| Details | |
|---|---|
| Target OS: | Ubuntu* 22.04 LTS |
| Ubuntu* 20.04 LTS | |
| Ubuntu* 18.04 LTS | |
| Windows* 10 | |
| Windows* 11 | |
| Programming Language: | Python* 3.7~3.9 |
| Time to Complete: | 10-12min |
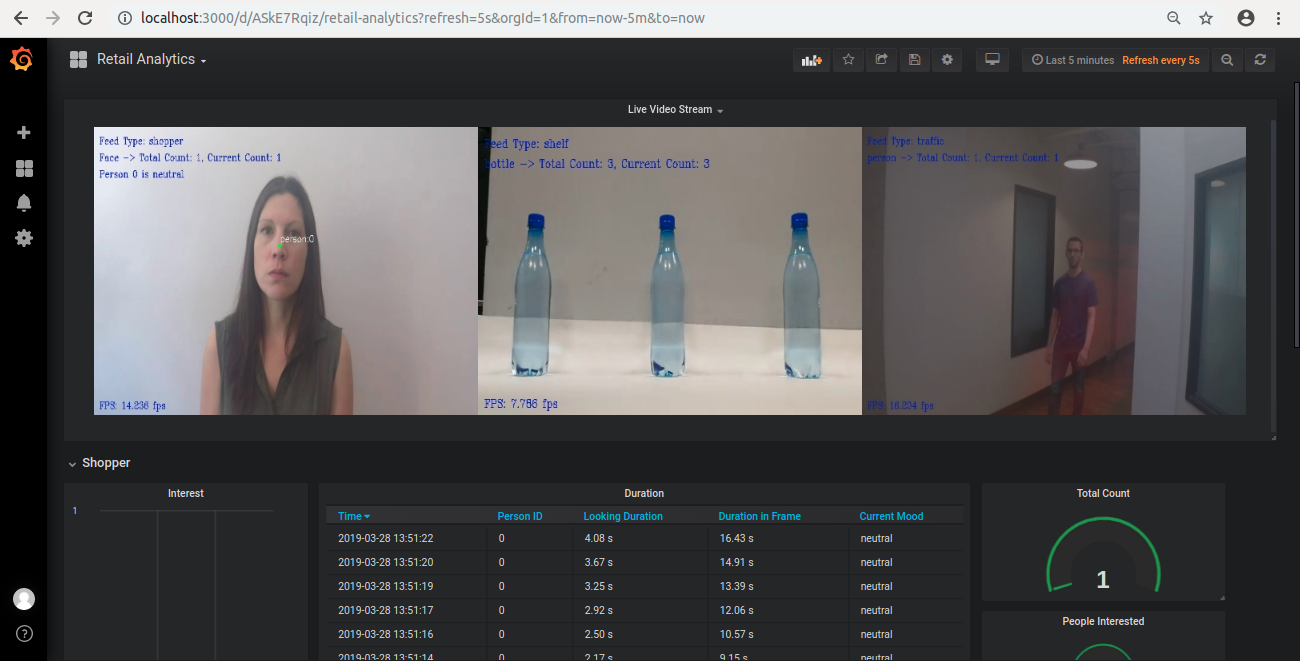
This smart retail analytics application monitors people activity, counts total number of people inside a retail store and keeps a check on the inventory by detecting the products specified by the user. It detects objects on any number of screens by using video or camera resources.
- 6th +.. Generation Intel® Core™ processors with Iris® Pro graphics or Intel® HD Graphics
- Ubuntu* 22.04 LTS
Note: We recommend using a 4.14+ Linux* kernel with this software. Run the following command to determine your kernel version:uname -a - Anaconda
- OpenCL™ Runtime Package
- Intel® Distribution of OpenVINO™ latest release
- Grafana*
- InfluxDB*
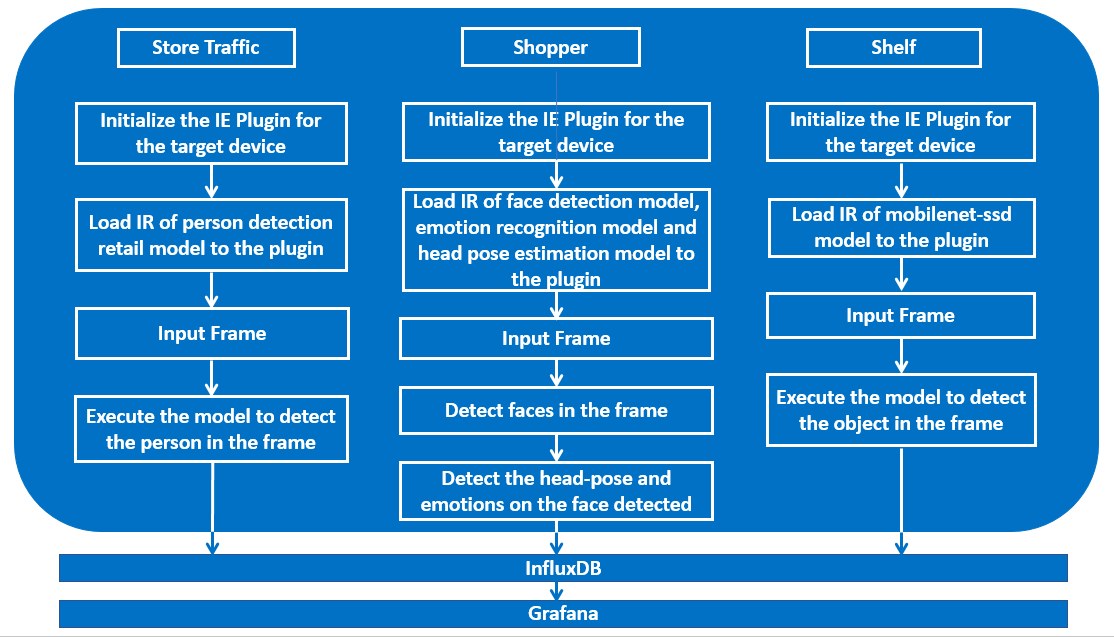
The application uses the Inference Engine included in the Intel® Distribution of OpenVINO™ toolkit. It accepts multiple video input feeds and user can specify the feed type for each video. There are three feed types that application supports:
-
Shopper: If the feed type of the video is shopper, the application grabs the frame from that input stream and uses a Deep Neural Network model for detecting the faces in it. If there is anybody present in the frame, it is counted as a shopper. Once the face is detected, the application uses head-pose estimation model to check the head pose of the person. If the person is looking at the camera then his emotions are detected using emotions recognition model. Using the data obtained from this, it infers if the person is interested or not and gives the total number of people detected. It also measures the duration for which the person is present in the frame and the duration for which he was looking at the camera.
-
Store traffic: If the video feed type is traffic, the application uses a Deep Neural Network model to detect people in the frame. The total number of people visited and the number of people currently present in front the camera is obtained from this.
-
Shelf: This feed type is used to keep a check on the product inventory. If the video feed type is shelf, an object detection model is used to detect the product specified by the user in the frame from this video stream. It detects the objects and gives the number of objects present in the frame.
The application is capable of processing multiple video input feeds, each having different feed type. The data obtained from these videos is stored in InfluxDB for analysis and visualized on Grafana. It uses Flask python web framework to live stream the output videos to the Grafana.
Architectural Diagram
sudo apt-get install python3.9-dev
conda create -n openvino-env python=3.9 -y
conda activate openvino-env
Steps to clone the reference implementation: (smart-retail-analytics)
sudo apt-get update && sudo apt-get install git
git clone https://github.com/intel-iot-devkit/smart-retail-analytics.git
cd smart-retail-analytics
pip install openvino-dev[caffe] ####[caffe,tensorflow,tensorflow2,onnx]
## To view all open-model-zoo available models..
omz_info_dumper --print_all
You will need the OpenCL™ Runtime Package if you plan to run inference on the GPU. It is not mandatory for CPU inference.
InfluxDB is a time series database designed to handle high write and query loads. It is an integral component of the TICK stack. InfluxDB is meant to be used as a backing store for any use case involving large amounts of timestamped data, including DevOps monitoring, application metrics, IoT sensor data, and real-time analytics.
Grafana is an open-source, general purpose dashboard and graph composer, which runs as a web application. It supports Graphite, InfluxDB, Prometheus, Google Stackdriver, AWS CloudWatch, Azure Monitor, Loki, MySQL, PostgreSQL, Microsoft SQL Server, Testdata, Mixed, OpenTSDB and Elasticsearch as backends. Grafana allows you to query, visualize, alert on and understand your metrics no matter where they are stored.
The AJAX Panel is a general way to load external content into a grafana dashboard.
The application uses Intel® Pre-Trained models in the feed type shopper i.e.face-detection-adas-0001, head-pose-estimation-adas-0001, emotion-recognition-retail-0003. For the feed type traffic, person-detection-retail-0002 is used and these can be downloaded using model downloader script.
For video feed type shelf, mobilenet-ssd model is used that can be downloaded using downloader script present in Intel® Distribution of OpenVINO™ toolkit.
The mobilenet-ssd model is a Single-Shot multibox Detection (SSD) network intended to perform object detection. This model is implemented using the Caffe* framework. For details about this model, check out the repository.
To install the dependencies and to download the models and optimize, run the below command:
##cd <path to smart-retail-analytics directory>
sudo apt-get update
sudo apt install curl
sudo curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
sudo apt-get install influxdb
sudo service influxdb start
wget -O grafana_5.3.2_amd64.deb https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_5.3.2_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_5.3.2_amd64.deb
sudo grafana-cli plugins install ryantxu-ajax-panel
sudo apt-get install python3-pip
sudo pip3 install influxdb numpy flask jupyter networkx google --upgrade google-api-python-client
-
Open new terminal and type below cmds
sudo apt install influxdb-client service influxdb start influx CREATE DATABASE Retail_Analytics exit -
These below cmd will be downloaded models in the required locations:
###cd to smart-retail-analytics/resources cd resources omz_downloader --name person-detection-retail-0013,face-detection-adas-0001,head-pose-estimation-adas-0001,emotions-recognition-retail-0003,person-detection-retail-0002,mobilenet-ssd,ssd300 --output_dir models -
To install the download the models and optimize mobilenet-ssd model, run the below command:
mo --input_proto models/public/ssd300/models/VGGNet/VOC0712Plus/SSD_300x300_ft/deploy.prototxt --input_model models/public/ssd300/models/VGGNet/VOC0712Plus/SSD_300x300_ft/VGG_VOC0712Plus_SSD_300x300_ft_iter_160000.caffemodel --data_type FP16 --output_dir ir -
Download the videos inside resources:
wget -O face-demographics-walking.mp4 https://github.com/intel-iot-devkit/sample-videos/raw/master/face-demographics-walking.mp4 wget -O bottle-detection.mp4 https://github.com/intel-iot-devkit/sample-videos/raw/master/bottle-detection.mp4 wget -O head-pose-face-detection-female.mp4 https://github.com/intel-iot-devkit/sample-videos/raw/master/head-pose-face-detection-female.mp4 cd ..
The shelf feed type in the application requires a labels file associated with the model being used for detection. All detection models work with integer labels and not string labels (e.g. for the ssd300 and mobilenet-ssd models, the number 15 represents the class "person"), that is why each model must have a labels file, which associates an integer (the label the algorithm detects) with a string (denoting the human-readable label).
The labels file is a text file containing all the classes/labels that the model can recognize, in the order that it was trained to recognize them (one class per line).
For mobilenet-ssd model, labels.txt file is provided in the resources directory.
The resources/config.json contains the videos along with the video feed type.
The config.json file is of the form name/value pair, "video": <path/to/video> and "type": <video-feed-type>
For example:
{
"inputs": [
{
"video": "path-to-video",
"type": "video-feed-type"
}
]
}
The path-to-video is the path, on the local system, to a video to use as input.
If the video type is shelf, then the labels of the class (person, bottle, etc.) to be detected on that video is provided in the next column. The labels used in the config.json file must be present in the labels from the labels file.
The application can use any number of videos for detection (i.e. the config.json file can have any number of blocks), but the more videos the application uses in parallel, the more the frame rate of each video scales down. This can be solved by adding more computation power to the machine the application is running on.
The application works with any input video. Sample videos for object detection are provided here.
For first-use, we recommend using the face-demographics-walking, head-pose-face-detection-female, bottle-detection videos. The videos are automatically downloaded in the resources/ folder by setup.sh.
