CVPRW 2018, Oral @ MBCC Workshop
最后一个作者 John K. Tsotsos 的个人主页值得探索一下。
Priming, 中文叫作 "启动", 是一个蛮复杂的概念. 在这篇论文中, 作者认为 visual priming 就是 an effect of top-down signaling in the visual system triggered by the said cue, 我们就按照本文的定义来理解, 不去管什么内隐记忆.
首先, cue 是与 label 不同的存在, cue 是在训练 label 之外额外的信息. label 只有在 training 阶段才有, 在 test 阶段则是没有的; 而 cue 则是在所有阶段都是有的. 事实上, cue 其实是一类 top-down signal, 是来源于 external (exogenous) stimuli 的 top-down signal. 除了 cue 之外, top-down signal 也可以来自于 internal (endogenous) processes of reasoning.
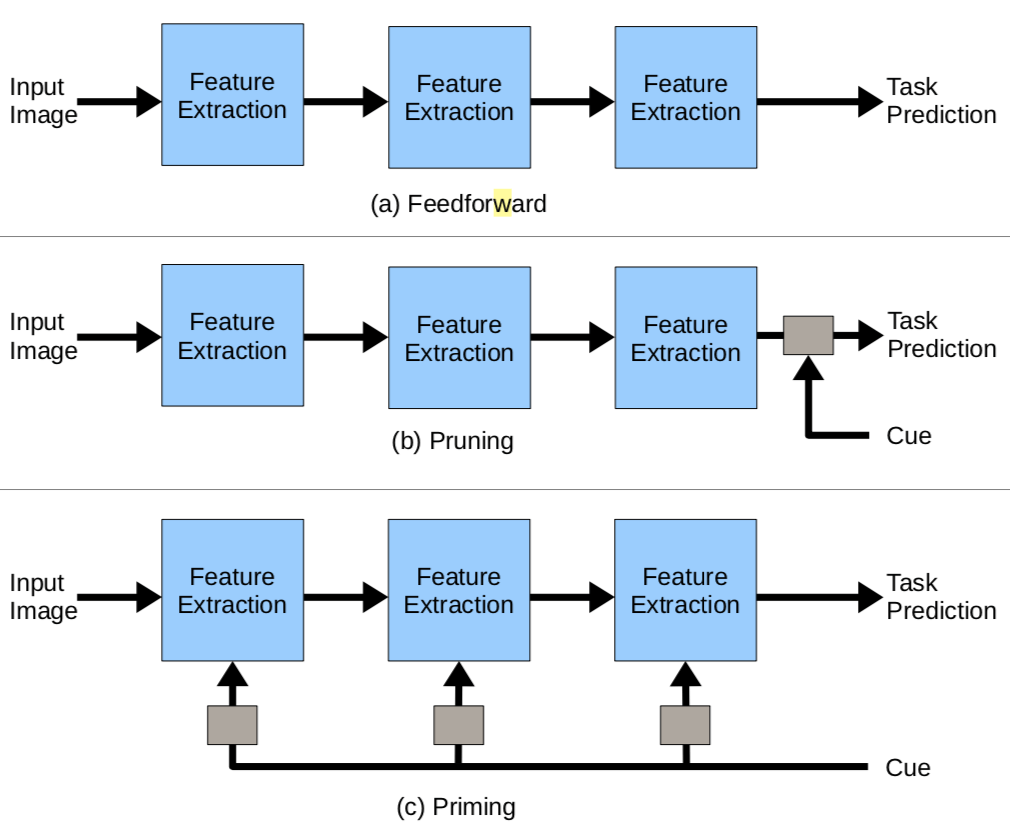
关于如何使用 cue, 有三种策略, 分别是 free viewing, pruning 和 priming:
- free viewing: 不被告知 cue, freely viewing the image, the default strategy, 如果用这种方式, 下图能看到的就是 a dry grassy field near a house 而已
- pruning: a modification to the decision process after all the computation is finished. When the task is to detect objects, this can mean retaining all detections match the cue, even very low confi- dence ones and discarding all others.
- priming: allows the cue to affect the visual process from early layers, 如果提前告诉你找一只猫, 那么就简单很多了, 如下图所示

pruning 和 priming 都是 viable ways to incorporate the knowledge brought on by the cue
- free viewing 的缺点: Viewing the image for an unlimited amount of time
- pruning 的缺点: pruning the results is less effective
- priming 的优点: allowing detection where it was previously unlikely to occur in free-viewing conditions.
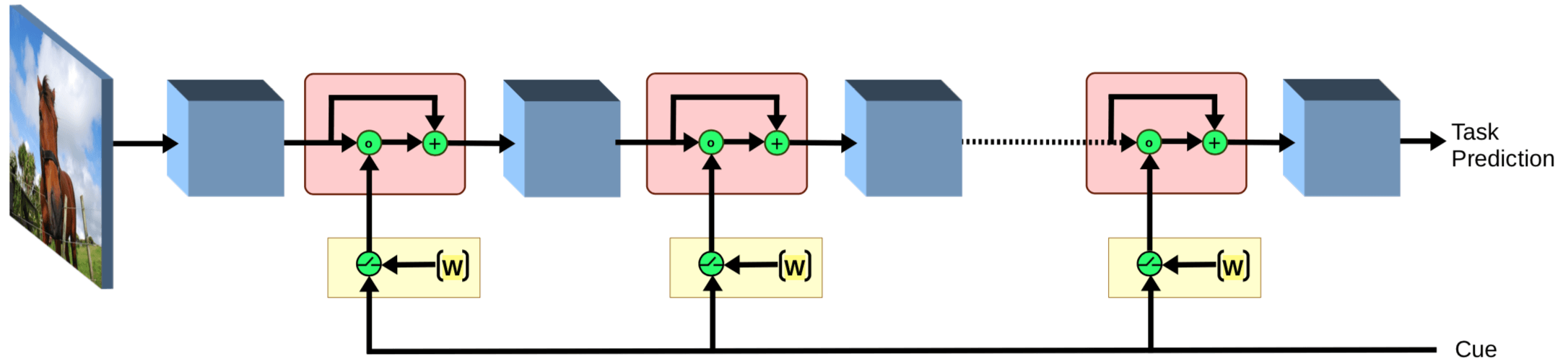
本文叫作 Priming Neural Networks,意图提出 a mechanism to mimic the process of priming,所以本文其实本质上也是一个试图模拟 Top-Down 的 Attention 方法,就像 DES。事实上 Priming / Top-down Attention 是 a modulatory, cue dependent effect on layers of features within a network, 模型方法如下所示:

与 DES 不同的是:
- 这里的 top-down feedback 是影响每一个 layer 的
- DES 里面的 cue 是通过 Weakly Supervised Semantic Segmentation 完成的,而本文好像是给定的 cue 表达;
- DES 是生成一个 Pixel-wise weight map,而 PrimingNN 是 Channel-wise 的 weight vector
cue 与 label 的不同:
- cue 是在训练 label 之外额外的信息
- label 只有在训练阶段 available, 而 cue 是在训练和测试阶段都 available
- 举个例子, 在语义分割 (多类) 中, label 就是训练集的 mask 标记, 而 cue 可以是在这张图像中是否包含特定类, 因此在给定 cue 后, 语义分割任务就被简化成在图像中分割出指定的一定包含的类别, 例子就是下图, 如果不告诉你里面有只猫, 很难发现猫, 告诉了, 努力找一下是能找到的.
- 因为 cue 是在我做预测之前就知道的, 所以如果利用上 cue 就是 top-down 的
本文这里强调的作用是:对于人眼,在知道了 cue 之后可以发现之前 near unnoticeable 的目标;对于计算模型,可以帮助发现纯粹 Bottom-Up 会忽略的小目标,(关键在于给定 cue)
从下图中可以看出,Priming 的一大好处是可以发现许多 small Object,如果不做 priming,这些 small Object 是会被 baseline 给忽略掉的;从左到右分别是input image, ground-truth, baseline segmentation(DeepLab), primed network. 在知道了 cue 后, 能够发现 small object, 这个道理其实是显然的, 关键在于怎么拿到 cue 信息?

本文给出的 Priming 框架是这样的,感觉这里的 Priming 基本就等于 Top-Down Attention 了。是的,按照文章的说法, 也就是说,Visual Priming 就是一个在给定 cue 之后的 Top-down signaling。
- A cue about some target in the image is given by and external source or some form of feedback.
- The process of priming involves affecting each layer of computation of the network by modulating representations along the path.
cue 是 top-down signaling 的来源,首先第一步是怎么刻画 cue?在这里,cue 是给定的,比如 a binary encoding of them presence of some target(s) (e.g, objects),注意的是,cue 是在 label 之外的信息。这里作者似乎是直接给的,而 DES 里那样是从弱监督语义分割来的。弱监督还是利用的 label 的信息,并没有信息的增益,顶多是相对于 Object Detection 分支,语义分割也许会弥补上一些 Object Detection 分支疏漏的信息。
不过直接给 label 之外的 cue,对于很多场景还是比较难实现的。
需要有一个 mechanism 来 transforms an external cue about the presence of a certain class in an image (e.g., “person”) to a modulatory signal that affects all layers of the network.
具体这个 mechanism 的实现方式,本文是在原先网络的基础上,增加了一个 add a parallel branch
Top-down feedback 在本文中的表现就是对 neural network layers 的调制,特别是对低层的 layers 的, 具体如下图所示
作者认为之前 Priming 的工作没有研究 the explicit role of category cues to prime the visual hierarchy for object detection and segmentation,也就是没有给出具体的调制方式?但 Shrivastava2016ContextualPA 这篇文章是 16 年的,在本文之前啊,作者说 Shrivastava2016ContextualPA 是 append directly the semantic segmentation predictions to the visual hierarchy,回去看了下论文,的确是 append 的方式,而本文是 Residual Multiplication。
$$ \hat{x}{i j}=\alpha{i j} \cdot x_{i j}+x_{i j} $$
上面这个 Attention 方式跟 BAM: Bottleneck Attention Module 这篇论文里的方式是一样的,看来用 Residual Formulation + an additive model 这种是共识了,论文里也说了试过很多方式,还是这种效果最好。
本文中的
作者说有 3 种 detection strategies:
- free viewing:没有 cue 的情况下
- priming:a modification to the computation performed when viewing the scene with the cue in mind(注意,这是在计算阶段)priming often highly increases the chance of detecting the cued object.
- pruning:a modification to the decision process after all the computation is finished(注意,这是在决策阶段)When the task is to detect objects, this can mean retaining all detections match the cue, even very low confidence ones and discarding all others.
我感觉现在主流的方法就是走得这个路线:Viewing the image for an unlimited amount of time and pruning the results is less effective,这里的 pruning 可以是 NMS 这种操作
priming 和 pruning 的差别在于,pruning 只是对于 forward 的 decision 做删减,而 priming 则是 allows the cue to affect the visual process from early layers,就是因为调制了 early layers,所以 priming 才可以 allowing detection where it was previously unlikely to occur in free-viewing conditions。
Priming 这个概念在各篇论文中的运用情况:
- 在 Priming Neural Networks 中, 对 Priming 的诠释是 said cue 作为 top-down signal 影响 feature Extraction, top-down signal 的来源就是 said cue, 是在 label 之外准确的信息, 影响的方式是与 feature map 相乘
- 在 Contextual Priming and Feedback for Faster R-CNN 中, 对 Priming 的诠释是 top-down signal 影响 feature Extraction, top-down signal 的来源就是 Semantic Segmentation 子任务, 影响方式是 Semantic Segmentation 子任务中的特征通过 L2 Normalization 和 max pooling 后 concat 到 Detection Branch 中去
- 在 Contextual Priming for Object Detection 中, 做的是 Contextual Priming, 对 context 的定义是图像中除了 local neighborhood 之外的所有区域, 是局部区域的补集, Object priming: P (o | v_C ) gives priors for the most likely object categories (o) given context information. 因此, 这篇文章中的 Priming 不是 Top-down signal, 而是整体先于局部的 Priming, Priming 的信息来源就是 context feature, 作用方式就是 P(O |vC) = P(σ |x,o,vC)P(x|o,vC)P(o|vC) 这样的概率相乘
参考素材: