紀錄 2018 - 2020 解決 Leetcode 過程。
目前沒有分得很細,先根據難易度分,然後因為有特別再解 tree 和 db 所以將這兩部分再分章節。 點上面連結可以快速跳到對應錨點,每個章節上面有 content 連節讓你快速跳回來目錄。個人覺得目前這樣還是容易混亂,也顯現我在解題過程其實是很看心情 QQ 再思考一下更好方法。
紀錄 2018 - 2020 解決 Leetcode 過程。
目前沒有分得很細,先根據難易度分,然後因為有特別再解 tree 和 db 所以將這兩部分再分章節。 點上面連結可以快速跳到對應錨點,每個章節上面有 content 連節讓你快速跳回來目錄。個人覺得目前這樣還是容易混亂,也顯現我在解題過程其實是很看心情 QQ 再思考一下更好方法。
找出不重複的欄位,概念上就是透過 group by 與 having 去過濾
SELECT Email
FROM Person
GROUP BY Email
HAVING COUNT(*) > 1 猜數字遊戲,就是不知道數字然後先給一個初始值開始猜,測試有給一個 api 假如猜的數字比較小就回傳 1,猜得數比較大就回傳 -1,猜對就回傳 0
一般的解法應該會是不斷加一、簡一去逼近這樣,但會有問題,假如答案是 10000 給你一個 1 那程式會執行 9999 次累加,太慢 因此做法應該是先從高位數慢慢去檢查(例如先檢查 萬位數、千位數、百位數依序)我的做法:
用一個 while 迴圈,先根據給的 n 建立一個對等長度的 count,接著在 while 迴圈去做檢查,假如加上這個 count 爆掉,代表最高位數相等了,於是把 count 退後一個十位,接著 dec 設為 false 開始去檢查第二個位數,假設第二個位數也爆掉了,於是再回到 count 把 count 退一位數去檢查,於是你每一個位數最多就是檢查 8 次
def guessNumber(self, n):
"""
:type n: int
:rtype: int
"""
import math
digit = int(math.log10(n))+1
count = 10
for _ in range(digit-1):
count *= 10
dec, digi = True, True
while True:
if dec:
ret = guess(n+count)
if ret == -1:
count = count // 10
dec = False
elif ret == 1:
n += count
elif ret == 0:
return n+count
elif digi:
ret = guess(n+count)
if ret == -1:
n -= count
elif ret == 1:
dec = True
elif ret == 0:
return n+count或是用二元搜尋概念
def guessNumber(self, n):
"""
:type n: int
:rtype: int
"""
right = n
left = 1
mid = n / 2
while left <= right:
res = guess(mid)
if res == 0:
return mid
elif res == -1:
right = mid - 1
elif res == 1:
left = mid + 1
mid = (right + left) / 2
return mid題目要解的是有兩群數字: a, b,要把 b 內的所有數字消耗掉 b 的數字要小於等於 a 才能被消耗,假如都能就回傳 true,反之回傳 false
這題難點在 1.能否在 O(N) 結束(一個 for) 2.搜尋過程何時結束?
想法大概是先把兩個數字 sort 接著循序去讀 b,假如數字大於 g 就跳 g 下一個,然後透過 count 來紀錄,因此 count 的數量如果已經滿足等於 b 那就跳出
def findContentChildren(self, g, s):
"""
:type g: List[int]
:type s: List[int]
:rtype: int
"""
count, size = 0, len(g) - 1
g.sort()
s.sort()
for _s in s:
if count > size:
break
elif _s >= g[count]:
count += 1
return count 題目很單純,就是要種一株花,但是花會互搶養份,1 代表有話 0 代表沒有花,你有一堆尚未下土的花要種在哪。
舉例:
演算法的設計一開始我是這樣想,for 迴圈,然後看前面,看後面都是 0 才種。但這會出問題,假如花圃只有 [0] or [0,0] 這樣程式設計會無法運作 所以想了一下應該要用一個變數來儲存前面一個的狀態,接著有幾種可能:
| 當下 | 前狀態 |
|---|---|
| 1 | False |
| 1 | True |
| 0 | False |
| 0 | True |
def canPlaceFlowers(flowerbed, n):
"""
:type flowerbed: List[int]
:type n: int
:rtype: bool
"""
before = False
for idx, f in enumerate(flowerbed):
if f == 1 and before == False:
before = True
elif f == 1 and before == True:
flowerbed[idx-1] = 0
n += 1
elif f == 0 and before == False and n != 0:
flowerbed[idx] = 1
before = True
n -= 1
elif f == 0 and before == True:
before = False
#print(' ->', before, flowerbed)
return False if bool(n) else True找出最多的差距 1 的數組,例如 (1,2), (3,4) 這樣就是一對的。這題主要是考搜尋速度,hash
def findLHS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
dicts = {}
for num in nums:
dicts[num] = dicts.get(num, 0) + 1
max_pair = 0
for i in dicts:
if i + 1 in dicts:
max_pair = max(max_pair, dicts[i]+dicts[i+1])
return max_pair處理字串
def toGoatLatin(S):
"""
:type S: str
:rtype: str
"""
vowel = ['a','e','i','o','u']
count, words, ret = 1, S.split(' '), []
for word in words:
if word[0].lower() in vowel:
ret.append('{}{}{}'.format(word, 'ma', 'a'*count))
else:
ret.append('{}{}{}{}'.format(word[1:], word[0], 'ma', 'a'*count))
count += 1
return ' '.join(ret)這題要找出 alice, bob 交換糖果之後兩個人變成一樣,這題重點在於,因為要每一次去搜尋 B,這是平凡搜尋,所以要用 set() 這個資料結構才會快
def fairCandySwap(self, A, B):
"""
:type A: List[int]
:type B: List[int]
:rtype: List[int]
"""
sum_a, sum_b = sum(A), sum(B)
avg = (sum_a + sum_b) // 2
set_a, set_b = set(A), set(B)
for a in set_a:
b = avg - (sum_a - a)
if b in set_b:
return [a, b]
return []最快的方法,用 diff,代表 a 要交換的值
diff = (sum(B)-sum(A)) // 2
set_b = set(B)
for a in A:
b = diff + a
if b in set_b:
return [a, b]
return []似曾相識阿,去計算 binary 裡面最長的 1 與 1,做法是這樣轉成 2 進位然後開始計算,如果是 1 且不是開始開始記錄,假如是最後 1 那就去確認是不是最大的。假如是 0 且已經開始機算就累加
def binaryGap(self, N):
"""
:type N: int
:rtype: int
"""
binary = bin(N)[2:]
gap = 0
start, count = False, 0
for b in binary:
if b == '1' and not start:
start = True
elif b == '1' and start:
gap = max(gap, count+1)
count = 0
elif b == '0' and start:
count += 1
return gap26 的解法
index = [i for i, v in enumerate(bin(N)) if v == '1']
#a = [1,2,3], b = [4,5,6] then zip(a,b)=[(1, 4), (2, 5), (3, 6)]
#a = [1,2,3], c = [4,5,6,7,8], then zip(a,c)=[(1, 4), (2, 5), (3, 6)]
# 元素个数与最短的列表一致
#这道题把index和每一项下面的index相减取最大值,如果index里只有一个数那么return 0
if len(index)==1:
return 0
else:
return max([b - a for a, b in zip(index, index[1:])])
用列表去記錄對應的字母長度,每一行能夠存入 100 units,所以假設 a=50,寫入第二個 a 就要換行了,但假如 a=50 b=49 那同樣寫入 a, b 再寫入 a 就要寫入第三行
key point 用 ascii 去對應串列字母的長度,然後用三個變數在計算累積的字母長度,行數與下一行
def numberOfLines(self, widths, S):
"""
:type widths: List[int]
:type S: str
:rtype: List[int]
"""
w, w_next, lines = 0, 0, 0
for idx, s in enumerate(S):
w += widths[ord(s)-97]
if idx < len(S) - 1:
w_next = widths[ord(S[idx+1])-97]
if w >= 100:
w -= 100
lines += 1
elif w + w_next > 100:
w = 0
lines += 1
if w > 0:
lines += 1
return [lines, w]看到不錯寫法
def numberOfLines(self, widths, S):
"""
:type widths: List[int]
:type S: str
:rtype: List[int]
"""
res = []
lines = 1
count = 0
for s in S:
pos = widths[ord(s)- 97]
if count + pos <= 100:
count += pos
else:
lines += 1
count = pos
return [lines, count]一個字串 S, 和字串裡面的字元 C。C 可能有很多個,遍歷字串,找出其和 C 最近距離想法,從左邊搜尋,從右邊搜尋。搜尋方法是遇到 C 就更新 index 值然後計算
def shortestToChar(S, C):
"""
:type S: str
:type C: str
:rtype: List[int]
"""
ret, i = [], S.index(C)+1
for idx, value in enumerate(S):
if C == value:
i = max(i, idx + 1)
ret.append(abs(idx-i+1))
ret2, i = [], S[::-1].index(C)+1
for idx, value in enumerate(S[::-1]):
if C == value:
i = max(i, idx + 1)
ret2.append(abs(idx-i+1))
return [min(ret[i], ret2[::-1][i]) for i in range(len(S))]另外一個解法就是直接置換要稍微想一下,首先往前搜尋先找到第一個 index 位置。往後搜尋就是不用管第一個 C 位置在哪
# Forward
ret, i = [], S.index(C)+1
for idx, value in enumerate(S):
if C == value:
i = max(i, idx + 1)
ret.append(abs(idx-i+1))
# Reversed
i = 0
for idx in range(len(S)-1, -1, -1):
if S[idx] == C:
i = idx
ret[idx] = min(abs(i-idx), ret[idx])
return ret或是經典向左向右找
res = [0 for i in range(len(S))]
left, right = -1, 0
while right < len(S):
while right < len(S) and S[right] != C:
right += 1
if right < len(S):
res[right] = 0
elif right == len(S):
for l in range(left+1, right):
res[l] = l-left
break
if left == -1:
for j in range(1,right+1):
res[right - j] = j
else:
for k in range(1, (right-left)/2+1):
res[left+k] = k
res[right-k] = k
left = right
right += 1
return res就是只重新排列字串,符號不用,一開始想到的爛解法。
def reverseOnlyLetters(self, S):
"""
:type S: str
:rtype: str
"""
from collections import deque
queues = deque(S)
rever_queue, sign = [], []
str_range = list(range(65, 91)) + list(range(97, 123))
for s in S:
if ord(s) not in str_range:
sign.append(s)
for idx, value in enumerate(S):
if value in sign:
rever_queue.append(value)
else:
while True:
r = queues.pop()
if r not in sign:
rever_queue.append(r)
break
return ''.join(rever_queue) def reverseOnlyLetters(S):
s = list(S)
l, r = 0, len(s)-1
while l < r:
if not s[l].isalpha():
l += 1
elif not s[r].isalpha():
r -= 1
else:
s[l],s[r] = s[r],s[l]
l += 1
r -= 1
return ''.join(s)看到,恍然大悟的解法
找尋一組字串根據 index 重新排列後非遞增函數的數量
def minDeletionSize(self, A):
"""
:type A: List[str]
:rtype: int
"""
deletions = list(zip(*A))
count = 0
for idx, d in enumerate(deletions):
if list(d) != sorted(d):
count += 1
return count二元搜尋,這是平凡再平凡不過的題目,記住和 quick search 不一樣喔!二元搜尋就是有一個預先排列好的數列不斷減半搜尋,這樣時間複雜度會是 O(log(n)) 重點就是要設定 first, last 與 midpoint
def search(nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: int
"""
first, last = 0, len(nums)-1
found = False
while first <= last and not found:
midpoint = (first + last) // 2
if nums[midpoint] == target:
found = True
else:
if target < nums[midpoint]:
last = midpoint - 1
else:
first = midpoint + 1
return midpoint if found else -1這個題目稱為 Brackets 如果有興趣可以參考我的 O(n) 做法 要解決是給一個 string 包含以下幾種 '(', ')', '{', '}', '[' and ']', 去檢查是否合法。
條件
其實就是 stack 的 FILO,後來 leetcode 又寫了另一類似解法
def isValid(self, s):
"""
:type s: str
:rtype: bool
"""
pare = {'(':')', '{':'}', '[':']'}
stack = []
for p in s:
if p in pare.keys():
stack.append(p)
elif p in pare.values():
if not stack:
return False
elif pare[stack[-1]] == p:
stack.pop()
else:
return False
if not stack:
return True
else:
return False就是要根據切割長度來分配,寫了一個效能不是很好的做法。
S = ''.join(S.split('-')).upper()[::-1]
ret = ''
for idx, s in enumerate(S):
if idx != 0 and idx % K == 0:
ret += '-'
ret += s
return ret[::-1]反轉元音,就是 a, e, i, o, u 這幾個反轉
def reverseVowels(self, s):
"""
:type s: str
:rtype: str
"""
vowels = ['a','e','i','o','u']
rever = []
ret = []
for i in s:
if i.lower() in vowels:
rever.append(i)
ret.append(None)
else:
ret.append(i)
for idx, value in enumerate(ret):
if value is None:
ret[idx] = rever.pop()
return ''.join(ret)效率比較好的演算法
def reverseVowels(self, s):
"""
:type s: str
:rtype: str
"""
vowels = {'a', 'e', 'i', 'o', 'u', 'A', 'E', 'I', 'O', 'U'}
s = list(s)
i, j = 0, len(s) - 1
while i < j:
if s[i] not in vowels:
i += 1
elif s[j] not in vowels:
j -= 1
else:
s[i], s[j] = s[j], s[i]
i += 1
j -= 1
return ''.join(s)破題,就是最後不要 10
def isOneBitCharacter(self, bits):
"""
:type bits: List[int]
:rtype: bool
"""
n = len(bits)
i = 0
while i < n -1:
if bits[i] == 0:
i += 1
else:
i += 2
return i == n-1 找出正確長按鍵,覺得最近腦袋不好,都會想一些怪怪解法,算了算了心累心累
def isLongPressedName(self, name, typed):
"""
:type name: str
:type typed: str
:rtype: bool
"""
from itertools import groupby
names = [[k, list(g)] for k, g in groupby(name)]
typeds = [[k, list(g)] for k, g in groupby(typed)]
if len(names) != len(typeds):
return False
for idx, value in enumerate(names):
if names[idx][0] == typeds[idx][0]:
if len(typeds[idx][1]) < len(names[idx][1]):
return False
else:
return False
return Truei = 0
for l in typed:
if i == len(name):
return True
if l == name[i]:
i += 1
elif l != name[i-1]:
return False
if i == len(name):
return True
else:
return False覺得題目寫得不甚清楚,怎麼說呢?因為 a^2 + b^2 = c 但沒說 a, b 其中可不可以是 0,反正後來測了一下發現其中一個數可以是 0,嗯,所以後來我的解法就是 用一個 while 迴圈,先用 C 去減去某個數平方,接著再看看這個數能不能被開根號。
但效能不太好 qq
def judgeSquareSum(self, c):
"""
:type c: int
:rtype: bool
"""
if c == 0:
return True
import math
a = 1
while True:
b_pow = c - math.pow(a, 2)
if b_pow >= 0:
b = math.sqrt(b_pow)
if int(b) == b:
return True
else:
return False
a += 1後來又想起好解法
low = 0
high = int(c**0.5)
while low <= high:
v = low*low + high*high
if v < c:
low += 1
elif v > c:
high -= 1
else:
return True
return False快速解題,反轉字串但是限制把字串切個成 2k 組,然後每一組的 k 個 string 反轉。
應幹法:
def reverseStr(self, s, k):
"""
:type s: str
:type k: int
:rtype: str
"""
l = 2*k
count = len(s) // l + 1
begin = 0
reverse = ''
for c in range(count):
if c == count:
temp = s[begin:]
if len(temp) >= k:
temp = temp[0:k][::-1] + temp[k:]
else:
temp = s[begin:begin+l]
temp = temp[0:k][::-1] + temp[k:]
reverse += temp
begin += l
return reverse看到不錯作法:
def reverseStr(self, s, k):
"""
:type s: str
:type k: int
:rtype: str
"""
i =0
mylist = []
count = 0
while i < len(s):
if count%2 != 0 :
mylist.append(s[i:i+k])
else:
mylist.append(s[i:i + k][::-1])
i += k
count += 1
return ''.join(mylist)帕斯卡三角形,就是一種規則,原本想到寫法用前一個結果去計算下一個結果,所以多寫一個 method,但感覺效能不佳。
def generate(self, numRows):
"""
:type numRows: int
:rtype: List[List[int]]
"""
if numRows == 0:
return []
ret = [[1]]
for n in range(numRows-1):
data = self.gen(ret[n])
ret.append(data)
return ret
def gen(self, lists):
ret = []
for idx in range(len(lists)+1):
if idx == 0 or idx == len(lists):
ret.append(lists[0])
else:
data = lists[idx-1] + lists[idx]
ret.append(data)
return ret看一下別人解法 lambda
def generate(numRows):
"""
:type numRows: int
:rtype: List[List[int]]
"""
if numRows==0:
return []
res = [[1]]
if numRows == 1:
return [[1]]
else:
for i in range(1,numRows):
res += [list(map(lambda x,y: x+y,res[i-1]+[0], [0]+res[i-1]))]
return res覺得這題難再說明(尤其是英文),我覺得搞懂英文其實問題不難。 題目要講的有兩個概念,每一局得到分數,和加總分數。兩邊要分別來處理:
C 代表前一個分數要移除D 代表前一個有效分數要乘以 2+ 代表加總前兩個數據簡單做法就是建立一個 list 來處理這些操作,這樣就會建立一個新的 list 最後再加總這個 list,夠簡單吧,下面這解法可以跑出 32ms NO.1(好啦,這種題目對於時間複雜度根本沒意義 XDDDD)
def calPoints(self, ops):
"""
:type ops: List[str]
:rtype: int
"""
collects = []
for stack in ops:
if stack == "C":
collects.pop()
elif stack == "D":
data = collects[-1]
collects.append(int(data)*2)
elif stack == '+':
collects.append(collects[-1]+collects[-2])
else:
collects.append(int(stack))
return sum(collects)來個簡單的無聊題,根據要求 filter 字串後找除沒有重複的 email,回傳數量
def numUniqueEmails(self, emails):
"""
:type emails: List[str]
:rtype: int
"""
emails_filter = []
for email in emails:
local, domain = email.split('@')
local = local.split('+')
if len(local) >= 2:
local = local[0].replace('.', '')
emails_filter.append("{}@{}".format(local, domain))
return len(set(emails_filter))一個無聊題目,就是給一個二維陣列去算到底有幾個 3*3 滿足每一行、列、對角線總和都一樣
然後我就開始硬幹了,寫了有夠奇怪的程式碼。概念上就是三層迴圈,行與列和對角線,然後還要去檢查小於 0 大於 9 的矩陣式不合法的,但馬的這程式碼....
def numMagicSquaresInside(self, grid):
"""
:type grid: List[List[int]]
:rtype: int
"""
count = 0
for idx in range(3, len(grid)+1):
subgrid = grid[idx-3:idx]
for i in range(3, len(subgrid[0])+1):
collect = set()
river = []
diag_l = 0
diag_r = 0
candidate = True
for idx, g in enumerate(subgrid):
if idx <= 2:
river.extend(g[i-3:i])
collect.add(sum(g[i-3:i]))
diag_l += g[i-3:i][idx]
diag_r += g[i-3:i][2-idx]
collect.add(diag_l)
collect.add(diag_r)
for i in river:
if i <= 0 or i > 9:
candidate = False
break
if len(collect) == 1 and candidate:
count += 1
return count不過好像有個準則是可以判斷中間數是不是 5
根據值是 odd, even 放在對應的 index 位置,沒想太多,用了個 while 迴圈先將值存到另一個 list,然後再用 zip 分類,但速度太慢
ret = [[], []]
while True:
for idx, value in enumerate(A):
if value % 2: #even
ret[1].append(A.pop(idx))
else:
ret[0].append(A.pop(idx))
if not A:
break
even, odds = ret
result = [item for tup in zip(even, odds) for item in tup ]
return result比較好的做法:
res = [0]*len(A)
odd = 1
even = 0
for i in A:
if i % 2 == 0:
res[even] = i
even += 2
else:
res[odd] = i
odd += 2
return res做個 hashmap,主要就是可以了解一些 dict 特性,可以讓性能加速
class MyHashMap:
def __init__(self):
"""
Initialize your data structure here.
