- git fetch
- git stash
- git checkout
- git rebase
- git reset
- git cherry -v
- git cherry-pick
- git merge --squash
- git reset --hard
- git worktree
- git clean -df
- git log -G
- git reflog
- index
- work space
- HEAD
- git cat-file
- git ls-files
2017-11-09 @klook
-
solve more problem, increase efficiency. avoid error.
-
knowing what is happening.
-
choose the right tool to do the right thing
-
find out what happened in git history, AKA: 'who did this?!!'
-
recover from an error stage.
-
best practices
-
workflow (chen)
Note:
- this is a discussion.
- my opinions are biased
- basics: getting and creating project, setup and config, clone, .gitignore (hide changes you don't want to see or track.), basic usage
- things are useful but simple to know: tagging, prettify
source code control manage system used for linux kernel
-
distributed
-
performance
-
integrity (SHA-1, used ubiquitously)
-
all other vcs are trash
-
BitKeeper no longer

- Git is fundamentally a content-addressable filesystem with a VCS user interface written on top of it.

- It means that at the core of Git is a simple key-value data store. What this means is that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content.
-
Now, let’s use git hash-object to create a new data object and manually store it in your new Git database:
-
In its simplest form, git hash-object would take the content you handed to it and merely return the unique key that would be used to store it in your Git database. The -w option then tells the command to not simply return the key, but to write that object to the database. Finally, the --stdin option tells git hash-object to get the content to be processed from stdin;
~/git $ git init test
Initialized empty Git repository in /home/octave/git/test/.git/
~/git $ cd test/
.git
~/git/test (master #)$ find .git/objects/
.git/objects/
.git/objects/info
.git/objects/pack
~/git/test (master #)$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
~/git/test (master #)$ find .git/objects/ -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
- git-cat-file - Provide content or type and size information for repository objects
~/git/test (master #)$ git cat-file -t d670460b4b4aece5915caf5c68d12f560a9fe3e4
blob
~/git/test (master #)$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
~/git/test (master #)$ echo 'version 1' > test.txt
~/git/test (master #%)$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
~/git/test (master #%)$ echo 'version 2' > test.txt
~/git/test (master #%)$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
~/git/test (master #%)$ find .git/objects -type f
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
~/git/test (master #%)$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30
version 1
~/git/test (master #%)$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
version 2-
All the content is stored as tree and blob objects, with trees corresponding to UNIX directory entries and blobs corresponding more or less to inodes or file contents. A single tree object contains one or more tree entries, each of which contains a SHA-1 pointer to a blob or subtree with its associated mode, type, and filename.
-
You can fairly easily create your own tree. Git normally creates a tree by taking the state of your staging area or index and writing a series of tree objects from it. So, to create a tree object, you first have to set up an index by staging some files. To create an index with a single entry — the first version of your test.txt file — you can use the plumbing command git update-index. You use this command to artificially add the earlier version of the test.txt file to a new staging area. You must pass it the --add option because the file doesn’t yet exist in your staging area (you don’t even have a staging area set up yet) and --cacheinfo because the file you’re adding isn’t in your directory but is in your database. Then, you specify the mode, SHA-1, and filename:
-
Git normally creates a tree by taking the state of your staging area or index and writing a series of tree objects from it.
~/git/test (master #%)$ git update-index --add --cacheinfo 100644 83baae61804e65cc73a7201a7252750c76066a30 test.txt- Now, you can use git write-tree to write the staging area out to a tree object.
~/git/test (master *+)$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
~/git/test (master *+)$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
~/git/test (master *+)$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
- You’ll now create a new tree with the second version of test.txt and a new file as well:
~/git/test (master *+)$ echo 'new file' > new.txt
~/git/test (master *+%)$ git update-index --add --cacheinfo 100644 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
~/git/test (master +%)$ git update-index --add new.txtYour staging area now has the new version of test.txt as well as the new file new.txt. Write out that tree (recording the state of the staging area or index to a tree object) and see what it looks like:
~/git/test (master +)$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
~/git/test (master +)$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
- Just for fun, you’ll add the first tree as a subdirectory into this one. You can read trees into your staging area by calling git read-tree. In this case, you can read an existing tree into your staging area as a subtree by using the --prefix option with this command:
~/git/test (master +)$ git read-tree --prefix=whatever-you-name-it d8329fc1cc938780ffdd9f94e0d364e0ea74f579
~/git/test (master *+)$ git write-tree
3c2b28b833b0951d4ea54f94bcc7b21b934ab640
~/git/test (master *+)$ git cat-file -p 3c2b28b833b0951d4ea54f94bcc7b21b934ab640
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 whatever-you-name-it
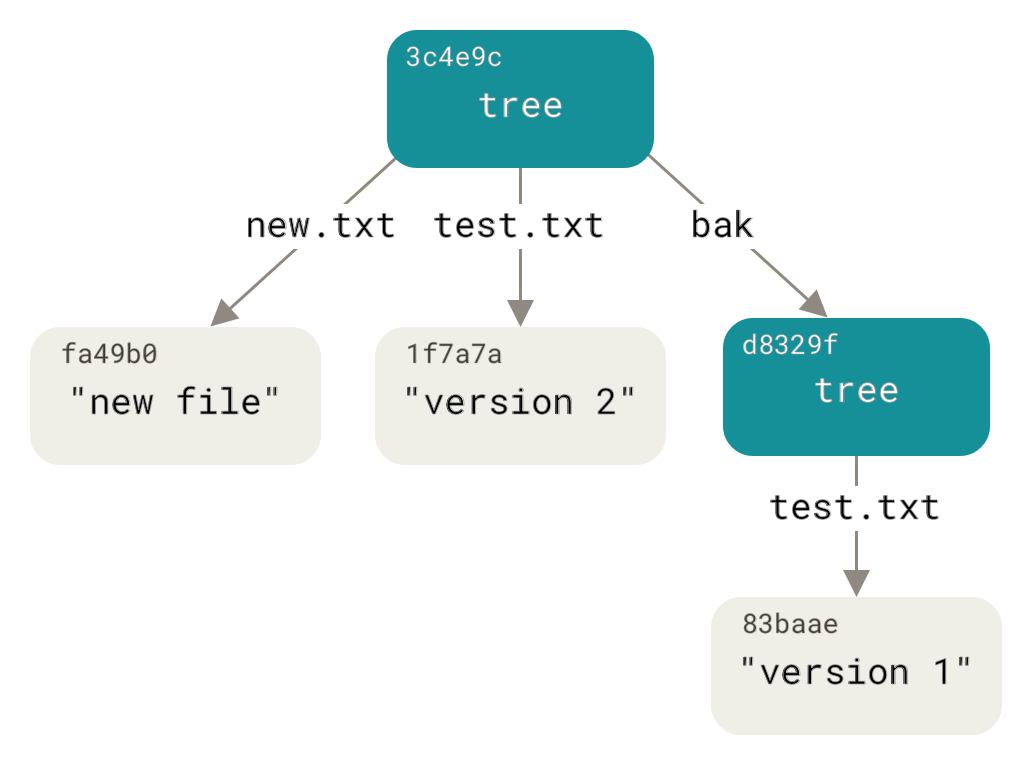
- now have three trees that represent the different snapshots of your project that you want to track
.git/objects/
├── 01
│ └── 55eb4229851634a0f03eb265b69f5a2d56f341 tree v2
├── 1f
│ └── 7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 'version 2'
├── 3c
│ └── 2b28b833b0951d4ea54f94bcc7b21b934ab640 tree v3
├── 83
│ └── baae61804e65cc73a7201a7252750c76066a30 blob 'version 1'
├── d6
│ └── 70460b4b4aece5915caf5c68d12f560a9fe3e4 blob 'test content'
├── d8
│ └── 329fc1cc938780ffdd9f94e0d364e0ea74f579 tree v1
├── fa
│ └── 49b077972391ad58037050f2a75f74e3671e92 blob 'new file'
├── info
└── pack
9 directories, 7 files
- you must remember all three SHA-1 values in order to recall the snapshots. You also don’t have any information about who saved the snapshots, when they were saved, or why they were saved.
