Note: This was previously introduced last year, given the noise and confusion generated, I am opening a new issue to hopefully explain and answer questions more directly (you don't need the background of these issues, it would take some time to consume them and they are incomplete, but they are #3745 and a larger topic on text-transforms, design and theory in #3775)
The rendering of mathematical text employs common conventions that allow authors to express and readers to understand their meaning. Sometimes this involves how they are laid out, but often it is in the particulars of character's rendering. To this end, Unicode defines a range for Mathematical Alphanumeric Symbols and particular stylistic variants which can convey additional local contextual value and convey meaning. As one example: it is possible for an equation to employ two variants of the same character representing different things, as in the example below from Unicode of a well known equation requiring this. At the top is how it is intended to be understood, with distinctly rendered H's and below is how it would be (incorrectly/confusingly) be understood without this distinction.
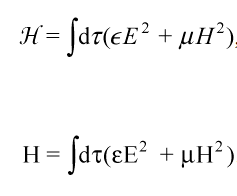
This is quite a complex topic for a wide range of reasons and various distinctions can be more or less important at various levels. Because of this, Unicode has added support for thousands of numerical 'symbols', including invisibles, allowing decent encoding of mathematics as text with its own 'alphabet', even where there is look-alike overlap, for example, Mathematical sigmas are not the same as related Greek letters despite their recognizable appearance in much the same way that in everyday text O and 0 or 1 and l are distinct characters, and their applications and have various uses/treatments (see https://en.wikipedia.org/wiki/Sigma#Science_and_mathematics and https://en.wikipedia.org/wiki/Sigma#Mathematical_Sigma)
MathML offered structure and markup oriented solutions which didn't require access to characters in Plane 1 of Unicode. In a very general way, the structures provided by MathML are useful in that they fit the DOM/markup model, allow styling, and you can thus lay good default rules upon them: Single character identifiers (<mi>) for example are rendered as italics by default according to normal conventions. Thus, the following MathML...
<math display="block">
<mrow>
<msup>
<mi>x</mi>
<mn>2</mn>
</msup>
<msup>
<mi>y</mi>
<mn>2</mn>
</msup>
</mrow>
</math>
Would render with the identifiers x and y as italic mathematical identifiers as:
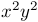
MathML allows that you can override these as necessary or provide the additional distinctions. Because of where it fits in history, MathML co-evolved a solution of overiding by providing an attribute called mathvariant which allowed values of what are now the Unicode variant names. For example, if we want to express an equation about a real number ala
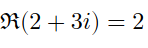
The Fraktur R is in Plane 1. In addition to allowing authors to eventually use the unicode character (ℜ), MathML historically provided the mathvariant allowing authors (and tools) to express this as
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mi mathvariant="fraktur">R</mi>
<mo stretchy="false">(</mo>
<mn>2</mn>
<mo>+</mo>
<mn>3</mn>
<mi>i</mi>
<mo stretchy="false">)</mo>
<mo>=</mo>
<mn>2</mn>
</math>
As in the example from Unicode (provided in Backgound) above, this may, or may not be critically significant for a given case - but it is important that this distinction is maintained as text as much as possible for copy/paste operations or for speech subsystems. While the spec recommends that authors use the unicode characters directly where it is important, since a large corpus of millions of MathML equations exist, and numerous tools for creating it currently rely on understanding the mathvariant attribute, it must be maintained and supported.
Based on 3 implementations experience, MathML-Core accomplshes this largely by mapping this legacy attribute to CSS's infrastructure and text-transform values.
MathML-Core largely codifies the mapping and seeks to expose this to authors and increase interoperability, it extends CSS Text L3 with new values for text-transform that play this role in mapping alphanumeric text to the equivalent Mathematical Alphanumeric Symbols as
[none | [capitalize | uppercase | lowercase ] || full-width || full-size-kana | [capitalize | uppercase | lowercase ] || [ math-auto | math-bold | math-italic | math-bold-italic | math-double-struck | math-bold-fraktur | math-script | math-bold-script | math-fraktur | math-sans-serif | math-bold-sans-serif | math-sans-serif-italic | math-sans-serif-bold-italic | math-monospace | math-initial | math-tailed | math-looped | math-stretched ]
math-auto is the default value for text-transform of MathML elements. It follows convention and automatically renders single letter identifiers with mathematical italics, and others normally.
Proposal details at https://mathml-refresh.github.io/mathml-core/#new-text-transform-values Tentative tests are at web-platform-tests/wpt#16922