You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
How to prove the null hypothesis with the evidence
Data Collection and Decision Making
Collect data and use decision rule to reject or not reject hypothesis
Take Action Based on Decision
Do shit with the results.
Type Errors
Type I | a | False Positive - Accepting a hypothesis that is not actually true, aka level of significance
Type II | b | False Negative - Not accepting a hypothesis that is actually true
Both have consequences, but false negatives can be a bit more consequential.
Relationship Between a(type I) and b(type II)
Powerful test is a smaller probablity of B. The best way to reduce them together is by increasing sample size, but is not always practical.
u<sub>0</sub> - the benchmark
This isn't from _our sample_, this is derived from a standard or a spec.
It's how we compare our sample u against this benchmark.
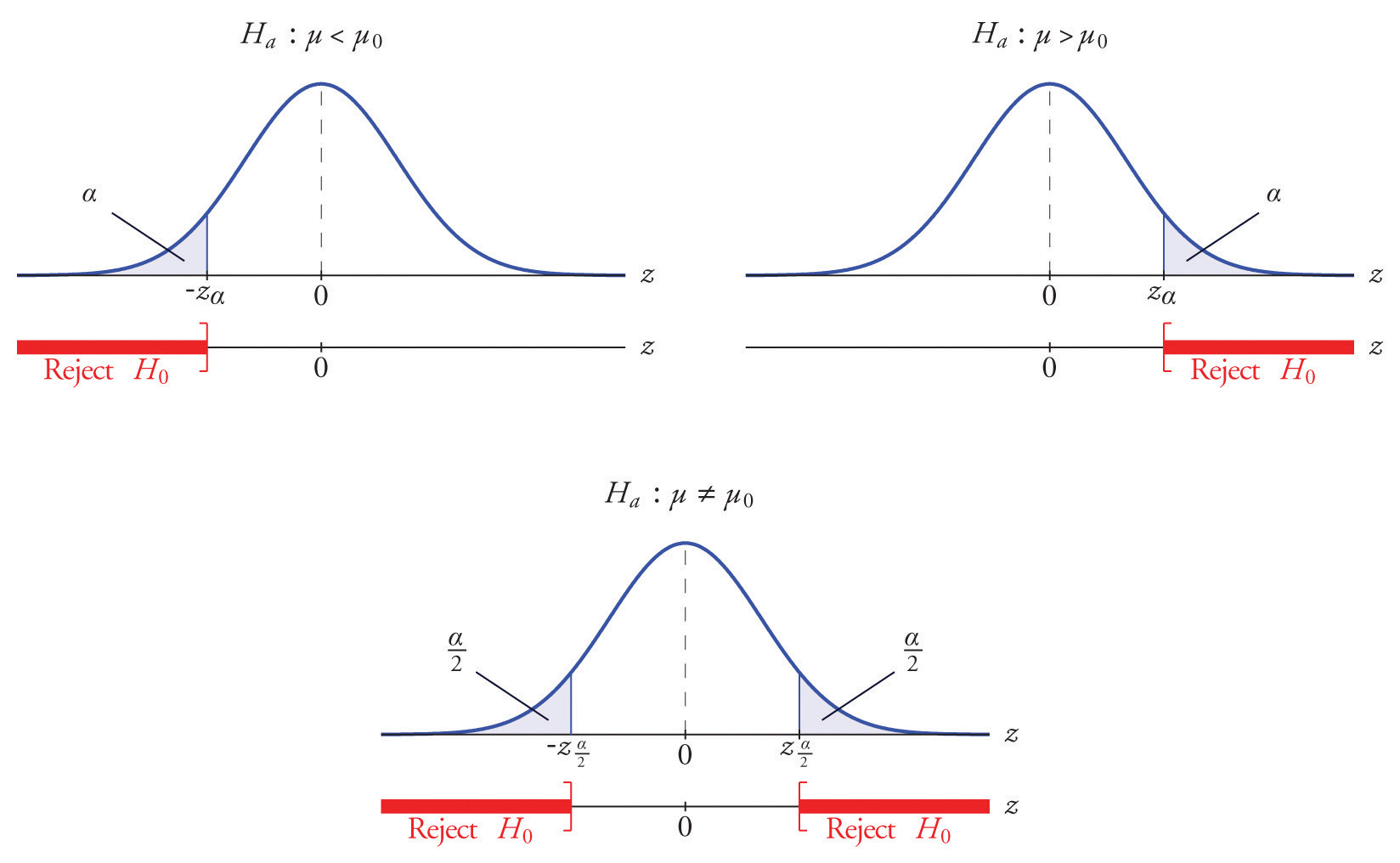
When we determine tailed-test we look at the direction of the inequality points in H1
Left-Tailed: u < u0
Two-Tailed: u != u0
Right-Tailed: u > u0
Decision Rule
This is the deciding factor of the outcome of our test. Every test is a comparison against the null hypothesis (a "truthy" standard, unless known otherwise) to understanding if an extreme outcome is occuring, causing us to REJECT the hypothesis.
Rejection Region - Area under the curve which represents an extreme outcome Test Statistics - The difference of the sample statistics and the hypothesized parameter, when it falls in the rejection region it will result in a fail test.
comparison of tailed test
Crtical Value - Basically the bounds of when to reject H0, or not to (z or t value based on known std). Decision Rule - Based on step 2, it will define what the critical value is based on our level of significance (a | prob of type I error).
We are looking for a small value of a preferably. For example, in a normal distribution, 95% is a benchmark of a standard level of acceptance, thus we would want less than 5% of a chance for type I errors (false positives, rejecting a true hypothesis) to occur.... a = .05 (.05/2 for each tail if it's a two-tailed test). But if we increase our level of acceptance, 99%, we can only deny our hypothesis if extremes occur within 1%, a = .01.
The z-score is the test statistics if we know u and std, and represents our standardized score for the sample statistics.
The z calculated score should be near 0 if the sample mean is close to the true mean of the population.
Critical Value
We compare our calculated z-score to the critical value stated in our hypothesis, this will determine if to reject hypothesis or not.
In a two tailed test, we know the risk is split between both tails (a/2).
P-Value Method
Another way that is preferred because you account for the strength in your evidence against the null hypothesis. It's a measure of the chance of the observed sample