目录
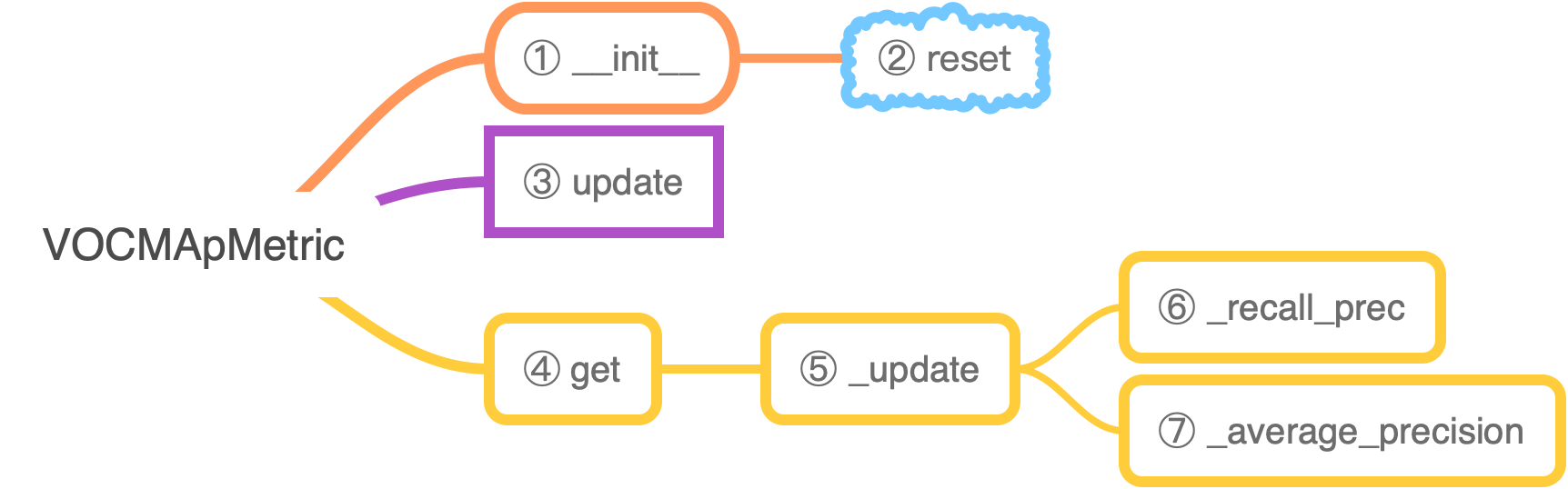
self.sum_metric是一个 List,一共有num_classes + 1个元素,前num_classes个元素都是每一类的 AP,最后一个元素是所有类别 AP 的均值 mAPupdate函数的作用是更新self._n_pos,self._score,self._match_recall_prec函数的作用是根据目前的self._n_pos,self._score,self._match算出目前的rec和precreset函数负责将self._n_pos,self._score,self._match,self.num_inst,self.sum_metric这些状态量归零get函数返回每类类名和 AP,最后是 mAP_update函数调用_recall_prec函数获得recall,precs,然后根据recall,precs通过调用self._average_precision函数算出 ap
1. __init__
def __init__(self, iou_thresh=0.5, class_names=None):
super(VOCMApMetric, self).__init__('VOCMeanAP')
if class_names is None:
self.num = None
else:
assert isinstance(class_names, (list, tuple))
for name in class_names:
assert isinstance(name, str), "must provide names as str"
num = len(class_names)
self.name = list(class_names) + ['mAP']
self.num = num + 1
self.reset()
self.iou_thresh = iou_thresh
self.class_names = class_names- self.class_names 是前景 class 的 list
- self.num 是前景类数再加上 1(这个 1 是 mAP)
- self.name 就是前景类名的 List 再加上 'mAP'
- 还会调用一下 self.reset() 将 self._n_pos, self._score, self._match, self.num_inst, self.sum_metric 这些统计量初始化
2. reset
def reset(self):
"""Clear the internal statistics to initial state."""
if getattr(self, 'num', None) is None:
self.num_inst = 0
self.sum_metric = 0.0
else:
self.num_inst = [0] * self.num
self.sum_metric = [0.0] * self.num
self._n_pos = defaultdict(int)
self._score = defaultdict(list)
self._match = defaultdict(list)reset 函数的作用很简单,就是将self._n_pos, self._score, self._match, self.num_inst, self.sum_metric 这些统计量初始化,那这些统计量具体是干嘛的呢?
