \u003c len(s):\\n if MoreEqK \u003c= T:\\n s_new = ord(s[end]) - 97\\n freq[s_new] += 1\\n if freq[s_new] == 1:\\n MoreEqK += 1\\n if freq[s_new] == k:\\n Found += 1\\n end += 1\\n else:\\n symb = ord(s[beg]) - 97\\n beg += 1\\n if freq[symb] == k:\\n Found -= 1\\n freq[symb] -= 1\\n if freq[symb] == 0:\\n MoreEqK -= 1\\n \\n if MoreEqK == T and Found == T:\\n result = max(result, end - beg)\\n \\n return result\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606383042, | |
| "creationDate": 1606383042 | |
| } | |
| }, | |
| { | |
| "id": 867030, | |
| "title": "[Python] dfs O(V+E), explained", | |
| "taskUrl": "https://leetcode.com/problems/evaluate-division", | |
| "post": { | |
| "id": 1582454, | |
| "content": "First of all, if we look carefully at this problem we can see, that it is graph problem: let our variables be nodes and divistions be connections. It is also given, that there is no contradictions in this graph and divisions by zero, so we do not need to think about it. Let us use `dfs(start, comp, w)` function, with parameters:\\n1. `start` is current node(variable) we visit\\n2. `comp` number of connected component: imagine we have `x/y = 4, y/z = 3` and `a/b = 2`, then first component is `(x,y,z)` and second is `(a,b)`.\\n3. `w` is current weight or value of our node: imagine that we start with node `x`, then we have weight for `x = 1`, weight for `y = 1/4` and weight for `z = 1/12`.\\n\\nSo, what `dfs` function will do? for given `start` value it traverse our graph and check if `self.w[j][0] = -1`. We define `for var in varbs: self.w[var] = [-1,-1]` in the beginning: first value is responsible for number of connected component and second number is responsible for weight. So, if we have neighbour, which is not visited yet, we run `dfs` recursively.\\n\\nMain function: first we grab the names of all variables (nodes), using `varbs = set(chain(*equations))`, then we create defaultdict of edges: for every equation we add two connections: one for direct and one for inversed. Next we iterate over all variables and run `dfs` if this variable(node) is not visited yet.\\nFinally, we traverse `queries` and we found that one of the variables is not in `varbs` or they both are, but they are in two different connected components, we return `-1`. If it is not the case, we return division of weights.\\n\\n**Complexity**: Time complexity is `O(E+V+Q)`, where `V` is number of variables (nodes), `E` is number of equations (edges) and `Q` is number of queries, because complexity of dfs is `O(E+V)` and we also have `Q` queries. Space complexity is also `O(E+V+Q)` to keep all nodes, edges and answers for queries.\\n\\n```\\nclass Solution:\\n def dfs(self, start, comp, w):\\n self.w[start] = [comp, w]\\n for j, weight in self.edges[start]:\\n if self.w[j][0] == -1:\\n self.dfs(j, comp, w/weight)\\n \\n def calcEquation(self, equations, values, queries):\\n varbs = set(chain(*equations))\\n result, it = [], 0\\n self.edges = defaultdict(list)\\n for it, [i,j] in enumerate(equations):\\n self.edges[i].append([j, values[it]])\\n self.edges[j].append([i, 1/values[it]])\\n \\n self.w = defaultdict(list)\\n for var in varbs: self.w[var] = [-1,-1]\\n \\n for key in varbs:\\n if self.w[key][0] == -1:\\n self.dfs(key, it, 1)\\n it += 1\\n \\n for a,b in queries:\\n if a not in varbs or b not in varbs or self.w[a][0] != self.w[b][0]:\\n result.append(-1.0)\\n else:\\n result.append(self.w[a][1]/self.w[b][1])\\n \\n return result\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601275985, | |
| "creationDate": 1601196211 | |
| } | |
| }, | |
| { | |
| "id": 808977, | |
| "title": "[Python] Simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/sum-of-left-leaves", | |
| "post": { | |
| "id": 1481741, | |
| "content": "Very simple problem, where we just need to traverse our tree and find left leaves.\\n\\nLet us defint `dfs(self, root, side)`, where `root` is current node and `side` is `-1` if this node is left children of some other node and `+1` if this node is right children of some node. Then:\\n\\n1. If we reached `None` node, then we just return, we are out of tree\\n2. If current node do not have children, then we check that it is left children of some other node and if it is the case, we add its value to global `self.sum`.\\n3. Finally, run recursively `dfs` for left children with `-1` and for right children with `1`.\\n\\n**Complexity**: time complexity is `O(n)`, because we traverse every node only once. Space complexity is `O(h)`, where `h` is height of our tree.\\n\\n```\\nclass Solution:\\n def dfs(self, root, side):\\n if not root: return\\n \\n if not root.left and not root.right:\\n if side == -1: self.sum += root.val\\n \\n self.dfs(root.left, -1)\\n self.dfs(root.right, 1)\\n \\n def sumOfLeftLeaves(self, root):\\n self.sum = 0\\n self.dfs(root, 0)\\n return self.sum\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598255490, | |
| "creationDate": 1598255490 | |
| } | |
| }, | |
| { | |
| "id": 673129, | |
| "title": "[Python] O(n^2) easy to come up, detailed explanations", | |
| "taskUrl": "https://leetcode.com/problems/queue-reconstruction-by-height", | |
| "post": { | |
| "id": 1245104, | |
| "content": "The idea of my solution is following: let us find the first person in our queue, how can we do it? First, it should be a person with `k=0`, and also it should be a person with minumum height among all these people. What happened, when we found this person? We need to update values of `k` for all persons after, for which heights were less or equal than this person. However in this way we modify our data, so I use line `people = [[x,y,y] for x, y in people]` to reconstrunct our data: `0`-th index is for height, `2`-nd for modified `k` and `1`-st for original `k`.\\n\\nLet us go through example and see how it works, `people = [[7, 0], [4, 4], [7, 1], [5, 0], [6, 1], [5, 2]]`:\\n\\n1. Modify data: `[[7, 0, 0], [4, 4, 4], [7, 1, 1], [5, 0, 0], [6, 1, 1], [5, 2, 2]]`\\n2. Choose the smallest element with `k_modified = 0`: this is `[5,0,0]`: we pop this element and modify the rest: `[[7, 0, 0], [4, 4, 3], [7, 1, 1], [6, 1, 1], [5, 2, 1]]`, where we changed values of `k_modified` for `[4, 4, 4]` and `[5, 2, 2]`\\n3. Choose the smallest new element, which is `[7, 0, 0]` and modify `people = [[4, 4, 2], [7, 1, 0], [6, 1, 0], [5, 2, 0]]`\\n4. Choose the smallest new element, which is `[5, 2, 0]` and modify `people = [[4, 4, 1], [7, 1, 0], [6, 1, 0]]`\\n5. Choose the smallest new element, which is `[6, 1, 0]` and modify `people = [[4, 4, 0], [7, 1, 0]]`\\n6. Choose the smallest new element, which is `[4, 4, 0]` and modify `people = [[7, 1, 0]]`\\n7. Choose the smallest new element, which is [`7, 1, 0]` and modify `people = []`\\n\\n**Complexity.** Time complexity is `O(n^2)`, because we do `n` iterations, and find minimum and modify at most `n` elements on each iteration. Space comlexity is `O(n)`.\\n\\n\\n```\\nclass Solution:\\n def reconstructQueue(self, people):\\n people = [[x,y,y] for x, y in people]\\n \\n out = []\\n while people:\\n ind = people.index(min(people,key=lambda x: (x[2],x[0])))\\n out.append(people.pop(ind))\\n people = [[x,y,z - (x \u003c= out[-1][0])] for x,y,z in people ]\\n \\n return [[x,y] for x,y,z in out]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please\\n**Upvote!**", | |
| "updationDate": 1591447632, | |
| "creationDate": 1591435483 | |
| } | |
| }, | |
| { | |
| "id": 791032, | |
| "title": "[Python] 2 lines with counter + Oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/longest-palindrome", | |
| "post": { | |
| "id": 1449227, | |
| "content": "Note, that it every palindrome we need to use every letter `even` number of times, maybe except one letter in the middle. Note also, that this condition is also sufficient: if we have frequencies for each letter which are even and one frequence is odd, we can always create palindrome. For example let us have `aaaaaa`, `c`, `bbbb`, then we create `aaabbcbbaaa`.\\n\\nSo, all we need to do is to count frequencies of each letter and take as much letters as possible. There are two possible cases:\\n1. If we have only `zero` or `one` letters with odd frequencies, then we can use all the letters.\\n2. If we have `k\u003e1` letters with odd frequencies, we need to remove exactly `k-1` letter to build palindrome.\\n\\n**Complexity**: space complexity is `O(k)`, where `k` is size of used alphabet. Time complexity is `O(n)`, where `n` is length of our string: we process it once to get counter, then we find reminders of frequencies modulo `2` in `O(k)`.\\n\\n\\n```\\nclass Solution:\\n def longestPalindrome(self, s):\\n odds = sum([freq % 2 for _,freq in Counter(s).items()])\\n return len(s) if odds \u003c=1 else len(s) - odds + 1 \\n```\\n\\n### Oneliner\\nThe same logic can be written as oneliner\\n```return len(s) if (o:=sum([f%2 for _,f in Counter(s).items()])) \u003c=1 else len(s)-o+1```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597398718, | |
| "creationDate": 1597393277 | |
| } | |
| }, | |
| { | |
| "id": 812428, | |
| "title": "[Python] easy solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/fizz-buzz", | |
| "post": { | |
| "id": 1487750, | |
| "content": "This is very classical and old interview question and I think already a lot was discussed. Here is my solution, where we use simple approach: we iterate over numbers, check for each number what we need to add and add it. Also, for more universality I use `words = [\"Fizz\", \"Buzz\"]`, `mods = [3,5]` and `k=2`. What we do next is just iterate over numbers and for each number check if it is divisible by `3` and by `5`.\\n\\n**Complexity**: time complexity is `O(n)`, more precisely, we do `2` division checks for each number and then add result to `res`. It can be optimized, if we do not check each number, but firstly create array `[1,2,3,...,n]`, and then traverse only numbers divisible by `3` in one pass and numbers divisible by `5` in second pass. Space complexity is `O(n)` as well.\\n\\n```\\nclass Solution:\\n def fizzBuzz(self, n):\\n words, mods = [\"Fizz\", \"Buzz\"], [3, 5]\\n k, res = 2, []\\n for i in range(1, n+1):\\n current_str = \"\"\\n for j in range(k):\\n if i%mods[j] == 0: current_str += words[j]\\n \\n if not current_str:\\n res.append(str(i))\\n else:\\n res.append(current_str)\\n \\n return res\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598430042, | |
| "creationDate": 1598430042 | |
| } | |
| }, | |
| { | |
| "id": 950617, | |
| "title": "[Python] Fastest dp with bit manipulation, explained", | |
| "taskUrl": "https://leetcode.com/problems/partition-equal-subset-sum", | |
| "post": { | |
| "id": 1728260, | |
| "content": "The idea here is to use usual dp with states, but to encode them with numbers. Let me explain on small example, what I mean. Imagine, that we have numbers `A = [1,5,11,5]`, then let us start with `a = 1`:\\n\\n1. Step 1, what numbers, we can get, using only first number `1`: it is only `1`, so `a = 11`: we have onese on the places we can represent.\\n2. Step 2, what numbers we can get, using only numbers `1` and `5`: it is `1`, `5` and `6`, and `a = 1100011`\\n3. Step 3, what numbers we can get, using numbers `1`, `5`, `11`? it is `1,5,6,11,12,16,17`, so `a = 110001100001100011`, where we have ones on exactly the places which can be represented with some sum of numbers.\\n4. Step 4, we have now `a = 11000110001110001100011`\\n\\nFinally, we need to just check if we have `1` in the middle of this number or not.\\n\\n**Complexity**: time complexity is `O(N*n)`, where `N = sum(A)` and `n = len(A)`. Space complexity is `O(N)`. Note, that in practice however it will work several times faster than usual dp due to fast bit operations.\\n\\n```\\nclass Solution:\\n def canPartition(self, A):\\n a = reduce(lambda a, num: a|(a\u003c\u003cnum), A, 1)\\n return sum(A)%2 == 0 and a \u0026 (1 \u003c\u003c (sum(A)//2)) != 0\\n```\\n\\n**Update**: oneliner from **rkmd**:\\n```\\nreturn not (t := sum(A)) % 2 and reduce(lambda a, x: a | a \u003c\u003c x, A, 1) \u0026 1 \u003c\u003c t // 2\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606475555, | |
| "creationDate": 1606468098 | |
| } | |
| }, | |
| { | |
| "id": 849128, | |
| "title": "[Python] O(32n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/maximum-xor-of-two-numbers-in-an-array", | |
| "post": { | |
| "id": 1550989, | |
| "content": "Let us try to build the biggest XOR number binary digit by digit. So, the first question we are going to ask, is there two numbers, such that its XOR starts with `1......` (length is `32` bits). Howe we can find it? Let us use the idea of Problem 1: TwoSum: put all prefixes of lengh one to set and then try to find two numbers in this set such that their XOR starts with `1` (at first we have at most `2` elements in our set). Imagine that there are two numbers, which XOR starts with `1......`, then the next question is there are two numbers with XOR starts with `11.....`, we again iterate through all numbers and find two of them with `XOR` starts with `11`. It can happen that on the next step we did not find `XOR` starts with `111.....`, then we do not change our `ans` and on next step we are looking for `XOR` starts with `1101...` and so on. So:\\n\\n1. We iterate, starting from the first digit in binary representation of number and go to the right.\\n2. For each traversed digit we update our binary mask: in the beginning it is `10000...000`, then it is `11000...000`, `11100...000` and in the end `11111...111`. We need this mask to quickly extract information about first several digits of our number.\\n3. Create set of all possible starts of numbers, using `num \u0026 mask`: on the first iterations it will be first digit, on the next one first two digits and so on.\\n4. Apply TwoSum problem: if we found two numbers with `XOR` starting with `start`, then we are happy: we update our `ans` and break for inner loop: so we continue to look at the next digit.\\n\\n**Complexity**: Time complexity is `O(32n)`, because we traverse our numbers exactly `32` times. I do not like when this is called `O(n)` complexity, because we have quite big constant here. Space complexity is `O(n)`.\\n\\n\\n```\\nclass Solution:\\n def findMaximumXOR(self, nums):\\n ans, mask = 0, 0\\n for i in range(31, -1, -1):\\n mask |= 1\u003c\u003ci\\n found = set([num \u0026 mask for num in nums])\\n \\n start = ans | 1\u003c\u003ci\\n for pref in found:\\n if start^pref in found:\\n ans = start\\n break\\n \\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600246257, | |
| "creationDate": 1600246257 | |
| } | |
| }, | |
| { | |
| "id": 728266, | |
| "title": "[Python] DFS with stack, 2 solutions, exaplained", | |
| "taskUrl": "https://leetcode.com/problems/flatten-a-multilevel-doubly-linked-list", | |
| "post": { | |
| "id": 1342703, | |
| "content": "In this problem we need to traverse our multilevel doubly linked list in some special order and rebuild some connections. We can consider our list as graph, which we now need to traverse. What graph traversal algorighms do we know? We should think about dfs and bfs. Why I choose dfs? Because we need to traverse as deep as possible, before we traverse neibhour nodes, and that is what dfs do exactly! When you realise this, problem becomes much more easier. So, algorighm look like:\\n\\n1. Put `head` of our list to stack and start to traverse it: `pop` element from it and add two two elements instead: its `next` and its `child`. The order is **important**: we first want to visit `child` and then `next`, that is why we put `child` to the top of our stack.\\n2. Each time we `pop` last element from stack, I write it to auxilary `order` list.\\n3. Last step is to rebuild from our `order` list flattened doubly linked list.\\n\\n**Complexity**: time complexity is `O(n)`, where `n` is number of nodes in our list. In this approach we also use `O(n)` additional space, because I keep `order` list. This can be avoid, if we make connections on the fly, but it is a bit less intuitive in my opinion, but ofcourse more optimal in space complexity.\\n\\n```\\nclass Solution:\\n def flatten(self, head):\\n if not head: return head\\n stack, order = [head], []\\n\\n while stack:\\n last = stack.pop()\\n order.append(last)\\n if last.next:\\n stack.append(last.next)\\n if last.child:\\n stack.append(last.child)\\n \\n for i in range(len(order) - 1):\\n order[i+1].prev = order[i]\\n order[i].next = order[i+1]\\n order[i].child = None\\n \\n return order[0]\\n```\\n\\n**Solution without extra array**: the same idea, where we reconnect our nodes directly, without `order` array. It is `O(h)` in memory, where `h` is number of levels (in the worst case it will be `O(n)`).\\n\\n```\\nclass Solution(object):\\n def flatten(self, head):\\n if not head: return head\\n \\n dummy = Node(0)\\n curr, stack = dummy, [head]\\n while stack:\\n last = stack.pop() \\n if last.next:\\n stack.append(last.next)\\n if last.child:\\n stack.append(last.child)\\n curr.next = last\\n last.prev = curr \\n last.child = None\\n curr = last\\n \\n res = dummy.next\\n res.prev = None\\n return res\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594371518, | |
| "creationDate": 1594366541 | |
| } | |
| }, | |
| { | |
| "id": 793070, | |
| "title": "[Python] O(n log n) sort ends with proof, explained", | |
| "taskUrl": "https://leetcode.com/problems/non-overlapping-intervals", | |
| "post": { | |
| "id": 1452564, | |
| "content": "How you can handle this problem if you see it first time? If number of segments is small, we can try to check all possible options. However in this problem number of segments can be quite big and it is not going to work. Next options are dp or greedy approaches, that we need to check, and let us try to use greedy approach. Let us try to build the longest set of non-overlapping intevals. There are different options how we can try to choose greedy strategy:\\n\\n1. The first one strategy, which is not going to work is to sort segments by its starts, but we have counterexample here: `[1,100], [2,3], [3,4]`: we will choose only first segment, however we can choose two of them.\\n2. Another strategy is to sort segments by its ends? Why it is going to work? Let us prove it by mathematical induction: we have segments `s_1, ... , s_n` with sorted ends and we can choose `k` out of these `n` segments, such that they not overlap. We add `s_{n+1}` segment, such that its end is greater or equal than the end of `s_n`. How many segments we can choose out of our new `n+1` segments? It can not be more that `k+1`, because we can choose at most `k` out of first `n`. Also, we can choose `k+1` only in the case, when we take the last segment. When we can take the last segment? Only if it is not intersecting with segment number `n`! Because if it is intersection with some previous segment, it **must** intersect with segment number `n`: intersection of `s_{n+1}` with `s_i` means that start of `s_{n+1}` is more that end of `s_i`. and the bigger `i`, the bigger the end of `s_i`. So we always can use greedy strategy.\\n\\n**Complexity**: time complexity is `O(n log n)`, for sort all segments and space complexity is `O(n)` if we count that we use space for sorted intervals.\\n\\n```\\nclass Solution:\\n def eraseOverlapIntervals(self, intervals):\\n intervals.sort(key = lambda x: x[1])\\n n, count = len(intervals), 1\\n if n == 0: return 0\\n curr = intervals[0]\\n \\n for i in range(n):\\n if curr[1] \u003c= intervals[i][0]:\\n count += 1\\n curr = intervals[i]\\n \\n return n - count \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597493545, | |
| "creationDate": 1597493000 | |
| } | |
| }, | |
| { | |
| "id": 814463, | |
| "title": "[Python] Binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/find-right-interval", | |
| "post": { | |
| "id": 1490955, | |
| "content": "Let us look carefully at our statement: for each interval `i` we need to find interval `j`, whose start is bigger or equal to the end point of interval `i`. We can rephrase this:\\nGiven end of interval `i`, we need to find such point among starts of interval, which goes immedietly after this end of iterval `i`. How we can find this point? We can sort our intervals by starts (and hopefully there is no equal starts by statement) and then for each end of interval find desired place. Let us go through exapmle:\\n`[1,12], [2,9], [3,10], [13,14], [15,16], [16,17]` (I already sorted it by starts):\\n\\n1. Look for number `12` in `begs = [1,2,3,13,15,16]`. What place we need? It is `3`, because `12 \u003c13` and `12 \u003e 3`.\\n2. Look for number `9`, again place is `3`.\\n3. Look for number `10`, place is `3`.\\n4. Look for number `14`, place is `4`, because `13\u003c14\u003c15`.\\n5. Look for number `16`, what is place? In is `5`, because `begs[5] = 16`. Exactly for this reason we use `bisect_left`, which will deal with these cases.\\n6. Look for number `17`, what is place? it is `6`, but it means it is bigger than any number in our `begs`, so we should return `-1`.\\n\\nSo, what we do:\\n1. Sort our intervals by starts, but also we need to keep they original numbers, so I sort triplets: `[start, end, index]`.\\n2. Create array of starts, which I call `begs`.\\n3. Creaty `out` result, which filled with `-1`.\\n4. Iterate over `ints` and for every end `j`, use `bisect_left`. Check that found index `t \u003c len(begs)` and if it is, update `out[k] = ints[t][2]`. Why we update in this way, because our intervals in sorter list have different order, so we need to obtain original index.\\n\\n**Complexity**: time complexity is `O(n log n)`: both for sort and for `n` binary searches. Space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def findRightInterval(self, intervals):\\n ints = sorted([[j,k,i] for i,[j,k] in enumerate(intervals)])\\n begs = [i for i,_,_ in ints]\\n out = [-1]*len(begs)\\n for i,j,k in ints:\\n t = bisect.bisect_left(begs, j)\\n if t \u003c len(begs):\\n out[k] = ints[t][2]\\n \\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598520577, | |
| "creationDate": 1598520577 | |
| } | |
| }, | |
| { | |
| "id": 779227, | |
| "title": "[Python] dfs + hash table, using cumulative sums, explained", | |
| "taskUrl": "https://leetcode.com/problems/path-sum-iii", | |
| "post": { | |
| "id": 1429641, | |
| "content": "If we can have any solution, that this problem is indeed medium. However if we wan to have `O(n)` time solution, in my opinion it is more like hard, because we need to use dfs + hash table in the same time.\\n\\nFirst of all, let us evaluate cumulative sum of our tree, what does it mean? Here an example: for each node we evaluate sum of path from this node to root.\\n\\n\\n\\n\\nAlso we evaluate number of nodes in our tree. What we need to find now? Number of pairs of two nodes, one of them is descendant of another and difference of cumulative sums is equal to `sum`. Let me explain my `dfs(self, root, sum)` function:\\n\\n1. If we reached `None`, just go back.\\n2. We have `self.count` hash table, where we put `root.val + sum`: number we are looking for when we visited this node: for example if we are in node with value `15` now (see our example), then we want to find node with values `15+8` inside. \\n3. Also, we add to our final result number of solution for our `root.val`. \\n4. Run recursively our `dfs` for left and right children\\n5. Remove our `root.val + sum` from our hash table, because we are not anymore in `root` node.\\n\\nNow, let us consider our `pathSum(self, root, sum)` function:\\n1. If tree is empty, we return `0`\\n2. Define some global variables.\\n3. Run our `cumSum` function to evaluate cumulative sums\\n4. Run `dfs` method.\\n5. In the end we need to subtract `self.n*(sum == 0)` from our result. Why? Because if `sum = 0`, then we will count exactly `self.n` empty cumulative sums, which consist of zero elements.\\n\\n**Complexity**: Time complexity to evaluate cumulative sums is `O(n)`. The same time complexity is for `dfs` function. Space complexity is also `O(n)`, because we need to keep this amount of information in our `count` hash table.\\n\\n```\\nclass Solution:\\n def cumSum(self, root):\\n self.n += 1\\n for child in filter(None, [root.left, root.right]):\\n child.val += root.val\\n self.cumSum(child)\\n \\n def dfs(self, root, sum):\\n if not root: return None\\n \\n self.count[root.val + sum] += 1\\n self.result += self.count[root.val]\\n self.dfs(root.left, sum)\\n self.dfs(root.right, sum)\\n self.count[root.val + sum] -= 1\\n \\n def pathSum(self, root, sum):\\n if not root: return 0\\n \\n self.n, self.result, self.count = 0, 0, defaultdict(int)\\n self.cumSum(root)\\n self.count[sum] = 1\\n self.dfs(root, sum)\\n return self.result - self.n*(sum == 0) \\n```\\n\\n**Update**: thanks @rkmd for pointing out that we do not really need to evaluate cumlative sums, we can do in on the fly. Also if we do it on the fly, we do not need to check case if `sum == 0`. Here is the code:\\n\\n```\\nclass Solution:\\n def dfs(self, root, sum, root_sum):\\n if not root: return None\\n \\n root_sum += root.val\\n self.result += self.count[root_sum] \\n self.count[root_sum + sum] += 1\\n self.dfs(root.left, sum, root_sum)\\n self.dfs(root.right, sum, root_sum)\\n self.count[root_sum + sum] -= 1\\n \\n def pathSum(self, root, sum):\\n self.result, self.count = 0, defaultdict(int)\\n self.count[sum] = 1\\n self.dfs(root, sum, 0)\\n return self.result\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596888925, | |
| "creationDate": 1596872165 | |
| } | |
| }, | |
| { | |
| "id": 714130, | |
| "title": "[Python] Math oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/arranging-coins", | |
| "post": { | |
| "id": 1317340, | |
| "content": "We need `1` coin for first level, `2` coins for second level and so on. So, if we have `s` layers, we need exactly `1+2+...+s = s*(s+1)/2` coins. Reformulating problem statement, we need to find the biggest `s`, such that `s*(s+1)/2 \u003c= n` or `s^2 + s - 2n \u003c= 0.` This is quadratic inequality, and to solve it we need to find roots of `s^2 + s - 2n = 0` equation first:\\n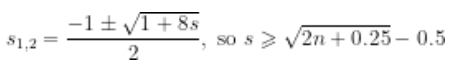\\n\\n\\n**Complexity**: both time and space is `O(1)`.\\n\\n**Other solutions**: we can do it in `O(n)` with linear search, if we just add level by level. We can also use **binary search** with `O(log n)` complexity.\\n\\n\\n```\\nclass Solution:\\n def arrangeCoins(self, n):\\n return int(sqrt(2*n + 0.25) - 0.5)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**\\n**P.S** Does anyone know how to resize images here? What I do, I just make it lower quality, but it looks not very nice.", | |
| "updationDate": 1593589528, | |
| "creationDate": 1593588286 | |
| } | |
| }, | |
| { | |
| "id": 775738, | |
| "title": "[Python] 2 solutions with O(n) time/O(1) space, explained", | |
| "taskUrl": "https://leetcode.com/problems/find-all-duplicates-in-an-array", | |
| "post": { | |
| "id": 1423727, | |
| "content": "### Solution 1: rearragne numbers\\n\\nIf we are not allowed to use additional memory, the only memory we can use is our original list `nums`. Let us try to put all numbers on they own places, by this I mean, we try to up number `k` to place `k-1.` \\nLet us iterate through numbers, and change places for pairs of them, if it is needed. Consider and example `[4, 3, 2, 7, 8, 2, 3, 1]`:\\n\\n1. We look at first number `4` and change it with number, which is on the place with number `4-1`, so we have `[7, 3, 2, 4, 8, 2, 3, 1]`, `i = 0`.\\n2. We still look at first number and now we put it to place `7-1`: `[3, 3, 2, 4, 8, 2, 7, 1]`, `i = 0`.\\n3. We still look at first number and now we put it to place `3-1`: `[2, 3, 3, 4, 8, 2, 7, 1]`, `i = 0`.\\n4. We still look at first number and now we put it to place `2-1`: `[3, 2, 3, 4, 8, 2, 7, 1]`, `i = 0`.\\nNow, if we look at first place, we see number `3`, which we need to put on place, where we already have number `3`. So, we stop with `i = 0`.\\n5. Continue with `i = 1, 2, 3` and see that number is already on its place, so we do nothin.\\n6. For `i = 4`, we do: `[3, 2, 3, 4, 1, 2, 7, 8]`.\\n7. Still, `i = 4`, we do: `[1, 2, 3, 4, 3, 2, 7, 8]`, we stop here, because `nums[4] = 3` but number `3` is already on place `3-1`.\\n8. We continue with `i = 5, 6, 7` and do nothing\\n\\nFinally, what we need to do with obtained array: find all places with **wrong** numbers and return these places, here it is numbers `3` and `2`: `[1, 2, 3, 4`, **3**, **2**, `7, 8]`.\\n\\n**Complexity**: time complexity `O(n)`, because with each swap on numbers, we put at least one of them on its place. Additional space complexity is `O(1)`.\\n\\n```\\nclass Solution(object):\\n def findDuplicates(self, nums):\\n for i in range(len(nums)):\\n while i != nums[i] - 1 and nums[i] != nums[nums[i]-1]:\\n\\t\\t\\t\\tnums[nums[i]-1], nums[i] = nums[i], nums[nums[i]-1]\\n\\n return [nums[it] for it in range(len(nums)) if it != nums[it] - 1]\\n```\\n\\n### Solution 2: hash numbers\\n\\nActually, there is more clean, but much more tricky solution, where we again change our `nums`, but in different way. Let us again go through the same example and see how it works:\\n\\n1. First, we look at number `4`, look at place number `3`, see, that number there is positive, it means, we did not met number `4` yet, so we just change sign and have: `nums = [4, 3, 2, -7, 8, 2, 3, 1]`, `ans = []`.\\n2. Similarly, we look at next number `3` and change sign of number in cell `3-1`: \\n`nums = [4, 3, -2, -7, 8, 2, 3, 1]`, `ans = []`.\\n3. Continue with next number, which is `-2` now. Number is negative, but what we are interested in is `nums[2-1]`, which is `3`, so we change its sign and have `nums = [4, -3, -2, -7, 8, 2, 3, 1]`, `ans = []`.\\n4. Next number is `-7`, so we have `nums = [4, -3, -2, -7, 8, 2, -3, 1]`, `ans = []`.\\n5. Next number is `8`, so we have `nums = [4, -3, -2, -7, 8, 2, -3, -1]`, `ans = []`.\\n6. Next number is `2`, we look at place with number `2-1 = 1` and see, that we have there negative number. It means, that we already seen number `2` before, so it is duplicate, and we add it to our answer: `nums = [4, -3, -2, -7, 8, 2, -3, -1]`, `ans = [2]`.\\n7. Next number is `-3`, so we look at cell with number `3-1`, where we see negative number, so we see number `3` before, we update: `nums = [4, -3, -2, -7, 8, 2, -3, -1]`, `ans = [2, 3]`.\\n8. Finally, we see number `-1`, so we change sign of number with index `1-1`: `ans = [-4, -3, -2, -7, 8, 2, -3, -1]`, `ans = [2, 3]`.\\n\\n**Complexity**: again, time complexity is `O(n)`, because we iterate once over our `nums`, space complexity is `O(1)`.\\n\\n```\\nclass Solution(object):\\n def findDuplicates(self, nums):\\n ans = []\\n for num in nums:\\n if nums[abs(num)-1] \u003c 0:\\n ans.append(abs(num))\\n else:\\n nums[abs(num)-1] *= -1\\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596711302, | |
| "creationDate": 1596700289 | |
| } | |
| }, | |
| { | |
| "id": 926807, | |
| "title": "[Python] Two stacks solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/add-two-numbers-ii", | |
| "post": { | |
| "id": 1686632, | |
| "content": "If we can not reverse our original lists, why not to put them into stack? So, what we do is the following:\\n\\n1. Iterate over the first and the second lists and create two stacks: `st1` and `st2`.\\n2. Iterate over stacks, pop last elements from stack if possible, if not, use `0` for empty stack. Add these two numbers and evaluate next `digit` and `carry`. Create new node with `digit` and attach it before current `head`, update `head`.\\n3. Just return `head` in the end.\\n\\n**Complexity**: time and space complexity is `O(m+n)`, where `m` and `n` lengths of our lists.\\n\\n```\\nclass Solution:\\n def addTwoNumbers(self, l1, l2):\\n st1, st2 = [], []\\n while l1:\\n st1.append(l1.val)\\n l1 = l1.next\\n \\n while l2:\\n st2.append(l2.val)\\n l2 = l2.next\\n \\n carry, head = 0, None\\n\\n while st1 or st2 or carry:\\n d1, d2 = 0, 0\\n d1 = st1.pop() if st1 else 0\\n d2 = st2.pop() if st2 else 0\\n carry, digit = divmod(d1 + d2 + carry, 10)\\n head_new = ListNode(digit)\\n head_new.next = head\\n head = head_new\\n \\n return head\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604762916, | |
| "creationDate": 1604753682 | |
| } | |
| }, | |
| { | |
| "id": 886354, | |
| "title": "[Python] O(n) solution, using preorder traversal, explained", | |
| "taskUrl": "https://leetcode.com/problems/serialize-and-deserialize-bst", | |
| "post": { | |
| "id": 1615598, | |
| "content": "My idea to solve this problem is to use **Problem 1008**. Construct Binary Search Tree from Preorder Traversal. So:\\n\\n1. For our serialization we just get preorder traversel (iterative or recursion, whatever you want, I used iterative, using stack).\\n2. For deserialization we use solution with `O(n)` time complexity: we give the function two bounds - `up` and `down`: the maximum number it will handle. The left recursion will take the elements smaller than `node.val` and the right recursion will take the remaining elements smaller than `bound`.\\n\\n**Complexity**: both for serialization and deserialization is `O(n)`, because `self.index` will be increased by one on each iteration.\\n\\n```\\nclass Codec:\\n def serialize(self, root):\\n if not root: return \"\"\\n stack, out = [root], []\\n while stack:\\n cur = stack.pop()\\n out.append(cur.val)\\n for child in filter(None, [cur.right, cur.left]):\\n stack += [child]\\n \\n return \\' \\'.join(map(str, out))\\n \\n def deserialize(self, data):\\n preorder = [int(i) for i in data.split()]\\n def helper(down, up):\\n if self.idx \u003e= len(preorder): return None\\n if not down \u003c= preorder[self.idx] \u003c= up: return None\\n root = TreeNode(preorder[self.idx])\\n self.idx += 1\\n root.left = helper(down, root.val)\\n root.right = helper(root.val, up)\\n return root\\n \\n self.idx = 0\\n return helper(-float(\"inf\"), float(\"inf\"))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602239308, | |
| "creationDate": 1602238658 | |
| } | |
| }, | |
| { | |
| "id": 821420, | |
| "title": "[Python] O(h) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/delete-node-in-a-bst", | |
| "post": { | |
| "id": 1503007, | |
| "content": "It will be easier if we consider some tree and try to understand, what we need to do in different cases.\\n\\n\\n\\n0. First we need to find our node in tree, so we just traverse it until `root.val == key`.\\n1. Case 1: node do not have any children, like `1`, `8`, `11`, `14`, `6` or `18`: then we just delete it and nothing else to do here.\\n2. Case 2: node has left children, but do not have right, for example `3` or `20`. In this case we can just delete this node and put connection betweeen its parent and its children: for example for `3`, we put connection `5-\u003e1` and for `20` we put connection `17-\u003e18`. Note, that the property of BST will be fulfilled, because for parent all left subtree will be less than its value and nothing will change for others nodes.\\n3. Case 3: node has right children, but do not have left, for example `13` and `17`. This case is almost like case `2`: we just can delete node and reconnect its parent with its children.\\n4. Case 4: node has both children, like `12`, `5`, `7`, `9` or `15`. In this case we can not just delete it. Let us consider node `5`. We want to find succesor of this node: the node with next value, to do this we need to go one time to the right and then as left as possible. For node `5` our succesor will be `6`: we go `5-\u003e7-\u003e6`. How we can delete node `5` now? We swap nodes `5` and `6` (or just put value `6` to `5`) and then we need to deal with new tree, where we need to delete node which I put in square. How to do it? Just understand, that this node do not have left children, so it is either Case 1 or Case 3, which we already can solve.\\n\\n\\n\\n\\n**Complexity**: Complexity of finding node is `O(h)`, Cases 1,2,3 is `O(1)`. Complexity of Case `4` is `O(h)` as well, because we first find succesor and then apply one of the Cases 1,3 only once. So, overall complexity is `O(h)`. Space complexity is `O(h)` as well, because we use recursion and potentially we can find our node in the bottom of tree.\\n\\n```\\nclass Solution(object):\\n def deleteNode(self, root, key):\\n if not root: return None\\n \\n if root.val == key:\\n if not root.right: return root.left\\n \\n if not root.left: return root.right\\n \\n if root.left and root.right:\\n temp = root.right\\n while temp.left: temp = temp.left\\n root.val = temp.val\\n root.right = self.deleteNode(root.right, root.val)\\n\\n elif root.val \u003e key:\\n root.left = self.deleteNode(root.left, key)\\n else:\\n root.right = self.deleteNode(root.right, key)\\n \\n return root\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598863253, | |
