- Installation
- Create PostgreSQL Cluster
- Connect to a PostgreSQL Cluster
- psql
- pgAdmin
- Updating PostgreSQL Cluster
- High Availability
- Scale up and down
- Manual failover
- Synchronous Replication
- Tolerations
- Setup pgBouncer
- Installing pgBoucner
- connecting through pgBouncer
- Disaster Recovery
- Backups, local and remote
- Scheduled Backup
- Restore
- Delete backups
- Testing HA and Stress Testing !
- Connection setting to Odoo
Create new Kubernetes Cluster on Google Cloud.
Install Google Cloud SDK: https://cloud.google.com/sdk/docs/install
Initialize Gcloud on local machine:
gcloud init
Login and select the project.
Connect to cluster:
gcloud container clusters get-credentials <cluster-name> --zone <your-zone> --project <project-name>Install PGO
kubectl create namespace pgo
kubectl apply -f https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.1/installers/kubectl/postgres-operator.ymlGoto GC console under Workloads should be:
- pgo-deploy
- postgres-operator
Install the pgo Client
curl https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.1/installers/kubectl/client-setup.sh > client-setup.sh
chmod +x client-setup.sh
./client-setup.shthen permanently add these variables to your environment, run the following:
cat <<EOF >> ~/.bashrc
export PGOUSER="${HOME?}/.pgo/pgo/pgouser"
export PGO_CA_CERT="${HOME?}/.pgo/pgo/client.crt"
export PGO_CLIENT_CERT="${HOME?}/.pgo/pgo/client.crt"
export PGO_CLIENT_KEY="${HOME?}/.pgo/pgo/client.key"
export PGO_APISERVER_URL='https://127.0.0.1:8443'
export PGO_NAMESPACE=pgo
EOF
source ~/.bashrcNOTE: For macOS users, you must use ~/.bash_profile or ~/.zshrc instead of ~/.bashrc
Done!
Next, check the Postgres Operator is up and running:
kubectl -n pgo get pods,deploymentsNext, how to connect to the Postgres Operator from the pgo command-line client:
In a new console window, run the following command to set up a port forward:
kubectl -n pgo port-forward svc/postgres-operator 8443:8443Back to your original console window, you can verify that you can connect to the PostgreSQL Operator using the following command:
pgo versionIf successful, you should see output similar to this:
pgo client version 4.7.1
pgo-apiserver version 4.7.1
Try creating a PostgreSQL cluster called hippo:
pgo create cluster -n pgo hippoMore Options to create clusters:
- --metric
- --custom-config
- --replica-count
It may take a few moments for the cluster to be provisioned. You can see the status of this cluster using the pgo test command:
pgo test -n pgo hippo
When everything is up and running, you should see output similar to this:
cluster : hippo
Services
primary (10.97.140.113:5432): UP
Instances
primary (hippo-7b64747476-6dr4h): UP
On GC console, see additional workloads deployed:
- hippo
- hippo-xyz
Common Options to create cluster
Create a High Availability PostgreSQL Cluster
pgo create cluster hippo --replica-count=1
Customize PostgreSQL Configuration
For example, let’s say we want to create a PostgreSQL cluster with shared_buffers set to 2GB, max_connections set to 30 and password_encryption set to scram-sha-256. We would create a configuration file that looks similar to:
---
bootstrap:
dcs:
postgresql:
parameters:
max_connections: 30
shared_buffers: 2GB
password_encryption: scram-sha-256Save this configuration in a file called postgres-ha.yaml.