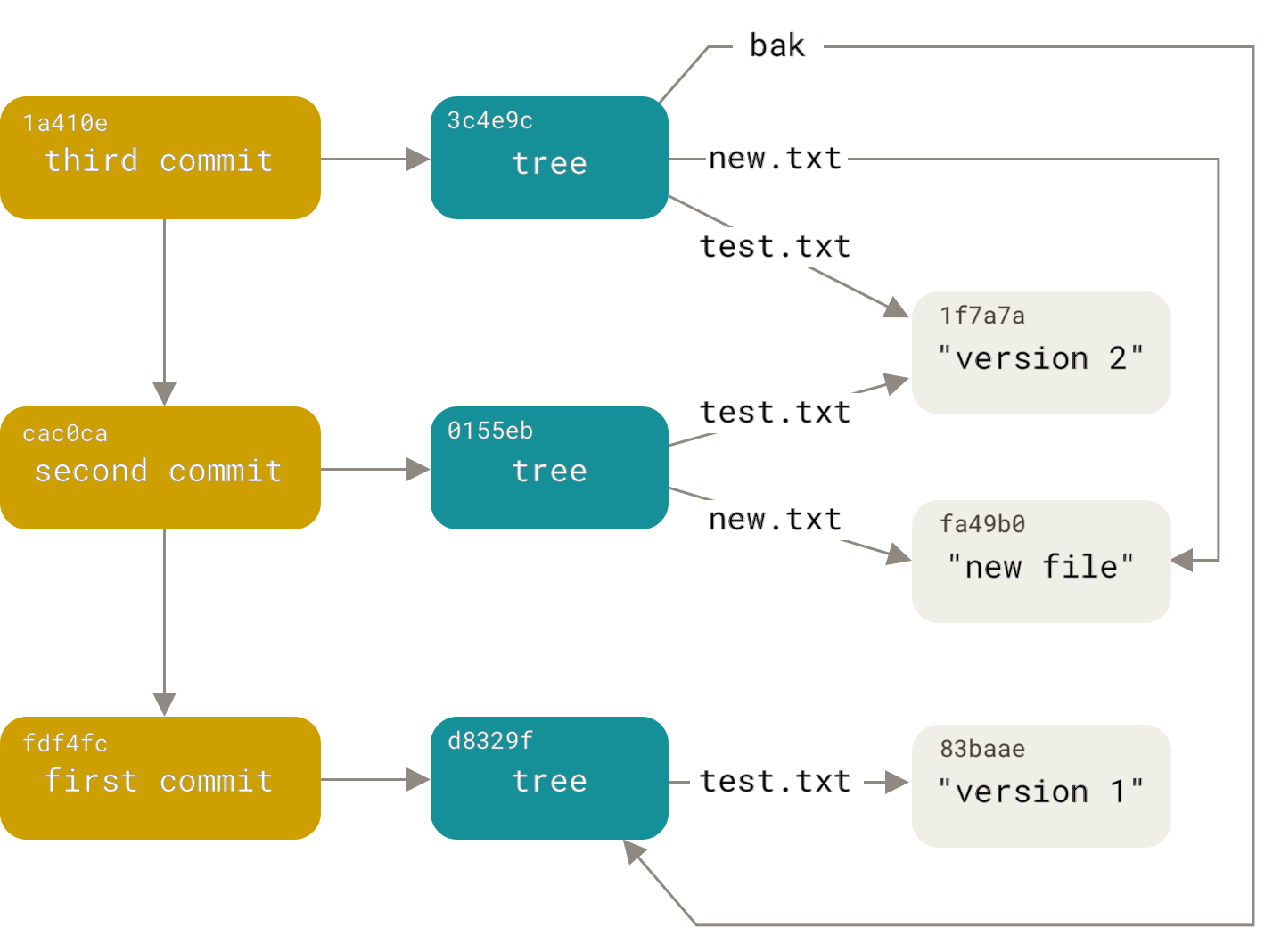
~/git/test (master *+)$ echo 'first commit' | git commit-tree d8329fc
79f6bdef16b32cef42b1bde8973f07329b2398b1
- You will get a different hash value because of different creation time and author data.
~/git/test (master *+)$ git cat-file -p 79f6bdef16b32cef42b1bde8973f07329b2398b1
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author octave <octave@klook.com> 1510198028 +0800
committer octave <octave@klook.com> 1510198028 +0800
first commit
- The format for a commit object is simple: it specifies the top-level tree for the snapshot of the project at that point; the author/committer information (which uses your user.name and user.email configuration settings and a timestamp); a blank line, and then the commit message.
~/git/test (master *+)$ echo 'second commit' | git commit-tree 0155eb -p 79f6bdef16b32cef42b1bde8973f07329b2398b1
414b938a2b89933461ffab680bd22f6d8dd0d9ca
~/git/test (master *+)$ echo 'third commit' | git commit-tree 3c2b28 -p 414b938a2b89933461ffab680bd22f6d8dd0d9ca
845d6be1d937b48500230ca61981f686696273d8
- Each of the three commit objects points to one of the three snapshot trees you created.
~/git/test (master *+)$ git log --stat 845d6be1d937b48500230ca61981f686696273d8
commit 845d6be1d937b48500230ca61981f686696273d8
Author: octave <octave@klook.com>
Date: Thu Nov 9 11:31:00 2017 +0800
third commit
whatever-you-name-it/test.txt | 1 +
1 file changed, 1 insertion(+)
commit 414b938a2b89933461ffab680bd22f6d8dd0d9ca
Author: octave <octave@klook.com>
Date: Thu Nov 9 11:30:07 2017 +0800
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit 79f6bdef16b32cef42b1bde8973f07329b2398b1
Author: octave <octave@klook.com>
Date: Thu Nov 9 11:27:08 2017 +0800
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
- Amazing. You’ve just done the low-level operations to build up a Git history without using any of the front end commands. This is essentially what Git does when you run the git add and git commit commands — it stores blobs for the files that have changed, updates the index, writes out trees, and writes commit objects that reference the top-level trees and the commits that came immediately before them.
.git/objects/
├── 01
│ └── 55eb4229851634a0f03eb265b69f5a2d56f341
├── 1f
│ └── 7a7a472abf3dd9643fd615f6da379c4acb3e3a
├── 3c
│ └── 2b28b833b0951d4ea54f94bcc7b21b934ab640
├── 41
│ └── 4b938a2b89933461ffab680bd22f6d8dd0d9ca
├── 79
│ └── f6bdef16b32cef42b1bde8973f07329b2398b1
├── 83
│ └── baae61804e65cc73a7201a7252750c76066a30
├── 84
│ └── 5d6be1d937b48500230ca61981f686696273d8
├── d6
│ └── 70460b4b4aece5915caf5c68d12f560a9fe3e4
├── d8
│ └── 329fc1cc938780ffdd9f94e0d364e0ea74f579
├── fa
│ └── 49b077972391ad58037050f2a75f74e3671e92
├── info
└── pack
12 directories, 10 files
-
commit
- def: Stores the current contents of the index in a new commit along with a log message from the user describing the changes.
- Git stores a commit object that contains a pointer to the snapshot of the content you staged. This object also contains the author’s name and email, the message that you typed, and pointers to the commit or commits that directly came before this commit (its parent or parents):
- When you commit in Git, Git stores a commit object that contains a pointer to the snapshot of the content you staged, the author and message metadata, and zero or more pointers to the commit or commits that were the direct parents of this commit: zero parents for the first commit, one parent for a normal commit, and multiple parents for a commit that results from a merge of two or more branches.
- The action of storing a new snapshot of the project’s state in the Git history, by creating a new commit representing the current state of the index and advancing HEAD to point at the new commit.
