Last active
May 14, 2019 23:31
-
-
Save ThomasDelteil/f52349f26701d519b93649e21e62ff77 to your computer and use it in GitHub Desktop.
WorkshopNLP
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "cells": [ | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
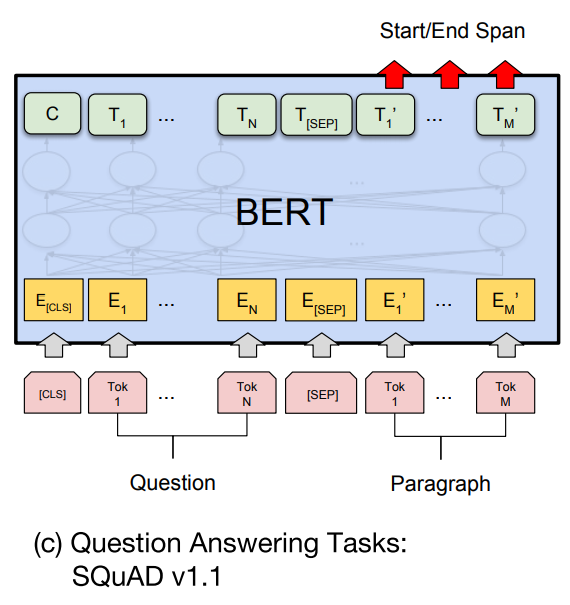
| "# BERT Question Answering" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Fine-tuning BERT on Q/A domain" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "First we fine-tune the pre-trained BERT model on the Question Answering task by running this script:\n", | |
| "\n", | |
| "```\n", | |
| "cd gluon-nlp/scripts/bert\n", | |
| "python finetune_squad.py --optimizer adam --batch_size 12 --lr 3e-5 --epochs 2 --gpu\n", | |
| "```\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Inference of new data" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 31, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "import os, sys, collections, ast\n", | |
| "\n", | |
| "sys.path.insert(0, 'gluon-nlp/scripts/bert')\n", | |
| "sys.path.insert(0, 'gluon-nlp/scripts/question_answering')\n", | |
| "\n", | |
| "import mxnet as mx\n", | |
| "from mxnet import nd\n", | |
| "import gluonnlp as nlp\n", | |
| "from gluonnlp.data import BERTTokenizer\n", | |
| "from mxnet.gluon.data import SimpleDataset\n", | |
| "\n", | |
| "from bert_qa_dataset import SQuADTransform\n", | |
| "from bert_qa_evaluate import predictions\n", | |
| "from bert_qa_model import BertForQA" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 40, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "Result = collections.namedtuple('_Result', ['start_logits', 'end_logits'])\n", | |
| "\n", | |
| "########################\n", | |
| "# Compute Context #\n", | |
| "########################\n", | |
| "ctx = mx.gpu() if mx.context.num_gpus() > 0 else mx.cpu()" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Getting the model" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 60, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def get_model(param_file_path= 'my_params.params', ctx=mx.cpu()):\n", | |
| "\n", | |
| "\n", | |
| " ########################\n", | |
| " # Load the model #\n", | |
| " ########################\n", | |
| " bert, vocab = nlp.model.get_model(\n", | |
| " name='bert_12_768_12',\n", | |
| " dataset_name='book_corpus_wiki_en_uncased',\n", | |
| " pretrained=False,\n", | |
| " ctx=ctx,\n", | |
| " use_pooler=False,\n", | |
| " use_decoder=False,\n", | |
| " use_classifier=False)\n", | |
| " bert.encoder._output_attention = False\n", | |
| "\n", | |
| " net = BertForQA(bert)\n", | |
| " tokenizer = BERTTokenizer(vocab)\n", | |
| " data_transformer = SQuADTransform(tokenizer)\n", | |
| "\n", | |
| " net.load_parameters(param_file_path, ctx=ctx)\n", | |
| "\n", | |
| " return net, tokenizer, data_transformer" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "Running the inference" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 193, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "def get_result(paragraph, question, net, tokenizer, data_transformer, ctx=mx.cpu()):\n", | |
