-
-
Save cbaziotis/7ef97ccf71cbc14366835198c09809d2 to your computer and use it in GitHub Desktop.
| def dot_product(x, kernel): | |
| """ | |
| Wrapper for dot product operation, in order to be compatible with both | |
| Theano and Tensorflow | |
| Args: | |
| x (): input | |
| kernel (): weights | |
| Returns: | |
| """ | |
| if K.backend() == 'tensorflow': | |
| return K.squeeze(K.dot(x, K.expand_dims(kernel)), axis=-1) | |
| else: | |
| return K.dot(x, kernel) | |
| class AttentionWithContext(Layer): | |
| """ | |
| Attention operation, with a context/query vector, for temporal data. | |
| Supports Masking. | |
| Follows the work of Yang et al. [https://www.cs.cmu.edu/~diyiy/docs/naacl16.pdf] | |
| "Hierarchical Attention Networks for Document Classification" | |
| by using a context vector to assist the attention | |
| # Input shape | |
| 3D tensor with shape: `(samples, steps, features)`. | |
| # Output shape | |
| 2D tensor with shape: `(samples, features)`. | |
| How to use: | |
| Just put it on top of an RNN Layer (GRU/LSTM/SimpleRNN) with return_sequences=True. | |
| The dimensions are inferred based on the output shape of the RNN. | |
| Note: The layer has been tested with Keras 2.0.6 | |
| Example: | |
| model.add(LSTM(64, return_sequences=True)) | |
| model.add(AttentionWithContext()) | |
| # next add a Dense layer (for classification/regression) or whatever... | |
| """ | |
| def __init__(self, | |
| W_regularizer=None, u_regularizer=None, b_regularizer=None, | |
| W_constraint=None, u_constraint=None, b_constraint=None, | |
| bias=True, **kwargs): | |
| self.supports_masking = True | |
| self.init = initializers.get('glorot_uniform') | |
| self.W_regularizer = regularizers.get(W_regularizer) | |
| self.u_regularizer = regularizers.get(u_regularizer) | |
| self.b_regularizer = regularizers.get(b_regularizer) | |
| self.W_constraint = constraints.get(W_constraint) | |
| self.u_constraint = constraints.get(u_constraint) | |
| self.b_constraint = constraints.get(b_constraint) | |
| self.bias = bias | |
| super(AttentionWithContext, self).__init__(**kwargs) | |
| def build(self, input_shape): | |
| assert len(input_shape) == 3 | |
| self.W = self.add_weight((input_shape[-1], input_shape[-1],), | |
| initializer=self.init, | |
| name='{}_W'.format(self.name), | |
| regularizer=self.W_regularizer, | |
| constraint=self.W_constraint) | |
| if self.bias: | |
| self.b = self.add_weight((input_shape[-1],), | |
| initializer='zero', | |
| name='{}_b'.format(self.name), | |
| regularizer=self.b_regularizer, | |
| constraint=self.b_constraint) | |
| self.u = self.add_weight((input_shape[-1],), | |
| initializer=self.init, | |
| name='{}_u'.format(self.name), | |
| regularizer=self.u_regularizer, | |
| constraint=self.u_constraint) | |
| super(AttentionWithContext, self).build(input_shape) | |
| def compute_mask(self, input, input_mask=None): | |
| # do not pass the mask to the next layers | |
| return None | |
| def call(self, x, mask=None): | |
| uit = dot_product(x, self.W) | |
| if self.bias: | |
| uit += self.b | |
| uit = K.tanh(uit) | |
| ait = K.dot(uit, self.u) | |
| a = K.exp(ait) | |
| # apply mask after the exp. will be re-normalized next | |
| if mask is not None: | |
| # Cast the mask to floatX to avoid float64 upcasting in theano | |
| a *= K.cast(mask, K.floatx()) | |
| # in some cases especially in the early stages of training the sum may be almost zero | |
| # and this results in NaN's. A workaround is to add a very small positive number ε to the sum. | |
| # a /= K.cast(K.sum(a, axis=1, keepdims=True), K.floatx()) | |
| a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx()) | |
| a = K.expand_dims(a) | |
| weighted_input = x * a | |
| return K.sum(weighted_input, axis=1) | |
| def compute_output_shape(self, input_shape): | |
| return input_shape[0], input_shape[-1] |
@cbaziotis My loss is still NaN despite the small epsilon. Any recommended paths for debugging?