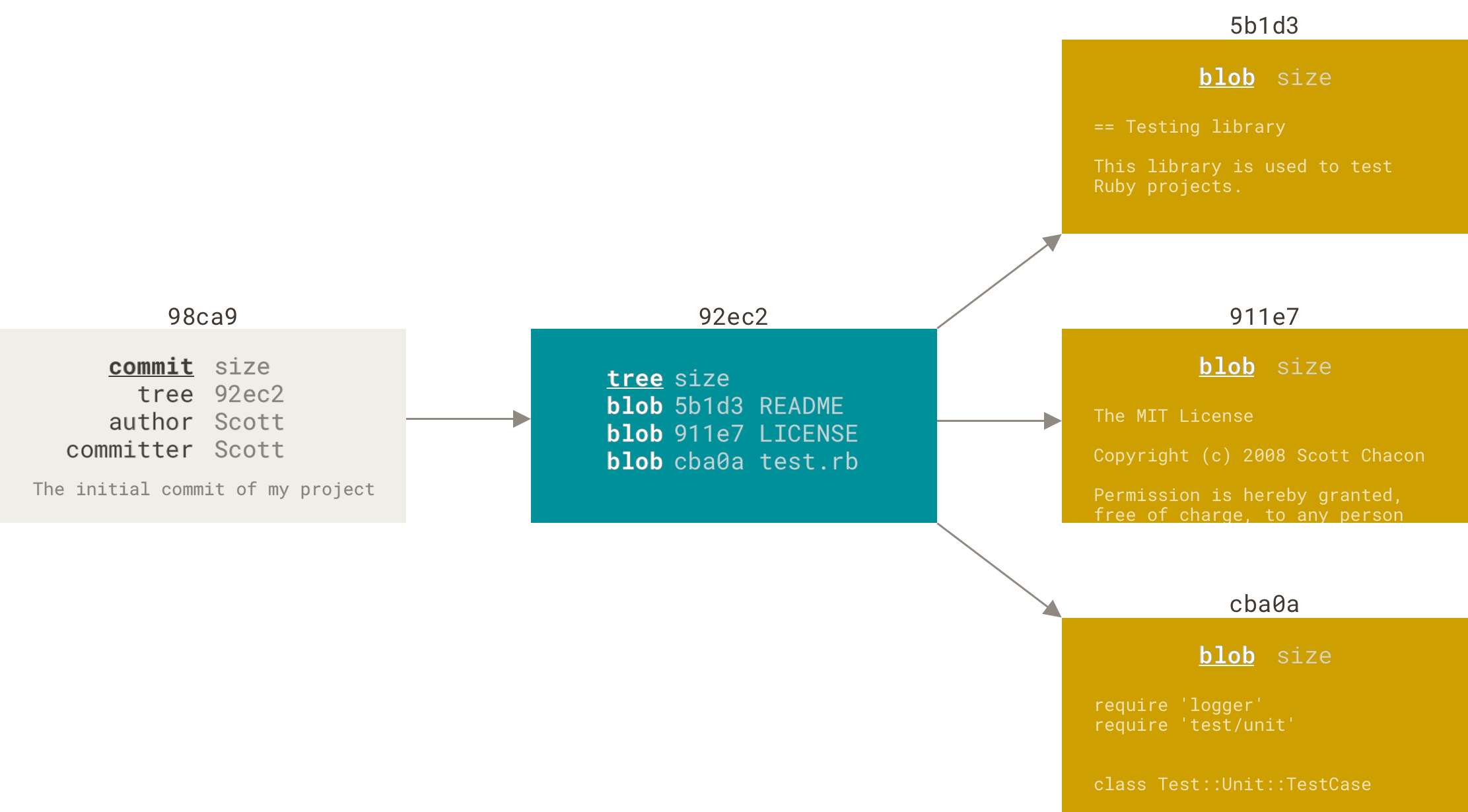
Git doesn’t store data as a series of changesets or deltas, but instead as a series of snapshots.
- The Git directory is where Git stores the metadata and object database for your project. This is the most important part of Git, and it is what is copied when you clone a repository from another computer.
- ./objects
- The objects directory stores all the content for your database,
- ./refs
- the refs directory stores pointers into commit objects in that data (branches, tags, remotes and more),
- You can run something like git log 1a410e to look through your whole history, but you still have to remember that 1a410e is the last commit in order to walk that history to find all those objects. You need a file in which you can store the SHA-1 value under a simple name so you can use that pointer rather than the raw SHA-1 value.
- In Git, these are called “references” or “refs;”
- ./HEAD
- the HEAD file points to the branch you currently have checked out,
- A named reference to the commit at the tip of a branch.
- ./index
- the index file is where Git stores your staging area information
- A collection of files with stat information, whose contents are stored as objects. The index is a stored version of your working tree https://stackoverflow.com/questions/4084921/what-does-the-git-index-contain-exactly/4086986#4086986
- ./objects

-
HEAD
- The HEAD in Git is the pointer to the current branch reference, which is in turn a pointer to the last commit you made or the last commit that was checked out into your working directory. That also means it will be the parent of the next commit you do. It's generally simplest to think of it as HEAD is the snapshot of your last commit.

-
INDEX
- index: The "index" holds a snapshot of the content of the working tree, and it is this snapshot that is taken as the contents of the next commit. Thus after making any changes to the working tree, and before running the commit command, you must use the add command to add any new or modified files to the index.it's simplest to think of it as the Index is the snapshot of your next commit.
