网站,提供文字,图片,视频供人访问获取信息。 有部分人需要完成任务,就是从网上获取信息,加工之后,再将加工后的信息传播到网上。 而爬虫主要完成的就是这个任务流程。
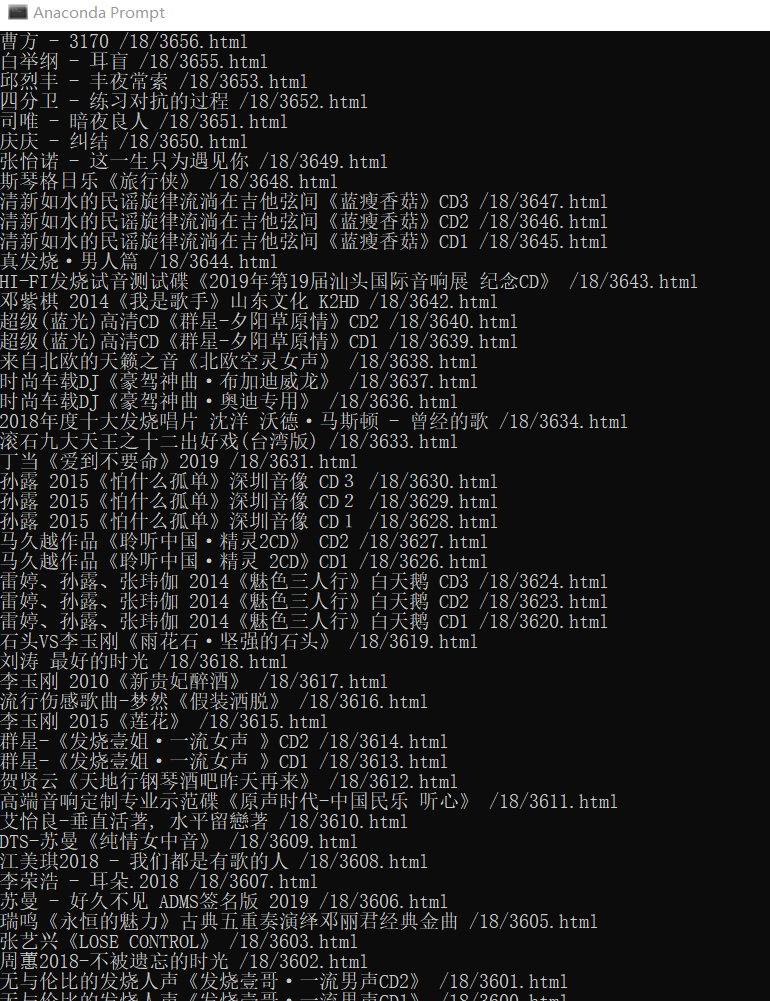
目标:了解requests的基础用法
效果:
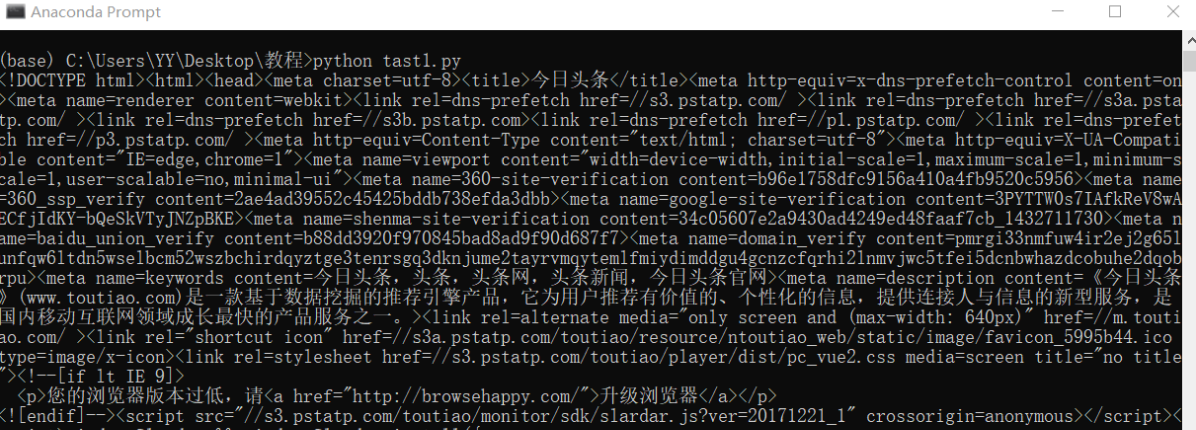
目标:了解字符串截取操作。
效果:

帮助: 这里有个写好的函数提取两个字符串中间的内容。
def find_between( s, first, last ):
try:
start = s.index( first ) + len( first )
end = s.index( last, start )
return s[start:end]
except ValueError:
return ""
网址:http://p3.pstatp.com/large/pgc-image/5a6168582c8f4a8ca4187fc6e7cf4648
目标:掌握文件操作
效果:

目标:掌握文件操作,字符串截取操作 , 多行字符串的定义
帮助:
1用requests访问网址,获得其源码。
2从源码中截取出下载链接,就用之前任务中的截取函数
3.用requests访问下载链接,得到文件内容
4.保存到文件中
效果:

网址:https://www.jianshu.com/p/f23ccd6821f6
目标:掌握requests设置头部
帮助:
- jianshu.com设置了访问限制。
- 用requests直接get,会提示403错误,禁止访问。
- 通过设置头部的user-agent,就能通过允许。
问题效果:
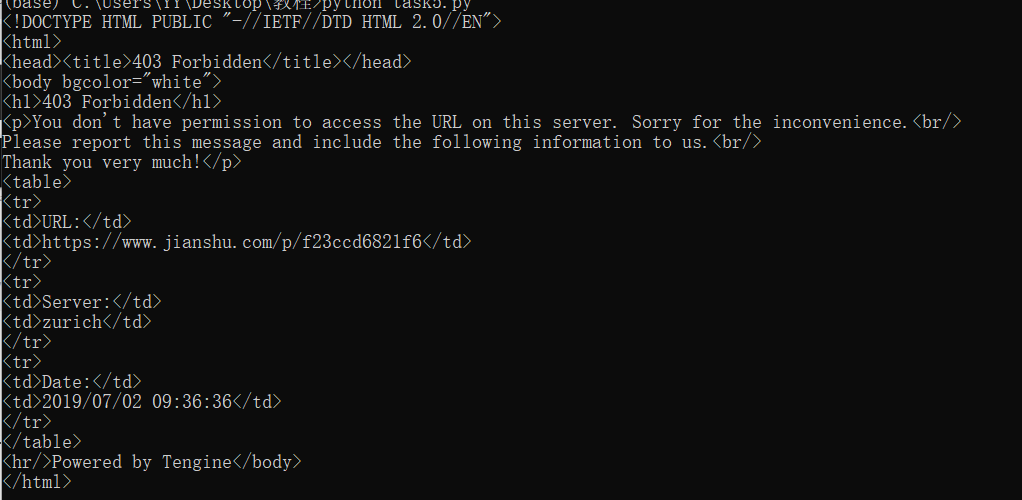
网址:https://www.jianshu.com/p/f23ccd6821f6
目标:掌握pyquery的用法
帮助:
- 安装:pip install pyquery
- 使用:
from pyquery import PyQuery as pq
url = "https://www.jianshu.com/p/f23ccd6821f6"
res=requests.get(url)
dom = pq(res.text)
pubtime = dom(".publish-time")
效果:

目标:掌握pyquery提取列表的方法
效果:
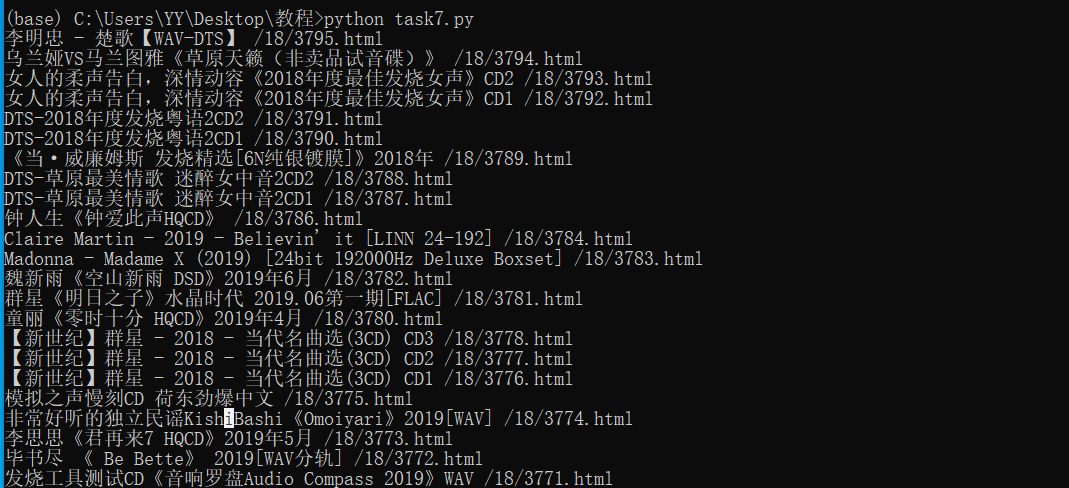
目标:掌握pyquery提取列表的方法,和简易翻页
帮助: https://tzg.ylzmjd.com/cd/?pn=2 pn=后面的数字是几,就是第几页。通过改变这个数字实现翻页。
效果: