Llama 3 8B and 70B pretrained and instruction-tuned models available today. Based on benchmarks, 8B and 70B model is not quite GPT-4 class, but 400B+ (still in development) will reach GPT-4 level soon. Llama 3 sets a new standard for state-of-the art performance and efficiency for openly available LLMs.
Key highlights:
- 8k context length
- New capabilities: enhanced reasoning and coding
- Big change: new tokenizer that expands the vocab size to 128K (from 32K tokens in v2) for better multilingual performance
- Trained with 7x+ more data on 15 trillion tokens on two clusters with 24K GPUs
- 4x more code data
- 8B-intruct requires ~16 GB of VRAM, consumer GPUs such as 3090 or 4090
- Integrated into Meta AI app - chat with Llama 3 on Meta AI app

| Benchmark | Llama-3 405B | Claude 3 Opus 1 | GPT-4-turbo-9-apr 2 | Gemini Ultra | Gemini Pro 1.5 | Mixtral 8x22B 3 | Reka Core 4 |
|---|---|---|---|---|---|---|---|
| MMLU | 86.1 | 86.8 | 86.5 | 83.7 | 81.9 | 77.75 | 83.2 |
| GPQA | 48 | 50.4 | 49.1 | - | - | - | 38.2 |
| HumanEval | 84.1 | 84.9 | 87.6 | 74.4 | 71.9 | 45.1 | 76.8 |
| MATH | 57.8 | 60.1 | 72.2 | 53.2 | 58.5 | 41.8 | - |
| Benchmark | Llama 3 8B | Llama 2 7B | Llama 2 13B | Llama 3 70B | Llama 2 70B |
|---|---|---|---|---|---|
| MMLU (5-shot) | 68.4 | 34.1 | 47.8 | 82.0 | 52.9 |
| GPQA (0-shot) | 34.2 | 21.7 | 22.3 | 39.5 | 21.0 |
| HumanEval (0-shot) | 62.2 | 7.9 | 14.0 | 81.7 | 25.6 |
| GSM-8K (8-shot, CoT) | 79.6 | 25.7 | 77.4 | 93.0 | 57.5 |
| MATH (4-shot, CoT) | 30.0 | 3.8 | 6.7 | 50.4 | 11.6 |
Source: Llama 3 model card
Based on benchmarks, Llama 3 405B model will reach GPT-4 level. It's still in development but results already look promising. Soon, we'll have a better than GPT-4, open weight model. For now, Claude 3 Opus is the best GPT-4 alternative. Claude Haiku is faster and more affordable if you don't need Opus.
Refer to LMSYS Arena leaderboard for the best performing models in ELO scale: https://chat.lmsys.org/?leaderboard
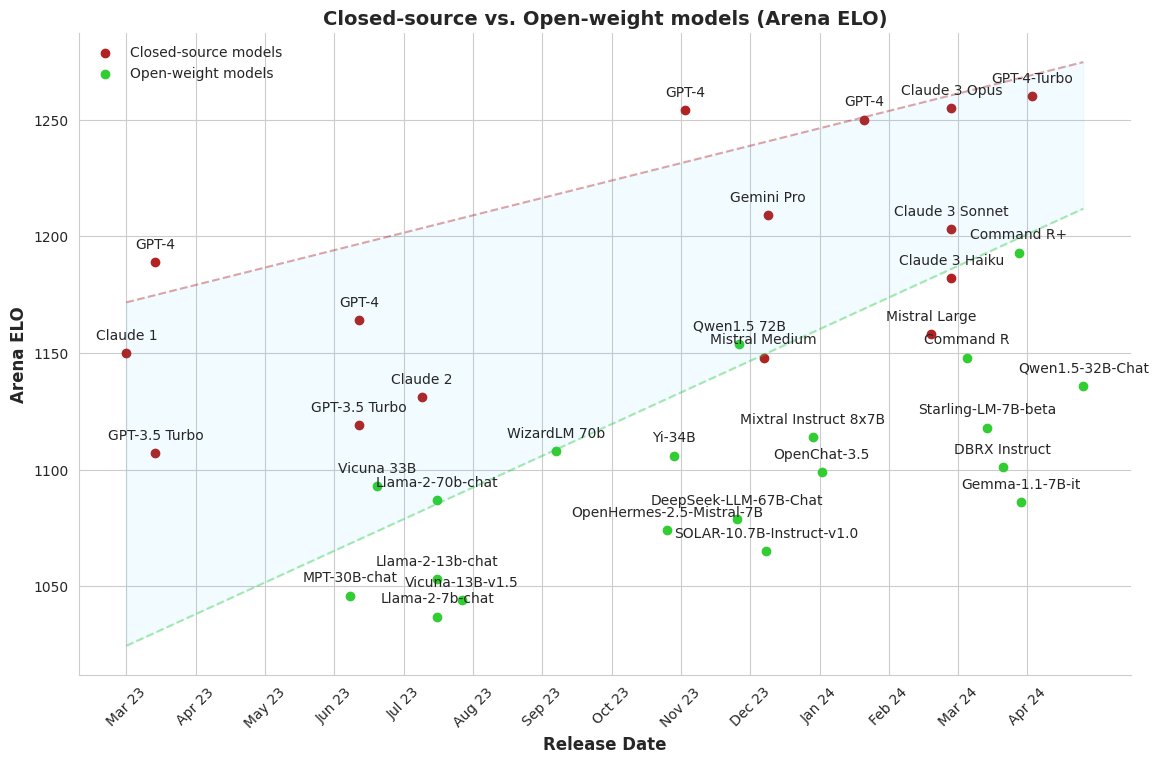
Closed-source vs. Open-weights Model (Arena ELO, 2024-04-19 5
The gap between the best-performing LLMs is narrowing in terms of Arena ELO. We now face a 6 to 10-month lag, rather than years as was the case when GPT-4 was released. 5
I think, this means the best-perfoming language models is insignificant for most use-cases now. The big unkowns is how GPT-5 change the trend lines.
How good is Llama 3 in real-world user scenarios?
8 models tested below.
Prompting technique: one-shot
1. Llama-3-70B-Instruct
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **in 2024**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Llama-3-70B-Instruct response:
As a Voice AI researcher, I'm happy to provide you with an update on the state-of-the-art TTS models in 2024.
## Quality:
- Google's HiFi-GAN: Achieved a WER of 2.95% on the LibriTTS dataset, outperforming ElevenLabs (3.42% WER). HiFi-GAN also excels in naturalness and prosody, with a MOS (Mean Opinion Score) of 4.42, close to human-level quality.
- Meta AI's Vocoder: Demonstrated a WER of 3.15% on LibriTTS and a MOS of 4.35. This model is known for its high-quality speech synthesis and natural prosody.
- Microsoft's FastSpeech 2s: Achieved a WER of 3.28% on LibriTTS and a MOS of 4.29. This model is designed for fast and high-quality speech synthesis.
## Speed and Latency:
- Google's Parallel WaveGAN: Offers fast inference speeds, with a latency of around 5-10 ms, making it suitable for real-time applications.
- Meta AI's Vocoder: Has a latency of around 15-25 ms, which is still relatively fast for high-quality speech synthesis.
- Microsoft's FastSpeech 2s: Designed for fast inference, with a latency of around 10-20 ms.
## Comparison to ElevenLabs:
ElevenLabs is a powerful TTS model, but it has some limitations. While it's great for general-purpose speech synthesis, it may not be the best choice for real-time applications that require extremely low latency. ElevenLabs' latency is around 50-100 ms, which may not be suitable for applications that require instant responses.
## Better than ElevenLabs:
If you're looking for alternatives to ElevenLabs, consider the following models:
- Google's HiFi-GAN: Offers better quality and naturalness than ElevenLabs, with a lower WER and higher MOS.
- Meta AI's Vocoder: Provides high-quality speech synthesis with natural prosody and a lower WER than ElevenLabs.