~/git/test (master *+)$ git ls-files --stage 100644 fa49b077972391ad58037050f2a75f74e3671e92 0 new.txt 100644 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a 0 test.txt 100644 83baae61804e65cc73a7201a7252750c76066a30 0 whatever-you-name-it/test.txt
-
WORKING DIR
- Finally, you have your working directory. This is where the content of files are placed into actual files on your filesystem so they're easily edited by you. The Working Directory is your scratch space, used to easily modify file content.
~/git/test (master *+)$ tree . . ├── new.txt └── test.txt 0 directories, 2 files
- workflow: So, Git is all about recording snapshots of your project in successively better states by manipulating these three trees, or collections of contents of files


you can use reset to update part of the Index or the Working Directory with previously committed content this way.
- an example of reset
https://git-scm.com/blog/2011/07/11/reset.html // this could be used as a comprehensive example.

-
file
-
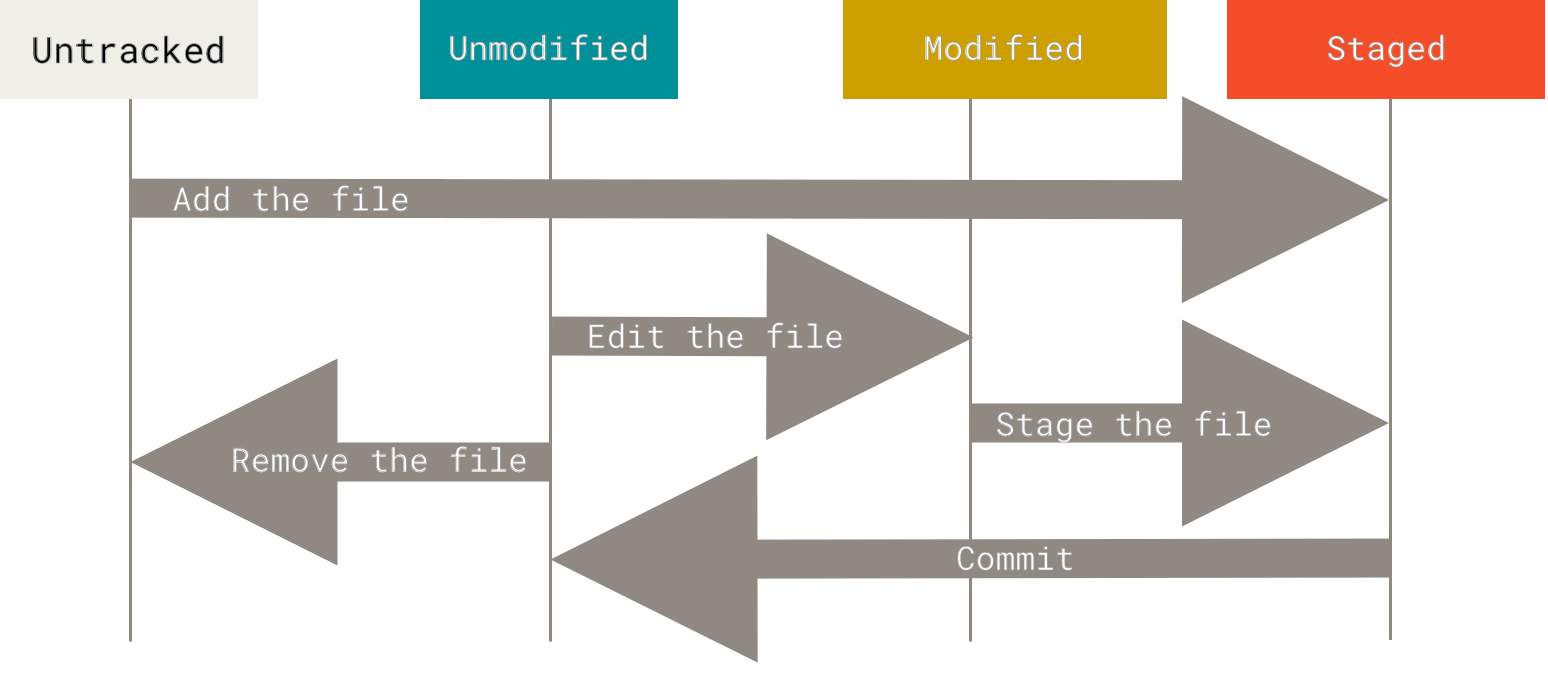
The lifecycle of the status of your files.
