I recommend you know the basic knowledge Kubernetes Pods before reading this blog. You can check this doc for details about Kubernetes Pods.
Normally, when working with Kubernetes, rather than directly managing a group of replicated Pods, you would like to leverage higher-level Kubernetes objects & workloads to manage those Pods for you. Kubernetes Deployments is one of the most common workloads in Kubernetes that provides flexible life cycle management for a group of replicated Pods.
A Deployment is a Kubernetes object that provides declarative updates, such as scaling up/down, rolling updates, and rolling back, for a group of identical Pods. In other words, A Deployment ensures a group of identical Pods to achieve the desired state.
Rather than directly managing Pods, Deployment utilizes ReplicaSets to perform declarative updates for a group of replicated Pods. The following picture demonstrates the relationship between ReplicaSets and Deployment:
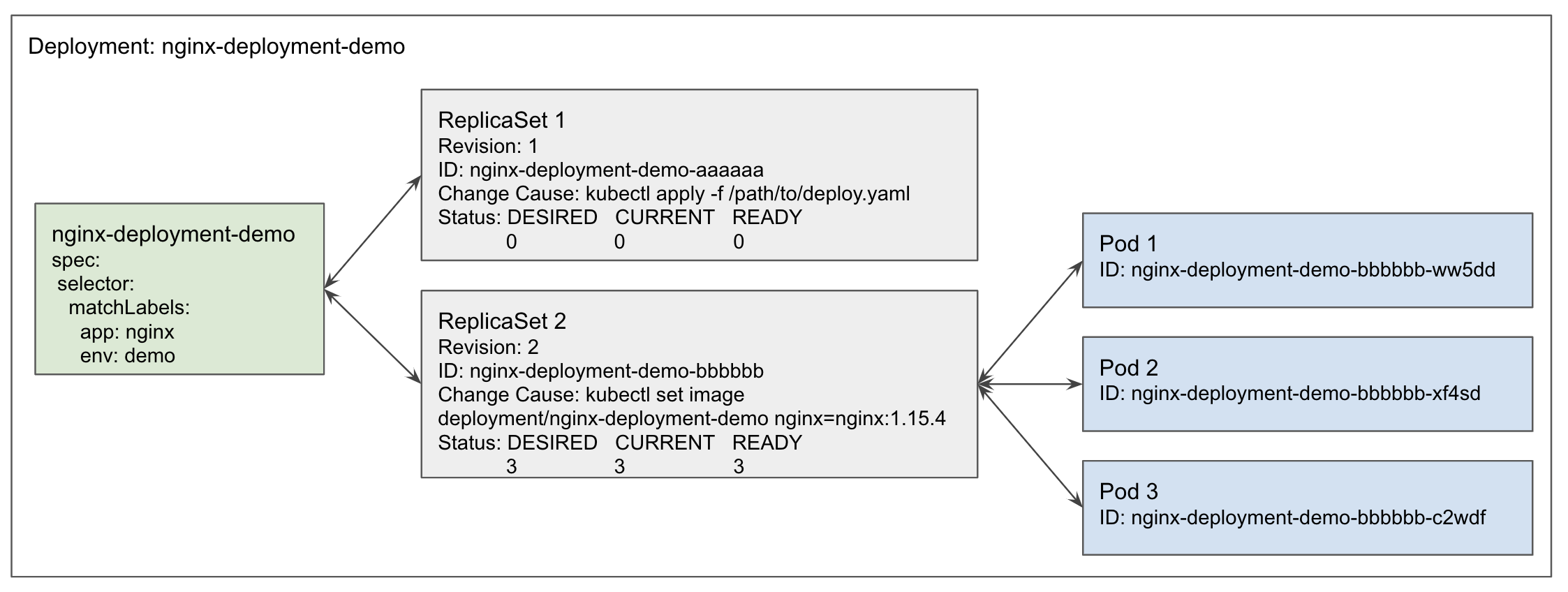
ReplicaSet ensures that a specific number of pod replicas are running at a given time, based on replica number defined in a ReplicaSet manifest. Although it provides an easy way to replicates Pods, it lacks the ability to do rolling updates on pods.
Deployments are built on the top of ReplicaSets. A Deployment essentially is a set of ReplicaSets. It rolls out a new ReplicaSet with the desired number of Pods and smoothly terminates Pods in the old ReplicaSet when a rolling update occurs. In other words, a Deployment performs the rolling update by replacing the current ReplicaSet with a new one. You can check this doc for more details about rolling update or rolling back Deployments.
The following is an example of a Deployment configuration for creating a Nginx server with three replicated Pods.
https://gist.github.com/ef54bc01057f82be160b4cc2c5331076
The field metadata contains metadata of this Deployment, which includes the name of the Deployment and the Namespace it belongs to.
You can also put labels and annotations in the field metadata.
The field spec defines the specification of this Deployment and the field spec.template defines a template for creating the Pods this Deployment manages.
The field spec.selector is used for the Deployment to find which pods to manage.
In this example, the Deployment uses app: nginx && env: demo defined in the field sepc.selector.matchLabels to find
the pods that have labels {app: nginx, env: demo} (defined in the field spec.template.metadata.labels).
The field sepc.selector.matchLabels defines a map of key-value pairs and match requirements are ANDed.
Instead of using the field sepc.selector.matchLabels, you can use the field sepc.selector.matchExpressions to define more sophisticated match roles.
You can check this doc for
more details about the usage of the field sepc.selector.matchExpressions.
As you can see, a Deployment relies on pod labels and pod selector to find its pods. Therefore, it is recommended to put some unique pod labels for a Deployment. Otherwise, Deployment A may end up with managing the pods that belongs to Deployment B.
The field spec.replica specifies the desired number of Pods for the Deployment. Kubernetes guarantees that there are always the spec.replica number of Pods are up and running.
It is Highly recommended to run at least two replicas for any Deployment in Production. This is because having at least two replicas at the beginning can help you keep your Deployments stateless, as the problem can be easily detected when you are trying to introduce "stateful stuff" to a Deployment with at least two replicas. For example, you will quickly realize the problem when you are trying to add a cron job to a two-replicas Deployment to process some data in a daily base: the data will be processed twice a day as all replicas will execute this cron job every day, which may cause some unexpected behaviour. In addition, a singleton pod may cause some downtime in some cases. For example, a single-replica deployment will not be available for a moment when the single Pod is triggered to restart for whatever reason.
The field spec.strategy defines the strategy for replacing old pods with new ones when a rolling update occurs.
The field spec.strategy.type can be Recreate or RollingUpdate. The default value is RollingUpdate.
In general, it is not recommended use Recreate in Production based on the consideration of availability.
This is because Recreate will introduce downtime when a rolling update occurs: All the existing pods need to be terminated before new ones are created when spec.strategy.type is Recreate.
You can use maxUnavailable and maxSurge to control the update process when you set spec.strategy.type == RollingUpdate.
The field maxUnavailable sets the maximum number of Pods that can be unavailable during an update process,
while the field maxSurge specifies the maximum number of Pods that can be created over the desired number of Pods.
The default value is 25% for these two fields. Moreover, they cannot be set 0 at the same time, as this stops the Deployment from performing the rolling update.
you can set the field maxUnavailable 0 as this is the most effective way to prevent your old pods from being terminated while there are some problems spinning up new pods.
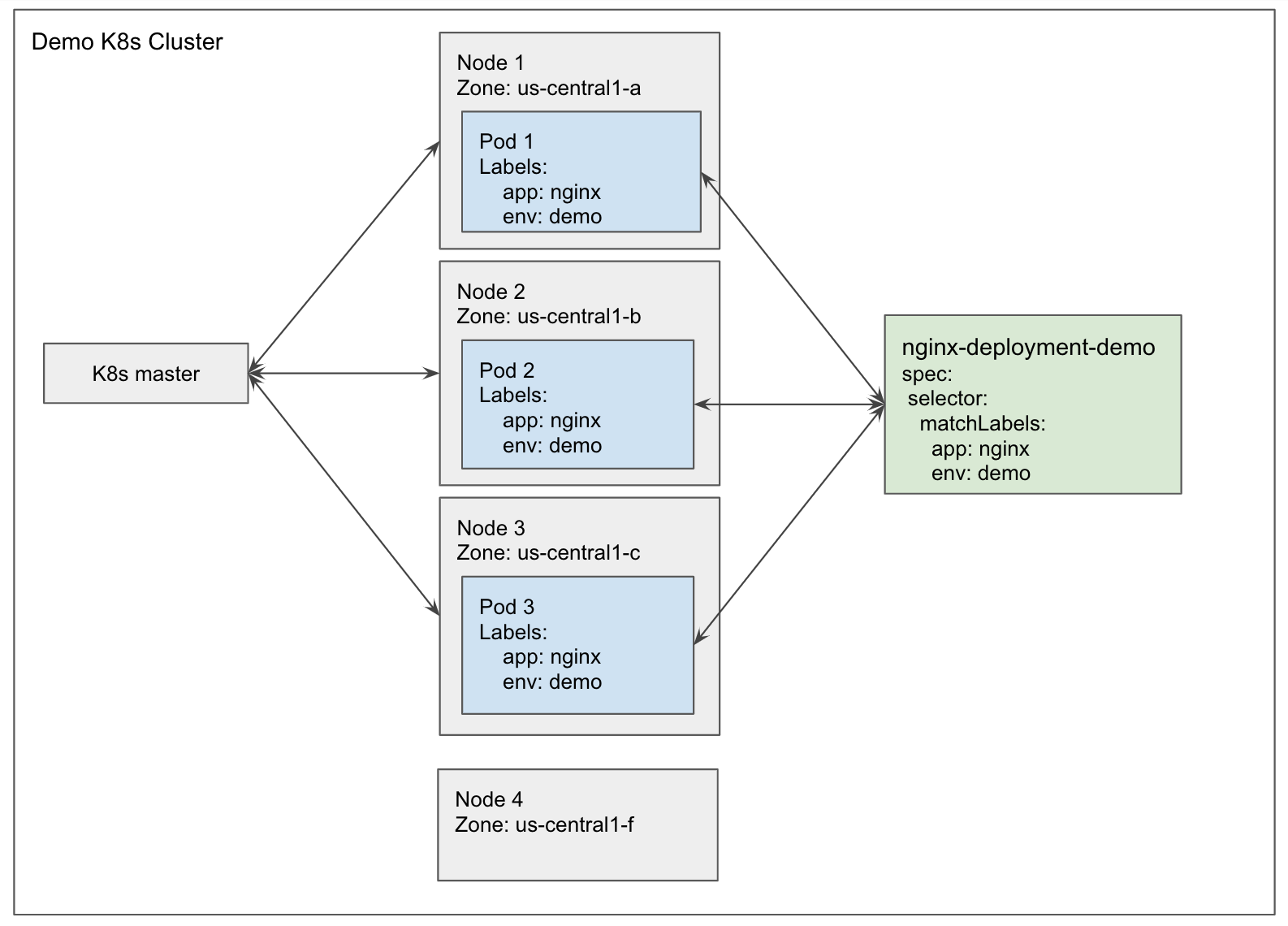
The field affinity inside the field spec.template.spec allows you to specify on which zones/nodes you want to run your Deployment's Pods.
As shown in the following picture, the ideal scenario of running a Deployment is running multiple replicas in different nodes in different zones, and avoid running multiple replicas in the same node.
You can check this doc for more details about how to assign your Deployment's Pods to proper nodes.
You can check this blog if you are curious about how to run stateful applications in Kubernetes.