Challenge : Write less than 100 word paragraph on any 5 important topics related to Deep Learning Models
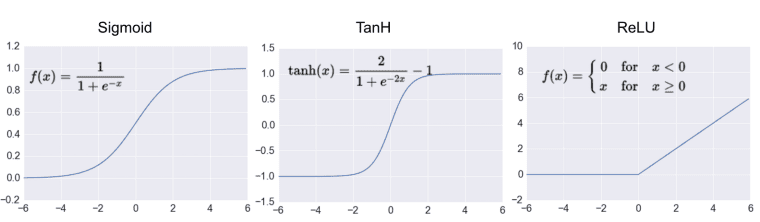
Activation functions are introduced in the neural network to capture non-linearities in the input data. It converts the weighted sum of a node's input with an addition of bias, to the node's output, eventually providing an advantage to the network on controlling output of the nodes, compared to a network without activation function which essentially works as linear regression model.

Some most used activation functions are:
After convolution operation, each of the output channels contains a grid of values, which is a response map of the filter over the input, indicating the response of that filter pattern at different locations on the input.
Complete output containing width x height x no. of channels is called a feature map, because every channel in the depth axis is a feature that tends to encode the spatial presence of some pattern or concept in the input.
This output feature map after convolution operation is a 3D tensor, having width, height and depth which no longer stands for specific colors like in an RGB input, rather we call them filters/kernels. Filters encode specific aspects of the input data. For example, patterns encoded by the filters at beginning layer of convolution networks are mainly collections of various edge detectors.
Ex:


Convolutions extract spatial patches around every tile in an input image tensor. The concept of 1x1 convolution, also known as pointwise convolution, arrives when the patches extracted consist of a single tile.

Here convolution operation computes features that mix together information from the channels of the input tensor, but it does not mix information across space. As a result, each channel is highly auto-correlated across space, but different channels might not be highly correlated with each other.

A convolution operate by sliding windows of size typically 3x3 over the 3D input feature map, stopping at each potential location, and extracting the 3D patch of encompassing features. Each such 3D patch is then transformed via a tensor product with a same learned weight matrix called convolution kernel into a 1D vector. All these vectors are then spatially reassembled into a 3D output map.

Convolution Layers learn local patterns in their input feature space, in contrast to global patterns learned by Dense Layers.