-
-
diff
-
add
- In order to begin tracking a new file, you use the command git add.
- Defination: This command updates the index using the current content found in the working tree, to prepare the content staged for the next commit.
-
status
- defi: Displays paths that have differences between the index file and the current HEAD commit, paths that have differences between the working tree and the index file, and paths in the working tree that are not tracked by Git
-
branch
- what defines a branch, where stored?
- A branch in Git is simply a lightweight movable pointer to one of these commits.
- Because a branch in Git is actually a simple file that contains the 40 character SHA-1 checksum of the commit it points to
- What happens if you create a new branch? Well, doing so creates a new pointer for you to move around. Let’s say you create a new branch called testing. You do this with the git branch command: show an example https://git-scm.com/book/en/v1/Git-Branching-What-a-Branch-Is
-
checkout
- def: Updates files in the working tree to match the version in the index or the specified tree.
- This moves HEAD to point to the testing branch

-
remote branch, track
git push -u- origin/master is local
-
merge
-
Join two or more development histories together
-
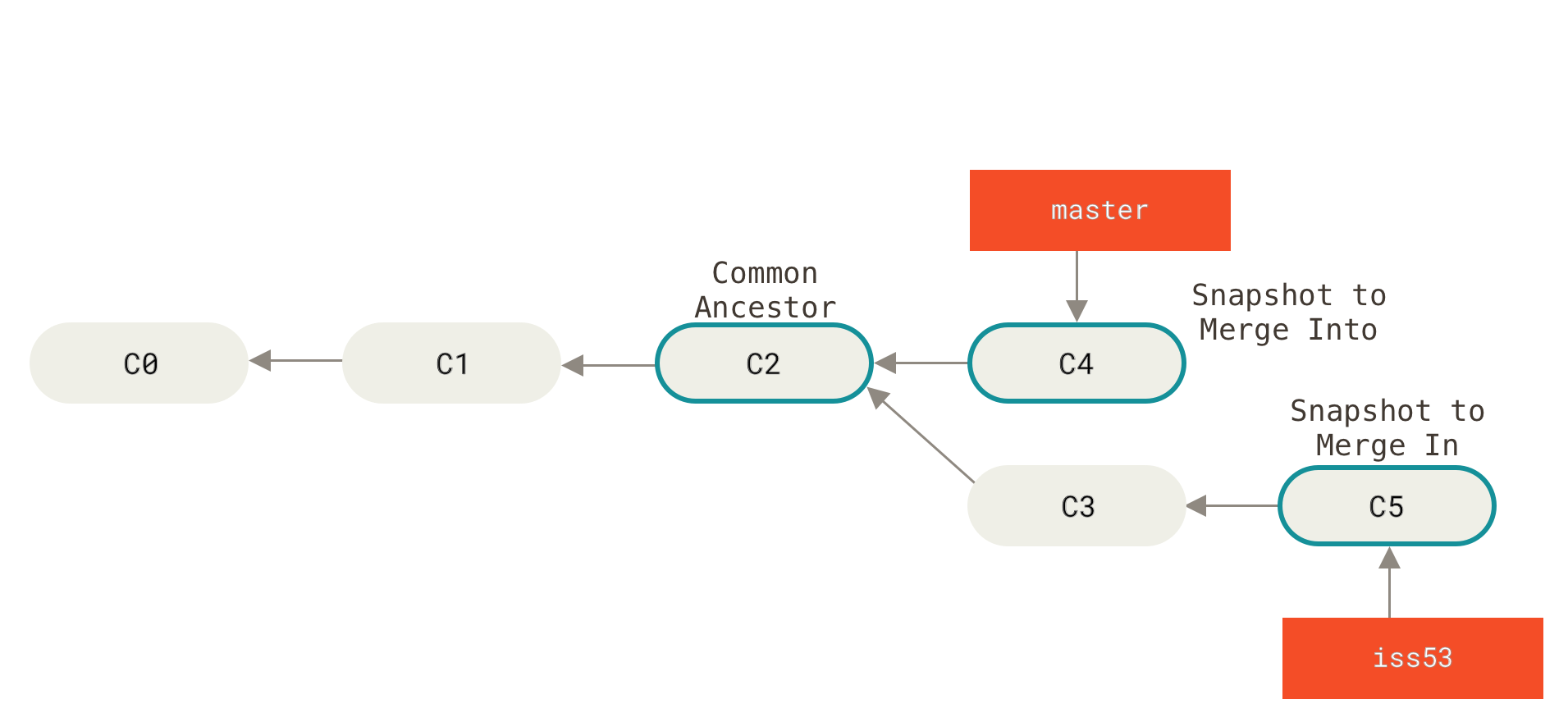
Incorporates changes from the named commits (since the time their histories diverged from the current branch) into the current branch. This command is used by git pull to incorporate changes from another repository and can be used by hand to merge changes from one branch into another.
