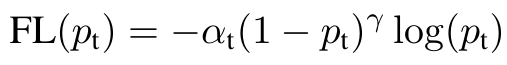
- α:为了解决 Class Imbalance 问题而引入,对于样本数过多的那一类样本,α 应设得较低,这样就降低了该类样本对于 Loss 的重要性 (alpha 越大,就是对正类的损失惩罚越大,这样的话,文章中 alpha = 0.25,所以是正类惩罚少,负类惩罚多)
- γ:为了降低易分样本的权重,专注于训练难分负样本而引入,(1 - Pt)∈(0,1),当样本易分类时,(1 - Pt)很小,(1 - Pt)^γ 会变得更小,这样就减少了简单易分类样本的重要性,相对增加了那些误分类样本的重要性
"""
sparse_label : bool, default True
Whether label is an integer array instead of probability distribution.
"""
self._sparse_label = sparse_label- 默认值是 True,就是我们常用的 Label 样式,如果是二分类,那么里面每一个元素都是 0 或 1
if sparse_label and (not isinstance(num_class, int) or (num_class < 1)):
raise ValueError("Number of class > 0 must be provided if sparse label is used.")- 这表明,如果要
sparse_label为 True,必须要指定num_class,对于 Sigmoid 的输出,照理说num_class肯定等于 1 才对?
if self._sparse_label:
one_hot = F.one_hot(label, self._num_class)
else:
one_hot = label > 0- 但是在我们二分类的情形里面,希望 one_hot 是同 label 一样大小尺寸的矩阵,或者在 label 就是 one_hot,因此需要
self._sparse_label是 False
if not self._from_logits:
pred = F.sigmoid(pred)- 从这里可以看到,Focal Loss 期待的输入是 sigmoid 的输出,注意不是 Softmax
pt = F.where(one_hot, pred, 1 - pred)- 从上面看出,
one_hot是一个指示器,如果真实的 label 是 1,那么就用 pred(这边 pred 是对正类的预测概率),如果真实的 label 是 0,那么就用 1 - pred
alpha = F.where(one_hot, self._alpha * t, (1 - self._alpha) * t)- 可以看到正类的前的权重是 alpha,是 0.25;负类的是 1 - alpha,是 0.75
如果
pred 应该为 N x 1 x H x W 或者 N x H x W,
假设我是 二分类的 Softmax output,那么 pred 就是一个 N x 2 x H x W 的张量。
if not self._from_logits:
pred = F.sigmoid(pred)经过上面代码后,因为 Sigmoid 是对自己的 prediction score,相当于 pred 里面是各自 prediction score 的概率
if self._sparse_label:
one_hot = F.one_hot(label, self._num_class)
else:
one_hot = label > 0label 是一个 N x H x W 的张量,经过 F.one_hot 后得到的 one_hot 是一个 N x H x W x 2 的矩阵,这个形状与 N x 2 x H x W 的 pred 的形状是不同的。如果要想把 one_hot 变成一个 N x 2 x H x W 的张量,则要添加下面代码
one_hot = one_hot.swapaxes(1,3)假设是第一个样本的最左上角的像素标签是 0,也就是 label[0, 0, 0] = 0,那么经过 F.one_hot 我们就可以得到 one_hot[0, 0, 0, 0] = 1, one_hot[0, 1, 0, 0] = 0]
pt = F.where(one_hot, pred, 1 - pred)对于 label[0, 0, 0] 这个位置,pt[0,0,0,0] 照理说应该为背景的概率,但是 where 函数返回的是 前景的概率,
pt[0,1,0,0] 照理说应该为前景的概率,但是 where 函数返回的是 背景的概率,
不对不对,就不应该用 softmax