Database: [DATABASE] -> [TABLE] -> [ROW]
Elasticsearch: [INDEX] -> [TYPE] -> [DOCUMENT]
A node is a running instance of Elasticsearch, while a cluster consists of one or more nodes with the same cluster.name that are working together to share their data and workload. As nodes are added to or removed from the cluster, the cluster reorganizes itself to spread the data evenly.
Initial State:

One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster. The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows. Any node can become the master.
An index is a logical namespace that points to one or more physical shards.
A shard is a low-level worker unit that holds just a slice of all the data in the index. A shard is a single instance of Lucene, and is a complete search engine in its own right. Documents are stored and indexed in shards, but applications don’t talk to them directly. Instead, they talk to an index.
A shard can be either a primary shard or a replica shard.
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time. By default, indices are assigned five primary shards.
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
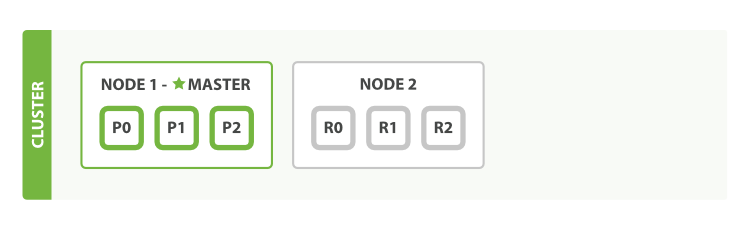
Single Node, Three Shards:

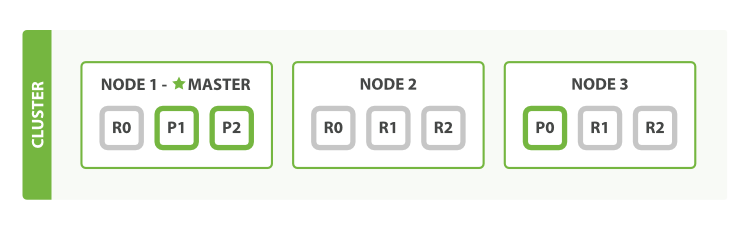
If we start a second node, our cluster would look like:
If we start a third node, our cluster reorganizes itself to look like:
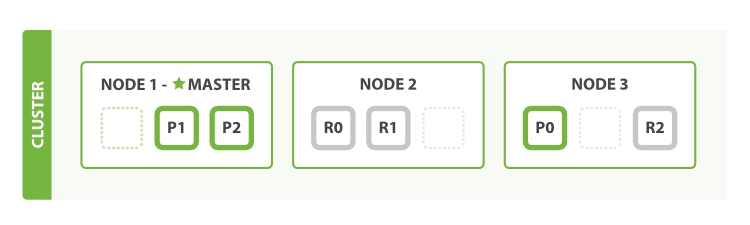
Let’s increase the number of replicas from the default of 1 to 2:
PUT /blogs/_settings
{
"number_of_replicas" : 2
}