A---B---C topic / D---E---F---G master -
Then "git merge topic" will replay the changes made on the topic branch since it diverged from master (i.e., E) until its current commit (C) on top of master, and record the result in a new commit along with the names of the two parent commits and a log message from the user describing the changes.
A---B---C topic / \ D---E---F---G---H master
-
-
rebase
-
Reapply commits on top of another base tip
-
All changes made by commits in the current branch but that are not in are saved to a temporary area.
A---B---C topic / D---E---F---G master -
The commits that were previously saved into the temporary area are then reapplied to the current branch, one by one, in order. to:
A'--B'--C' topic / D---E---F---G master -
can also be used as local cleanup
-
need
git push --force. be careful!
-
-
merge vs rebase
- Both of these commands are designed to integrate changes from one branch into another branch—they just do it in very different ways.
- On the other hand, this also means that the feature branch will have an extraneous merge commit every time you need to incorporate upstream changes. If master is very active, this can pollute your feature branch’s history quite a bit. While it’s possible to mitigate this issue with advanced git log options, it can make it hard for other developers to understand the history of the project.
- The major benefit of rebasing is that you get a much cleaner project history.
- First, it eliminates the unnecessary merge commits required by git merge.
- Second, as you can see in the above diagram, rebasing also results in a perfectly linear project history—you can follow the tip of feature all the way to the beginning of the project without any forks.
- golden rule: The golden rule of git rebase is to never use it on public branches.
-
git-cherry-pick
- Apply the changes introduced by some existing commits
- In SCM jargon, "cherry pick" means to choose a subset of changes out of a series of changes (typically commits) and record them as a new series of changes on top of a different codebase. In Git, this is performed by the "git cherry-pick" command to extract the change introduced by an existing commit and to record it based on the tip of the current branch as a new commit.
-
commit --amend
- recover from a bad amend https://stackoverflow.com/questions/38001038/how-to-undo-a-git-commit-amend
-
detached HEAD
- Normally the HEAD stores the name of a branch, and commands that operate on the history HEAD represents operate on the history leading to the tip of the branch the HEAD points at. However, Git also allows you to check out an arbitrary commit that isn’t necessarily the tip of any particular branch. The HEAD in such a state is called "detached".
-
reflog
- def: Reference logs, or "reflogs", record when the tips of branches and other references were updated in the local repository.
- A reflog shows the local "history" of a ref.
-
worktree
- def: Manage multiple working trees attached to the same repository. A git repository can support multiple working trees, allowing you to check out more than one branch at a time.
- The working tree is a single checkout of one version of the project. These files are pulled out of the compressed database in the Git directory and placed on disk for you to use or modify
-
know your status.(where am I? what am I doing? where do I go?)
-
know from where to where
-
don't just listen to git status
- rebase: don't pull again
-
do check git log
-
reflog
-
stackoverflow
-
dos:
- know more about git
- branching
- The way Git branches is incredibly lightweight, making branching operations nearly instantaneous, and switching back and forth between branches generally just as fast.
- prettify
- make alias
- git_prompt
- worktree
- git status often
- promoting: tagging
- git stash
- backup branch
- use a workflow
- keep up to date, find conflicts earlier
- keep the reflog
- commit
- compact your commits before deploy/push
- commit often
- write good commit message
- git diff before commit
- good branch naming
-
don'ts
- don't
git reset --hard, - don't clean file.
git checkout -- <file> / git clean -f - don't specify remote branch every time
- don't rewrite public history
- don't keep life-time branch.
- use
git fetchrather thangit pull# because git pull will do merge, but we want rebase.
- don't
https://sethrobertson.github.io/GitBestPractices/
