Historically, all memory on x86 architectures were equally accessibly by all CPUs on the system. This is an effective implementation, but there's increased bandwidth on the bus, and the more CPUs you have, the further away from the memory it is. This layout is called Uniform Memory Access.
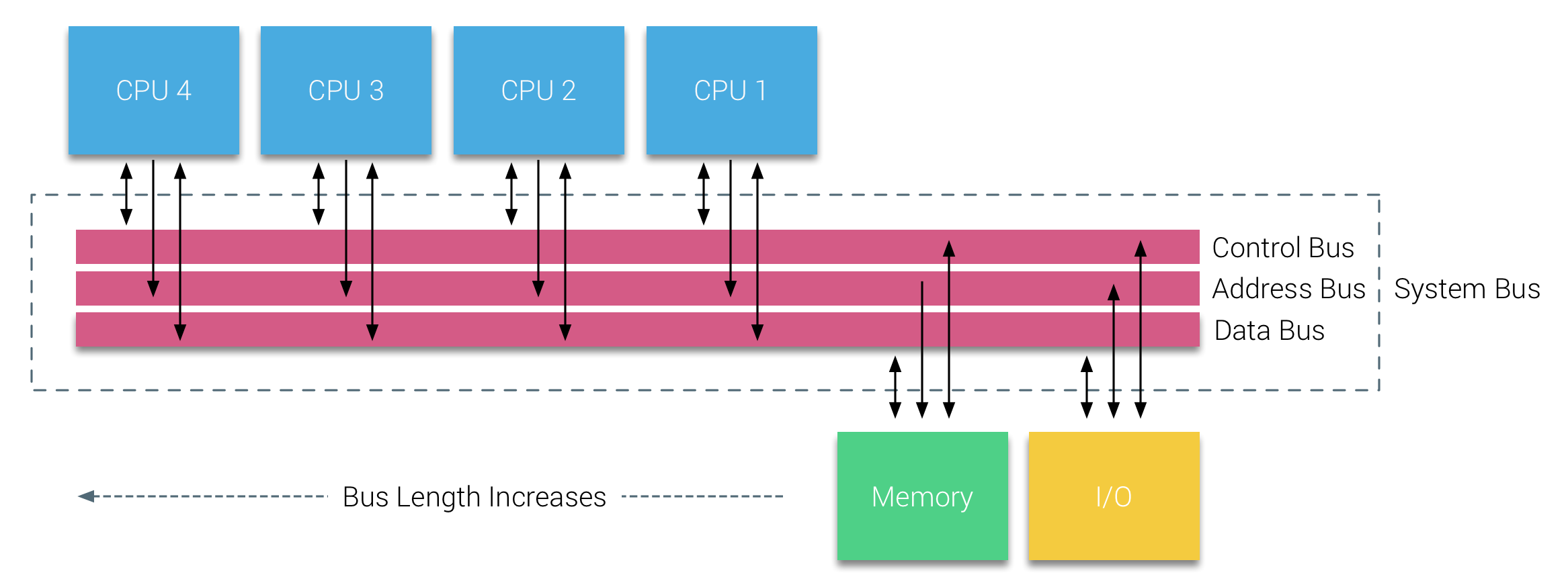
Modern x86 architectures introuduce the concept of memory nodes (also referred to elsewhere as zones or cells), where new writes are associated with a CPU's memory node. The nodes are connected by a bus, so all the memory is still accessible via any CPU, but of course, we have faster memory access time for CPUs accessing local nodes.
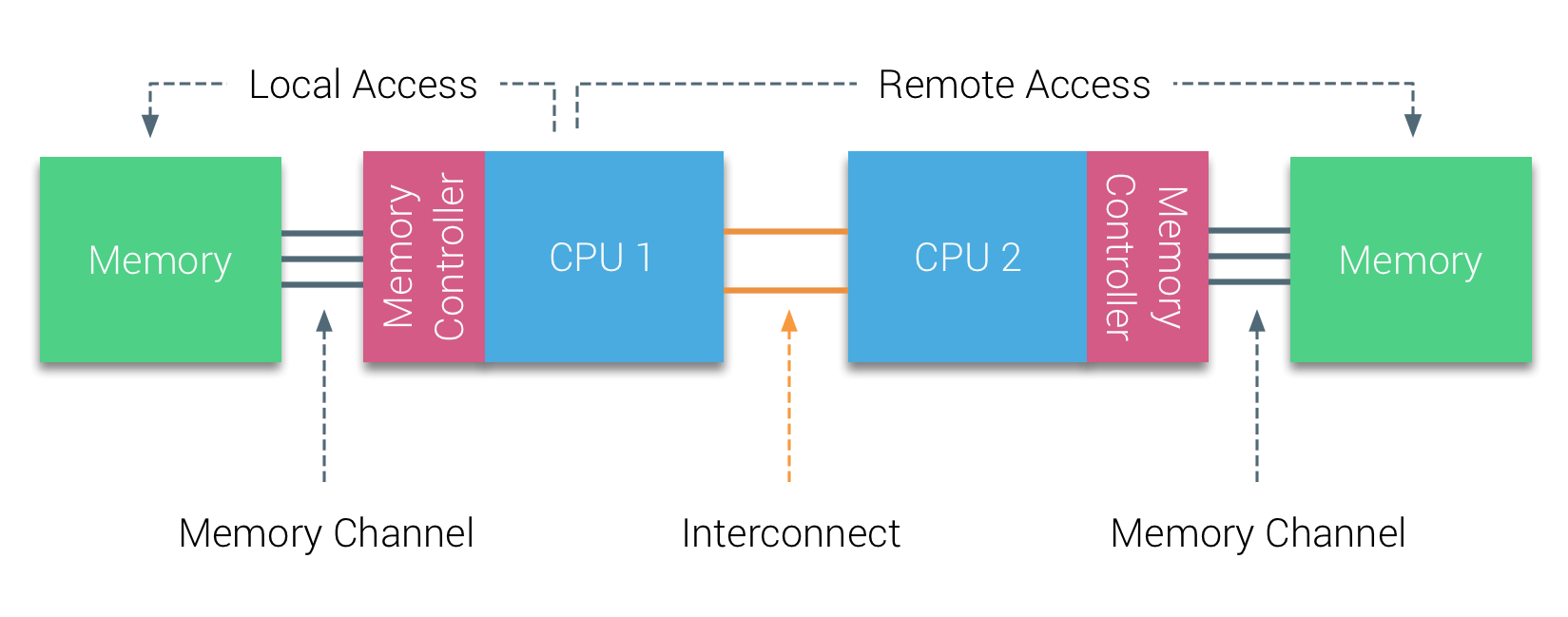
When you have a virtualization layer on top, and you are scheduling workloads, you can take advantage of this by pinning processes to specific CPUs.
In K8s, the API that allows you to enable for a pod is a bit clunky - but it's still possible. This requires you to put your pod in the Guaranteed QoS - where your pod resource.requests = resource.limits. For tightly packed clusters or workloads where elasticity is a must, this may not be feasible.
This guarantees your pod exclusively uses a CPU, and thus most of it a task's memory access should be the CPU's local memory node.
More reading:
- https://frankdenneman.nl/2016/07/07/numa-deep-dive-part-1-uma-numa/
- https://kubernetes.io/blog/2018/07/24/feature-highlight-cpu-manager/
- https://kubernetes.io/docs/tasks/administer-cluster/cpu-management-policies/
- https://www.redhat.com/en/blog/driving-fast-lane-cpu-pinning-and-numa-topology-awareness-openstack-compute