Next, create a ConfigMap called hippo-custom-config like so:
kubectl -n pgo create configmap hippo-custom-config --from-file=postgres-ha.yaml
pgo create cluster hippo --custom-config=hippo-custom-config
After your cluster is created, connect to your cluster and confirm that your settings have been applied:
SHOW shared_buffers;
shared_buffers
----------------
2GB
You can get information about the users in your cluster with the pgo show user command:
pgo show user -n pgo --show-system-accounts hippo
To set or change the default password for testuser:
pgo update user -n pgo hippo --username=testuser --password=datalake
Connecting via psql
Check available services and look for hippo service:
kubectl -n pgo get svc
In a different console window, set up a port forward to the hippo service:
kubectl -n pgo port-forward svc/hippo 5432:5432
In the first windows, execute this and enter the testuser password:
psql -h localhost -p 5432 -U testuser -W hippo
You should then be greeted with the PostgreSQL prompt:
psql (13.3)
Type "help" for help.
hippo=>
Connecting via pgAdmin 4
To add pgAdmin 4 to hippo, you can execute the following command:
pgo create pgadmin -n pgo hippo
On GC console, another workload is created hippo-pgadmin. Then check for the pgadmin service hippo-pgadmin:
kubectl -n pgo get svc
in a different terminal, set up a port forward to pgAdmin 4:
kubectl -n pgo port-forward svc/hippo-pgadmin 5050:5050
Navigate your browser to http://localhost:5050
To set or change the default password for testuser:
pgo update user -n pgo hippo --username=testuser --password=datalake
Create a PostgreSQL Cluster With Monitoring
pgo update cluster hippo --enable-metrics
Must install pgo metric operator:
kubectl apply -f https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.1/installers/metrics/kubectl/postgres-operator-metrics.yml
Customize PVC Size
pgo update cluster hippo --pvc-size=20Gi
To update exising cluster:
kubectl -n pgo edit configmap hippo-pgha-config
Restart pg cluster
pgo restart hippo --query
pgo restart hippo
After your cluster is created, connect to your cluster and confirm that your settings have been applied:
SHOW shared_buffers;
shared_buffers
----------------
2GB
There are certain things that can happen in the environment that PostgreSQL is deployed in that can affect its uptime, including:
- The database storage disk fails or some other hardware failure occurs
- The network on which the database resides becomes unreachable
- The host operating system becomes unstable and crashes
- A key database file becomes corrupted
- A data center is lost
There may also be downtime events that are due to the normal case of operations, such as performing a minor upgrade, security patching of operating system, hardware upgrade, or other maintenance.
Fortunately, the Crunchy PostgreSQL Operator is prepared for this.
Scale up and down
High availability is enabled in the PostgreSQL Operator by default so long as you have more than one replica. To create a high availability PostgreSQL cluster, you can execute the following command:
pgo create cluster hippo --replica-count=1
You can scale an existing PostgreSQL cluster to add HA to it by using the pgo scale command:
pgo scale hippo
To scale down a PostgreSQL cluster, you will have to provide a target of which instance you want to scale down. You can do this with the pgo scaledown command:
pgo scaledown hippo --query
List of targets is displayed. Once you have determined which instance you want to scale down, you can run the following command:
pgo scaledown hippo --target=hippo-ojnd
Manual failover
Each PostgreSQL cluster will manage its own availability. If you wish to manually fail over, you will need to use the pgo failover command.
There are two ways to issue a manual failover to your PostgreSQL cluster:
- Allow for the PostgreSQL Operator to select the best replica candidate for failover.
To have the PostgreSQL Operator select the best replica candidate for failover, all you need to do is execute the following command:
pgo failover hippo
The PostgreSQL Operator will determine which is the best replica candidate to fail over to, and take into account factors such as replication lag and current timeline.
- Select your own replica candidate for failover.
If you wish to have your cluster manually failover, you must first query your determine which instance you want to fail over to. You can do so with the following command:
pgo failover hippo --query
Select the failover target. Once you have determine your failover target, you can run the following command:
pgo failover hippo --target==hippo-ojnd
Synchronous Replication
If you have a write sensitive workload and wish to use synchronous replication, you can create your PostgreSQL cluster with synchronous replication turned on:
pgo create cluster hippo --sync-replication
Please understand the tradeoffs of synchronous replication before using it.
Tolerations
If you want to have a PostgreSQL instance use specific Kubernetes tolerations, you can use the --toleration flag on pgo scale. Any tolerations added to the new PostgreSQL instance fully replace any tolerations available to the entire cluster.
