This is an introduction to managing infrastructure (Infra) and system administration operations (Ops) particularly for deep learning applications.
Q: I have my Jupyter notebooks and virtual machines that comes with all batteries included. Why do I have to handle bare-metal machines?
A: You don't (if you are not interested). In most cases, the normal virtual machines with everything included, e.g. AWS Sagemaker or Azures Machine Learning Studio. But these are technically "Managed" Virtual Machines and often fixing something that goes wrong after the VM has been spun up for a couple of months will lead to the same issues that requires the knowledge of infra-ops to handle/fix the issue.
- General
- CPUs
- GPUs
- Additional Materials
The cloud isn't a single thing, in fact, it's a couple of different things depends on who's selling it. The cloud services comes in a spectrum of:
- Infrastructure as a Service (IaaS)
- Platform as a Service (PaaS)
- Software as a Service (SaaS)
One way to visualize them is something like:
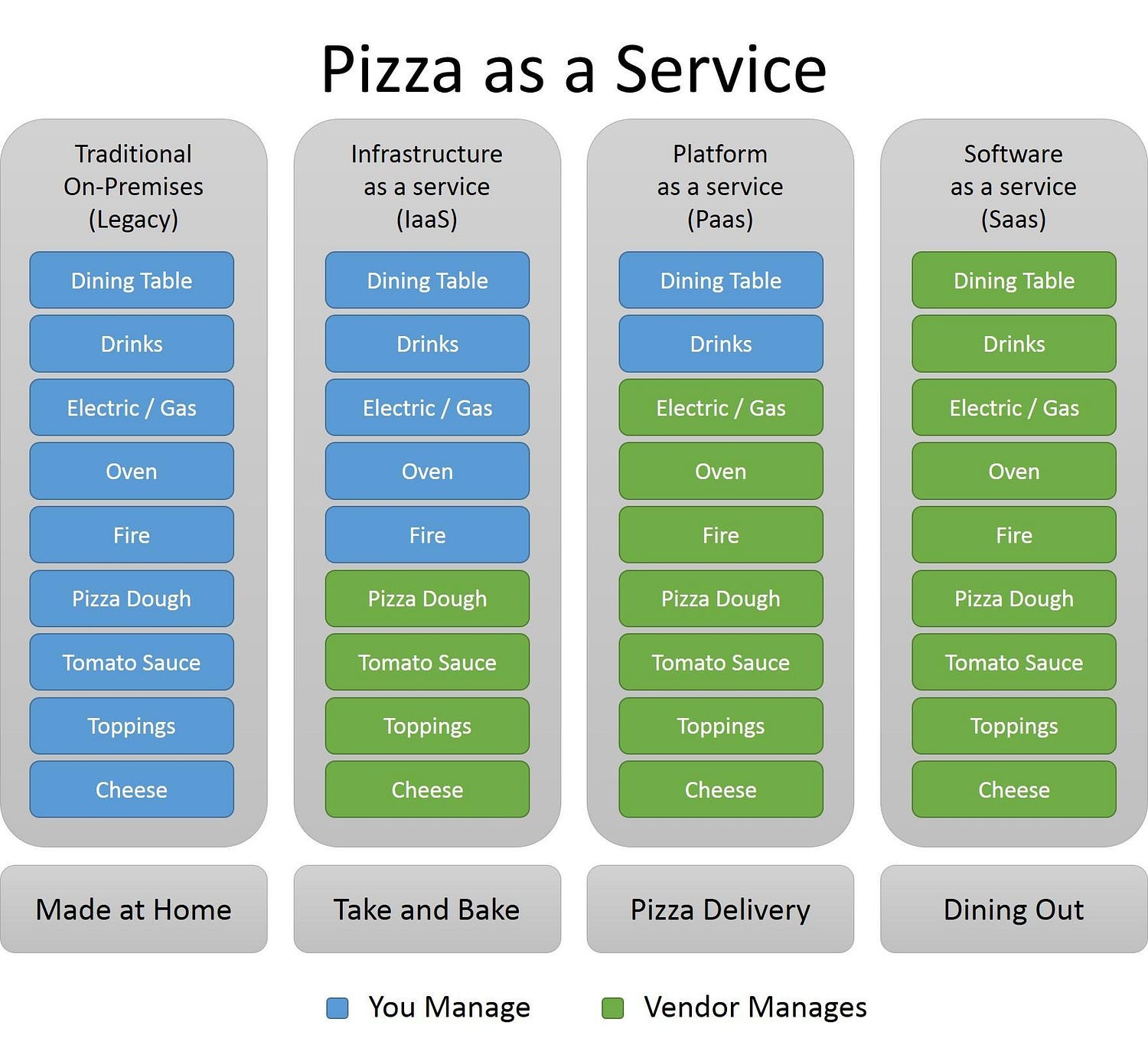
Where, as a sysadmin/Ops personnel, for the
- the On-prem and IaaS end of the spectrum, you have more control over the tech stack wherease
- the SaaS end of the spectrum, you'll be running more maintenance tasks
An example of which tech falls into which part of the spectrum:

Q: Why do we need to know all these?!
A: Because other than data, compute is the next important thing even before you can run any fancy AI models. To get the right resource is important, esp. when you need to know your capabilities of using/maintenance the resources you've asked for.
There's also something between PaaS and SaaS, call Function as a Service (FaaS), those are usually the serverless deployments options. But in the case of ML/DL, we can think of them as functions/libraries needed to train models/process data.
Specifically for ML/DL related software, we see:
-
IaaS: Virtual Machines
- AWS EC2
- DigitalOcean Droplets
- GCP Compute Engines
-
PaaS: Managed Virtual Environments
- AWS Sagemakers
- Google Colab
- Nvidia GPU Cloud
- Custom Anaconda environments
-
SaaS: Generally API calls on pre-trained models or used for automatically training models.
- Google AutoML
- Google Natural Language API
- Microsoft Translator
- Nuance ASR / TTS
The hardware forms the core of whichever IaaS instance or PaaS instance we spin up, usually the libraries that are compiled on different hardware is in some subtle way different. Even if it's in Python, there might be different .whl distributions that needs to be created for different hardware and different OS. So it is best to go through some optimized libraries that comes with the hardware we use to fully appreciate our work.
“People who are really serious about software should make their own hardware.”
- Alan Kay
Other than the CPUs or GPUs that we know well, there's also FPGA and ASIC cards. But it's out of scope for this session, I'll leave you with this comparison from a Toshiba whitepaper

Instruction Set of Architecture (ISA) is an abstract model for CPUs to interact with you. Think of it as the lowest level you can get to program/code. And the most common architecture that we interact daily is the x86 instruction set from the Intel CPU chips. The x86 comes in various bit range, the one that we know of today is x86-64, the 64-bit flavor powering our popular Ubuntu OS.
On top of the ISAs, there are extended instructions that can be used to instruct the computers that are more useful for our machine/deep learning usages, esp the SIMD (Single Instruction, Multiple Data) (parallel computing) class of instructions, important ones includes:
You will see that the machine/deep learning libraries that fully utilized those SIMD instructions will result in faster computations than those without. At this point, I would strongly recommend you to read Bogoychev's (2019) thesis, esp. Chapter 1 and 2 to understand more about hardwares and instruction sets.
We know about the popular mainstream Intel i3, i5, i7 and i9 cores but on the server rack we commonly use the Xeon cores. Those are the "brand names". What's more important are the micro-architectures; differet Intel chipsets micro-architectures comes with different capabilities in terms of the instruction sets listed above. The more recent Intel micro-architectures are Broadwell, Haswell, Skylake, Cascadelake and most recently CooperLake and IceLake.
Choosing machines with the right micro-architectures that has the correct instructions capabilities is important in deployment to ensure that you get the right bang for the buck. So lets focus on the AVX instructions that are the most commonly known to be used by deep learning optimization libraries. The most mainstream AVX instruction is AVX2, more Intel micro-architectures and some AMD chips (Zen 2 and Zen 3, powering the Ryzen models) has the AVX2 instructions. So technically anything that you can compile with AVX2 on an Intel machine can be compiled in AMD (as long as the library checks for subtlety).
There seems to be no problem and need to learn about these low level instructions when I work with Python or high-level languages. But to optimize your code, at some point you'll end up hacking the Python internals/interpreters to put in the lower-level instructions listed above (if possible), or just re-code entirely in a language that has more direct access to those instructions.
Intel CPUs comes with optimized low-level matrix optimization package call the Math Kernel Library (MKL) https://software.intel.com/content/www/us/en/develop/tools/math-kernel-library.html that uses the SIMD instructions. This is usually use in inference deployments where we want to be able to scale our solutions to more than the maximum capacity of the GPU. Most deep learning libraries with CPU supports would have MKL support (sometimes optional).
To install MKL on Ubuntu 18.04, first fetch the encryption keys and add them the apt package manager (this will indicate to the OS, the site to get the packages):
wget https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS-2019.PUB
sudo apt-key add GPG-PUB-KEY-INTEL-SW-PRODUCTS-2019.PUB
Note: For reference, see DigitalOcean reference for an explanation of GPG public key.
Add a full list of intel products to the apt source list (this will indicate to the OS, the package available under this distribution of MKL 2019:
wget https://apt.repos.intel.com/setup/intelproducts.list -O /etc/apt/sources.list.d/intelproducts.list
Then finally the real installation:
sudo apt update
sudo apt install intel-mkl-2019.0-045
The installed MKL will be usually at /opt/intel. After installation, you need to add the environmental variable (so that when you install packages, they know MKL exists and can find them in the right path).
export MKL_ROOT_DIR=/opt/intel/mkl
export LD_LIBRARY_PATH=$MKL_ROOT_DIR/lib/intel64:/opt/intel/lib/intel64_lin:$LD_LIBRARY_PATH
export LIBRARY_PATH=$MKL_ROOT_DIR/lib/intel64:$LIBRARY_PATH
Note:
- Most packages that uses MKL looks for the
MKL_ROOT_DIRvariable when looking for Intel MKL. - The
LD_LIBRARY_PATHand sometimesLIBRARY_PATHare the paths that most librareis look for when linking dynamic libraries/shared libraries.
For later Ubuntu versions, MKL has been packaged in the multiverse repositories, you can look for the supported packages on https://packages.ubuntu.com/search?keywords=intel-mkl. (For more details on how to enable/disable non-default -verse in Ubuntu, take a look at https://itsfoss.com/ubuntu-repositories/. I would strongly discourage usage of multiverse on production machines/docker images).
There is also the MKL 2020 through the Parallel XE version but I would advise using it until deep learning libraries becomes more matured in chasing MKL versions =)
GPUs are what's powering today's machine (mostly deep) learning. It is mainly produced by Nvidia and powered by the development suite of libraries call CUDA (Compute Unified Device Architecture). The official documentation of the CUDA is on https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
In most cases, we use the Python interface to tensor operations in CUDA. So the main concern is making sure that we have the right CUDA version installed as per required by the libary. But sometimes when we use these libraries they end up crappy error CUDA errors that we often have no clue to fix the problem unless we look at the native CUDA code. For reference look for cudaError in https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__TYPES.html and then trace back from the Python code to the underlying C++ tensor library they're calling with the CUDA error code.
If you dig hard enough, you'll reach the ISA page for the CUDA compiler instructions, i.e. PTX ISA.
Ah ha, Instruction Set Architecture!! ISA will haunt you enough if you go low enough...
Note: Nvidia is NOT the only provider of GPUs that provides library with deep learning tensor operations. If you're interested take a look at (ROCm](https://github.com/RadeonOpenCompute/ROCm) i.e. open source =)
First check your Ubuntu distro version with lsb_release -a, you will see
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.4 LTS
Release: 18.04
Codename: bionic
In the above example, your version of Ubuntu is 18.04.4.
It is advisable to do the apt updates and upgrades as such before reinstalling cuda:
$ sudo apt update && sudo apt upgrade
If you're confident enough do a dist-upgrade
$ sudo apt dist-upgrade
Always update and upgrade the OS for the existing version, esp. for security packages. But AVOID upgrading OS versions upon need release, most of the time deep/machine learning libraries don't support bleeding edge OS that quickly. I strongly suggest that you make sure you're on an LTS (Long Term Support) version instead of chasing OS upgrades.
To check if you're on LTS, do cat /etc/update-manager/release-upgrades you'll see:
$ cat /etc/update-manager/release-upgrades
# Default behavior for the release upgrader.
[DEFAULT]
# Default prompting behavior, valid options:
#
# never - Never check for, or allow upgrading to, a new release.
# normal - Check to see if a new release is available. If more than one new
# release is found, the release upgrader will attempt to upgrade to
# the supported release that immediately succeeds the
# currently-running release.
# lts - Check to see if a new LTS release is available. The upgrader
# will attempt to upgrade to the first LTS release available after
# the currently-running one. Note that if this option is used and
# the currently-running release is not itself an LTS release the
# upgrader will assume prompt was meant to be normal.
Prompt=lts
And if you really really want to be on the bleeding edge, do do-release-upgrade, (Not advisable unless you know what you're doing) :
$ sudo do-release-upgrade
Lastly, if you want more stable OS, drop Ubuntu, go Debian (https://www.debian.org/) or if "you're feeling lucky", try Pop!_OS (https://pop.system76.com/)
After checking OS version, check which CUDA version the deep poison of your choice supports:
- Tensorflow: https://www.tensorflow.org/install/gpu
- PyTorch: https://pytorch.org/
- Marian: marian-nmt/marian-dev#526
I strongly advise AGAINST installing latest CUDA if your chosen poison supports lower versions of CUDA.
With your OS version and desired CUDA version, go to http://developer.download.nvidia.com/compute/cuda/repos/, select the appropriate OS and the CUDA version.
E.g. if you are using:
- Ubuntu 18.04 and CUDA 10.2 with an Intel chipset supporting 32 or 64-bits, you'll go to http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/, look for the
.pubfile.
sudo apt-get purge nvidia*
sudo apt-get autoremove && sudo apt-get autoclean
sudo rm -rf /usr/local/cuda
Add the CUDA public repo key (the .pub file) to your apt repositories, and then update your apt manager:
sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
echo "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 /" | sudo tee /etc/apt/sources.list.d/cuda.list
sudo apt-get update
At this point if you have others CUDA keys, and should there be a conflict, go to /etc/apt/sources.list.d/cuda.list text file and delete out the existing deb http://http://developer.download.nvidia.com/compute/cuda/repos/... line, then redo the above commands.
There are many ways to install the CUDA drivers and CUDA version you'll need. Trusting the .pub key from not missing up the CUDA drivers, do this to force install the CUDA:
sudo apt-get -o Dpkg::Options::="--force-overwrite" install cuda-10-2 cuda-drivers
After the install is complete, restart the machine with:
sudo shutdown -r now
It is highly recommended that you walk through https://missing.csail.mit.edu/ if you are unfamiliar with the Linux terminals/tooling.
To monitor GPU usage across multiple nodes, there are proper CUDA cluster management tools, https://developer.nvidia.com/cluster-management but if you need a quick and dirty way to just look at which machine has spare GPU, try https://github.com/jonsafari/network-gpu-info