| "creationDate": 1598863253 | |
| } | |
| }, | |
| { | |
| "id": 887690, | |
| "title": "[Python] O(n log n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons", | |
| "post": { | |
| "id": 1617924, | |
| "content": "This problem is almost identical to problem **435 Non-overlapping Intervals**, but here we need to find not how many interals we need to remove, but how many non-overlapping intervals we have. Also one small difference is that here intervals `[1,2]` and `[2,3]` overlapping, because they have common end.\\n\\nFor more explanations, please look at my solution of problem **435**:\\nhttps://leetcode.com/problems/non-overlapping-intervals/discuss/793070/Python-O(n-log-n)-sort-ends-with-proof-explained\\n\\n**Complexity**: it is the same as problem 435: time is `O(n log n)` and space is `O(n)`.\\n\\n```\\nclass Solution:\\n def findMinArrowShots(self, points):\\n points.sort(key = lambda x: x[1])\\n n, count = len(points), 1\\n if n == 0: return 0\\n curr = points[0]\\n \\n for i in range(n):\\n if curr[1] \u003c points[i][0]:\\n count += 1\\n curr = points[i]\\n \\n return count \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602321283, | |
| "creationDate": 1602321283 | |
| } | |
| }, | |
| { | |
| "id": 975319, | |
| "title": "[Python] O(n^2) two 2-sum, explained", | |
| "taskUrl": "https://leetcode.com/problems/4sum-ii", | |
| "post": { | |
| "id": 1770673, | |
| "content": "Let us look at pairs of numbers from `A` and `B` and calculate all `O(n^2)` of them. Next, we look at all pairs from `C` and `D` and again calculate all of them. Now, our problem is reduced to **2-sum** problem: we need to find two numbers from two lists, such that sum of them equal to `0`. There is couple of moments we need to care about:\\n\\n1. There can be duplicates, so we keep `Counter()` for our sums.\\n2. When we update `ans`, we check how many numbers we have in first counter and multiply it by how many times we have for opposite number.\\n\\n**Complexity**: total complexity is `O(n^2)` to look at all pairs from `(A, B)` and `(C, D)`. Space complexity is also `O(n^2)`. One possible optimization is to first create counters from our lists and work with them directly.\\n\\n```\\nclass Solution:\\n def fourSumCount(self, A, B, C, D):\\n Cnt1, Cnt2, ans = Counter(), Counter(), 0\\n for a, b in product(A, B):\\n Cnt1[a + b] += 1\\n \\n for c, d in product(C, D):\\n Cnt2[c + d] += 1\\n \\n for val in Cnt1:\\n if -val in Cnt2:\\n ans += Cnt1[val]*Cnt2[-val]\\n \\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608197331, | |
| "creationDate": 1608197331 | |
| } | |
| }, | |
| { | |
| "id": 906876, | |
| "title": "[Python] O(n) solution with decreasing stack, explained", | |
| "taskUrl": "https://leetcode.com/problems/132-pattern", | |
| "post": { | |
| "id": 1651909, | |
| "content": "Let us keep evaluate `min_list`, where `min_list[i] = min(nums[0], ..., nums[i])`.\\nAlso let us traverse our `nums` from the end and keep stack with decreasing elements, which are more than `min_list[j]` for given `j`.\\nWe will try to find `132` pattern, where `nums[j]` is middle number in this pattern.\\n\\nLet us look through the code and see what is going on:\\n1. If `nums[j] \u003c= min_list[j]`, there is no need to put this number to stack: it means actually that `nums[j]` is less than all previous numbers and it can not be the middle element in our `132` pattern.\\n2. Now, if `nums[j] \u003e min_list[j]`, we need to keep our stack clean: if we have numbers which are leaa or equal than `min_list[j]`, we remove them from our stack. So, we have now `stack[-1] \u003e min_list[j]`. If it is also happen, that `stack[-1] \u003c nums[j]`, then we are happy: we found our pattern: we choose `stack[-1]` for our `2` in pattern, `nums[j]` for our `3` and element where minumum reached: `min_list[j]` for our `1`: we have our `1` less than `2` and `2` less than `3`. In this case we immedietly return `True`. In the end we append `nums[j]` to our stack.\\n3. If we traversed all list and did not found pattern, we return `False`.\\n\\nSo, what exaclty will be in our stack on each step? \\n1. There always be numbers more or equal than `nums[j]` inside\\n2. Which are going in decreasing order. \\n\\nWhy it will not change on the next step? If our next number (`nums[j-1]`) is more than top of our stack, we found our `132` pattern! If it is less, then we put it into our stack and decreasing order is satisfied (property s) and if we have top of our stack equal to `nums[j-1]`, so property `1` is also satisfied.\\n\\n**Complexty** is `O(n)`, both for time and memory, because we traverse our list twice: once in one direction and once in opposite\\n\\n\\n```\\nclass Solution:\\n def find132pattern(self, nums):\\n min_list = list(accumulate(nums, min))\\n stack, n = [], len(nums)\\n \\n for j in range(n-1, -1, -1):\\n if nums[j] \u003e min_list[j]:\\n while stack and stack[-1] \u003c= min_list[j]:\\n stack.pop()\\n if stack and stack[-1] \u003c nums[j]:\\n return True\\n stack.append(nums[j]) \\n return False\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603450680, | |
| "creationDate": 1603443910 | |
| } | |
| }, | |
| { | |
| "id": 935112, | |
| "title": "[Python] Math solution, detailed expanations", | |
| "taskUrl": "https://leetcode.com/problems/poor-pigs", | |
| "post": { | |
| "id": 1700993, | |
| "content": "What matters is number of tests `T` and number of pigs `x`. Let us ask inverse question: how many states can we generate with `x` pigs and `T` tests to cover `N` scenarios? This is **estimation + example** problem, where we need to 1) prove, that we can not make `N` bigger than some number and 2) give an example, where this `N` is possible. \\n\\n**Estimation**: The number of states is exactly `(T+1)^x` and here is why. For each pig during `T` tests, it has exactly `T+1` states: dies at some test `#i`, where `1\u003c= i \u003c= T)` or still alive eventually. For `x` pigs, obviously the maximum possible number of states we could have is `(T+1)^x` since each is independent and one pig can not influence on another one. \\n\\n**Example**: From other side, we can construct the example, using `(T+1)` based numbers: at first test for `i`-th pig choose all numbers, where `i`-th digit is `0`. If all pigs are dead, we can immediately say what bucket was poisoned. If `k` pigs are alive, there will be `T^k` possible options for `T-1` days and `k` pigs, which can be solved, using induction. For better understanding, imaging the special case: let us have `x=3` pigs and `T=2` tests. Then our plan is the following:\\n\\nWe have `27` different positions: \\n`000 001 002` `100 101 102` `200 201 202` \\n`010 011 012` `110 111 112` `210 211 212`\\n`020 021 022` `120 121 122` `220 221 222`\\n\\nOn the first test, first pig will drink from first `9` bucktes: `000, 001, 002, 010, 011, 012, 020, 021, 022`, if it is not dead, on the second test it drink from the second `9` buckets `100, 101, 102, 110, 111, 112, 120, 121, 122`. Why we choose this bucktes? Because for the first group it always starts with `0` and second always starts with `1`. What can be our results?\\n\\n1. This pig dies after first test, so we can conclude, that our bucket has form `0**`.\\n2. This pig dies after second test, so we can conclude, that our bucket has form `1**`.\\n3. It will not die at all (lucky bastard), then our bucket has form `2**`.\\n\\nSo, what was the purpuse of first pig? To understand the first digit in our bucket number.\\n\\nNo, let us look at the second pig: we do very similar procedure for it: on the first test it will drink from the `9` buckets from first line: `000, 001, 002, 100, 101, 102, 200, 201, 202`: all buckets with second number equal to `0`, on the second test, it will drink from `010, 011, 012, 110, 111, 112, 210, 211, 212`: from all buckets with second number equel to `1`. We again can do the following inference:\\n\\n1. This pig dies after first test, so we can conclude, that our bucket has form `*0*`.\\n2. This pig dies after second test, so we can conclude, that our bucket has form `*1*`.\\n3. It will not die at all (lucky bastard), then our bucket has form `*2*`.\\n\\nFinally, we have the third pig, which help us to understand if we have `**0`, `**1` or `**2`.\\n\\nLooking at all information we have now about the frist, the second and the third digits in our bucket number we can say what bucket we have!\\n\\n**Complexity**: it is just `O(1)` time and space if we assume that we can evaluate `log` in `O(1)` time.\\n\\n```\\nclass Solution:\\n def poorPigs(self, buckets, minutesToDie, minutesToTest):\\n return ceil(log(buckets)/log(minutesToTest//minutesToDie + 1))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605351666, | |
| "creationDate": 1605342956 | |
| } | |
| }, | |
| { | |
| "id": 826121, | |
| "title": "[Python] 2 solutions/1 oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/repeated-substring-pattern", | |
| "post": { | |
| "id": 1511259, | |
| "content": "Nice and easy problem, which can be solved in different ways.\\n\\n### Solution 1\\n\\nJust check all posible divisors of lenght of `s`, replicate them and compare them with original string. If we have found it, we return `True`, if we reached the end and we did not find any, we return `False`.\\n\\n**Complexity**: time complexity is `O(n*sqrt(n))`, because we have no more than `O(sqrt(n))` divisors of number `n` (we can split them into pairs, where one number in pair will be `\u003csqrt(n)`. Space compexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def repeatedSubstringPattern(self, s):\\n N = len(s)\\n for i in range(1, N//2+1):\\n if N % i == 0 and s[:i]* (N//i) == s:\\n return True\\n return False\\n```\\n\\n### Solution 2\\nBut wait, there is more! There is in fact very short and interesting solution. Let us replicate our sting, remove first and last elements and try to find original string: for example:\\n\\n`s = abcdabcd`, then we have `bcdabcdabcdabc`, where we can find `abcdabcd` inside. It is a bit more difficult to prove, that opposite is true: if we found substring it will mean that we have repeated substring pattern. I will add proof a bit later.\\n\\n**Complexity**: time complexity is basically `O(n)`, because we can find substrings in linear time. In python function `in` will work, using Boyer\\u2013Moore algorithm, which is in average work in linear time (if you do not like average, you can use KMP, which have worst linear time, not average). Space complexity is `O(n)`.\\n\\n```\\nreturn s in (s+s)[1:-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599117863, | |
| "creationDate": 1599117863 | |
| } | |
| }, | |
| { | |
| "id": 720541, | |
| "title": "[Python] Bit Manipulation t\u0026(t-1) trick, explained", | |
| "taskUrl": "https://leetcode.com/problems/hamming-distance", | |
| "post": { | |
| "id": 1328960, | |
| "content": "We are asked to find the number of positions, where `x` and `y` have equal bits. It is the same as finding number of `1` bits in number `t = x^y`. There is efficient way to find number of `1` bits in any number, using `t = t\u0026(t-1)` trick: this operation in fact removes the last `1` bit from `t`. So, we just apply this rule in loop and increment our counter `Out`.\\n\\n**Complexity** is `O(k)`, where `k` is Hamming distance between numbers `x` and `y`, memory is `O(1)`. Note, that it works (twice?) faster than usual bit counts, which have always `32` iterations.\\n\\n```\\nclass Solution:\\n def hammingDistance(self, x, y):\\n Out, t = 0, x^y \\n while t:\\n t, Out = t \u0026 (t-1), Out + 1\\n return Out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593933731, | |
| "creationDate": 1593933491 | |
| } | |
| }, | |
| { | |
| "id": 723842, | |
| "title": "[Python] O(mn) simple loop solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/island-perimeter", | |
| "post": { | |
| "id": 1334657, | |
| "content": "How we can evaluate perimeter of our island? We can evaluate perimeters off all squares first, and then subtract all sides of cells, which need to be removed, and that is all!\\n\\n1. Perimeter of each cell is equal to `4`, so when we see non-empty cell, we add `4`.\\n2. For each non-empty cell with coordinates `(i,j)`, if `(i-1,j)` also non-empty, we need to subract `1` from our perimeter, which can be done with line `Perimeter -= grid[i][j]*grid[i-1][j]`. Note, that for the case `1 1`, we subtract `1` twice, so perimeter will be `4+4-1-1 = 6`, as it should be. Similar for other neibours of cell `(i,j)`.\\n\\n\\n\\n\\n\\n\\n**Complexity**: time complexity is `O(mn)`, because we traverse our grid once and for each cell check `4` neighbors. Space complexity is `O(1)`, because we do not use any extraspace, only `Perimeter`.\\n\\n\\n```\\nclass Solution:\\n def islandPerimeter(self, grid):\\n m, n, Perimeter = len(grid), len(grid[0]), 0\\n\\n for i in range(m):\\n for j in range(n):\\n Perimeter += 4*grid[i][j]\\n if i \u003e 0: Perimeter -= grid[i][j]*grid[i-1][j]\\n if i \u003c m-1: Perimeter -= grid[i][j]*grid[i+1][j]\\n if j \u003e 0: Perimeter -= grid[i][j]*grid[i][j-1]\\n if j \u003c n-1: Perimeter -= grid[i][j]*grid[i][j+1]\\n \\n return Perimeter\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594131842, | |
| "creationDate": 1594106846 | |
| } | |
| }, | |
| { | |
| "id": 689872, | |
| "title": "[Python] Check all options carefully, explained", | |
| "taskUrl": "https://leetcode.com/problems/validate-ip-address", | |
| "post": { | |
| "id": 1274625, | |
| "content": "The main difficulty of this problem if you meet it on real interview, is to not forget any border cases, there are **a lot** of them. First of all let us split problem into two subproblems: possible candidates for **IPv4** and possible candidates for **IPv6**.\\n\\n1. We have candidate for **IPv4** if we meet symbol **.** in our data. If we met it, we split our data into parts, using **.** and we need to check:\\n1.1 If we have not **4** parts, we return `\"Neither\"`.\\n1.2 We check each part and if it is empty and if it starts with zero, but not zero, we also return `\"Neither\"`.\\n1.3 Finally, we check that every part is number and is less than 256, if it is not true, we return `\"Neither\"`.\\n1.4 If we passed all previous steps, we return `IPv4`.\\n2. We have candidate for **IPv4** if we meet symbol **:** in our data. If we met it, we split our data into parts, using **:** and we need to check:\\n2.1 If number of parts not equal to `8`, we return `\"Neither\"`\\n2.2 If we have empty parts of parts with length more than `4`, we return `\"Neither\"`\\n2.3 We check each symbol in our part and if we found something not in `1234567890abcdefABCDEF`, we return `\"Neither\"`\\n2.4 If we passed all previous steps, we return `IPv6`.\\n\\n**Complexity**: both time and space are `O(n)`, where `n` is number of elements in our string.\\n\\n```\\nclass Solution:\\n def validIPAddress(self, IP):\\n if \".\" in IP:\\n splitted = IP.split(\".\")\\n if len(splitted) != 4: return \"Neither\"\\n for part in splitted:\\n if len(part) == 0 or (len(part)\u003e1 and part[0] == \"0\"): return \"Neither\"\\n if not part.isnumeric() or int(part) \u003e 255: return \"Neither\" \\n return \"IPv4\" \\n elif \":\" in IP:\\n symbols = \"0123456789abcdefABCDEF\"\\n splitted = IP.split(\":\")\\n if len(splitted) != 8: return \"Neither\"\\n for part in splitted:\\n if len(part) == 0 or len(part) \u003e 4: return \"Neither\"\\n for elem in part:\\n if elem not in symbols: return \"Neither\" \\n return \"IPv6\" \\n return \"Neither\"\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592298238, | |
| "creationDate": 1592292805 | |
| } | |
| }, | |
| { | |
| "id": 816210, | |
| "title": "[Python] rejection sampling, 2 lines, explained", | |
| "taskUrl": "https://leetcode.com/problems/implement-rand10-using-rand7", | |
| "post": { | |
| "id": 1493814, | |
| "content": "What we can do here is to generate numbers between `1` and `7` and this makes this problems both easy and difficult. Easy, because you do not have a lot of choice what to do, difficult, because we need to use not very big number of generations. Can we use one number between `1` and `7` to generate number between `1` and `10`? I do not think so, we have very small choice. Can we use `2`? Yes, we can, here is the strategy:\\n1. Generate `a` from `1` to `7` and `b` from `1` to `7`, then we have `7x7 = 49` options. Let us create number `c = (a-1)*7 + b-1`, then we can show that `c` is number between `0` and `48`: substitute all possible values for `a` and `b` and you will see. \\n2. Now, let us divide these number into groups: `[0,9]; [10;19]; [20;29]; [30;39]; [40;48]`. If we get into one of the first four group we are happy: there is ten number in each group, so we just return `c%10 + 1`.\\n3. If we are in the fifth group, we are not happy, there are only `9` numbers in this group and we need `10`, use `9` is not fair. So in these case, we say, that our experiment was not working, and we just start it all over again! That is all.\\n\\n**Complexity**: what we do here is called sampling with rejection. Success of first sampling is `p = 40/49`. If first time our sampling was not working and it worked second time we have `(1-p)*p`, if it worked third time it is `(1-p)*(1-p)*p` and so on. Each time we use two `rand7()` generation. So, overall our **expectation** is `2*p + 4*(1-p)*p + 6*(1-p)^2*p + ...` How to compute it? Note, that it is nothing else than geometrical distribution: https://en.wikipedia.org/wiki/Geometric_distribution, so the answer is just `2/p` = `98/40 = 2.45`.\\n\\n```\\nclass Solution:\\n def rand10(self):\\n c = (rand7() - 1)*7 + rand7() - 1\\n return self.rand10() if c \u003e= 40 else (c % 10) + 1\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598600214, | |
| "creationDate": 1598600214 | |
| } | |
| }, | |
| { | |
| "id": 864975, | |
| "title": "[Python] Merge intervals O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/teemo-attacking", | |
| "post": { | |
| "id": 1578872, | |
| "content": "If we look carefully at this problem we can see that all we need to do is to merge some intervals with equal length and return total length of merged intervals. Note also that intervals are already sorted by its beginings (and ends as well, because they have equal length), so usual sorting step can be skipped.\\n \\n All we need to do is to traverse our `timeSeries` and check if difference between current point and previous is more than `duration`. If it is more, we add `duration` to total sum, if it is less, we add difference between current and previous elements. Also we need to deal with border case of empty array and if array is not empty, add `duration` in the end. \\n \\n **Complexity**: time complexity is `O(n)`, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def findPoisonedDuration(self, timeSeries, duration):\\n n, out = len(timeSeries), 0\\n if n == 0: return 0\\n for i in range(n-1):\\n out += min(timeSeries[i+1] - timeSeries[i], duration)\\n return out + duration\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601106668, | |
| "creationDate": 1601106668 | |
| } | |
| }, | |
| { | |
| "id": 805232, | |
| "title": "[Python] Short solution with binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/random-point-in-non-overlapping-rectangles", | |
| "post": { | |
| "id": 1474797, | |
| "content": "Basically, this problem is extention of problem **528. Random Pick with Weight**, let me explain why. Here we have several rectangles and we need to choose point from these rectangles. We can do in in two steps:\\n\\n1. Choose rectangle. Note, that the bigger number of points in these rectangle the more should be our changes. Imagine, we have two rectangles with 10 and 6 points. Then we need to choose first rectangle with probability `10/16` and second with probability `6/16`.\\n2. Choose point inside this rectangle. We need to choose coordinate `x` and coordinate `y` uniformly.\\n\\nWhen we `initailze` we count weights as `(x2-x1+1)*(y2-y1+1)` because we also need to use boundary. Then we evaluate cumulative sums and normalize.\\n\\nFor `pick` function, we use **binary search** to find the right place, using uniform distribution from `[0,1]` and then we use uniform discrete distribution to choose coordinates `x` and `y`. \\n\\n**Complexity**: Time and space complexity of `__init__` is `O(n)`, where `n` is number of rectangles. Time complexity of `pick` is `O(log n)`, because we use binary search. Space complexity of `pick` is `O(1)`.\\n\\n**Remark**: Note, that there is solution with `O(1)` time/space complexity for `pick`, using smart mathematical trick, see my solution of problem **528**: https://leetcode.com/problems/random-pick-with-weight/discuss/671439/Python-Smart-O(1)-solution-with-detailed-explanation\\n\\n\\n```\\nclass Solution:\\n def __init__(self, rects):\\n w = [(x2-x1+1)*(y2-y1+1) for x1,y1,x2,y2 in rects]\\n self.weights = [i/sum(w) for i in accumulate(w)]\\n self.rects = rects\\n\\n def pick(self):\\n n_rect = bisect.bisect(self.weights, random.random())\\n x1, y1, x2, y2 = self.rects[n_rect] \\n return [random.randint(x1, x2),random.randint(y1, y2)]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598085073, | |
| "creationDate": 1598085073 | |
| } | |
| }, | |
| { | |
| "id": 985751, | |
| "title": "[Python] Short solution, using defaultdict, explained", | |
| "taskUrl": "https://leetcode.com/problems/diagonal-traverse", | |
| "post": { | |
| "id": 1787654, | |
| "content": "Main trick to solve this problem easily is to understand the structure of our diagonal traverse. Let us call level each diagonal we traverse: \\n1. In first level we have only one coordinates: `[0, 0]`.\\n2. In second level we have two points: `[0, 1]` and `[1, 0]`.\\n3. In third level we have three points: `[0, 2]`, `[1, 1]` and `[2, 0]`.\\n\\nNow, aogorithm becomes very easy:\\n1. For each level put all elements in this level to dictionary `levels`: note, that for each level we put it in direct order.\\n2. Now, for each level choose if we traverse it in direct order or reverse, using `[::lev%2*2-1]` notation. If `lev` is odd number, then we have `[::1]`, that is direct order, if `lev` is even, we have `[::-1]`, that is reverse order.\\n\\n**Complexity**: time complexity is `O(mn)`: we traverse each element once. Additional space complexity in this approach is also `O(mn)`, because we keep `levels` dictionary. Theoretically, we can put our data directly into long list and then reverse some parts, we will have `O(1)` additional space in this case.\\n\\n```\\nclass Solution:\\n def findDiagonalOrder(self, matrix):\\n if not matrix: return []\\n m, n = len(matrix), len(matrix[0])\\n levels = defaultdict(list)\\n for i, j in product(range(m), range(n)):\\n levels[i+j].append(matrix[i][j])\\n \\n out = []\\n for lev in range(m + n):\\n out += levels[lev][::lev%2*2-1] \\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608892480, | |
| "creationDate": 1608892480 | |
| } | |
| }, | |
| { | |
| "id": 675096, | |
| "title": "[Python] O(amount * N) simple dp explained (updated)", | |
| "taskUrl": "https://leetcode.com/problems/coin-change-2", | |
| "post": { | |
| "id": 1248506, | |
| "content": "Let `dp_sum[i][j]` be a number of ways to represent amount `i` such that we use only first `j` coins. We initialize the first column of this table with `1`, because we can say there is one way to get `amount = 0`, using first `j` coins: do not take any coins.\\nTo find `dp_sum[i][j]` we need to look at the last coin taken, it consists of two terms:\\n1. `dp_sum[i][j-1]`, number of options, where we take only first `j-1` coins\\n2. `dp_sum[i-coins[j]][j]`, number of options, where we removed coin number `j` and we need to find number of options for the rest amount.\\n\\n**Example**: let us consider `coins = [1,2,5]` and amont = 5. Then table `dp_sum` will be equal to\\n| | 0 | 1 | 2 | 3 | 4 | 5 |\\n|-------------|---|---|---|---|---|---|\\n| **coin #0 (1)** | 1 | 1 | 1 | 1 | 1 | 1 |\\n| **coin #1 (2)** | 1 | 1 | 2 | 2 | 3 | 3 |\\n| **coin #2 (5)** | 1 | 1| 2 | 2 | 3 | 4 |\\n\\n**Complexity** time and space is `O(amount *N)`, where `N` is number of different coins, because we need only `O(1)` to update each cell.\\n\\nIn code I use index `i+1` instead of `i`, because we start from `1`st column, not `0`th.\\n\\n**Update** Space complexity can be reduced to `O(amount)`, because for every `j` we look at most one row back.\\n\\n```\\nclass Solution:\\n def change(self, amount, coins):\\n N = len(coins)\\n if N == 0: return int(N == amount)\\n \\n dp_sum = [[0] * N for _ in range(amount + 1)]\\n for i in range(N): dp_sum[0][i] = 1\\n \\n for i,j in product(range(amount), range(N)):\\n dp_sum[i+1][j] = dp_sum[i+1][j-1]\\n if i+1 - coins[j] \u003e= 0:\\n dp_sum[i+1][j] += dp_sum[i+1-coins[j]][j] \\n \\n return dp_sum[-1][-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please\\n**Upvote!**", | |
| "updationDate": 1596709282, | |
| "creationDate": 1591519735 | |
| } | |
| }, | |
| { | |
| "id": 675424, | |
| "title": "[Python] Oneliner Magical solution with Generating functions", | |
| "taskUrl": "https://leetcode.com/problems/coin-change-2", | |
| "post": { | |
| "id": 1249080, | |
| "content": "This is classical problem for generation functions: you can see this example on wikipedia: number of ways to make change (https://en.wikipedia.org/wiki/Examples_of_generating_functions).\\n\\nHowerer the main difficulty here is to make it work in time. What I did is I choose `x = 2^32`, spend like 4 hours, trying different ways to multiply polynomials, using convolutions and optimizing code to avoid TLE and here is the result.\\n\\n**Update**: \\n\\nLet us go through example `target = 5` and `coins = [1, 2, 5]`\\n1. We build 3 generating polynoms: `1+x+x^2+x^3+x^4+x^5`, `1+x^2+x^4` and `1+x^5`. What we need to do now is to multiply these polynomials and evaluate coefficient before term with degree `target`. Indeed:\\n`(1+x+x^2+x^3+x^4+x^5)*(1+x^2+x^4)*(1+x^5) = ... + x*x^4*1 + 1*1*x^5 + x^3*x^2*1 + x^5*1*1`, there is `4` possible ways to get degree `5`. \\n2. Note, that if all coefficients are less than some big number `N`, say `N=1000` for example and `polynom = 13x^2 + 6x + 3`, than `polynom(1000) = 13006003`, so we can easily distinguish coefficients for each degree, if we look at our number as number in base `1000`. \\n3. To make it faster we use the fact `(1+x+x^2+x^3+x^4+x^5) = (x^6-1)/(x-1)`, `(1+x^2+x^4) = (x^6-1)/(x^2-1)` and `1+x^5=(x^10-1)/(x^5-1)`.\\n4. We take `N=2^32`, because it is given in statement that we can never get numbers more than `N`.\\n5. Substitute `N=2^32` into our polynom and evaluate it! Python allows as to do computations of big numbers.\\n6. Optimisations: use a lot of bit manipulations to avoid TLE.\\n\\n\\n```\\nclass Solution:\\n def change(self, amount, coins):\\n S = [(((1\u003c\u003c(32*(amount//i*i + i)))) - 1)//((1\u003c\u003c(i*32)) - 1) for i in coins]\\n prodd = 1\\n \\n for i in S: prodd = (prodd * i) \u0026 ((1\u003c\u003c((amount +1)*32))-1)\\n return prodd\u003e\u003e(32*amount)\\n```\\n\\nWe can write it as Oneliners in the following ways - thanks **https://leetcode.com/joric/** for this!\\n\\n```\\nreturn reduce(lambda p,i:(p*i)\u0026(1\u003c\u003c((amount+1)*32))-1,[((1\u003c\u003c(32*(amount//i*i+i)))-1)//((1\u003c\u003c(i*32))-1) for i in coins],1)\u003e\u003e(32*amount)\\n```\\n\\n```python\\nreturn list(accumulate(coins,lambda p,i:(p*(((1\u003c\u003c(32*(amount//i*i+i)))-1)//((1\u003c\u003c(i*32))-1)))\u0026((1\u003c\u003c((amount+1)*32))-1),initial=1))[-1]\u003e\u003e(32*amount)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1591620618, | |
| "creationDate": 1591536344 | |
| } | |
| }, | |
| { | |
| "id": 766364, | |
| "title": "[Python] Simple O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/detect-capital", | |
| "post": { | |
| "id": 1407609, | |
| "content": "We can solve this problem in oneline, if we use python functionality: functions `isupper()` `islower()` and `istitle()`. I think the first two ones are pretty classical and a lot of people aware of them (if not, it is very easy to write this function, just check if symbol is between `a` and `z` for `islower()` and from `A` to `Z` for `isupper()`). Howerer the third one is a bit cheating, so I decided not to use it.\\n\\nSo, we can have three cases. Let us evaluate number of capital letters first:\\n1. If number of capital letters is equal to `0`, then we return `True`.\\n2. If number of capital letters is equal to `n` - number of all letters, we also return `True`.\\n3. If number of capital letters is equal to `1` and first letter is capital, we return `True`.\\n4. If none of `3` conditions above fulfilled, we return `False`.\\n\\n**Complexity**: time complexity is `O(n)`, because we traverse our string once. Space complexity is `O(1)`, because we have only couple of additional constants.\\n\\n```\\nclass Solution:\\n def detectCapitalUse(self, word):\\n Num_cap, n = 0, len(word)\\n for letter in word: \\n Num_cap += letter.isupper()\\n if Num_cap == 0 or Num_cap == n or Num_cap == 1 and word[0].isupper():\\n return True\\n return False\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596267610, | |
| "creationDate": 1596267610 | |
| } | |
| }, | |
| { | |
| "id": 653061, | |
| "title": "[Python] Detailed explanation, O(n) time\u0026space, cumulative sums", | |
| "taskUrl": "https://leetcode.com/problems/contiguous-array", | |
| "post": { | |
| "id": 1211405, | |
| "content": "Let us change all 0 in our array with -1. Then we need to find the contiguous subarray with sum equal to zero. There are still O(n^2) different contiguous subarrays, but we do not need to evaluate them all. If we evaluate all cumulative sums, then we need to find two cumulative sums which are equal and have the biggest distance. Example:\\n\\n``` nums = [1, 0, 0, 1, 1, 1, 1, 0, 1] -\u003e[1, -1, -1, 1, 1, 1, 1, -1, 1] -\u003e [1, 0, -1, 0, 1, 2, 3, 2, 3]``` \\nand the biggest distance between equal elements is 4, element number 0 and element number 4.\\n\\nWe are going to keep ```ind``` hashtable, where for each value of cumulative sum we keep indexes for the first and for the last element with this value in our cumulative sum. Continue with our example:\\n```\\nind[0] = [1,3]\\nind[1] = [0,4]\\nind[-1] = [2,2]\\nind[2] = [5,7]\\nind[3] = [6,8]\\n```\\n\\n**Complexity** We need to go through our ```nums``` twice: first, when we build cumulative sums and then when we create our ```ind``` hash-table, hence we have O(n) time complexity. Also, there can be at most 2n + 1 elements in our hash-table - with values from -n to n (in fact not more than n of them will be there, because we have only n cumulative sums). So time complexity is also O(n).\\n\\n``` \\nclass Solution:\\n def findMaxLength(self, nums):\\n nums = list(accumulate([x * 2 - 1 for x in nums]))\\n ind = defaultdict(list)\\n ind[0] = [-1,-1]\\n for i in range(len(nums)):\\n if not ind[nums[i]]:\\n ind[nums[i]] = [i,i]\\n else:\\n ind[nums[i]][1] = i\\n \\n max_len = 0\\n for i in ind:\\n max_len = max(max_len,ind[i][1]-ind[i][0])\\n return max_len\\n```\\n\\t \\nIf you have any questions, feel free to ask. Upvote if you like this solution.", | |
| "updationDate": 1590494586, | |
| "creationDate": 1590478716 | |
| } | |
| }, | |
| { | |
| "id": 671439, | |
| "title": "[Python] Smart O(1) solution with detailed explanation", | |
| "taskUrl": "https://leetcode.com/problems/random-pick-with-weight", | |
| "post": { | |
| "id": 1242010, | |
| "content": "Probably you already aware of other solutions, which use linear search with `O(n)` complexity and binary search with `O(log n)` complexity. When I first time solved this problem, I thought, that `O(log n)` is the best complexity you can achieve, howerer it is not! You can achieve `O(1)` complexity of function `pickIndex()`, using smart mathematical trick: let me explain it on the example: `w = [w1, w2, w3, w4] = [0.1, 0.2, 0.3, 0.4]`. Let us create `4` **boxes** with size `1/n = 0.25` and distribute original weights into our boxes in such case, that there is no more than 2 parts in each box. For example we can distribute it like this:\\n1. Box 1: `0.1` of `w1` and `0.15` of `w3`\\n2. Box 2: `0.2` of `w2` and `0.05` of `w3`\\n3. Box 3: `0.1` of `w3` and `0.15` of `w4`\\n4. Box 4: `0.25` of `w4`\\n\\n(if weights sum of weights is not equal to one, we normalize them first, dividing by sum of all weights).\\n\\n\\nthis method has a name: https://en.wikipedia.org/wiki/Alias_method , here you can see it in more details.\\n\\n**Sketch of proof**\\nThere is always a way to distribute weights like this, it can be proved by **induction**, there is always be one box with weight `\u003c=1/n` and one with `\u003e=1/n`, we take first box in full and add the rest weight from the second, so they fill the full box. Like we did for Box 1 in our example: we take `0.1` - full `w1` and `0.15` from `w3`. After we did it we have `w2: 0.2, w3: 0.15` and `w4: 0.4`, and **again** we have one box with `\u003e=1/4` and one box with `\u003c=1/4`.\\n\\nNow, when we created all boxes, to generate our data we need to do 2 steps: first, to generate box number in `O(1)`, because sizes of boxes are equal, and second, generate point uniformly inside this box to choose index. This is working, because of **Law of total probability**.\\n\\n**Complexity**. Time and space complexity of preprocessing is `O(n)`, but we do it only once. Time and space for function `pickIndex` is just `O(1)`: all we need to do is generate uniformly distributed random variable twice!\\n\\n\\n**Code** is not the easiest one to follow, but so is the solution. First, I keep two dictionaries `Dic_More` and `Dic_Less`, where I distribute weights if they are more or less than `1/n`. Then I Iterate over these dictionaries and choose one weight which is more than `1/n`, another which is less, and update our weights. Finally when `Dic_Less` is empty, it means that we have only elements equal to `1/n` and we put them all into separate boxes. \\nI keep boxes in the following way: `self.Boxes` is a list of tuples, with 3 numbers: index of first weight, index of second weight and split, for example for Box 1: `0.1` of `w1` and `0.15` of `w3`, we keep `(1, 3, 0.4)`. If we have only one weight in box, we keep its index.\\n\\n```\\nclass Solution:\\n def __init__(self, w):\\n ep = 10e-5\\n self.N, summ = len(w), sum(w)\\n weights = [elem/summ for elem in w]\\n Dic_More, Dic_Less, self.Boxes = {}, {}, []\\n \\n for i in range(self.N):\\n if weights[i] \u003e= 1/self.N:\\n Dic_More[i] = weights[i]\\n else:\\n Dic_Less[i] = weights[i]\\n\\n while Dic_More and Dic_Less:\\n t_1 = next(iter(Dic_More))\\n t_2 = next(iter(Dic_Less))\\n self.Boxes.append([t_2,t_1,Dic_Less[t_2]*self.N])\\n\\n Dic_More[t_1] -= (1/self.N - Dic_Less[t_2])\\n if Dic_More[t_1] \u003c 1/self.N - ep:\\n Dic_Less[t_1] = Dic_More[t_1]\\n Dic_More.pop(t_1)\\n Dic_Less.pop(t_2)\\n \\n for key in Dic_More: self.Boxes.append([key])\\n\\n def pickIndex(self):\\n r = random.uniform(0, 1)\\n Box_num = int(r*self.N)\\n if len(self.Boxes[Box_num]) == 1:\\n return self.Boxes[Box_num][0]\\n else:\\n q = random.uniform(0, 1)\\n if q \u003c self.Boxes[Box_num][2]:\\n return self.Boxes[Box_num][0]\\n else:\\n return self.Boxes[Box_num][1]\\n```\\n\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please \\n**Upvote!**", | |
