- Labelling Scenes
- Robot Navigation
- Self-Driving Cars
- Body Recognition (Microsoft Kinect)
- Disease and Cancer Detection
- Facial Recognition
- Activity Recognition
- Handwriting Recognition
- Sign Language Interpretation
- Identifying objects in satellite images
Image features are interesting areas (such as edges, corners, blobs) somewhat unique to that specific image, also popularly called key point features or interest points. By analysing the image, identifying a set of key points and computer a descriptor vector or feature vector for each key point, we can analyse, describe and match images in the application of image alignment, 3D reconstruction, robot navigation, object recognition, motion tracking and more. Some of the popular feature detection techniques are listed below:
-
SIFT (Scale Invariant Feature Transform) is widely used in computer vision as it very successfully deal with the scale invariance issue. Interesting key points is detect using Difference of Gaussian method. SIFT is patented and no longer included in the OpenCV 3.0+ library by default.
-
SURF (Speeded Up Robust Features) is quite effective by computationally expensive. As name suggests, it is a speeded-up version of SIFT. It uses Hessian matrix approximation to detect interesting points and use sum of Haar wavelet responses for orientation assignment. Like SIFT, SURF is no longer included in the OpenCV 3.0+ library by default.
-
FAST (Features from Accelerated Segment Test) is used in real time application for key point detection ONLY. There is no descriptor and we can use SIFT or SURF to compute that.
-
BRIEF (Binary Robust Independent Elementary Features) is a faster method feature descriptor calculation and matching. BRIEF is a feature descriptor ONLY, it doesn’t provide any method to find the features. So we will have to use any other feature detectors like SIFT, SURF, FAST.
-
ORB (Oriented FAST and Rotated BRIEF) combines both FAST and BRIEF. ORB is included in the OpenCV 3.0+ library by default.
-
HOGs (Histogram of Oriented Gradients) is a feature descriptor that has been widely and successfully used for object detection. It represents objects as A SINGLE feature vector as opposed to a set of feature vectors where each represents a segment of the image. HOGs is computed by sliding window detector over an image, where a HOG descriptor is computed for each position then combined to a single feature vector for representing the image.

Figure 1: A HOG descriptor
HAAR classifier method proposed by Paul Viola and Michael Jones in their paper, "Rapid Object Detection using a Boosted Cascade of Simple Features" in 2001. It is a machine learning based approach where a cascade function is trained from a lot of positive and negative images. It is then used to detect objects in other images. Features are extracted using sliding windows of rectangular blocks. OpenCV already contains many pre-trained classifiers for face, eyes, smiles, etc. Those XML files are stored in the Users\liangx\AppData\Local\Continuum\anaconda3\Lib\site-packages\cv2\data.
-
Also you can find the pre-trained face, body, smile classifiers at Github: https://github.com/opencv/opencv/tree/master/data/haarcascades https://github.com/opencv/opencv/tree/master/data/haarcascades_cuda (cuda version)
-
For pre-trained vehicle detection https://github.com/andrewssobral/vehicle_detection_haarcascades
-
Train your own OpenCV Haar Classifier http://coding-robin.de/2013/07/22/train-your-own-opencv-haar-classifier.html https://github.com/mrnugget/opencv-haar-classifier-training
[1] Ross, Girshick (2014). "Rich feature hierarchies for accurate object detection and semantic segmentation" . Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE. https://arxiv.org/abs/1311.2524
[2] Girschick, Ross (2015). "Fast R-CNN" . Proceedings of the IEEE International Conference on Computer Vision: 1440–1448. https://arxiv.org/abs/1504.08083
[3] Shaoqing, Ren, Kaiming He, Ross Girshick, and Jian Sun (2015). "Faster R-CNN" . “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, https://arxiv.org/pdf/1506.01497.pdf
[4] Liu, Wei (October 2016). “SSD: Single shot multibox detector”. European Conference on Computer Vision. Lecture Notes in Computer Science. 9905. pp. 21–37. https://arxiv.org/abs/1512.02325
YOLOv3 is extremely fast and accurate for real time object detection. More YOLO publications, Darknet, comparison to other object detectors can be found at:
https://pjreddie.com/darknet/yolo/
[5] Redmon, Joseph (2016). "You only look once: Unified, real-time object detection". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[6] Redmon, Joseph (2017). "YOLO9000: better, faster, stronger".
[7] Redmon, Joseph (2018). "Yolov3: An incremental improvement".
