All examples use the Stretcher ruby gem
- An Information Retrieval (IR) System
- A way to search your data in terms of natural language, and so much more
- A distributed version of Lucene with a JSON API
- A fancy clustered, eventually consistent database
Lucene is an information retrieval library providing full-text indexing and search. Elastisearch provides a RESTish HTTP interface, clustering support, and other tools on top of it.
- Data is stored in an index, similar to an SQL DB
- Each index can store multiple types, similar to an SQL table
- Items inside the index are documents that have a type
- All documents are nested JSON data
- Strongly typed schema
# Setup our server
server = Stretcher::Server.new('http://localhost:9200')
# Create the index with its schema
server.index(:foo).create(mappings: {
tweet: {
properties: {
text: {type: 'string',
analyzer: 'snowball'}}}}) rescue nilwords = %w(Many dogs dog cat cats candles candleizer abscond rightly candlestick monkey monkeypulley deft deftly)
words.each.with_index {|w,idx|
server.index(:foo).type(:tweet).put(idx+1, {text: w })
}- The document is a simple JSON hash:
{"text": "word" } - Each document has a unique ID
- We use
put, elasticsearch has a RESTish API
# A simple search
server.index(:foo).search(query: {match: {text: "abscond"}}).results.map(&:text)
=> ["abscond"]- our query is actually a JSON object
- our response is also JSON!
Analysis is the process whereby words are transformed into tokens. The Snowball analyzer, for instance, turns english words into tokens based on their stems.

server.analyze("deft", analyzer: :snowball).tokens.map(&:token)
=> ["deft"]
server.analyze("deftly", analyzer: :snowball).tokens.map(&:token)
=> ["deft"]
server.analyze("deftness", analyzer: :snowball).tokens.map(&:token)
=> ["deft"]
server.analyze("candle", analyzer: :snowball).tokens.map(&:token)
=> ["candl"]
server.analyze("candlestick", analyzer: :snowball).tokens.map(&:token)
=> ["candlestick"]# Will match deft and deftly
server.index(:foo).search(query: {match: {text: "deft"}}).results.map(&:text)
=> ["deft", "deftly"]
# Will match candle, but not candlestick
server.index(:foo).search(query: {match: {text: "candle"}}).results.map(&:text)
# => ["candles"]# NGram
server.analyze("news", tokenizer: "ngram", filter: "lowercase").tokens.map(&:token)
# => ["n", "e", "w", "s", "ne", "ew", "ws"]
# Stop word
server.analyze("The quick brown fox jumps over the lazy dog.", analyzer: :stop).tokens.map(&:token)
#=> ["quick", "brown", "fox", "jumps", "over", "lazy", "dog"]
# Path Hierarchy
server.analyze("/var/lib/racoons", tokenizer: :path_hierarchy).tokens.map(&:token)
# => ["/var", "/var/lib", "/var/lib/racoons"]# Create the index
server.index(:users).create(settings: {analysis: {analyzer: {my_ngram: {type: "custom", tokenizer: "ngram", filter: 'lowercase'}}}}, mappings: {user: {properties: {name: {type: :string, analyzer: :my_ngram}}}})
# Store some fake data
users = %w(bender fry lela hubert cubert hermes calculon)
users.each_with_index {|name,i| server.index(:users).type(:user).put(i, {name: name}) }
# Our analyzer in action
server.index(:users).analyze("hubert", analyzer: :my_ngram).tokens.map(&:token)
# => ["h", "u", "b", "e", "r", "t", "hu", "ub", "be", "er", "rt"]
# Some queries
# Exact
server.index(:users).search(query: {match: {name: "Hubert"}}).results.map(&:name)
=> ["hubert", "cubert", "bender", "hermes", "fry", "calculon", "lela"]
# A Mis-spelled query
server.index(:users).search(query: {match: {name: "Calclulon"}}).results.map(&:name)
=> ["calculon", "lela", "cubert", "bender", "hubert"]# Individual docs can be boosted
server.index(:users).type(:user).put(1000, {name: "boiler", "_boost" => 1_000_000})
server.index(:users).search(query: {match: {name: "bender"}}).results.map(&:name)
# Wha?
# => ["boiler", "bender", "hermes", "cubert", "hubert", "calculon", "fry", "lela"]
server.index(:users).search(query: {match: {name: "lela"}}).results.map(&:name)
# Sweet Zombie Jesus!
=> ["boiler", "lela", "calculon", "bender", "hermes", "cubert", "hubert"]ElasticSearch can report counts of common terms in documents, frequently seen on the left-hand side of web-sites these are 'facets'

POST /bands
PUT /bands/band/_mapping
{"band":{"properties":{"name":{"type":"string"},"genre":{"type":"string","index":"not_analyzed"}}}}
POST /_bulk
{"index": {"_index": "bands", "_type": "band", "_id": 1}}
{"name": "Stone Roses", "genre": "madchester"}
{"index": {"_index": "bands", "_type": "band", "_id": 2}}
{"name": "Aphex Twin", "genre": "IDM"}
{"index": {"_index": "bands", "_type": "band", "_id": 4}}
{"name": "Boards of Canada", "genre": "IDM"}
{"index": {"_index": "bands", "_type": "band", "_id": 5}}
{"name": "Mogwai", "genre": "Post Rock"}
{"index": {"_index": "bands", "_type": "band", "_id": 6}}
{"name": "Godspeed", "genre": "Post Rock"}
{"index": {"_index": "bands", "_type": "band", "_id": 7}}
{"name": "Harry Belafonte", "genre": "Calypso"}
// Perform a search
POST /bands/band/_search
{"size": 0, "facets":{"bands":{"terms":{"field":"genre"}}}}
// A more specific search
POST /bands/band/_search
{"size": 5, "query": {"match": {"name": "Harry"}}, "facets":{"bands":{"terms":{"field":"genre"}}}}
- Generally use an RDBMS(SQL) as primary store
- Elasticsearch data should respond correctly to RDBMS transactions
- Elasticsearch data can be rebuilt from RDBMS any time
- ActiveRecord objects do not necessarily map 1:1 w/ ES objects
- ES should fail gracefully whenever possible. If ES dies, your app should degrade, not stop.
after_save do
es_client.put(self.id, self.as_json)
endBad because:
- Another after_save block fails causing a transaction rollback, won't rollback elasticsearch
- ES goes down, your app goes down
- Even if you handle ES going down, you have to figure out which records need re-indexing when it comes back up
after_save do
# Add to RBDMS queue of objects needing indexing
IndexRequest.create(self)
endGood because:
- Processed in background
- Transaction safe
- If ES dies, our queue backs up
- BONUS: Efficient bulk update now possible

- Indexes are rebuilt w/o using queue
- Multiple DelayedJob workers run mod sharded queries over table
- High-speed, parallel re-imports possible
- New content will use queue
- No (good) Way in ES to change field type.
- Delete / Rebuild may leave site inoperable too long
- Allow N indexes per model
- All indexes are updated in real-time, IndexRequest queue centralizes reqs
- Batch job runs in background retroactively adding new records
- When new index caught up, point queries at it, delete old
- Ability to map models:indexes 1:n. We implemented m:n
- Simultaneous bulk range and real-time indexing
- Fast enough bulk operations that you don't take ∞ time
- Some queries will be large and programmatically generated
- Our largest query > 100 lines expanded JSON
- Sometimes need to run A/B tests between queries
- Each query gets own class
- Plenty of space for DRY helpers within classes
- When running A/B tests, subclassing for variations
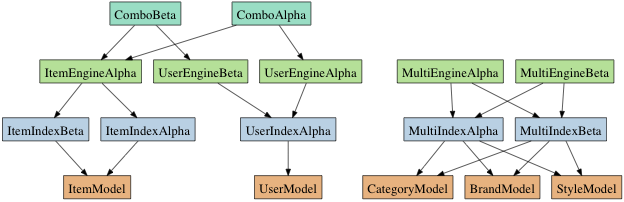

- All queries run across all shards in the cluster
- Shards are allocated automatically to nodes and rebalanced
- A query to any node will work, the actual queries will be executed on the proper shard / node
- Shards are rack aware
- Indexes have a configurable number of replicas, set this based on your failure tolerance
- elasticsearch is easy to set up!
- Just a java jar, all you need is java installed
- Has a .deb package available
- Clustering just works...
- If on a LAN they will find each other and figure everything out
- If on EC2, install the EC2 plugin and they will find each other
- There is no built-in security, but proxying nginx in front works well
- This talk: http://bit.ly/142wv13
- http://www.elasticsearch.org/
- http://exploringelasticsearch.com (my free book on elasticsearch)
- https://github.com/PoseBiz/stretcher
- Paramedic Cluster Monitoring tool: https://github.com/karmi/elasticsearch-paramedic