| "updationDate": 1596993000, | |
| "creationDate": 1591342707 | |
| } | |
| }, | |
| { | |
| "id": 876197, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/k-diff-pairs-in-an-array", | |
| "post": { | |
| "id": 1598142, | |
| "content": "Let us just use counter and count frequency of each number in our array. We can have two options:\\n\\n1. `k \u003e 0`, it means, that for each unique number `i` we are asking if number `i+k` also in table.\\n2. `k = 0`, it means, that we are looking for pairs of equal numbers, so just check each frequency.\\n\\n**Complexity**: time and space complexity is `O(n)`, because we traverse our array twice: first time to create counter and second to find `res`.\\n\\n```\\nclass Solution:\\n def findPairs(self, nums, k):\\n count = Counter(nums)\\n if k \u003e 0:\\n res = sum([i + k in count for i in count])\\n else:\\n res = sum([count[i] \u003e 1 for i in count])\\n return res\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601710138, | |
| "creationDate": 1601710138 | |
| } | |
| }, | |
| { | |
| "id": 983076, | |
| "title": "[Python] O(m) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/next-greater-element-iii", | |
| "post": { | |
| "id": 1783459, | |
| "content": "Let us start from example and see how our algorithm should work.\\nImaigne `n = 234157641`. Our goal is to find next number with the same digits, which is greater than given one and which is the smallest one. It makes sense to try to take our number as close to original one as possible. Let us try to do it: can it start from `2......`, yes, for example `24...`. Can it start with `2341...`? Yes, it can be `23417...`. Can it start with `23415...`? No, it can not, and the reason, that the rest what we have `7641` already biggest number given digits `7, 6, 4, 1`. \\nSo, we can see now, how our algorithm should work:\\n1. Start from the end and look for increasing pattern, it our case `7641`.\\n2. If it happen, that all number has increasing pattern, there is no bigger number with the same digits, so we can return `-1`.\\n3. Now, we need to find the first digit in our ending, which is less or equal to `digits[i-1]`: we have ending `5 7641` and we are looking for the next number with the same digits. What can go instead of `5`: it is `6`! Let us change these two digits, so we have `6 7541` now. Finally, we need to reverse last ditits to get `6 1457` as our ending.\\n\\n**Complexity**: time complexity is `O(m)`, where `m` is number of digits in our number, space complexity `O(m)` as well.\\n\\n**PS** see also problem **31. Next Permutation**, which uses exactly the same idea.\\n\\n```\\nclass Solution:\\n def nextGreaterElement(self, n):\\n digits = list(str(n))\\n i = len(digits) - 1\\n while i-1 \u003e= 0 and digits[i] \u003c= digits[i-1]:\\n i -= 1\\n \\n if i == 0: return -1\\n \\n j = i\\n while j+1 \u003c len(digits) and digits[j+1] \u003e digits[i-1]:\\n j += 1\\n \\n digits[i-1], digits[j] = digits[j], digits[i-1]\\n digits[i:] = digits[i:][::-1]\\n ret = int(\\'\\'.join(digits))\\n \\n return ret if ret \u003c 1\u003c\u003c31 else -1\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608720286, | |
| "creationDate": 1608720286 | |
| } | |
| }, | |
| { | |
| "id": 927899, | |
| "title": "[Python] Short dfs solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/binary-tree-tilt", | |
| "post": { | |
| "id": 1688619, | |
| "content": "Just traverse tree, using `dfs`, where we keep two values: sum of all tilts of current subtree and sum of nodes in current subtree. Then:\\n\\n1. If we in `None` node, we return `[0, 0]`: we do nat have any subtree and tilt.\\n2. Let `t1, s1` be tilt and sum of nodef for left subtree and `t2, s2` for right subtree. Then how we can ealuate final sum of tilts for given node: it is `abs(s1-s2)` plus tilts for its children. To evaluate sum of all values in subtree we just need to evaluate `s1+s2+node.val`.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(h)`.\\n\\n```\\nclass Solution:\\n def findTilt(self, root):\\n def dfs(node):\\n if not node: return [0,0]\\n t1, s1 = dfs(node.left)\\n t2, s2 = dfs(node.right)\\n return [t1+t2+abs(s1-s2), s1+s2+node.val]\\n return dfs(root)[0]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604823135, | |
| "creationDate": 1604823135 | |
| } | |
| }, | |
| { | |
| "id": 931664, | |
| "title": "[Python] Math, check diagonals, explained", | |
| "taskUrl": "https://leetcode.com/problems/valid-square", | |
| "post": { | |
| "id": 1695134, | |
| "content": "I will use function `check(p1, p2, p3, p4)`, which will check if we have a square with `p1--p2` being one diagonal and `p3--p4` being another diagonal. We need to check several properties to have square:\\n\\n1. First of all, every square is parallelogram, so middle points of both diagonals should be the same, so if they are not, we return `False`.\\n2. Second, diagonals should have equal length.\\n3. So far, if we have previous two properties, we can have rectangle, not square, so we need to check that pairs of adjacent sides are equal.\\n4. Finally, we need to make sure, that our square is not empty, that is its side is not equal to `0`, or `p1` not equal to `p2`.\\n\\nNow, we need to apply this function `3` times, because point `p1` must be in some diagonal and it has `3` different options how to choose second element for this diagonal:\\n\\n1. `p1--p2` and other diagonal `p3--p4`\\n2. `p1--p3` and other diagonal `p2--p4`\\n3. `p1--p4` and other diagonal `p2--p3`\\n\\n**Complexity** Time and space complexity is `O(1)`, however with quite big constant, around `54` arithmetical operations for time.\\n\\n```\\nclass Solution:\\n def validSquare(self, p1, p2, p3, p4):\\n def dist(p,q):\\n return (p[0]-q[0])**2 + (p[1]-q[1])**2\\n \\n def check(p1,p2,p3,p4):\\n if p1[0]+p2[0] != p3[0]+p4[0] or p1[1]+p2[1] != p3[1]+p4[1]: return False\\n if dist(p1,p2) != dist(p3,p4) or dist(p1,p4) != dist(p2,p4): return False\\n if p1 == p2: return False\\n return True\\n \\n return check(p1,p2,p3,p4) or check(p1,p3,p2,p4) or check(p1,p4,p2,p3)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605083139, | |
| "creationDate": 1605083139 | |
| } | |
| }, | |
| { | |
| "id": 960419, | |
| "title": "[Python] 2 lines, using groupby, explained", | |
| "taskUrl": "https://leetcode.com/problems/can-place-flowers", | |
| "post": { | |
| "id": 1745034, | |
| "content": "Let us consider several cases and underatand, what is going on:\\n1. Case, when we have empty cases in the start (or end), like `1..`, `01..`, `001..`, `0001..`, `00001..`, ... We can notice, that if we have `k` zeroes, than we can put no more than `k//2` flowers.\\n2. Case in the middle, like `..11..`, `..101..`, `..1001..`, `..10001..`, `..100001..`: in this case we can notice, tha we can put no more than `(k-1)//2` flowers in each group.\\n\\nHow to handle this two groups so they work in the same way? Add `0` to the beginning and to the end of our `flowerbed`. Next step is to use `groupby`: which will evaluate lengths of each group. Finally, we choose only `even` element from our list of lengths, for each element evaluate `(i-1)//2` maximum number of flowers we can plant into this group, sum them and check if this number is more or equal to `n`.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is also `O(n)`.\\n\\n```\\nclass Solution:\\n def canPlaceFlowers(self, flowerbed, n):\\n t = [len(list(j)) for i, j in groupby([0] + flowerbed + [0])]\\n return sum((i-1)//2 for i in t[0::2]) \u003e= n\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607156666, | |
| "creationDate": 1607156666 | |
| } | |
| }, | |
| { | |
| "id": 760266, | |
| "title": "[Python] 4 lines linear solution, detailed explanation", | |
| "taskUrl": "https://leetcode.com/problems/task-scheduler", | |
| "post": { | |
| "id": 1397053, | |
| "content": "This is quite difficult problem if you want to have optimal solution. First, I tried several ideas, using queue and greedy algorithm, where I tried to build sequence symbol by symbol, but it was working very slow and I get TLE. So, I decided to stop coding and to think. \\n\\nSo, what is the main trick? First of all notice, that what is matter, is frequence of each letter, not order.\\n For each letter we need to evaluate minimum window size we need to fully use this letter. For example, if we have `4` letters `A` in our tasks and `n = 3`, then minimum window looks like `A...A...A...A`. So, the minimum length in this case we need is `13 = (n+1) * 3 + 1`. Let us call this number 13 **characteristic** of letter `A`. More examples:\\n1. If `n = 4` and we have `BBBBB`, than **characteristic** of letter `B` is equal to `(n+1) * 4 + 1 = 21`.\\n2. If `n = 1` and we have `CC`, than **characteristic** of letter `C` is equal to `(n+1) * 1 + 1 = 3`.\\n\\nSo, we need to evaluate **characteristics** of all letters and just choose the maximum one? Similar, but not exaclty. What if we have two letters with the same **characteristic** (it means they have the same frequencies), like we have `AAAABBBB`. Then we need to have window `A...A...A...A` and also window `B...B...B...B`, and you can not put one inside another. So, in this case we need at least one symbol more, and example will be `AB..AB..AB..AB`.\\n\\nIn this problem we are asked, what is the **minimum** number of units we need to use, so, mathematicaly speaking, we need to do two steps:\\n\\n1. **Estimation:** prove, that we need at least say **k** units.\\n2. Give an **example** for this **k** units, how to construct desired sequence. (note, that in this problem you do not really ask to create example, but we still need to prove, that it exists).\\n\\nWe already considered **Estimation**: we need to find elements with the highest **characteristic** and check how many such elements we have. So, if `freq = Counter(tasks)` and `Most_freq = freq.most_common()[0][1]` is the element with highest frequency, than `Found_most = sum([freq[key] == Most_freq for key in freq])` is number of such elements and we return `max(len(tasks), (Most_freq - 1) * (n + 1) + Found_most)`, because we can not be shorter than `len(tasks)`.\\n\\nThe most difficult part is to prove that **example** exists. Let us consider case, where we have `AAAA`, `BBBB`, `n = 5` and also we have some letters. Then first step is to build:\\n\\n`AB....AB....AB....AB`\\n\\nWhat we know about other elements? Their frequencies are less than `Most_freq = 4`. So, let us start to fill dots in special order:\\n\\n`A B 1 4 7 10 A B 2 5 8 11 A B 3 6 9 12 A B`\\n\\nWhy we choose this order? Because for any `Most_freq - 2` elements with adjacent numbers, places will be at least `n` elements apart! So all we need to do is to fill elements with frequencies `Most_freq - 1` first, and then fill all the other empty places.\\n\\nThere is another case, where `(Most_freq - 1) * (n + 1) + Found_most \u003c len(tasks)`, for example when we have something like `AABBCCD`, `n = 2` In this case we can show that answer should be equal to `len(tasks)`. We again start with most with most common letters and try to form answer. However we can see, that we can not combine properly `A.A`, `B.B` and `C.C` like we did previously, so we combine them as `ABCABC`. The last step is to insert remaining letters between constructed string. It is not very strict explanation, but I hope it helps. \\n\\n**Complexity**: time complexity is `O(n)`, to evaluate `freq` and one more pass to find all elements with highest frequency. Then we just evaluate answer in constant time. Space complexity is `O(26)`, because there are `26` different letters.\\n\\n```\\nclass Solution:\\n def leastInterval(self, tasks, n):\\n freq = Counter(tasks)\\n Most_freq = freq.most_common()[0][1]\\n Found_most = sum([freq[key] == Most_freq for key in freq])\\n return max(len(tasks), (Most_freq - 1) * (n + 1) + Found_most)\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595941414, | |
| "creationDate": 1595929675 | |
| } | |
| }, | |
| { | |
| "id": 726732, | |
| "title": "[Python] 10 lines BFS, explained with figure", | |
| "taskUrl": "https://leetcode.com/problems/maximum-width-of-binary-tree", | |
| "post": { | |
| "id": 1340046, | |
| "content": "In this problem we need to find maximum width of binary tree, so we need to use some tree traversal algorithm. BFS or DFS? I prefer to use **BFS**, because it emulate level by level traversal. While we traverse we need to keep some information about our node: its `level`, but also its `num`, which is number in level if this level was full. So, let us keep 3 informations for each node: `[num, level, node]`. How we change this information, when we traverse tree? We increase level by `1`, and for `num`, for left children we evaluate `2*num` and for the right we evaluate `2*num + 1`. You can see how it works on the following tree (here in brackets I show 2 numbers : `[num, level]`. For example for node with `[num, level] = [5, 3]`, left children will have `[10, 4]` and right `[11, 4]`.\\n\\n\\n\\nSo, we traverse our tree, using **BFS**, keep this information. Also we have `level_old` and `num_old` variable, which keep information for the first (the most left) node on each level, using this values we can understand if new level is started, and if started, we update it and for each new node we can evaluate current width of traversing layer.\\n\\n**Complexity**: time complexity is `O(n)`, where `n` is number of nodes, because we traverse our tree, using bfs. Space complexity is `O(w)`, where `w` is the biggest number of nodes in level, because we need to keep our queue. Potentially it is equal to `O(n)`. If we use **DFS**, then space complexity will be `O(h)`, where `h` is height of tree.\\n\\n\\n\\n\\n```\\nclass Solution:\\n def widthOfBinaryTree(self, root):\\n level_old, num_old, max_width = 1, 1, 0\\n queue = deque([[level_old,num_old,root]])\\n\\n while queue: \\n [num, level, node] = queue.popleft()\\n if level \u003e level_old:\\n level_old, num_old = level, num\\n \\n max_width = max(max_width, num - num_old + 1)\\n if node.left: queue.append([num*2, level+1, node.left])\\n if node.right: queue.append([num*2+1,level+1, node.right])\\n \\n return max_width\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594281727, | |
| "creationDate": 1594281404 | |
| } | |
| }, | |
| { | |
| "id": 916196, | |
| "title": "[Python] Short O(n log n) solution, beats 100%, explained", | |
| "taskUrl": "https://leetcode.com/problems/number-of-longest-increasing-subsequence", | |
| "post": { | |
| "id": 1667994, | |
| "content": "The idea of my solution is to use so-called Patience sort: https://en.wikipedia.org/wiki/Patience_sorting\\n\\nThe idea is to keep several `decks`, where numbers in each deck are decreasing. Also when we see new card, we need to put it to the end of the leftest possible deck. Also we have `paths`: corresponing number of LIS, ending with given `num`. That is in `paths[0]` we keep number of LIS with length `1`, in `paths[k]` we keep number of LIS with length `k+1`. (we keep cumulative sums) Also we keep `ends_decks` list to have quick access to end of our decks.\\n\\n**Property**: It can be proved, that each LIS can be formed as choosing not more than one number from each deck and choosing them, looking at decks from left to right.\\n\\nImagine, that we have `nums = [1,3,5,4,7,10,8,2,8]`, then we have the following `decks` and `paths` step by step:\\n\\n`decks = [[-1]] paths = [[0, 1]]`\\n`decks = [[-1], [-3]] paths = [[0, 1], [0, 1]]`\\n`decks = [[-1], [-3], [-5]] paths = [[0, 1], [0, 1], [0, 1]]`\\n`decks = [[-1], [-3], [-5, -4]] paths = [[0, 1], [0, 1], [0, 1, 2]]`\\n`decks = [[-1], [-3], [-5, -4], [-7]] paths = [[0, 1], [0, 1], [0, 1, 2], [0, 2]]`\\n`decks = [[-1], [-3], [-5, -4], [-7], [-10]] paths = [[0, 1], [0, 1], [0, 1, 2], [0, 2], [0, 2]]`\\n`decks = [[-1], [-3], [-5, -4], [-7], [-10, -8]] paths = [[0, 1], [0, 1], [0, 1, 2], [0, 2], [0, 2, 4]]`\\n`decks = [[-1], [-3, -2], [-5, -4], [-7], [-10, -8]] paths = [[0, 1], [0, 1, 2], [0, 1, 2], [0, 2], [0, 2, 4]]`\\n`decks = [[-1], [-3, -2], [-5, -4], [-7], [-10, -8, -8]] paths = [[0, 1], [0, 1, 2], [0, 1, 2], [0, 2], [0, 2, 4, 6]]`\\n\\n\\nWe use negative numbers, so each deck is sorted in increasing way instead of decreasing.\\n\\nWhen we see new `num`, then we first find `deck_idx`: number of deck we need to put this `num`. Now, we want to find number of LIS, ending with this `num`: for this we need to look at previous deck and find the place of `num` inside this deck: here we use our **property**, we update our `n_path`.\\n\\nNow, we need to decide where we put this number:\\n1. If our `deck_idx` is equal to `len(decks)`, it means, that we need to create new `deck`: we create new deck with one element, update `ends_decks` and also append `n_paths` to our `paths`.\\n2. In opposite case, we need to add `nums` to the end of corresponding deck, again update `ends_decks` and update our `pathcs[deck_idx]`: it will consist of two parts: `n_paths`: number of paths, such that previous element is from previous or before decks. Also we have `paths[deck_idx][-1]`, because we keep cumulative sums inside.\\n\\nFinally, we return `paths[-1][-1]`, it is number of LIS with the biggest length.\\n\\n**Complexity** is `O(n log n)`, because for each new `num` we process it in `O(log n)`. Space complexity is `O(n)`. When I run it, i have times, I have times from 60ms to 72ms, where `60`ms beats 100% of python solutions.\\n\\n```\\nclass Solution:\\n def findNumberOfLIS(self, nums):\\n if not nums: return 0\\n \\n decks, ends_decks, paths = [], [], []\\n for num in nums:\\n deck_idx = bisect.bisect_left(ends_decks, num)\\n n_paths = 1\\n if deck_idx \u003e 0:\\n l = bisect.bisect(decks[deck_idx-1], -num)\\n n_paths = paths[deck_idx-1][-1] - paths[deck_idx-1][l]\\n \\n if deck_idx == len(decks):\\n decks.append([-num])\\n ends_decks.append(num)\\n paths.append([0,n_paths])\\n else:\\n decks[deck_idx].append(-num)\\n ends_decks[deck_idx] = num\\n paths[deck_idx].append(n_paths + paths[deck_idx][-1])\\n \\n return paths[-1][-1]\\n```\\n\\n**Shorter version** it can be written in shorter version, if we prefill our `decks`, `decks_ends` and `paths` first. However I do no know if we can do binary search in python by **key**: if we can, we can remove `ends_decks` at all and simplify it even more. Can somebody help me with it?\\n```\\nclass Solution:\\n def findNumberOfLIS(self, nums):\\n if not nums: return 0\\n n = len(nums) + 1\\n \\n decks, ends_decks, paths = [[] for _ in range(n)], [float(\"inf\")]*n, [[0] for _ in range(n)]\\n for num in nums:\\n idx = bisect.bisect_left(ends_decks, num)\\n n_paths = 1\\n if idx \u003e 0:\\n l = bisect.bisect(decks[idx-1], -num)\\n n_paths = paths[idx-1][-1] - paths[idx-1][l]\\n \\n decks[idx].append(-num)\\n ends_decks[idx] = num\\n paths[idx].append(n_paths + paths[idx][-1])\\n \\n return paths[paths.index([0]) - 1][-1]\\n```\\n\\n\\n**PS**: see also my solution of problem 300: Longest Increasing Subsequence: https://leetcode.com/problems/longest-increasing-subsequence/discuss/667975/Python-3-Lines-dp-with-binary-search-explained\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604051547, | |
| "creationDate": 1604048207 | |
| } | |
| }, | |
| { | |
| "id": 688273, | |
| "title": "[Python] Intuitive recursive solution, O(h), explained", | |
| "taskUrl": "https://leetcode.com/problems/search-in-a-binary-search-tree", | |
| "post": { | |
| "id": 1271795, | |
| "content": "This is exercise to undertand what is Binary Search Tree and how it works. Remember, that **left** subtree is always lesser than root and **right** subtree is always bigger than root.\\nSo, what we need to do? We start from the root of our tree and compare value in its root. If value we are looking is **less** than value in root, we go left, if it is **more**, we go to the right. When we stop? Either if we found place, where these two values are equal, or we reached NULL leaf (it means we visited leaf and descended to its NULL children). In this cases we save found node to global variable, which we return in the end.\\n\\n**Complexity**, both time and space is `O(h)`, where `h` is heigth of our tree.\\n\\n**Remark**: I used `helper` function, which is not necessary here, but in this way the code is more universal for different trees traversal problems, where you need to return more difficult objects. \\n\\n```\\nclass Solution:\\n def helper(self, root):\\n if not root or root.val == self.val: \\n self.Found = root\\n return root\\n \\n if root.val \u003c self.val:\\n return self.helper(root.right)\\n \\n if root.val \u003e self.val:\\n return self.helper(root.left)\\n \\n def searchBST(self, root, val):\\n self.val = val\\n self.Found = None\\n self.helper(root)\\n return self.Found\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592206266, | |
| "creationDate": 1592205653 | |
| } | |
| }, | |
| { | |
| "id": 881677, | |
| "title": "[Python] O(h) recursive solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/insert-into-a-binary-search-tree", | |
| "post": { | |
| "id": 1607514, | |
| "content": "What we need to do in this problem is just traverse our tree and find the correct place for our new value:\\n\\n1. If we have `val \u003c root.val`, we need to go left: if it is possible, we go left; if left children is not existing, then we create it with `val` value.\\n2. If we have `val \u003e root.val`, we need to go right: if it is possible, we go right; if right children is not existing, then we create it with `val` value.\\n\\nFinally, we run our `dfs` function from `root` and return `root`.\\n\\n**Complexity** time and space complexity is `O(h)`, where `h` is height of our tree.\\n\\n```\\nclass Solution:\\n def insertIntoBST(self, root, val):\\n def dfs(root):\\n if val \u003c root.val:\\n if root.left:\\n dfs(root.left)\\n else:\\n root.left = TreeNode(val)\\n else:\\n if root.right:\\n dfs(root.right)\\n else:\\n root.right = TreeNode(val)\\n \\n if not root: return TreeNode(val)\\n dfs(root)\\n return root\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601973618, | |
| "creationDate": 1601973618 | |
| } | |
| }, | |
| { | |
| "id": 884759, | |
| "title": "[Python] very simple solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/binary-search", | |
| "post": { | |
| "id": 1612831, | |
| "content": "We just need to do what is asked in the name of this problem: binary search! Also we need to find index of found element, so we check `3` conditions: `nums[mid] == target`, `nums[mid] \u003c target` and `nums[mid] \u003e target`.\\n\\n\\n**Complexity** is `O(log n)`, classical complexity of binary search, because on each step we reduce searching region twice.\\n\\n```\\nclass Solution:\\n def search(self, nums, target):\\n beg, end = 0, len(nums) - 1\\n while beg \u003c= end:\\n mid = (beg + end)//2\\n if nums[mid] == target: return mid\\n if nums[mid] \u003c target:\\n beg = mid + 1\\n else:\\n end = mid - 1\\n return -1\\n```", | |
| "updationDate": 1602146497, | |
| "creationDate": 1602146497 | |
| } | |
| }, | |
| { | |
| "id": 768659, | |
| "title": "[Python] Easy Multiplicative Hash, explained", | |
| "taskUrl": "https://leetcode.com/problems/design-hashset", | |
| "post": { | |
| "id": 1411563, | |
| "content": "The goal of this problem is to create simple hash function, not using build-in methods. One of the simplest, but classical hashes are so-called **Multiplicative hashing**: https://en.wikipedia.org/wiki/Hash_function#Multiplicative_hashing.\\nThe idea is to have hash function in the following form.\\n\\n\\nHere we use the following notations:\\n1. `K` is our number (key), we want to hash.\\n2. `a` is some big odd number (sometimes good idea to use prime number) I choose `a = 1031237` without any special reason, it is just random odd number.\\n3. `m` is length in bits of output we wan to have. We are given, that we have no more than `10000` operations overall, so we can choose such `m`, so that `2^m \u003e 10000`. I chose `m = 15`, so in this case we have less collistions.\\n4. if you go to wikipedia, you can read that `w` is size of machine word. Here we do not really matter, what is this size, we can choose any `w \u003e m`. I chose `m = 20`.\\n\\nSo, everything is ready for function `eval_hash(key)`: `((key*1031237) \u0026 (1\u003c\u003c20) - 1)\u003e\u003e5`. Here I also used trick for fast bit operation modulo `2^t`: for any `s`: `s % (2^t) = s \u0026 (1\u003c\u003ct) - 1`.\\n\\nHow our `HashSet` will look and work like:\\n1. We create list of empty lists `self.arr = [[] for _ in range(1\u003c\u003c15)]`. \\n2. If we want to `add(key)`, then we evaluate hash of this key and then add this `key` to the place `self.arr[t]`. However first we need to check if this element not it the list. Ideally, if we do not have collisions, length of all `self.arr[i]` will be `1`. \\n3. If we want to `remove(key)` element, we first evaluate it hash, check corresponding list, and if we found element in this list, we remove it from this list.\\n4. Similar with `contains(key)`, just check if it is in list.\\n\\n**Complexity**: easy question is about space complexity: it is `O(2^15)`, because this is the size of our list. We have a lot of empty places in this list, but we still need memory to allocate this list of lists. Time complexity is a bit tricky. If we assume, that probability of collision is small, than it will be in average `O(1)`. However it really depends on the size of our `self.arr`. If it is very big, probability is very small. If it is quite tight, it will increase. For example if we choose size `1000000`, there will be no collisions at all, but you need a lot of memory. So, there will always be trade-off between memory and time complexity.\\n\\n```\\nclass MyHashSet: \\n def eval_hash(self, key):\\n return ((key*1031237) \u0026 (1\u003c\u003c20) - 1)\u003e\u003e5\\n\\n def __init__(self):\\n self.arr = [[] for _ in range(1\u003c\u003c15)]\\n\\n def add(self, key: int) -\u003e None:\\n t = self.eval_hash(key)\\n if key not in self.arr[t]:\\n self.arr[t].append(key)\\n\\n def remove(self, key: int) -\u003e None:\\n t = self.eval_hash(key)\\n if key in self.arr[t]:\\n self.arr[t].remove(key)\\n\\n def contains(self, key: int) -\u003e bool:\\n t = self.eval_hash(key)\\n return key in self.arr[t]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596359152, | |
| "creationDate": 1596359152 | |
| } | |
| }, | |
| { | |
| "id": 868623, | |
| "title": "[Python] 2 pointers O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/subarray-product-less-than-k", | |
| "post": { | |
| "id": 1585281, | |
| "content": "It is given that all numbers are natural, that is they are more or equal than `1`. The idea is to use two pointers (or sliding window) approach, where at each moment of time we try to extend our window. Let us `beg, end-1` be the beginning and end of our window (it means that if `beg=end=0`, our window is empty), `P` is current product of numbers in our window and `out` is our answer we need to return.\\n\\nOn each iteration, we extend our window by one number to the right: however we need to check first, that the product do not exceed `k`. So, we remove numbers from the beginning of our window, until product is less then `k`. Note also, that we can not have `end \u003c beg`, so we break if it is the case: it means than our window becomes empty. Finally, we update `out += end - beg + 1`: this is number of subarrays ending with `end` with product less than `k`.\\n\\n**Complexity**: time complexity is `O(n)`, because on each step we increase either `beg` or `end`. Space complexity is `O(1)`. \\n\\n```\\nclass Solution:\\n def numSubarrayProductLessThanK(self, nums, k):\\n out, beg, end, P = 0, 0, 0, 1\\n while end \u003c len(nums):\\n P *= nums[end]\\n while end \u003e= beg and P \u003e= k:\\n P /= nums[beg]\\n beg += 1\\n out += end - beg + 1\\n end += 1\\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601279648, | |
| "creationDate": 1601279648 | |
| } | |
| }, | |
| { | |
| "id": 904118, | |
| "title": "[Python] Stack O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/asteroid-collision", | |
| "post": { | |
| "id": 1646888, | |
| "content": "Let us traverse our asteroids from left to right and keep in stack so-called `stable` set: it means, that the will be no collisions anymore in our stack. What happen, when we add new asteroid: there can be `3` main cases:\\n\\n1. If we have in stack `[....7]` and we add `-3`, then this last asteroid is destroyed, which is the last one: so if we have `stack[-1] + stack[-2] \u003e 0`, then we pop the last element fro our stack.\\n2. If we have in stack `[....3]` and we add `-7`, then asteroid with weight `3` is destroyed: so we need to pop one elements before last from our stack.\\n3. If we have in stack `[....3]` and we add `-3`, then both these two asteroids is destroyed: we remove two last elements from our stack.\\n\\n**Complexity**: time complexity is `O(n)`, because for each asteroid, we can either put or remove it from stack once (not also that we sometimes remove not last element, but one before last, but complexity of this operation is still `O(1)`. Space complexity is also can be potentially as big as `O(n)`.\\n\\n```\\nclass Solution:\\n def asteroidCollision(self, asteroids):\\n stack = []\\n for ast in asteroids:\\n stack.append(ast)\\n while len(stack) \u003e 1 and stack[-1] \u003c 0 and stack[-2] \u003e 0:\\n if stack[-1] + stack[-2] \u003c 0: stack.pop(-2)\\n elif stack[-1] + stack[-2] \u003e 0: stack.pop()\\n else:\\n stack.pop(); stack.pop()\\n break\\n \\n return stack\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603270588, | |
| "creationDate": 1603270588 | |
| } | |
| }, | |
| { | |
| "id": 990399, | |
| "title": "[Python] Math O(1) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/reach-a-number", | |
| "post": { | |
| "id": 1795305, | |
| "content": "Let us look at several first steps and understand, which numbers we can reach.\\n\\n1. `n = 1`, numbers we can reach are `-1, 1`\\n2. `n = 2`, numbers we can reach are `-3, -1, 1, 3`.\\n3. `n = 3`, numbers we can reach are `-6, -4, -2, 0, 2, 4, 6`\\n4. `n = 4`, numbers we can reach are `-10, -8, -6, -4, -2, 0, 2, 4, 6, 8, 10`\\n5. `n = 5`, numbers we can reach are `-15, -13, ..., 13, 15`\\n6. `n = 6`, numbers we can reach are `-21, -19, ..., 19, 21`\\n\\nWhat we can notice looking at these numbers are 2 things:\\n1. We always have continious range either in odd or in even numbers.\\n2. We have `odd -\u003e even -\u003e even -\u003e odd` period, depending on `n`. How we can get it? Sum of numbers from `1` to `n` is `n*(n+1)/2` and parity of number depends only on this number and will not change if we replace some of `+` to `-`.\\n\\nSo, we need to find smallest integer. `n`, such that `n*(n+1)/2 \u003e= target`, or `n^2 + n - 2*target \u003e= 0`. This can solved as quadratic equation with solution `bound = ceil(sqrt(2*abs(target)+0.25) - 0.5)`. Also we need to fix odd/even of our number. If we have `bound = 10` for example and even `target`, we need to choose `bound = 11`: smallest bound more or equal to `10`, such that final answer can be even. Similarly we need to check all other cases.\\n\\n**Complexity**: if we assume that we can take `sqrt` in `O(1)` complexity, then all complexity of algorithm is `O(1)`, both for time and space.\\n\\n```\\nclass Solution:\\n def reachNumber(self, target):\\n bound = ceil(sqrt(2*abs(target)+0.25) - 0.5)\\n if target % 2 == 0:\\n if bound % 4 == 1: bound += 2\\n if bound % 4 == 2: bound += 1\\n else:\\n if bound % 4 == 3: bound += 2\\n if bound % 4 == 0: bound += 1\\n \\n return bound\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1609181821, | |
| "creationDate": 1609150104 | |
| } | |
| }, | |
| { | |
| "id": 828031, | |
| "title": "[Python] Greedy O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/partition-labels", | |
| "post": { | |
| "id": 1514519, | |
| "content": "The idea of this solution is greedily construct our partition, let us consider the example\\n`S = ababcbacdefegdehijhklij`. We need to start with letter `a` and we can not stop, until we reach the last occurence of `a`: so, we need to take `ababcba` part at least. But if we take this part, we need to consider letters `b` and `c` as well and also traverse our string until we meet the last occurence of these letters, so we need to take `ababcbac`. Here we can stop, because we already take into account all symbols inside this string. So, we go to the next symbol and repeat our partition. So, what we have in my code:\\n\\n1. First, we need to know all ends for each letter in advance, I call it `ends`.\\n2. Also, `curr` is current index and `last` is index we need to traverse until. For each group of symbols we need to do: `last = ends[S[curr]]`: we find the place we need to traverse; while we do no reach this place, we look at the next symbol and update our `last`. So, we stop, when `curr` become greater than `last`.\\n3. We add `curr` to our `out` result. \\n4. Note, that we need to have `[8,7,8]` for our example, but we get `[8,15,23]`, places where our partitions are. So, we evaluate differences `8-0`, `15-8`, `23-15` and return them.\\n\\n**Complexity**: time complexity is `O(n)`, we traverse our string twice: one time when we evaluate `ends` and second time when we do partitions. Space complexity is `O(26)`: to keep our `ends` (also we have answer, but it can not be greater than `26` as well).\\n\\n```\\nclass Solution:\\n def partitionLabels(self, S):\\n ends = {c: i for i, c in enumerate(S)} \\n curr, out = 0, [0]\\n \\n while curr \u003c len(S):\\n last = ends[S[curr]]\\n while curr \u003c= last:\\n symb = S[curr]\\n last = max(last, ends[symb])\\n curr += 1\\n out.append(curr)\\n \\n return [out[i]-out[i-1] for i in range(1, len(out))]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599217144, | |
| "creationDate": 1599208568 | |
| } | |
| }, | |
| { | |
| "id": 686906, | |
| "title": "[Python] Multipass BFS O(V^2) + Dijkstra with SortedList, explained", | |
| "taskUrl": "https://leetcode.com/problems/cheapest-flights-within-k-stops", | |
| "post": { | |
| "id": 1269266, | |