self._n_pos是一个字典,里面的每一个 key 都是 类号,而self._n_pos[l]是记录每类 GT Object 的个数,就是 #Trueself._score是一个字典,里面的每一个 key 都是 类号,而self._score[l]是记录所有模型预测成第 l 类的 Valid Prediction 的 score,这个 Array 很长self._match是一个字典,里面的每一个 key 都是 类号,而self._match[l]是记录所有模型预测成第 l 类的 Valid Prediction 的正确与否,也就是是否与 GT 匹配,这个 Array 也会很长;也就是记录每一个 Valid Prediction 是 True Positive 还是 False Positive,self._match[l]的元素是 1 就表示是 True Positive,self._match[l]的元素是 0 就表示是 False Positive- self.sum_metric: 是一个 List,里面存了每一类的 AP 和 mAP
- self.num_inst: 是一个 List,里面的元素似乎都是 1
3. update
总而言之,update 函数的功能就是根据当前输入更新 self._n_pos (GT Object 个数),self._score (所有 Valid Prediction 的 Score),self._match (所有 Valid Prediction 的 True Positive 还是 False Positive)
def update(self, pred_bboxes, pred_labels, pred_scores,
gt_bboxes, gt_labels, gt_difficults=None):虽然 update 函数的注释里写到
- pred_bboxes 是 shape
B, N, 4, - pred_labels 是 shape
B, N - pred_scores 是 shape
B, N - gt_bboxes 是 shape
B, M, 4 - gt_labels 是 shape
B, M
但实际 结合 train_ssd.py 和 SSD 类的代码看,update 函数的输入应该是:
- pred_bboxes 是 shape
B, N, 4 - pred_labels 是 shape
B, N, 1 - pred_scores 是 shape
B, N, 1 - gt_bboxes 是 shape
B, M, 4 - gt_labels 是 shape
B, M, 1 - gt_difficults 是 shape
B, M, 1
还有就是,从 eval_ssd.py 调用这部分的代码看来,上面这些应该都是 List of MXNet.NDArray,List 里面的元素数量取决于 GPU 的数量。
def as_numpy(a):
"""Convert a (list of) mx.NDArray into numpy.ndarray"""
if isinstance(a, (list, tuple)):
out = [x.asnumpy() if isinstance(x, mx.nd.NDArray) else x for x in a]
try:
out = np.concatenate(out, axis=0)
except ValueError:
out = np.array(out)
return out
elif isinstance(a, mx.nd.NDArray):
a = a.asnumpy()
return a- 如果 a 是 List of MXNet.NDArray,
out = [x.asnumpy() if isinstance(x, mx.nd.NDArray) else x for x in a]会将其变成 List of NumPy.NDArray - 然后
out = np.concatenate(out, axis=0)会将 List 里面的 NumPy.NDArray 沿着 batch axis 拼起来,比如我两个 GPU,那么 a 这个 List of NumPy.NDArray 里面每个都是 (B // 2, N, 4),拼起来后 out 就是一个 (B, N, 4) 的 NumPy.NDArray
for pred_bbox, pred_label, pred_score, gt_bbox, gt_label, gt_difficult in zip(
*[as_numpy(x) for x in [pred_bboxes, pred_labels, pred_scores,
gt_bboxes, gt_labels, gt_difficults]]):- as_numpy(x) 会将 pred_bboxes 这样的 List of MXNet.NDArray (B // 2, N, 4) 变成 NumPy.NDArray (B, N, 4),假设我是 2 个 GPU
- 对于 NumPy 数组,上面代码的 zip 打散后是按照数组的 axis = 0 来迭代的,也就是每一个样本,所以
B, N, 4的 pred_bboxes 是依次返回N, 4的 pred_bbox
- pred_bbox 是 shape
N, 4 - pred_label 是 shape
N, 1 - pred_score 是 shape
N, 1 - gt_bbox 是 shape
