For my final project, I have continued work on the Exchatter framework. Exchatter is a Node.js framework for creating personalized chat bots.
While Exchatter is far from complete, my project exhibits some of the core algorithms that will be used in the release such as:
- Text normalization
- Cosine Similarity
- Levinshtein Distance
- Sentiment analysis
This version of Exchatter receives text messages, analyzes a large personal SMS corpus, and responds with a message from that corpus that it finds to be most appropriate. If Exchatter does not find a similar message in the corpus, it defaults to using Cleverbot for a response. If there is an error using Cleverbot, a message from Eliza will be produced instead.
Note: One significant difference between this version of Exchatter and the final release is that it does not currently do any text generation. Exchatter also uses no hard-coded rules. All responses are produced using text similarity algorithms.
Text (949) 247-8255 to chat with an Exchatter modeled after me (Brannon Dorsey). Text response times are calculated based on my SMS metadata over the past 2 years, so it might take a little while for me to respond.
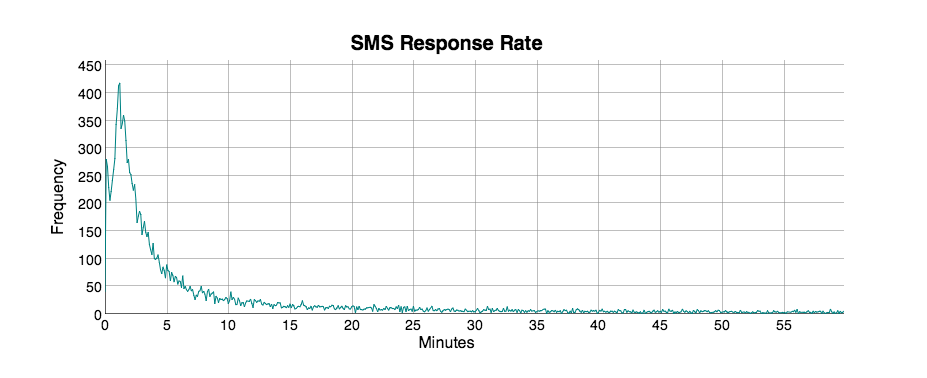
If you don't get a response within the hour, the server may be down. Follow this link to check if Exchatter is working. If it throws a 502 Exchatter is temporarily down.
There are also some major problems with Exchatter as it exists now. Most namely, it is far too specific. Because Exchatter relies heavily on a corpus of prior messages, often times messages sent to it yield unpredictable responses because: 1) No similar messages exist in the corpus, or 2) similar messages in the corpus rely heavily on the context of the original conversation that they were used in. Sometimes Exchatter just gives a response that is completely wrong. However, often the humor in the mistake is better than the proper response.
Exchatter also seems to only provide accurate messages to very general prompts like "how are you?", "what are you doing?", "what's up", etc... It struggles with conversation more elaborate than that. You sort of have to play into Exchatter's responses in order to maintain a semi-coherent conversation.
Exchatter is far from complete. Here are the main things that need to be implemented (or improved):
- Better similarity matching
- Text generation
- Rule based fallbacks
- Sentiment influence (currently only being analyzed)
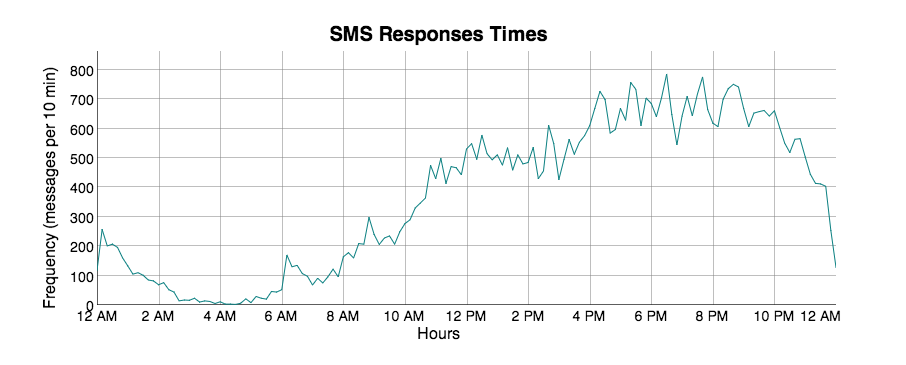
- Response rates that factor in time of day (see below)
For a full list of proposed features check out the Exchatter feature list. For a glimpse of how Exchatter will be used, check out the proposed API.