| "content": "There are a lot of different ways to handle this problem: using DFS, BFS, Dijkstra, Bellman-Ford, Dynamic programming. For me it is easier to use **BFS**, because we are asked to find the shortest distance between two given cities, not with all `dst` like in Dijkstra or Bellman-Ford. \\n\\n**BFS** the idea is to traverse our graph in usual bfs routine and also take into account that we can have maximum `k` stops, that is our pathes should have length less or equal than `k + 1`. To implement bfs in python usual way is to use deque (double ended queue), it works pretty fast in python. We can not use usual list like in dfs (for similate stack), because here we need to pop elements from the beginning of our queue.\\n\\nWe need to keep in each cell of our queue `3` values: current `city`, current number of `visited` cities and current `price`. It is worth to investigate new city if 3 conditions met:\\n1. Our current price is less or equal to minumum price found so far.\\n2. If we still can visit one more city, `visited \u003c k+1`.\\n3. The current city is not our destination yet.\\n\\nIf we reached our city of destination, we update minimum price we get so far.\\n\\n**Complexity**, both time and memory of bfs is `O(V + E)`, where `E` is number of edges and `V` is number of vertices. Note however, that we have here multipass bfs, when we visit node, we do not mark it as visited, and we can visit it several times. In fact this algorighm is very similar to Dijkstra algorighm, and I think complexity is `O(E + V^2) = E(V^2)`, because we traverse each edge only once, but we can visit nodes a lot of times. **Update** I do no think it is quite true, need to be checked.\\n\\n\\n```\\nclass Solution:\\n def findCheapestPrice(self, n, flights, src, dst, k):\\n graph = defaultdict(list)\\n deque_vert = deque([[src, 0, 0]])\\n min_price = float(\\'inf\\')\\n \\n for i, j, w in flights: \\n graph[i].append([j, w])\\n\\n while deque_vert:\\n city, visited, price = deque_vert.popleft()\\n\\n if price \u003c= min_price and visited \u003c= k and city != dst:\\n for neibh, price_neibh in graph[city]:\\n deque_vert.append([neibh, visited + 1, price + price_neibh])\\n \\n if city == dst:\\n min_price = min(min_price, price)\\n \\n return min_price if min_price != float(\\'inf\\') else -1\\n```\\n\\n### Dijkstra \\n\\nThere is better complexity time solution (however we need bigger tests to check it).\\nI was wonderig is it possible to use `SortedList`, instead of `Heap` in Dijkstra algorighm, and the answer is yes! What we need to do is to pop the smallest element and to insert into our list in logarighmic time. Here we need to keep `2`-dimensional table `dist` for shortest distances with given length of path. \\n\\n**Complexity** I think it is `O(E+(Vk)*log(Vk))`, because there will be no more than `Vk` different elements in our SortedList (Heap) at any moment.\\n\\n```\\nclass Solution:\\n def findCheapestPrice(self, n, flights, src, dst, k):\\n graph = defaultdict(list)\\n dist = [[float(\"inf\")] * (k+2) for _ in range(n)] \\n dist[src][0] = 0\\n\\n SList = SortedList([[0, 0, src]])\\n \\n for i, j, w in flights: \\n graph[i].append([j, w])\\n \\n while SList:\\n price, visited, city = SList.pop(0)\\n\\n if city == dst: return price\\n \\n if visited \u003c= k:\\n for neibh, price_neibh in graph[city]: \\n candidate = dist[city][visited] + price_neibh\\n if candidate \u003c= dist[neibh][visited + 1]:\\n dist[neibh][visited + 1] = candidate\\n SList.add([price + price_neibh, visited + 1, neibh])\\n \\n return -1\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592161536, | |
| "creationDate": 1592127567 | |
| } | |
| }, | |
| { | |
| "id": 752481, | |
| "title": "[Python] Simple dfs backtracking, explained", | |
| "taskUrl": "https://leetcode.com/problems/all-paths-from-source-to-target", | |
| "post": { | |
| "id": 1384081, | |
| "content": "First thing we need to notice, when we see this problem, that number of nodes is very small, it is in `[2,15]` range. It usually means, that we need to implement some bruteforce algorighm. What is also given, that our graph do not have any loops, which will make our life easier. Let us use function `dfs(formed)`, where `formed` is path created so far.\\n1. We need to stop and add `formed` to list of solutions `sol` if we reached the target.\\n2. If we did not reach it, then for all children of last element, we run `dfs(formed + [child])`.\\n3. Finally, we run our `dfs` function for `dfs([0])`.\\n\\n**Complexity**: Let us consider the case of graph on `n` nodes, where any node from `i` to `j` exists, where `i\u003cj`. For example for `n=4`, we have `graphs = [[1,2,3,4],[2,3,4],[3,4],[4],[]]`. How many paths we have it his case? It is exactly `2^(n-1)`, because for any number from `1` to `n-1` you can either visit this node or not. For `n=4` we have the following pathes:\\n`[0,4],[0,1,4],[0,2,4],[0,3,4],[0,1,2,4],[0,1,3,4],[0,2,3,4],[0,1,2,3,4]`. Also for each path has in average `O(n)` elements. So, overall time and space complexity in this case is `O(n 2^n)`.\\n\\n**Further improvements** The main problem of this method is that is we have some dead-end, we do extra-job, checking options, which can not lead to success. I think, one possible improvement is to do topological sort of our data first and try to remove dead-ends, but I am not sure.\\n\\n```\\nclass Solution:\\n def allPathsSourceTarget(self, graph): \\n def dfs(formed):\\n if formed[-1] == n - 1:\\n sol.append(formed)\\n return \\n for child in graph[formed[-1]]:\\n dfs(formed + [child])\\n \\n sol, n = [], len(graph) \\n dfs([0])\\n return sol\\n```\\n\\nIf you have any questoins, feel free to ask. If you like the solution and explanation, please **upvote!**", | |
| "updationDate": 1595580557, | |
| "creationDate": 1595580557 | |
| } | |
| }, | |
| { | |
| "id": 910867, | |
| "title": "[Python] O(R^2) simulation, explained", | |
| "taskUrl": "https://leetcode.com/problems/champagne-tower", | |
| "post": { | |
| "id": 1658939, | |
| "content": "What we need to do in this problem is to simulate our pouring process: imagine, that we have `6` cups of water arrived at some place, then one full cup is left on this place and `2.5` cups go to the right bottom and left bottom cups. What we need to do now is to simulate this process!\\n\\n1. We start with `l = [poured]` - top layer\\n2. Then we process full current layer to create next layer. We need to check if we have enough champagne: if we have less than `1`, this cup is dead-end. If it has more than `1`, then we add values to bottom layer.\\n\\n**Complexity**: time complexity is `O(R^2)`, where `R = query_row`, space complexity is `O(R)`.\\n\\n```\\nclass Solution:\\n def champagneTower(self, poured, query_row, query_glass):\\n l = [poured]\\n for _ in range(query_row):\\n l_new = [0] * (len(l) + 1)\\n for i in range(len(l)):\\n pour = (l[i] - 1)/2\\n if pour \u003e 0:\\n l_new[i] += pour\\n l_new[i+1] += pour\\n \\n l = l_new\\n \\n return min(1, l[query_glass])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603705250, | |
| "creationDate": 1603705250 | |
| } | |
| }, | |
| { | |
| "id": 944921, | |
| "title": "[Python] Just use set, explained", | |
| "taskUrl": "https://leetcode.com/problems/unique-morse-code-words", | |
| "post": { | |
| "id": 1718047, | |
| "content": "Nothing very special about this problem: we just need to iterate through our `words` and for each of them build string. It is actually can be done even in one line (not including `alphabet`) if we use double comperehsions, but this is up to you if you like oneliners.\\n\\n**Complexity**: time and space complexity is `O(n*k)`, where `n` is number of words and `k` average is length of each word and we note that length of each encoding is not more than `4`. Space complexity is `O(n*k)` as well.\\n\\n```\\nclass Solution:\\n def uniqueMorseRepresentations(self, words):\\n alphabet = [\".-\",\"-...\",\"-.-.\",\"-..\",\".\",\"..-.\",\"--.\",\"....\",\"..\",\".---\",\"-.-\",\".-..\",\"--\",\"-.\",\"---\",\".--.\",\"--.-\",\".-.\",\"...\",\"-\",\"..-\",\"...-\",\".--\",\"-..-\",\"-.--\",\"--..\"]\\n ans = []\\n for word in words:\\n ans.append(\"\".join(alphabet[ord(s)-ord(\"a\")] for s in word))\\n return len(set(ans))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606033975, | |
| "creationDate": 1606033975 | |
| } | |
| }, | |
| { | |
| "id": 800051, | |
| "title": "[Python] Just do what is asked, explained", | |
| "taskUrl": "https://leetcode.com/problems/goat-latin", | |
| "post": { | |
| "id": 1465242, | |
| "content": "This is easy prolem, where you need just to do what is asked, without really thinking.\\n\\n1. Split our sentence into words, using `.split()`. If it is not allowed we can just traverse it and find spaces.\\n2. For every word check if it starts with vowel, if it is, add `ma` and `i+1` letters `a` to the end. It is `i+1`, because we start from zero index.\\n3. If first letter is not vowel, remove first letter and add it to the end, also add `ma` and letters `a`.\\n\\n**Complexity**: time and space complexity is `O(n) + O(k^2)`, where `n` is number of symbols in our string and `k` is number of words: do not forget about letters `a` in the end: we add `1 + 2 + ... + k = O(k^2)` letters in the end.\\n\\n```\\nclass Solution:\\n def toGoatLatin(self, S):\\n words = S.split()\\n vowels = set(\"AEIOUaeiou\")\\n for i in range(len(words)):\\n if words[i][0] in vowels:\\n words[i] = words[i] + \"ma\" + \"a\"*(i+1)\\n else:\\n words[i] = words[i][1:] + words[i][0] + \"ma\" + \"a\"*(i+1)\\n \\n return \" \".join(words)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597838526, | |
| "creationDate": 1597822450 | |
| } | |
| }, | |
| { | |
| "id": 930392, | |
| "title": "[Python] Oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/flipping-an-image", | |
| "post": { | |
| "id": 1692976, | |
| "content": "Let us do exactly what is asked in this problem: for each row: flip the image horizontally, then invert it. Quick way to get `0` from `1` and `1` from `0` is to use `1^q` (however tests are so small, so difference is not very big).\\n\\n**Complexity**: time complexity is `O(mn)`, where `m`, `n` are sizes of image. Space complexity is also `O(mn)` if we count output and `O(1)` space if we do not count. Note, that if we allowed to modify original image, than we can have `O(1)` space.\\n\\n```\\nclass Solution:\\n def flipAndInvertImage(self, A):\\n return [[1^q for q in row[::-1]] for row in A]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604996041, | |
| "creationDate": 1604996041 | |
| } | |
| }, | |
| { | |
| "id": 832150, | |
| "title": "[Python] 2 lines, using convolutions, explained", | |
| "taskUrl": "https://leetcode.com/problems/image-overlap", | |
| "post": { | |
| "id": 1521122, | |
| "content": "If you have some data science backgroud, as I have, then it is not difficult to think about convolutions, when you see this problem. Let me remind you, what 2d convolution is: this is special operations between matrices, which use the notion of sliding window. For each window we need to evaluate sum of products of all elements in this window and the second matrix, which is called **filter**. For example for thise red matrix we have `1*1 + 0*0 + 0*1 + 1*0 + 1*1 + 0*0 + 1*1 + 1*0 + 1*1 = 4`. \\n\\n\\n\\nNow, notice, that each value in the resulting matrix will show how many overlaps we have for shifted image! However there is couple of points we need to deal with:\\n\\n1. Let as add a lot of zeros to the `B` matrix: by this I mean, if it had `n x n` size, let us make it `3n x 3n` with original matrix `B` in the middle and zeroes outside. Why we need this? Because we need to consider all possible shifts, including `n` shift to the right, left, up and down.\\n2. Also, I want to use `scipy.ndimage` library, which have `convolve` function, exactly what we need. But before we use it, we need to rotate image `A` by `180` degrees! This step was not obvious for me, but this is because convolution is defined a bit different in different sources.\\n3. Finally, we return maximum of resulting matrix.\\n\\n**Complexity**: Let `n` be size of images. Then to evaluate one element of resulting image we need to make `n^2` multiplications and summations. We have `O(n^2)` elements in the end, so we have `O(n^4)` complexity. Memory is `O(n^2)`.\\n\\n```\\nfrom scipy.ndimage import convolve\\nimport numpy as np\\n\\nclass Solution:\\n def largestOverlap(self, A, B):\\n B = np.pad(B, len(A), mode=\\'constant\\', constant_values=(0, 0))\\n return np.amax(convolve(B, np.flip(np.flip(A,1),0), mode=\\'constant\\'))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599381512, | |
| "creationDate": 1599381342 | |
| } | |
| }, | |
| { | |
| "id": 937652, | |
| "title": "[Python] one pass, O(1) space, explained", | |
| "taskUrl": "https://leetcode.com/problems/longest-mountain-in-array", | |
| "post": { | |
| "id": 1705588, | |
| "content": "Let us traverse our numbers and keep two variables: `state` and `length`, where:\\n1. `state` is current state of our mountain: it is `0` in the beginning and also means that we can not start our mountain from given index. `state` equal to `1` means, that we are on increasing phase of our mountain and `state` equal `2` means, that we are on decreasing phase of our mountain.\\n2. `length` is current length of mountain built so far.\\n\\nNow, we need to carefully look at our states and see what we need to do in one or another situation:\\n1. If `state` is equal to `0` or `1` and next element is more than current, it means we can continue to build increasing phase of mountain: so, we put `state` equal to `1` and increase `length` by `1`.\\n2. If `state` is equal to `2` and next element is more then curren, it means, that previous mountain just finished and we are currently buildind next mountain, for examle in `0,1,0,2,0`: first mountain is `0,1,0` and second is `0,2,0`. In this case we already build `2` elements of new mountain (mountains have `1` common element), so we put `length = 2` and `state = 1`.\\n3. If `state` is equal to `1` or `2` and next element is less than current, it means that we are on the decreasing phase of mountain: we put `state = 2` and also increase `length` by `1`. Note, that only here we need to update `max_len`, because our mountain is legible on this stage.\\n4. Finally, if we have some other option: it is either next element is equal to current, or we have state `0` and next element is less than previous, we need put our `state` and `length` to values as we just started.\\n\\n**Complexity**: time complexity is `O(n)`, we make one pass over data, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def longestMountain(self, A):\\n n, max_len = len(A), 0\\n state, length = 0, 1\\n for i in range(n-1):\\n if state in [0, 1] and A[i+1] \u003e A[i]:\\n state, length = 1, length + 1\\n elif state == 2 and A[i+1] \u003e A[i]:\\n state, length = 1, 2\\n elif state in [1, 2] and A[i+1] \u003c A[i]:\\n state, length = 2, length + 1\\n max_len = max(length, max_len)\\n else:\\n state, length = 0, 1\\n \\n return max_len\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605518822, | |
| "creationDate": 1605518822 | |
| } | |
| }, | |
| { | |
| "id": 914844, | |
| "title": "[Python] O(n) solution, using groupby, explained", | |
| "taskUrl": "https://leetcode.com/problems/maximize-distance-to-closest-person", | |
| "post": { | |
| "id": 1665704, | |
| "content": "What we need to do in this problem is to find the person with maximum distance to closest person. Imagine, that we have something like:\\n`000100000111000100001000000`.\\nThen we need to look at groups of zeroes we have and:\\n1. For the very left and for the very right groups fo zeroes we need to evaluate size of this groups: for example here we have `3` zeroes for the left group and `6` zeroes for the right group.\\n2. For the groups of zeroes in the middle, the distance to closest person is (k + 1)//2, where `k` is number of zeroes in this group. For example for group of `5` zeroes we have `1000001`, and the optimal way is to put person in the middle: `1001001`. If we have `4` zeroes: `100001`, we can put person in one of the two places in the middle: `101001` or `100101`.\\n\\nWhat we need to do now is just use python `groupby` function and for each group evaluate the optimal position.\\n\\n**Complexity**: Time complexity is `O(n)` to use groupby, which iterate over our data. Space complexity is also `O(n).\\n\\n```\\nclass Solution:\\n def maxDistToClosest(self, seats):\\n out = max(seats[::-1].index(1), seats.index(1))\\n for seat, group in groupby(seats):\\n if seat: continue\\n out = max(out, (len(list(group))+1)//2)\\n\\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603960341, | |
| "creationDate": 1603960341 | |
| } | |
| }, | |
| { | |
| "id": 938792, | |
| "title": "[Python] Oneliner solution with diagram, explained", | |
| "taskUrl": "https://leetcode.com/problems/mirror-reflection", | |
| "post": { | |
| "id": 1707495, | |
| "content": "The idea of this problem, instead of reflecting our ray, we will look at it from the point of view of our ray, which is straight line: see the following image for better understanding.\\n\\n\\n\\n\\nHow we can find what we need to return: `0`, `1` or `2`:\\n1. If both number of reflections of our room are even, like in our image, we need to return 1.\\n2. If horizontal line of reflections is odd and vertical is even, we need to return `0`.\\n3. If horizontal line of reflections is even and vertical is odd, we need to return `2`.\\n4. Note, that it can not happen that both number are even, than we have one angle before, if we divide these two numbers by 2.\\n\\nFinally, all this can be written in oneliner as follow:\\n\\n**Complexity**: time and space complexity is `O(1)` if we assume that we can find `gcd` in `O(1)` time (which is true for int32 numbers). If you want to be more mathematically correct, it is `O(log n)`.\\n\\n```\\nclass Solution:\\n def mirrorReflection(self, p, q):\\n return (q//gcd(p,q)%2 - p//gcd(p,q)%2 + 1)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605601335, | |
| "creationDate": 1605601335 | |
| } | |
| }, | |
| { | |
| "id": 891021, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/buddy-strings", | |
| "post": { | |
| "id": 1623801, | |
| "content": "Let us carefully cover all possible cases in this problem:\\n1. If lengths of strings are different, we immedietly return `False`.\\n2. If counters of strings are different, we also return `False`.\\n3. Let us also evaluate for each place if symbols in `A` and `B` are equal. We can afford to have only `2` symbols which are not equal or `0`: in first case we change two different symbols and in second two equal. So, if number of not equal symbols is not `0` or `2`, we return `False`.\\n4. Also, if we have number `diff_places == 0`, it means that we changed two equal symbols. We can not do it if all string has different symbols, like `abtlpe`, so we return `False` in this case.\\n5. If we have `diff_places == 2`, it means that we changed two different symbols. We can not do it if string is just one symbols repeated, like `ddddddd`, so we return `False` in this case.\\n6. Finally, if we did not return anything yet, we return `True`.\\n\\n**Complexity** is `O(n)`, because we use counters, which is linear and number of not equal symbols which is linear as well.\\n\\n```\\nclass Solution:\\n def buddyStrings(self, A, B):\\n if len(A) != len(B): return False\\n Count_A, Count_B = Counter(A), Counter(B)\\n if Count_A != Count_B: return False\\n diff_places = sum([i!=j for i,j in zip(A,B)])\\n if diff_places not in [0, 2]: return False\\n if diff_places == 0 and len(Count_A) == len(A): return False\\n if diff_places == 2 and len(Count_A) == 1: return False\\n return True\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1602492855, | |
| "creationDate": 1602492855 | |
| } | |
| }, | |
| { | |
| "id": 969234, | |
| "title": "[Pyton] O(n) time/O(h) space, explained", | |
| "taskUrl": "https://leetcode.com/problems/smallest-subtree-with-all-the-deepest-nodes", | |
| "post": { | |
| "id": 1759881, | |
| "content": "Let us use `dfs(level, node)` function, where:\\n\\n1. `level` is distance between root of our tree and current `node` we are in.\\n2. result of this function is the distance between `node` and its farthest children: that is the largest numbers of steps we need to make to reach leaf.\\n\\nSo, how exactly this function will work:\\n1. If `not node`, then we are in the leaf and result is `0`.\\n2. in other case, we run recursively `dfs` for `node.left` and `node.right`.\\n3. What we keep in our `cand`: in first value sum of distances to root and to farthest leaf, second value is distance to root and final value is current node. Note, that `cand[0]` represent length of the longest path going from root to leaf, through our `node`.\\n4. `if cand[0] \u003e self.ans[0]:` it means that we found node with longer path going from root to leaf, and it means that we need to update `self.ans`.\\n5. Also, if `cand[0] = self.ans[0]` and also `lft = rgh`, it means that we are now on the longest path from root to leaf and we have a **fork**: we can go either left or right and in both cases will have longest paths. Note, that we start from root of our tree, so it this way we will get **fork** which is the closest to our root, and this is exactly what we want in the end.\\n6. Finally, we return `cand[0] - cand[1]`: distance from node to farthest children.\\n\\n**Complexity**: time complexity is `O(n)`: to visit all nodes in tree. Space complexity is `O(h)`, where `h` is height of tree.\\n\\n```\\nclass Solution:\\n def subtreeWithAllDeepest(self, root):\\n self.ans = (0, 0, None)\\n def dfs(lvl, node):\\n if not node: return 0\\n lft = dfs(lvl + 1, node.left)\\n rgh = dfs(lvl + 1, node.right)\\n cand = (max(lft, rgh) + 1 + lvl, lvl, node)\\n\\n if cand[0] \u003e self.ans[0] or cand[0] == self.ans[0] and lft == rgh:\\n self.ans = cand\\n \\n return cand[0] - cand[1]\\n \\n dfs(0, root)\\n return self.ans[2]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607770108, | |
| "creationDate": 1607768923 | |
| } | |
| }, | |
| { | |
| "id": 979066, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/decoded-string-at-index", | |
| "post": { | |
| "id": 1776935, | |
| "content": "Let us iterate over our string `S` and check lengths of string we have after each step. Let us consider example `S = hi2bob3`.\\n\\n1.`h`, length = 1\\n2.`hi`, length = 2\\n3.`hi2`, string becomes `hihi` and length equal to `4`.\\n4.`hi2b`, string becomes `hihib`, length equal to `5`.\\n5.`hi2bo`, string becomes `hihibo`, length equal to `6`.\\n6.`hi2bob`, string becomes `hihibob`, length equal to `7`.\\n7.`hi2bob3`, string becomes `hihibobhihibobhihibob`, length equal to `21`.\\n\\nLet us write down all these lengths into array `len`: if we have letter, we increase previous element by `1`, if it is digit, we increase previous element multiplied by this digit.\\n\\nNow, we need to find letter, imagine we have `K = 18`. We will traverse our `S` from the end and check `K % lens[i]`. \\n1. `18 \u003c 21`, so on this step we do nothing.\\n2. `18 % 7` = 4, it means, that string `hihibob` repeated `3` times and we need to choose element number `4` from this string.\\n3. `4 \u003c 6, 4 \u003c 5`, so we skip these two steps\\n4. Now we have `K = 4` and `lens[i] = 4`, and we make `K = 0`. We are good, we can stop? Not exactly, the problem, that now we on the place `hi2` and we are on digit symbol, so we need to continue.\\n5. Now, `K = 0` and `lens[i] = 2`, and also we have string `hi` so far, so we can stop and answer will be `i`.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity as well. Space complexity can be reduced to `O(1)`, if we do not store `lens` and only the last one and go back on the fly.\\n\\n```\\nclass Solution:\\n def decodeAtIndex(self, S, K):\\n lens, n = [0], len(S)\\n for c in S:\\n if c.isdigit():\\n lens.append(lens[-1]*int(c))\\n else:\\n lens.append(lens[-1] + 1)\\n \\n for i in range(n, 0, -1):\\n K %= lens[i]\\n if K == 0 and S[i-1].isalpha():\\n return S[i-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608462746, | |
| "creationDate": 1608462746 | |
| } | |
| }, | |
| { | |
| "id": 654840, | |
| "title": "[Python] Simple dfs traversal O(E+V), detailed explanations", | |
| "taskUrl": "https://leetcode.com/problems/possible-bipartition", | |
| "post": { | |
| "id": 1214282, | |
| "content": "This is classical graph theory problem: you have graph, and you need to check if it can be bipartitioned: all nodes must be divided into two groups, such that there is not connections between nodes in each group.\\n\\nClassical way to solve this problem is any graph traversal algorighm, here I chose dfs. \\nThe variable `self.adj_list` is adjacency list of our graph, for example if we have connections\\n`[[1,2],[2,3],[3,4],[4,5],[1,5]]`, then it is equal to `1:{2,5}; 2:{1,3}, 3:{4,2}, 4:{3,5}, 5:{1,4}`\\nI also have `self.found_loop` variable to terminate early if we found loop with odd length, which is sufficient and necessary condition that graph **can not be bipartitioned**, for example in our case we have `1-\u003e2-\u003e3-\u003e4-\u003e5-\u003e1` the loop with size 5.\\n\\nWhen we traverse nodes, we evaluate their distances (in my code list `self.dist`) from the starting point, and if in some moment node is already visited and its parity is broken, than we found odd loop.\\n\\nNote also, that original graph is not necessarily connected, and we need to start our dfs from all nodes to make sure that we traverse all graph.\\n\\n**Complexity** We traverse every connection between nodes only once, so we have classical O(E+V) time complexity, where E is number of edges and V is number of vertices (V = N in our case and V = len(dislikes)). Space complexity is also O(E+V), because we keep adjacency list for all our nodes and colors\\n\\n```\\nclass Solution:\\n def dfs(self, start):\\n if self.found_loop == 1: return #early stop if we found odd cycle\\n \\n for neib in self.adj_list[start]:\\n if self.dist[neib] \u003e 0 and (self.dist[neib] - self.dist[start]) %2 == 0:\\n self.found_loop = 1\\n elif self.dist[neib] \u003c 0: #not visited yet\\n self.dist[neib] = self.dist[start] + 1\\n self.dfs(neib)\\n \\n def possibleBipartition(self, N, dislikes):\\n self.adj_list = defaultdict(list)\\n self.found_loop, self.dist = 0, [-1] *(N+1)\\n \\n for i,j in dislikes:\\n self.adj_list[i].append(j)\\n self.adj_list[j].append(i)\\n \\n for i in range(N):\\n if self.found_loop: return False #early stop if we found odd cycle\\n \\n if self.dist[i] == -1: #not visited yet\\n self.dist[i] = 0\\n self.dfs(i)\\n \\n return True\\n```\\n\\nIf you have any question, feel free to ask. If you like the explanations, please upvote", | |
| "updationDate": 1590569118, | |
| "creationDate": 1590567753 | |
| } | |
| }, | |
| { | |
| "id": 958059, | |
| "title": "[Python] Inorder dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/increasing-order-search-tree", | |
| "post": { | |
| "id": 1741206, | |
| "content": "Let us construct new tree, using already existing nodes. My `dfs` function will have two outputs: node with smallest value (root of tree) and node with biggest value (leaf of tree). Then, all we need to do is to run `dfs` recursively:\\n\\n1. First, we denote `l1 = node` and `r2 = node`, this is for the case, if we will not have left or right children.\\n2. If we have left children, we create straight tree for left subtree using recursion and attach our `node` as right children of leaf of this tree.\\n3. If we have right children, we againg create straigh tree for right subtree using recursion and attach `r1` as right children of `node`.\\n4. We put left children of node to `None` to avoid loops in our final tree.\\n5. Return `dfs(root)[0]`: only root of constructed tree, not need to return leaf.\\n\\n**Complexity**: time complexity is `O(n)`, because we visit each node exactly once. Space compexity is `O(h)`, height of our tree.\\n\\n```\\nclass Solution:\\n def increasingBST(self, root):\\n def dfs(node):\\n l1, r2 = node, node\\n \\n if node.left: \\n l1, l2 = dfs(node.left)\\n l2.right = node\\n \\n if node.right:\\n r1, r2 = dfs(node.right)\\n node.right = r1\\n \\n node.left = None\\n return (l1, r2)\\n \\n return dfs(root)[0]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606986544, | |
| "creationDate": 1606986544 | |
| } | |
| }, | |
| { | |
| "id": 943592, | |
| "title": "[Python] Math solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/numbers-at-most-n-given-digit-set", | |
| "post": { | |
| "id": 1715692, | |
| "content": "This is one of those numbers problems, where we need to go digit by digit and count number of good number. Let me explain what I mean by that: imagine, that we have number `n = 314792` and `digits = [1,3,5,7]`, then we can split all numbers which are less or equal to `n` to several groups.\\n\\n1. `n` itself: `314792`.\\n2. Numbers, which have form `31479?`, where question mark can be any number **less** than `2` and in our `digits` array.\\n3. Numbers, which have form `3147?*`, where question mark can be any number **less** than `9` and * mark means any digit from `digits`.\\n4. Numbers, which have form `314?**`, where question mark can be any number **less** than 7 and * again means any digit from `digits`.\\n5. Numbers, which have form `31?***`.\\n6. Numbers, which have form `3?****`.\\n7. Numbers, which have form `?*****`.\\n8. Finally, numbers which have form `*****`, `****`, `***`, `**`, `*`.\\n\\nWe can note, that we need to evaluate several times number of digits in `digits` which are less than some digit `2`, `9`, `7` and so on. We can just precompute array `up` for this purpuse. Also let `T` be number of our `digits`, `str_n` will be string created from `n`, `k` be length of this string and `d_set` be set of all `digits`.\\n\\nWhat we need to do in main part of my algorithm:\\n1. Iterate from digit to digit, starting with `i = 0`.\\n2. Check if number constructed from first `i` digits have only `digits` inside: see step `4`: there we have numbers, starting with `314` and they can not be good. On step `5` however numbers start with `31` and it is OK for us.\\n3. Add `up[int(str_n[i])]` multiplied by `T` to the power `k-i-1` to our answer: just combinatorics to choose candidates for `?` place and for `*` place.\\n4. Finally, we need to deal with the last case: numbers with less number of digits and with first case: number `n` itself.\\n\\n**Complexity**: time complexity is `O(10k + T)`, where `k` is lenght of our number `n` and `k` is lenght of `digits`. Actually, it can be just written as `O(T)`, because `10k \u003c= 100` always. Space complexity is `O(T)`.\\n\\n```\\nclass Solution:\\n def atMostNGivenDigitSet(self, digits, n):\\n up, ans, T, str_n = [0]*10, 0, len(digits), str(n)\\n for i in range(10):\\n for dig in digits:\\n up[i] += (dig \u003c str(i))\\n \\n k, d_set = len(str_n), set(digits)\\n for i in range(k):\\n if i \u003e 0 and str_n[i-1] not in d_set: break\\n ans += up[int(str_n[i])] * T**(k-i-1)\\n \\n addon = (T**k - 1)//(T-1) - 1 if T != 1 else k - 1\\n return ans + addon + (not set(str_n) - set(digits))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605950516, | |
| "creationDate": 1605950516 | |
| } | |
| }, | |
| { | |
| "id": 803633, | |
| "title": "[Python] O(n) In place partition, explained", | |
| "taskUrl": "https://leetcode.com/problems/sort-array-by-parity", | |
| "post": { | |
| "id": 1471817, | |
| "content": "One way to solve this problem is to just sort data or use additional memory. However, there is better approach without using additional memory, using two pointers. The idea is to have two pointers: `beg` and `end`, where `beg` points just after the group of formed even elements in the beginning and `end` points just before group of odd elements in the end. Let us consider example: `A = [1,10,2,3,7,7,8,2,1,4]`. On each step I show current `A`, `beg` and `end`. I denote by bold font numbers which are already on place.\\n\\n1. Step 1: A = [4, 10, 2, 3, 7, 7, 8, 2, 1, **1**], `beg = 0`, `end = 8`\\n2. Step 2: A = [**4**, 10, 2, 3, 7, 7, 8, 2, 1, **1**], `beg = 1`, `end = 8`\\n3. Step 3: A = [**4, 10**, 2, 3, 7, 7, 8, 2, 1, **1**], `beg = 2`, `end = 8`\\n4. Step 4: A = [**4, 10, 2**, 3, 7, 7, 8, 2, 1, **1**], `beg = 3`, `end = 8`\\n5. Step 5: A = [**4, 10, 2**, 1, 7, 7, 8, 2, **3, 1**], `beg = 3`, `end = 7`\\n6. Step 6: A = [**4, 10, 2**, 2, 7, 7, 8, **1, 3, 1**], `beg = 3`, `end = 6`\\n7. Step 7: A = [**4, 10, 2, 2**, 7, 7, 8, **1, 3, 1**], `beg = 4`, `end = 6`\\n8. Step 8: A = [**4, 10, 2, 2**, 8, 7, **7, 1, 3, 1**], `beg = 4`, `end = 5`\\n9. Step 9: A = [**4, 10, 2, 2, 8**, 7, **7, 1, 3, 1**], `beg = 5`, `end = 5`\\n10. Step 10: A = [**4, 10, 2, 2, 8, 7, 7, 1, 3, 1**], `beg = 5`, `end = 4`\\n\\n**Complexity**: Time complexity is `O(n)`, space complexity is `O(1)`, because we do all in place.\\n\\nNote also, that this problem is special case of problem **75: Sort Colors**, where we need to partition in three parts, here we have only two. See my post, explaing this problem.\\nhttps://leetcode.com/problems/sort-colors/discuss/681526/Python-O(n)-3-pointers-in-place-approach-explained\\n\\n```\\nclass Solution:\\n def sortArrayByParity(self, A):\\n beg, end = 0, len(A) - 1\\n \\n while beg \u003c= end:\\n if A[beg] % 2 == 0:\\n beg += 1\\n else:\\n A[beg], A[end] = A[end], A[beg]\\n end -= 1\\n return A\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597999496, | |
| "creationDate": 1597999011 | |
| } | |
| }, | |
| { | |
| "id": 980294, | |
| "title": "[Python] O(n log n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/smallest-range-ii", | |
| "post": { | |
| "id": 1778881, | |
| "content": "In this problem we need to add `K` to some numbers and subtract `K` from some numbers, such that final gap between minimum and maximum number is minimal. Notice, that it is equivalent to just subtracting `2*K` from some subset of numbers we have. Imagine, that we choose indexes `i_1 \u003c ... \u003c i_l` for numbers we want to subtract `2K` from. How we can find now gap between minimum and maximum elements?\\n\\n1. We choose `i_1 \u003c ... \u003c i_l` indexes for numbers we want to subtract `2*K`, let us define `j_1 \u003c ... \u003c j_m` indexes for numbers we do not touch.\\n2. Then we can look at it as following: we have segment `A[i_1] - 2*K to A[i_l] - 2*K` and we have segment `A[j_1] to A[j_m]` and we need to find maximum distance between ends of these segments. Notice now, that if segments `[i_1, i_l]` and `[j_1, j_m]` have intersections, than we can decrease size of one of them, so final gap between maximum and minimum values can only decrease.\\n3. It means it fact, that indexes we choose follow the pattern: `0, ..., i` for first set and `i+1, ..., n-1` for the second set: we do not touch elements in first group and subtract `2*K` from elements from second group. Notice also, that there is case, when one of the groups is empty, in this case, gap will be `A[-1] - A[0]`.\\n\\n**Complexity**: it is `O(n log n)` to sort data and `O(n)` to traverse it, leading to `O(n log n)` final complexity. Additional space complexity is `O(log n)` if we sort in place (note, that sort in place will not be `O(1)`, but `O(log n)`).\\n\\n```\\nclass Solution:\\n def smallestRangeII(self, A, K):\\n A.sort()\\n n, ans = len(A), float(\"inf\")\\n\\n for i in range(n-1):\\n cands = [A[0], A[i], A[i+1] - 2*K, A[-1] - 2*K]\\n ans = min(ans, max(cands) - min(cands))\\n \\n return min(ans, A[-1] - A[0])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608544068, | |
| "creationDate": 1608544023 | |
| } | |
| }, | |
| { | |
| "id": 873333, | |
| "title": "[Python] easy solution, using queue, explained", | |
| "taskUrl": "https://leetcode.com/problems/number-of-recent-calls", | |
| "post": { | |
| "id": 1593400, | |
| "content": "What we need to keep in this problem is sliding window of recent calls. So, we need to remove old calls, if they are too old and append new ones. Ideal data structure is queue, and in python we usualy use `deque`. So, there are 3 simple steps to succes:\\n\\n1. Add new call time to the end of our queue.\\n2. Remove old times: we pop from the beginning of our queue until time is not older than `last - 3000`.\\n3. Return length of our queue: it will be exaclty what we need.\\n\\n**Complexity**: even though for each call of `ping` function we can potentially call a lot of `popleft()`, if we run `ping` `n` times we will have `O(n)` complexity: each element go to queue and from queue only once, so we can say amortised time complexity is `O(1)`. Space complexity can be potentially `O(3000)`. \\n\\n```\\nclass RecentCounter:\\n def __init__(self):\\n self.calls = deque()\\n\\n def ping(self, t):\\n self.calls.append(t)\\n while self.calls[0] \u003c self.calls[-1] - 3000:\\n self.calls.popleft()\\n return len(self.calls)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601542762, | |
| "creationDate": 1601542762 | |
| } | |
| }, | |
| { | |
| "id": 936480, | |
| "title": "[Python] Simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/range-sum-of-bst", | |
| "post": { | |
| "id": 1703637, | |
| "content": "One way to solve this problem is just iterate over our tree and for each element check if it is range or not. However here we are given, that out tree is `BST`, that is left subtree is always lesser than node lesser than right subtree. So, let us modify classical `dfs` a bit, where we traverse only nodes we need:\\n\\n1. Check value `node.val` and if it is in our range, add it to global sum.\\n2. We need to visit left subtree only if `node.val \u003e low`, that is if `node.val \u003c low`, it means, that all nodes in left subtree less than `node.val`, that is less than `low` as well.\\n3. Similarly, we visit right subtree only if `node.val \u003c high`.\\n\\n**Complexity**: time complexity is `O(n)`, where `n` is nubmer of nodes in our tree, space complexity potentially `O(n)` as well. We can impove our estimations a bit and say, that time and space is `O(m)`, where `m` is number of nodes in our answer.\\n\\n```\\nclass Solution:\\n def rangeSumBST(self, root, low, high):\\n def dfs(node):\\n if not node: return\\n if low \u003c= node.val \u003c= high: self.out += node.val\\n if node.val \u003e low: dfs(node.left)\\n if node.val \u003c high: dfs(node.right)\\n \\n self.out = 0\\n dfs(root)\\n return self.out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605441087, | |
| "creationDate": 1605441087 | |
| } | |
| }, | |
| { | |
| "id": 966752, | |
| "title": "[Python] One pass, explained", | |
| "taskUrl": "https://leetcode.com/problems/valid-mountain-array", | |
| "post": { | |
| "id": 1755757, | |
| "content": "Let us start from the left of our `arr` and go to the right until it is possible, that is until our data is increasing. Also we start from the end and go to the left until our data is decreasing. If we met somwhere in the middle in point, which is neither `0` nor `n-1`, it means that we found our mountain, in other case array is not mountain.\\n\\n**Complexity**: we pass over our data only once, so time complexity is `O(n)`; space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def validMountainArray(self, arr):\\n n = len(arr)\\n beg, end = 0, n - 1\\n while beg != n-1 and arr[beg + 1] \u003e arr[beg]: beg += 1\\n while end != 0 and arr[end - 1] \u003e arr[end]: end -= 1 \\n return beg == end and end != n-1 and beg != 0\\n```\\n\\nSee other mountain array problems:\\n**845. Longest Mountain in Array:** https://leetcode.com/problems/longest-mountain-in-array/discuss/937652/Python-one-pass-O(1)-space-explained\\n\\n**1671 Minimum Number of Removals to Make Mountain Array:** https://leetcode.com/problems/minimum-number-of-removals-to-make-mountain-array/discuss/952053/Python-3-solutions%3A-LIS-dp-O(n-log-n)-explained\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607588629, | |
| "creationDate": 1607588461 | |
| } | |
| }, | |
| { | |
| "id": 907925, | |
| "title": "[Python] 2 Pointers greedy approach, explained", | |
| "taskUrl": "https://leetcode.com/problems/bag-of-tokens", | |
| "post": { | |
| "id": 1653776, | |
| "content": "The first thing we need to notice, that if we want to play token face up, we need to do it with the smallest value, if we want to play token down, we need to do it with the biggest value. So:\\n\\n1. Sort our tokens in increasing order.\\n2. Now, we use two pointers approach, `beg` pointer deals with small values, and `end` pointer deals with big values.\\n3. At each step, our goal is to maximize our score, so we first check if we can play our token up: if we can, we do it, decrease `P`, increase `S`; also we move `beg` one position to the right and we update our `max_S`: it can happen in future, that final `S` is not the biggest one, so we need to fix the biggest reached score. If it is not possible to play token up, we try to play token down: we increase our `P`, decrease `S` and move `end` pointer one place to the left. If both of these options are not possible, we break.\\n4. Finally, we return `max_S`, maximum score reached during all traversal of tokens.\\n\\n**Complexity**: time complexity is `O(n log n)` to sort our data and `O(n)` to use two pointers approach, so it is `O(n log n)` in all. Space complexity is `O(log n)`, if we sort our `tokens` in place (it is not `O(1)`, because for example merge or quick sort and others use recursion with `O(log n)` space for stack).\\n\\n```\\nclass Solution:\\n def bagOfTokensScore(self, tokens, P):\\n tokens.sort()\\n beg, end, S, max_S = 0, len(tokens) - 1, 0, 0\\n while beg \u003c= end:\\n if tokens[beg] \u003c= P:\\n P -= tokens[beg]\\n S += 1\\n max_S = max(max_S, S)\\n beg += 1\\n elif S \u003e= 1:\\n P += tokens[end]\\n S -= 1\\n end -= 1\\n else: break\\n return max_S\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603527192, | |
| "creationDate": 1603527192 | |
| } | |
| }, | |
| { | |
| "id": 822874, | |
| "title": "[Python] Check all permutations, explained", | |
| "taskUrl": "https://leetcode.com/problems/largest-time-for-given-digits", | |
| "post": { | |
| "id": 1505446, | |
| "content": "In this problem we are asked to check if some possible permutation of digits creates maximum possible valid time. One way to handle this problem is to just check all possible `4! = 24` permutations: this number is quite small and we can afford it. So, we:\\n\\n1. Create `out = \"\"`, here we will keep our answer.\\n2. Check all permutations of `A`, in python there is special function for it, why not use it: for each permutation check if it is valid time: hour need to be `\u003c=23` and minutes need to be `\u003c=59`, which can be written as `P[2] \u003c= 5`.\\n3. Now, compare new build time with our current maximum and choose best of them. This is all!\\n\\n**Complexity**: time complexity is `O(1)`, but more strictrly it is `O(k!)`, we need to check all permutations in any case, where `k=4` is size of `A`. Space complexity is `O(1)` also, which is more like `O(k)` to keep our answer and compare it with `out`.\\n\\n```\\nclass Solution:\\n def largestTimeFromDigits(self, A):\\n out = \"\"\\n for P in permutations(A):\\n if P[0]*10 + P[1] \u003c= 23 and P[2] \u003c= 5:\\n out = max(out, str(P[0])+str(P[1]) + \":\" + str(P[2])+str(P[3]))\\n \\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598944879, | |
| "creationDate": 1598944879 | |
| } | |
| }, | |
| { | |
| "id": 819919, | |
| "title": "[Python] Union find solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/largest-component-size-by-common-factor", | |
| "post": { | |
| "id": 1500411, | |
| "content": "If you try to run usual dfs/bfs on this problem, you will get TLE, so we need to think something smarter. Note, that if two numbers has common factor more than `1`, it means that they have **prime** common factor. So, let us for example consider all even numbers: they all have prime common factor `2`, so we can immediatly say, that they should be in the same group. Consider all numbers which are divisible by `3`, they also can be put in the same group. There is special data stucture: Disjoint set (https://en.wikipedia.org/wiki/Disjoint-set_data_structure), which is very suitable for these type of problems.\\n\\nLet us consider example `[2,3,6,7,4,12,21,39]` an go through my code:\\n\\n1. `primes_set(self,n)` return set of unique prive divisors of number `n`, for example for `n = 12` it returns set `[2,3]` and for `n=39` it returns set `[3,13]`.\\n2. Now, what is `primes` defaultdict? For each found prime, we put indexes of numbers from `A`, which are divisible by this prime. For our example we have: `2: [0,2,4,5], 3:[1,2,5,6,7], 7:[3,6], 13:[7]`. So, what we need to do now? We need to union `0-2-4-5`, `1-2-5-6-7` and `3-6`.\\n3. That exaclty what we do on the next step: iterate over our `primes` and create connections with `UF.union(indexes[i], indexes[i+1])`\\n4. Finally, when we made all connections, we need to find the biggest group: so we find parent for each number and find the bigges frequency.\\n\\n**Complexity**: this is interesting part. Let `n` be length of `A` and let `m` be the biggest possible number. Function `primes_set` is quite heavy: for each number we need to check all numbers before its square root (if number is prime we can not do better with this approach), so complexity of `primes_set` is `O(sqrt(m))`. We apply this function `n` times, so overall complexity of this function will be `O(n*sqrt(m))`. We also have other parts of algorithm, where we put prime numbers to dictionary, complexity will be `O(n*log(m))` at most, because each number has no more, than `log(m)` different prime divisors. We also have the same number of `union()` calls, which will work as `O(1)` if we use it with ranks, and slower if we use it without ranks as I did, but still fast enough to be better than our bottleneck: `O(n*sqrt(m))` complexity for prime factors generation. That is why I use Union Find without ranks: if you want to improve algorighm, you need to deal with `primes_set()` function.\\nSpace complexity is `O(n*log(m))` to keep all prime factors and to keep our `DSU` data structure.\\n\\n```\\nclass DSU:\\n def __init__(self, N):\\n self.p = list(range(N))\\n\\n def find(self, x):\\n if self.p[x] != x:\\n self.p[x] = self.find(self.p[x])\\n return self.p[x]\\n\\n def union(self, x, y):\\n xr, yr = self.find(x), self.find(y)\\n self.p[xr] = yr\\n\\nclass Solution:\\n def primes_set(self,n):\\n for i in range(2, int(math.sqrt(n))+1):\\n if n % i == 0:\\n return self.primes_set(n//i) | set([i])\\n return set([n])\\n\\n def largestComponentSize(self, A):\\n n = len(A)\\n UF = DSU(n)\\n primes = defaultdict(list)\\n for i, num in enumerate(A):\\n pr_set = self.primes_set(num)\\n for q in pr_set: primes[q].append(i)\\n\\n for _, indexes in primes.items():\\n for i in range(len(indexes)-1):\\n UF.union(indexes[i], indexes[i+1])\\n\\n return max(Counter([UF.find(i) for i in range(n)]).values())\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598780598, | |
| "creationDate": 1598780598 | |
| } | |
| }, | |
| { | |
| "id": 717491, | |
| "title": "[Python] Loop detection, explained", | |
| "taskUrl": "https://leetcode.com/problems/prison-cells-after-n-days", | |
| "post": { | |
| "id": 1323176, | |
| "content": "Let us solve this problem by definition: we do iteration by iteration. However if `N` is very big, then we spend `O(N)` time and it can take too much time. Note, that there can be only `2^8` possible options for cells (in fact only `2^6` even, because after first step the first and the last symbols will always be zeros). It means, that afrer some number of iterations, cells start to repeat, and we found a **loop**.\\n\\nHow can we find a loop? We need to keep our positions in hash-table, so we can find `loop_len`. We do iteration by iteration and if we found a loop, we need to do `(N - i) % loop_len` more steps.\\n\\n**Complexity**: time and memory is `O(64)`, because the loop size will be not more than `64`.\\n\\n```\\nclass Solution:\\n def next_step(self, cells):\\n res = [0] * 8\\n for i in range(1,7):\\n res[i] = int(cells[i-1] == cells[i+1])\\n return res\\n \\n def prisonAfterNDays(self, cells, N):\\n found_dic = {}\\n for i in range(N):\\n cells_str = str(cells)\\n if cells_str in found_dic:\\n loop_len = i - found_dic[cells_str]\\n return self.prisonAfterNDays(cells, (N - i) % loop_len)\\n else:\\n found_dic[cells_str] = i \\n cells = self.next_step(cells) \\n \\n return cells\\n```\\n\\n**PS** there are also solutions which are using the fact that if there is a loop, it will always have length `14` (or divisor of it). However will you find this on real interview?\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593763343, | |
| "creationDate": 1593762577 | |
| } | |
| }, | |
| { | |
| "id": 798436, | |
| "title": "[Python] dfs/dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/numbers-with-same-consecutive-differences", | |
| "post": { | |
| "id": 1462317, | |
| "content": "Let us try to build our number digit by digit. Define `dfs(i,j)`, where `i` is number of digits we build so far and `j` is the last digit in builded numbers. For example `dfs(3,2) = [212, 432, 232]`. We need to:\\n\\n1. if `j` not in `[0,9]` we return `[]`, there is not numbers and also if `j==0 and i = 1`, it means, that first digit is zero. However there is one exeption, if `N == 1`, we need to return all `10` digits.\\n2. if `i == 1`, than there is only one desired number, `j`.\\n3. Also we need to be careful with case `K = 0`, it this case we have only one option how to build next digit: `dfs(i-1,j)`, and if `K != 0`, we have two options: `dfs(i-1, j+K)` and `dfs(i-1,j-K)`.\\n4. Finally, we need to run `dfs(N,i)` for every digit.\\n\\n**Complexity**: time complexity is `O(2^(n-1) * 10)`, because we start with all digits and then each step we have at most two options. Space complexity is the same and it can be reduced if we use integers instead of strings.\\n\\n```\\nclass Solution:\\n def numsSameConsecDiff(self, N, K):\\n @lru_cache(None)\\n def dfs(i,j):\\n if j \u003c 0 or j \u003e 9 or (j == 0 and i == 1): return []\\n if i == 1: return [str(j)]\\n dirs, out = set([K, -K]), []\\n for d in dirs:\\n out += [s+str(j) for s in dfs(i-1,j+d)]\\n return out\\n \\n if N == 1: return range(10)\\n return list(chain(*[dfs(N, i) for i in range(10)]))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597738937, | |
| "creationDate": 1597738937 | |
| } | |
| }, | |
| { | |
| "id": 817862, | |
| "title": "[Python] O(n) flips/O(n^2) time, explained", | |
| "taskUrl": "https://leetcode.com/problems/pancake-sorting", | |
| "post": { | |
| "id": 1496737, | |
| "content": "The idea is the following: first, put pancake with the biggest index on its place, then we never need to move it! Let us go through example:\\n`[3,2,4,6,5,1]`.\\n\\n1. We want to put pancake number `6` to the end, we can no do it immediatly, so let us put it to the beginning first: we need to flip first **4** pancakes: `A = [6,4,2,3,5,1]`. On the next step we can flip first **6** pancakes, so we have `A = [1,5,3,2,4,6]`.\\n2. Now, we want to put pancake number `5` to its place, we first flip first **2** pancakes to have `[5,1,3,2,4,6]` and then first **5**, to have `[4,2,3,1,5,6]`.\\n3. Similar logic with number `4`, but it is already in the beginning, so one step is enough: we flip first **4** pancakes to have `[1,3,2,4,5,6]`. \\n4. Put `3` to its place: flip first **2** to have `[3,1,2,4,5,6]` and then flip first **3** to have `[2,1,3,4,5,6]`.\\n5. Finally, put `2` on its place, flit first **2**: we have `[1,2,3,4,5,6]`.\\n\\nSo, our filps are the following: **[4,6,2,5,4,2,3,2]**.\\n\\n**Comlexity**: this is interesting part, we need to compute two types of complexities: classical one and how many flips we make. Note, that we make `O(n)` flips, because at each step we need to make no more than `2`. Now, note, that on each step we make no more than `O(n)` operations, because we need to inverse some part of array. So, overall complexity will be `O(n^2)`. Space complexity is `O(n)` to keep our answer.\\n\\n\\n```\\nclass Solution:\\n def pancakeSort(self, A):\\n result, n = [], len(A)\\n for i in range(n,0,-1):\\n pl = A.index(i)\\n if pl == i-1: continue\\n if pl != 0:\\n result.append(pl+1)\\n A[:pl+1] = A[:pl+1][::-1]\\n result.append(i)\\n A[:i] = A[:i][::-1]\\n \\n return result\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598686373, | |
| "creationDate": 1598686373 | |
| } | |
| }, | |
| { | |
| "id": 659966, | |
| "title": "[Python] Easy, heap O(n log k) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/k-closest-points-to-origin", | |
| "post": { | |
| "id": 1222741, | |
| "content": "When you see in the statement of the problem that you need you find k biggest or k smallest elements, you should immediately think about heaps or sort. Here we need to find the k smallest elements, and hence we need to keep **max** heap. Why max and not min? We always keep in the root of our heap the `k`-th smallest element. Let us go through example: `points = [[1,2],[2,3],[0,1]], [3,4]`, `k = 2`. \\n1. First we put points `[1,2]` and `[2,3]` into our heap. In the root of the heap we have maximum element `[2,3]`\\n2. Now, we see new element `[0,1]`, what should we do? We compare it with the root, see, that it is smaller than root, so we need to remove it from our heap and put new element instead, now we have elements `[1,2]` and `[0,1]` in our heap, root is `[1,2]`\\n3. Next element is `[3,4]` and it is greater than our root, it means we do not need to do anything.\\n\\n### Complexity\\nWe process elements one by one, there are `n` of them and push it into heap and pop root from our heap, both have `O(log k)` complexity, so finally we have `O(n log k)` complexity, which is faster than `O(n log n)` algorighm using sorting.\\n\\n### Code:\\nFirst, we create heap (which is by definition **min** heap in python, so we use negative distances). Then we visit all the rest elements one by one and update our heap if needed.\\n\\n```\\nclass Solution:\\n def kClosest(self, points, K):\\n heap = [[-i*i-j*j, i, j] for i,j in points[:K]]\\n rest_elem = [[-i*i-j*j, i, j] for i,j in points[K:]]\\n heapq.heapify(heap)\\n for s, x, y in rest_elem:\\n if s \u003e heap[0][0]:\\n heapq.heappush(heap, [s,x,y])\\n heapq.heappop(heap)\\n\\n return [[x,y] for s,x,y in heap]\\n```", | |
| "updationDate": 1590846605, | |
| "creationDate": 1590828204 | |
| } | |
| }, | |
| { | |
| "id": 660016, | |
| "title": "[Python] oneliner using sort", | |
| "taskUrl": "https://leetcode.com/problems/k-closest-points-to-origin", | |
| "post": { | |
| "id": 1222806, | |
| "content": "Even though this algorighm has not optimal algorithmic complexity (it is `O(n log n)` vs heaps `O(n log k)`, on leetcode it can work faster. Just sort points by distances and choose the smallest `K` of them\\n\\n```\\nclass Solution:\\n def kClosest(self, points, K):\\n return sorted(points, key = lambda x: x[0]**2 + x[1]**2)[:K]\\n```", | |
| "updationDate": 1590830396, | |
| "creationDate": 1590830396 | |
| } | |
| }, | |
| { | |
| "id": 972954, | |
| "title": "[Python] oneliner O(n) explained", | |
| "taskUrl": "https://leetcode.com/problems/squares-of-a-sorted-array", | |
| "post": { | |
| "id": 1766765, | |
| "content": "Note, that our numbers will look like this: first we have some negative numbers in increasing order (may be `0` of them) and then we have some positive numbers in increasing order (again may be `0` of them). \\n\\n1. Note, that if we have negative number in increasing order, then their squares will be in decreasing order, so we need to invert this part.\\n2. If we have positive increasing numbers, then their squares also increasing numbers.\\n3. Now we have two lists with increasing numbers and we need to creaty one list with increasing numbers, how we can do it? We can use **merge** sort and do it by hands. However it happens, that if we run the code as it is it will be `O(n)`. Why? Because python uses so-called **Timsort** https://en.wikipedia.org/wiki/Timsort which will look for sorted patterns in data.\\n\\n**Complexity**: time and space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def sortedSquares(self, nums):\\n return sorted([i**2 for i in nums if i \u003e 0][::-1] + [i**2 for i in nums if i \u003c= 0])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1608021152, | |
| "creationDate": 1608021152 | |
| } | |
| }, | |
| { | |
| "id": 855647, | |
| "title": "[Python] simple dfs/backtracking, explained", | |
| "taskUrl": "https://leetcode.com/problems/unique-paths-iii", | |
| "post": { | |
| "id": 1562493, | |
| "content": "If you look carefully at your problem constraints: `m*n \u003c= 20`, where `m` and `n` your grid sizes, we can guess, that we need to use dfs in this problem: that is try to check all possible options. So, we need to do several steps:\\n\\n1. Find our starting point: traverse all grid and find cell with value `1`. Also count number of cells we need to visit, I denoted them `empty`.\\n2. Now, use recursive `dfs(x,y, rest)` function, where `x` and `y` are current coordinates in our cell and `rest` is how many empty cells we need to traverse.\\n2.1 First we check if we can move to the current cell: if it is outside our grid and it is already visited or have obstacle, we return\\n2.2 If current cell is end cell and we already visited all cells, we add `1` to `self.ans`.\\n2.3 Define list of neighbours and for each of them run our `dfs`: mark visited cell with `-2` and then mark it back when we go outside recursion. It is important to do this, because in python `grid` is global variable and we need to change it back.\\n3. FInally, we just run `dfs(sx, sy, empty - 1)`, where `(sx, sy)` is coordinates of starting cell and return `self.ans`.\\n\\n**Complexity**: Space complexity is `O(mn)`, this is the possible biggest length of our recursion stack. Time complexity is `O(3^(mn))`, because on each step (except first) we have no more than `3` options to go: all directions except direction we came from. In practice however it will work much faster than this estimate because of big number of dead-ends\\n\\n```\\nclass Solution:\\n def uniquePathsIII(self, grid):\\n self.ans, empty = 0, 0\\n m, n = len(grid[0]), len(grid)\\n def dfs(x, y, rest):\\n if x \u003c 0 or x \u003e= n or y \u003c 0 or y \u003e= m or grid[x][y] \u003c 0: return\\n if grid[x][y] == 2 and rest == 0:\\n self.ans += 1\\n \\n neibs = [[0,1],[0,-1],[1,0],[-1,0]]\\n for dx, dy in neibs:\\n save = grid[x][y]\\n grid[x][y] = -2\\n dfs(x+dx, y+dy, rest - 1)\\n grid[x][y] = save\\n \\n for i,j in product(range(n), range(m)):\\n if grid[i][j] == 1: (sx, sy) = (i,j)\\n empty += (grid[i][j] != -1)\\n\\n dfs(sx, sy, empty-1)\\n return self.ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600591301, | |
| "creationDate": 1600591301 | |
| } | |
| }, | |
| { | |
| "id": 810791, | |
| "title": "[Python] Universal, true O(days) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-cost-for-tickets", | |
| "post": { | |
| "id": 1484868, | |
| "content": "There are a lot of different dp solution, which have `O(days)` complexity, which is in fact `O(30*days)`, so it depeneds a lot on our numbers `[1,7,30]`. My solution is universal: you can choose any passes you want, and time complexity will not depend on them. Let me introduce my notations:\\n\\n1. `k` is number of passes and `P` is durations of these passes, in our case it is `[1,7,30]`; cost is minimal cost so far, in the beginning it is equal to `0`.\\n2. `Q` is list of `k` queues. Why we need queues? When we want to find the best cost we can have at some day `d`, we need to look back `30` days before, so why not keep all these period in queue? What we keep in this queue? We keep pairs `[day, cost]`. Also we have queue for `7` day pass and for `1` day pass.\\n\\nLet us go through example for better understanding:\\n`days = [1,4,6,7,8,20], costs = [2,7,15]`.\\n\\n\\n1. `day = 1`, `Q[0] = [[1,2]], Q[1] = [[1,7]], Q[2] = [[1, 15]]`: for the first day we put it in all three queues.\\n2. `day = 4`, `Q[0] = [[4,4]], Q[1] = [[1,7], [4,9]], Q[2] = [[1,15], [4,17]]`: we update `Q[0]`, also `Q[1]` and `Q[2]` now have two elements.\\n3. `day = 6`, `Q[0] = [[6,6]], Q[1] = [[1,7], [4, 9], [6,11]], Q[2] = [[1,15], [4,17], [6,19]]`: update `Q[0]`, add element to `Q[1]` and `Q[2]`. \\n4. `day = 7`, `Q[0] = [[7,8]], Q[1] = [[1,7], [4,9], [6,11], [7,13]], Q[2] = [[1,15], [4,17], [6,19], [7,21]]`, similar logic.\\n5. `day = 8`, `Q[0] = [[8,9]], Q[1] = [[4,9], [6,11], [7,13], [8,14]], Q[2] = [[1,15], [4,17], [6,19], [7,21], [8,22]]`: update `Q[0]`, also add element to the end of `Q[1]` and remove element from the beginning of `Q[1]`, because it is outdated.\\n6. `day = 20`, `Q[0] = [[20,11]], Q[1] = [[20,16]], Q[2] = [[1,15], [4,17], [6,19], [7,21], [8,22], [20,24]]`.\\n\\nSo, we iterate through our days and update our queues on each step. Then we choose minimum possible result.\\n\\n**Complexity**: time complexity is `O(days)`, length of `days` list, because we process each element at most `3` times: we can put and remove it to each queue only once. For general case complexity is `O(days * k)`. Space complexity is `O(30+7+1)` in our case and `O(sum(P))` in general case.\\n\\n\\n\\n```\\nclass Solution:\\n def mincostTickets(self, days, costs):\\n k, P, cost = 3, [1,7,30], 0\\n Q = [deque() for _ in range(k)]\\n\\n for d in days:\\n for i in range(k):\\n while Q[i] and Q[i][0][0] + P[i] \u003c= d: Q[i].popleft()\\n Q[i].append([d, cost + costs[i]])\\n \\n cost = min([Q[i][0][1] for i in range(k)])\\n\\n return cost\\n```\\n\\n**Remark** I think this problem is similar to problem **264. Ugly Number II**, there we also need to keep several candidates for new number and update them.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598347537, | |
| "creationDate": 1598347434 | |
| } | |
| }, | |
| { | |
| "id": 777584, | |
| "title": "[Python] Simple dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/vertical-order-traversal-of-a-binary-tree", | |
| "post": { | |
| "id": 1426857, | |
| "content": "First of all, I want to mention, that problem statement is not clear at all, I need to go to comments to understand, what order they expect us to return nodes in levels. So, we have `X` coordinate and `Y` coordinate, we need to group them by `X` coordinate. If we have the same `X` coordinate, we need to check:\\n1. First put nodes with higher `Y` coordinates, that ones, which are close to root\\n2. If two nodes have the same `Y` coordinate also, we need to put small values before big values.\\n\\nLet us define `dic`, where we create our vertical layers, and `self.min_l` and `self.max_l` be minimal and maximal numbers of vertical layers. Let us start to traverse our graph, using `dfs`, with parameters: \\n\\n1. `root` is current node we are in now\\n2. `lvl_h` is horizontal coordinate, that is `X`\\n3. `lvl_v` is vertical coordinate, that is `-Y`: note, that I increase my `Y` coordinate as I go down, it is simpler to deal in this way.\\n\\nInside `dfs` we do the following steps:\\n1. Update `self.min_l` and `self.max_l`.\\n2. Add `lvl_v` and `root.val` pair to our dictionary. We need to add pair to sort it after.\\n3. Finally, visit left and right children if it is possible.\\n\\nIn the end, we need to sort each level, and add it to final list of lists.\\n\\n**Complexity**: Usual `dfs` traversal will take `O(n)` time. However we need to sort each level, before we give final result. Let us have `w_1, ..., w_h` nodes on each layer. then we need to do `w_1 log w_1 + ... + w_h log w_h \u003c n * log W` operations, where `W` is width of the biggest layer. So, complexity is `O(n log W)`, which potentially can be `O(n log n)`, because the widest level can have upto `n/2` nodes. Space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def verticalTraversal(self, root):\\n dic = defaultdict(list)\\n self.min_l, self.max_l = float(\"inf\"), -float(\"inf\")\\n def dfs(root, lvl_h, lvl_v):\\n self.min_l = min(lvl_h, self.min_l)\\n self.max_l = max(lvl_h, self.max_l)\\n dic[lvl_h].append((lvl_v, root.val))\\n if root.left: dfs(root.left, lvl_h-1, lvl_v+1)\\n if root.right: dfs(root.right, lvl_h+1, lvl_v+1)\\n \\n dfs(root, 0, 0)\\n out = []\\n for i in range(self.min_l, self.max_l + 1):\\n out += [[j for i,j in sorted(dic[i])]]\\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1611909249, | |
| "creationDate": 1596789637 | |
| } | |
| }, | |
| { | |
| "id": 781642, | |
| "title": "[Python] clean BFS solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/rotting-oranges", | |
| "post": { | |
| "id": 1433621, | |
| "content": "This is graph traversal problem, so here we have a choise: to use `dfs` or to use `bfs`. What is asked: minimum number of minutes passed until there is no fresh orange. In graphs it means to find the greatest distance from rotten oranges to any other orange. Usually, if we need to find the distances, we use `bfs`. So, let me define my variables:\\n\\n1. `m` and `n` are dimensions of our `grid`, also we have `queue` to run our `bfs` and also we want to count number of fresh oranges: we need this to check in the end if all oranges become rotten or not.\\n2. We put all rotten oranges coordinates to our `queue`, so we are going to start from all of them. Also we count number of fresh oranges.\\n3. Define directions we can go: four of them and put `levels = 0`.\\n\\nNow, we traverse our `grid`, using `bfs`, using level by level traversal: it means, that each time, when we have some elements in `queue`, we popleft all of them and put new neighbours to the end. In this way each time we reach line `levels += 1`, we have nodes with distance which is `1` bigger than previous level. In the end `levels - 1` will be our answer, because one time in the end when we do not have anythin to add, `levels` still be incremented by one.\\n\\nFinally, we check if we still have fresh oranges, and if yes, return `-1`. If not, we need to return `max(levels-1, 0)`, because it can happen, that our queue was empty in the beginning and we do not need to subtract `1`.\\n\\n**Complexity**: time complexity is `O(mn)`, because we first traverse our grid to fill `queue` and found number of fresh oranges. Then we use classical `bfs`, so each node will be added and removed from `queue` at most `1` time. Space complexity is also can be `O(mn)`, we can have for example `O(mn)` rotten oranges in the very beginnig.\\n\\n```\\nclass Solution:\\n def orangesRotting(self, grid):\\n m, n, queue, fresh = len(grid), len(grid[0]), deque(), 0\\n for i,j in product(range(m), range(n)):\\n if grid[i][j] == 2: queue.append((i,j))\\n if grid[i][j] == 1: fresh += 1\\n dirs = [[1,0],[-1,0],[0,1],[0,-1]]\\n levels = 0\\n \\n while queue:\\n levels += 1\\n for _ in range(len(queue)):\\n x, y = queue.popleft()\\n for dx, dy in dirs:\\n if 0\u003c=x+dx\u003cm and 0\u003c=y+dy\u003cn and grid[x+dx][y+dy] == 1:\\n fresh -= 1\\n grid[x+dx][y+dy] = 2\\n queue.append((x+dx, y+dy))\\n \\n return -1 if fresh != 0 else max(levels-1, 0)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1596964369, | |
| "creationDate": 1596964355 | |
| } | |
| }, | |
| { | |
| "id": 901350, | |
| "title": "[Python] short O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-domino-rotations-for-equal-row", | |
| "post": { | |
| "id": 1641937, | |
| "content": "Nothing very special about this problem: we just need to do, what is asked. Let us do it in two steps:\\n1. Find out if we are able to rotate several dominoes to get what we want. How we can do it? All we need to do is to evaluate intersections of all sets of values for each domino. If this set is empty, then answer is `-1`.\\n2. Now, let us look on the first element of `s` if it is not empty. Then we calculate two numbers: one if we want to rotate them such that upper line has equal numbers and another if we want to rotate if we want second line have equal numbers. Finally, we return minumum of these two numbers. (note, that it can happen also, that `s` has two elements, it means, that all dominoes are equal, and when we make one of the rows equal, the second one will have equal numbers as well).\\n\\n**Complexity**: time complexity is `O(n)`, because we traverse our list only 2 times each. Note, that even though we traverse our lists twice, this algorithm is not 2 times slower than so-called one-pass traversals.\\n\\n```\\nclass Solution:\\n def minDominoRotations(self, A, B):\\n s, n = set([1,2,3,4,5,6]), len(A)\\n for i in range(n): s \u0026= set([A[i], B[i]])\\n if not s: return -1\\n flips1 = sum(A[i] == list(s)[0] for i in range(n))\\n flips2 = sum(B[i] == list(s)[0] for i in range(n))\\n return min(n - flips1, n - flips2) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603098113, | |
| "creationDate": 1603098113 | |
| } | |
| }, | |
| { | |
| "id": 880072, | |
| "title": "[Python] Oneliner explained", | |
| "taskUrl": "https://leetcode.com/problems/complement-of-base-10-integer", | |
| "post": { | |
| "id": 1604849, | |
| "content": "What we actually need to find in this problem is length of our number in bits: if we have `10 = 1010`, then complementary is `5 = 101`. Note, that `5 + 10 = 15 = 2^4 - 1`. So, let us just find length of our number in bits and subtract `N-1`.\\n\\n**Complexity** time complexity is `O(log N)` to find its length; space complexity is also `O(log N)` to keep binary representation of our number.\\n\\n```\\nclass Solution:\\n def bitwiseComplement(self, N):\\n return (1\u003c\u003c(len(bin(N)) - 2)) - 1 - N\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601889155, | |
| "creationDate": 1601889155 | |
| } | |
| }, | |
| { | |
| "id": 964319, | |
| "title": "[Python] Modular arithmetic, explained", | |
| "taskUrl": "https://leetcode.com/problems/pairs-of-songs-with-total-durations-divisible-by-60", | |
| "post": { | |
| "id": 1751629, | |
| "content": "If you are familiar with modular arithmetic, this problem will be very easy for you. So, we need to find number of pairs of songs, such that total duration in each pair is divisible by `60`: there can be several cases how it is possible. Imagine we have `2` songs `a` and `b`, then:\\n[1]. `a` and `b` have reminders `0`.\\n[2]. `a` has reminder `1` and `b` has reminder `59`.\\n[3]. `a` has reminder `2` and `b` has reminder `58`.\\n\\n[59]. `a` has reminder `58` and `b` has reminder `2`.\\n[60] `a` has reminder `59` and `b` has reminder `1`.\\n\\nSo, what we need to do now: for each reminder calculate how many number we have with this reminder and then evaluate sum of products: `a1*a59 + a2*a58 + ...`, where `a1` is number of numbers with reminder `1` and so on. Also we need to be careful with reminders `0` and `30`: for them we need to choose number of combinations.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(60) = O(1)`.\\n\\n```\\nclass Solution:\\n def numPairsDivisibleBy60(self, time):\\n d, T = Counter(), 60\\n for t in time: d[t%T] += 1\\n ans = sum(d.get(i,0)*d.get(T-i,0) for i in range(1, T//2))\\n q1, q2 = d.get(0,0), d.get(T//2, 0)\\n return ans + q1*(q1-1)//2 + q2*(q2-1)//2\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607418882, | |
| "creationDate": 1607418882 | |
| } | |
| }, | |
| { | |
| "id": 948435, | |
| "title": "[Python] Math, Pigeon holes, explained", | |
| "taskUrl": "https://leetcode.com/problems/smallest-integer-divisible-by-k", | |
| "post": { | |
| "id": 1724286, | |
| "content": "First of all, let us notice, that if number is divisible by `2` or by `5`, then we need to return `-1` immediatly, because number ending with `1` can not divide by `2` or `5`. From now on we assume, that `K` is not divisible by `2` or `5`. Let us consider numbers:\\n\\n`1`\\n`11`\\n`111`\\n...\\n`111...111`,\\n\\nwhere were have `K` ones in the last group. Then, there can be only two cases:\\n1. All reminders of given numbers when we divide by `K` are different.\\n2. Some two reminders are equal.\\n\\nIn the first case, we have `K` numbers and also `K` possible reminders and they are all different, it means, that one of them will be equal to `0`.\\n\\nIn the second case, two numbers have the same reminder, let us say number `11...1111` with `a` ones and `111...11111` with `b` ones, where `b \u003e a`. Then, difference of these two numbers will be divisible by `K`. What is the difference? It is number `11...1100...000` with `b-a` ones and `a` zeroes at the end. We already mentioned that `K` is not divisible by `2` or `5` and it follows, that `11...111` divisible by `K` now, where we have `b-a` ones.\\n\\nSo, we proved the following statements: **if K not divisible by 2 and 5, then N \u003c= K**. What we need to do now is just iterate through numbers and stop when we find number divisible by `K`. To simplify our cumputation, we notice, that each next number is previous multiplied by `10` plus `1`.\\n\\n**Complexity**: time complexity is `O(n)`, space is `O(1)`.\\n\\n```\\nclass Solution(object):\\n def smallestRepunitDivByK(self, K):\\n if K % 2 == 0 or K % 5 == 0: return -1\\n rem, steps = 1, 1\\n while rem % K != 0:\\n rem = (rem*10 + 1) % K\\n steps += 1\\n return steps\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606294818, | |
| "creationDate": 1606294818 | |
| } | |
| }, | |
| { | |
| "id": 835958, | |
| "title": "[Python] 2 Easy recursion solutions, explained", | |
| "taskUrl": "https://leetcode.com/problems/sum-of-root-to-leaf-binary-numbers", | |
| "post": { | |
| "id": 1527459, | |
| "content": "Let us traverse our tree and change values of nodes, so when we reach leaf we will have in this leaf exactly the number we need to add to total sum. Imagine, we have path `10110`, then let us look at sequence: `1, 10, 101, 1011, 10110`, which is equivalent to `1, 2, 5, 11, 22`. \\n\\n1. If we reached leaf, add value of this leaf to total sum.\\n2. Check left and right children and if they exist, update their values; run dfs for these children.\\n\\n**Complexity**: time complexity is `O(n)`: to traverse our tree. Space complexity is `O(h)` for dfs stack. Note, that we change our tree in process, but it can be easily avoided: instead of changing values we can return value for `dfs` function.\\n\\n```\\nclass Solution:\\n def sumRootToLeaf(self, root):\\n def dfs(node):\\n if not node.left and not node.right: self.sum += node.val\\n for child in filter(None, [node.left, node.right]):\\n child.val += node.val * 2\\n dfs(child)\\n \\n self.sum = 0\\n dfs(root)\\n return self.sum\\n```\\n\\n### Solution 2: without changing tree\\n\\n```\\nclass Solution:\\n def sumRootToLeaf(self, root):\\n def dfs(node, Q):\\n if not node.left and not node.right: self.sum += Q\\n for child in filter(None, [node.left, node.right]):\\n dfs(child, Q*2 + child.val)\\n \\n self.sum = 0\\n dfs(root, root.val)\\n return self.sum\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599552731, | |
| "creationDate": 1599552471 | |
| } | |
| }, | |
| { | |
| "id": 929284, | |
| "title": "[Python] O(n): look at child, explained", | |
| "taskUrl": "https://leetcode.com/problems/maximum-difference-between-node-and-ancestor", | |
| "post": { | |
| "id": 1690986, | |
| "content": "Let us traverse our tree from top to bottom with `dfs` function, where we pass parameters:\\n\\n1. `node` is current node we visiting\\n2. `high` is maximum over all node values, which are above our `node`, that is the maximum among parent, parent of parent, parent of parent of parent and so on.\\n3. `low` is minumum over all node values, which are above our `node`.\\n\\nNo, we iterate over our tree and:\\n1. Update our `self.Max`: look at two values `abs(node.val - low)` and `abs(node.val - high)`: it will be the biggest candidates for difference between node and its ancestor, where `node` is **lying in lower layer**.\\n2. Now, we run our `dfs` for left and right children, where we updated `low` and `high` values: we need to include current `node.val`.\\n\\nWe start with `dfs(root, root.val, root.val)`, because we do not have nodes which are above our root.\\n\\n**Complexity**: time complexity is `O(n)`, space complexity is `O(h)`, as any usual dfs have.\\n\\n```\\nclass Solution:\\n def maxAncestorDiff(self, root):\\n \\n self.Max = 0\\n def dfs(node, low, high): \\n if not node: return\\n\\n self.Max = max(self.Max, abs(node.val-low), abs(node.val-high))\\n low1, high1 = min(low, node.val), max(high, node.val)\\n dfs(node.left, low1, high1)\\n dfs(node.right, low1, high1)\\n \\n dfs(root, root.val, root.val)\\n return self.Max\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604915984, | |
| "creationDate": 1604915984 | |
| } | |
| }, | |
| { | |
| "id": 667781, | |
| "title": "[Python] 3 Lines O(n log n) with sort, explained", | |
| "taskUrl": "https://leetcode.com/problems/two-city-scheduling", | |
| "post": { | |
| "id": 1235983, | |
| "content": "Let us first send all the people to the first city. Now, we need to choose half of them and change their city from first to second. Which ones we need to choose? Obviously the half with the smallest **difference** of costs between second and first cities. This difference can be negative and positive. Let us go through example: `costs = [[10,20],[30,200],[400,50],[30,20]]`\\nThen:\\n1. We put all of them to 1 city and pay `10 + 30 + 400 + 30`\\n2. Now, evaluate differences: `10, 170, -350, -10`.\\n3. Choose 2 smallest differences, in this case it is `-350` and `-10` (they are negative, so we can say we get a refund)\\n4. Evaluate final sum as `10 + 30 + 400 + 30` + `-350 + -10 = 110`\\n\\n**Complexity** is `O(n log n)`, because we need to make one sort, and `O(n)` for evaluating differences and two sums. Space complexity is `O(n)`, because we need to keep array of differences.\\n\\n```\\nclass Solution:\\n def twoCitySchedCost(self, costs):\\n FirstCity = [i for i,j in costs]\\n Diff = [j - i for i,j in costs]\\n return sum(FirstCity) + sum(sorted(Diff)[:len(costs)//2])\\n```\\n\\nIt can be written as oneliner, but then it is quite difficult to follow.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote**!", | |
| "updationDate": 1591183212, | |
| "creationDate": 1591169562 | |
| } | |
| }, | |
| { | |
| "id": 807541, | |
| "title": "[Python] Trie with reversed words, explained", | |
| "taskUrl": "https://leetcode.com/problems/stream-of-characters", | |
| "post": { | |
| "id": 1479198, | |
| "content": "It is pretty straightforward to use Tries for these type of problems, however it is not obvious how. My first solution was as it is given in the hint of this problem: create Trie of all given words and keep also set of all possible nodes in our trie for suffixes of our stream. However it was working very slow, \u003e10000ms initialy and 7000-9000ms after optimizations. \\n\\nSo, alternative idea is to put all our words to Trie in reversed order. Why it can be a good idea? Imagine we have a current stream `abcdefghij` and we have dictionary `[hij, xyz, abc, hijk]` Then what we need to check if some suffix of this word in our dictinonary. It means that `jihgfedcba` should have `jih` as prefix. If we add one letter to strim, so we have `abcdefghijk`, we need to find prefixes in `kjihgfedcba` and so on.\\n\\nSo, what we have in my code?\\n\\n1. `Trie` class with initialization and `insert` function. Each node has children and flag `.end_node`, which says if some word ends with this node.\\n2. Put all reversed words to our Trie\\n3. For each new element of stream, we keep it in `deque`, so we can easily add it to the left of our reversed stream. Then we traverse our `Trie` and look if we reached some end node.\\n\\n**Complexity**: Let `m` be the longest length of word and `n` be number of words. Also let `w` be number of `query(letter)`. Then space complexity is `O(mn + w)` to keep our tree. In fact we can cut our `deque` if it has length more than `m`, because we never reach nodes which are far in our deque. Time complexity is `O(wm)`, because for each of `w` queries we need to traverse at most `m` letters in our trie.\\n\\nNote that other method complexity I mentioned in the beginning in theory is also `O(wm)`, but in practise it works like `10` times slower. The problem is with tests like `aaaaaa...aaab`.\\n\\n\\n```\\nclass TrieNode:\\n def __init__(self):\\n self.children, self.end_node = {}, 0\\n \\nclass Trie:\\n def __init__(self):\\n self.root = TrieNode()\\n\\n def insert(self, word):\\n root = self.root\\n for symbol in word:\\n root = root.children.setdefault(symbol, TrieNode())\\n root.end_node = 1\\n\\nclass StreamChecker:\\n def __init__(self, words):\\n self.trie = Trie()\\n self.Stream = deque()\\n for word in words: self.trie.insert(word[::-1])\\n \\n def query(self, letter):\\n self.Stream.appendleft(letter)\\n cur = self.trie.root\\n for c in self.Stream:\\n if c in cur.children:\\n cur = cur.children[c]\\n if cur.end_node: return True\\n else: break\\n return False\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1598190829, | |
| "creationDate": 1598186598 | |
| } | |
| }, | |
| { | |
| "id": 850437, | |
| "title": "[Python] O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/robot-bounded-in-circle", | |
| "post": { | |
| "id": 1553378, | |
| "content": "Let `dx, dy` be directions of our robot and `x,y` be its coordinates. Then using linear algepra we can say that if we rotate to the left, then `dx, dy = -dy, dx`, similar if we rotate to the right. So, now we can easily follow the place of our robot. How to understand if his path will be bounded by some circle? We need to understand if he is going to loop. There are `3` possible options where path will be bounded.\\n1. In the end it will arrive to the starting position.\\n2. It will not arrive to the starting position and his orientation is rotated to the left or to the right. Then it can be shown easily that after `4` loops robot will return to the original place.\\n3. It will not arrive to the start and his orientation is opposite, then after `2` loops he will arrive at the starting place.\\n\\nSo, let us just check that after `4` times we traverse our `instructions` robot will be at the start, that is all!\\n\\n**Complexity**: Time complexity is `O(4n)`, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def isRobotBounded(self, instructions):\\n dx, dy, x, y = 0, 1, 0, 0\\n for l in 4*instructions:\\n if l == \"G\": \\n x, y = x+dx, y+dy\\n elif l == \"L\":\\n dx, dy = -dy, dx\\n else:\\n dx, dy = dy, -dx\\n \\n return (x,y) == (0,0)\\n```\\n\\n**PS** I realized that we do not really need to traverse `instructions` 4 times, we can just return `(x,y) == 0 or (dx, dy) != (0,1)`, but this solution was already provided by others, so I left my solution as it is.\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600330466, | |
| "creationDate": 1600330314 | |
| } | |
| }, | |
| { | |
| "id": 695029, | |
| "title": "[Python] Binary search O(n log n) average with Rabin-Karp, explained", | |
| "taskUrl": "https://leetcode.com/problems/longest-duplicate-substring", | |
| "post": { | |
| "id": 1284382, | |
| "content": "This is quite difficult problem in fact and you will be very unlucky if you have this on real interview. However if you familiar with **Rabin-Karp** algorighm, it will be not so difficult. \\nYou can see it in full details on Wikipedia: https://en.wikipedia.org/wiki/Rabin%E2%80%93Karp_algorithm\\n\\nHere I briefly explain the idea of it. Imagine, that we have string `abcabcddcb`, and we want to check if there are two substrings of size `3`, which are equal. Idea is to **hash** this substrings, using rolling hash, where `d` is our **base** and `q` is used to avoid overflow.\\n1. for `abc` we evaluate `[ord(a)*d^2 + ord(b)*d^1 + ord(c)*d^0] % q` \\n2. for `bca` we evaluate `[ord(b)*d^2 + ord(c)*d^1 + ord(a)*d^0] % q`\\n Note, that we can evaluate rolling hash in `O(1)`, for more details please see wikipedia.\\n...\\n\\nHowever, it can happen that we have **collisions**, we can falsely get two substrings with the same hash, which are not equal. So, we need to check our candidates.\\n\\n### Binary search for help\\nNote, that we are asked for the longest duplicate substring. If we found duplicate substring of length `10`, it means that there are duplicate substrings of lenths `9,8, ...`. So, we can use **binary search** to find the longest one.\\n\\n**Complexity** of algorighm is `O(n log n)` if we assume that probability of collision is low.\\n\\n### How to read the code\\n\\nI have `RabinKarp(text, M,q)` function, where `text` is the string where we search patterns, `M` is the length we are looking for and `q` is prime modulo for Rabin-Karp algorighm.\\n\\n1. First, we need to choose `d`, I chose `d = 256`, because it is more than `ord(z)`.\\n2. Then we need to evaluate auxiliary value `h`, we need it for fast update of rolling hash.\\n3. Evalute hash for first window\\n4. Evaluate hashes for all other windows in `O(n)` (that is `O(1)` for each window), using evaluated `h`. \\n5. We keep all hashes in **dictionary**: for each hash we keep start indexes of windows.\\n6. Finally, we iterate over our dictionary and for each unique hash we check all possible combinations and compare not hashes, but original windows to make sure that it was not a collision.\\n\\nNow, to the `longestDupSubstring(S)` function we run binary search, where we run our `RabinKarp` funcion at most `log n` times.\\n\\n```\\nclass Solution:\\n def RabinKarp(self,text, M, q):\\n if M == 0: return True\\n h, t, d = (1\u003c\u003c(8*M-8))%q, 0, 256\\n\\n dic = defaultdict(list)\\n\\n for i in range(M): \\n t = (d * t + ord(text[i]))% q\\n\\n dic[t].append(i-M+1)\\n\\n for i in range(len(text) - M):\\n t = (d*(t-ord(text[i])*h) + ord(text[i + M]))% q\\n for j in dic[t]:\\n if text[i+1:i+M+1] == text[j:j+M]:\\n return (True, text[j:j+M])\\n dic[t].append(i+1)\\n return (False, \"\")\\n\\n def longestDupSubstring(self, S):\\n beg, end = 0, len(S)\\n q = (1\u003c\u003c31) - 1 \\n Found = \"\"\\n while beg + 1 \u003c end:\\n mid = (beg + end)//2\\n isFound, candidate = self.RabinKarp(S, mid, q)\\n if isFound:\\n beg, Found = mid, candidate\\n else:\\n end = mid\\n\\n return Found\\n```\\n\\n**Further discussion** I did some research in this domain, and there are different ways to handle this problem:\\n1. You can solve it, using **suffix array** in `O(n log n)` (or even `O(n)` with **suffix trees**) complexity, see https://cp-algorithms.com/string/suffix-array.html for suffix array which is a bit easier than suffix trees https://en.wikipedia.org/wiki/Suffix_tree\\n2. You can solve it with **Tries**, complexity To be checked.\\n3. I think there is solution where we use KMP, but I have not seen one yet.\\n4. If you have more ideas, plese let me know!\\n\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592681821, | |
| "creationDate": 1592559292 | |
| } | |
| }, | |
| { | |
| "id": 857489, | |
| "title": "[Python] linear solution, using cumulative sums, explained", | |
| "taskUrl": "https://leetcode.com/problems/car-pooling", | |
| "post": { | |
| "id": 1565777, | |
| "content": "Let us start with example and understand what exactly we are asked to do:\\n`trips = [[3,2,7],[3,7,9],[8,3,9]], capacity = 11`. Let us represent it in the following way:\\n\\n`# # 3 3 3 3 3 # # #`\\n`# # # # # # # 3 3 3`\\n`# # # 8 8 8 8 8 8 8`\\n\\nNow, the question is we sum all these lists, where we deal `#` as `0` (`0 0 3 11 11 11 11 11 11 11`) will some number be more than `capacity = 11` or not. Let us instead each list construct another list, such that its cumulative sum is our list:\\n\\n`0 0 3 0 0 0 0 -3 0 0 0`\\n`0 0 0 0 0 0 0 3 0 0 -3`\\n`0 0 0 8 0 0 0 0 0 0 -8`\\n\\nThen if we sum these lists and evaluate cumulative sums, we will have exactly what is needed:\\n\\n`0 0 3 8 0 0 0 0 0 0 -11 -\u003e cumulative sums -\u003e 0 0 3 11 11 11 11 11 11 11 0`\\n\\n**Complexity**: time and space complexity is `O(m)`, where `m` is maximum point of time we have.\\n\\n```\\nclass Solution:\\n def carPooling(self, trips, capacity):\\n m = max([i for _,_,i in trips])\\n times = [0]*(m+2)\\n for i,j,k in trips:\\n times[j+1] += i\\n times[k+1] -= i\\n return max(accumulate(times)) \u003c= capacity \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600685481, | |
| "creationDate": 1600685481 | |
| } | |
| }, | |
| { | |
| "id": 796574, | |
| "title": "[Python] Math O(k) solution with explanation", | |
| "taskUrl": "https://leetcode.com/problems/distribute-candies-to-people", | |
| "post": { | |
| "id": 1459075, | |
| "content": "There are different ways how you can handle this problem, I prefer mathematical way. Let us define `k = num_people` and `n = candies` and try to understand how many candies we need to give to `i`-the person. \\n\\n| 1 | 2 | 3 | ... | k |\\n|------|-----|------|-----|-----|\\n| **k+1** | **k+2** | **k+3** | **...** | **2k** |\\n| **...** | **...** | **...** | **...** | **...** |\\n| **sk+1** | **...** | **sk+i** | | |\\n\\nWe need to find the biggest `s`, such that the sum of numbers before is less or equal to `n`. Let us compute it:\\n\\n**1.** First row: `k(k+1)/2`, sum of arithmetic progression.\\n\\n**2.** Second row: `k(k+1)/2 + k^2`.\\n\\n**3.** Third row: `k(k+1)/2 + 2*k^2`.\\n...\\n\\n**s-1.** `k(k+1)/2 + (s-1)*k^2`.\\n\\n**s.** `s*k*i + i(i+1)/2`.\\n\\nLet us evaluate this sum and solve quadratic inequality:\\n\\n\\n\\n\\nSo, we have root `s = ((-1-2*i) + sqrt(1+8*n))/(2*k)` and we need to find the biggest integer number which is less than `s`, let us define it `t = floor(s)`.\\nNow, how many candies we need to give to this person? It is `i + (k+i) + ... + (sk+i) = i*(t+1) + k*t*(t+1)//2`. Finally, we need to find the last person, who gets the rest of the candies. How we can do it? I evaluate difference `s - floor(s)` and choose the person with the biggest difference.\\n\\n**Complexity**: time and space complexity is `O(k)`, where `k` is number of people. \\n\\n\\n```\\nclass Solution:\\n def distributeCandies(self, candies, num_people):\\n k, n = num_people, candies\\n alloc = [0]*k\\n Final = (0, 0)\\n for i in range(1, k+1):\\n s = ((-1-2*i) + sqrt(1+8*n))/(2*k)\\n t = floor(s)\\n alloc[i-1] = i*(t+1) + k*t*(t+1)//2\\n Final = max(Final, (s-floor(s), i)) \\n \\n alloc[Final[1]-1] += (n - sum(alloc))\\n \\n return alloc\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597656003, | |
| "creationDate": 1597656003 | |
| } | |
| }, | |
| { | |
| "id": 924174, | |
| "title": "[Python] Oneliner O(n), explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-cost-to-move-chips-to-the-same-position", | |
| "post": { | |
| "id": 1682122, | |
| "content": "Quite easy problem when you undrstand what you need to do. So, we have chips on different positions, and we can move them for free in `+2` and `-2` positions: it means, that we can for free move all chips with **odd** positions to one odd position and chips with **even** positions to one even positions. Moreover, we can make these odd and even positions adjacent. So, what we need to do now is just calculate how many we have on even positions and on odd positions and choose the smallest number.\\n\\n**Complexity**: time complexity is `O(n)`, we just iterate our numbers once, space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def minCostToMoveChips(self, P):\\n return min((odd := sum(1 for p in P if p%2)), len(P) - odd)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604578587, | |
| "creationDate": 1604567768 | |
| } | |
| }, | |
| { | |
| "id": 925512, | |
| "title": "[Python] Short and clean binary search, explained", | |
| "taskUrl": "https://leetcode.com/problems/find-the-smallest-divisor-given-a-threshold", | |
| "post": { | |
| "id": 1684416, | |
| "content": "It this problem we need to find the smallest divisor, given a threshold. Notice, that this is perfect problem for binary search: we have row of answers for questions are we higher than threshold for given number? : `no, no, no, ... no, yes, yes, ... yes` and we need to find the place with first yes.\\n1. We define `beg = 0`, `end = max(nums) + 1`, so we know that answer for `beg` is `no` and we also know that answer for `end` is `yes`.\\n2. Look at the middle number: if answer is yes, it means, that we need to look at the right part: so you again have range with `no` in the beginning and `yes` in the end. If answer is no, we consider the second half.\\n3. Finally, we will find interval with size 2: `no, yes`, and we need to return `end`.\\n\\n**Complexity**: time complexity is `O(n log N)`, where `n` is lenght of `nums` and `N` is biggest number from `nums`. Additional space complexity is `O(1)`. (though we already have `O(n)` for our data)\\n\\n```\\nclass Solution:\\n def smallestDivisor(self, nums, threshold):\\n beg, end = 0, max(nums) + 1\\n while beg + 1 \u003c end:\\n mid = (beg + end)//2\\n if sum(ceil(num/mid) for num in nums) \u003c= threshold:\\n end = mid\\n else:\\n beg = mid \\n return end\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604820443, | |
| "creationDate": 1604654760 | |
| } | |
| }, | |
| { | |
| "id": 790113, | |
| "title": "[Python] O(k) on the fly, explained", | |
| "taskUrl": "https://leetcode.com/problems/iterator-for-combination", | |
| "post": { | |
| "id": 1447682, | |
| "content": "There are different ways to solve this problem, one of them is to generate all possible combination and then when we asked to return next, just take the next one. Also we can use bitmasks, where we try to generate next combination and check if we choose correct number of elements or not. However I prefer to do it in a bit different way, I say it is honest iterator, where we find next permutation, given current one. Let me consider and example:\\n\\n`acfxyz`, where we can use full alphabet. How can we find the next combination? We need to look at the end of our combination and try to increment it. Can we increment `z`? No, we can not, the same for `y` and `x`. What we can increment is `f`, so next combination will be `acghij`.\\nThis is the key remark of my method. Let us consider function `next()`:\\n\\n1. First we check if we already have some combination before, if not, just create the first one.\\n2. Now, we need to find the longest commont suffix, like we did in our example between current state and our string. I do this, using `commonprefix` function.\\n3. Now, we need to find the place for previous symbol in our `characters`. Why? Because in our example we have alphabet `abc...xyz`, but we can have something like `acdehkxyz`, and we need to know, what is going after `h`. It is `i`? No, in this case it is `k`.\\n4. Finally, we construct new state, taking first `len(character) - end - 1` elements from previous state and adding `end + 1` elements starting from `place + 1` from our `characters`.\\n5. To implement `hashNext()` we just need to check if we reached the last state.\\n\\n**Complexity** of `hasNext()` is `O(k)`, where `k = combinationLength`. Complexity of `next()` is also `O(k)`, because we need to find the longest suffix, also we need to find element in string, using `index()` (this can be reduced to `O(1)`, using hash table) and finally, we need to construct and return new state, which has length `k`, which can not be improved.\\n\\n```\\nfrom os.path import commonprefix\\n\\nclass CombinationIterator:\\n\\n def __init__(self, characters, combinationLength):\\n self.c = characters\\n self.len = combinationLength\\n self.state = \"\"\\n \\n def next(self):\\n if self.state == \"\":\\n self.state = self.c[:self.len]\\n else:\\n end = len(commonprefix([self.c[::-1], self.state[::-1]]))\\n place = self.c.index(self.state[-end-1])\\n self.state = self.state[:-end-1] + self.c[place + 1: place + 2 + end]\\n return self.state\\n\\n def hasNext(self):\\n return self.state != self.c[-self.len:]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1597346325, | |
| "creationDate": 1597346325 | |
| } | |
| }, | |
| { | |
| "id": 878505, | |
| "title": "[Python] Sort starts in O(n log n), explained", | |
| "taskUrl": "https://leetcode.com/problems/remove-covered-intervals", | |
| "post": { | |
| "id": 1602243, | |
| "content": "Let us sort our intervals by their starts and traverse them one by one (if we have the same ends, we first choose intervals with smaller ends, so they will be traversed first) Also let us keep `right` variable, which will be the biggest right end of interval so far. So, what does it mean that one interval is covered by some other? It means that `end \u003c= right`: we have some previous interval with end more than current end and start which is less than current interval.\\n\\n**Complexity**: for time complexity we sort intervals in `O(n log n)` and then traverse them in `O(n)`. Space complexity is `O(n)` if we are not allowed to change `intervals` and `O(log n)` we are allowed to modify `intervals`.\\n\\n```\\nclass Solution:\\n def removeCoveredIntervals(self, intervals):\\n intervals.sort(key = lambda x: (x[0], -x[1]))\\n right, rem, n = -1, 0, len(intervals)\\n for _, end in intervals:\\n if end \u003c= right:\\n rem += 1\\n else:\\n right = end\\n return n - rem\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1601812668, | |
| "creationDate": 1601812555 | |
| } | |
| }, | |
| { | |
| "id": 918946, | |
| "title": "[Python] simple O(n) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/convert-binary-number-in-a-linked-list-to-integer", | |
| "post": { | |
| "id": 1672879, | |
| "content": "What we need to do in this problem is just to understand how binary numbers work. Imagine, that we have number `101100`. Then, it is equal to `1*2^5 + 0*2^4 + 1*2^3 + 1*2^2 + 0*2^1 + 0^2^0`.\\n\\nSo what we need to do is just to iterate over our linked list, multiply current `s` by `2` and add value of new element!\\n\\n**Complexity**: time complexity is `O(n)`, where `n` is length of our linked list and space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def getDecimalValue(self, head):\\n s = 0\\n while head:\\n s = 2*s + head.val\\n head = head.next\\n return s\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604220491, | |
| "creationDate": 1604220491 | |
| } | |
| }, | |
| { | |
| "id": 853592, | |
| "title": "[Python] Solution, using queue, explained", | |
| "taskUrl": "https://leetcode.com/problems/sequential-digits", | |
| "post": { | |
| "id": 1558694, | |
| "content": "Let us create queue, where we put numbers `1,2,3,4,5,6,7,8,9` at the beginning. Then on each step we are going to extract number and put this number with added to the end incremented last digit: so we have on the next step:\\n\\n`2,3,4,5,6,7,8,9,12`\\n`3,4,5,6,7,8,9,12,23`\\n...\\n`12,23,34,45,56,67,78,89`\\n`23,34,45,56,67,78,89,123`,\\n...\\n\\nOn each, when we extract number from the beginning we check if it is in our range and if it is, we put it into our `out` list. Then we add new candidate to the end of our queue. In this way we make sure, that we generate elements in increasing order.\\n\\n**Complexity**: There will be `9+8+...+ 1` numbers with sqeuential digits at all and for each of them we need to check it at most once (though in practice we wil finish earlier), so time complexity is `O(45) = O(1)`. Space complexity is also `O(45) = O(1)`.\\n\\n```\\nclass Solution:\\n def sequentialDigits(self, low, high):\\n out = []\\n queue = deque(range(1,10))\\n while queue:\\n elem = queue.popleft()\\n if low \u003c= elem \u003c= high:\\n out.append(elem)\\n last = elem % 10\\n if last \u003c 9: queue.append(elem*10 + last + 1)\\n \\n return out\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1600503102, | |
| "creationDate": 1600503102 | |
| } | |
| }, | |
| { | |
| "id": 829720, | |
| "title": "[Python] O(n1 + n2) inorder traversal, explained", | |
| "taskUrl": "https://leetcode.com/problems/all-elements-in-two-binary-search-trees", | |
| "post": { | |
| "id": 1517123, | |
| "content": "Pretty **easy** problem in my opinion: because the first idea which you usually think when you see this problem will work. So, what we need to do?\\n\\n1. Traverse each tree, using inorder traversal, in this way for BST result will be sorted list.\\n2. Now, we have two sorted lists, and all we need to do is to merge them, using the same routine we use in merge sort.\\n\\n**Complexity**: time complexity is `O(n1)` for first BST, where `n1` is number of nodes and `O(n2)` for the second tree. Then we need to merge and we do it in `n1+n2` time, so overall time complexity is `O(n1+n2)`. Space complexity is also `O(n1+n2)`. I think space can be improved a bit, if we somehow directly merge values from both trees in the same list.\\n\\n```\\nclass Solution:\\n def getAllElements(self, root1, root2):\\n def inorder(root, lst):\\n if not root: return\\n inorder(root.left, lst)\\n lst.append(root.val)\\n inorder(root.right, lst)\\n \\n lst1, lst2 = [], []\\n inorder(root1, lst1)\\n inorder(root2, lst2)\\n \\n i1, i2, res = 0, 0, []\\n s1, s2 = len(lst1), len(lst2)\\n \\n while i1 \u003c s1 and i2 \u003c s2:\\n if lst1[i1] \u003c lst2[i2]:\\n res += [lst1[i1]]\\n i1 += 1\\n else:\\n res += [lst2[i2]]\\n i2 += 1\\n \\n return res + lst1[i1:] + lst2[i2:]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1599333727, | |
| "creationDate": 1599290627 | |
| } | |
| }, | |
| { | |
| "id": 953127, | |
| "title": "[Python] iterative dfs, explained", | |
| "taskUrl": "https://leetcode.com/problems/jump-game-iii", | |
| "post": { | |
| "id": 1732835, | |
| "content": "This is in fact graph traversal problem: given `start` position and moving rules, we need to check if we can reach node with value `0`. There are as usual 3 classical approaches how you can do it:\\n\\n1. bfs, using queue\\n2. dfs, using stack\\n3. dfs, using recursion\\n\\nIn this problem, dimensions are not very big, so we can actually choose any of the methods. I chose dfs, using stack, so, what we have here:\\n\\n`stack` is what we keep for our dfs traversal, `visited` is already visited indexes, so we will not have infinite loop. As usual, we extract element from the top of our `stack`, and if `arr[pos`] equal to zero, we reached our goal and we return True. Then we mark our node as visited and try to make two jumts: forward and backward. We do them only we did not visited these indexes yet.\\n\\n**Complexity**: Time complexity is `O(n)`, where `n` is size of our `arr`: we only traverse indexes in this array. Space complexity is `O(n)` as well to keep array of visited nodes (or we can modify `arr`, but I think it is a bit of a cheat).\\n\\n```\\nclass Solution:\\n def canReach(self, arr, start):\\n stack, visited, n = [start], set(), len(arr)\\n \\n while stack:\\n pos = stack.pop()\\n if arr[pos] == 0: return True\\n visited.add(pos)\\n cand1, cand2 = pos + arr[pos], pos - arr[pos]\\n if cand1 \u003c n and cand1 not in visited: stack.append(cand1)\\n if cand2 \u003e= 0 and cand2 not in visited: stack.append(cand2)\\n \\n return False\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606639368, | |
| "creationDate": 1606639368 | |
| } | |
| }, | |
| { | |
| "id": 735395, | |
| "title": "[Python] math solution + Oneliner, explained", | |
| "taskUrl": "https://leetcode.com/problems/angle-between-hands-of-a-clock", | |
| "post": { | |
| "id": 1355023, | |
| "content": "To solve this problem we need to understand the speeds of Hands of a clock.\\n\\n1. Let us find the place, where **hour hand** is. First, whe have `12` hours in total, for `360` degrees, that means `30` degrees per hour. Also, for every `60` minutes, our hour hand rotated by `1` hour, that is `30` degrees, so for every minute, it is rotated by `0.5` degrees. So, final place for hour hand is `30*hour + 0.5*minutes`\\n2. Let us find the place, where **minute hand** is: every `60` minutes minute hand makes full rotation, that means we have `6` degrees for each minute.\\n3. Finally, we evaluate absolute difference between these two numbers, and if angle is more than `180` degrees, we return complementary angle.\\n\\n**Complexity**: time and space is `O(1)`, we just use some mathematical formulae.\\n\\n```\\nclass Solution:\\n def angleClock(self, hour, minutes):\\n H_place = 30*hour + 0.5*minutes\\n M_place = 6*minutes\\n diff = abs(H_place - M_place)\\n return diff if diff \u003c= 180 else 360 - diff\\n```\\n\\n**Oneliner**\\nWe can write this as oneliner as well:\\n```\\nreturn min(abs(30*hour-5.5*minutes),360-abs(30*hour-5.5*minutes))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1594716305, | |
| "creationDate": 1594713427 | |
| } | |
| }, | |
| { | |
| "id": 988714, | |
| "title": "[Python] bfs with small trick, explained", | |
| "taskUrl": "https://leetcode.com/problems/jump-game-iv", | |
| "post": { | |
| "id": 1792568, | |
| "content": "In this problem we are asked to find shortest path between two nodes in some graph, so the first idea you should think is bfs (or Dijkstra algorithm). Actually, bfs is almost sufficient here, but we need to do one optimization which increase our speed dramatically.\\n\\n1. Let us use `d`: defaultdict, where for each value we keep list of all possible indexes for this value. We need this to make fast steps of type 3.\\n2. Let `visited` be as usual set of visited nodes, we need it in usual bfs, not to visit any node two times.\\n3. Let `visited_groups` be set of visited **values**: we need it for the following reason. Imagine, we have `arr = [1, 1, 1, 1, 1, 1, 1, 1, 1, 2]`. Then first time we see `1`, we visit all other `1`. Second time we see `1`, we do not need to check its neibors of type `3`, we already know that we visited them. Without this optimization time complexity can be potentially `O(n^2)`.\\n4. What we do next is classical **bfs**: we extract node from queue, visit two neibors of types `1` and `2` and if we did not visit value of this node yet, we visit its all neibors of type `3`.\\n\\n**Complexity**: time complexity is `O(n)`: we visit every index only once and try to visit every node no more than `3` times: for each type of neighbors. Space complexity is `O(n)` as well: to keep `visited` and `visited_groups` sets.\\n\\n```\\nclass Solution:\\n def minJumps(self, arr):\\n n = len(arr)\\n d = defaultdict(list)\\n for i, num in enumerate(arr):\\n d[num].append(i)\\n \\n queue = deque([(0, 0)])\\n visited, visited_groups = set(), set()\\n \\n while queue:\\n steps, index = queue.popleft()\\n if index == n - 1: return steps\\n \\n for neib in [index - 1, index + 1]:\\n if 0 \u003c= neib \u003c n and neib not in visited:\\n visited.add(neib)\\n queue.append((steps + 1, neib))\\n \\n if arr[index] not in visited_groups:\\n for neib in d[arr[index]]:\\n if neib not in visited:\\n visited.add(neib)\\n queue.append((steps + 1, neib))\\n visited_groups.add(arr[index])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1609059975, | |
| "creationDate": 1609059975 | |
| } | |
| }, | |
| { | |
| "id": 655787, | |
| "title": "[Python] O(nk) KMP with DP, very detailed explanation.", | |
| "taskUrl": "https://leetcode.com/problems/find-all-good-strings", | |
| "post": { | |
| "id": 1215786, | |
| "content": "## Part 1: Prefix function\\nRemind the definition of prefix function on a simple example: let `s = ababcaba`, then prefix funtion is `[0,0,1,2,0,1,2,3]`, because for example for substring `ababcab`, the longest equal prefix and suffix `ab` have length 2. There is efficient way to evaluate prefix function, using KMP algorighm. More precisely our function `prefix(self, s)` will give us the length of longest common prefix and suffix, for example for our `s = ababcaba` result will be equal to 3 and we can find it in O(len(s)).\\n\\n## Part 2: Preprosess evil\\nNow, we want to preprocess our `evil` string and create some useful data, we are going ot use later. Let us againg consider `A = evil = ababcaba`. Create `connections` as `T by k` matrix, where `T` is the size of our alphabet and `k = len(evil)`. In `connections[i][j]` we are going to store the length of maximum suffix of string `A_0,...,A_{i-1} + char(j)` which is at the same time is prefix of `A` (here char(0) = \"a\", char(1) = \"b\" and so on). A bit difficult to understand, let us consider example: `connections[3][0] = 1`, because `A_0 A_1 A_2 + char(0) = abaa` and this string has suffix `a` which is prefix of `A`. `connections[3][1] = 4`, because `A_0 A_1 A_2 + char(1) = abab`, which is prefix of `A`.\\nLet us fully fill this table `connections`:\\n\\n| | a | b | c | d | e | f |\\n|------------------------------|---|---|---|---|---|---|\\n| k = 0, starts with \"\" | 1 | 0 | 0 | 0 | 0 | 0 |\\n| k = 1, starts with \"a\" | 1 | 2 | 0 | 0 | 0 | 0 |\\n| k = 2, starts with \"ab\" | 3 | 0 | 0 | 0 | 0 | 0 |\\n| k = 3, starts with \"aba\" | 1 | 4 | 0 | 0 | 0 | 0 |\\n| k = 4, starts with \"abab\" | 3 | 0 | 5 | 0 | 0 | 0 |\\n| k = 5, starts with \"ababc\" | 6 | 0 | 0 | 0 | 0 | 0 |\\n| k = 6, starts with \"ababca\" | 1 | 7 | 0 | 0 | 0 | 0 |\\n| k = 7, starts with \"ababcab\" | 8 | 0 | 0 | 0 | 0 | 0 |\\n\\nLet us note one thing: there is **a lot** of zeros in this table, we can say that this table is sparse. So, we can write this table in different way, I called this list `conn`:\\n\\n1. `conn[0] = [0,1]`\\n2. `conn[1] = [0,1], [1,2]`\\n3. `conn[2] = [0,3]`\\n3. `conn[3] = [0,1], [1,4]`\\n3. `conn[4] = [0,3], [2,5]`\\n3. `conn[5] = [0,6]`\\n3. `conn[6] = [0,1], [1,7]`\\n3. `conn[7] = [0,8]`\\n\\nLooks better, is it? Howerer we still need one more table: `connections_num_zeros`, where we keep for every `k` and `j` number of zero elements in `k`-th row of matrix `connections`, which we met before element number `j`. Why we need this in the future? Because we need to deal with alphabetical order. \\n\\n## Part 3: Dynamic progaramming\\nLet us reformulate a bit our original problem and introduce funcion `findLesserGood(self, n, k, string, N, evil)`, where `n` is length of or `string`, `k` is length of `evil` and `N` is modulo which we use for long arithmetics. This function finds number of strings alphabetically less or equal than `string`, such that it do not have `evil` substring inside. Then it is enough to apply this function twice (for `s1`, `s2`), get difference and handle border case (string `s1`). \\n\\nWe have `dp_bord[i][j]` and `dp_notb[i][j]` two `n x k` arrays, first one to handle border cases, where we search for number of strings, starting with `i` characters of `string` and such that its longest suffix equal to prefix of `evil` has length `j`. Border cases means that next element we can take should be more or equal than corresponding element is `string`. Second array `dp_notb[i][j]` is for not border cases with the same logic it is number of all string of length `i`, such that the longest common suffix of it and prefix of `evil` has lengh `j`.\\n\\nPrecalcualted matrices help us efficiently update our tables: when we try to add new symbol we need to understand in `O(1)`, how changes its longes common suffix and prefix of string `evil`. That is why we evaluated our `connections` and `con` tables.\\n\\n## Part 4: Complexity\\n`n` is lenth of original string `s1` and `s2`, `k` is length of `evil` and `T` is the size of alphabet.\\n\\nTo create connections in part 2 we have complexity `O(k^2T)` (I think it can be improved to `O(kT)` if we do it in smarter way, but it is not the bottleneck, so we keep it like this), because we iterate over k, over all alphabet and apply our `O(k)` complexity prefix function once inside, same time is needed to evaluate `connections_num_zeros`. Memory here is `O(Tk)` to keep couple of matrixes.\\n\\nComplexity of `findLesserGood` is `O(nkT)`: there is two loops with size `n` and `k` and also inside we go over all `conn` list, which is sure not more than `k`. In fact, this complexity is equal to `O(nk)`, because matrix `connections` is very sparse and `conn` has `O(k)` elements instead of `O(kT)` (if I am wrong, please let me know!). Space complexity is obviously `O(nk)`.\\n\\nFinally, time complexity is `O(nk + k^2T) = O(nk)` for our constraints and space complexity is `O(Tk + nk) = O(nk)` also.\\n\\n## Part 5. Code\\nNow, if we put all the stuff we discussed togeter, we can have the following code:\\n\\n```\\nclass Solution:\\n def prefix(self, s):\\n p = [0] * len(s)\\n for i in range(1, len(s)):\\n k = p[i - 1]\\n while k \u003e 0 and s[k] != s[i]: \\n k = p[k - 1]\\n if s[k] == s[i]:\\n k += 1\\n p[i] = k\\n return p[-1]\\n\\n def CreateConnections(self, evil, T):\\n k = len(evil)\\n connections = [[-1]*T for _ in range(k)]\\n conn = [[] for _ in range(k)]\\n for i in range(k):\\n for letter in self.alphabet:\\n curr_max = self.prefix(evil + \"#\" + evil[0:i] + letter)\\n \\n if curr_max != k: #process case when we reached the end of evil string\\n connections[i][ord(letter) - ord(\"a\")] = curr_max\\n\\n if curr_max != 0:\\n conn[i].append([ord(letter) - ord(\"a\"), curr_max])\\n\\n connections_num_zeros = [[0] for _ in range(k)]\\n for i in range(k):\\n for j in range(1, T + 1):\\n connections_num_zeros[i] += [connections_num_zeros[i][-1] + (connections[i][j-1] == 0)]\\n\\n return connections_num_zeros, conn\\n\\n def findLesserGood(self, n, k, string, N, evil):\\n dp_bord = [[0]*k for _ in range(n)]\\n dp_notb = [[0]*k for _ in range(n)]\\n \\n dp_bord[0][0] = 1\\n \\n for it_n in range(n-1):\\n for it_k in range(k):\\n ord_num = ord(string[it_n + 1]) - ord(\"a\")\\n\\n for letter, s in self.con[it_k]:\\n dp_notb[it_n+1][s] += dp_notb[it_n][it_k]\\n if letter \u003c ord_num:\\n dp_notb[it_n+1][s] += dp_bord[it_n][it_k]\\n\\n dp_notb[it_n +1][0] += self.con_numzero[it_k][-1] * dp_notb[it_n][it_k] \\n dp_notb[it_n +1][0] += self.con_numzero[it_k][ord_num] * dp_bord[it_n][it_k]\\n \\n dp_notb[it_n+1][it_k] %= N\\n\\n index = self.prefix(evil + \"#\" + string[0:it_n+2])\\n if index != k and sum(dp_bord[it_n]) != 0:\\n dp_bord[it_n + 1][index] = 1\\n \\n return sum(dp_bord[-1]) + sum(dp_notb[-1])\\n\\n def findGoodStrings(self, n, s1, s2, evil):\\n self.alphabet = string.ascii_lowercase\\n N, k = 10**9 + 7, len(evil)\\n \\n self.con_numzero, self.con = self.CreateConnections(evil, len(self.alphabet))\\n res1 = self.findLesserGood(n + 1, k, \"#\" + s2, N, evil)\\n res2 = self.findLesserGood(n + 1, k, \"#\" + s1, N, evil)\\n return (res1 - res2 + 1 - (evil in s1)) % N\\n```\\n\\nIf you have any questions, feedback or improvements, feel free to ask. If you reached this place and like the explanations, please **upvote**!", | |
| "updationDate": 1590616144, | |
| "creationDate": 1590614551 | |
| } | |
| }, | |
| { | |
| "id": 921642, | |
| "title": "[Python] Oneliner using groupby, explained", | |
| "taskUrl": "https://leetcode.com/problems/consecutive-characters", | |
| "post": { | |
| "id": 1677794, | |
| "content": "What you need to do in this problem is just iterate over string and find groups of equal symbols, and then return the length of the longest group. Natural way to do it is to use functionality of itertools library, more precisely `groupby` function. By definition, if we do not specify arguments for groupby, it will create groups exactly with equal elements, so what we need to do is just to choose group with the biggest size and return it!\\n\\n**Complexity**: time and space complexity is `O(n)`, because we iterate over our data once, but also we need to have space to keep our groupby object.\\n\\n```\\nclass Solution:\\n def maxPower(self, s: str) -\u003e int:\\n return max(len(list(j)) for _,j in groupby(s))\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604393606, | |
| "creationDate": 1604393606 | |
| } | |
| }, | |
| { | |
| "id": 649959, | |
| "title": "[Python] O(n) time and O(k+H) space DFS preorder traversal, explained", | |
| "taskUrl": "https://leetcode.com/problems/pseudo-palindromic-paths-in-a-binary-tree", | |
| "post": { | |
| "id": 1206260, | |
| "content": "First note, that pseudo-palindromic path mean that it has all occurunces of digits even, may be except one: like 11223 can be written as 12321 and 111444 can not, because it has two digits with odd occurences. So, for each leaf we need to evaluate occurences of all digits and count it only if number of odd occurences is \u003c=1.\\n\\nLet ```dict_freq``` be a frequences dictionary for digits, where we keep 0 if we meet digit even number of times and 1 if we meet digit odd number of times. Let ```Pal``` be a variable, which counts number of odd frequences in ```dict_freq```: we want to find all leafs, for which this value is \u003c= 1.\\n\\nNow, what we do is simple dfs: preorder traversal. Because ```dict_freq``` is global variable and we change it in our recursion, we need to change back it values, when we go outside of recursion (note, that in some other solutions, which use bit manipulations, it is not necessary, but here we need to do like this). Finally, because we do only O(1) operations for each node, we have O(n) time complexity. We have O(k+H) space complexity, where H is the height of tree and k is number of digits (here k = 9) to maintain implicit stack and ```dict_freq``` dictionary.\\n\\n\\n```\\nclass Solution:\\n def dfs(self, root):\\n if not root: return\\n \\n cur, pal = self.dict_freq[root.val], self.Pal\\n \\n self.Pal = self.Pal - 1 if cur == 1 else self.Pal + 1\\n self.dict_freq[root.val] = (cur + 1) % 2\\n \\n if not root.left and not root.right and self.Pal \u003c= 1:\\n self.Res += 1\\n \\n self.dfs(root.left)\\n self.dfs(root.right)\\n \\n self.Pal, self.dict_freq[root.val] = pal, cur\\n \\n def pseudoPalindromicPaths (self, root):\\n self.dict_freq = defaultdict(int)\\n self.Pal, self.Res = 0, 0\\n self.dfs(root)\\n return self.Res\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1609233949, | |
| "creationDate": 1590344990 | |
| } | |
| }, | |
| { | |
| "id": 649795, | |
| "title": "[Python] O(mn) time and memory clean DP with explanations", | |
| "taskUrl": "https://leetcode.com/problems/max-dot-product-of-two-subsequences", | |
| "post": { | |
| "id": 1205995, | |
| "content": "Let ```dp[i][j]``` be the maximum dot product for first ```i``` numbers from ```nums1``` and first ```j``` numbers from ```nums2```. Note, that ```dp[0][0] = 0``` is for the case where we take 0 elements from both ```nums1``` and ```nums2``` (that is we use dummy first column and row). Let us forgot for the moment, that product need to be **not empty**, then we can just use ```dp[i+1][j+1] = max(dp[i][j] + nums1[i]*nums2[j], dp[i][j+1], dp[i+1][j])```, because we can:\\n1. Either include ```nums1[i]*nums2[j]``` into our dot product and we need to add value of ```dp[i][j]```\\n2. Or do not inculde ```nums1[i]*nums2[j]```, that is choose the best from ```dp[i][j+1]``` or ```dp[i+1][j]``` problems.\\n\\nNow, if we do it it can happen that our product is **empty**, and we need to handle this case separatly: it can happen if all numbers in one array are negative and all numbers in another array is positive.\\n\\n```\\nclass Solution:\\n def maxDotProduct(self, nums1, nums2):\\n M, N = len(nums1), len(nums2)\\n\\t\\t\\n if (max(nums1) \u003c 0 and min(nums2) \u003e 0):\\n return max(nums1) * min(nums2) \\n if (max(nums2) \u003c 0 and min(nums1) \u003e 0):\\n return min(nums1) * max(nums2) \\n\\t\\t\\t\\n dp = [[0 for _ in range(N+1)] for _ in range(M+1)]\\n for i in range(M):\\n for j in range(N):\\n dp[i+1][j+1] = max(dp[i][j] + nums1[i]*nums2[j], dp[i][j+1], dp[i+1][j])\\n return dp[-1][-1]\\n```\\n", | |
| "updationDate": 1590350878, | |
| "creationDate": 1590339308 | |
| } | |
| }, | |
| { | |
| "id": 660760, | |
| "title": "[Python] O(nk) solution with sets, explained.", | |
| "taskUrl": "https://leetcode.com/problems/check-if-a-string-contains-all-binary-codes-of-size-k", | |
| "post": { | |
| "id": 1224013, | |
| "content": "Go over all possible substrings of length `k` and add them to set, and check in the end if the size of our set is `2^k`. \\n\\n**Complexity** is `O(nk)`, do you know if it can be solved in better complexity?\\n\\n```\\nclass Solution:\\n def hasAllCodes(self, s, k):\\n sset = set()\\n for i in range(len(s) - k + 1):\\n sset.add(s[i:i+k])\\n return len(sset) == 1 \u003c\u003c k\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1590856760, | |
| "creationDate": 1590856760 | |
| } | |
| }, | |
| { | |
| "id": 660586, | |
| "title": "[Python] Clean O(M^2N) dp, 10 lines, explained", | |
| "taskUrl": "https://leetcode.com/problems/cherry-pickup-ii", | |
| "post": { | |
| "id": 1223663, | |
| "content": "The idea here is to use dynamic programming with 3 states: `dp[j][i1][i2]`, where `j` is the number of row and, `i1` is the number of column for the first robot and `i2` is the number of column for the second robot. I also added dummy columns filled with big negative numbers to handle with border cases.\\n\\nFirst, we need to fill `dp[0][1][M]` value of our table, which corresponds to column `0` for the first robot and column `M-1` for the second robot. Then we just go through the table and check all possible `3 x 3 = 9` cases for previous state of our robots, find maximum and update. We also need to deal with case, when they are at the same cell, which can be done with `(grid[j][i1-1] + grid[j][i2-1])//(1 + (i1 == i2))` code. In the end we need to return maximum over possile `M*M` values in the last row, that is for `dp[-1]`\\n\\n### Complexity \\nWe have `O(9*M*M*N)` time complexity, where `M` is number of columns and `N` is number of rows, because we potentially need to check upto 9 candidates. Time complexity is `O(M*M*N)` to keep `dp` table.\\n\\n\\n\\n```\\nclass Solution:\\n def cherryPickup(self, grid):\\n M, N = len(grid[0]), len(grid)\\n\\n dp = [[[-10**9] * (M+2) for _ in range(M+2)] for _ in range(N)]\\n dp[0][1][M] = grid[0][0] + grid[0][M-1]\\n for j in range(1, N):\\n for i1, i2 in product(range(1, M+1), range(1, M+1)):\\n cand_prev = []\\n for shift1, shift2 in product([-1,0,1], [-1,0,1]):\\n cand_prev.append(dp[j-1][i1 + shift1][i2 + shift2])\\n dp[j][i1][i2] = (grid[j][i1-1] + grid[j][i2-1])//(1 + (i1 == i2)) + max(cand_prev)\\n\\n return max(list(map(max, *dp[-1]))) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote**!", | |
| "updationDate": 1608369486, | |
| "creationDate": 1590854681 | |
| } | |
| }, | |
| { | |
| "id": 661778, | |
| "title": "[Python] Clean dfs with explanations", | |
| "taskUrl": "https://leetcode.com/problems/reorder-routes-to-make-all-paths-lead-to-the-city-zero", | |
| "post": { | |
| "id": 1225785, | |
| "content": "Let us put all the edges into adjacency list twice, one with weight `1` and one with weight `-1` with oppisite direction. Then what we do is just traverse our graph using usual dfs, and when we try to visit some neighbour, we check if this edge is usual or reversed.\\n\\n**Complexity** is `O(V+E)`, because we traverse our graph only once.\\n\\n```\\nclass Solution:\\n def dfs(self, start):\\n self.visited[start] = 1\\n for neib in self.adj[start]:\\n if self.visited[neib[0]] == 0:\\n if neib[1] == 1:\\n self.count += 1\\n self.dfs(neib[0])\\n \\n def minReorder(self, n, connections):\\n self.visited = [0] * n\\n self.adj = defaultdict(list) \\n self.count = 0\\n for i, j in connections:\\n self.adj[i].append([j,1])\\n self.adj[j].append([i,-1])\\n\\n self.dfs(0)\\n return self.count\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote**!", | |
| "updationDate": 1590899200, | |
| "creationDate": 1590898047 | |
| } | |
| }, | |
| { | |
| "id": 661757, | |
| "title": "[Python] 10 Lines, 90%, Multionomial coefficients, explained", | |
| "taskUrl": "https://leetcode.com/problems/probability-of-a-two-boxes-having-the-same-number-of-distinct-balls", | |
| "post": { | |
| "id": 1225742, | |
| "content": "This is an interesting mathematical problem. Denote by `k` different number of balls and by `B1, ..., Bk` number of balls of each type. Then we need to put into first box `X1, ..., Xk` balls and into the second `B1 - X1, ..., Bk - Xk`. We need to check 2 properties:\\n1. Number of balls in two boxes are equal.\\n2. Number of ball types in each boxes are equal.\\n\\nThen we need to evaluate total number of possibilites for boxes, using **Multinomial coefficients**, (see https://en.wikipedia.org/wiki/Multinomial_theorem for more details) and divide it by total number of possibilities. Let us work through example: `B1, B2, B3 = 1, 2, 3`, then all possible ways to put into boxes are:\\n1. (0, 0, 0) and (1, 2, 3)\\n2. (0, 0, 1) and (1, 2, 2)\\n3. (0, 0, 2) and (1, 2, 1)\\n\\n...\\n\\n22. (1, 2, 1) and (0, 0, 2)\\n23. (1, 2, 2) and (0, 0, 1)\\n24. (1, 2, 3) and (0, 0, 0)\\n\\nBut only for 2 of them holds the above two properties:\\n1. (0, 2, 1) and (1, 0, 2)\\n2. (1, 0, 2) and (0, 2, 1)\\n\\nSo, the answer in this case will be `[M(0, 2, 1) * M(1, 0, 2) + M(1, 0, 2) * M(0, 2, 1)]/ M(1, 2, 3)`\\n\\n**Complexity** We check all possible `(B1+1) * ... * (Bk+1)` splits into two boxes, and then evaluate number of zeros and multinomial coefficientes, so it is `O(B1 ... Bk * k)`\\n\\n**Update** There is more elegant way to use multinomial coefficients, which I updated.\\n\\n```\\nclass Solution:\\n def multinomial(self, n):\\n return factorial(sum(n))/prod([factorial(i) for i in n])\\n \\n def getProbability(self, balls):\\n k, n, Q = len(balls), sum(balls)// 2, 0\\n arrays = [range(0,i+1) for i in balls]\\n t = list(product(*arrays))\\n for i in range(len(t)):\\n if sum(t[i]) == n and t[i].count(0) == t[-i-1].count(0):\\n Q += self.multinomial(t[i]) * self.multinomial(t[-i-1]) \\n\\n return Q / self.multinomial(list(balls)) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote**!", | |
| "updationDate": 1599569963, | |
| "creationDate": 1590897910 | |
| } | |
| }, | |
| { | |
| "id": 685772, | |
| "title": "[Python] Classical down-up solution explained, O(n^3).", | |
| "taskUrl": "https://leetcode.com/problems/allocate-mailboxes", | |
| "post": { | |
| "id": 1267040, | |
| "content": "Let `dp[i][k]` be a minimum total distance when we use `i` houses and only `k` mailboxes.\\nThe idea is when we add new mailbox, undersand, how many houses it can cover.\\nHow we can evaluate `dp[i][k]`? We need to look for all smaller `j` at the element `dp[j][k-1]` and also we need to know what distance we need to add for houses between `j` and `i` with only one mailbox.\\n\\nGood idea is to precalculate all possible `costs[i][j]`: total distances to cover all houses between number `i` and number `j`. I used idea of **@hiepit**, who did it in `O(n^3)` elegant way: we need to put mailbox into the median of our points. Note, that this part can be improved to `O(n^2)`, but it is not worth it, because we have bigger terms.\\n\\nNow, all we need to do is to iterate over all `n` houses and over all `k` mailboxes and update all table `dp`, let us do it on example `houses = [1,4,8,10,20]`. Here by # I denoted elements which are in fact should be zeros: number of houses is less or equal than number of mailboxes. However it is not neccesary to see what is inside, because we never use these elements. We also define the first row of our `dp` table with `costs[0][:]`, because it is exactly total minimum distance for `1` mailbox.\\n\\n| | 1 | 4 | 8 | 10 | 20 |\\n|-------|---|---|---|----|----|\\n| **k = 1** | # | 3 | 7 | 13 | 15 |\\n| **k = 2** | # | # | 3 | 5 | 13 |\\n| **k = 3** | # | # | # | 2 | 5 |\\n\\n**Complexity**: time complexity is `O(n^3 + n^2k) = O(n^3)`, space complexity is `O(nk)`.\\n\\n\\n```\\nclass Solution:\\n def minDistance(self, houses, k):\\n n = len(houses)\\n houses = sorted(houses)\\n costs = [[0] * n for _ in range(n)]\\n \\n for i, j in product(range(n), range(n)):\\n median = houses[(i + j) // 2]\\n for t in range(i, j + 1):\\n costs[i][j] += abs(median - houses[t])\\n \\n dp = [[10**6] * k for _ in range(n)]\\n for i in range(n): dp[i][0] = costs[0][i]\\n \\n for k_it in range(1, k):\\n for i_1 in range(n):\\n for i_2 in range(i_1):\\n dp[i_1][k_it] = min(dp[i_1][k_it], dp[i_2][k_it-1] + costs[i_2+1][i_1])\\n \\n return dp[-1][-1] \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1592075579, | |
| "creationDate": 1592075325 | |
| } | |
| }, | |
| { | |
| "id": 959365, | |
| "title": "[Python] O(sqrt(n)) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/the-kth-factor-of-n", | |
| "post": { | |
| "id": 1743275, | |
| "content": "I do not know why this problem is marked medium: even bruteforce solution will work here fine, because given `n` is small: no more than `10000`. However I prefer more optimal solution: we can check only divisors which are less than square root of `n`: each of them will have pair: for any `d` divisor of `n`, number `n/d` is also divisor of `n`. There is one exception, when `d = n/d` and we do not have pair. Let us find all factors before square root of `n` and put the into list, and also put all divisors which are after square root of `n` to another list. Then we combine these two lists and return element number `k`.\\n\\n**Complexity**: time and space complexity is `O(sqrt(n))`, because there will be at most `2*sqrt(n)` factors of `n`.\\n\\n```\\nclass Solution:\\n def kthFactor(self, n, k):\\n f1, f2 = [], []\\n for s in range(1, int(sqrt(n)) + 1 ):\\n if n % s == 0:\\n f1 += [s]\\n f2 += [n//s]\\n \\n if f1[-1] == f2[-1]: f2.pop()\\n \\n factors = f1 + f2[::-1]\\n return -1 if len(factors) \u003c k else factors[k-1]\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1607074770, | |
| "creationDate": 1607074770 | |
| } | |
| }, | |
| { | |
| "id": 708109, | |
| "title": "[Python] O(n) dynamic programming, detailed explanation", | |
| "taskUrl": "https://leetcode.com/problems/longest-subarray-of-1s-after-deleting-one-element", | |
| "post": { | |
| "id": 1306918, | |
| "content": "One way to deal this problem is **dynamic programming**. Let `dp[i][0]` be the length of longest subarray of ones, such that it ends at point `i`. Let `dp[i][1]` be the length longest subarray, which has one **zero** and ends at point `i`. Let us traverse through our `nums` and update our `dp` table, we have two options:\\n\\n0. `dp[0][0] = 1` if `nums[0] = 1` and `0` in opposite case.\\n1. If `nums[i] = 1`, than to update `dp[i][0]` we just need to look into `dp[i-1][0]` and add one, the same true is for `dp[i][1]`.\\n2. If `nums[i] = 0`, than `dp[i][0] = 0`, we need to interrupt our sequence without zeroes. `dp[i][1] = dp[i-1][0]`, because we we added `0` and number of `1` is still `i-1`. \\n\\nLet us go through example `[1,0,1,1,0,0,1,1,0,1,1,1]`:\\nthen we have the following `dp` table:\\n\\n| 1 | 0 | 1 | 2 | 0 | 0 | 1 | 2 | 0 | 1 | 2 | 3 |\\n|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|\\n| **0** | **1** | **2** | **3** | **2** | **0** | **1** | **2** | **2** | **3** | **4** | **5** |\\n\\n\\n**Complexity**: time and space is `O(n)`, because we iterate over our table `dp` once. Space can be reduced to `O(1)` because we only look into the previous column of our table.\\n\\n**Extension and follow-up**. Note, that this solution can be easily extended for the case, when we need to delete `k` elements instead of one, with time complexity `O(nk)` and space complexity `O(k)`.\\n\\n**Other solutions**. This problem can be solved with sliding window technique as well, or we can evaluate sizes of groups of `0`\\'s and `1`\\'s and then choose two group of `1`\\'s, such that it has group of `0`\\'s with only one element between them. \\n\\n\\n```\\nclass Solution:\\n def longestSubarray(self, nums):\\n n = len(nums)\\n if sum(nums) == n: return n - 1\\n \\n dp = [[0] * 2 for _ in range(n)]\\n dp[0][0] = nums[0]\\n \\n for i in range(1, n):\\n if nums[i] == 1:\\n dp[i][0], dp[i][1] = dp[i-1][0] + 1, dp[i-1][1] + 1\\n else:\\n dp[i][0], dp[i][1] = 0, dp[i-1][0]\\n \\n return max([i for j in dp for i in j]) \\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1593273770, | |
| "creationDate": 1593273770 | |
| } | |
| }, | |
| { | |
| "id": 710229, | |
| "title": "[Python] Short DP with Binary Masks, O(n^2*2^n), explained", | |
| "taskUrl": "https://leetcode.com/problems/parallel-courses-ii", | |
| "post": { | |
| "id": 1310647, | |
| "content": "There are a lot of not-working greedy solutions for this problem, but I think the only one truly correct way to solve it is to use binary masks, see similarity with **Travelling Salesman Problem**. (see https://en.wikipedia.org/wiki/Travelling_salesman_problem and https://en.wikipedia.org/wiki/Held%E2%80%93Karp_algorithm)\\n\\nLet us denote by `dp[i][j]` tuple with: \\n1. minumum number of days we need to finish\\n2. number of non-zero bits for binary mask of the last semester\\n3. binary mask of the last semester\\n\\nall courses denoted by binary mask `i` and such that the last course we take is `j`. For example for `dp[13][3]`, `i=13` is represented as `1101`, and it means that we take courses number `0`, `2`, `3` and the last one we take is number `3`. (instead of starting with `1`, let us subtract `1` from all courses and start from `0`).\\n\\nLet us also introduce `bm_dep[i]`: this will be binary mask for all courses we need to take, before we can take course number `i`. For example `bm_dep[3] = 6 = 110` means, that we need to take courses `1` and `2` before we can take course number `3`.\\n\\nNow, let us iterate over all `i in range(1\u003c\u003cn)`. Let us evaluate `n_z_bit`, this will be an array with all places with non-zero bits. For example for `i=13=1101`, `n_z_bit = [0,2,3]`.\\n\\nWhat we need to do next, we:\\n1. First check that we really can take new course number `j`, using `bm_dep[j] \u0026 i == bm_dep[j]`.\\n2. Now, we want to update `dp[i][j]`, using `dp[i^(1\u003c\u003cj)][t]`, for example if we want to find answer for `(1,3,4,5)` courses with `3` being the last course, it means that we need to look into `(1,4,5)` courses, where we add course `3`.\\n3. We check how many courses we already take in last semester, using `bits \u003c k`, and also make sure, that we can add new course to last semester. Now we have two candidates: `(cand, bits + 1, mask + (1\u003c\u003cj))` and `dp[i][j]` and we need to choose the best one. In other case, we need to take new semester: so `cands` will be equalt to `cands + 1`, `bits` will be equal to `1` and binary mask for last semester is `1\u003c\u003cj`.\\n\\n**Complexity** is `O(n^2*2^n)`, because we iterate all bitmasks and then we iterate over all pairs of non-zero bit, and we heve `O(n^2)` of them. Memory is `O(2^n * n)`.\\nI think it can be simplified to `O(n*2^n)/O(2^n)` complexity, but I am not sure yet.\\n\\n```\\nclass Solution:\\n def minNumberOfSemesters(self, n, dependencies, k):\\n dp = [[(100, 0, 0)] * n for _ in range(1\u003c\u003cn)]\\n \\n bm_dep = [0]*(n)\\n for i,j in dependencies:\\n bm_dep[j-1]^=(1\u003c\u003c(i-1))\\n\\n for i in range(n):\\n if bm_dep[i] == 0: dp[1\u003c\u003ci][i] = (1, 1, 1\u003c\u003ci)\\n \\n for i in range(1\u003c\u003cn):\\n n_z_bits = [len(bin(i))-p-1 for p,c in enumerate(bin(i)) if c==\"1\"]\\n \\n for t, j in permutations(n_z_bits, 2):\\n if bm_dep[j] \u0026 i == bm_dep[j]:\\n cand, bits, mask = dp[i^(1\u003c\u003cj)][t]\\n if bm_dep[j] \u0026 mask == 0 and bits \u003c k:\\n dp[i][j] = min(dp[i][j], (cand, bits + 1, mask + (1\u003c\u003cj)))\\n else:\\n dp[i][j] = min(dp[i][j], (cand+1, 1, 1\u003c\u003cj))\\n \\n return min([i for i, j, k in dp[-1]])\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605599633, | |
| "creationDate": 1593364507 | |
| } | |
| }, | |
| { | |
| "id": 909373, | |
| "title": "[Python] DP solution, using game theory, explained", | |
| "taskUrl": "https://leetcode.com/problems/stone-game-iv", | |
| "post": { | |
| "id": 1656297, | |
| "content": "In this problems we have game with two persons, and we need to understand who is winning, if they play with optimal strategies. In this game at each moment of time we have several (say `k`) stones, and we say that it is **position** in our game. At each step, each player can go from one position to another. Let us use classical definitions:\\n\\n1. The empty game (the game where there are no moves to be made) is a losing position.\\n2. A position is a winning position if at least one of the positions that can be obtained from this position by a single move is a losing position.\\n3. A position is a losing position if every position that can be obtained from this position by a single move is a winning position.\\n\\nWhy people use definitions like this? Imagine that we are in winning position, then there exists at least one move to losing position (**property 2**), so you make it and you force your opponent to be in loosing position. You opponent have no choice to return to winning position, because every position reached from losing position is winning (**property 3**). So, by following this strategy we can say, that for loosing positions Alice will loose and she will win for all other positions.\\n\\nSo, what we need to check now for position **state**: all positions, we can reach from it and if at least one of them is `False`, our position is winning and we can immedietly return `True`. If all of them are `True`, our position is loosing, and we return `False`. Also we return `False`, if it is our terminal position.\\n\\n**Complexity**: For each of `n` positions we check at most `sqrt(n)` different moves, so overall time complexity is `O(n sqrt(n))`. Space complexity is `O(n)`, we keep array of length `n`.\\n\\n```\\nclass Solution:\\n def winnerSquareGame(self, n):\\n \\n @lru_cache(None)\\n def dfs(state):\\n if state == 0: return False\\n for i in range(1, int(math.sqrt(state))+1):\\n if not dfs(state - i*i): return True\\n return False\\n \\n return dfs(n)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1603611132, | |
| "creationDate": 1603611132 | |
| } | |
| }, | |
| { | |
| "id": 917693, | |
| "title": "[Python] Short O(mn) dp solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/number-of-ways-to-form-a-target-string-given-a-dictionary", | |
| "post": { | |
| "id": 1670564, | |
| "content": "Let us denote by `dp[i][j]` number of solutions, such that the last symbol we take was from `i`-th column and also we create exactly `j` symbold of our `target`. Let also `sp[i][j]` be cumulative sum of `dp` on first index, that is `sp[i][j] = sp[i-1][j] + ... + sp[0][j]`.\\n\\nNow, the question is how we an evaluate `dp[i][j]`. By definition, the last symbol we take is from `i`-th column. So, first, we need to understand how many options we have to take this symbol: for quick acces we use `Q[i][j]` array, how many times we have symbol `j` in `i`-th column. We need to multiply this number by `sp[i-1][j-1] = dp[0][j-1] + ... + dp[i-1][j-1]`, because previous taken symbol can be from any of previous columns. For example, it can happen, that `Q[i][ord(target[j]) - ord(\"a\")] = 0`, it means that `dp[i][j] = 0` immedietly. Also we need to consider one more corner case: if `j = 0`, it means, we just start to build our `target` string, so in this case we do not need to multiply by `sp[i-1][j-1]`. Finally, we update our `sp` and do not forget to use modulo `N`.\\n\\n**Complexity**: space complexity is `O(26n + nk)` to keep our `Q`, `dp` and `sp` tables. Time complexity is `O(nm + nk)` to form `Q` table and to update `dp` and `sp` tables.\\n\\n\\n```\\nclass Solution:\\n def numWays(self, words, target):\\n m, n, k, N = len(words), len(words[0]), len(target), 10**9 + 7\\n Q = [[0] * 26 for _ in range(n)]\\n dp = [[0] * k for _ in range(n)]\\n sp = [[0] * k for _ in range(n)]\\n for i in range(n):\\n for j in range(m):\\n Q[i][ord(words[j][i]) - ord(\"a\")] += 1\\n\\n dp[0][0] = sp[0][0] = Q[0][ord(target[0]) - ord(\"a\")]\\n \\n for i in range(1, n):\\n for j in range(k):\\n if j \u003e 0: dp[i][j] = Q[i][ord(target[j]) - ord(\"a\")] * sp[i-1][j-1]\\n else: dp[i][j] = Q[i][ord(target[j]) - ord(\"a\")]\\n sp[i][j] = (sp[i-1][j] + dp[i][j]) % N\\n\\n return sp[-1][-1] % N\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604161021, | |
| "creationDate": 1604160091 | |
| } | |
| }, | |
| { | |
| "id": 918393, | |
| "title": "[Python] O((m+n)^2) solution, explained", | |
| "taskUrl": "https://leetcode.com/problems/kth-smallest-instructions", | |
| "post": { | |
| "id": 1671859, | |
| "content": "Actualy, I was suprised, why this problem is marked as Hard: all you need to do is to on each moment of time see how many options we have if we go to the right and if we can afford this step or no. If we are out of options, that is `k = 1`, then we build the rest of the sequence either with `H` or with `V`.\\n\\n**Complexity**: time complexity is `O((m+n)^2)` for time: we use `comb()` function `O(m+n)` times, where complexity of each evaluation is `O(m+n)` as well. Space complexity is `O(1)`.\\n\\n```\\nclass Solution:\\n def kthSmallestPath(self, destination, k):\\n m, n, ans = destination[0], destination[1], \"\"\\n for i in range(m+n):\\n if k == 1: #no options left\\n ans += \"H\"*n + \"V\"*m\\n break\\n\\n if k \u003c= comb(m+n-1, m):\\n n -= 1\\n ans += \"H\"\\n else:\\n ans += \"V\"\\n k -= comb(m+n-1, m)\\n m -= 1\\n \\n return ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1604215406, | |
| "creationDate": 1604203284 | |
| } | |
| }, | |
| { | |
| "id": 936467, | |
| "title": "[Python] Short and clean dp with diagram, expained", | |
| "taskUrl": "https://leetcode.com/problems/maximize-grid-happiness", | |
| "post": { | |
| "id": 1703605, | |
| "content": "Let us us dynamic programming with the following states: \\n\\n1. `index`: number of cell in our grid, going from `0` to `mn-1`: from top left corner, line by line.\\n2. `row` is the next row filled with elements `0`, `1` (for introvert) or `2` (for extravert): see on my diagramm.\\n3. `I` is number of interverts we have left.\\n4. `E` is number of extraverts we have left.\\n\\n\\n\\n\\nNow, let us fill out table element by element, using `dp` function:\\n\\n1. First of all, if we reached `index == -1`, we return 0, it is our border case.\\n2. Compute `R` and `C` coordinates of our cell.\\n3. Define `neibs`: it is parameters for our recursion: fist element is what we put into this element: `0`, `1` or `2`, second and third elements are new coordinates and last one is gain.\\n4. Now, we have `3` possible cases we need to cover: new cell is filled with `0`, `1` or `2` and for each of these cases we need to calculate `ans`:\\na) this is `dp` for our previous row, shifted by one\\nb) gain we need to add when we add new intravert / extravert / empty\\nc) check right neighbor (if we have any) and add `fine`: for example if we have 2 introverts, both of them are not happy, so we need to add `-30-30`, if we have one introvert and one extravert, it is `20-30` and if it is two extraverts it is `20+20`.\\nd) do the same for down neigbor if we have any (**see illustration for help**)\\n\\nFinally, we just return `dp(m*n-1, tuple([0]*n), I, E)`\\n\\n**Complexity**: time complexity is `O(m*n*I*E*3^n)`, because: `index` goes from `0` to `mn-1`, `row` has `n` elements, each of them equal to `0`, `1` or `2`.\\n\\n```\\nclass Solution:\\n def getMaxGridHappiness(self, m, n, I, E):\\n InG, ExG, InL, ExL = 120, 40, -30, 20\\n fine = [[0, 0, 0], [0, 2*InL, InL+ExL], [0, InL+ExL, 2*ExL]]\\n \\n @lru_cache(None)\\n def dp(index, row, I, E):\\n if index == -1: return 0\\n\\n R, C, ans = index//n, index%n, []\\n neibs = [(1, I-1, E, InG), (2, I, E-1, ExG), (0, I, E, 0)] \\n \\n for val, dx, dy, gain in neibs:\\n tmp = 0\\n if dx \u003e= 0 and dy \u003e= 0:\\n tmp = dp(index-1, (val,) + row[:-1], dx, dy) + gain\\n if C \u003c n-1: tmp += fine[val][row[0]] #right neighbor\\n if R \u003c m-1: tmp += fine[val][row[-1]] #down neighbor\\n ans.append(tmp)\\n\\n return max(ans)\\n \\n if m \u003c n: m, n = n, m\\n \\n return dp(m*n-1, tuple([0]*n), I, E)\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1605440336, | |
| "creationDate": 1605440113 | |
| } | |
| }, | |
| { | |
| "id": 952053, | |
| "title": "[Python] 3 solutions: LIS; dp; O(n log n), explained", | |
| "taskUrl": "https://leetcode.com/problems/minimum-number-of-removals-to-make-mountain-array", | |
| "post": { | |
| "id": 1730649, | |
| "content": "## Solution 1: using LIS\\n\\nThe first idea when I saw this problem is to use already existing problem **300**: Longest Increasing Subsequence (LIS), you can see my solutions with explanations here https://leetcode.com/problems/longest-increasing-subsequence/discuss/667975/Python-3-Lines-dp-with-binary-search-explained\\n\\nSo, the idea is the following: split our list into two parts, and find LIS for left part and also Longest Decreasing Subsequence for the second part. However we need to handle couple of things before: first of all, we want our LIS end with index `i`, so for this we can remove all elements which are less than `nums[i]` from our part. The same we do for the right part and we also reverse it. Finally, find LIS for these parts and if lengths of both parts `2` or more, it means we can construct Mountain Array, so we update our `max_found`.\\n\\n**Complexity**: time complexity it is `O(n log n)` for one LIS, so it will be `O(n^2 log n)` for all partitions, space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def minimumMountainRemovals(self, nums):\\n def lengthOfLIS(nums):\\n dp = [10**10] * (len(nums) + 1)\\n for elem in nums: \\n dp[bisect.bisect_left(dp, elem)] = elem \\n return dp.index(10**10)\\n\\n max_found = 0\\n n = len(nums)\\n for i in range(1, n - 1):\\n left = [num for num in nums[:i] if num \u003c nums[i]] + [nums[i]]\\n right = [nums[i]] + [num for num in nums[i+1:] if num \u003c nums[i]]\\n right = right[::-1]\\n a, b = lengthOfLIS(left), lengthOfLIS(right)\\n if a \u003e=2 and b \u003e= 2: \\n max_found = max(max_found, a + b - 1)\\n\\n return n - max_found\\n```\\n\\n## Solution 2, using pure dp\\n\\nActually, it can be done in easier way: let `dp1[i]` be maximum length of LIS, ending with element index `i` and `dp2[i]` be maximum length of Mountain array. Then, update of `dp1` is straightforward: iterate over all previous elements and update it. For `dp2[i]` we again need to iterate over all previous elements and if `nums[j] \u003c nums[i]`, we can update `dp2[i]`, using `dp2[j] + 1` or `dp1[j] + 1`.\\n\\n**Complexity**: time complexity is `O(n^2)`, space complexity is `O(n)`.\\n\\n```\\nclass Solution:\\n def minimumMountainRemovals(self, nums):\\n n = len(nums)\\n dp1, dp2 = [1]*n, [1]*n\\n for i in range(1, n):\\n for j in range(i):\\n if nums[j] \u003c nums[i]: dp1[i] = max(dp1[i], 1+dp1[j])\\n if nums[j] \u003e nums[i]: \\n if dp1[j] \u003e 1: dp2[i] = max(dp2[i], 1 + dp1[j])\\n if dp2[j] \u003e 1: dp2[i] = max(dp2[i], 1 + dp2[j])\\n \\n return n - max(dp2)\\n```\\n\\n## Solution 3, O(n log n)\\n\\nActually, we can update LIS solution we already have, but now we need to return also `lens` array, where `lens[i]` is the lenght of LIS, ending with index `i`.\\n\\n```\\nclass Solution:\\n def minimumMountainRemovals(self, nums):\\n def LIS(nums):\\n dp = [10**10] * (len(nums) + 1)\\n lens = [0]*len(nums)\\n for i, elem in enumerate(nums): \\n lens[i] = bisect_left(dp, elem) + 1\\n dp[lens[i] - 1] = elem \\n return lens\\n \\n l1, l2 = LIS(nums), LIS(nums[::-1])[::-1]\\n ans, n = 0, len(nums)\\n for i in range(n):\\n if l1[i] \u003e= 2 and l2[i] \u003e= 2:\\n ans = max(ans, l1[i] + l2[i] - 1)\\n \\n return n - ans\\n```\\n\\nIf you have any questions, feel free to ask. If you like solution and explanations, please **Upvote!**", | |
| "updationDate": 1606591416, | |
| "creationDate": 1606579658 | |
| } | |
| } | |
| ] |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| 15 | https://leetcode.com/problems/3sum/discuss/725581/python-2-pointers-on2-solution-explained | |
|---|---|---|
| 24 | https://leetcode.com/problems/largest-rectangle-in-histogram/discuss/995249/Python-increasing-stack-explained | |
| 35 | https://leetcode.com/problems/search-insert-position/discuss/679918/Python-2-Solutions%3A-Oneliner-and-Classical-BS-explained | |
| 39 | https://leetcode.com/problems/combination-sum/discuss/875097/Python-bactracking-solution-explained | |
| 41 | https://leetcode.com/problems/first-missing-positive/discuss/871665/Python-O(n)-solution-without-additional-memory-explained | |
| 47 | https://leetcode.com/problems/permutations-ii/discuss/932924/Python-simple-dfsbacktracking-explained | |
| 50 | https://leetcode.com/problems/powx-n/discuss/738830/python-recursive-olog-n-solution-explained | |
| 56 | https://leetcode.com/problems/merge-intervals/discuss/939998/python-sort-and-traverse-explained | |
| 57 | https://leetcode.com/problems/insert-interval/discuss/844494/Python-O(n)-solution-explained | |
| 58 | https://leetcode.com/problems/length-of-last-word/discuss/847535/Python-solution-without-split-explained | |
| 59 | https://leetcode.com/problems/spiral-matrix-ii/discuss/963128/Python-rotate-when-need-explained | |
| 60 | https://leetcode.com/problems/permutation-sequence/discuss/696390/Python-Math-solution-O(n2)-expained | |
| 61 | https://leetcode.com/problems/rotate-list/discuss/883252/Python-O(n)-solution-explained | |
| 62 | https://leetcode.com/problems/unique-paths/discuss/711190/Python-2-solutions%3A-dp-and-oneliner-math-explained | |
| 66 | https://leetcode.com/problems/plus-one/discuss/722211/python-find-maximum-9-in-the-end-explained | |
| 67 | https://leetcode.com/problems/add-binary/discuss/743698/python-8-lines-neat-solution-explained | |
| 70 | https://leetcode.com/problems/climbing-stairs/discuss/764847/python-2-solution-dp-fibonacci-math-explained | |
| 72 | https://leetcode.com/problems/edit-distance/discuss/662395/python-classical-dp-omn-explained | |
| 74 | https://leetcode.com/problems/search-a-2d-matrix/discuss/896821/Python-Simple-binary-search-explained | |
| 75 | https://leetcode.com/problems/sort-colors/discuss/681526/Python-O(n)-3-pointers-in-place-approach-explained | |
| 78 | https://leetcode.com/problems/subsets/discuss/729842/python-3-solutions-backtracking-2-oneliners-explained | |
| 79 | https://leetcode.com/problems/word-search/discuss/747144/python-dfs-backtracking-solution-explained | |
| 80 | https://leetcode.com/problems/remove-duplicates-from-sorted-array-ii/discuss/967951/Python-Two-pointers-approach-explained | |
| 81 | https://leetcode.com/problems/search-in-rotated-sorted-array-ii/discuss/942575/Python-Binary-search-%2B-dfs-explained-with-diagram | |
| 91 | https://leetcode.com/problems/decode-ways/discuss/987013/Python-O(n)-timeO(1)-space-dp-explained | |
| 96 | https://leetcode.com/problems/unique-binary-search-trees/discuss/703049/Python-Math-oneliner-O(n)-using-Catalan-number-explained | |
| 98 | https://leetcode.com/problems/validate-binary-search-tree/discuss/974185/Python-simple-dfs-explained | |
| 99 | https://leetcode.com/problems/recover-binary-search-tree/discuss/917430/Python-O(n)O(1)-Morris-traversal-explained | |
| 100 | https://leetcode.com/problems/same-tree/discuss/733783/python-3-lines-recursion-explained | |
| 103 | https://leetcode.com/problems/binary-tree-zigzag-level-order-traversal/discuss/749036/python-clean-bfs-solution-explained | |
| 104 | https://leetcode.com/problems/maximum-depth-of-binary-tree/discuss/955641/Python-2-lines-dfs-explained | |
| 106 | https://leetcode.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal/discuss/758662/Python-O(n)-recursion-explained-with-diagram | |
| 107 | https://leetcode.com/problems/binary-tree-level-order-traversal-ii/discuss/715874/python-classical-bfs-level-traversal-with-queue-explained | |
| 110 | https://leetcode.com/problems/balanced-binary-tree/discuss/981648/Python-simple-dfs-explained | |
| 111 | https://leetcode.com/problems/minimum-depth-of-binary-tree/discuss/905643/Python-Simple-dfs-explained | |
| 116 | https://leetcode.com/problems/populating-next-right-pointers-in-each-node/discuss/934066/Python-O(n)-time-O(log-n)-space-recursion-explained | |
| 117 | https://leetcode.com/problems/populating-next-right-pointers-in-each-node-ii/discuss/961868/Python-O(n)-solution-explained | |
| 119 | https://leetcode.com/problems/pascals-triangle-ii/discuss/787212/Python-Two-O(k)-memory-Oneliners-explained | |
| 121 | https://leetcode.com/problems/best-time-to-buy-and-sell-stock/discuss/851941/Python-O(n)-dynamic-programming-solution-explained | |
| 123 | https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iii/discuss/794633/python-on-solution-with-optimization-explained | |
| 125 | https://leetcode.com/problems/valid-palindrome/discuss/770465/python-two-pointers-on-time-o1-space-explained | |
| 129 | https://leetcode.com/problems/sum-root-to-leaf-numbers/discuss/705994/Python-dfs-O(n)-with-explanations | |
| 130 | https://leetcode.com/problems/surrounded-regions/discuss/691646/python-omn-3-colors-dfs-explained | |
| 131 | https://leetcode.com/problems/palindrome-partitioning/discuss/971898/Python-dpdfs-solution-explained | |
| 133 | https://leetcode.com/problems/clone-graph/discuss/902767/Python-dfs-recursive-solution-explained | |
| 134 | https://leetcode.com/problems/gas-station/discuss/860396/Python-O(n)-greedy-solution-explained | |
| 137 | https://leetcode.com/problems/single-number-ii/discuss/699889/python-bit-manipulation-o32n-but-easy-exaplained | |
| 139 | https://leetcode.com/problems/word-break/discuss/870102/Pyhon-dfs-using-lru_cache-explained | |
| 140 | https://leetcode.com/problems/word-break-ii/discuss/763221/python-dp-solution-explained | |
| 142 | https://leetcode.com/problems/linked-list-cycle-ii/discuss/912276/Python-2-pointers-approach-explained | |
| 143 | https://leetcode.com/problems/reorder-list/discuss/801883/python-3-steps-to-success-explained | |
| 147 | https://leetcode.com/problems/insertion-sort-list/discuss/920371/Python-Insertion-Sort-explained | |
| 148 | https://leetcode.com/problems/sort-list/discuss/892759/Python-O(n-log-n-log-n)-merge-sort-explained | |
| 151 | https://leetcode.com/problems/reverse-words-in-a-string/discuss/737124/python-2-solutions-oneliner-inplace-for-list-of-chars-explained | |
| 152 | https://leetcode.com/problems/maximum-product-subarray/discuss/841176/Python-dp-solution-explained | |
| 154 | https://leetcode.com/problems/find-minimum-in-rotated-sorted-array-ii/discuss/754100/Python-dfs-%2B-binary-search-explained | |
| 165 | https://leetcode.com/problems/compare-version-numbers/discuss/837727/Python-easy-split-solution-explained | |
| 171 | https://leetcode.com/problems/excel-sheet-column-number/discuss/783383/python-oneliner-base-26-numeral-system-explained | |
| 173 | https://leetcode.com/problems/binary-search-tree-iterator/discuss/965565/Python-Stack-solution-%2B-follow-up-explained | |
| 174 | https://leetcode.com/problems/dungeon-game/discuss/698271/Python-Short-DP-9-lines-O(mn)-top-down-explained | |
| 179 | https://leetcode.com/problems/largest-number/discuss/863489/Python-2-lines-solution-using-sort-explained | |
| 187 | https://leetcode.com/problems/repeated-dna-sequences/discuss/898299/Python-2-lines-solution-explained | |
| 188 | https://leetcode.com/problems/best-time-to-buy-and-sell-stock-iv/discuss/900151/Python-O(nk)-dynamic-programming-explained | |
| 189 | https://leetcode.com/problems/rotate-array/discuss/895412/Python-O(n)-inplace-solution-explained | |
| 190 | https://leetcode.com/problems/reverse-bits/discuss/732138/python-o32-simple-solution-explained | |
| 198 | https://leetcode.com/problems/house-robber/discuss/846004/Python-4-lines-easy-dp-solution-explained | |
| 203 | https://leetcode.com/problems/remove-linked-list-elements/discuss/745470/python-one-pass-on-time-o1-memory-explained | |
| 207 | https://leetcode.com/problems/course-schedule/discuss/658297/Python-Topological-sort-with-recurcive-dfs-explained | |
| 210 | https://leetcode.com/problems/course-schedule-ii/discuss/741784/python-topological-sort-with-recurcive-dfs-explained | |
| 211 | https://leetcode.com/problems/add-and-search-word-data-structure-design/discuss/774530/Python-Trie-solution-with-dfs-explained | |
| 212 | https://leetcode.com/problems/word-search-ii/discuss/712733/Python-Trie-solution-with-dfs-explained | |
| 213 | https://leetcode.com/problems/house-robber-ii/discuss/893957/Python-Just-use-House-Robber-twice | |
| 216 | https://leetcode.com/problems/combination-sum-iii/discuss/842764/Python-backtrack-solution-explained | |
| 218 | https://leetcode.com/problems/the-skyline-problem/discuss/954585/Python-O(n-log-n)-solution-using-heap-explained | |
| 220 | https://leetcode.com/problems/contains-duplicate-iii/discuss/824603/Python-SortedList-O(n-log-k)-solution-explained. | |
| 222 | https://leetcode.com/problems/count-complete-tree-nodes/discuss/701466/Python-O(log-n-*-log-n)-solution-with-Binary-Search-explained | |
| 226 | https://leetcode.com/problems/invert-binary-tree/discuss/664122/python-3-lines-recursion-expained | |
| 227 | https://leetcode.com/problems/basic-calculator-ii/discuss/658480/Python-Basic-Calculator-I-II-III-easy-solution-detailed-explanation | |
| 228 | https://leetcode.com/problems/summary-ranges/discuss/913432/Python-Two-pointers-O(n)-solution-explained | |
| 229 | https://leetcode.com/problems/majority-element-ii/discuss/858872/Python-Voting-O(n)-solution-explained | |
| 231 | https://leetcode.com/problems/power-of-two/discuss/676737/python-oneliner-o1-bit-manipulation-trick-explained | |
| 237 | https://leetcode.com/problems/delete-node-in-a-linked-list/discuss/665803/Python-2-lines-easy-modify-values-in-your-list | |
| 239 | https://leetcode.com/problems/sliding-window-maximum/discuss/951683/Python-Decreasing-deque-short-explained | |
| 258 | https://leetcode.com/problems/add-digits/discuss/756533/Python-Math-O(1)-oneliner-explained | |
| 260 | https://leetcode.com/problems/single-number-iii/discuss/750622/python-4-lines-on-time-o1-space-explained | |
| 264 | https://leetcode.com/problems/ugly-number-ii/discuss/718879/python-on-universal-dp-solution-explained | |
| 274 | https://leetcode.com/problems/h-index/discuss/656820/python-on-timespace-with-explanation | |
| 274 | https://leetcode.com/problems/h-index/discuss/656820/Python-Short-O(n)-timeandspace-explained | |
| 275 | https://leetcode.com/problems/h-index-ii/discuss/693380/python-binary-search-olog-n-time-o1-space-explained | |
| 279 | https://leetcode.com/problems/perfect-squares/discuss/707526/python-fastest-osqrtn-solution-with-math-explanied | |
| 287 | https://leetcode.com/problems/find-the-duplicate-number/discuss/704693/Python-2-solutions%3A-Linked-List-Cycle-O(n)-and-BS-O(n-log-n)-explained | |
| 290 | https://leetcode.com/problems/word-pattern/discuss/833961/Python-2-hash-tables-explained | |
| 299 | https://leetcode.com/problems/bulls-and-cows/discuss/839444/Python-Simple-solution-with-counters-explained | |
| 300 | https://leetcode.com/problems/longest-increasing-subsequence/discuss/667975/Python-3-Lines-dp-with-binary-search-explained | |
| 309 | https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-cooldown/discuss/761720/Python-dp-O(n)-solution-using-differences-explained | |
| 310 | https://leetcode.com/problems/minimum-height-trees/discuss/923071/Python-Find-diameter-using-2-dfs-explained | |
| 312 | https://leetcode.com/problems/burst-balloons/discuss/970727/Python-5-lines-dp-explained | |
| 316 | https://leetcode.com/problems/remove-duplicate-letters/discuss/889477/Python-O(n)-greedy-with-stack-explained | |
| 332 | https://leetcode.com/problems/reconstruct-itinerary/discuss/709590/python-short-euler-path-finding-oe-log-e-explained | |
| 334 | https://leetcode.com/problems/increasing-triplet-subsequence/discuss/976393/Python-O(n)-solution-explained | |
| 337 | https://leetcode.com/problems/house-robber-iii/discuss/946176/Python-very-short-dfs-explained | |
| 338 | https://leetcode.com/problems/counting-bits/discuss/656539/Python-Clean-dp-solution-O(n)-beats-99-with-explanations. | |
| 342 | https://leetcode.com/problems/power-of-four/discuss/772269/Python-O(1)-oneliner-solution-explained | |
| 344 | https://leetcode.com/problems/reverse-string/discuss/669571/python-oneliner-two-pointers-explained | |
| 347 | https://leetcode.com/problems/top-k-frequent-elements/discuss/740374/python-5-lines-on-buckets-solution-explained | |
| 368 | https://leetcode.com/problems/largest-divisible-subset/discuss/684738/python-short-dp-with-on2-explained-update | |
| 380 | https://leetcode.com/problems/insert-delete-getrandom-o1/discuss/683267/Python-O(1)-using-two-hash-tables-beats-97-explained | |
| 382 | https://leetcode.com/problems/linked-list-random-node/discuss/956872/Python-Reservoir-sampling-(follow-up)-explained | |
| 392 | https://leetcode.com/problems/is-subsequence/discuss/678389/python-3-solutions-dp-2-pointers-follow-up-bs-explained | |
| 394 | https://leetcode.com/problems/decode-string/discuss/941309/python-stack-solution-explained | |
| 395 | https://leetcode.com/problems/longest-substring-with-at-least-k-repeating-characters/discuss/949552/Python-sliding-window-solution-explained | |
| 399 | https://leetcode.com/problems/evaluate-division/discuss/867030/Python-dfs-O(V%2BE)-explained | |
| 404 | https://leetcode.com/problems/sum-of-left-leaves/discuss/808977/Python-Simple-dfs-explained | |
| 406 | https://leetcode.com/problems/queue-reconstruction-by-height/discuss/673129/python-on2-easy-to-come-up-detailed-explanations | |
| 409 | https://leetcode.com/problems/longest-palindrome/discuss/791032/Python-2-lines-with-counter-%2B-Oneliner-explained | |
| 412 | https://leetcode.com/problems/fizz-buzz/discuss/812428/Python-easy-solution-explained | |
| 416 | https://leetcode.com/problems/partition-equal-subset-sum/discuss/950617/Python-Fastest-dp-with-bit-manipulation-explained | |
| 421 | https://leetcode.com/problems/maximum-xor-of-two-numbers-in-an-array/discuss/849128/Python-O(32n)-solution-explained | |
| 430 | https://leetcode.com/problems/flatten-a-multilevel-doubly-linked-list/discuss/728266/python-dfs-with-stack-2-solutions-exaplained | |
| 435 | https://leetcode.com/problems/non-overlapping-intervals/discuss/793070/Python-O(n-log-n)-sort-ends-with-proof-explained | |
| 436 | https://leetcode.com/problems/find-right-interval/discuss/814463/Python-Binary-search-explained | |
| 437 | https://leetcode.com/problems/path-sum-iii/discuss/779227/python-dfs-hash-table-using-cumulative-sums-explained | |
| 441 | https://leetcode.com/problems/arranging-coins/discuss/714130/python-math-oneliner-explained | |
| 442 | https://leetcode.com/problems/find-all-duplicates-in-an-array/discuss/775738/python-2-solutions-with-on-timeo1-space-explained | |
| 445 | https://leetcode.com/problems/add-two-numbers-ii/discuss/926807/Python-Two-stacks-solution-explained | |
| 449 | https://leetcode.com/problems/serialize-and-deserialize-bst/discuss/886354/Python-O(n)-solution-using-preorder-traversal-explained | |
| 450 | https://leetcode.com/problems/delete-node-in-a-bst/discuss/821420/Python-O(h)-solution-explained | |
| 452 | https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons/discuss/887690/Python-O(n-log-n)-solution-explained | |
| 454 | https://leetcode.com/problems/4sum-ii/discuss/975319/Python-O(n2)-two-2-sum-explained | |
| 456 | https://leetcode.com/problems/132-pattern/discuss/906876/Python-O(n)-solution-with-decreasing-stack-explained | |
| 458 | https://leetcode.com/problems/poor-pigs/discuss/935112/Python-Math-solution-detailed-expanations | |
| 459 | https://leetcode.com/problems/repeated-substring-pattern/discuss/826121/Python-2-solutions1-oneliner-explained | |
| 461 | https://leetcode.com/problems/hamming-distance/discuss/720541/python-bit-manipulation-tt-1-trick-explained | |
| 463 | https://leetcode.com/problems/island-perimeter/discuss/723842/Python-O(mn)-simple-loop-solution-explained | |
| 468 | https://leetcode.com/problems/validate-ip-address/discuss/689872/python-check-all-options-carefully-explained | |
| 470 | https://leetcode.com/problems/implement-rand10-using-rand7/discuss/816210/Python-rejection-sampling-2-lines-explained | |
| 495 | https://leetcode.com/problems/teemo-attacking/discuss/864975/Python-Merge-intervals-O(n)-solution-explained | |
| 497 | https://leetcode.com/problems/random-point-in-non-overlapping-rectangles/discuss/805232/Python-Short-solution-with-binary-search-explained | |
| 498 | https://leetcode.com/problems/diagonal-traverse/discuss/985751/Python-Short-solution-using-defaultdict-explained | |
| 518 | https://leetcode.com/problems/coin-change-2/discuss/675096/python-oamount-n-simple-dp-explained-updated | |
| 518 | https://leetcode.com/problems/coin-change-2/discuss/675424/python-4-lines-magical-solution-with-generating-functions | |
| 520 | https://leetcode.com/problems/detect-capital/discuss/766364/python-simple-on-solution-explained | |
| 525 | https://leetcode.com/problems/contiguous-array/discuss/653061/python-detailed-explanation-on-timespace-cumulative-sums | |
| 528 | https://leetcode.com/problems/random-pick-with-weight/discuss/671439/python-smart-o1-solution-with-detailed-explanation-update | |
| 532 | https://leetcode.com/problems/k-diff-pairs-in-an-array/discuss/876197/Python-O(n)-solution-explained | |
| 556 | https://leetcode.com/problems/next-greater-element-iii/discuss/983076/Python-O(m)-solution-explained | |
| 563 | https://leetcode.com/problems/binary-tree-tilt/discuss/927899/Python-Short-dfs-solution-explained | |
| 593 | https://leetcode.com/problems/valid-square/discuss/931664/Python-Math-check-diagonals-explained | |
| 605 | https://leetcode.com/problems/can-place-flowers/discuss/960419/Python-2-lines-using-groupby-explained | |
| 621 | https://leetcode.com/problems/task-scheduler/discuss/760266/Python-4-lines-linear-solution-detailed-explanation | |
| 662 | https://leetcode.com/problems/maximum-width-of-binary-tree/discuss/726732/python-10-lines-bfs-explained-with-figure | |
| 673 | https://leetcode.com/problems/number-of-longest-increasing-subsequence/discuss/916196/Python-Short-O(n-log-n)-solution-beats-100-explained | |
| 700 | https://leetcode.com/problems/search-in-a-binary-search-tree/discuss/688273/python-intuitive-recursive-solution-oh-explained | |
| 701 | https://leetcode.com/problems/insert-into-a-binary-search-tree/discuss/881677/Python-O(h)-recursive-solution-explained | |
| 704 | https://leetcode.com/problems/binary-search/discuss/884759/Python-very-simple-solution-explained | |
| 705 | https://leetcode.com/problems/design-hashset/discuss/768659/python-easy-multiplicative-hash-explained | |
| 713 | https://leetcode.com/problems/subarray-product-less-than-k/discuss/868623/Python-2-pointers-O(n)-solution-explained | |
| 735 | https://leetcode.com/problems/asteroid-collision/discuss/904118/Python-Stack-O(n)-solution-explained | |
| 754 | https://leetcode.com/problems/reach-a-number/discuss/990399/Python-Math-O(1)-solution-explained | |
| 763 | https://leetcode.com/problems/partition-labels/discuss/828031/Python-Greedy-O(n)-solution-explained | |
| 787 | https://leetcode.com/problems/cheapest-flights-within-k-stops/discuss/686906/python-multipass-bfs-ov2-dijkstra-with-sortedlist-explained | |
| 797 | https://leetcode.com/problems/all-paths-from-source-to-target/discuss/752481/python-simple-dfs-backtracking-explained | |
| 799 | https://leetcode.com/problems/champagne-tower/discuss/910867/Python-O(R2)-simulation-explained | |
| 804 | https://leetcode.com/problems/unique-morse-code-words/discuss/944921/Python-Just-use-set-explained | |
| 824 | https://leetcode.com/problems/goat-latin/discuss/800051/python-just-do-what-is-asked-explained | |
| 832 | https://leetcode.com/problems/flipping-an-image/discuss/930392/Python-Oneliner-explained | |
| 835 | https://leetcode.com/problems/image-overlap/discuss/832150/Python-2-lines-using-convolutions-explained | |
| 845 | https://leetcode.com/problems/longest-mountain-in-array/discuss/937652/python-one-pass-o1-space-explained | |
| 849 | https://leetcode.com/problems/maximize-distance-to-closest-person/discuss/914844/Python-O(n)-solution-using-groupby-explained | |
| 858 | https://leetcode.com/problems/mirror-reflection/discuss/938792/python-oneliner-solution-with-diagram-explained | |
| 859 | https://leetcode.com/problems/buddy-strings/discuss/891021/Python-O(n)-solution-explained | |
| 865 | https://leetcode.com/problems/smallest-subtree-with-all-the-deepest-nodes/discuss/969234/Pyton-O(n)-timeO(h)-space-explained | |
| 880 | https://leetcode.com/problems/decoded-string-at-index/discuss/979066/Python-O(n)-solution-explained | |
| 886 | https://leetcode.com/problems/possible-bipartition/discuss/654840/python-simple-dfs-traversal-oev-detailed-explanations | |
| 897 | https://leetcode.com/problems/increasing-order-search-tree/discuss/958059/Python-Inorder-dfs-explained | |
| 902 | https://leetcode.com/problems/numbers-at-most-n-given-digit-set/discuss/943592/Python-Math-solution-explained | |
| 905 | https://leetcode.com/problems/sort-array-by-parity/discuss/803633/Python-O(n)-In-place-partition-explained | |
| 910 | https://leetcode.com/problems/smallest-range-ii/discuss/980294/Python-O(n-log-n)-solution-explained | |
| 933 | https://leetcode.com/problems/number-of-recent-calls/discuss/873333/Python-easy-solution-using-queue-explained | |
| 938 | https://leetcode.com/problems/range-sum-of-bst/discuss/936480/python-simple-dfs-explained | |
| 941 | https://leetcode.com/problems/valid-mountain-array/discuss/966752/Python-One-pass-explained | |
| 948 | https://leetcode.com/problems/bag-of-tokens/discuss/907925/Python-2-Pointers-greedy-approach-explained | |
| 949 | https://leetcode.com/problems/largest-time-for-given-digits/discuss/822874/Python-Check-all-permutations-explained | |
| 952 | https://leetcode.com/problems/largest-component-size-by-common-factor/discuss/819919/Python-Union-find-solution-explained | |
| 957 | https://leetcode.com/problems/prison-cells-after-n-days/discuss/717491/python-loop-detection-explained | |
| 967 | https://leetcode.com/problems/numbers-with-same-consecutive-differences/discuss/798436/python-dfsdp-solution-explained | |
| 969 | https://leetcode.com/problems/pancake-sorting/discuss/817862/Python-O(n)-flipsO(n2)-time-explained | |
| 973 | https://leetcode.com/problems/k-closest-points-to-origin/discuss/659966/Python-Easy-heaps-O(n-log-k)-solution-explained | |
| 973 | https://leetcode.com/problems/k-closest-points-to-origin/discuss/660016/Python-oneliner-using-sort | |
| 977 | https://leetcode.com/problems/squares-of-a-sorted-array/discuss/972954/Python-oneliner-O(n)-explained | |
| 980 | https://leetcode.com/problems/unique-paths-iii/discuss/855647/Python-simple-dfsbacktracking-explained | |
| 983 | https://leetcode.com/problems/minimum-cost-for-tickets/discuss/810791/Python-Universal-true-O(days)-solution-explained | |
| 987 | https://leetcode.com/problems/vertical-order-traversal-of-a-binary-tree/discuss/777584/python-simple-dfs-explained | |
| 994 | https://leetcode.com/problems/rotting-oranges/discuss/781642/python-clean-bfs-solution-explained | |
| 1007 | https://leetcode.com/problems/minimum-domino-rotations-for-equal-row/discuss/901350/Python-short-O(n)-solution-explained | |
| 1009 | https://leetcode.com/problems/complement-of-base-10-integer/discuss/880072/Python-Oneliner-explained | |
| 1010 | https://leetcode.com/problems/pairs-of-songs-with-total-durations-divisible-by-60/discuss/964319/Python-Modular-arithmetic-explained | |
| 1015 | https://leetcode.com/problems/smallest-integer-divisible-by-k/discuss/948435/Python-Math-Pigeon-holes-explained | |
| 1022 | https://leetcode.com/problems/sum-of-root-to-leaf-binary-numbers/discuss/835958/Python-2-Easy-recursion-solutions-explained | |
| 1026 | https://leetcode.com/problems/maximum-difference-between-node-and-ancestor/discuss/929284/Python-O(n)%3A-look-at-child-explained | |
| 1029 | https://leetcode.com/problems/two-city-scheduling/discuss/667781/Python-4-Lines-O(n-log-n)-with-sort-explained | |
| 1032 | https://leetcode.com/problems/stream-of-characters/discuss/807541/Python-Trie-with-reversed-words-explained | |
| 1041 | https://leetcode.com/problems/robot-bounded-in-circle/discuss/850437/Python-O(n)-solution-explained | |
| 1044 | https://leetcode.com/problems/longest-duplicate-substring/discuss/695029/Python-Binary-search-O(n-log-n)-average-with-Rabin-Karp-explained | |
| 1094 | https://leetcode.com/problems/car-pooling/discuss/857489/Python-linear-solution-using-cumulative-sums-explained | |
| 1103 | https://leetcode.com/problems/distribute-candies-to-people/discuss/796574/python-math-ok-solution-with-explanation | |
| 1217 | https://leetcode.com/problems/minimum-cost-to-move-chips-to-the-same-position/discuss/924174/Python-Oneliner-O(n)-explained | |
| 1283 | https://leetcode.com/problems/find-the-smallest-divisor-given-a-threshold/discuss/925512/Python-Short-and-clean-binary-search-explained | |
| 1286 | https://leetcode.com/problems/iterator-for-combination/discuss/790113/Python-O(k)-on-the-fly-explained | |
| 1288 | https://leetcode.com/problems/remove-covered-intervals/discuss/878505/Python-Sort-starts-in-O(n-log-n)-explained | |
| 1290 | https://leetcode.com/problems/convert-binary-number-in-a-linked-list-to-integer/discuss/918946/Python-simple-O(n)-solution-explained | |
| 1291 | https://leetcode.com/problems/sequential-digits/discuss/853592/Python-Solution-using-queue-explained | |
| 1305 | https://leetcode.com/problems/all-elements-in-two-binary-search-trees/discuss/829720/Python-O(n1-%2B-n2)-inorder-traversal-explained | |
| 1306 | https://leetcode.com/problems/jump-game-iii/discuss/953127/Python-iterative-dfs-explained | |
| 1344 | https://leetcode.com/problems/angle-between-hands-of-a-clock/discuss/735395/python-math-solution-oneliner-explained | |
| 1345 | https://leetcode.com/problems/jump-game-iv/discuss/988714/Python-bfs-with-small-trick-explained | |
| 1397 | https://leetcode.com/problems/find-all-good-strings/discuss/655787/python-onk-kmp-with-dp-very-detailed-explanation | |
| 1446 | https://leetcode.com/problems/consecutive-characters/discuss/921642/Python-Oneliner-using-groupby-explained | |
| 1457 | https://leetcode.com/problems/pseudo-palindromic-paths-in-a-binary-tree/discuss/649959/Python-O(n)-time-and-O(k%2BH)-space-DFS-preorder-traversal-solution-with-explanation | |
| 1458 | https://leetcode.com/problems/max-dot-product-of-two-subsequences/discuss/649795/python-omn-time-and-memory-clean-dp | |
| 1461 | https://leetcode.com/problems/check-if-a-string-contains-all-binary-codes-of-size-k/discuss/660760/python-onk-solution-with-sets-explained | |
| 1463 | https://leetcode.com/problems/cherry-pickup-ii/discuss/660586/python-clean-om2n-dp-10-lines-explained | |
| 1466 | https://leetcode.com/problems/reorder-routes-to-make-all-paths-lead-to-the-city-zero/discuss/661778/python-clean-dfs-with-explanations | |
| 1467 | https://leetcode.com/problems/probability-of-a-two-boxes-having-the-same-number-of-distinct-balls/discuss/661757/python-10-lines-90-multionomial-coefficients-explained | |
| 1478 | https://leetcode.com/problems/allocate-mailboxes/discuss/685772/python-classical-down-up-solution-explained-on3 | |
| 1492 | https://leetcode.com/problems/the-kth-factor-of-n/discuss/959365/Python-O(sqrt(n))-solution-explained | |
| 1493 | https://leetcode.com/problems/longest-subarray-of-1s-after-deleting-one-element/discuss/708109/python-on-dynamic-programming-detailed-explanation | |
| 1494 | https://leetcode.com/problems/parallel-courses-ii/discuss/710229/python-short-dp-with-binary-masks-on22n-explained | |
| 1510 | https://leetcode.com/problems/stone-game-iv/discuss/909373/Python-DP-solution-using-game-theory-explained | |
| 1639 | https://leetcode.com/problems/number-of-ways-to-form-a-target-string-given-a-dictionary/discuss/917693/Python-Short-O(mn)-dp-solution-explained | |
| 1643 | https://leetcode.com/problems/kth-smallest-instructions/discuss/918393/Python-O((m%2Bn)2)-solution-explained | |
| 1659 | https://leetcode.com/problems/maximize-grid-happiness/discuss/936467/Python-Short-and-clean-dp-with-diagram-expained | |
| 1671 | https://leetcode.com/problems/minimum-number-of-removals-to-make-mountain-array/discuss/952053/Python-3-solutions%3A-LIS-dp-O(n-log-n)-explained |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| package main | |
| import ( | |
| "encoding/json" | |
| "fmt" | |
| "io/ioutil" | |
| "net/http" | |
| "os" | |
| "regexp" | |
| "strconv" | |
| "strings" | |
| ) | |
| var client = &http.Client{} | |
| func main() { | |
| ids, err := parseIds("babichev.csv") | |
| fmt.Println(ids) | |
| if err != nil { | |
| fmt.Println(err) | |
| return | |
| } | |
| topics, err := readTopics(ids) | |
| if err != nil { | |
| fmt.Println(err) | |
| return | |
| } | |
| fmt.Println(ids, len(ids)) | |
| err = writeTopics("babichev.json", topics) | |
| if err != nil { | |
| fmt.Println(err) | |
| } | |
| fmt.Println("done") | |
| } | |
| type Post struct { | |
| ID int `json:"id"` | |
| Content string `json:"content"` | |
| UpdationDate int `json:"updationDate"` | |
| CreationDate int `json:"creationDate"` | |
| } | |
| type Topic struct { | |
| ID int `json:"id"` | |
| Title string `json:"title"` | |
| TaskURL string `json:"taskUrl"` | |
| Post Post `json:"post"` | |
| } | |
| type Data struct { | |
| Topic Topic `json:"topic"` | |
| } | |
| type Result struct { | |
| Data Data `json:"data"` | |
| } | |
| type TaskID struct { | |
| taskLink string | |
| id int | |
| } | |
| func writeTopics(filename string, topics []Topic) error { | |
| bytes, err := json.Marshal(topics) | |
| if err != nil { | |
| return err | |
| } | |
| err = ioutil.WriteFile(filename, bytes, 0644) | |
| return err | |
| } | |
| func readTopics(ids []TaskID) (topics []Topic, err error) { | |
| var topic *Topic | |
| for _, id := range ids { | |
| topic, err = readTopic(id.id) | |
| topic.TaskURL = id.taskLink | |
| if err != nil { | |
| return | |
| } | |
| topics = append(topics, *topic) | |
| } | |
| return | |
| } | |
| func parseIds(filename string) (ids []TaskID, err error) { | |
| var seq int | |
| var url string | |
| f, err := os.Open(filename) | |
| if err != nil { | |
| return | |
| } | |
| defer f.Close() | |
| re := regexp.MustCompile(`/\d+/`) | |
| reURL := regexp.MustCompile(`https://leetcode.com/problems/[^/]+`) | |
| for n, err := fmt.Fscan(f, &seq, &url); n != 0 && err == nil; n, err = fmt.Fscan(f, &seq, &url) { | |
| var taskID TaskID | |
| urlBytes := []byte(url) | |
| idRes := string(re.Find(urlBytes)) | |
| taskID.id, err = strconv.Atoi(strings.Trim(idRes, "/")) | |
| taskID.taskLink = string(reURL.Find(urlBytes)) | |
| ids = append(ids, taskID) | |
| } | |
| return | |
| } | |
| func readTopic(id int) (topic *Topic, err error) { | |
| var data Result | |
| cont, err := read(id) | |
| if err != nil { | |
| return | |
| } | |
| err = json.Unmarshal(cont, &data) | |
| if err != nil { | |
| return | |
| } | |
| return &data.Data.Topic, nil | |
| } | |
| func read(id int) (content []byte, err error) { | |
| url := "https://leetcode.com/graphql" | |
| method := "POST" | |
| query := fmt.Sprintf(`{"operationName":"DiscussTopic","variables":{"topicId":%v},"query":"query DiscussTopic($topicId: Int!) {\n topic(id: $topicId) {\n id\n title\n post {\n ...DiscussPost\n }\n }\n}\n\nfragment DiscussPost on PostNode {\n id\n content\n updationDate\n creationDate\n author {\n username\n }\n }\n"}`, id) | |
| payload := strings.NewReader(query) | |
| req, err := http.NewRequest(method, url, payload) | |
| if err != nil { | |
| fmt.Println(err) | |
| return | |
| } | |
| req.Header.Add("sec-ch-ua", "\"Google Chrome\";v=\"89\", \"Chromium\";v=\"89\", \";Not A Brand\";v=\"99\"") | |
| req.Header.Add("accept", "*/*") | |
| req.Header.Add("X-NewRelic-ID", "UAQDVFVRGwEAXVlbBAg=") | |
| req.Header.Add("x-csrftoken", "7oEOdbDWkx27S6lB2kOkMLtI8F1xKYWAspX0y5mSqnuSL5YLdKoHEKYtjxkfH5Kw") | |
| req.Header.Add("sec-ch-ua-mobile", "?0") | |
| req.Header.Add("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36") | |
| req.Header.Add("content-type", "application/json") | |
| req.Header.Add("Cookie", "__cf_bm=5eceb9f0d8f9a4a277082586322ae39348641f5e-1617196161-1800-AW6CEdXadtEik4XNTUsLW2ArnhKaAUthhuY3YOVDdhNVpYVDdCT+SqW/aCaZv97PSFD71B3mo1GmHnCtDeqZ8KQ=; __cfduid=dc6299f72540ee04ac2d15004383f03411617177420; csrftoken=tlJEiXgBwEes5qpVtxTOH8nALwQmYj9p5LLYBSlzsxwIMdvr0a6W0oyqRarALXIw") | |
| res, err := client.Do(req) | |
| if err != nil { | |
| return | |
| } | |
| defer res.Body.Close() | |
| body, err := ioutil.ReadAll(res.Body) | |
| if err != nil { | |
| return | |
| } | |
| return body, err | |
| } |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment