1. 概述
在 YOLO3DefaultTrainTransform 中创建 YOLOV3PrefetchTargetGenerator 实例的代码如下:
self._target_generator = YOLOV3PrefetchTargetGenerator(
num_class=len(net.classes), **kwargs)在 YOLO3DefaultTrainTransform 中调用 YOLOV3PrefetchTargetGenerator 实例的代码如下:
objectness, center_targets, scale_targets, weights, class_targets = self._target_generator(
self._fake_x, self._feat_maps, self._anchors, self._offsets,
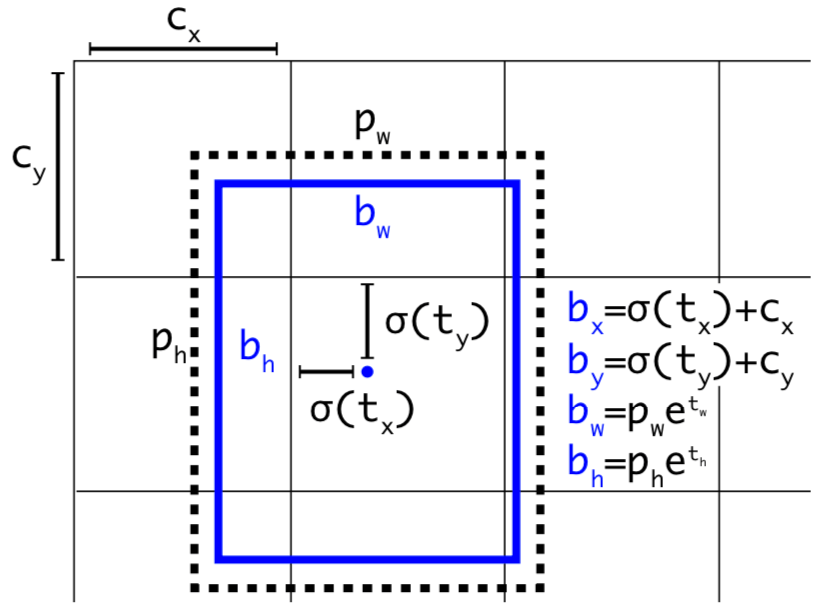
gt_bboxes, gt_ids, gt_mixratio)输入:
self._fake_x: fake input data, 是 (1, 3, H, W) 的 mx.ndarray, 全零, 因为是 fake data 嘛; 这个输入的作用是提供 orig image 的 height 和 width (orig_height 和 orig_width)self._feat_maps是 YOLO3 在 training mode 且 时返回的第 4 个元素, 是 List of mx.ndarray, 里面每个元素是 fake_featmap, 大小为 (1, 1, H_i, W_i), 而且是面积最小的 (1, H_3 x W_3, 1, 2) 在最前面, 因为 Feature Pyramid, 逆序; 这个输入的作用是提供 layer output 的 feature map 的 height 和 width- self._anchors 是 List of mx.ndarray, 每个元素大小为 (1, 1, 3, 2), 因为这里的 anchors 是 output block 输出的 (其实就是创建 YOLOV3 网络是传入的 anchors), 而 output block 是按照 feature map 的大小逆序被调用的, 因此在这个 List 中, anchor 面积最大的是在最前面, 浅层面积小的 anchor 在最后; 这个输入的作用有两个, 一个是提供每层 layer 的 anchor 个数 (num_anchors), 另一个作用是提供与 gt box 计算 IoU 时的 anchor 尺寸 (all_anchors)
- self._offsets 是 List of mx.ndarray, 每个元素大小为 (1, H_i x W_i, 1, 2), 而且面积最小的 (1, H_3 x W_3, 1, 2) 是第一个元素, 因为 Feature Pyramid, 存的是作为当前 feature map 以行优先逐个扫描整个 feature map 单索引的 index; 这个输入的作用也是两个, 一个是提供所有 layer anchor 总数, 即 H_3 x W_3 + H_2 x W_2 + H_1 x W_1; 另一个作用是提供每层的 anchor 在 anchor 总数中的索引, 即 0 : H_3 x W_3, H_3 x W_3 : H_3 x W_3 + H_2 x W_2 和 H_3 x W_3 + H_2 x W_2 : H_3 x W_3 + H_2 x W_2 + H_1 x W_1
- gt_bboxes 是 (1, M, 4) 的 mxnet.ndarray,是 [xmin, ymin, xmax, ymax] 的 Corner 编码,这些都是范围在 0 - 图像宽或高 之间的整数
- gt_ids 是 (1, M, 1) 的 mxnet.ndarray,是不带 Background 的类别标号
- 在不用 mixup 的情况下, gt_mixratio 为 None
输出:
- 输出的 objectness 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 1) 的 mx.ndarray, 在不用 mixup 的情况下, 匹配 anchor 的数值为 1
- 输出的 center_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray, 里面存的是在原图上 gt box 中心与所属 cell 左上角的归一化距离 (以 cell 长或宽的归一化距离)
- 输出的 scale_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray, 里面存的是在原图上 gt box 的长或宽相对于所匹配 anchor 长或宽的比例再取 log
- 输出的 weights 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray
- 输出的 class_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, num_class) 的 mx.ndarray
因此, YOLOV3PrefetchTargetGenerator 类实例的作用是将 Label for Human (gt_bboxes 和 gt_ids) 转化成 Label for Model 即 anchors 的 label (objectness, center_targets, scale_targets, class_targets), 具体流程是:
- 根据输入的 feature maps 大小和 anchor 的尺寸配置, 为 feat maps 上的每个点都生成相应的 anchors
- 根据 gt_bboxes 和 gt_ids, 计算 IoU, 挑选与给定的 gt bbox 最 match 的 anchor
- 根据 gt_bboxes 和 gt_ids 编码好 anchor 的 objness, bbox, cls_id
2. 代码详解
2.1 __init__
def __init__(self, num_class, **kwargs):
super(YOLOV3PrefetchTargetGenerator, self).__init__(**kwargs)
self._num_class = num_class
self.bbox2center = BBoxCornerToCenter(axis=-1, split=True)
self.bbox2corner = BBoxCenterToCorner(axis=-1, split=False)- self.bbox2center 注意下 split=True
2.2 forward
def forward(self, img, xs, anchors, offsets, gt_boxes, gt_ids, gt_mixratio=None):输入:
- img 是 (1, 3, H, W) 的 mx.ndarray
- xs 是 List of mx.ndarray, 里面每个元素是 fake_featmap, 大小为 (1, 1, H_i, W_i)
- anchors 是 List of mx.ndarray, 每个元素大小为 (1, 1, 3, 2)
- offsets 是 List of mx.ndarray, 每个元素大小为 (1, H_i x W_i, 1, 2), 而且面积最小的 (1, H_3 x W_3, 1, 2) 是第一个元素, 因为 Feature Pyramid, 存的是作为当前 feature map 以行优先逐个扫描整个 feature map 单索引的 index
- gt_boxes 是 (1, M, 4) 的 mxnet.ndarray,是 [xmin, ymin, xmax, ymax] 的 Corner 编码
- gt_ids 是 (1, M, 1) 的 mxnet.ndarray,是不带 Background 的类别标号
- 在不用 mixup 的情况下, gt_mixratio 为 None
assert isinstance(anchors, (list, tuple))
all_anchors = nd.concat(*[a.reshape(-1, 2) for a in anchors], dim=0)
assert isinstance(offsets, (list, tuple))
all_offsets = nd.concat(*[o.reshape(-1, 2) for o in offsets], dim=0)- all_anchors 是 (9, 2) 的 mx.ndarray, 里面存的是各自预设的 anchor size
- all_offsets 是 (H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 2) 的 mx.ndarray, 存的是作为当前 feature map 以行优先逐个扫描整个 feature map 单索引的 index
num_anchors = np.cumsum([a.size // 2 for a in anchors])
num_offsets = np.cumsum([o.size // 2 for o in offsets])
_offsets = [0] + num_offsets.tolist()
assert isinstance(xs, (list, tuple))
assert len(xs) == len(anchors) == len(offsets) - num_anchors 是 array([3, 6, 9])
- num_offsets 是 array([H_3 x W_3, H_3 x W_3 + H_2 x W_2, H_3 x W_3 + H_2 x W_2 + H_1 x W_1])
- _offsets 是 List, 即 array([0, H_3 x W_3, H_3 x W_3 + H_2 x W_2, H_3 x W_3 + H_2 x W_2 + H_1 x W_1])
# orig image size
orig_height = img.shape[2]
orig_width = img.shape[3]顾名思义, 图像的 height 和 width
with autograd.pause():
# outputs
shape_like = all_anchors.reshape((1, -1, 2)) * all_offsets.reshape(
(-1, 1, 2)).expand_dims(0).repeat(repeats=gt_ids.shape[0], axis=0)- all_anchors.reshape((1, -1, 2)) 得到的是 (1, 9, 2) 的 mx.ndarray
- all_offsets.reshape((-1, 1, 2)).expand_dims(0).repeat(repeats=gt_ids.shape[0], axis=0) 得到的是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 1, 2) 这样的 mx.ndarray, 存的是作为当前 feature map 以行优先逐个扫描整个 feature map 单索引的 index, gt_ids.shape[0] 就是 1 啊
- broadcast 相乘以后得到的 shape_like 是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 2) 这样的 mx.ndarray
center_targets = nd.zeros_like(shape_like)
scale_targets = nd.zeros_like(center_targets)
weights = nd.zeros_like(center_targets)
objectness = nd.zeros_like(weights.split(axis=-1, num_outputs=2)[0])
class_targets = nd.one_hot(objectness.squeeze(axis=-1), depth=self._num_class)
class_targets[:] = -1 # prefill -1 for ignores - center_targets, scale_targets 和 weights 都是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 2) 的全零 mx.ndarray
- objectness 是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 1) 的全零 mx.ndarray
- class_targets 是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, num_class) 的 one-hot 编码 mx.ndarray, 然后又将里面的 value 全部设置成 -1, 我搞不太懂, 那干嘛要用 one_hot, 直接 ones_like 然后乘上 -1 不就可以了么
# for each ground-truth, find the best matching anchor within the particular grid
# for instance, center of object 1 reside in grid (3, 4) in (16, 16) feature map
# then only the anchor in (3, 4) is going to be matched
gtx, gty, gtw, gth = self.bbox2center(gt_boxes)- gtx, gty, gtw, gth 都是 (1, M, 1) 的 mx.ndarray, 分别是 cx, cy, w, h
shift_gt_boxes = nd.concat(-0.5 * gtw, -0.5 * gth, 0.5 * gtw, 0.5 * gth, dim=-1)- shift_gt_boxes 其实是以当前 gt box 的 center 为坐标轴零点, 将当前 gt box 转化成 Corner 编码, [xmin, ymin, xmax, ymax] 为 [-0.5 * gtw, -0.5 * gth, 0.5 * gtw, 0.5 * gth]
- shift_gt_boxes 的大小为 (1, M, 4)
anchor_boxes = nd.concat(0 * all_anchors, all_anchors, dim=-1) # zero center anchors
shift_anchor_boxes = self.bbox2corner(anchor_boxes) - anchor_boxes 是 (9, 4) 的 mx.ndarray, 从下一行代码可以知道这是 Center 编码, 即 [cx, cy, w, h], 所有 cx 和 cy 都是 0, w 和 h 都是相应的 Anchor Size 的宽和长, [0, 0, w_i, h_i]
- shift_anchor_boxes 就是将上面的 Center 编码的 anchor_boxes 变成 Corner 编码的 shift_anchor_boxes, 即
[xmin, ymin, xmax, ymax], 也就是 [-w_i/2, -h_i/2, w_i/2, h_i/2] - shift_anchor_boxes 还是 (9, 4) 的 mx.ndarray
ious = nd.contrib.box_iou(shift_anchor_boxes, shift_gt_boxes).transpose((1, 0, 2))- shift_anchor_boxes 是 (9, 4), shift_gt_boxes 是 (1, M, 4)
- nd.contrib.box_iou(shift_anchor_boxes, shift_gt_boxes) 返回的是 (9, 1, M) 的 mx.ndarray, 再经过 transpose 后得到的是 (1, 9, M) 的 mx.ndarray
- ious 是一个 (1, 9, M) 的 mx.ndarray
- 这么做有什么意义呢? 这似乎是在假设每个 gt box 的中心都在 Anchor 的中心, 然后两者计算一下 IoU
# real value is required to process, convert to Numpy
matches = ious.argmax(axis=1).asnumpy() # (B, M)
valid_gts = (gt_boxes >= 0).asnumpy().prod(axis=-1) # (B, M) - matches 是 (1, M) 的 np.ndarray, 里面每个元素都是与 gt box iou 最大的那个 anchor 的 index, 可以看到这里是对所有尺度的 anchor 都做
- gt_boxes 是 (1, M, 4) 的 mxnet.ndarray,是 [xmin, ymin, xmax, ymax] 的 Corner 编码, (gt_boxes >= 0).asnumpy().prod(axis=-1) 就是在 check [xmin, ymin, xmax, ymax] 里面是否有小于 0 的, 只有大于等于 0 的才是 valid
- 得到的 valid_gts 是 (1, M) 的 np.ndarray, 里面的元素是 1 或 0, 用于指定该 gt box 是否是 valid gt box
np_gtx, np_gty, np_gtw, np_gth = [x.asnumpy() for x in [gtx, gty, gtw, gth]]
np_anchors = all_anchors.asnumpy()
np_gt_ids = gt_ids.asnumpy()
np_gt_mixratios = gt_mixratio.asnumpy() if gt_mixratio is not None else None - 就是将 gtx, gty, gtw, gth 从 mx.ndarray 变成 np.ndarray, np_gtx, np_gty, np_gtw, np_gth 这些的大小仍然是 (1, M, 1)
- 同理, np_anchors 是 (9, 2) 的 np.ndarray
- np_gt_ids 是 (1, M, 1) 的 mxnet.ndarray,是不带 Background 的类别标号
- np_gt_mixratios 也是 None 这里
# TODO(zhreshold): the number of valid gt is not a big number, therefore for loop
# should not be a problem right now. Switch to better solution is needed.
for b in range(matches.shape[0]):
for m in range(matches.shape[1]):
if valid_gts[b, m] < 1:
break
match = int(matches[b, m])
nlayer = np.nonzero(num_anchors > match)[0][0]
height = xs[nlayer].shape[2]
width = xs[nlayer].shape[3]
gtx, gty, gtw, gth = (np_gtx[b, m, 0], np_gty[b, m, 0],
np_gtw[b, m, 0], np_gth[b, m, 0])
# compute the location of the gt centers
loc_x = int(gtx / orig_width * width)
loc_y = int(gty / orig_height * height)
# write back to targets
index = _offsets[nlayer] + loc_y * width + loc_x
center_targets[b, index, match, 0] = gtx / orig_width * width - loc_x # tx
center_targets[b, index, match, 1] = gty / orig_height * height - loc_y # ty
scale_targets[b, index, match, 0] = np.log(max(gtw, 1) / np_anchors[match, 0])
scale_targets[b, index, match, 1] = np.log(max(gth, 1) / np_anchors[match, 1])
weights[b, index, match, :] = 2.0 - gtw * gth / orig_width / orig_height
objectness[b, index, match, 0] = (
np_gt_mixratios[b, m, 0] if np_gt_mixratios is not None else 1)
class_targets[b, index, match, :] = 0
class_targets[b, index, match, int(np_gt_ids[b, m, 0])] = 1 - matches 的 shape 是 (1, M) 或者说 (B, M)
- b 表示是 batch 中第几个 sample, 因为我们是用 fake data, 这里 b 就是 0
- m 是 M 个 gt box 的 index
- valid_gts[b, m] < 1 为真, 则表示这个 gt box 不是一个 valid 的, 所以就 break, 但这就终止当前样本的循环
- match 是 anchors 里面与 gt box iou 最大的那个 anchor 的 index
- nlayer 就是返回 0, 1, 2 中的一个, 看目前这个 anchor 的 index 是在哪一个 layer 上的, 因为 Feature Pyramid 是逆序的, 0 对应着 H_3, W_3 这个最小的 Feature map, 1 对应着 H_2 x W_2 的 Feature map, 2 对应着 H_1 x W_1, nlayer 就是与当前 gt box 最 match 的这个 anchor 是属于哪个 scale 的 (逆序)
- height = xs[nlayer].shape[2]
- xs 是 List of mx.ndarray, 里面每个元素是 fake_featmap, 大小为 (1, 1, H_i, W_i), 因此, height 是 H_i, width 是 W_i, 这里大小为 (1, 1, H_3, W_3) 是第一个元素, (1, 1, H_1, W_1) 是最后元素
- gtx, gty, gtw, gth 分别是第 m 个 gt box 的 cx, cy, w, h, 这些都是在原图上的数值
- loc_x 就是 int(cx / H * H_i), 因为 cx 是在 original image 上的位置, 因此 gtx / orig_width 就是 0-1 之间的归一化位置, 然后再乘上 width (W_i), 就是在当前的 feature map 上的 location
- 因此, loc_x 和 loc_y 就是当前的 gt box 的中心在当前 feature map 上的 location, 因为 int 就是直接去掉小数部分, 就是下采样的, 因此把 loc_x 和 loc_y 如果反映射到原图上, 当前的 feature map 上的当前点(loc_x, loc_y) 会变成一个 stride x stride 大小的 cell, 而 loc_x 和 loc_y 反映射回去会是这个 cell 的左上角, 就像下图所示, 里面每一个方格都是原图上的一个 cell, 蓝点是 gt box 的中心
- index 这个很有趣, 要知道 _offsets 这个 List 就是 [0, H_3 x W_3, H_3 x W_3 + H_2 x W_2, H_3 x W_3 + H_2 x W_2 + H_1 x W], 而 center_targets 是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 2) 的全零 mx.ndarray, index 就是当前的 tx 和 ty 在 center_targets 中第 2 维 的 index, _offsets[nlayer] 表示与当前 gt box 最匹配的 anchor 是属于哪个 layer 的 (逆序)
- gtx / orig_width * width - loc_x 是一个在 0 - 1 之间的小数, 反映的是 gt box 中心距离所属 cell 左上角的距离与这个 cell 长或宽的比例, 以 cell 长或宽归一化的距离 cell 左上角的归一化距离. gty / orig_height * height - loc_y 也是同理如此
- np.log(max(gtw, 1) / np_anchors[match, 0]) 表明这个 scale 是相对于最匹配的 anchor 的长或宽的比例再取 log
- weights 似乎放得是 当前 gt box 面积占整个图像面积的比例, 不清楚还要用 2 来减是为什么?
- 在不用 mixup 的时候, objectness 里面 gt box 对应的数值就是 1
- class_targets 是 (1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, num_class) 的 mx.ndarray, 里面的数值都是 -1, 倒数第二行的作用是将当前 gt box 对应 (最匹配) 的 anchor 的所有可能的类标号都设置成 0, 最后一行是将对应的真实的类设置成 1. 也就是对于与 gt box 对应的 anchor 才采用 One-hot 编码, 不匹配的都采用 -1.
# since some stages won't see partial anchors, so we have to slice the correct targets
objectness = self._slice(objectness, num_anchors, num_offsets)
center_targets = self._slice(center_targets, num_anchors, num_offsets)
scale_targets = self._slice(scale_targets, num_anchors, num_offsets)
weights = self._slice(weights, num_anchors, num_offsets)
class_targets = self._slice(class_targets, num_anchors, num_offsets)
return objectness, center_targets, scale_targets, weights, class_targets从后面的 _slice 函数解读可知:
- 输出的 objectness 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 1) 的 mx.ndarray, 在不用 mixup 的情况下, 匹配 anchor 的数值为 1, 其余为 0
- 输出的 center_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray, 里面存的是在原图上 gt box 中心与所属 cell 左上角的归一化距离 (以 cell 长或宽的归一化距离)
- 输出的 scale_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray, 里面存的是在原图上 gt box 的长或宽相对于所匹配 anchor 长或宽的比例再取 log
- 输出的 weights 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 2) 的 mx.ndarray
- 输出的 class_targets 是 (1, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, num_class) 的 mx.ndarray
2.3 _slice
def _slice(self, x, num_anchors, num_offsets):
"""since some stages won't see partial anchors, so we have to slice the correct targets"""
# x with shape (B, N, A, 1 or 2)
anchors = [0] + num_anchors.tolist()
offsets = [0] + num_offsets.tolist()
ret = []
for i in range(len(num_anchors)):
y = x[:, offsets[i]:offsets[i+1], anchors[i]:anchors[i+1], :]
ret.append(y.reshape((0, -3, -1)))
return nd.concat(*ret, dim=1)- 输入 x 的 shape 是 (B, N, A, 1 or 2), B 是 batch size, N 是 H_3 x W_3 + H_2 x W_2 + H_1 x W_1, A 是 9 (所有尺度的 anchor 个数), (B, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 1)
- 输入 num_anchors = [3, 6, 9], num_offsets = [H_3 x W_3, H_2 x W_2 + H_1 x W_1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1]
- anchors = [0, 3, 6, 9], offsets = [0, H_3 x W_3, H_2 x W_2 + H_1 x W_1, H_3 x W_3 + H_2 x W_2 + H_1 x W_1]
- y 依次是
- x[:, 0 : H_3 x W_3, 0 : 3, 1], 大小为 (B, H_3 x W_3, 3, 1), reshape 后大小为 (B, H_3 x W_3 x 3, 1)
- x[:, H_3 x W_3 : H_3 x W_3 + H_2 x W_2, 3 : 6, 1], 大小为 (B, H_2 x W_2, 3, 1), reshape 后大小为 (B, H_2 x W_2 x 3, 1)
- x[:, H_3 x W_3 + H_2 x W_2 : H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 6 : 9, 1], 大小为 (B, H_1 x W_1, 3, 1), reshape 后大小为 (B, H_1 x W_1 x 3, 1)
- 输出返回的大小为 (B, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 1) 的 mx.ndarray
总而言之, 这个函数的作用就是将 (B, H_3 x W_3 + H_2 x W_2 + H_1 x W_1, 9, 1) 的输入变成 (B, H_3 x W_3 x 3 + H_2 x W_2 x 3 + H_1 x W_1 x 3, 1) 的 mx.ndarray