For example, to assign equality toleration for a key/value pair of zone/west, you can run the following command:
pgo scale hippo --toleration=zone=west:NoSchedule
pgBouncer is a lightweight connection poooler and state manager that provides an efficient gateway to metering connections to PostgreSQL. The PostgreSQL Operator provides an integration with pgBouncer that allows you to deploy it alongside your PostgreSQL cluster.
Enable pgBouncer
On provisioned PostgreSQL:
pgo create pgbouncer hippo
There are several managed objects that are created alongside the pgBouncer Deployment, these include:
- The pgBouncer Deployment itself
- One or more pgBouncer Pods
- A pgBouncer ConfigMap, e.g. hippo-pgbouncer-cm which has two entries:
- pgbouncer.ini, which is the configuration for the pgBouncer instances
- pg_hba.conf, which controls how clients can connect to pgBouncer
- A pgBouncer Secret e.g. hippo-pgbouncer-secret, that contains the following values:
- password: the password for the pgbouncer user. The pgbouncer user is described in more detail further down.
- users.txt: the description for how the pgbouncer user and only the pgbouncer user can explicitly connect to a pgBouncer instance.
Connect to a Postgres Cluster Through pgBouncer
In a separate terminal window, run the following command:
kubectl -n pgo port-forward svc/hippo-pgbouncer 5432:5432
We can the connect to PostgreSQL via pgBouncer by executing the following command:
psql -h localhost -p 5432 -U testuser -W hippo
You should then be greeted with the PostgreSQL prompt:
psql (13.3)
Type "help" for help.
hippo=>
More info: https://access.crunchydata.com/documentation/postgres-operator/4.7.1/tutorial/pgbouncer/
When using the PostgreSQL Operator, the answer to the question “do you take backups of your database” is automatically “yes!”
The PostgreSQL Operator leverages a pgBackRest repository to facilitate the usage of the pgBackRest features in a PostgreSQL cluster. When a new PostgreSQL cluster is created, it simultaneously creates a pgBackRest repository as described in creating a PostgreSQL cluster section.
Creating a Backup
To create a backup (an incremental pgBackRest backup), you can run the following command:
pgo backup hippo
PostgreSQL Operator initially creates a pgBackRest full backup when the cluster is initial provisioned.
Creating a Full Backup
You can create a full backup using the following command:
pgo backup hippo --backup-opts="--type=full"
Creating a Differential Backup
You can create a differential backup using the following command:
pgo backup hippo --backup-opts="--type=diff"
Creating an Incremental Backup
You can create a differential backup using the following command:
pgo backup hippo --backup-opts="--type=incr"
An incremental backup is created without specifying any options after a full or differential backup is taken.
Creating Backups in S3
The PostgreSQL Operator supports creating backups in S3 or any object storage system that uses the S3 protocol. For more information, please read the section on PostgreSQL Operator Backups with S3 in the architecture section.
Creating Backups in GCS
The PostgreSQL Operator supports creating backups in Google Cloud Storage (GCS). For more information, please read the section on PostgreSQL Operator Backups with GCS in the architecture section.
Set Backup Retention
By default, pgBackRest will allow you to keep on creating backups until you run out of disk space. As such, it may be helpful to manage how many backups are retained.
pgBackRest comes with several flags for managing how backups can be retained:
- --repo1-retention-full: how many full backups to retain
- --repo1-retention-diff: how many differential backups to retain
- --repo1-retention-archive: how many sets of WAL archives to retain alongside the full and differential backups that are retained
For example, to create a full backup and retain the previous 7 full backups, you would execute the following command:
pgo backup hippo --backup-opts="--type=full --repo1-retention-full=7"
Schedule Backups
It is good practice to take backups regularly. The PostgreSQL Operator allows you to schedule backups to occur automatically.
The PostgreSQL Operator comes with a scheduler is essentially a cron server that will run jobs that it is specified. Schedule commands use the cron syntax to set up scheduled tasks.
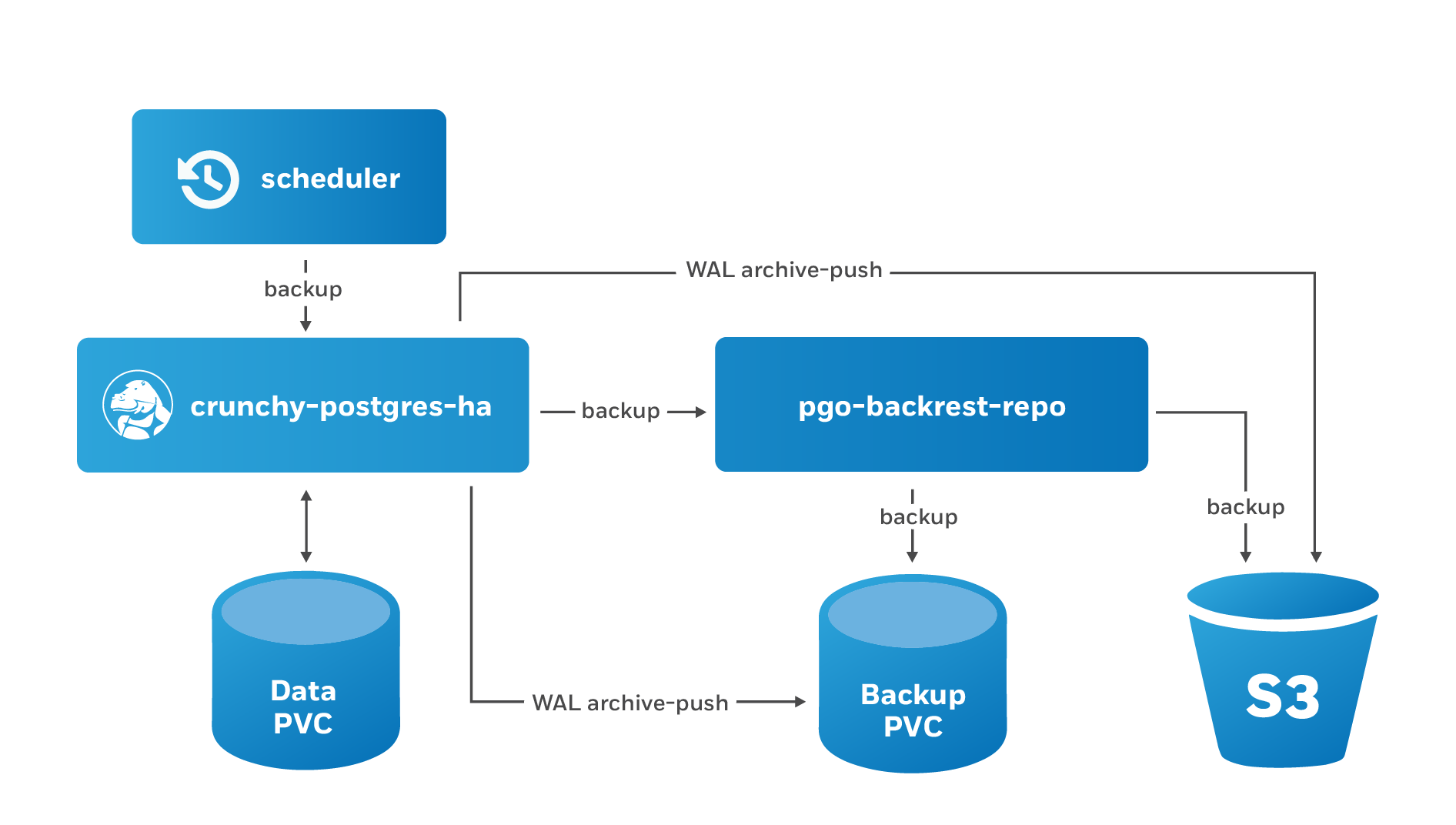
For example, to schedule a full backup once a day at 1am, the following command can be used:
pgo create schedule hippo --schedule="0 1 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=full
To schedule an incremental backup once every 3 hours:
pgo create schedule hippo --schedule="0 */3 * * *" \
--schedule-type=pgbackrest --pgbackrest-backup-type=incr
View Backups
You can view all of the available backups in your pgBackRest repository with the pgo show backup command:
pgo show backup hippo
Restores
The PostgreSQL Operator supports the ability to perform a full restore on a PostgreSQL cluster (i.e. a “clone” or “copy”) as well as a point-in-time-recovery. There are two types of ways to restore a cluster:
- Restore to a new cluster using the --restore-from flag in the pgo create cluster command. This is effectively a clone or a copy.
- Restore in-place using the pgo restore command. Note that this is destructive.
It is typically better to perform a restore to a new cluster, particularly when performing a point-in-time-recovery, as it can allow you to more effectively manage your downtime and avoid making undesired changes to your production data.
Additionally, the “restore to a new cluster” technique works so long as you have a pgBackRest repository available: the pgBackRest repository does not need to be attached to an active cluster! For example, if a cluster named hippo was deleted as such:
pgo delete cluster hippo --keep-backups
you can create a new cluster from the backups like so:
pgo create cluster datalake --restore-from=hippo
Restore modes:
- Restore to a New Cluster (aka “copy” or “clone”): Restoring to a new PostgreSQL cluster allows one to take a backup and create a new PostgreSQL cluster that can run alongside an existing PostgreSQL cluster.
- Restore in-place: Restoring a PostgreSQL cluster in-place is a destructive action that will perform a recovery on your existing data directory. This is accomplished using the pgo restore command. The most common scenario is to restore the database to a specific point in time.
More info: https://access.crunchydata.com/documentation/postgres-operator/4.7.1/tutorial/disaster-recovery/
Within a Kubernetes Cluster
Using the Kubernetes DNS naming standard. Following the example we’ve created, the hostname for our PostgreSQL cluster is hippo.pgo (or hippo.pgo.svc.cluster.local). So we can construct a Postgres URI that contains all of the connection info:
postgres://testuser:securerandomlygeneratedpassword@hippo.pgo.svc.cluster.local:5432/hippo
which breaks down as such:
- postgres: the scheme, i.e. a Postgres URI
- testuser: the name of the PostgreSQL user
- securerandomlygeneratedpassword: the password for testuser
- hippo.pgo.svc.cluster.local: the hostname
- 5432: the port
- hippo: the database you want to connect to
Outside a Kubernetes Cluster
To connect to a database from an application that is outside a Kubernetes cluster, you will need to set one of the following:
- A Service type of LoadBalancer or NodePort
- An Ingress. The PostgreSQL Operator does not provide any management for Ingress types.
To have the PostgreSQL Operator create a Service that is of type LoadBalancer or NodePort, you can use the --service-type flag as part of creating a PostgreSQL cluster, e.g.:
pgo create cluster hippo --service-type=LoadBalancer
You can also set the ServiceType attribute of the PostgreSQL Operator configuration to provide a default Service type for all PostgreSQL clusters that are created.
Create odoo user:
- enter psql with postgres user
- execute: CREATE USER odoo WITH PASSWORD 'odoo' SUPERUSER;
Create odoo workload:
- HOST = hippo.pgo.svc.cluster.local
- PORT = 5432
- USER = odoo
- PASSWORD = odoo
Down scale odoo to 1 replica. Create odoo service with port mapping 80:8069. Install Odoo Sale and Accounting addon with demo data.
Test scenario:
- Scale to 2 pg replicas
- check data on both replicas
- Check hippo service, what is the serving pod
- Shut down/delete the service pod
- Check hippo service again, what is the serving pod
- Check Odoo connection and data integrity
Other scenario: manually failover replicas:
- query replica
- run: pgo failover hippo
- check the serving pods on the service before and after manual failover
- https://access.crunchydata.com/documentation/postgres-operator/4.7.1/quickstart/
- https://cloud.google.com/sdk/docs/install

Artikel ini disponsori oleh RoyalQ, robot trading crypto-currency otomatis yang bisa menghasilkan profit konsisten 10-30% per bulan sambil anda tidur!
Klik disini PENDAFTARAN: https://raqsy.com/s/4CXXV
Informasi lebih detail: https://royalq.info/