This is a quick Python script I wrote to download HumbleBundle books in batch. I bought the amazing Machine Learning by O'Reilly bundle. There were 15 books to download, with 3 different file formats per book. So I scratched a quick script to download all of them in batch.
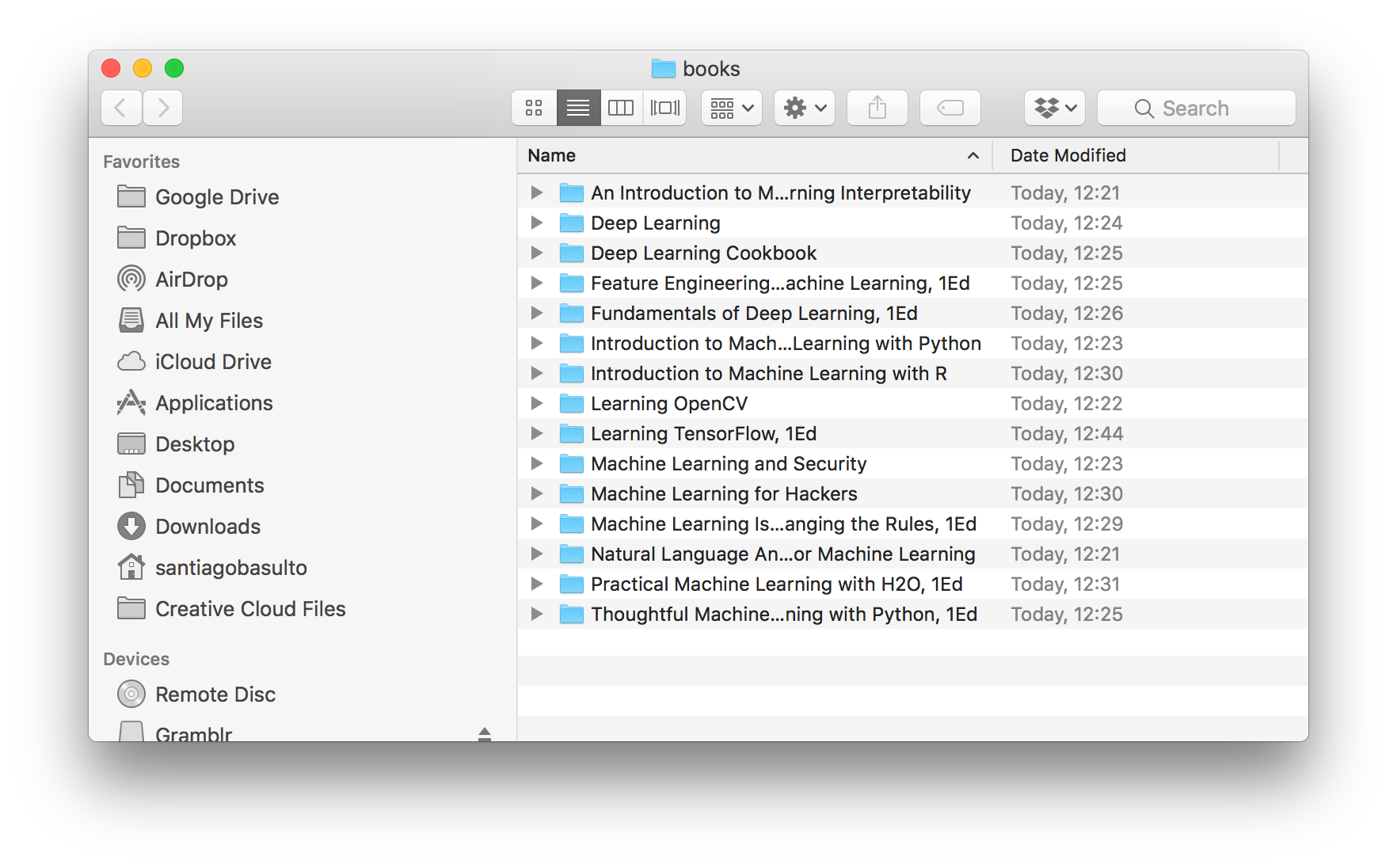
(Final Result: books downloaded)
It's a simple script, the only problem is extracting the generated HTML from Humble Bundle. Here is a step by step guide:
After your purchase, open the download page:

This is how mine looks like
I'm using Chrome, but Firefox also works for this. Right click anywhere on the page and click on "Inspect Element":
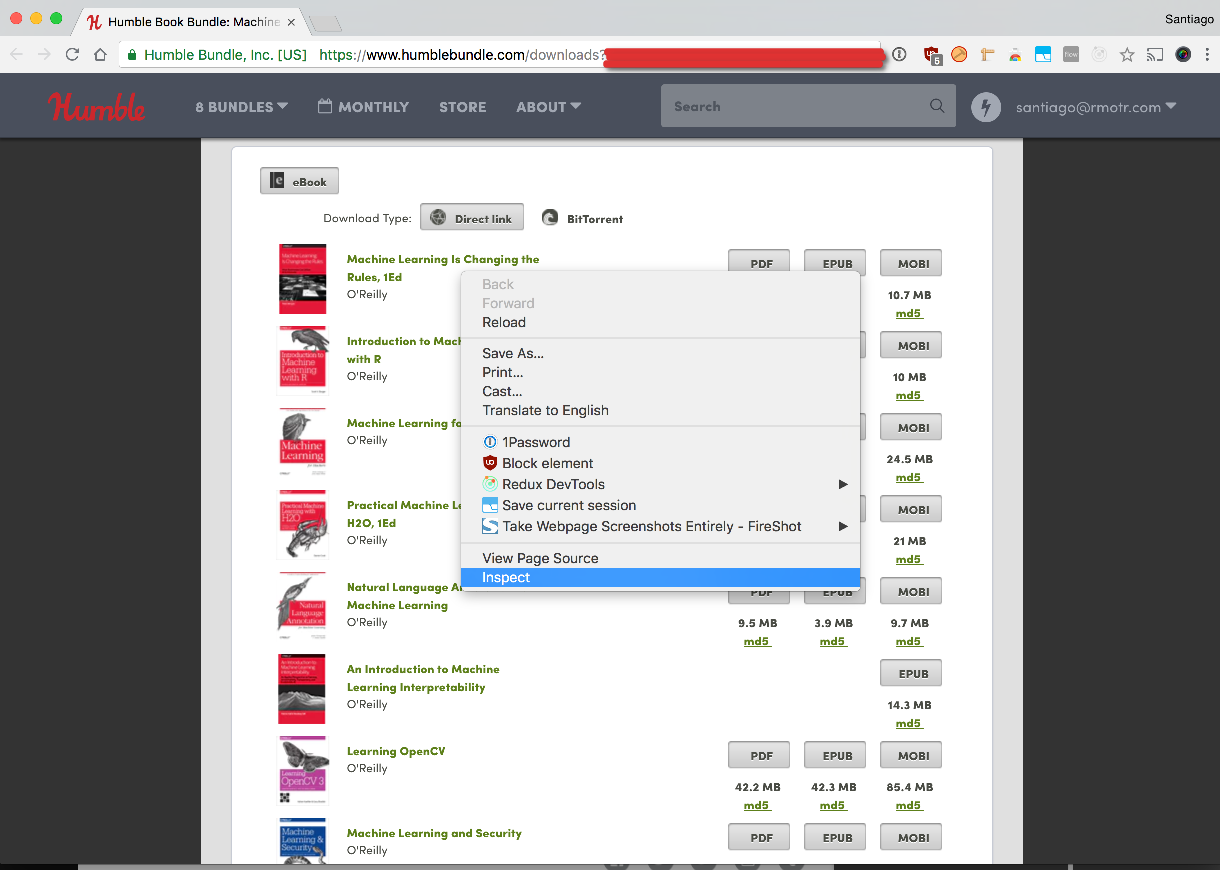
Once you click on Inspect, the developer window should pop up:

Scroll up until you see the initial <html> element. Once you've identified it, right click on it and do: Copy > Copy Element

Create a new file in your favorite editor and paste the contents that you've just copied from the previous step.
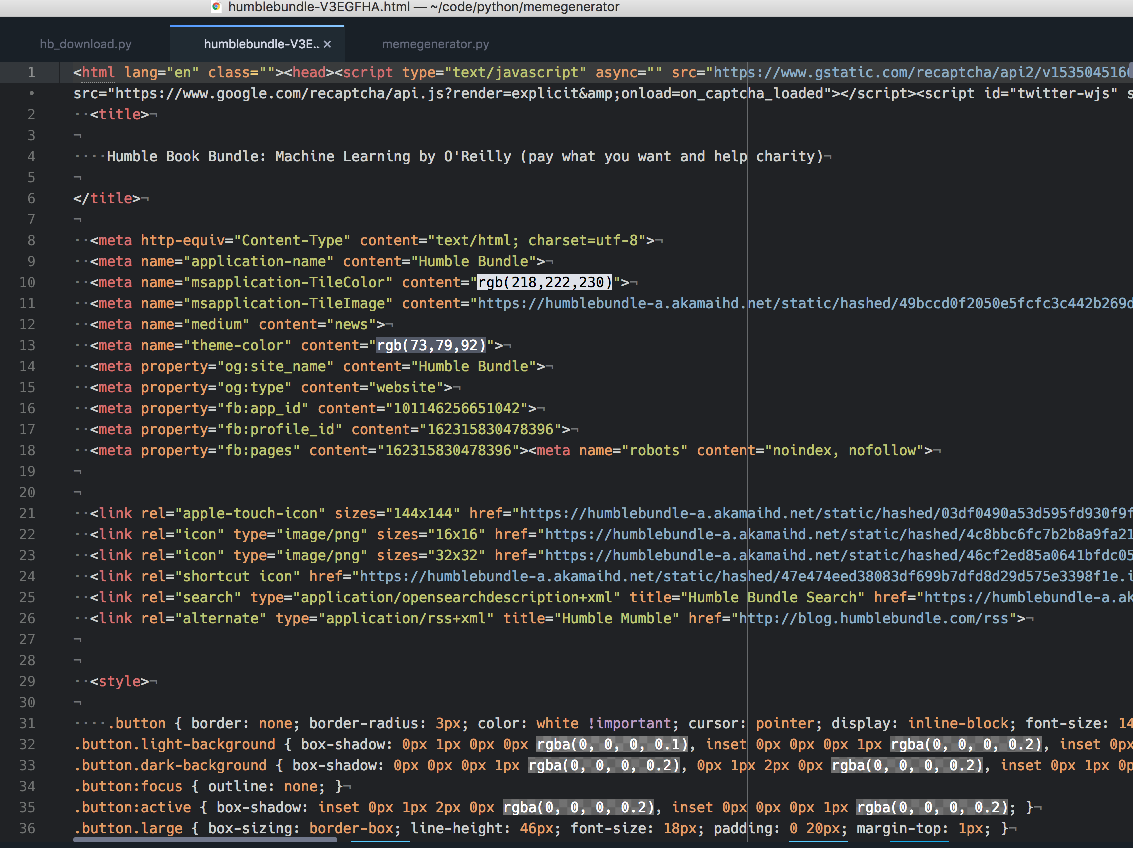
Use a good name for the html file because we'll use it next. For example: humble_bundle_ml.html
Important: this script requires Python 3
Now you're ready to download those books. In your command line tool, create a virtualenv and install dependencies:
$ pip install beautifulsoup4 requestsNow you can invoke the actual command:
$ python hb_download.py humble_bundle_ml.html --epub --pdfBy default it'll download the books in a directory named books/. You can change that with the -d command.
❯ python hb_download.py --help
usage: hb_download.py [-h] [-d DESTINATION_DIR] [--epub] [--pdf] [--mobi]
html_file
Download
positional arguments:
html_file HTML file to download books from
optional arguments:
-h, --help show this help message and exit
-d DESTINATION_DIR, --destination-dir DESTINATION_DIR
Directory where books will be saved
--epub
--pdf
--mobi