M, 4 - gt_label 是 shape
M, 1
# strip padding -1 for pred and gt
valid_pred = np.where(pred_label.flat >= 0)[0]
pred_bbox = pred_bbox[valid_pred, :]
pred_label = pred_label.flat[valid_pred].astype(int)
pred_score = pred_score.flat[valid_pred] - 因为 pred_label 的 shape 是
N, 1,所以 flat 就是将其变成 N,然后得到 valid_pred 这是一个 index,形状是 (N’, ) 的一维 Array - pred_bbox 是
N‘, 4 - pred_label 是 (N', )
- pred_score 是 (N', )
valid_gt = np.where(gt_label.flat >= 0)[0]
gt_bbox = gt_bbox[valid_gt, :]
gt_label = gt_label.flat[valid_gt].astype(int)
if gt_difficult is None:
gt_difficult = np.zeros(gt_bbox.shape[0])
else:
gt_difficult = gt_difficult.flat[valid_gt] - valid_gt 是形状是 (M’, ) 的 index
- gt_bbox 是
M‘, 4 - gt_label 是 (M', )
- gt_difficult 是 (M', )
for l in np.unique(np.concatenate((pred_label, gt_label)).astype(int)):
pred_mask_l = pred_label == l
pred_bbox_l = pred_bbox[pred_mask_l]
pred_score_l = pred_score[pred_mask_l]l是类号- 因为 pred_label 是 (N', ),因此 pred_mask_l 还是 (N', ) 的 Array,里面的元素都是 True 和 False,可以作为 Logical Index
- pred_bbox_l 是
N_l, 4的矩阵 - pred_score_l 是 (N_l, ) 的 Array
# sort by score
order = pred_score_l.argsort()[::-1]
pred_bbox_l = pred_bbox_l[order]
pred_score_l = pred_score_l[order]- 因为 pred_score_l 是 (N_l, ) 的 Array,所以 order 是形状为 (N_l, ) 的 Array,只不过里面每个元素都是 Index
- pred_bbox_l 还是
N_l, 4的矩阵,只不过里面的元素是按照对应的 Prediction Score 从大到小排序的 - pred_score_l 还是 (N_l, ) 的 Array,只不过里面的元素是按照从大到小排列的
gt_mask_l = gt_label == l
gt_bbox_l = gt_bbox[gt_mask_l]
gt_difficult_l = gt_difficult[gt_mask_l]- 因为 gt_label 是 (M', ),因此 gt_mask_l 还是 (M', ) 的 Array,里面的元素都是 True 和 False,可以作为 Logical Index
- gt_bbox_l 是
M_l, 4的矩阵 - gt_difficult_l 是 (M_l, ) 的 Array
self._n_pos[l] += np.logical_not(gt_difficult_l).sum()
self._score[l].extend(pred_score_l)- 添加当前样本中属于 l 类的非困难目标个数,
self._n_pos[l]是记录第 l 类的目标总数 - pred_score_l 是 (N_l, ) 的 Array,
self._score[l]是记录所有模型预测成第 l 类的 Anchor 的 Prediction score,这个 Array 可以很长了
if len(pred_bbox_l) == 0:
continue
if len(gt_bbox_l) == 0:
self._match[l].extend((0,) * pred_bbox_l.shape[0])
continue- 如果 pred_bbox_l 是空的,这是有可能的,因为这个样本里可能不含这一类,也可能会卡 pred_socre 的数值,比如我喜欢卡 0.5,空的话,就直接下一个样本,因为后面的代码是根据 iou 统计预测正确的数量,pred_bbox_l 是空,也就是预测没有,所以后面的代码就没必要了
- 如果 gt_bbox_l 为空,那么说明所有 pred_bbox_l 都预测错了,也就是都没有跟 GT 匹配上,所以
self._match[l]里面的元素都是 0,self._match[l]负责记录所有模型预测成第l类的 Anchor 的正确与否,因为这里做了pred_bbox_l.shape[0]也就是N_l个预测,都错了,所以要给self._match[l]extendN_l个 0 - 如果 gt_bbox_l 为空,那么肯定就没有跟 GT 匹配的预测,所以后面的代码可以不用跑了
# VOC evaluation follows integer typed bounding boxes.
pred_bbox_l = pred_bbox_l.copy()
pred_bbox_l[:, 2:] += 1
gt_bbox_l = gt_bbox_l.copy()
gt_bbox_l[:, 2:] += 1pred_bbox_l [:, 2:] += 1是让y_max和x_max加 1,这样计算面积的时候gluoncv.utils.bbox_iou就不用设置 offset 了,为了让 end_pos - beg_pos + 1;- pred_bbox_l 的顺序是
[xmin, ymin, xmax, ymax] gt_bbox_l也同理
iou = bbox_iou(pred_bbox_l, gt_bbox_l)
gt_index = iou.argmax(axis=1)
# set -1 if there is no matching ground truth
gt_index[iou.max(axis=1) < self.iou_thresh] = -1
del iou- pred_bbox_l 是
N_l, 4的矩阵,gt_bbox_l 是M_l, 4的矩阵 - iou 是一个
N_l, M_l的矩阵 - gt_index 是 (N_l, ) 的 Array,里面存的是当前被判断为 l 类的 Anchor 和 哪一个 l 类的 GT Box 重叠的 iou 最大,也就是存的是 gt_bbox_l 中的 index
- 经过
gt_index[iou.max(axis=1) < self.iou_thresh] = -1之后,小于 iou_thresh 的 gt_index 中的元素被设置成 -1。到目前为止,每一个 GT Box 是会被 assign 给多个被判断为 l 类的 Anchor 的,后面的代码是要确保每一个 GT Box 都只会 assign 给一个被判断为 l 类的 Anchor。
selec = np.zeros(gt_bbox_l.shape[0], dtype=bool)
for gt_idx in gt_index:
if gt_idx >= 0:
if gt_difficult_l[gt_idx]:
self._match[l].append(-1)
else:
if not selec[gt_idx]:
self._match[l].append(1)
else:
self._match[l].append(0)
selec[gt_idx] = True
else:
self._match[l].append(0)- selec 是 (M_l, ) 的 Array, 里面的元素都是 True 或 False, 初始化的时候是全部都是 False,M_l 是当前样本中属于 l 类的 GT Object / Box 的个数
- gt_index 是 (N_l, ) 的 Array,里面存的是当前被判断为 l 类的 Anchor 和 哪一个 l 类的 GT Box 重叠的 iou 最大,也就是存的是 gt_bbox_l 中的 index;所以这个 for 循环一共会迭代 N_l 次,而且迭代的顺序是按照 Prediction Score 从大到小来的,所以跑完 for 循环后,
self._match[l]会被 extendN_l个元素 - gt_idx >= 0 是正常的,index 就应该从 0 开始;那什么时候会出现 gt_idx < 0 的情况呢?是上面
gt_index[iou.max(axis=1) < self.iou_thresh] = -1的代码,将一些 iou 小于 iou_thresh 的 gt_idx 设置成 -1,对于这些self._match[l].append(0) - if gt_difficult_l[gt_idx] 是怎么回事?进入到判断 if gt_difficult_l[gt_idx] 表明 gt_idx >= 0,所以这一个 gt_idx 是一个有效的 index,如果 if gt_difficult_l[gt_idx] 是 True,则表示这个 Prediction 对应的 GT Object 是 difficult 的,对应的状态是 -1;但因为我的样本没有设置 difficult 所以 True 状态不会被激发,只会进入 else 区块的代码
- if not selec[gt_idx] 如果是 True 则表明目前这个 gt_idx 对应的 GT Box 还没有分配给之前 Prediction Score 更高的,所以这个 GT Object 就会被分配给当前的 Anchor / Prediction,
selec[gt_idx] = True这句话就表示 gt_idx 这个 GT Box 的状态设置成被分配了,self._match[l].append(1)就表示目前这个 valid 的 Prediction 是一个 True Positive;如果if not selec[gt_idx]是 False,则表示当前这个 GT Box 已经被 assign 给其他 Score 更高的 Prediction 了,所以self._match[l].append(0)表示目前这个 valid 的 Prediction 是一个 False Positive
4. get
self._update() # update metric at this time
if self.num is None:
if self.num_inst == 0:
return (self.name, float('nan'))
else:
return (self.name, self.sum_metric / self.num_inst)
else:
names = ['%s'%(self.name[i]) for i in range(self.num)]
values = [x / y if y != 0 else float('nan') \
for x, y in zip(self.sum_metric, self.num_inst)]
return (names, values)- 通过调用
self._update()函数,self.sum_metric里面已经更新成目前最新的各类 AP 和 mAP 了,self.num_inst中永远都是 1 - 然后就是一次返回 类名 和 AP(最后元素是字符 mAP 和 mAP 的 value)
5. _update
总而言之,_update 就是通过调用 self._recall_prec() 和 self._average_precision 这两个函数计算出每类的 AP 和 mAP
aps = []
recall, precs = self._recall_prec()- aps 是个 List,用来存每类算出来的 AP
- 通过调用
self._recall_prec()计算出每类目前的 prec 和 rec,注意 recall 和 precs 都是 List of Numpy Array,里面记录了每一类按照 Score 排序的 Precision 和 Recall,他们要作为_average_precision的输入来计算每类的 AP
for l, rec, prec in zip(range(len(precs)), recall, precs):
ap = self._average_precision(rec, prec)
aps.append(ap)
if self.num is not None and l < (self.num - 1):
self.sum_metric[l] = ap
self.num_inst[l] = 1- 通过调用
self._average_precision计算得到每一类的 AP - 将计算出来的 ap 赋值给 self.sum_metric[l]
if self.num is None:
self.num_inst = 1
self.sum_metric = np.nanmean(aps)
else:
self.num_inst[-1] = 1
self.sum_metric[-1] = np.nanmean(aps)- 根据 aps 里的每类的 AP,计算出 mAP (就是求均值)
6. _recall_prec
def _recall_prec(self):
""" get recall and precision from internal records """- _recall_prec 这个函数的作用就是根据 self._n_pos (#GT Box),self._score,self._match 这三个统计量计算出 rec (recall) 和 prec (precision)
- 注意 prec 和 rec 都是 List of List,并不是我原以为的是 List of float,所以 prec[l] 和 rec[l] 还是一个列表,并不是一个数,具体看下面的代码
n_fg_class = max(self._n_pos.keys()) + 1
prec = [None] * n_fg_class
rec = [None] * n_fg_class- n_fg_class 顾名思义,是前景类的类数
- prec 和 rec 用来记录这些前景类的 Precision 和 Recall
for l in self._n_pos.keys():
score_l = np.array(self._score[l])
match_l = np.array(self._match[l], dtype=np.int32)- score_l 是目前 self._score[l] 也就是 Valid Prediction 预测是 l 类的个数,为什么要加一个 np.array() 呢?因为 self._score[l] 是一个 List,有一个
haha = []和wawa = np.zeros(4),做haha.extend(wawa)得到的还是一个 List,所以这一步是将其变为 Numpy Array - match_l 是目前的 Valid Prediction 的 match 情况
order = score_l.argsort()[::-1]
match_l = match_l[order]- order 是将 score_l 从大到小排序的得到的 index,match_l 则是按照 order 重新排列一下,排在前面的都是 score 很高的
- 为什么要做排序?因为 AP 本身就是一个依赖 ranking 的 metric,忘记了的话,可以看一下这篇文章 mAP (mean Average Precision) for Object Detection
tp = np.cumsum(match_l == 1)
fp = np.cumsum(match_l == 0)- 注意
np.cumsum得到的还是和match_l长度一样的 Numpy Array - tp 是一个 Numpy Array,里面是按照 Score 排序的 预测正确(TP)的数量累加
- fp 是一个 Numpy Array,里面是按照 Score 排序的 预测错误(FP)的数量累加
# If an element of fp + tp is 0,
# the corresponding element of prec[l] is nan.
with np.errstate(divide='ignore', invalid='ignore'):
prec[l] = tp / (fp + tp)
# If n_pos[l] is 0, rec[l] is None.
if self._n_pos[l] > 0:
rec[l] = tp / self._n_pos[l]- prec[l] 和 rec[l] 就是按照定义计算 Precision 和 Recall,只不过这里的 prec[l] 和 rec[l] 都是按照 Score 排序的 Numpy Array
- 所以最后返回 prec 和 rec 都是 List of Numpy Array,里面记录了每一类按照 Score 排序的 Precision 和 Recall
def _average_precision(self, rec, prec):- 输入的 rec 是 numpy.array,是 cumulated recall,按照具体某一类按照 Score 排序计算的 Recall
- 输入的 prec 是 numpy.array,是 cumulated precision,按照具体某一类按照 Score 排序计算的 Precision
if rec is None or prec is None:
return np.nan显然意见,如果 rec 或者 prec 是 None,那么就不用计算 AP 了,直接就是 nan 了
# append sentinel values at both ends
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], np.nan_to_num(prec), [0.]))- 为了之后做积分运算,将两头补上
# compute precision integration ladder
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])range(mpre.size - 1, 0, -1)返回的 List 是[1, 2, 3, ..., mpre.size - 1],一共 mpre.size - 1 个元素,因为 idx 是 i - 1 则会遍历第[0, 1, 2, ..., mpre.size - 2]个元素。- 做
np.maximum(mpre[i - 1], mpre[i])是为什么?是因为计算 AP 的 Precision 是用 Maximum Precision to the right。
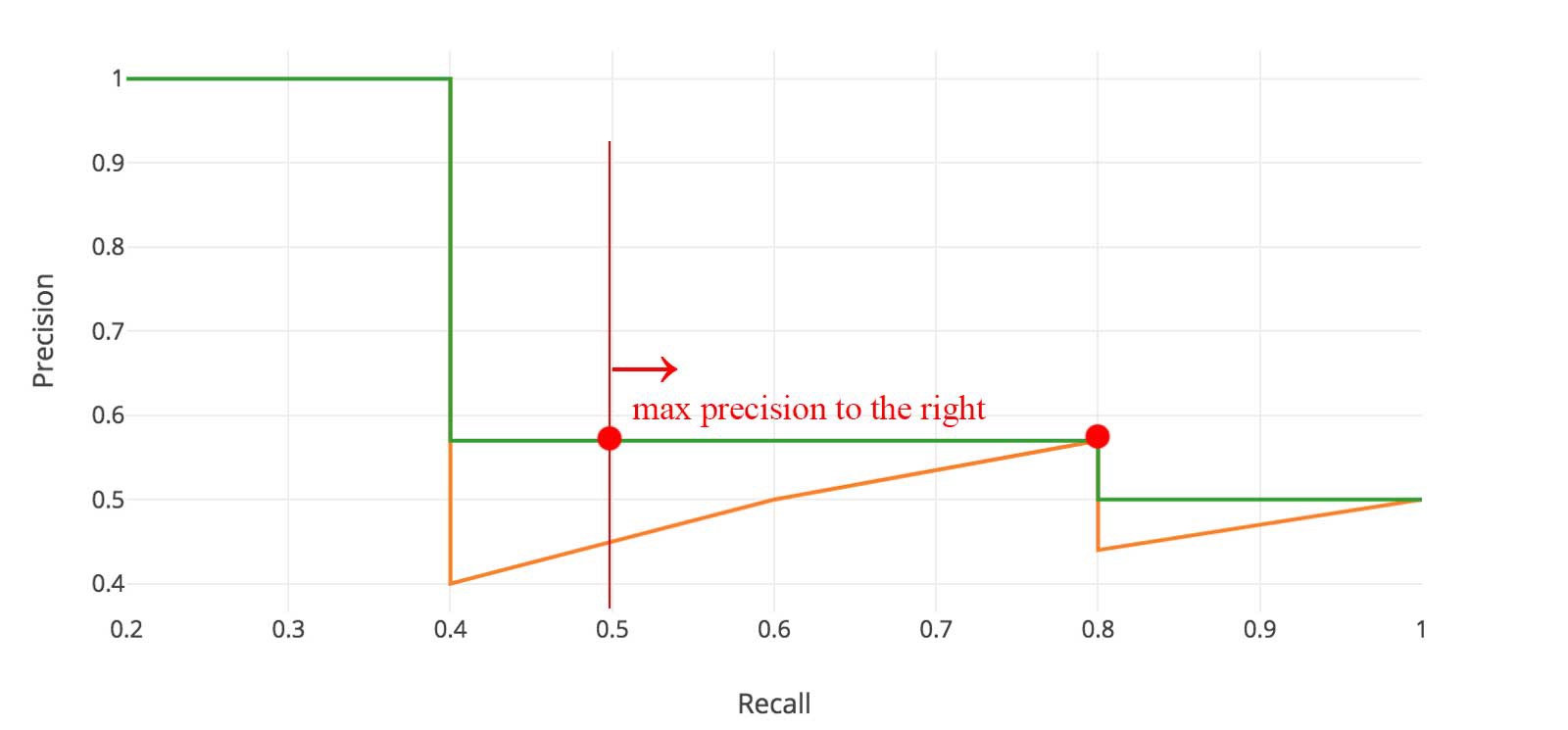
# look for recall value changes
i = np.where(mrec[1:] != mrec[:-1])[0]- 注意,
i是一个 numpy.array 里面存的是 mrec 数值发生变化的点,不是 mpre,千万不要当成是上图 绿颜色 那根线的数值发生变化的点的 index - 为什么要计算 mrec 发生变化的点呢?因为 AP 就是计算上图绿颜色那根线下面的面积,面积的计算公式是
sum (\delta recall) * prec,高是对应的 prec,\delta recall就是两个不同的 recall value 之间的差,所以这就是为什么要找 recall value 发生变化的 index 了
# sum (\delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap- 就是按照
sum (\delta recall) * prec这个公式计算 AP,然后返回 ap,这里的 ap 是一个具体的数字