Sorry for not replying sooner, but notifications for gist comments apparently don't work.
isaacs/github#21
Regarding some of the errors: the layer was developed using Theano as a backend. I have updated the gist and now it also works with Tensorflow. However, i suggest to use Theano, as it has better RNN performance. Please use the new version and let me know.
Also, i have not tested the layer with Keras 2, but i assume it will need only some minor syntactic changes.
@Helw150 do you mind sharing the code for your model?
Thank you for this! using it in my school project.
one comment: even with your fix in line:105, I still sometimes encountered the NaN issue.
following BiMPM, I used K.max(sum(...), K.epsilon()) which turned out to be more stable.
hope this helps.
Updated for Keras 2.
Line 93: I had to replace ait = K.dot(uit, self.u) with ait = dot_product(uit, self.u) to make it work with TF
@sreiling If that, there is not error. But the model result is different. If I make that,AttentionWithContext's output dimension is lstm's hidden dim, compute_output_shape's output dim is input's last dim(embedding dim). Is it right?
Really great code @cbaziotis! I've used it several times for classification problem. But, I've been wondering how to use this in a seq2seq architecture? Many thanks!
L93 was also creating an issue for me with TensorFlow so I reused the dot_product() function like on L87
Thanks so much for this terrific gist (as well as your other Attention one)!
One minor bug: on line 93, K.dot should be replaced by dot_product, so that it works with TensorFlow as backend.
Nice work. Thanks for sharing the code.
I have a problem when I'm using the code. My sequences have varying lengths and I’m using bucketing to solve the issue. Therefore I define the LSTM input shape as (None, None, features), i.e. there are no explicit timesteps. But your code needs a fixed timestep, so there always raises an error. As far as I know, the number of timesteps doesn't need to be fixed. Therefore I wonder if there's a way to modify the code to support that. Thanks.
Thank you for your code.
I want to use the Layer(with some adaptive changes) in my code as part of my graduation thesis. I wonder how should I cite it.
Hello everyone
I was wondering, does anyone know how to create an attention layer with a custom (fixed, or trainable) context vector? I have tried this:
def call(self, inputs, mask=None):
x = inputs[0]
context = inputs[1]
uit = K.dot(x, self.W)
if self.bias:
uit += self.b
uit = K.tanh(uit)
ait = K.dot(uit, context)
a = K.exp(ait)
# apply mask after the exp. will be re-normalized next
if mask is not None:
# Cast the mask to floatX to avoid float64 upcasting in theano
a *= K.cast(mask, K.floatx())
# in some cases especially in the early stages of training the sum may be almost zero
# and this results in NaN's. A workaround is to add a very small positive number ε to the sum.
# a /= K.cast(K.sum(a, axis=1, keepdims=True), K.floatx())
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
a = K.expand_dims(a)
weighted_input = x * a
return K.sum(weighted_input, axis=1)
having also modified some other aspects such as the get_output_shape_for and compute_output_shape methods. Here is how I create and apply the layer with the custom context vector:
# Some other code...
context = Dropout(0.01)(dense) # 150 dimensional vector
...
