Last active
March 8, 2019 18:10
-
-
Save ThomasDelteil/63a37d87bb14c7b98f0b4cd9a4167d32 to your computer and use it in GitHub Desktop.
GRT_Amazon_08
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Gluon-NLP" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "1. Pre-trained word embeddings\n", | |
| "2. Pre-trained language models\n", | |
| "3. Fine-tuning BERT \n", | |
| "\n", | |
| "http://gluon-nlp.mxnet.io/" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "## Pre-trained word embeddings" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "Here we introduce how to use pre-trained word embeddings, where each word is represened by a vector. Two popular word embeddings are GloVe and fastText. The used GloVe and fastText pre-trained word embeddings here are from the following sources:\n", | |
| "\n", | |
| "* GloVe project website:https://nlp.stanford.edu/projects/glove/\n", | |
| "* fastText project website:https://fasttext.cc/\n", | |
| "\n", | |
| "Let us first import the following packages used in this example." | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:37.022037Z", | |
| "start_time": "2018-06-06T21:56:35.507701Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "import mxnet as mx\n", | |
| "from mxnet import gluon, nd\n", | |
| "import gluonnlp as nlp\n", | |
| "import re" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "We pick a specific pre-trained embedding" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:42.177372Z", | |
| "start_time": "2018-06-06T21:56:39.926375Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "embedding = nlp.embedding.create('glove', source='glove.6B.50d')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:43.752190Z", | |
| "start_time": "2018-06-06T21:56:42.180013Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "vocab = nlp.Vocab(nlp.data.Counter(embedding.idx_to_token))\n", | |
| "vocab.set_embedding(embedding)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "Below shows the size of `vocab` including a special unknown token." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:43.761479Z", | |
| "start_time": "2018-06-06T21:56:43.754645Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "len(vocab.idx_to_token)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "We can access attributes of `vocab`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:43.772797Z", | |
| "start_time": "2018-06-06T21:56:43.764792Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "print(vocab['beautiful'])\n", | |
| "print(vocab.idx_to_token[71424])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:43.791341Z", | |
| "start_time": "2018-06-06T21:56:43.776953Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def cos_sim(x, y):\n", | |
| " return nd.dot(x, y) / (nd.norm(x) * nd.norm(y))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "### Word Similarity" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "Given an input word, we can find the nearest $k$ words from the vocabulary (400,000 words excluding the unknown token) by similarity. The similarity between any pair of words can be represented by the cosine similarity of their vectors." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:44.041379Z", | |
| "start_time": "2018-06-06T21:56:44.016299Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def norm_vecs_by_row(x):\n", | |
| " return x / nd.sqrt(nd.sum(x * x, axis=1)).reshape((-1,1))\n", | |
| "\n", | |
| "def get_knn(vocab, k, word):\n", | |
| " word_vec = vocab.embedding[word].reshape((-1, 1))\n", | |
| " vocab_vecs = norm_vecs_by_row(vocab.embedding.idx_to_vec)\n", | |
| " dot_prod = nd.dot(vocab_vecs[4:], word_vec)\n", | |
| " indices = nd.topk(dot_prod.squeeze(), k=k+1, ret_typ='indices')\n", | |
| " indices = [int(i.asscalar())+4 for i in indices]\n", | |
| " # Remove unknown and input tokens.\n", | |
| " return vocab.to_tokens(indices[1:])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "Let us find the 5 most similar words of 'baby' from the vocabulary (size: 400,000 words)." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:44.508966Z", | |
| "start_time": "2018-06-06T21:56:44.044708Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_knn(vocab, 5, 'baby')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "source": [ | |
| "We can verify the cosine similarity of vectors of 'baby' and 'babies'." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:44.520428Z", | |
| "start_time": "2018-06-06T21:56:44.511361Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "cos_sim(vocab.embedding['baby'], vocab.embedding['babies'])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "Let us find the 5 most similar words of 'run' from the vocabulary." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:45.464662Z", | |
| "start_time": "2018-06-06T21:56:44.957783Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_knn(vocab, 5, 'research')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "Let us find the 5 most similar words of 'beautiful' from the vocabulary." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:46.093124Z", | |
| "start_time": "2018-06-06T21:56:45.468022Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_knn(vocab, 5, 'computer')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Challenge**\n", | |
| "\n", | |
| "Try out the `get_knn` function with a word of your own" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "### Word Analogy" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "notes" | |
| } | |
| }, | |
| "source": [ | |
| "We can also apply pre-trained word embeddings to the word analogy problem. For instance, \"man : woman :: son : daughter\" is an analogy. The word analogy completion problem is defined as: for analogy 'a : b :: c : d', given teh first three words 'a', 'b', 'c', find 'd'. The idea is to find the most similar word vector for vec('c') + (vec('b')-vec('a')).\n", | |
| "\n", | |
| "In this example, we will find words by analogy from the 400,000 indexed words in `vocab`." | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:46.158875Z", | |
| "start_time": "2018-06-06T21:56:46.103712Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def get_top_k_by_analogy(vocab, k, word1, word2, word3):\n", | |
| " word_vecs = vocab.embedding[word1, word2, word3]\n", | |
| " \n", | |
| " word_diff = (word_vecs[1] - word_vecs[0] + word_vecs[2])\n", | |
| " \n", | |
| " vocab_vecs = norm_vecs_by_row(vocab.embedding.idx_to_vec)\n", | |
| " dot_prod = nd.dot(vocab_vecs[4:], word_diff.squeeze()).squeeze()\n", | |
| " \n", | |
| " indices = dot_prod.topk(k=k+1, ret_typ='indices')\n", | |
| " indices = [int(i.asscalar())+4 for i in indices]\n", | |
| " words = [w for w in vocab.to_tokens(indices) if w != word3]\n", | |
| " return words[:k]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "### Semantic Analogy\n", | |
| "\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:46.626485Z", | |
| "start_time": "2018-06-06T21:56:46.161792Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'man', 'woman', 'son')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "source": [ | |
| "Let us verify the cosine similarity between vec('son')+vec('woman')-vec('man') and vec('daughter')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:46.644371Z", | |
| "start_time": "2018-06-06T21:56:46.629075Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "def cos_sim_word_analogy(vocab, word1, word2, word3, word4):\n", | |
| " words = [word1, word2, word3, word4]\n", | |
| " vecs = vocab.embedding[words]\n", | |
| " return cos_sim(vecs[1] - vecs[0] + vecs[2], vecs[3])\n", | |
| "\n", | |
| "cos_sim_word_analogy(vocab, 'man', 'woman', 'son', 'daughter')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:47.104740Z", | |
| "start_time": "2018-06-06T21:56:46.647576Z" | |
| }, | |
| "scrolled": true, | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'celtics', 'nba', 'patriots')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'france', 'football', 'india')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'wine', 'red', 'sky')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'russia', 'moscow', 'france')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "### Syntactic Analogy" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:47.502780Z", | |
| "start_time": "2018-06-06T21:56:47.107420Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'bad', 'worst', 'big')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": { | |
| "ExecuteTime": { | |
| "end_time": "2018-06-06T21:56:47.898396Z", | |
| "start_time": "2018-06-06T21:56:47.505389Z" | |
| }, | |
| "slideshow": { | |
| "slide_type": "fragment" | |
| } | |
| }, | |
| "outputs": [], | |
| "source": [ | |
| "get_top_k_by_analogy(vocab, 1, 'do', 'did', 'go')" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Challenge**\n", | |
| "\n", | |
| "write one semantic and one syntactic analogy using `get_top_k_by_analogy`" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": { | |
| "slideshow": { | |
| "slide_type": "slide" | |
| } | |
| }, | |
| "source": [ | |
| "### Application\n", | |
| "\n", | |
| "- Language Modelling\n", | |
| "- Neural Machine Translation\n", | |
| "- Text classification" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "# Language Modelling\n", | |
| "Generating text with a pre-trained language model" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "ctx = mx.gpu() if mx.context.num_gpus() > 0 else mx.cpu()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "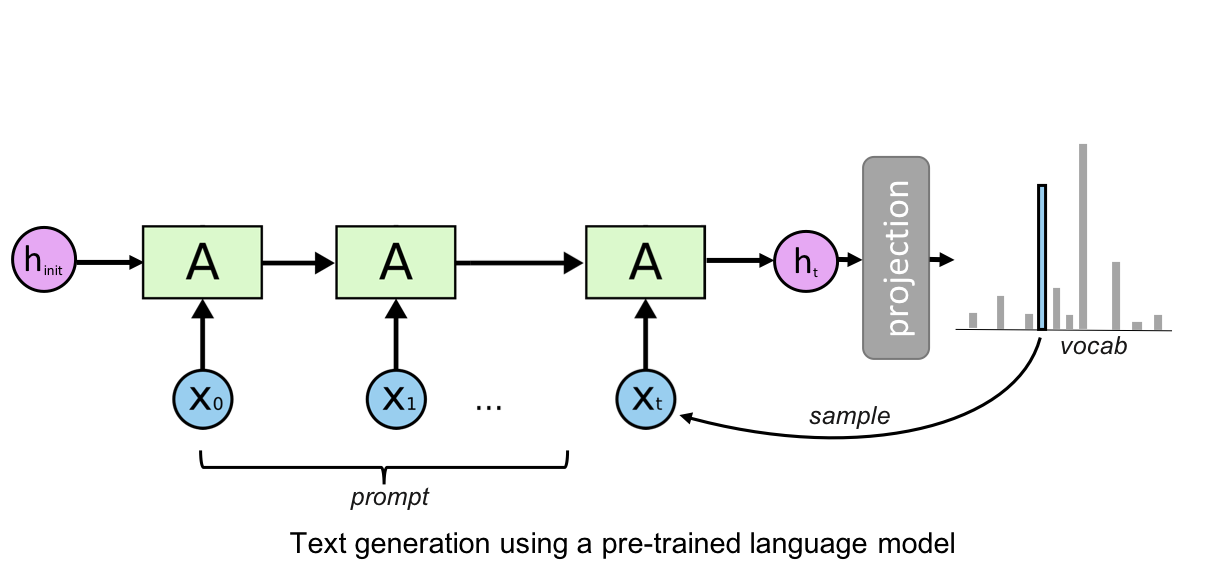\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "lm_model, vocab = nlp.model.get_model(name='big_rnn_lm_2048_512',\n", | |
| " dataset_name='gbw',\n", | |
| " pretrained=True,\n", | |
| " ctx=ctx)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "We need a decoder function that can be called recursively by our sampler" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "class Decoder:\n", | |
| " def __init__(self, model):\n", | |
| " self.model = model\n", | |
| " \n", | |
| " def __call__(self, inputs, states):\n", | |
| " outputs, states = self.model(mx.nd.expand_dims(inputs, axis=0), states)\n", | |
| " return outputs[0], states\n", | |
| "\n", | |
| "decoder = Decoder(lm_model)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Instead of taking the most probable value for the next token, we sample from the distribution" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "sampler = nlp.model.SequenceSampler(beam_size=1,\n", | |
| " decoder=decoder,\n", | |
| " eos_id=vocab['<eos>'],\n", | |
| " max_length=20,\n", | |
| " temperature=0.30)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Setting up the prompt for our language model" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "prompt = \"This was the day ,\"\n", | |
| "prompt_tokenized = prompt.split(' ')\n", | |
| "bos_ids = [vocab[ele] for ele in prompt_tokenized]" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Getting the initial states of the model" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "init_states = lm_model.begin_state(batch_size=1, ctx=ctx)\n", | |
| "_, sampling_states = lm_model(mx.nd.expand_dims(mx.nd.array(bos_ids[:-1], ctx=ctx), axis=1), init_states)\n", | |
| "\n", | |
| "inputs = mx.nd.full(shape=(1,), ctx=ctx, val=bos_ids[-1])" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": null, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "samples, _, valid_lengths = sampler(inputs, sampling_states)\n", | |
| "for sample, valid_length in zip(samples[0].asnumpy(), valid_lengths[0].asnumpy()):\n", | |
| " sentence = prompt_tokenized[:-1] +[vocab.idx_to_token[ele] for ele in sample[:valid_length]]\n", | |
| " print(' '.join(sentence))" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "**Challenge**\n", | |
| "\n", | |
| "- Modify the prompt to generate sentences of your own.\n", | |
| "\n", | |
| "- Modify the temperature parameter to evaluate its impact on token sampling" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "celltoolbar": "Slideshow", | |
| "kernelspec": { | |
| "display_name": "conda_mxnet_p36", | |
| "language": "python", | |
| "name": "conda_mxnet_p36" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.6.5" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 2 | |
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/bin/bash | |
| echo ". /home/ec2-user/anaconda3/etc/profile.d/conda.sh" >> ~/.bashrc | |
| source ~/.bashrc | |
| source activate mxnet_p36 | |
| sudo chown -R ec2-user /tmp | |
| pip uninstall mxnet-cu90mkl -y | |
| pip install mxnet-cu90mkl --user --pre --upgrade | |
| pip install gluonnlp --user --pre --upgrade | |
| pip install gluoncv --user --pre --upgrade | |
| cd /home/ec2-user/SageMaker | |
| git clone https://gist.github.com/ThomasDelteil/63a37d87bb14c7b98f0b4cd9a4167d32 GRT_gluon_toolkits | |
| wget http://gluon-nlp.mxnet.io/_downloads/sentence_embedding.zip | |
| unzip sentence_embedding.zip -d GRT_gluon_toolkits | |
| rm sentence_embedding.zip |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment