I choose Golang to implement the API for two reasons. First, this is a challenge, it will be boring if I keep using my old stack. Second, Golang makes writing a concurrent program easily which is what the requirements ask for.
1. The API must be able to handle high throughput (~1k requests per second).
2. The API should also be able to recover and restart if it unexpectedly crashes.
3. Assume that the API will be running on a small machine with 1 CPU and 512MB of RAM.
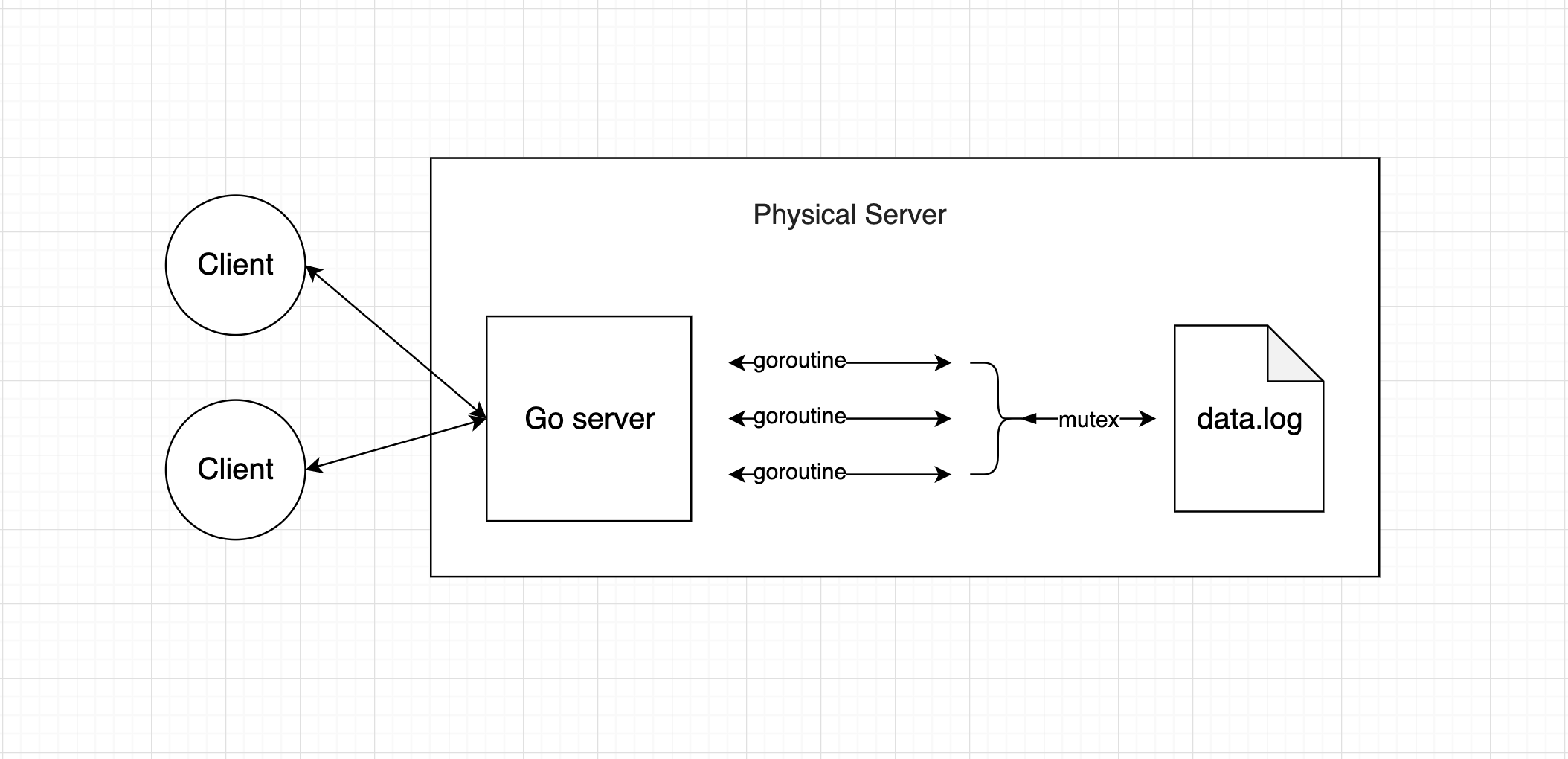
For No.1 and No.3, we need to use 1 CPU and 512MB of RAM to handle ~1k requests per second. Therefore, asynchronous I/O would be the best choice. Golang has goroutine which is a perfect fit for this situation. To support restart, we can use Supervisord to monitor the current Go web server, I didn't implement this part because it's more related to configuration than system design (I used it before, feel free to ask me questions for it). To support recovery, for instance, when the server is out of power. There are two options to achieve it. Option one will be let the server to maintain the state, in this project would be current and previous fibonacci num in the file system. Since goroutine may lead to a race condition when reading and writing a file. I use a mutex to fix it. The current structure looks like this.
Another option would be to use a FIFO queue like this so we don't have to use mutex since all the tasks will run by the order.
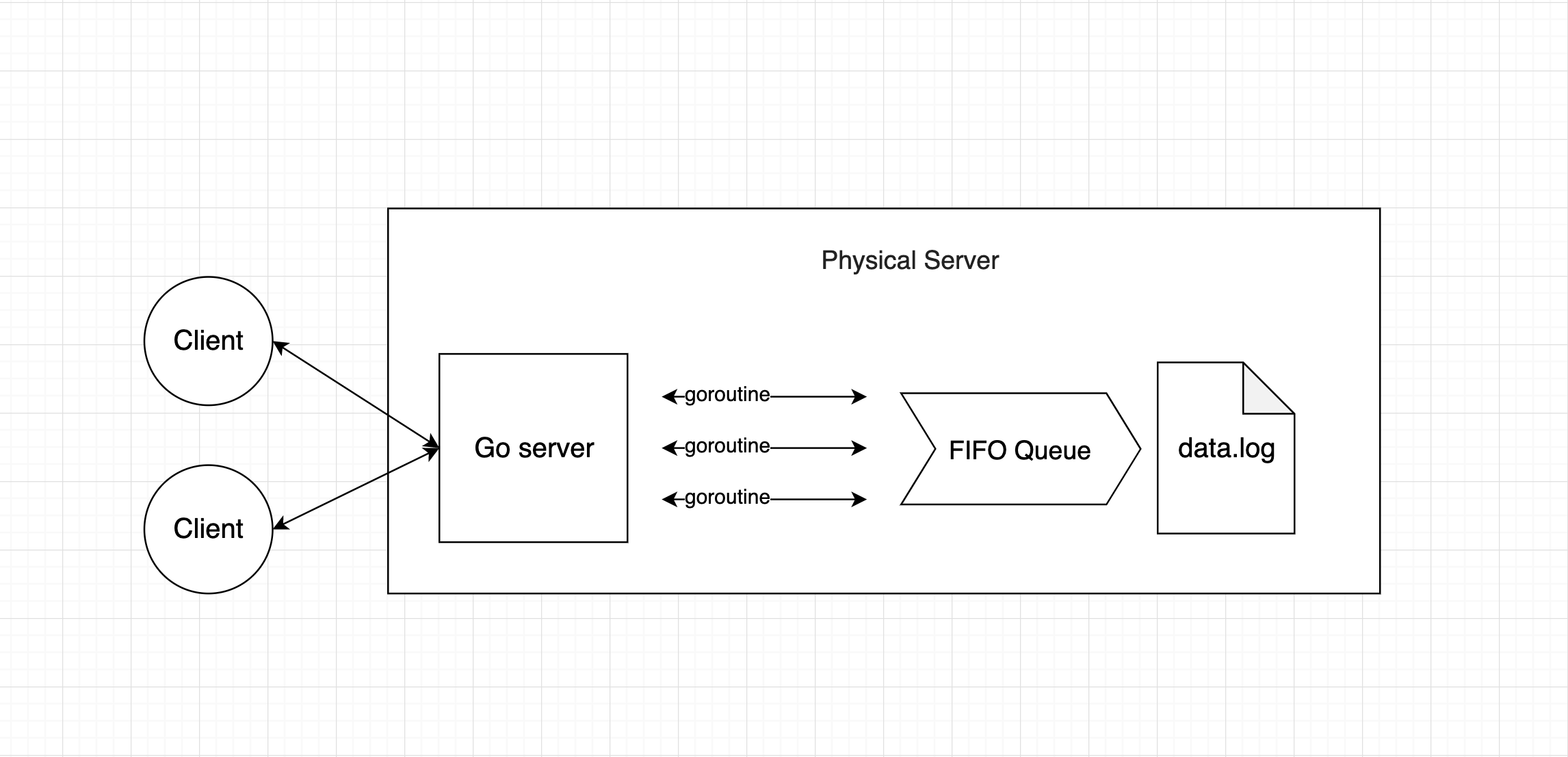
However, since we need to handle high throughput, the queue should be as big as possible, but we will lose all of the tasks once the server unexpectedly crashes which is not acceptable. That is why I choose option one.
- I'm not familiar with Testing in Go, but we should write some tests for this project.
- We can use a faster algorithm to calculate fibonacci sequence like this
I don't think our business model based on this fibonacci sequence API (maybe it's a good idea :D). This challenge can transform into
How to finish CPU-bound tasks in high throughput
Let's say, our challenge ask us to return the fibonacci sequence depeondon the input value like this:
fib(10) -> 55
fib(1) -> 1
The API is independent by each other so Cache would help us a lot here. we can pre-calculated the fibonacci sequence and store them in NoSQL database like Redis. When the user asks for a fibonacci num, we can just return the value from NoSQL without calculation. Looks great, right. But what happens is the user ask for a huge number like:
fib(500000)
It's unrealistic to store all the fib number in NoSQL since it's extremely huge (store fib(1) to fib(500000) can take several Gb of memory). We can use a little trick here. we store only every X of fibonacci sequence in our NoSQL, For instance fib(0), fib(1), fib(10), fib(11), fib(20), fib(21), fib( 30) , fib(31), when we need to return a fibonacci number like fib(25), we can use binary search to find the biggest fibonacci sequence small than 25, in this case fib(20) and fib(21), then calculate fib(25) base on it. we can also adjust the X depend on our requirement. It's a trade-off.
Feel free to correct me if you found a better solution.