For example:
The config.json would be:
{
"inputs": [
{
"video": "sample-videos/head-pose-face-detection-female.mp4",
"type": "shopper"
},
{
"video": "sample-videos/bottle-detection.mp4",
"label": "bottle",
"type": "shelf"
},
{
"video": "sample-videos/face-demographics-walking.mp4",
"type": "traffic"
}
]
}
To use any other video, specify the path in config.json file
Replace path/to/video with the camera ID in config.json and the label to be found, where the ID is taken from the video device (the number X in /dev/videoX).
On Ubuntu, to list all available video devices use the following command:
ls /dev/video*
For example, if the output of above command is /dev/video0, then config.json would be:
{
"inputs": [
{
"video": "0",
"type": "shopper"
}
]
}
Change the current directory to the git-cloned application code location on your system:
###cd to smart-retail-analytics/application
cd application
- Replace the inference file
###Download the latest inference.py file replace with old
sudo rm -r inference.py
wget https://gist.githubusercontent.com/bharath5673/5368e610b312b02d2c666e403959e53a/raw/4fcec6f4dad5ac13da90f3de7e3dc1feaac7da34/inference.py
-
A user can specify a target device to run on by using the device command-line argument
-d_<model-acronym> (Ex. d_fm, d_pm, d_mm, d_om or d_pd)followed by one of the valuesCPU,GPU,MYRIADorHDDL. -
Not specifying any target device means by default all the models will run on CPU, although this can also be explicitly specified by the device command-line argument
-
To run the application :
python3 smart_retail_analytics.py -fm ../resources/models/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm ../resources/models/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm ../resources/models/intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -om ../resources/ir/VGG_VOC0712Plus_SSD_300x300_ft_iter_160000.xml -pr ../resources/models/intel/person-detection-retail-0002/FP16/person-detection-retail-0002.xml -lb ../resources/labels.txt -d_pd CPU -d_fm CPU -d_pm CPU -d_mm CPU -d_om CPU
Once the command is executed in the terminal, configure the Grafana dashboard using the instructions given in the next section to see the output.
To run the application on sync mode, use -f sync as command line argument. By default, the application runs on async mode.
The application can use different hardware accelerator for different models. The user can specify the target device for each model using the command line argument as below:
-d_fm <device>: Target device for Face Detection network (CPU, GPU, MYRIAD, HETERO:FPGA,CPU or HDDL).-d_pm <device>: Target device for Head Pose Estimation network (CPU, GPU, MYRIAD, HETERO:FPGA,CPU or HDDL).-d_mm <device>: Target device for Emotions Recognition network (CPU, GPU, MYRIAD, HETERO:FPGA,CPU or HDDL).-d_om <device>: Target device for mobilenet-ssd network (CPU, GPU, MYRIAD, HETERO:FPGA,CPU or HDDL).-d_pd <device>: Target device for Person Detection Retail network (CPU, GPU, MYRIAD, HETERO:FPGA,CPU or HDDL).
For example:
To run Face Detection model with FP16 and Emotions Recognition model with FP32 on GPU, Head Pose Estimation model on MYRIAD, mobilenet-ssd and person-detection model on CPU, use the below command:
python3 smart_retail_analytics.py -fm ../models/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm ../models/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm ../models/intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -om ../ir/VGG_VOC0712Plus_SSD_300x300_ft_iter_160000.xml -pr ../models/intel/person-detection-retail-0002/FP16/person-detection-retail-0002.xml -lb ../resources/labels.txt -d_fm GPU -d_pm MYRIAD -d_mm GPU -d_pd CPU -d_om CPU
To run with multiple devices use MULTI:device1,device2. For example: -d_fm MULTI:CPU,GPU,MYRIAD
Note:
- The Intel® Neural Compute Stick and Intel® Movidius™ VPU can only run FP16 models. The model that is passed to the application, must be of data type FP16.
FP32: FP32 is single-precision floating-point arithmetic uses 32 bits to represent numbers. 8 bits for the magnitude and 23 bits for the precision. For more information, click here
FP16: FP16 is half-precision floating-point arithmetic uses 16 bits. 5 bits for the magnitude and 10 bits for the precision. For more information, click here
To run the application on Intel® Movidius™ VPU, configure the hddldaemon by following the below steps:
-
Open the hddl_service.config using the below command:
sudo vi ${HDDL_INSTALL_DIR}/config/hddl_service.config -
Update "device_snapshot_mode": "None" to "device_snapshot_mode": "full".
-
Update HDDL configuration for tags.
"graph_tag_map":{"tagFace":1,"tagPose":1,"tagMood":2,"tagMobile":2,"tagPerson":2} -
Save and close the file.
-
Run hddldaemon.
${HDDL_INSTALL_DIR}/bin/hddldaemon
To run the application on the Intel® Movidius™ VPU, use the -d HDDL command-line argument:
python3 smart_retail_analytics.py -fm ../models/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm ../models/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm ../models/intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -om ../ir/VGG_VOC0712Plus_SSD_300x300_ft_iter_160000.xml -pr ../models/intel/person-detection-retail-0002/FP16/person-detection-retail-0002.xml -lb ../resources/labels.txt -d_pd HDDL -d_fm HDDL -d_pm HDDL -d_mm HDDL -d_om HDDL
- Open a new tab on the terminal and start the Grafana server using the following command:
sudo service grafana-server start
-
In your browser, go to localhost:3000.
-
Log in with user as admin and password as admin.
-
Click on Configuration.
-
Select “Data Sources”.
-
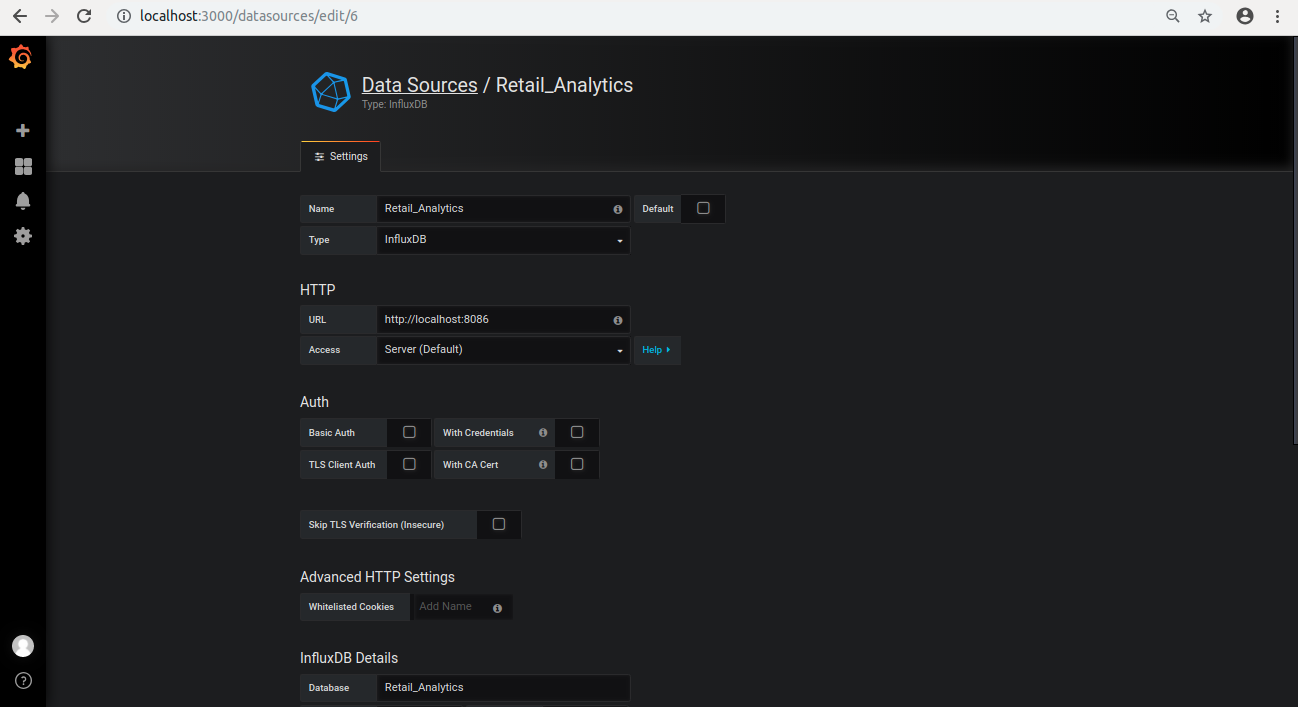
Click on “+ Add data source” and provide inputs below.
- Name: Retail_Analytics
- Type: InfluxDB
- URL: http://localhost:8086
- Database: Retail_Analytics
- Click on “Save and Test”
-
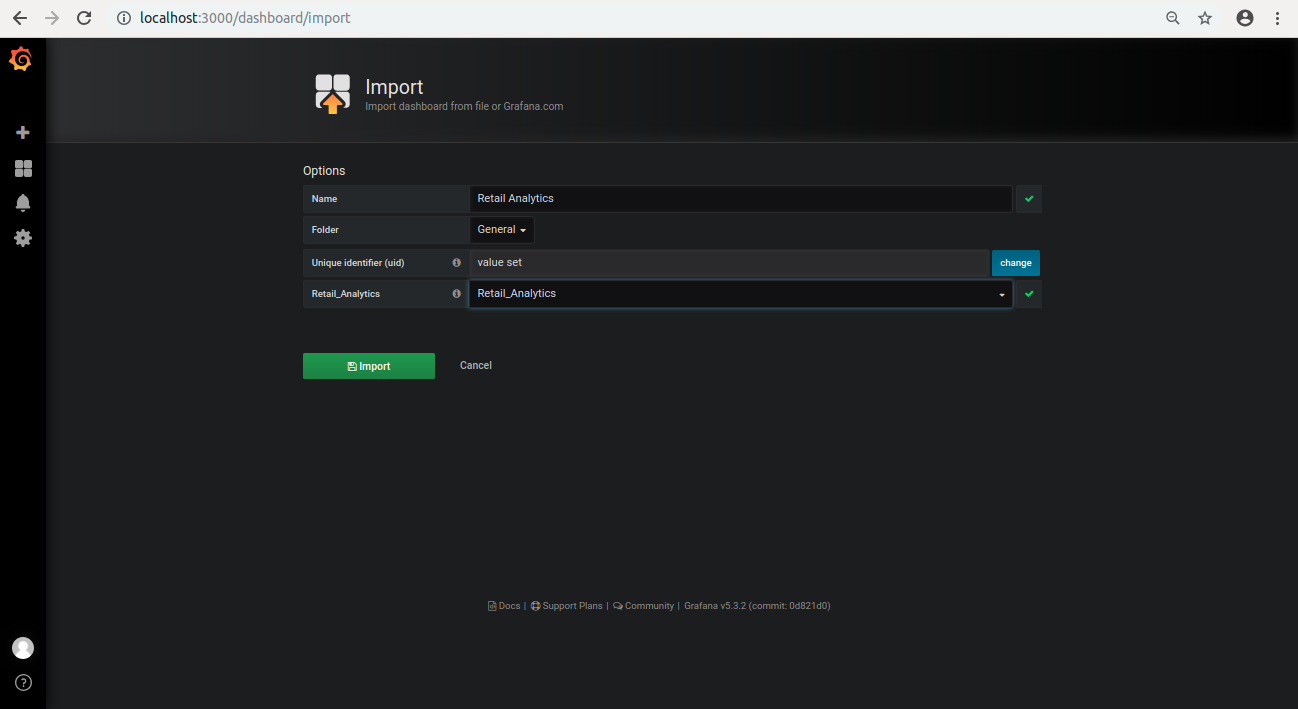
Click on + icon present on the left side of the browser, select import.
-
Click on Upload.json File.
-
Select the file name retail-analytics.json from smart-retail-analytics-python directory.
-
Select "Retail_Analytics" in Select a influxDB data source.
-
Click on import.
To containerize the smart-retail-analytics-python application using docker container, follow the instruction provided here.
Windows Requisites
download influxdb and create db
from
https://dl.influxdata.com/influxdb/releases/influxdb-1.6.5_windows_amd64.zip--help
https://www.youtube.com/watch?v=DmIWgkawcw4&t=96s&ab_channel=AbhishekJaindownload Grafana and run server
from
https://dl.grafana.com/enterprise/release/grafana-enterprise-8.5.4.windows-amd64.zipinstall ajax plugin on grafana
run application