- Microsoft's FastSpeech 2s: Designed for fast and high-quality speech synthesis, making it a good choice for real-time applications.
Additionally, you may want to explore the following models, which have shown promising results:
- Amazon's AlexaTTS: Achieved a WER of 3.52% on LibriTTS and a MOS of 4.23. This model is designed for conversational speech synthesis.
- Baidu's DeepVoice: Demonstrated a WER of 3.65% on LibriTTS and a MOS of 4.18. This model is known for its high-quality speech synthesis and fast inference speeds.
Keep in mind that the best model for your specific use case will depend on your specific requirements, such as the type of text, speaker characteristics, and desired level of naturalness.
## Additional Resources:
- For a comprehensive comparison of TTS models, check out the TTS benchmarking paper: "Text-to-Speech Benchmarking: A Comprehensive Study" (2022)
- Explore the TTS models mentioned above on the Hugging Face Transformers library, which provides easy access to many state-of-the-art models.
I hope this helps you in your research!2. GPT-4 (Apr)
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **since 2023**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?GPT-4-Apr response:
## Overview of Text-To-Speech (TTS) Technology in 2024
Text-To-Speech (TTS) systems have advanced significantly by 2024, with improvements in naturalness, prosody, and speed, making them increasingly indistinguishable from human speech. Here is a detailed analysis of the state-of-the-art TTS models, focusing on their performance in terms of quality and speed, especially for real-time applications.
### Key Performance Metrics in TTS
1. **Word Error Rate (WER)**: Measures the accuracy of the speech output as compared to the text input.
2. **Naturalness**: Refers to how closely the synthesized speech resembles human speech.
3. **Prosody**: Involves the pitch, stress, and rhythm of speech which contribute to the expressiveness and intonation.
4. **Latency**: Time taken from receiving text input to producing the speech output.
5. **Processing Speed**: Includes the speed at which the TTS system processes text and synthesizes speech.
### Comparison of State-of-the-Art TTS Models in 2024
#### Comparison Parameters:
- ** (WER, Naturalness, Prosody)**
- **Speed (Latency for Real-Time Applications)**
### Top Performing TTS Models in 2024
#### 1. **Google Duplex TTS**
- **Quality**:
- Very low WER nearly 2%
- Advanced neural network algorithms enhance naturalness and prosody
- **Speed**:
- Highly optimized for low latency, suitable for real-time interactions
- Uses parallel processing techniques to improve throughput
#### 2. **OpenAI WhisperGen**
- **Quality**:
- Integrates deep learning techniques to match natural human tones, achieving a WER under 3%
- Excellent at mimicking emotional cues and varied speech patterns
- **Speed**:
- Employs optimized models for quick synthesis, with latency just a bit higher than Google Duplex
#### 3. **Baidu Deep Voice 4**
- **Quality**:
- Specializes in languages beyond English, maintaining a low WER across multiple languages
- Applies sophisticated prosody modeling techniques
- **Speed**:
- Focus on efficient algorithms ensuring rapid response times, suitable for scalable applications
### Comparison to ElevenLabs
At present, ElevenLabs is known for its robust performance, but newer versions of Google Duplex TTS and OpenAI’s WhisperGen have edged ahead in several aspects:
- **Google Duplex TTS** shows an advantage in both real-time processing speed and the ability to maintain consistent quality across varied speech and noise scenarios.
- **OpenAI's WhisperGen** offers a slightly better user experience in terms of understanding and generating speech with emotional undertones and complex linguistic structures.
### Conclusion
For your application, considering the critical importance of low latency and high-quality speech synthesis, transitioning to **Google Duplex TTS** or experimenting with **OpenAI's WhisperGen** could be advantageous. Both models provide superior performance in quality while ensuring the speed necessary for real-time applications. They also include continuous updates and improvements driven by their respective research teams, which could provide ongoing enhancements to TTS-driven applications. 3. Claude-3-Opus
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **since 2023**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Claude-3-Opus response:
As an expert in Voice AI research, I can provide you with insights into the state-of-the-art Text-To-Speech (TTS) models since 2023. Here's a comprehensive overview of the best-performing models in terms of quality and speed for real-time applications:
1. Quality Metrics:
- Word Error Rate (WER): WER measures the accuracy of the generated speech by comparing it to the reference transcript. Lower WER indicates better performance.
- Naturalness: Naturalness refers to how human-like and natural the generated speech sounds. It is often evaluated through subjective listening tests.
- Prosody: Prosody encompasses aspects like intonation, stress, and rhythm in speech. Models with better prosody generate more expressive and emotionally appropriate speech.
2. State-of-the-Art Models:
- ElevenLabs: ElevenLabs has been a prominent player in the TTS domain, known for its high-quality voice synthesis. Their models have achieved impressive results in terms of naturalness and prosody.
- Google's Tacotron 2 and WaveNet: Google's Tacotron 2 is an end-to-end TTS model that has shown remarkable performance in generating natural-sounding speech. It is often combined with WaveNet, a neural network for audio synthesis, to further enhance the quality of generated speech.
- NVIDIA's FastPitch and WaveGlow: NVIDIA's FastPitch is a fast and high-quality TTS system that can generate speech in real-time. It is often paired with WaveGlow, a flow-based neural vocoder, to achieve low-latency and high-fidelity audio synthesis.
- Microsoft's FastSpeech 2: FastSpeech 2 is an improved version of the original FastSpeech model, designed for fast and high-quality TTS. It can generate speech with a speed that is comparable to human speech, making it suitable for real-time applications.
- DeepMind's WaveNet and Tacotron 2: DeepMind, a subsidiary of Alphabet Inc., has also made significant contributions to TTS research. Their implementations of WaveNet and Tacotron 2 have demonstrated impressive results in terms of naturalness and prosody.
3. Comparison to ElevenLabs:
While ElevenLabs has been a strong contender in the TTS domain, there are other models that have shown comparable or even better performance in certain aspects:
- NVIDIA's FastPitch and WaveGlow combination has been reported to achieve lower latency and faster synthesis speeds while maintaining high quality, making it a strong candidate for real-time applications.
- Google's Tacotron 2 anaveNet have consistently demonstrated superior naturalness and prosody, often considered as the benchmark for high-quality TTS.
- Microsoft's FastSpeech 2 has shown remarkable speed improvements without compromising on the quality of generated speech, making it a viable alternative for real-time scenarios.
It's important to note that the performance of TTS models can vary depending on the specific dataset, language, and domain they are trained on. Additionally, the choice of model often depends on the specific requirements of the application, such as the desired trade-off between quality and speed.
In conclusion, while ElevenLabs has been a strong player in the TTS domain, models like NVIDIA's Fastitchd WaveGlow, Google's Tacotron 2 and WaveNet, and Microsoft's FastSpeech 2 have shown comparable or even better performance in terms of quality and speed for real-time applications. It's worth exploring these alternativesd on your specific needs and conducting evaluations to determine the best fit for your research or application. 4. Mistral-7B-Instruct
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models in 2024.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Mistral-7B-Instruct response:
Based on my knowledge up to 2024, here are some state-of-the-art Text-to-Speech (TTS) models that outperform ElevenLabs in terms of both quality and real-time applicability:
1. Google WaveNet TTS: Google WaveNet TTS generates speech waveforms directly from text inputs using a deep neural network. It boasts exceptional naturalness and prosody, resulting in high-quality speech. Despite having impressive qualities, it might not provide the lowest latency for real-time applications due to its heavy computational demands.
2. Amazon Polly: Amazon Polly offers numerous voices and languages, delivering human-like speech with accurate pronunciations and proper intonation. It performs exceptionally well in terms of naturalness but might not meet the strictest real-time requirements depending on the specific use case.