"""
self.dicts = {}
def put(self, key, value):
"""
value will always be non-negative.
:type key: int
:type value: int
:rtype: void
"""
self.dicts[key] = value
def get(self, key):
"""
Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key
:type key: int
:rtype: int
"""
return self.dicts.get(key, -1)
def remove(self, key):
"""
Removes the mapping of the specified value key if this map contains a mapping for the key
:type key: int
:rtype: void
"""
if self.dicts.get(key, 0):
return self.dicts.pop(key)就找出不能分解成 2, 3, 5 的數字,特別的一點是 (1 行但 0 不行),while 迴圈就對惹,然後對於負數 mod 有個有趣的議題,不同語言做法不同(http://blog.thpiano.com/?p=1023)
def isUgly(self, num):
"""
:type num: int
:rtype: bool
"""
while True:
if num == 0:
return False
elif num == 1:
return True
elif num % 2 == 0:
num = num // 2
elif num % 3 == 0:
num = num // 3
elif num % 5 == 0:
num = num // 5
else:
return False
if num in [1, 2, 3, 5]:
return True其他覺得不錯作法
class Solution:
def isUgly(self, num):
"""
:type num: int
:rtype: bool
"""
if num <= 0:
return False
while num % 2 == 0:
num = num / 2
while num % 3 == 0:
num = num / 3
while num % 5 == 0:
num = num / 5
return abs(num) == 1 or num == 0去計算區間的數值加總,一開始當然還是笨笨的直接用串列切片+sum 還處理,後來看一下別人發現可以先累加起來後再去找區間
class NumArray:
def __init__(self, nums):
"""
:type nums: List[int]
"""
self.nums = nums
def sumRange(self, i, j):
"""
:type i: int
:type j: int
:rtype: int
"""
return sum(self.nums[i:j+1])先累加:
class NumArray(object):
def __init__(self, nums):
self.dp = nums
for i in range(1, len(nums)):
self.dp[i] += self.dp[i-1]
def sumRange(self, i, j):
return self.dp[j] - (self.dp[i-1] if i > 0 else 0)回文解題,不囉唆就是能接受 09 az A~Z 總之我很懶惰直接用 ord 去做 if else 判定符合於否?也許 re 會更適合吧? s = re.sub(r'[^a-zA-Z0-9]', '', s)
def isPalindrome(self, s):
"""
:type s: str
:rtype: bool
"""
s = ''.join([i for i in s.lower() if 123 > ord(i) >= 97 or 57 >= ord(i) >= 48])
return True if s == s[::-1] else False 覺得很奇怪,目前似乎在這種結構處理會比較清楚,但是遇到偏數學的問題會死掉 xdd。 總之這問題很簡單,domain 拜訪,例如網站 discuss.leetcode.com 會從 root 接著一路拜訪到最終節點 com -> leetcode -> dicuss
所以如果你拜訪了 dicsuss.leetcode.com, test.leetcode.com, 各一次,
用 Python 做沒有很難,就是用 dict 去存,然後兩層 for 處理資料。
def subdomainVisits(cpdomains):
"""
:type cpdomains: List[str]
:rtype: List[str]
"""
domains = {}
for cpdomain in cpdomains:
visit, cpdomain = cpdomain.split(' ')
cpdomain = cpdomain.split('.')
for i in range(len(cpdomain)):
domain = '.'.join(cpdomain[i:])
if domain in domains:
domains[domain] = int(visit) + domains[domain]
else:
domains.setdefault(domain, int(visit))
ret = ["{0} {1}".format(v,k) for k, v in domains.items()]
return ret沒什麼,就是只要出現一詞的單字。其實主要就是要怎麼找到出現一次的。set() 好用!
def uncommonFromSentences(self, A, B):
"""
:type A: str
:type B: str
:rtype: List[str]
"""
alls = A.split(' ') + B.split(' ')
reduce = list(set(alls))
ret = []
for r in reduce:
if alls.count(r) == 1:
ret.append(r)
return ret快速搜尋,主要就是比速度啦,可以用線性也可以用 log(n),線性就是一層 for,log(n)就是用快速搜尋。我很懶用腦直接線性
def peakIndexInMountainArray(self, A):
"""
:type A: List[int]
:rtype: int
"""
candidate = 0
for i in A:
candidate = max(candidate, i)
return A.index(candidate)log(n) 很單純就是找出第一個、最後一個和中間,假如中間那個大於前一個與後一個就是最大值,如果沒有,但大於前一個值那就從中間值的前一個再繼續,反之就是中間值變成最後一個值
def peakIndexInMountainArray(A):
"""
:type A: List[int]
:rtype: int
"""
start, end = 0, len(A) - 1
while start + 1 < end:
mid = start + (end - start) // 2
if A[mid - 1] < A[mid] > A[mid + 1]:
return mid
elif A[mid - 1] < A[mid]:
start = mid
else:
end = mid
return -1寫 tree 覺得太喪志,所以來寫一下簡單的,真的很簡單就是做一件事,把一個 list in list 做一次 reverse 然後再做一次與 1 的互斥來反轉。 重點是直接串列表達式搭配 lambda 實在是美不勝收
def flipAndInvertImage(self, A):
"""
:type A: List[List[int]]
:rtype: List[List[int]]
"""
return [map(lambda x:x^1, list(reversed(d))) for d in A]這個稍微要燒腦一下,主要有幾個條件 k=0, k>0, k<0,一開始我的想法是很單純:
def findPairs(nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: int
"""
repeat = 0
if k == 0:
for n in set(nums):
if nums.count(n) >= 2:
repeat += 1
return repeat
elif k > 0:
nums = list(set(nums))
nums.sort()
ret = []
for idx, n in enumerate(nums):
candidate = n + k
if candidate in nums[idx+1:]:
ret.append((n, candidate))
return len(ret)
elif k < 0:
return 0但這樣會超時,為什麼會超時是在 if candidate in num[ix=1:] 因為每一次搜尋都是線性的,所以必須從這邊著手優化:
概念上就是 dict 去存 candidate(nums[i]+k) 如果有就放到 count,因為 dict 是 O(1)
nums.sort()
count = []
dict = {}
for i in range(len(nums)):
if nums[i] in dict:
count.append((dict[nums[i]],nums[i]))
dict[nums[i]+k] = nums[i]
return len(set(count))
參考別人做法則是用 Python 一個 collections.Counter(),類似 dict 概念但更簡短。感覺挺美的記錄起來
res = 0
c = collections.Counter(nums)
for i in c:
if (k > 0 and i + k in c) or (k == 0 and c[i] > 1):
res += 1
return res找 tree 的深度。開始解 tree 的問題。後來有點沒理解物件怎麼操作所以偷看了一下答案,簡單來說就是 root 是個物件,然後把它擺入 list 中。
def minDepth(self, root):
"""
:type root: TreeNode
:rtype: int
"""
if root == None:
return 0
depth = 0
q = [root]
while len(q):
depth += 1
for i in range(0, len(q)):
if not q[0].left and not q[0].right:
return depth
if q[0].left:
q.append(q[0].left)
if q[0].right:
q.append(q[0].right)
q.remove(q[0])
return depth找出第三大的數,這很單純就是一種把多得先移除掉,然後排序找第三大的數。但假如沒有三個數以上,就找最後一個。
策略: set() 移除多餘數,接著反向排序,大->小,最後判斷是否有超過三個數以上,如果三個數以上就印出第 3 個,小於三個就印第 1 個(為什麼,因為沒有第三大就印最大)
def thirdMax(nums):
"""
:type nums: List[int]
:rtype: int
"""
new_nums = list(set(nums))
new_nums.sort(reverse=True)
if len(new_nums) >= 3:
return new_nums[2]
return new_nums[0]
if __name__ == '__main__':
print(thirdMax([4,3,2,1]))
print(thirdMax([3,2,1]))
print(thirdMax([1,2]))啊,不小心就第一名 36ms XD 看起來差不多要開始練中階難度惹~
多條件的判斷,我覺得考的是邏輯。因為有些條件互相干擾,所以要考驗邏輯是否清晰。
意思大概就是兩個字串 a, b 比較,如果 b 換了兩個字幕和 a 相同才能返回 True。直接上 code,這個解法大概速度 40ms 我是用 zip 法兩個字串根據順序變成一對,類似 A='aaab', B='aaac' -> [(a,a), (a,a), (a,a), (b,c)]。接著我就順序比對,接著用 candidate_a, b 去存不一樣的, same 去確認是否相同, diff 去知道不同出現幾次。
def buddyStrings(A, B):
"""
:type A: str
:type B: str
:rtype: bool
"""
if abs(len(A) - len(B)) >= 2:
return False
groups = list(zip(list(A), list(B)))
new_groups = list(set(groups))
print(new_groups)
candidate_a, candidate_b, same, diff = [], [], True, 0
for i in range(len(new_groups)):
if new_groups[i][0] != new_groups[i][1]:
candidate_a.append(new_groups[i][0])
candidate_b.append(new_groups[i][1])
same = False
diff += 1
print(len(groups), len(new_groups), diff)
if same:
if len(groups) == len(new_groups) and len(new_groups) != 1:
return False
return True
candidate_a.sort()
candidate_b.sort()
if candidate_a == candidate_b:
if diff > 2:
return False
return True
return False
if __name__ == '__main__':
print(buddyStrings(A="aaaaaaabc", B="aaaaaaacb"))
print(buddyStrings(A="aa", B="aa"))
print(buddyStrings(A="ab", B="ab"))
print(buddyStrings(A="abcd", B="badc"))set() 觀念,可以排除重複的 list。題目先要求把英文字母轉換成
alphabet = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."] 然後給幾個 word,問說這樣轉換會變成幾個新字?
我比較死腦,所以先 mapping 成字典再轉
def uniqueMorseRepresentations(self, words):
"""
:type words: List[str]
:rtype: int
"""
letters = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
alphabet = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
dict_alphabet = dict(zip(letters, alphabet))
new_words = []
for w in words:
new_words.append(''.join([dict_alphabet.get(i) for i in w]))
return len(set(new_words))還有個比較省力方法,就是用 ord 去算出字母對應的符號,例如 b = ord('a')-ord('b') = 1,計算能力差 QQ,大概四這樣:
new_words = []
for w in words:
temp = ''
new_words.append(''.join([alphabet[ord(i) - ord('a')] for i in w]))給一個 list,偶數排前,基數排後。然後用串列表達式跑出第一名 XDDDDD
def sortArrayByParity(self, A):
"""
:type A: List[int]
:rtype: List[int]
"""
odds = [a for a in A if a%2]
evens = [a for a in A if not a%2]
return evens + oddsToeplitz 矩陣內數字的對角線要相同。考搜尋演算法。這個在某個地方好用 bingo。我的解法是先建立 row, col 接著從第一行開始做為比較點,一行行搜尋,每切換一行,搜尋的位置就要往右移一位。
class Solution:
def isToeplitzMatrix(self, matrix):
"""
:type matrix: List[List[int]]
:rtype: bool
"""
row = len(matrix[0])
col = len(matrix)
candidate = matrix[0]
for i in range(1, col):
move = 1
for j in range(move, row):
if candidate[j-1] != matrix[i][j]:
return False
candidate = matrix[i]
move += 1
return True官方提供的另一個方法,神屌。
all(r == 0 or c == 0 or matrix[r-1][c-1] == val
for r, row in enumerate(matrix)
for c, val in enumerate(row))自我整除數字,例如 128 可以拆解 1, 2, 8 三個數字,128 % [1,2,3] 都為 0 所以就是可以自我整除數。但 10 這個數字包含 0 就不算自我整除數。
太久沒寫。很爛的寫法:
def selfDividingNumbers(left, right):
"""
:type left: int
:type right: int
:rtype: List[int]
"""
res = list()
for i in range(left, right+1):
divids = list(str(i))
if len(divids) == 1:
res.append(i)
else:
candidate = True
for j in [int(d) for d in divids]:
if j == 0:
candidate = False
elif i%int(j) != 0:
candidate = False
if candidate:
res.append(i)
return resshift list,考個 idx, value 之間的腦筋急轉彎。一開始我的想法假設這個移動是一次性的,就 [1,2,3,4,5,6,7] shift 3 就是 [5,6,7,1,2,3] 每個數字不會有一次以上停留。前提就是 shirt 要小於 list 長度,所以我這樣做,看似一切都是很美好,但假設錯誤。因為可能有一次以上停留。
例如 [1,2] shift k=2 這樣就出問題,因為數字經過移動之後又回到自己位置上,這樣寫法是錯誤的。
def rotate(nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: void Do not return anything, modify nums in-place instead.
"""
part1 = []
part2 = []
for n in range(k+1, len(nums)):
part1.append(nums[n])
for n in range(0, k+1):
part2.append(nums[n])
return part1 + part2於是想了一下,畫個表格答案就出來, 主要在於 shift 後處理,如果加上移動的位置超出原本長度,那你就要用 mod 去計算出相對的位置:
| idx | value | shift = 3 |
|---|---|---|
| 0 | 1 | idx + k = 3, 3%len(2) = 1 |
| 1 | 2 | idx + k = 4, 4%len(2) = 0 |
def rotate(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: void Do not return anything, modify nums in-place instead.
"""
new_nums = nums.copy()
for idx, value in enumerate(new_nums):
if idx + k < len(new_nums):
nums[idx+k] = value
else:
nums[(idx+k)%len(new_nums)] = value找出最大的迴文數字,例如 n = 2,最大的迴文數範圍就是 99*99 ~ 10*10 目標就是找這組乘數內最大的。
不過一開始想了很多方式都超時,最後覺得最好的做法仍舊超時,想法是用巢狀迴圈去相乘數字,因為要找最大迴文,範圍就在 9 為開頭範圍內。但這樣做法 n=7 就爆炸了。
def largestPalindrome(n):
"""
:type n: int
:rtype: int
"""
multi = 10**(n)-1
minnum = 10**(n-1)*9
if n == 1:
return 9
for i in range(multi, minnum, -1):
for j in range(multi, minnum, -1):
num = i * j
if str(num)[0::] == str(num)[::-1]:
return num % 1337
於是 Google 一下發現一個,這應該是作弊的做法吧?
return [9, 9009, 906609, 99000099, 9966006699, 999000000999, \
99956644665999, 9999000000009999][n - 1] % 1337
看到解答有些比較規矩的做法:
class Solution:
def largestPalindrome(self, n):
"""
:type n: int
:rtype: int
"""
if n == 1:
return 9
if n == 8:
return 475
upper = pow(10, n)
lower = pow(10, n - 1)
for p in self.gen(n):
pSqrt = int(math.sqrt(p))
for i in range(upper - 1, pSqrt, -1):
if p % i == 0:
return p % 1337
def gen(self, n):
upper = pow(10, n)
lower = pow(10, n - 1)
for i in range(upper - 1, lower - 1, -1):
yield int(str(i) + str(i)[::-1])
資料庫問題, 有個 table salary 需要做個變動 sex f -> m, m -> f 要如何做到? 用 update 來處理就行了。
Update salary
SET sex = (
CASE WHEN sex = "m"
THEN "f"
ELSE "m"
END
)
找出錯誤版本,簡單來說就是給你一串軟體版本數字 n = [1, 2, 3, 4, 5] 每個數字背後都有 True or False 代表好與壞,但如果我們想知道何時開始壞呢?
二進位搜尋(Binary search tree) 就成了我們的好幫手!因為他是效能很好的搜尋方法!
class Solution(object):
def firstBadVersion(self, n):
"""
:type n: int
:rtype: int
"""
low = 0
high = n
while low <= high:
mid = (low + high) // 2
value = isBadVersion(mid)
if value:
high = mid - 1
else:
low = mid + 1
return low小王和小明偏好的餐廳列表順位裡,彼此交集且是個人偏好較前面的獲選。意思就是小明偏好順序 ['subway', 'kfc', 'M'] 小王偏好順序 ['king nodle', 'subway', 'm']
彼此都喜歡的餐廳有 ['subway', 'm'] 但小明和小王偏好 subway 的順序加總是 0 + 1, m 是 2 + 2 所以 subway 是首選。
解法很簡單,先找出交集接著在找加總最小的。
class Solution(object):
def findRestaurant(self, list1, list2):
"""
:type list1: List[str]
:type list2: List[str]
:rtype: List[str]
"""
stack = []
for r in list1:
if r in list2:
stack.append(r)
min_sum = sum([len(list1), len(list2)])
candidate = []
for s in stack:
mins = sum([list1.index(s), list2.index(s)])
min_sum = min(min_sum, mins)
if mins <= min_sum:
candidate.append(s)
if len(stack) == 1:
return stack
return candidate找串列裡面由小到大的最長。例如 [1,3,5,7,3,4,9] 長度就是 1, 3, 5, 7 長度為 4。線性找 O(n),不斷與前一個數字比較。
def findLengthOfLCIS(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if not nums:
return 0
count = max_now = 1
for idx in range(1, len(nums)):
if nums[idx] > nums[idx - 1]:
count += 1
else:
max_now = max(max_now, count)
count = 1
max_now = max(max_now, count)
return max_now給定兩個串列: A or B 找出 B 是 A 的串列,且 A 重複最少次。覺得就是用 while 迴圈去累積 A 的倍數,條件是 A 的長度超過 10000 就判定沒有。
def repeatedStringMatch(self, A, B):
"""
:type A: str
:type B: str
:rtype: int
"""
a = A
mutiple = 1
while True:
if B in A:
return mutiple
A += a
mutiple += 1
if len(A) > 10000:
return -1以上的順序是新到舊
以下的順序是舊到新
問題是把 intenger 轉 binary 然後 0, 1 反轉。硬幹就是不斷 mod 2 解出二進位同時 xor 1 就是反轉的二進位。 應該有更漂亮的解法。這樣做大概是 O(N)
def findComplement(self, num):
"""
:type num: int
:rtype: int
"""
binary = []
while num != 0:
binary.insert(0, (num%2)^1)
num = num//2
return int(''.join(map(str, binary)),2)問題是用一個陣列存糖果,這些糖果要分配給哥哥、妹妹然後要一個人的到最多種類糖果。 乍看有點難,但其實挺容易,概念其實很簡單,不需要全部分配出來,只要先把糖果根據種列排序之後開始分糖給妹妹一人(假設妹妹要最多種類),用一個變數存當下拿到的種類,沒拿過就拿,有拿過就不拿,直到糖果都分完或是妹妹拿到一半的糖果了。
class Solution(object):
def distributeCandies(self, candies):
"""
:type candies: List[int]
:rtype: int
"""
candies.sort()
each_candy_num = len(candies)//2
sister = []
before_get = ''
for candy in candies:
if before_get != candy:
sister.append(candy)
before_get = candy
if len(sister) == each_candy_num:
return len(sister)
return len(sister)或是回傳糖果除 2 或是拿掉重複其一最小值。
return min(len(candies) / 2, len(set(candies)))找出 alphbet 中位於美式英文鍵盤中同一行。簡單說就是把字串拆成字元比較。不過要用到 set 先把重複的拿掉。
class Solution(object):
def findWords(self, words):
"""
:type words: List[str]
:rtype: List[str]
"""
line1 = ['q','w','e','r','t','y','u','i','o','p']
line2 = ['a','s','d','f','g','h','j','k','l']
line3 = ['z','x','c','v','b','n','m']
one_row = []
for word in words:
w = list(word.lower())
if set(w) - set(line1) == set():
one_row.append(word)
elif set(w) - set(line2) == set():
one_row.append(word)
elif set(w) - set(line3) == set():
one_row.append(word)
return one_row方格裡 1 是陸地 0 是河流,計算島嶼的長度。
概念,島嶼相連部分的邊會被重複計算,所以一個沒有相連的島嶼邊長是 4 左右兩個或是上下兩個相連島嶼長是 (4*2)-2=6 有了這個公式就好做了。
策略:看左看上,第一排島嶼沒有上只看左。左邊有島或是上面有島就各扣 2。挺無聊的。還沒想到更快作法,因為 dataset 一定要用 nested 讀, O(N^2)
def islandPerimeter(self, grid):
"""
:type grid: List[List[int]]
:rtype: int
"""
count = 0
for i in range(0, len(grid)):
for j in range(0, len(grid[i])):
#print('{}, {}:'.format(i, j))
if grid[i][j] == 1:
count += 4
#print(count)
if i == 0:
if j >= 1:
if grid[i][j-1] == 1:
count -= 2
#print(count)
else:
if j >= 1:
if grid[i][j-1] == 1:
count -= 2
#print(count)
if grid[i-1][j] == 1:
count -= 2
#print(count)
return count兩個 list 的交集。單純練 Python built-in function
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
set1 = set(nums1)
set2 = set(nums2)
return list(set1.intersection(set2))num1, num2 兩個 list, num1 是 num2 的子集,做一個任務,循序的讀 num1 接著對應相同數字 num2 所在 index 位置,接著往後找,如果有比它大的數字就成功,沒有就失敗。成功的用 list 把數字存起來,失敗的存 -1。看到有人用 stack技巧挺屌的。
我是取得數字後找到對應的 num2 數字 index,開始找,找到跳出,沒找到就到底結束。
def nextGreaterElement(self, findNums, nums):
"""
:type findNums: List[int]
:type nums: List[int]
:rtype: List[int]
"""
ret = []
for idx, value in enumerate(findNums):
i = nums.index(value)
while nums[i] <= value:
if i == len(nums)-1:
ret.append(-1)
break
i += 1
else:
ret.append(nums[i])
return ret 最長的不共同子序列,假如兩個字串不同那最長子序列一定是最長的字串長度,兩個字串相同就沒有不共同子序列
def findLUSlength(self, a, b):
"""
:type a: str
:type b: str
:rtype: int
"""
return a != b and max(len(a), len(b)) or -1在一個排序好的陣列找尋只有一個的數字。時間複雜度 O(logn) or O(1)。想到 binary search, 不過關於 O(1) 如何達到沒想法。二元搜尋也是頗為精巧,可以好好不斷品味。
def singleNonDuplicate(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
# binarysearch can limit time compilexy O(logn)
low = 0
high = len(nums) - 1
while low < high:
mid = low + (high - low) // 2
if mid % 2 == 1:
mid -= 1
if nums[mid] != nums[mid + 1]:
high = mid
else:
low = mid + 2
return nums[low]Happy Number 意思是給定進位置下將所有位數平房和不斷週而復始最後得到 1 的數。這個除了測試概念,但讓我收穫最多應該是在觀摩其他人的解法得到巧思。
一開始我是這樣做的,反正不管三七二十一我先查到 not happy number,想法是在無窮遞解的過程只要發現是屬於 Not happy number 就停止求解,沒什麼不多。但你就必須知道哪些 not happy number。
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
nohappy = [2,3,4,5,6,8,9,16,37,58,89,145,42,20]
if n in nohappy:
return False
if n == 1 or n == 7:
return True
while True:
nums = list(str(n))
temp = 0
for num in nums:
temp += int(num)**2
if temp == 1:
return True
if temp in nohappy:
break
n = temp
return False後來參考了其他大大解法發現一些很美妙的想法,有點像是 Divide and Conquer。首先建立一個 set() 存被分解的數,因為 not happy number 在不斷分解過程最後會重複:4 → 16 → 37 → 58 → 89 → 145 → 42 → 20 → 4 只要重複了就是 not happy number, 假如被分解成 1 就是 happy number。非常美麗的寫法。
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
value_set = set()
value_set.add(n)
current_value = n
while True:
current_value = self._get_next_value(current_value)
if current_value == 1:
return True
elif current_value in value_set:
return False
value_set.add(current_value)
def _get_next_value(self, current_value):
result = 0
while current_value > 0:
this_digit = current_value % 10
result += this_digit ** 2
current_value /= 10
return resulta 有沒有包含在 b 的問題。概念上有兩種做法,迴圈讀出 A 從 B 移除,假如沒有東西能夠移除就是 false,另外的概念比較快,就是先把重複的拿掉,接著迴圈比較 A 內字串是否有大於 B(要包含不能大於)
def canConstruct(self, ransomNote, magazine):
"""
:type ransomNote: str
:type magazine: str
:rtype: bool
"""
for i in set(ransomNote):
if ransomNote.count(i) > magazine.count(i):
return False
return True就是進位制轉換,簡單講就是不斷 mod 某個基底然後求得。有些技巧可以參考。
def convertToBase7(self, num):
"""
:type num: int
:rtype: str
"""
n = abs(num)
ans = ''
while n:
ans += str(n % 7)
n //= 7
return ['', '-'][num < 0] + ans[::-1] or '0'字串比較經典,比較字串共同的前綴,例如:abcde,abc 共同前綴 abc。除了自己解法也很值得看看別人解法:
思路是兩層巢狀迴圈,先兩兩比較,用一個空字串存相同的部分。這樣處理概念上 ok 但速度不快,因為每一次字串要在從前到後比對一次。
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
if len(strs) == 0:
return ''
common = strs[0]
for i in range(1, len(strs)):
minlen = min(len(strs[i]), len(common))
cmpstr = ''
"""
for j in range(0, minlen):
if common[:j+1] == strs[i][:j+1]:
cmpstr += common[j]
"""
j = 0
while j != minlen:
if common[:j+1] == strs[i][:j+1]:
cmpstr += common[j]
else:
break
j += 1
common = cmpstr
return common有看到一個相同概念但很漂亮的 decorator 寫法:
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
def prefix(str1, str2):
out = ''
for i in range(min(len(str1), len(str2))):
if str1[i] == str2[i]:
out += str1[i]
else:
return out
return out
if len(strs) == 0:
return ''
elif len(strs) == 1:
return strs[0]
elif len(strs) == 2:
return prefix(strs[0], strs[1])
else:
pre = prefix(strs[0], strs[1])
for i in range(2, len(strs)):
pre = prefix(pre, strs[i])
if pre == '':
break
return pre神奇解法 1,2:
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
if not strs: return ''
s1 = min(strs)
s2 = max(strs)
for i, c in enumerate(s1):
if c != s2[i]:
return s1[:i]
return s1
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
return os.path.commonprefix(strs)挺有趣解法:
def longestCommonPrefix(self, strs):
"""
:type strs: List[str]
:rtype: str
"""
# empty strs
if strs == []:
return ''
minLen = min([len(s) for s in strs])
allLen, ii = True, 0
for i in range(minLen):
ii = i
if len(set([s[i] for s in strs])) != 1:
allLen = False
break
return strs[0][:ii + int(allLen and minLen > 0)]找字串,目前最好的演算法是 KMP,先用簡單的暴力解法吧。
def strStr(self, haystack, needle):
"""
:type haystack: str
:type needle: str
:rtype: int
"""
if len(needle) == 0 or needle == "":
return 0
'''
n = len(needle)
for i in range(0, len(haystack)):
if haystack[i] == needle[0]:
if haystack[i:i+n] == needle:
return i
return -1
'''
if not needle:
return 0
for i in xrange(len(haystack)-len(needle)+1):
if haystack.startswith(needle, i):
return i
return -1就是給一組數,根據 list 排列好例如:10 = [1,0] 把這個數加上 1 印出結果。這邊用到技巧就是如何還原串列的數字。接著再塞回去串列,或是突然想到直接在串列內一個個加上去。
def plusOne(self, digits):
"""
:type digits: List[int]
:rtype: List[int]
"""
n = len(digits)
total = 0
for i in range(0, n):
total += digits[i]*(10**(n-i-1))
total += 1
return [ int(i) for i in str(total)]概念是從尾巴加上去,但效能比較差呢 XD
n = len(digits)
for i in range(n-1, -1, -1):
if i == n - 1:
digits[i] += 1
if digits[i] == 10:
digits[i] = 0
if i == 0:
digits.insert(0, 1)
else:
digits[i-1] += 1
return digits給一個二進位形式的字串像是 "11" 兩個相加,然後回傳二進位形式。
想法是二進位先轉成十進位相加,加完之後再轉回二進位 XD
def addBinary(self, a, b):
"""
:type a: str
:type b: str
:rtype: str
"""
a = sum([ 2**(len(a)-i-1) for i in range(0, len(a)) if a[i] != '0'])
b = sum([ 2**(len(b)-i-1) for i in range(0, len(b)) if b[i] != '0'])
return bin(a+b)[2::]偷懶一點也是可以
return bin(int(a, 2) + int(b, 2))[2:]就這樣進入動態規劃囉(DP, Dynamic Programming)。動態規劃演算法可以參考這篇。 經驗是他改善遞迴(Recursive)效能問題。會結合分治法將問題切割,解決子問題並且將答案儲存,需要再做查詢。這裡是爬樓梯問題。
如果採遞迴作法會像這樣,不過大概 n = 30 機器就不行了,因為遞迴採取是堆疊方式解題,數量級越大效能就越不彰。
def climbStairs(self, n):
"""
:type n: int
:rtype: int
"""
if n == 1 or n == 2:
return n
else:
return self.climbStairs(n-1) + self.climbStairs(n-2)採取動態規劃,先將預先知道的值都計算並且存起來。然後再回傳。計算方法就是向前取值。因為我們知道爬樓梯問題就是爬一階梯只有 1 種方法,爬二階梯只有 1 種方法(爬上一梯),爬三階需要爬上第二階梯和第一階梯以此類推。
所以我們用迴圈用向前推倒方式把爬到第幾階的數量加總。
def climbStairs(self, n):
"""
:type n: int
:rtype: int
"""
t = self.dynamic_programming(n=n)
return t[-1]
def dynamic_programming(self, n):
table = [1, 1]
for i in range(2, n+1):
table.append(table[i-1] + table[i-2])
return table找出兩兩成對中落單的唯一數字。既然是兩兩成對那就兩個兩個一組去比吧?while 會不會比較好?
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if len(nums) == 1:
return nums[0]
nums.sort()
for i in range(len(nums)-1, -1, -2):
if nums[i] != nums[i-1]:
return nums[i]後來想了一下更快的做法。先把串列加總,接著用 set 移除掉重複的接著加總乘以 2,這樣兩個加總得差就是遺失的數字。
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if len(nums) == 1:
return nums[0]
total = sum(nums)
single = sum(set(nums))*2
return single - total但我有看到一個挺酷的做法,就是自己與自己做 XOR 來做自反律,意思就是 a^b^b = a^0 = a。所以假如串列 [-1,-1,-2] -1^-1^-2 = -2。讚吧!
def singleNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
res = 0
for num in nums:
res = res^num
return res一山還比一山高,永遠有最快的。這題是在做把一個串列排序之後,前到後兩兩一組,取最小值的相加。概念很簡單但腦袋要轉! 一開始排序後線性取值兩兩比最小相加。殊不知道,其實根本不用多比較,基數就是最小值啊啊啊啊
def arrayPairSum(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
nums.sort()
count = 0
for i in range(0, len(nums), 2):
count += min(nums[i], nums[i+1])
return count這就是比較快的做法。
return sum(sorted(nums)[::2])給一個串列,數字是 1 or 0 找出連續最多的 1。有兩種做法,用一個 list 存每一段的加總然後再取出 max,或是建立一個 maxcount 每次中斷時比較,發現更大的值就置換。我是用第一種方法。
有個雷是假如最後一個數字是 1 代表沒有中斷,要再存一次,變成最後一個是 0 會多存一次。但沒有關係反正取最大只是重複一個。
def findMaxConsecutiveOnes(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
if len(nums) < 1:
return nums[0]
regist = []
count = 0
for i in range(0, len(nums)):
if nums[i]:
count += 1
else:
if i != 0:
regist.append(count)
count = 0
regist.append(count)
return max(regist)判斷字首的規則:1. 全部大寫, 2. 全部小寫, 3. 開頭大寫之後都小寫。 想法是用 ord() 的 build-in function 來判斷並存在一個串列。
def detectCapitalUse(self, word):
"""
:type word: str
:rtype: bool
"""
if len(word) == 1:
return True
ascii = []
for w in word:
if ord(w) < 65 or ord(w) > 90:
ascii.append(0)
else:
ascii.append(1)
if ascii[0]:
if 1 not in ascii[1::]:
return True
if 0 not in ascii[1::]:
return True
else:
if 1 not in ascii[1::]:
return True
return False但其實可以直接用 isupper() 這個 str 的方法來做判斷就可以。程式碼可以比較少,而且不用做第二次判斷和增加空間複雜度
def detectCapitalUse(self, word):
if len(word) > 1:
if word[0].isupper():
return word[1:].isupper() or word[1:].islower()
else:
return word[1:].islower()
else:
return True找出遺漏的數字。就是有一個長度 n 的串列有一些值可能重複或是不在範圍內要找出是哪些。 一開始想法就是建立一個正常的串列然後減去遺失串列。差異就是遺失的。
def findDisappearedNumbers(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
n = len(nums) + 1
full = set([ i for i in range(1, n)])
nums = set(nums)
return list(full - nums)Codility 也有類似的,當時解法是這樣。建立一個串列,用串列 index 作為判斷準則。串列都先塞 false, 假如值存在就換成 true。
def findDisappearedNumbers(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
seen = [False] * len(nums)
for value in nums:
if 1 <= value > len(nums):
pass
if seen[value-1] == True:
pass
seen[value-1] = True
return [i+1 for i in range(0, len(seen)) if not seen[i]]上面可以改寫判斷式:
def findDisappearedNumbers(self, nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
seen = [False] * len(nums)
for value in nums:
if len(nums) >= value >= 1:
seen[value-1] = True
return [i+1 for i in range(0, len(seen)) if not seen[i]]概念上來說除以 10,取餘數就可以不斷把數字做分解。
def addDigits(self, num):
"""
:type num: int
:rtype: int
"""
while num >= 10:
num = (num // 10) + (num % 10)
return numBinary search 的變形。找串列內某個和為 X 的 index 位置。
def twoSum(self, numbers, target):
"""
:type numbers: List[int]
:type target: int
:rtype: List[int]
"""
base = []
for i in range(0, len(numbers)):
if numbers[i] not in base:
guess = target - numbers[i]
ret = self.binary_search(numbers[i:], item=guess)
if ret:
if guess == numbers[i]:
return [i+1, numbers.index(guess)+2]
return [i+1, numbers.index(guess)+1]
base.append(numbers[i])
def binary_search(self, list, item):
low = 0
high = len(list) - 1
while low <= high:
mid = (low + high) // 2
guess = list[mid]
if guess == item:
return True#mid
if guess > item:
high = mid - 1
else:
low = mid + 1
return Falseif len(numbers) == 0 or len(numbers)==1:
return None
i=0
j=len(numbers)-1
while i<j:
total = numbers[i]+numbers[j]
if total == target:
return [i+1,j+1]
elif total<target:
i+=1
else:
j-=1
return None找出遺失的一個數字。一般來說會用迴圈去一個個找,但問題是如果數字在最後一個,那就會花飛很久例如 [0,1,2,3,4,5,6,8] 另外一種是用 set 相減找遺失的數。既然想到這個方法那乾脆加總原本串列和完整的各兩個串列然後相減
def missingNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
n = len(nums)+1
complety = [i for i in range(n)]
miss = sum(complety) - sum(nums)
return miss就是 26 進制轉換。看看別人優美的程式碼很不錯。
進制轉換就是有一張表,表示 base,然後由 x 進制轉 y 進制就是從右到左平方不斷累加,y 轉 x 回來就是 mod 取餘數。
def titleToNumber(s):
"""
:type s: str
:rtype: int
"""
words = [chr(i) for i in range(97, 123)]
nums = [i for i in range(1, 27)]
mapping = dict(zip(words, nums))
if len(s) == 1:
return mapping[s.lower()]
s = list(s)
n = len(s)
col = 0
for i in range(len(s) - 1, -1, -1):
col += mapping[s[i].lower()] * (26 ** (n - i - 1))
return col看到一個更好的做法:
def titleToNumber2(s):
"""
:type s: str
:rtype: int
"""
if not s:
return
result = 0
for ch in s:
result *= 26
result += ord(ch) - ord('A') + 1
return result給一個串列找出相乘最大的三值。例如 [-3, -2, -1, 0, 1, 2] 最大是 -3 * -2 * 2 = 12 其實就是比叫排序後前兩位相乘和倒數兩位相乘的大小。
def maximumProduct(nums):
"""
:type nums: List[int]
:rtype: int
"""
a, b, c = 0, 0, 0
nums.sort()
return max(nums[0] * nums[1] * nums[-1], nums[-1] * nums[-2] * nums[-3])反轉一個數字的二進位。長度 32bit
def reverseBits(self, n):
n = "".join(reversed(bin(n)[2:].zfill(32)))
return int(n, 2)同場加映對比。
把 x = 123 轉過來變成 321。策略就是一直取餘數,然後再重組。 很久以前解的,寫的好多喔 XDDD
def reverse(self, x):
"""
:type x: int
:rtype: int
"""
if x == 0:
return 0
isNegative = x < 0
if isNegative:
y = -1
x = abs(x)
else:
y = 1
temp = []
while x != 0:
temp.append(x%10)
x = x//10
ret = ""
for i in temp:
ret += str(i)
if int(ret) > 2147483647:
return 0
ret = int(ret)*y
return ret移動平均概念,注重效能。
def findMaxAverage(self, nums, k):
"""
:type nums: List[int]
:type k: int
:rtype: float
"""
sums = 0
max_avg = -10001
for i in range(len(nums)):
sums += nums[i]
if i >= k:
sums -= nums[i - k]
if i >= k - 1:
max_avg = max(max_avg, float(sums) / k)
return max_avg挺有趣的一個實用題。到底可以把一個句子切出幾個合理的字串。
通常以程式的觀點會想到,用 " " 空白分割?但接踵而來的問題會是,像 piapple apple oriange 這樣不盡然是以一個空白為切割的句子出現錯誤。
例如測試範例就用了 s = ", , , , a, eaefa"
我的想法是既然不知道空白,那我就都以一個空白來切割出新的串列。接著找出串列內不是空白的字串。
def countSegments(self, s):
"""
:type s: str
:rtype: int
"""
s = s.strip()
if s == "":
return 0
s = s.split(" ")
seg = []
for i in s:
if i != "":
seg.append(i)
return len(seg)但後來看了別人的做法發現,啊 其實只要用內建的切割, Python 自動幫你切出字串
def countSegments(self, s):
"""
:type s: str
:rtype: int
"""
return len(s.split())在一個串列內找出最多的元素,有些假設:假設一定有,且這元素大於全部 1/2。各位 stack 是你的好幫手。 反正就是一直和最後一個比,一樣放進去,不一樣取出一個。
def majorityElement(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
stack = []
for idx, value in enumerate(nums):
if not stack:
stack.append(value)
elif value != stack[-1]:
stack.pop()
else:
stack.append(value)
return stack[0]這個還有比較節省記憶體作法。可以讓空間維持 O(2), Codility 上有出過。但我比較不喜歡這種做法,Code 很冗長。
def majorityElement(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
candidate = -1
cnt = 0
for n in nums:
if cnt == 0:
candidate = n
cnt = 1
else:
if n == candidate:
cnt += 1
else:
cnt -= 1
return candidate驚人的做法,佩服佩服。感覺像是 TP 會寫的 code。
def majorityElement(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
numset = set(nums)
for _ in numset:
if nums.count(_)>len(nums)/2:
return _漢明重量(Hamming weight), 早已忘卻。就是計算一個二進位中 1 的數量。在高效能計算是很重要議題但我...
比較麻煩就是十進位轉二進位,接著就簡單了。
def hammingWeight(self, n):
"""
:type n: int
:rtype: int
"""
hw = list(bin(n)[2:].zfill(32)).count('1')
return hw如果要用高效計算可以參考下面:
def hammingWeight(self, n):
"""
:type n: int
:rtype: int
"""
res = 0
while n:
res += n & 1
n >>= 1
return res滿足加總為 k 的子序列,範例 [1,2,3] k = 3, 就是 [1,2], [3], 2 種
sol2:
def subarraySum(nums: List[int], k: int) -> int:
n = len(nums)
count = 0
for i in range(n):
_sum = 0
for j in range(i, n):
_sum += nums[j]
if _sum == k:
count += 1
return countsol3:
def subarraySum(nums, k):
d = {0: 1}
prefixsum = 0
count = 0
for n in nums:
prefixsum += n
if d.get(prefixsum - k, 0):
count += d.get(prefixsum-k)
d[prefixsum] = d.get(prefixsum, 0) + 1
return count這題是在 leetcode 很少見到的 Graph 題目,大意就是修習課程有先後順序,例如 C0, C1 兩堂課有限制先修完 C0 才能修 C1。這樣概念上就有了,就是所謂拓樸單向無環圖。雖然是中等,單如果對 Graph 沒有很認真去上課很難用腦空想,所以建議這題拿紙筆來畫。
假設課程有 C0, C1, C2, C3, C4, C5,課程先修關係的圖如下:

首先要在資料結構上建立一個 Graph ,這裡用鄰接表來建立資料結構,以範例課表將上圖轉換成鄰接表
| course | MAP |
|---|---|
| 0 | 4 |
| 1 | 4 \ 3 |
| 2 | 3 |
| 3 | 5 |
| 4 | 5 |
| 5 |
另外用一個限制表 inDegree 來儲存目前課程關聯的數量
| 0 | 0 | 0 | 2 | 2 | 2 |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 |
概念上是這樣,會先去搜尋鄰接表,根據入度不為 0 的課程去找尋入度為 0,只要沒有課程為環狀就代表正確。 可以用 DFS 開始進行搜尋流程
def canFinish2(numCourses: int, prerequisites: List[List[int]]) -> bool:
# BFS O(N), O(N^2) 建立一個 queue
N = numCourses
graph = collections.defaultdict(list) #圖
indegrees = collections.defaultdict(int) #限制 limit
for u, v in prerequisites:
graph[v].append(u)
indegrees[u] += 1
print(f"graph(圖): {graph},\nindegrees(限制): {indegrees}")
for i in range(N):
zeroDegree = False
# 確認是否有入度為 0 節點, 並且給 0 並且將 zerodegrees 設定起來
for j in range(N):
print(indegrees)
if indegrees[j] == 0:
zeroDegree = True
break
# 假如 zerodegree 沒有代表沒有入度為 0 為一個環
if not zeroDegree:
return False
indegrees[j] = -1
for node in graph[j]:
indegrees[node] -= 1
print('--'*3)
return True 這題汗顏,一個月前看了沒解出來,不過今天不知道為什麼腦袋比較靈光就知道怎麼解了 主要就是有一堆房間用串列儲存,索引就是房間號。房間裡面會有鑰匙或是沒有鑰匙,資料結構會類似 [[1],[2],[3],[]],一開始你會有房間 0 的鑰匙,以這個範例你就有房間 1 鑰匙,接著到房間 2 你有會有房間 3 鑰匙,最後你能夠把所有房間都打開,所以回傳 True。這個範例呢 [[1,3],[3,0,1],[2],[0]] 因為沒有辦法取得房間 2 鑰匙,所以回傳 False
解法很單純,要有一個表格紀錄那個房間被打開,另外有個資料結構放著 keys 每一次取出一把去開房間 (´・ω・`) 直到鑰匙都沒了
def canVisitAllRooms(rooms):
"""
:type rooms: List[List[int]]
:rtype: bool
"""
keys = rooms[0]
rooms_status = [True] + [False]*(len(rooms)-1)
if not keys and len(rooms) == 1:
return True
elif not keys and len(rooms) > 1:
return False
while True:
key = keys.pop()
if rooms_status[key] == False:
for k in rooms[key]:
keys.append(k)
rooms_status[key] = True
if len(keys) == 0:
break
return all(rooms_status) 這題給兩字串 S, T 要841. Keys and Rooms 求如果 S & T (交集)要按照 S 順序排(且要計入重複部分),T - S 差集則按照字母順序排。我用了兩個迴圈來處理。很醜
def customSortString(self, S, T):
"""
:type S: str
:type T: str
:rtype: str
"""
s = []
for i in S:
if i in T:
for _ in range(T.count(i)):
s.append(i)
diff = []
for j in T:
if j not in S:
diff.append(j)
diff.sort()
return ''.join(s+diff)另外一個優美作法,先計算每個的總數,然後存起來,剩下就是沒有的,最美的是讀出來就是排序...猛 collections
from collections import Counter
c = Counter(T)
result = ""
for char in S:
count = c[char]
result += char*count
c[char] = 0
for char in c:
count = c[char]
result += char*count
return result中階題目往往不是問題難,而是英文難。初階題目通常是概念很清楚。QQ 這個問題就是英文難,看不懂在講啥,所以去找了中文,才搞清楚天際線(skyline)是假命題 XDD
題目意思是有個二維陣列(list in list),例如 grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]],這代表是建築物高度,天際線呢分成兩個維度:平行與垂直,就是說你的 row 與 colum 不能超越這個平行與垂直天際線。
第一個問題: 平行、垂直的天際線要怎樣找出,其實就是每個 row, colum 的最大值:舉個例 [[1,2], [3,4]] 平行的天際線最大值就是 [3,4] 水平的最大值 [2,4]
grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]]
h = [max(g) for g in list(zip(*grid))]
v = [max(g) for g in grid]第二個問題: 有了水平垂直,要怎麼找出新的建築物最高度,首先比較水平每個值,例如 水平 [3,4], 垂直 [2,4] 比較 [1,2] 就是
| 比較 | 水平(比大 | 垂直(比小 | 結果 |
|---|---|---|---|
| 1 | 3 | 2 | 2 |
| 2 | 4 | 2 | 2 |
| ----- | ----- | ----- | ---- |
| 3 | 2 | 4 | 3 |
| 4 | 4 | 4 | 4 |
h = [max(g) for g in list(zip(*grid))]
v = [max(g) for g in grid]
new_grid = []
for i, g in enumerate(grid):
for j, value in enumerate(g):
hv = max(value, min(h[j], v[i]))
if hv > value:
new_grid.append(hv - value)
else:
pass第三個問題:不是找出新高度,是找出增加多少高度?囧,題目要看清楚,所以在尋找過程就先把值計算放到 list 接著在做加總
h = [max(g) for g in list(zip(*grid))]
v = [max(g) for g in grid]
new_grid = []
for i, g in enumerate(grid):
new_grid.append(sum([max(value, min(h[j], v[i])) - value if max(value, min(h[j], v[i])) > value else 0 for j, value in enumerate(g)]))大概4這樣,看大多數解題都是這樣,所以英文要學好 QQ
四則運算概念,我的想法很簡單用 if else 與 stack 來計算與儲存。總共會有三種規則,四個結果。計算後可以依序存在 stack 中
def complexNumberMultiply(self, a, b):
"""
:type a: str
:type b: str
:rtype: str
"""
stack = []
a, b = a.split('+'), b.split('+')
for i in a:
for j in b:
if 'i' in i and 'i' in j:
i = i.replace('i', '')
j = j.replace('i', '')
data = int(i) * int(j) * -1
stack.append(data)
elif 'i' in i or 'i' in j:
data = int(i.replace('i', '')) * int(j.replace('i', ''))
stack.append(data)
else:
data = int(i) * int(j)
stack.append(data)
f = stack[0] + stack[-1]
l = stack[1] + stack[2]
ret = '{}+{}i'.format(f, l)
return ret長網址轉換成短網址,但沒有限制短網址要是怎樣規格,總之可以轉換。所以就用字典存了。
class Codec:
def __init__(self):
self.map = {}
self.i = 0
def encode(self, longUrl):
"""Encodes a URL to a shortened URL.
:type longUrl: str
:rtype: str
"""
self.i += 1
self.map[self.i] = longUrl
return 'http://tinyurl.com/{}'.format(self.i)
def decode(self, shortUrl):
"""Decodes a shortened URL to its original URL.
:type shortUrl: str
:rtype: str
"""
return self.map[int(shortUrl.split('/')[-1])]計算戰艦問題,有用到 dfs 概念,但本身學藝不精沒想到備註一下
def countBattleships(self, board):
"""
:type board: List[List[str]]
:rtype: int
"""
count = 0
for i in range(0, len(board)):
for j in range(0, len(board[i])):
if j < len(board[i]) - 1:
if board[i][j] == 'X' and board[i][j+1] != 'X':
count += 1
elif board[i][j] == 'X':
count += 1
if i < len(board) - 1:
if board[i][j] == 'X' and board[i+1][j] == 'X':
count -= 1
return countCodility 很類似的題目。就是找重複的值,然後時間複雜度要在 n 內。主要思考方向就是要怎麼註記值。我的習慣做法是先將 list 排序,然後往前比較。
def findDuplicates(nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
nums.sort()
condidation = ''
stack = []
for n in nums:
if n != condidation:
condidation = n
else:
stack.append(n)
return list(set(stack))然後有看到別人做法是正負好標記法。感覺不錯紀錄一下:
遍歷nums,記當前數字為n(取絕對值),將數字n視為下標(因為a [i]∈[1,n]) 當n首次出現時,nums [n - 1]乘以-1 當n再次出現時,則nums [n - 1]一定<0,將n加入答案
def findDuplicates(nums):
"""
:type nums: List[int]
:rtype: List[int]
"""
ans = []
for n in nums:
if nums[abs(n) - 1] < 0:
ans.append(abs(n))
else:
nums[abs(n) - 1] *= -1
return ans這邊特別把 tree 的練習拉出來,因為比較困難,其實 tree 在資料結構尤其是 search 是密不可分的方法
計算 BST 最長路徑,路徑上的結點值都要相同。此題為 543 的加強版
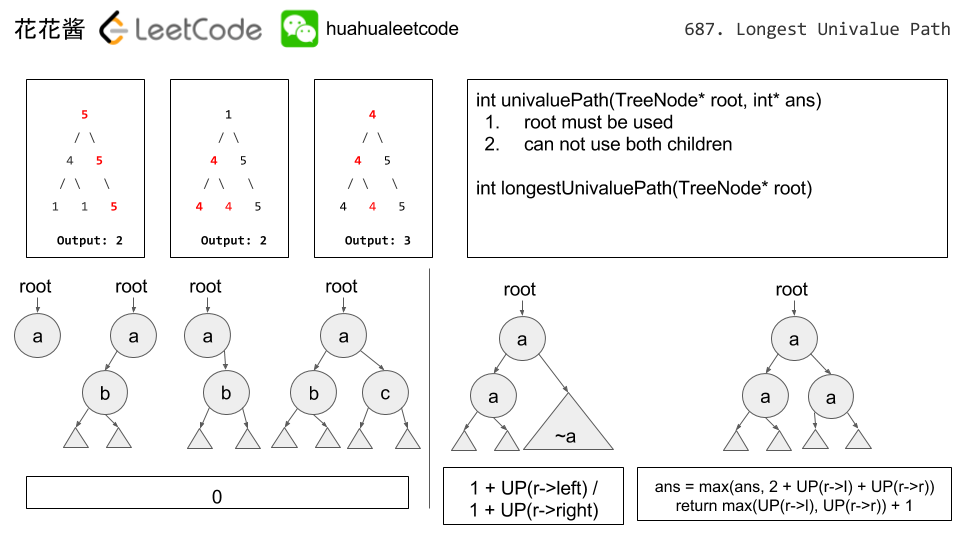
重點是不一定要經過 root,假如有折返點,只能經過一邊(左或是右),因為這是路徑問題假如返回那就變成樹。解題有幾種:
def longestUnivaluePath(self, root: TreeNode) -> int:
self.ans = 0
def arrow_length(node):
if not node:
return 0
left_length = arrow_length(node.left)
right_length = arrow_length(node.right)
left_arrow = right_arrow = 0
if node.left and node.left.val == node.val:
left_arrow = left_length + 1
if node.right and node.right.val == node.val:
right_arrow = right_length + 1
self.ans = max(self.ans, left_arrow + right_arrow)
return max(left_arrow, right_arrow)
arrow_length(root)
return self.ans計算 BST 的最大長度(題目定義是邊的數量 The length of path between two nodes is represented by the number of edges between them.),和 687 有點像。
解題想法是可以想像兩個箭頭從結點各自出發往 L, R 結點,然後回傳各自最長(相當於不斷遞迴在每個轉折點找),假如回傳值 L, R 有大於前一個則更新,最後的最長路徑就是 L + R + 1。
def diameterOfBinaryTree(self, root: TreeNode) -> int:
self.ans = 1
def depth(node):
if not node:
return 0
L = depth(node.left)
R = depth(node.right)
self.ans = max(self.ans, L+R+1)
return max(L, R) + 1
depth(root)
return self.ans - 1反轉二元樹,大家都知道 osx 套件管理工具作者 google 面試無法在白板上反轉的樹 QQ 其實很簡單就每一層的樹左右兩邊對調,但其實我也不知道白板要怎麼寫啦 XDDDDD
def invertTree(self, root: TreeNode) -> TreeNode:
if not root:
return None
root.left, root.right = root.right, root.left
self.invertTree(root.left)
self.invertTree(root.right)
return root本題給定一個 Binary tree 要求給 preorder 排列,其實這題可以變化成四題,分別是 Preorder, Inorder, Postorder, Level-order 所以可以變化出四種類型,題目分別為 144, 94, 145, (102, 103)。
Postorder Traversal 後序遍歷,理論上的遍歷順序是:左子樹、右子樹、根。根排在後面。
即是採用 Depth-first Search,只不過更動了節點的輸出順序,和其它三個 order 比較差異不過就是何時 output。
def postorderTraversal(self, root: TreeNode) -> List[int]:
res = []
if not root:
return res
if root.left:
res.extend(self.postorderTraversal(root.left))
if root.right:
res.extend(self.postorderTraversal(root.right))
res.append(root.val)
return res本題給定一個 Binary tree 要求給 preorder 排列,其實這題可以變化成四題,分別是 Preorder, Inorder, Postorder, Level-order 所以可以變化出四種類型,題目分別為 144, 94, 145, (102, 103)。
Preorder Traversal 前序遍歷,理論上的遍歷順序是:根、左子樹、右子樹。根排在前面。
即是 Depth-first Search,只不過更動了節點的輸出順序,這是關鍵,和其它三個 order 比較差異不過就是何時 output。
recursion:
def preorderTraversal(self, root: TreeNode) -> List[int]:
ans = []
def preorder(root):
if root == None:
return None
ans.append(root.val)
if root.left != None:
preorder(root.left)
if root.right != None:
preorder(root.right)
preorder(root)
return ans迭代寫起來比較困難,理解起來就是用一個 stack 去存 tree,接著只要 stack 有值就將值取出(FIFO)
Iteration:
def preorderTraversal(self, root: TreeNode) -> List[int]:
if not root:
return []
stack = []
ans = []
stack.append(root)
while stack:
node = stack.pop()
if not node:
continue
ans.append(node.val)
stack.append(node.right)
stack.append(node.left)
return ans本題給定一個 Binary tree 要求給 inorder 排列,其實這題可以變化成四題,分別是 Preorder, Inorder, Postorder, Level-order 所以可以變化出四種類型,題目分別為 144, 94, 145, (102, 103)。
Inorder Traversal 就是中序遍歷,理論上的遍歷順序是:左子樹、根、右子樹。根排在中間。 實際上是採用 Depth-first Search,只不過更動了節點的輸出順序,這是關鍵,和其它三個 order 比較差異不過就是何時 output。 題目可以有兩種解法: 遞迴(recursion) 或是迭代(Iteration)
recursion:
def inorderTraversal(self, root: TreeNode) -> List[int]:
ans = []
def inorder(root):
if root == None:
return None
if root.left != None:
inorder(root.left)
ans.append(root.val)
if root.right != None:
inorder(root.right)
inorder(root)
return ans
# Time complexity : O(n)
# Space complexity : The worst case space required is O(n), and in the average case it's O(logn) where nn is number of nodes.Iteration:
def inorderTraversal(self, root: TreeNode) -> List[int]:
stack = []
ans = []
while True:
while root:
stack.append(root)
root = root.left
if not stack:
return ans
root = stack.pop()
ans.append(root.val)
root = root.right
# Time complexity : O(n).
# Space complexity : O(n).這個題目挺酷的,一個 tree 的結構,你要找出中間的 node 之後得值,概念上來說就是一層層拆解 原本我的解法是把 head 放到一個串列,接著去取出串列然後判斷 .next 是否為 None,如果不是就放入串列
tree = [head]
res = []
while True:
node = tree.pop()
if node.next is None:
res.append(node.val)
start = len(res) // 2
return res[start:]
res.append(node.val)
tree.append(node.next)但看到一個更好的解法,是使用最後一個 .next 作為判斷條件,最後串列本身就是所有的 list 再回傳就好了,這個做法還不錯
current = [head]
while current[-1].next:
current.append(current[-1].next)
return current[len(current)/2]這題是給一個圖 Imgur 然後問如果給兩棵樹,能不能判斷他們的葉子是否相同。其實這個用 level-order 最快 不管從左邊或是右邊做廣度優先。
這樣做的:
def leafSimilar(self, root1, root2):
"""
:type root1: TreeNode
:type root2: TreeNode
:rtype: bool
"""
res1, res2 = [], []
search1, search2 = [root1], [root2]
while search1:
node = search1.pop()
res = True
for branch in (node.left, node.right):
if node.left is None and node.right is None and res:
res1.append(node.val)
res = False
elif branch is not None:
search1.append(branch)
while search2:
node = search2.pop()
res = True
for branch in (node.left, node.right):
if node.left is None and node.right is None and res:
res2.append(node.val)
res = False
elif branch is not None:
search2.append(branch)
return True if res1 == res2 else False不過根據 700 Search in a Binary Search Tree 的到靈感,可以改寫成 callback 方法
def leafSimilar(self, root1, root2):
"""
:type root1: TreeNode
:type root2: TreeNode
:rtype: bool
"""
leaf1 = []
leaf2 = []
self.traverse(root1, leaf1)
self.traverse(root2, leaf2)
return leaf1== leaf2
def traverse(self, root, res):
if not root:
return
if not (root.left or root.right):
res.append(root.val)
return
self.traverse(root.left, res)
self.traverse(root.right, res)這幾天在開發 Django 的網站和在看林老師的 ML 就沒有積極寫。今天動筆了一下 咪秋~
覺得撰寫順序改一下,應該新的在上才對。
因為開始寫一些 SQL 所以開始會寫一些簡單的 SQL 測驗,SQL 好難
最近都在看 DL 概念,都沒在寫。覺得自己好廢廢
很長一段時間又再看機器學習、學 Python 非同步、搞網頁、搞硬體該好好再繼續開始惹
又開始刷題,看看腦袋有沒有變好
想不到刷一刷一年也過惹,太慢囉!
分成中階和初階。中階的真的要想比較久
最近狀況不太好,寫題目不知道為什麼都會頓頓的
和 Adrian 陸續解了不少中等難度,過程就沒紀錄T_T。稍微討論絕的解題過程更應該注重互動以及如何陳述想法
很多題目做過,但再看忘記了,大概是不常用與當時沒有真正理解,所以就把他獨立出來解題了

{kind=link}
Easy 的題目做到現在除了 tree 的問題因為還沒複習沒寫不知道內容,其他都是考資料結構和演算法概念。