- Facebookが開発した クエリ言語
- 今はGraphQL Foundationに移管されている
https://quramy.github.io/graph-api-note/#/
- スキーマと静的な型
- Demand Driven Architecture
- Composition
スキーマには可能なクエリや操作の全てが記述されている。
表現方法はいくつかあるが、SDL(Schema Definition Language)で表現されることが多い。
type User {
id: ID!
name: String!
age: Int
friends: [User]
articles: [Article]
}
type Article {
id: ID!
title: String
body: String
}
type Query {
user(id: ID!): User
users: [User]
article(id: ID!): Article
}スキーマのお陰で、クエリに対する実行結果の型が静的に予測可能
query {
user(id: "Quramy") {
name
friends {
name
}
}
}type Data = {
user: {
name: string;
friends: {
name: string;
}[] | null;
} | null;
};Demand Driven Architecture(DDA)とは、データを取得する側が、どのようなレスポンスを必要とするかを宣言する方式のこと。
GraphQL以外のDDA:
- SQL
- SPARQL
- Falcor
- etc...
クライアントサイドにレスポンスの決定権を与える都合上、DDAではクエリ言語が必要になる。
対義語はSupply Driven Architectureであり、具体例はRESTやSOAP。レスポンスの形式がサーバーサイドによって固定されている方式を指す。
「データを取得する側」というのは、平たく言ってしまえばフロントエンド。 一見すると自由が与えられているようにも聞こえるが、自由には責任が伴うのが世の常。
Under-fetching / Over-fetching
- Under-fetching: 取得せねばならない項目をクエリに書き忘れること
- Over-fetching: クライアントで本来必要とする以上にデータを取得してしまうこと
Under-fetchingは機能要件に対する不備となる。1つフィールド名を書き忘れたら表示要件を満たせないアプリケーションに。
逆に、Over-fetchingの弊害は非機能要件側。不要な値がレスポンスに乗ることによる帯域逼迫や、最悪の場合サーバー側でN + 1を発生させて性能劣化要因に。 (実例: https://speakerdeck.com/nobuhikosawai/improving-online-shopping-site-performance-which-using-the-graphql?slide=57 )
フロントエンドエンジニアは、GraphQLクエリをアプリケーションに必要十分な状態に保ち続ける義務がある。
Over-fetching / Under-fetchingのリスクを低減させるには何をしたらいいのか?
Under-fetchingは防ぐには、適切にツールを使ってクエリから型を自動生成すればよい。
より対処が難しいのはOver-fetchingの方。
具体的な例で考えてみる。
例えば下記のようなクエリがあったとして、
query {
viewer {
repositories(first: 10) {
totalCount
edges {
node {
name
url
description
}
}
}
}
}description が本当に必要なのか、逆に足りていない項目は本当に無いのかどうかは、ViewとなっているComponentと突き合わせるしかない。
このアプリケーションに下記のようなコンポーネントがあれば、 description がクエリに含まれているのは妥当であると判断できる。
export default RepoItem = ({ name, url, description }) => (
<>
<a href={url}>{name}</a>
<span>{description}</span>
</>
);言い換えると、Component Scopedに取得データを宣言できれば管理しやすい ということ。
これはShadow DOM / CSS in JS / CSS Modules などの発想と一緒。 「コンポーネントに必要十分なCSSを、そのコンポーネントとセットで管理する」というアプローチで、画面の保守性や性能を保つことができる(ことフロントエンドに関しては、不要になったときに棄てやすいようなソースコード管理はとても重要)。
GraphQLにfragmentという構文が用意されており、フィールドの集合(selection set)を分離して別名を与えることができる。
例えば先のクエリにfragmentを適用して、3つに分割すると下記のように書き換えることができる。最終的なクエリの実行結果は全く変わらない。
fragment RepoItem on Repository {
name
url
description
}
fragment RepoList on RepositoryConnection {
totalCount
edges {
node {
id
...RepoItem
}
}
}
query AppQuery {
viewer {
repositories(first: 10) {
...RepoList
}
}
}こうして分割したフラグメントを、Component階層に合わせて配置するようにする。
export const RepoItemFragment = gql`
fragment RepoItem on Repository {
name
url
description
}
`;
export default RepoItem = (repo: { name, url, description }) => (
<>
<a href={url}>{name}</a>
<span>{description}</span>
</>
);import RepoItem, { RepoItemFragment } from "./repoItem";
export const RepoListFragment = gql`
${RepoItemFragment}
fragment RepoList on RepositoryConnection {
totalCount
edges {
node {
id
...RepoItem
}
}
}
`;
export default RepoList = ({ repositories: { totalCount, edges } }) => (
<>
<span>count: {totalCount}</span>
<ul>
{edges.map(({ node })=> (
<li key={node.id}>
<RepoItem repo={edge.node} />
</li>
))}
</ul>
</>
);import RepoList, { RepoListFragment } from "./repoList";
const query = gql`
${RepoListFragment}
viewer {
repositories(first: 10) {
...RepoList
}
}
`;
export default App = () => {
const { data } = useQuery(query);
return (
<div>
<RepoList repositories={data.viewer.repositories} />
</div>
);
};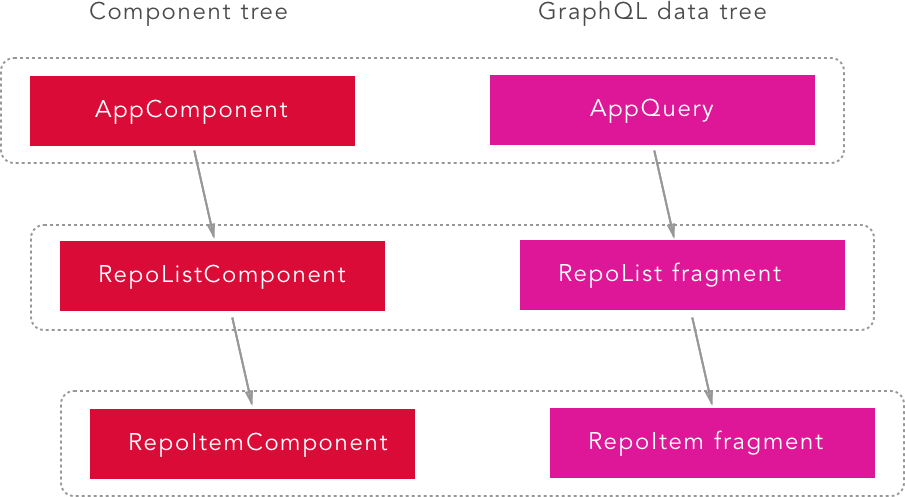
このように「ComponentとFragmentをセットで配置すること」をFragment Colocationという。
"Colocation"というのは「一緒に置く」という意味。ComponentとFragmentを一緒に管理する、という意味で使われる。
Facebook Relayの場合、Fragment Colocationを開発者に強制するフレームワーク設計となっているが、Apolloはそこまで堅い設計ではないため、クエリの分割管理指針はプロジェクト開始時にしっかり決めるべき。
「ColocationでOver-fetchingを発生させないようにする」ということを考えると、TSX中にテンプレートとしてGraphQLを記述しておき、フィールドが利用されていることを一目でわかるようにしておきたい。
export const RepoItemFragment = gql`
fragment RepoItem on Repository {
name
url
description
}
`;
type Props = {
repo: RepoItemFragmentType;
};
export default RepoItem = (repo: { name, url, description }: Props) => (
<>
<a href={url}>{name}</a>
<span>{description}</span>
</>
);JSX構文はTypeScriptのサポートがあるが、クエリ部分はテンプレート文字列でしかないため、開発サポートのために以下のNPMを開発している。
https://github.com/Quramy/ts-graphql-plugin
TypeScriptに対応したエディタ内で、補完、エラーチェック(syntax & semantic)をできるようにしている(Apolloが作っているVSC拡張と似ているが、ts-graphql-pluginはエディタを問わない)。
エディタサポート以外にも以下の機能が備わっている
- As CLI:
- クエリに対応した型定義生成
- .ts中のクエリのバリデーション
- As webpack custom transformer
- graphql-tag相当の処理をbuild時に行う(tree shakingと併せて使うと、graphql-jsのlexer/parserがdropされてbundle sizeが 30KB程度減らせる)
TypeScript AST と GraphQL ASTの両方を使っている。
- TypeScript AST example: https://astexplorer.net/#/gist/484905f95f1dda1d720683bcbafb117e/d36f56f1b9de4dd52a14cc2149b3ae20acf23b3a
- GraphQL AST example: https://astexplorer.net/#/gist/aa554382a078147d6989dba08b3eecd8/17d4c773fbe24c0e3eb0cdf3b3ec6366a60ad9c4
補完やバリデーションは、テンプレート文字列を探索し、文字列からGraphQL ASTへパースした後、解析器にかける流れ。
import { parse } from "graphql";
const visit = (node: ts.Node) => {
if (ts.isNoSubstitutionTemplateLiteral(node)) {
const gqlDocumentAst = parse(node.text);
// GraphQL ASTの解析
} else {
ts.forEachChild(ndoe, visit);
}
};
ts.forEachChild(program.getSourceFile('main.ts'), visit);Colocationでファイルを管理していると、export / import したFragmentがテンプレート中に埋め込まれる形になる(e.g. 下記の ${RepoItemFragment} の部分)。
/* repoItem.ts */
export const RepoItemFragment = gql`
fragment RepoItemFragment Repository {
name
}
`;/* repoList.ts */
import { RepoItemFragment } from "./repoItem";
export const RepoListFragment = gql`
${RepoItemFragment}
fragment RepoList on User {
repositories(first: 10) {
totalCount
edges {
node {
...RepoItem
}
}
}
}
`;こういった部分もTypeScript ASTから式情報を取り出し、(静的に解決できる範囲で)テンプレート文字列全体を評価してから、GraphQLとしての静的解析を実行している。
上記の例では、${RepoItemFragment} というconst値がどのファイルで定義されているのか?といった情報が解析時に必要となるため、TypeScript Language Service APIを使用することで解決している。
- DDAではフロントに責任が伴う
- クエリをどう管理するかが重要
- Colocationしましょう
- ts-graphql-plugin 試してみて