はじめまして!株式会社Sun Asteriskでエンジニアをやっているチョンと申します!
この記事はSun* Advent Calendar 2022の22日目の記事です。
機械学習分野がますます注目されていて、ますます重要になっています。私も8年前にSun Asteriskで参加したプロジェクトで自然言語処理と機械学習を導入する機会がありましたので、本記事ではその事例について分かりやすく共有できればと思います。
この事例では、以下の画像のように、特定のHTML記事を入力として、コンテンツ解析を行って、DBから関連記事を検索したり、自動的にカテゴリを分類する必要がありました。

これらの機能につては自然言語処理・機械学習の手法を使って実装しました。本記事では深い処理までではなく、実装アプローチの所だけを共有したいと思います。
アプローチはこんな感じで、学習パートと応用パートがあります。
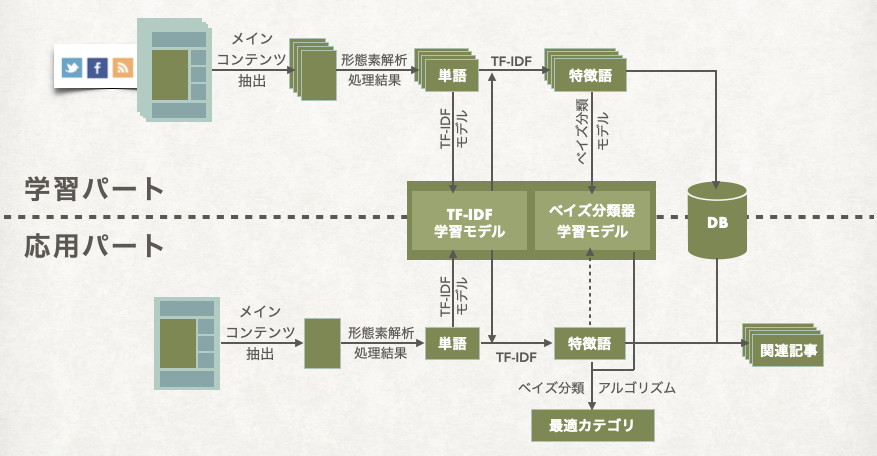
学習パートは大きく分けて
- 長期間コンテンツ収集
- 形態素解析処理
- 特徴語抽出
- 学習モデル作成
の4つの処理があります。それぞれについて説明いたします。
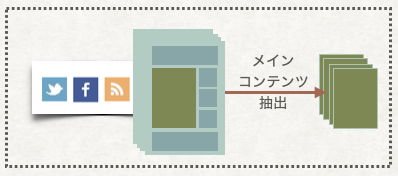
機械学習には信頼度が高い学習データが多く必要です。SNSやRSSなどから2年間で1000万件以上のHTML記事を収集しましたが、コンテンツ解析の信頼度を高めるため、記事のメインコンテンツの部分のみ抽出する必要がありました。一般のHTML記事にはメインコンテンツ以外、ヘッダー・フッターや関連記事枠などの不要な部分があり、コンテンツ解析する前にそれらの部分を外しておかないといけないということです。そうするためには、試行錯誤により特別扱いが必要なHTML構成のパターンを記録し、それらのパターンにそって処理を行いました。
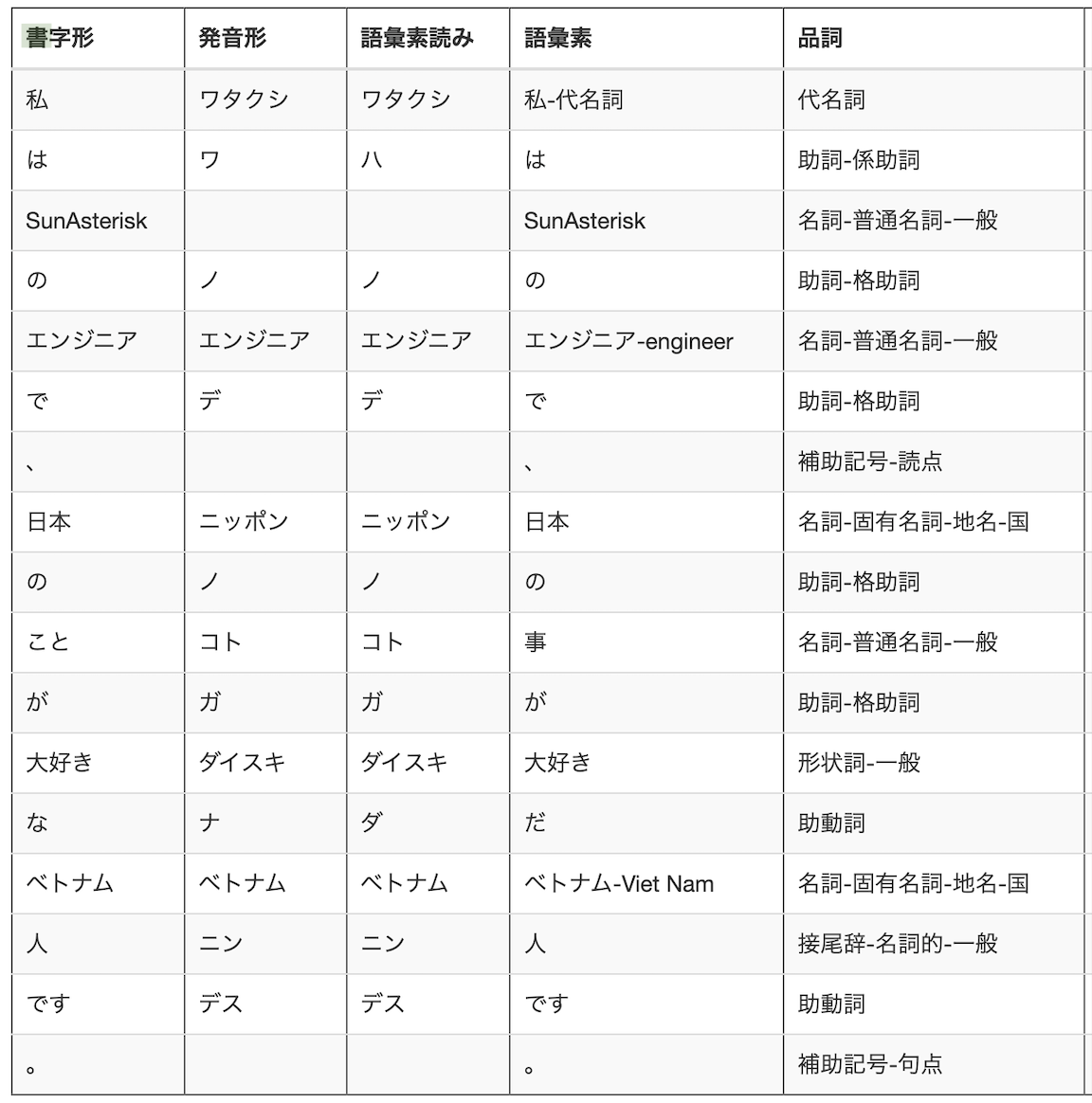
簡単に言うと、特定の文書に入っている単語とその品詞を解析することです。
例えば、「私はSunAsteriskのエンジニアで、日本のことが大好きなベトナム人です。」の文の解析結果はこんな感じです。
今回の事例の場合、記事のトピック(どこ、誰、何などの情報)を判定する必要がありましたが、それは記事に入ってる名詞でほぼ判定できるため、解析結果のうち名詞だけ利用しました。
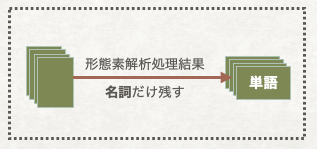
名詞だけ残しても、残っている単語がまだ多くありますし、どの単語のほうが重要なのか分からない状況です。この段階で、初めての学習モデルを作成しはじめました。これはTF-IDF学習モデルと言います。
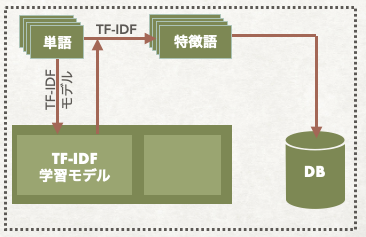
特定の文書に含まれる単語の重要度を評価できる手法です。公式は以下の通りですが、簡単に概要を説明すると、本記事にはたくさん出ていて、他の記事にはまあり出てこない単語の重要度を高くするというイメージです。
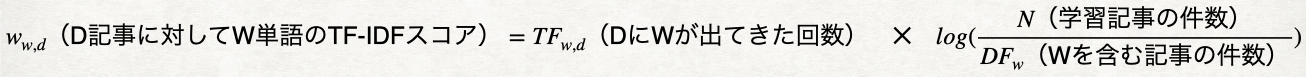
TF-IDF学習モデルに何を記録したかというと、単純に学習コンテンツの中に何の単語が何回出てきたかの集計データだけでした。学習データが充分な件数になったらTF-IDFで単語の重要度を計算出来まます。その計算ができてからそれぞれの記事に対して、重要度が高い上位20件を 「特徴語」 と呼んで、データベースにも保存しました。
特徴語を抽出できてから、もうひとつの学習モデルを作成しました。名前は単純ベイズ確率モデルです。
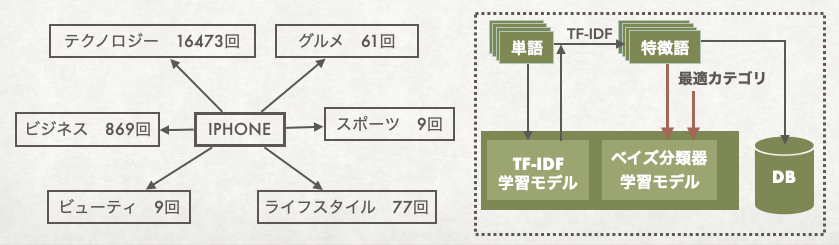
最初から「テクノロジー」、「スポーツ」、「ビジネス」などのカテゴリの集合を定義して、それぞれの学習コンテンツに最適なカテゴリをアサインしておきました。この学習モデルに何を学習させたかというと、各特徴語がそれぞれのカテゴリに何回出来きたかの集計データです。モデルの名前もどういうふうに応用できるかも応用パートで説明します。
これで学習パートについての説明が終わりましたので、特徴語抽出の例を一つ出したいと思います。特徴語だけをみてもだいたい記事のトピックを判断出来ますね!

では、これから応用パートについて説明します。
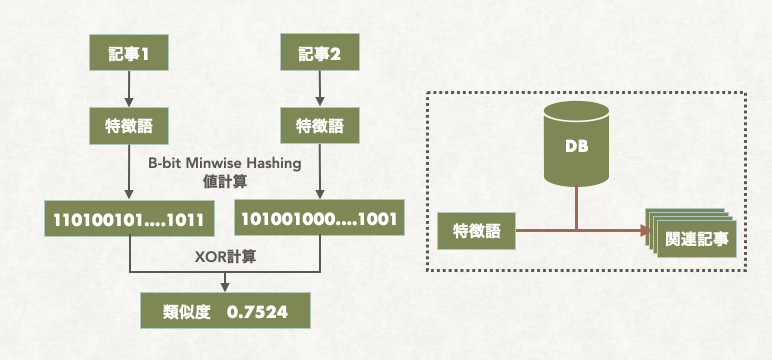
まずは関連記事検索についてですが、2つの記事の類似度を計算する必要があります。2つの単語の集合を2進数に変換して、類似度を高速で計算できるb-bit minwise hashingという手法を使いました。
記事Aの関連記事を検索する流れとしては、Aと同じ特徴語を持つ記事をデータベースから検索して、それぞれのペアの類似度を計算して、類似度は0.4~0.8であれば関連記事として判定しました。0.8以上をカウントしないのは同記事の可能性が高いからです。
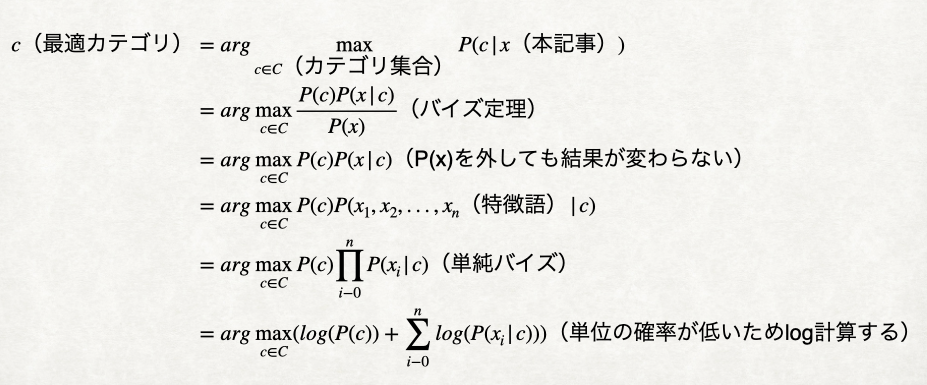
公式はこの画像の通りですが、単純ベイズ分類器を深く理解するために「バイズ定理」や「単純バイズ」などの理論の理解が必要です。簡単に説明すると単純ベイズ分類器は確率的な分類器で、特定の記事が特定のカテゴリの記事である確率を、そのカテゴリの中にその記事の各特徴語が出て来る確率で計算出来るものです。「テクノロジー」のカテゴリによく出てくる単語をたくさん持っている記事は「テクノロジー」の記事である可能性が高いことです。
学習パートで説明した単純ベイズ確率モデルができた前提で、公式にある部分的な確率を簡単に計算できて、カテゴリ自動分類機能を実装できました。
間違いなく機械学習の時代になっています。難しい分野ですが、私みたいに簡単なところから実際にやってみると意外と楽しいと思います。皆さんも機会があればぜひ試してください。
- TF-IDF https://ja.wikipedia.org/wiki/Tf-idf
- b-Bit Minwise Hashing https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/a13-li.pdf
- ベイズの定理 https://ja.wikipedia.org/wiki/%E3%83%99%E3%82%A4%E3%82%BA%E3%81%AE%E5%AE%9A%E7%90%86
- 単純ベイズ分類器 https://ja.wikipedia.org/wiki/%E5%8D%98%E7%B4%94%E3%83%99%E3%82%A4%E3%82%BA%E5%88%86%E9%A1%9E%E5%99%A8