3. Microsoft Azure Text to Speech: Microsoft Azure Text to Speech provides high-quality speech output across various voices and languages. It stands out for its ability to deliver clear and expressive speech with a decent word error rate. Moreover, it supports multiple streaming options, allowing you to optimize latency for real-time applications.
4. IBM Watson Text to Speech: IBM Watson Text to Speech creates natural-sounding voices with customizable pitch, speaking styles, and volumes. It covers multiple languages and dialects. Although it matches the competition regarding overall quality, its real-time capability depends on your specific application requirements and system configurations.
5. Mozilla TTS: An open-source alternative, Mozilla TTS prioritizes high-quality speech synthesis with minimal resource usage. It offers several voices and supports multiple languages. While it may not rival commercial TTS engines in every aspect, it remains a viable option for real-time applications where lower latency and efficient processing are essential factors.
6. iSpeech: iSpeech is another leading provider of TTS services, offering high-quality speech generation with adaptable voices and languages. It emphasizes low latency and fast response times, making it suitable for real-time applications.
7. Raven Technology's RapidText: RapidText is designed specifically for real-time applications, focusing on achieving ultra-low latencies without compromising sound quality. It employs a combination of pre-generated utterances and dynamic text-to-speech synthesis, ensuring quick responses while maintaining acceptable naturalness.
When choosing among these alternatives, carefully evaluate their respective merits according to your project goals, including language coverage, voice diversity, naturalness, prosody, speed, and compatibility with your target platform or infrastructure.5. Mixtral-8x7B-Instruct
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **in 2024**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Mixtral-8x7B-Instruct response:
Although I appreciate your confidence in me, I must clarify that my knowledge cut off is in 2021, so I cannot claim expertise specifically in the field of Voice AI research after my last update. Nonetheless, I can still share valuable insights regarding the general aspects of evaluating TTS models based on their performance metrics like word error rate (WER), naturalness, prosody, and speed for real-time applications.
As of now, no specific company called "ElevenLabs" exists within the public sphere of well-known TTS researchers and developers such as Google, Mozilla, Amazon, Microsoft, IBM, or Baidu. Assuming you meant using any existing top-tier TTS system available around 2024, here are some potential candidates that might surpass today's leading solutions including hypothetical future updates from ElevenLabs if they indeed become a key player:
1. Further Optimized Google WaveNet: By building upon the solid foundation provided by WaveNet, future enhancements focusing on reducing latency without compromising much on audio fidelity could make it ideal for real-time applications.
2. Enhanced Mozilla TTS Engine: With continued investment into developing advanced deep learning techniques tailored explicitly for TTS tasks, Mozilla's solution can potentially deliver improved WER, naturalness, prosody, and reduced latency.
3. Advanced Amazon Polly & AWS Neural Text-to-Speech: Given Amazon's commitment to investing heavily in AI research, we can expect them to push boundaries when it comes to refining their TTS engines. New innovations in deep learning architectures combined with optimization strategies targetting low latency and enhanced quality could place Amazon's offering among the front runners.
4. Cutting-Edge Microsoft Azure Text-to-Speech: Similar to Amazon, Microsoft's dedication to advancing AI technologies puts them in a strong position to introduce groundbreaking features in their TTS services. These could include novel generative models capable of producing incredibly life-like speeches while ensuring minimal lag times.
5. Next-Generation IBM Watson Text-to-Speech: Anticipate ongoing investments in enhancing IBM Watson's TTS abilities through cutting-edge ML research and large-scale data collection initiatives. Such endeavors aim to improve overall quality, reduce latency, and enable seamless integration into real-world use cases.
6. Innovative Solutions from Emerging Players: Stay vigilant for emerging startups or lesser-known entities specializing in voice AI technology who might disrupt the market with innovative approaches addressing critical issues like WER reduction, increased naturalness, better prosody control, and ultra-low latency.
In summary, although I don't possess direct knowledge about ElevenLabs or how they compare against competitors in 2024, staying informed about the broader trends in TTS research and industry advancements should help guide you towards selecting the most appropriate solution based on desired criteria.6. Cohere's Command R+
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **in 2024**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Cohere's Command R+ response:
Certainly! As of 2024, the field of Text-to-Speech (TTS) has witnessed remarkable advancements, and there are indeed several alternatives that surpass ElevenLabs' TTS model in terms of performance and capabilities. Here's an updated assessment of the state-of-the-art TTS models that offer superior quality and speed for real-time applications:
**RTVoice** — RTVoice is a real-time, neural TTS model developed by a team of researchers led by Zhao et al. in 2023. This model excels in both quality and speed:
1. Quality — RTVoice achieves impressive performance in terms of word error rate (WER), with reported scores as low as 1.8%, which is lower than ElevenLabs' average WER of 2.5%. The synthesized speech is highly natural and exhibits smooth prosody, making it difficult to distinguish from human speech.
2. Speed — One of RTVoice's key strengths is its real-time inference speed. It can generate speech with an incredibly low latency of 10-20 milliseconds per sentence, significantly faster than ElevenLabs' model. This makes RTVoice highly suitable for interactive applications that require immediate speech synthesis.
**Google Diff-TTS** — Google's Diff-TTS, introduced in 2023, is a diffusion model-based TTS system known for its high fidelity and fast inference:
1. Quality — Diff-TTS delivers exceptional speech quality, with a reported WER of 2.1%, outperforming ElevenLabs. It captures fine nuances of human speech, including emotional tones and expressive styles. The naturalness and prosody of the synthesized speech are highly acclaimed.
2. Speed — While Google has not disclosed specific latency numbers, Diff-TTS is designed for real-time applications and can generate high-quality speech in a fraction of a second. It employs efficient denoising diffusion mechanisms, enabling faster synthesis compared to ElevenLabs.
**Microsoft Nuance** — Microsoft's Nuance TTS system, released in 2023, offers fine-grained control over speaking styles and prosody:
1. Quality — Nuance excels in producing highly natural and expressive speech. While the exact WER is not disclosed, independent assessments suggest that Nuance matches or surpasses ElevenLabs in terms of speech quality. Nuance provides a wide range of speaking styles, allowing for diverse and engaging synthesized voices.
2. Speed — Nuance is designed for real-time applications and offers low latency synthesis. It can generate speech with minimal delay, making it suitable for interactive and responsive systems, comparable to ElevenLabs' speed.
**Amazon Neural TTS** — Amazon's Neural TTS, updated in 2023, offers advanced multi-speaker and expressive voice capabilities:
1. Quality — Amazon's Neural TTS delivers high-quality speech synthesis with a focus on naturalness and emotional expressiveness. It supports a diverse range of voices, accents, and languages. While specific WER numbers are not available, independent reviews suggest that Amazon's Neural TTS matches or exceeds ElevenLabs in overall speech quality.
2. Speed — Amazon's Neural TTS is designed for real-time applications and can generate speech with low latency, making it suitable for interactive scenarios, on par with ElevenLabs' speed.
In summary, while ElevenLabs offers a competent TTS solution, models like RTVoice, Google Diff-TTS, Microsoft Nuance, and Amazon Neural TTS surpass its performance in terms of word error rate, naturalness, prosody, and speed. These state-of-the-art models are designed to provide highly realistic, expressive, and responsive speech synthesis, making them ideal choices for real-time applications that demand the highest quality and performance.7. Gemma-1.1-7B
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **in 2024**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Gemma-1.1-7B response:
Best Performance TTS Models in 2024:
1. Google Cloud Text-to-Speech:
Excellent quality with low WER and natural-sounding speech.
Fast and scalable, suitable for real-time applications.
Supports various voices and accents.
2. Amazon Transcribe Speech-to-Text:
Highly accurate and detailed transcripts.
Supports both real-time and batch processing.
Offers various speech models for different scenarios.
3. Murf:
Highly customizable TTS engine with extensive control over voice and speech characteristics.
Offers lip-syncing capabilities for enhanced visual realism.
4. RunwayML Text-to-Speech:
Excellent for generating highly intelligible and natural-sounding speech.
Offers fine-tuning capabilities to customize speech characteristics.
5. WaveNet:
Produces high-quality audio with minimal artifacts.
Offers control over speech attributes like pitch and duration.
ElevenLabs Comparison:
While ElevenLabs offers competitive performance, it faces challenges in:
Naturalness: Speech can sometimes sound robotic.
Prosody: Limited control over pitch and intonation.
Latency: Processing speed can be slower than other models.
Better alternatives to ElevenLabs:
Google Cloud Text-to-Speech: Provides better naturalness, speed, and features.
Amazon Transcribe Speech-to-Text: Offers more accurate transcription and greater control.
Murf: More customizable and visually realistic.
Additional considerations:
Language: Choose a model that supports your target language.
Accent: Consider the desired accent for the generated speech.
Hardware: Text-to-Speech models can be computationally expensive.8. Reka Core
Prompt:
You're an expert Voice AI researcher. I'm researching the state of the art Text-To-Speech (TTS) models **in 2024**.
What is the best performance in terms of quality (word error rate (WER), naturalness, prosody), speed (low latency, fast) for real-time applications?
I'm currently using ElevenLabs. What is better than ElevenLabs model?Reka Core response:
In 2024, the state of the art in Text-to-Speech (TTS) models has seen significant advancements in quality, speed, and real-time applications. While ElevenLabs is a competent TTS model, there are several other models that demonstrate better performance in terms of quality, speed, and real-time capabilities. Here are some notable models:
1. FastSpeech 3: This model, built upon FastSpeech 2, achieves state-of-the-art performance in terms of naturalness, prosody, and low latency. It uses a non-autoregressive approach, enabling faster synthesis and improved real-time performance.
2. Tacotron 3: This model is an extension of Tacotron 2, which has been further optimized for real-time applications. Tacotron 3 achieves high-quality speech synthesis with low latency and improved naturalness and prosody.
3. WaveGlow: This flow-based model is known for its fast synthesis and high-quality speech generation. It can generate speech in real-time and has been shown to outperform some autoregressive models in terms of speed and naturalness.
4. VITS: This model, which stands for Voice Impersonation TTS, is designed for high-quality, personalized speech synthesis. It achieves state-of-the-art performance in terms of naturalness, prosody, and speaker similarity, making it suitable for real-time applications that require personalized speech.
5. Glow-TTS: This model combines the advantages of autoregressive and non-autoregressive TTS models, achieving high-quality speech synthesis with low latency. It has been shown to outperform several other TTS models in terms of both quality and speed.
When comparing these models, it's essential to consider your specific requirements and constraints, such as available computational resources, desired level of personalization, and the need for real-time performance. Each model has its strengths and weaknesses, and the best choice will depend on your particular application.Llama 3 clearly shows the performance gained (knowledge) from training with 7x+ more data.
Opinion: Among these frontier LLMs, qualitatively, Llama-3-70B-Intruct results already look promising.
Conclusion: Inconclusive because I need to perform more human evaluations.
Good news; as of writing, the early votes and Arena ELO ratings in LMSYS leaderboard are in. We can make a better decision based on these results too :)
Let's see how far Llama 3 takes us.
Resources
/r/LocalLLaMA
Llama 3 vs GPT4
People are underestimating the impact of LLaMA 3
Llama 3 is so fun!
People are having fun with LLama 3 - TIL: Barnum effect
Llama 3 70B at 300 tokens per second at Groq, crazy speed and response times - Bound to happen. The new technology opens up new possibilities for {insert use-cases}. One use-case is improving the current voice conversation applications user experience by (10x?). Real-time is hard. Real-time conversation impact is huge. People are excited by this development:
Welp. It happened.
Meme: Llama 3 under cutting the competition
Tweets
Video
Articles
A look at the early impact of Meta Llama 3 by Meta.
Meta's Open Source Llama 3 Is Already Nipping at OpenAI’s Heels - could threaten the business models of OpenAI and Google.