H = TimeDistributed(Dense(150))(g2) # (None, 50, 150) tensor
sentence = AttentionWithContext()([H, context])
SentenceEncoder = Model(input_premisse, sent)
However, when attempting to run
input_premisse = Input(shape=(50,))
input_hyp = Input(shape=(50,))
input_overlap = Input(shape=(1,))
input_refuting = Input(shape=(15,))
input_polarity = Input(shape=(2,))
input_hand = Input(shape=(26,))
input_sim = Input(shape=(1,))
input_bleu = Input(shape=(1,))
input_rouge = Input(shape=(3,))
...
premisse_representation = SentenceEncoder(input_premisse)
hyp_representation = SentenceEncoder(input_hyp)
concat = merge([premisse_representation, hyp_representation], mode='concat')
mul = merge([premisse_representation, hyp_representation], mode='mul')
dif = merge([premisse_representation, hyp_representation], mode=lambda x: x[0] - x[1], output_shape=lambda x: x[0])
final_merge = merge([concat, mul, dif, input_overlap, input_refuting, input_polarity, input_hand, input_sim, input_bleu, input_rouge], mode='concat')
I get an error on the final_merge which says:
line 229, in <module>
sent = AttentionWithContext()([H, context])
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 572, in __call__
self.add_inbound_node(inbound_layers, node_indices, tensor_indices)
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 635, in add_inbound_node
Node.create_node(self, inbound_layers, node_indices, tensor_indices)
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 172, in create_node
output_tensors = to_list(outbound_layer.call(input_tensors, mask=input_masks))
File "C:\Users\Luís Pedro\Desktop\my_layers.py", line 186, in call
a *= K.cast(mask, K.floatx())
File "D:\Anaconda3\Lib\site-packages\keras\backend\theano_backend.py", line 206, in cast
return T.cast(x, dtype)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 1259, in cast
_x = as_tensor_variable(x)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 200, in as_tensor_variable
raise AsTensorError("Cannot convert %s to TensorType" % str_x, type(x))
theano.tensor.var.AsTensorError: ('Cannot convert [None, None] to TensorType', <class 'list'>)
and if I comment out that specific lines, I instead get the error:
File "C:\Users\Luís Pedro\Desktop\generate-contexts.py", line 244, in <module>
final_merge = merge([concat, mul, dif, input_overlap, input_refuting, input_polarity, input_hand, input_sim, input_bleu, input_rouge], mode='concat')
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1680, in merge
name=name)
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1301, in __init__
self.add_inbound_node(layers, node_indices, tensor_indices)
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 635, in add_inbound_node
Node.create_node(self, inbound_layers, node_indices, tensor_indices)
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 172, in create_node
output_tensors = to_list(outbound_layer.call(input_tensors, mask=input_masks))
File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1394, in call
return K.concatenate(inputs, axis=self.concat_axis)
File "D:\Anaconda3\Lib\site-packages\keras\backend\theano_backend.py", line 583, in concatenate
return T.concatenate([to_dense(x) for x in tensors], axis=axis)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4734, in concatenate
return join(axis, *tensor_list)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4483, in join
return join_(axis, *tensors_list)
File "D:\Anaconda3\Lib\site-packages\theano\gof\op.py", line 615, in __call__
node = self.make_node(*inputs, **kwargs)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4216, in make_node
axis, tensors, as_tensor_variable_args, output_maker)
File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4282, in _make_node_internal
raise TypeError("Join() can only join tensors with the same "
builtins.TypeError: Join() can only join tensors with the same number of dimensions.
Any ideas? Thanks.
Just wondering whether
self.W = self.add_weight((input_shape[-1], input_shape[-1],)
is necessary. Can we simply use a vector here rather than a matrix?
https://gist.github.com/cbaziotis/7ef97ccf71cbc14366835198c09809d2#gistcomment-2373145
@LeZhengThu This code works for the variable length input I think. At least it works for my case.
I'm getting negative attention weights for some words using this. Is this supposed to happen? If so, any literature that indicates this should happen? If not, any ideas on how to fix?
@skywang329 Do you check a values or u values ? The attention weights are the a values and normally the exponential forces coefficient to be positive
https://gist.github.com/cbaziotis/7ef97ccf71cbc14366835198c09809d2#gistcomment-2605022
@ronggong could you provide a minimal working example? I'm using bucketing like @LeZhengThu (for efficiency reasons), so I set input_length=None since it varies from batch to batch. The output of my Bidirectional GRU layer has shape (?,?,256). When adding an AttentionWithContext layer, I get IndexError: pop index out of range.