| "\n", | |
| " features = data_transformer((0, 0, question, paragraph, [''], [0], 0))[0]\n", | |
| " examples = data_transformer._transform(*(0, 0, question, paragraph, [''], [0], 0))\n", | |
| "\n", | |
| " input_ids = nd.array(features[1]).astype('float32').expand_dims(axis=0).as_in_context(ctx)\n", | |
| " token_types = nd.array(features[2]).astype('float32').expand_dims(axis=0).as_in_context(ctx)\n", | |
| " valid_length = nd.array([features[3]]).astype('float32').as_in_context(ctx)\n", | |
| "\n", | |
| " out = net(input_ids, token_types, valid_length)\n", | |
| " output = nd.split(out, axis=2, num_outputs=2)\n", | |
| "\n", | |
| " start_logits = output[0].reshape((0, -3)).asnumpy()\n", | |
| " end_logits = output[1].reshape((0, -3)).asnumpy()\n", | |
| " all_possible_results = [Result(start.tolist(), end.tolist()) for start, end in zip(start_logits, end_logits)]\n", | |
| "\n", | |
| " all_predictions, all_nbest_json, scores_diff_json = predictions([examples], [all_possible_results], tokenizer, n_best_size=1)\n", | |
| "\n", | |
| " return all_predictions[0]\n", | |
| " " | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "\n", | |
| "\n", | |
| "\n", | |
| "\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "markdown", | |
| "metadata": {}, | |
| "source": [ | |
| "## Evaluation" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 194, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
| "net, tokenizer, data_transformer = get_model('gluon-nlp/scripts/bert/output_dir/net.params', ctx)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 195, | |
| "metadata": {}, | |
| "outputs": [], | |
| "source": [ | |
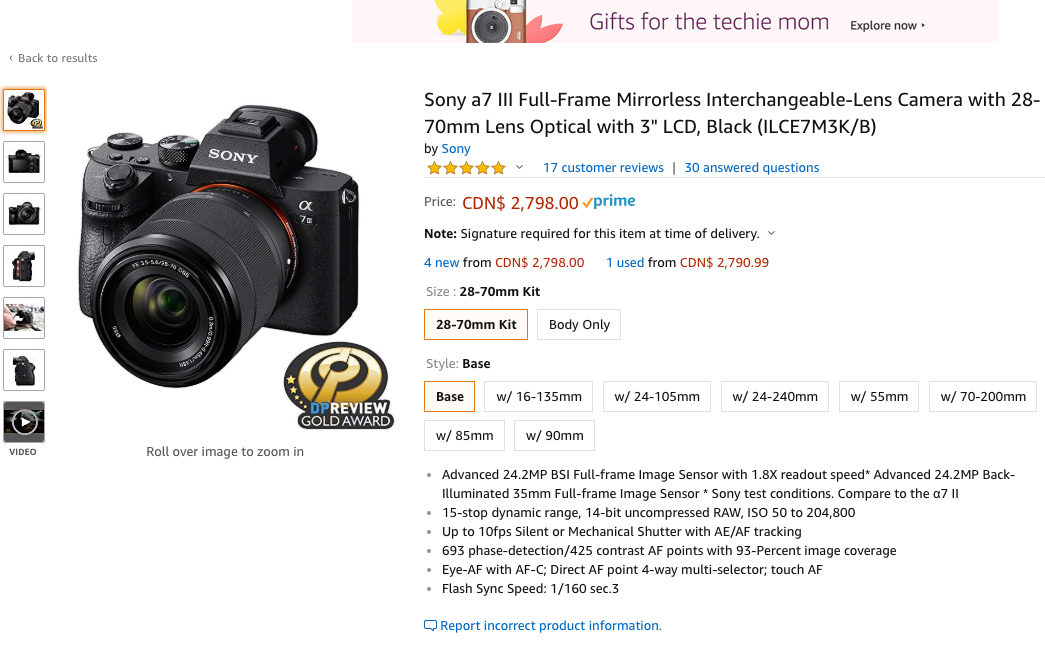
| "paragraph = \"\"\"\n", | |
| "Sony alpha7 III Full-frame Mirrorless Interchangeable-Lens Camera \n", | |
| "The a7 III has been refined for extraordinary image capture control and quality \n", | |
| "from the next generation 24.2MP full-frame BSI image sensor and latest BIONZ X\n", | |
| "image processor, down to the smallest operational detail. \n", | |
| "Featuring 693 phase AF points with up to 10fps1 continuous shooting 4K2 HDR3 \n", | |
| "video and the longest battery life of any mirrorless camera to date –\n", | |
| "the a7 III has everything you need (shown here with the Sony SEL2870 lens).\" \n", | |
| "\"\"\"\n" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 200, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'693'" | |
| ] | |
| }, | |
| "execution_count": 200, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "question = \"How many autofocus points does this camera have?\"\n", | |
| "get_result(paragraph, question, net, tokenizer, data_transformer, ctx)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 197, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'longest battery life'" | |
| ] | |
| }, | |