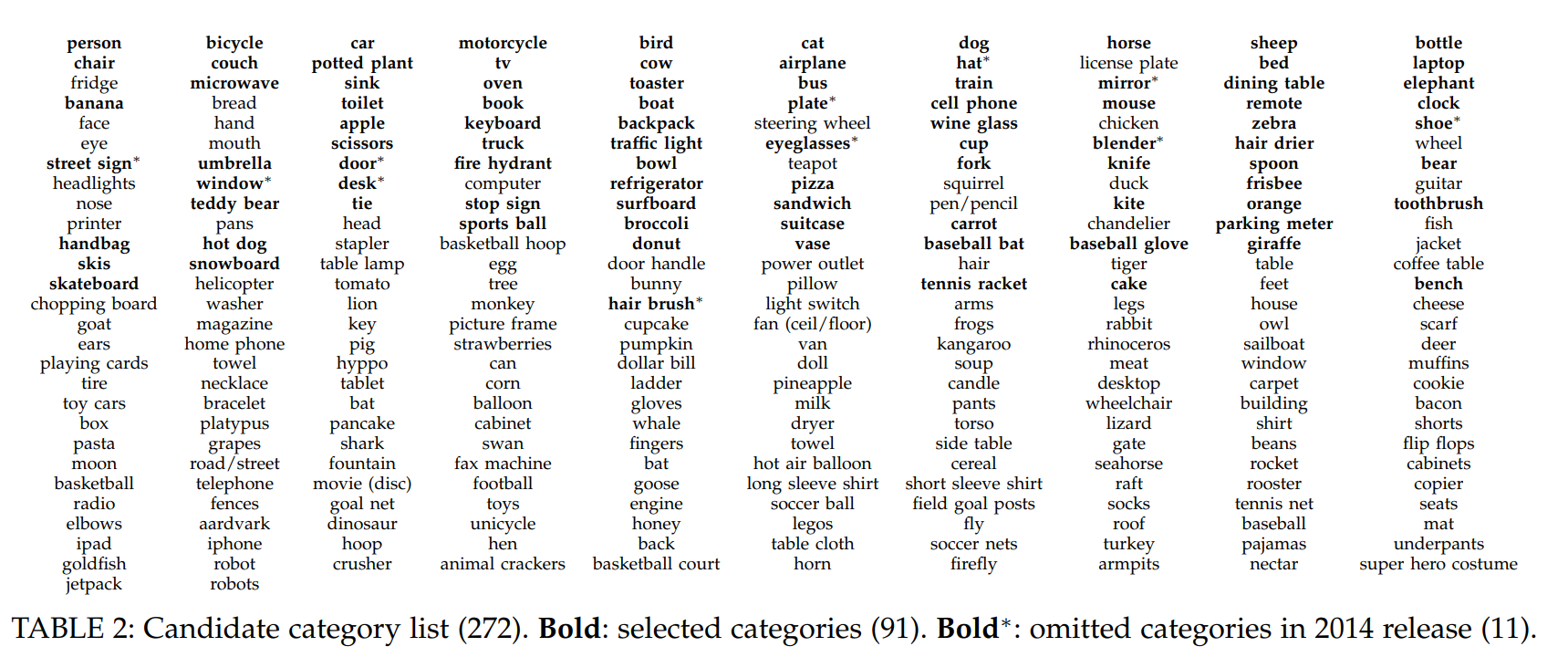
Tensorflow object detection API, which is pre-trained by Google, is a very good open source to be able to detect up to 91 categories of objects. It was trained on COCO data set (https://arxiv.org/pdf/1405.0312.pdf) and some other data sets. Please see table below for selected pre-trained candidates (which is bold in list). Fortunately, for those objects were not selected and not pre-trained in the API, there is possible way to re-train the detector API for the specific object detection. An example of re-train Tensorflow object detection API for hand detection: https://jkjung-avt.github.io/hand-detection-tutorial/
- For more information on model zoo, please read: https://modelzoo.co/model/objectdetection
- Tensorflow detection model zoo on Github: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
The ImageNet project is a large visual database designed for use in visual object recognition software research. The ImageNet project runs an annual software contest, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), where software pr ograms compete to correctly classify and detect objects and scenes. Here are the CNN architectures of ILSVRC top competitors, which are available in Keras with pre-trained models and weights. https://keras.io/applications/
Models for image classification with weights trained on ImageNet:
- Xception
- VGG16
- VGG19
- ResNet, ResNetV2, ResNeXt
- InceptionV3
- InceptionResNetV2
- MobileNet
- MobileNetV2
- DenseNet
- NASNet

- AlexNet (not in Keras applications): Top1 Accuracy: 57.1, Top5 Accuracy: 80.2, Parameters: 60 million, Depth: 7, Year: 2012
-
MS COCO (Common Objects in COntext)
COCO is a large-scale object detection, segmentation, and captioning dataset containing over 200,000 labeled images. It can be used for object segmentation, recognition in context, and many other use cases. http://cocodataset.org/#home -
ImageNet
ImageNet has a dictionary called WordNet, which has tens of thousands of object classes. http://www.image-net.org/ -
Pascal types of data sets
http://host.robots.ox.ac.uk/pascal/VOC/ -
CIFAR-10 dataset
The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. https://www.cs.toronto.edu/~kriz/cifar.html -
LVIS - A new dataset for long tail object recognition
LVIS is a new, large-scale instance segmentation dataset that features > 1000 object categories, many of which have very few training examples. LVIS presents a novel low-shot object detection challenge to encourage new research in object detection.
https://www.lvisdataset.org/ -
ImageNet-21K
ImageNet-1K serves as the primary dataset for pretraining deep learning models for computer vision tasks. ImageNet-21K dataset, which contains more pictures and classes, is used less frequently for pretraining, mainly due to its complexity, and underestimation of its added value compared to standard ImageNet-1K pretraining.
Paper - ImageNet-21K Pretraining for the Masses: https://arxiv.org/pdf/2104.10972.pdf
https://github.com/Alibaba-MIIL/ImageNet21K
https://github.com/Alibaba-MIIL/ImageNet21K/blob/main/dataset_preprocessing/processing_instructions.md