I fixed the error I was getting by replacing K.dot by dot_product line 93. The error had nothing to do with the length of the input.
Thanks for your implementation @cbaziotis! I have made some modifications on your code here in order to make it compatible with Keras 2.x and to also make easy recovering the attention weights for visualization. By the way, have you thought about making a PR for the attention layer on keras-contrib?
inputs = Input(shape=(100,))
embedding_layer = Embedding(maxnumber_of_tp, embedding_vecor_length, mask_zero=True)(inputs)
hidden = LSTM(64, return_sequences=True)(embedding_laye )
sentence, word_scores = Attention(return_attention=True)(hidden)
output = Dense(1, activation='sigmoid')(sentence)
model = Model(input=inputs, output=output)
I train it with a binary classification problem. My question is How should I catch 'word_scores'?
When I do this:
attention_model = Model(input= model.input, output= model.layers[-2].output)
I got the 'sentence' rather than 'word_scores '
Anyone knows?
Where is the context computed? I need to output a different sequence length than the one of the input.
The attention layer outputs a 2D tensor shape (none,256) any idea on how to make it output a 3D tensor without reshaping??!
Because I reshaped it to be (none,1,256) and my time distributed dense layers that follow expects (None, 1, 15) and I need it to expect what its actually receiving (none,20,15) since 20 is my max sentence length ?! Any ideas?
Great work, thanks!
I've made some small updates, so that the Layer works under Tensorflow 1.13 with Eager Execution (EE is awesome, with its imperative model, makes debugging soooooo much easier.)
will this work for different modalities like (visual and texual)?
Hello everyone
I was wondering, does anyone know how to create an attention layer with a custom (fixed, or trainable) context vector? I have tried this:
def call(self, inputs, mask=None): x = inputs[0] context = inputs[1] uit = K.dot(x, self.W) if self.bias: uit += self.b uit = K.tanh(uit) ait = K.dot(uit, context) a = K.exp(ait) # apply mask after the exp. will be re-normalized next if mask is not None: # Cast the mask to floatX to avoid float64 upcasting in theano a *= K.cast(mask, K.floatx()) # in some cases especially in the early stages of training the sum may be almost zero # and this results in NaN's. A workaround is to add a very small positive number ε to the sum. # a /= K.cast(K.sum(a, axis=1, keepdims=True), K.floatx()) a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx()) a = K.expand_dims(a) weighted_input = x * a return K.sum(weighted_input, axis=1)having also modified some other aspects such as the
get_output_shape_forandcompute_output_shapemethods. Here is how I create and apply the layer with the custom context vector:# Some other code... context = Dropout(0.01)(dense) # 150 dimensional vector ... H = TimeDistributed(Dense(150))(g2) # (None, 50, 150) tensor sentence = AttentionWithContext()([H, context]) SentenceEncoder = Model(input_premisse, sent)However, when attempting to run
input_premisse = Input(shape=(50,)) input_hyp = Input(shape=(50,)) input_overlap = Input(shape=(1,)) input_refuting = Input(shape=(15,)) input_polarity = Input(shape=(2,)) input_hand = Input(shape=(26,)) input_sim = Input(shape=(1,)) input_bleu = Input(shape=(1,)) input_rouge = Input(shape=(3,)) ... premisse_representation = SentenceEncoder(input_premisse) hyp_representation = SentenceEncoder(input_hyp) concat = merge([premisse_representation, hyp_representation], mode='concat') mul = merge([premisse_representation, hyp_representation], mode='mul') dif = merge([premisse_representation, hyp_representation], mode=lambda x: x[0] - x[1], output_shape=lambda x: x[0]) final_merge = merge([concat, mul, dif, input_overlap, input_refuting, input_polarity, input_hand, input_sim, input_bleu, input_rouge], mode='concat')I get an error on the final_merge which says:
line 229, in <module> sent = AttentionWithContext()([H, context]) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 572, in __call__ self.add_inbound_node(inbound_layers, node_indices, tensor_indices) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 635, in add_inbound_node Node.create_node(self, inbound_layers, node_indices, tensor_indices) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 172, in create_node output_tensors = to_list(outbound_layer.call(input_tensors, mask=input_masks)) File "C:\Users\Luís Pedro\Desktop\my_layers.py", line 186, in call a *= K.cast(mask, K.floatx()) File "D:\Anaconda3\Lib\site-packages\keras\backend\theano_backend.py", line 206, in cast return T.cast(x, dtype) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 1259, in cast _x = as_tensor_variable(x) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 200, in as_tensor_variable raise AsTensorError("Cannot convert %s to TensorType" % str_x, type(x)) theano.tensor.var.AsTensorError: ('Cannot convert [None, None] to TensorType', <class 'list'>)and if I comment out that specific lines, I instead get the error:
File "C:\Users\Luís Pedro\Desktop\generate-contexts.py", line 244, in <module> final_merge = merge([concat, mul, dif, input_overlap, input_refuting, input_polarity, input_hand, input_sim, input_bleu, input_rouge], mode='concat') File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1680, in merge name=name) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1301, in __init__ self.add_inbound_node(layers, node_indices, tensor_indices) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 635, in add_inbound_node Node.create_node(self, inbound_layers, node_indices, tensor_indices) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 172, in create_node output_tensors = to_list(outbound_layer.call(input_tensors, mask=input_masks)) File "D:\Anaconda3\Lib\site-packages\keras\engine\topology.py", line 1394, in call return K.concatenate(inputs, axis=self.concat_axis) File "D:\Anaconda3\Lib\site-packages\keras\backend\theano_backend.py", line 583, in concatenate return T.concatenate([to_dense(x) for x in tensors], axis=axis) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4734, in concatenate return join(axis, *tensor_list) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4483, in join return join_(axis, *tensors_list) File "D:\Anaconda3\Lib\site-packages\theano\gof\op.py", line 615, in __call__ node = self.make_node(*inputs, **kwargs) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4216, in make_node axis, tensors, as_tensor_variable_args, output_maker) File "D:\Anaconda3\Lib\site-packages\theano\tensor\basic.py", line 4282, in _make_node_internal raise TypeError("Join() can only join tensors with the same " builtins.TypeError: Join() can only join tensors with the same number of dimensions.Any ideas? Thanks.
@LuisPB7 I combine the context and key into a whole tensor as an input, then split them in the Attention class. But that needs some modification in the Attention codes (stuff like tensor calculation, input/output shape).
Will this work for images?
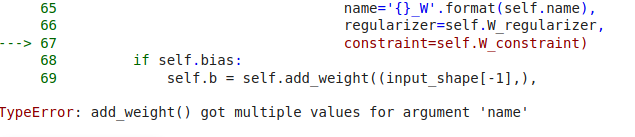
I am getting this error. Can anyone please help me resolve it.
CODE:
model.add(Bidirectional(LSTM(lstm_output_size, dropout_W=0.2,dropout_U=0.2, return_sequences=True)))
model.add(Bidirectional(LSTM(lstm_output_size, dropout_W=0.2,dropout_U=0.2, return_sequences=True)))
model.add(AttentionWithContext())
model.add(Dense(numclasses, activation='softmax'))
@cbaziotis
Thanks a lot for the code. I have a question about using mask. Could you please explain how to define and use a mask here? If I have already used a Masking layer before LSTM, e.g., x = Masking(mask_value=0.)(x), should I still use mask here? If so, how can I define the mask? I am using masking value as 0 in the masking layer for LSTM, then the LSTM layer knows which timesteps should be ignored. However, the LSTM features will not be zeros and might be arbitrary, how to define the mask for the attention layer then? Should we use the same mask as that for LSTM? Thank you very much.
Need some help in two lines.
In line 40, why is
assert len(input_shape) == 3required? What information is stored in input_shape?In line 87, why is
expand_dimbeing used?Thanks.