| "execution_count": 197, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "question = \"What is special about the battery of this camera?\"\n", | |
| "get_result(paragraph, question, net, tokenizer, data_transformer, ctx)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 198, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'Sony SEL2870'" | |
| ] | |
| }, | |
| "execution_count": 198, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "question = \"Which manufacturer produce the lens of this camera?\"\n", | |
| "get_result(paragraph, question, net, tokenizer, data_transformer, ctx)" | |
| ] | |
| }, | |
| { | |
| "cell_type": "code", | |
| "execution_count": 199, | |
| "metadata": {}, | |
| "outputs": [ | |
| { | |
| "data": { | |
| "text/plain": [ | |
| "'4K2 HDR3'" | |
| ] | |
| }, | |
| "execution_count": 199, | |
| "metadata": {}, | |
| "output_type": "execute_result" | |
| } | |
| ], | |
| "source": [ | |
| "question = \"What kind of video format is this camera able to shoot in?\"\n", | |
| "get_result(paragraph, question, net, tokenizer, data_transformer, ctx)" | |
| ] | |
| } | |
| ], | |
| "metadata": { | |
| "kernelspec": { | |
| "display_name": "Python 3", | |
| "language": "python", | |
| "name": "python3" | |
| }, | |
| "language_info": { | |
| "codemirror_mode": { | |
| "name": "ipython", | |
| "version": 3 | |
| }, | |
| "file_extension": ".py", | |
| "mimetype": "text/x-python", | |
| "name": "python", | |
| "nbconvert_exporter": "python", | |
| "pygments_lexer": "ipython3", | |
| "version": "3.6.5" | |
| } | |
| }, | |
| "nbformat": 4, | |
| "nbformat_minor": 2 | |
| } |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| bash | |
| cd SageMaker | |
| sudo yum install htop -y | |
| source activate mxnet_p36 | |
| echo "Preparing Face Recognition Lab" | |
| pip install gluoncv | |
| cd .. | |
| git clone https://github.com/THUFutureLab/gluon-face | |
| cd gluon-face/ | |
| python3 setup.py install | |
| cd .. | |
| cd SageMaker | |
| git clone https://github.com/ThomasDelteil/mxnet_mtcnn_face_detection FaceRecognition | |
| echo "Preparing Face Detection Lab" | |
| mkdir FaceDetection | |
| cd FaceDetection | |
| wget https://gist.githubusercontent.com/ThomasDelteil/f52349f26701d519b93649e21e62ff77/raw/4d4c81f73382de73d02199b9fe74939b7b49c4e9/face_detection.ipynb | |
| cd .. | |
| echo "Preparing GluonCV lab" | |
| mkdir GluonCV | |
| cd GluonCV | |
| wget https://gist.githubusercontent.com/ThomasDelteil/f52349f26701d519b93649e21e62ff77/raw/48dc108b25ed6d4eaeb0901485c7d2434524f5eb/gluonCV.ipynb | |
| cd .. | |
| echo "Preparing GAN Lab" | |
| pip install pillow | |
| git clone https://gist.github.com/vishaalkapoor/2fcce8981cad4af5cb42eb700974d3cf FaceGenerationGAN | |
| cd FaceGenerationGAN | |
| mkdir dataset output | |
| wget https://s3-us-west-2.amazonaws.com/mxnet-workshop-dropbox/celeba-dataset.zip | |
| cd dataset | |
| unzip ../celeba-dataset.zip | |
| unzip img_align_celeba.zip | |
| rm img*.zip list*.csv | |
| cd .. | |
| cd .. | |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment