MariaDB에서 HDFS로 로드하는 플로우를 살펴보겠습니다. ★by SDI
구성된 Flow의 모습입니다. 데이터베이스에서 데이터를 받아 CSV로 파일을 생성하여 HDFS로 로드하는 과정을 나타냅니다. 각 프로세서의 작업이 성공적으로 수행 할 경우는 success 커넥션으로 Flowfile이 전달되게 되며 HDFS로 결과가 로드되게 되며 실패했을 경우에는 failure 커넥션으로 Flowfile이 전달되어 로그를 남기는 구성입니다.

-
QueryDatabaseTable 제공된 명령문을 사용하여 SQL문을 생성하여 해당하는 row들을 가져옵니다. row들을 Avro 형태로 생성됩니다.
-
ConvertRecord Record의 포맷을 변경합니다. CSV, JSON, Avro, XML 포맷들 간의 변환이 가능합니다.
-
Gen_filename 생성할 파일의 이름을 지정하는 역할을 합니다.
-
PutHDFS Flowfile안의 Contents를 파일형태로 HDFS로 put 하는 역할을 합니다. NiFi가 설치된 디렉토리 내의 로그파일에 로그를 남기는 역할을 합니다. 주로 작업이 실패했을 경우에 로그를 남길 때 사용합니다.
-
LogAttribute NiFi가 설치된 디렉토리 내의 로그파일에 로그를 남기는 역할을 합니다. 주로 작업이 실패했을 경우에 로그를 남길 때 사용합니다.
Processor 단위로 Flow를 설명합니다. 가장 처음의 QueryDatabaseTable 프로세서에서는 모든 설정을 설명하며 다음 프로세서는 공통된 설정은 생략한채 Properties탭의 프로퍼티 정보들만 설명하도록 합니다.
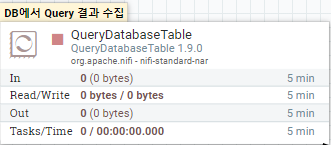 DB에서 Query 결과를 수집하여 Avro 형태의 Contents를 만드는 프로세스 입니다.
프로세스를 더블클릭하시거나 오른쪽 마우스를 클릭하여 팝업메뉴를 띄운후 Configure를 클릭하면 다음과 같은 Configure Processor를 보실 수 있습니다.
Configure Processor 에서는 프로세서의 동작 설정을 할 수 가 있습니다.
DB에서 Query 결과를 수집하여 Avro 형태의 Contents를 만드는 프로세스 입니다.
프로세스를 더블클릭하시거나 오른쪽 마우스를 클릭하여 팝업메뉴를 띄운후 Configure를 클릭하면 다음과 같은 Configure Processor를 보실 수 있습니다.
Configure Processor 에서는 프로세서의 동작 설정을 할 수 가 있습니다.
 SETTING 탭의 설정입니다.
SETTING 탭의 설정입니다.
-
Name 프로세서의 이름을 설정 할 수 있습니다.
-
Id 프로세서의 Id 입니다. 프로세서나 프로세서 그룹의 Id는 유니크 하므로 Id로 인해 구별 될 수 있습니다.
-
Type 프로세서의 주 기능을 나타내는 Type을 나타냅니다.
-
Bundle 프로세서들은 nar 확장자들로 되어 배포되어있는데 이들의 Bundle 정보를 나타냅니다.
-
Penalty Duration 데이터 조각 (FlowFile)을 처리하는 정상적인 과정에서 데이터는 현재 처리 할 수 없지만 나중에 데이터를 처리 할 수 있음을 나타내는 이벤트가 발생할 수 있습니다. 이 경우 프로세서는 FlowFile에 패널티를 주도록 선택할 수 있습니다. 이렇게하면 일정 시간 동안 FlowFile이 처리되지 않습니다. 예를 들어, 프로세서가 데이터를 원격 서비스로 푸시하지만 원격 서비스에 프로세서가 지정한 파일 이름과 같은 이름의 파일이 이미 존재하는 경우 프로세서는 FlowFile에 패널티를 줄 수 있습니다. Penalty Duration을 통해 DFM(Data Flow Manager)은 FlowFile의 패널티 처리 기간을 지정할 수 있습니다. 기본값은 30 초입니다.
-
Yield Duration 프로세서는 처리중인 데이터에 관계없이 프로세서가 더 이상 진행할 수 없는 상황이 존재한다고 판단 할 수 있습니다. 예를 들어, 프로세서가 데이터를 원격 서비스에 푸시하고 해당 서비스가 응답하지 않으면 프로세서가 아무런 진전을 이루지 못합니다. 결과적으로 프로세서는 Yield되어야하며, 일정 기간 동안 프로세서가 실행되도록 예약되지 않습니다. 해당 기간은 Yield Duration을 설정하여 지정합니다. 기본값은 1 초입니다.
-
Bulletin Level 프로세서가 로그에 기록 할 때마다 프로세서는 Bulletin도 생성합니다. 이 설정은 사용자 인터페이스에 표시되어야 하는 Bulletin의 가장 낮은 수준을 나타냅니다. 기본적으로 Bulletin Level은 WARN으로 설정되어 모든 경고 및 오류 수준의 Bulletin을 표시합니다.
-
Automatically Terminate Relationships 프로세서에 의해 정의 된 각 관계는 설명과 함께 여기에 나열됩니다. 프로세서가 유효하고 실행 가능한 것으로 간주 되려면 프로세서가 정의한 각 관계가 다운 스트림 구성 요소에 연결되거나 자동 종료되어야 합니다. 관계가 자동 종료되면 해당 관계로 라우트 된 모든 FlowFile이 플로우에서 제거되고 처리가 완료된 것으로 간주됩니다. 이미 다운 스트림 구성 요소에 연결된 모든 관계는 자동 종료 할 수 없습니다. 관계를 사용하는 Connection에서 관계를 먼저 제거해야합니다. 또한 자동 종료되도록 선택된 관계의 경우 관계가 연결에 추가되면 자동 종료 상태가 지워집니다 (해제 됨).
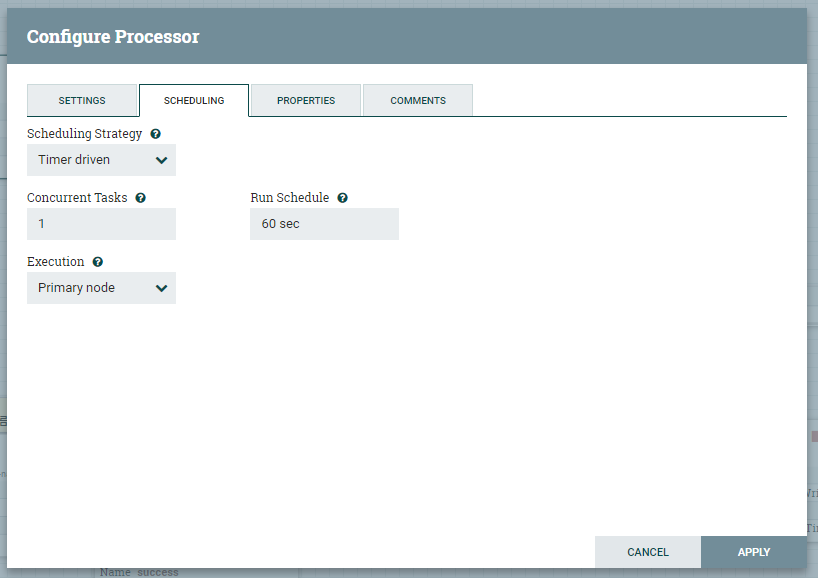 SCHEDULING 탭의 설정입니다.
SCHEDULING 탭의 설정입니다.
-
Scheduing Strategy 스케쥴링 전략을 선택 할 수 있습니다. 나이파이에서는 기본적으로 Timer driven 과 Cron driven 두가지의 방법이 지원됩니다. Event driven 방식은 현재 지원되지 않으며 추후 NiFi에서 제공하도록 개발중인 현황으로 보입니다.
-
Concurrent Tasks 해당 프로세서가 동작할 쓰레드의 갯수를 정해줄 수가 있습니다. 이 값을 늘리면 일반적으로 프로세서가 동일한 시간 내에 더 많은 데이터를 처리 할 수 있습니다. 이 옵션은 얼마나 많은 FlowFiles가이 프로세서에 의해 동시에 처리되어야 하는지를 제어합니다. 본질적으로 프로세서의 상대적 가중치를 제공합니다. 다른 프로세서 대신이 프로세서에 할당 할 시스템 리소스의 양을 제어합니다. 하지만 몇 가지 유형의 프로세서들은 한개의 쓰레드밖에 제공되지가 않습니다.
-
Run Schedule 해당 프로세서가 몇 초마다 동작하여 FlowFile을 Stream으로 전송할지를 결정합니다. 이 옵션은 Scheduling Strategy를 의존하여 결정됩니다.
-
Execution 프로세서가 실행되도록 예약 된 노드를 결정하는 데 사용됩니다. 'All nodes' 를 선택하면 이 프로세서가 클러스터의 모든 노드에서 예약됩니다. 'Primary node'를 선택하면 Primary node에서만 스케줄됩니다.
 PROPERTIES 탭의 설정입니다.
PROPERTIES 탭의 설정입니다.
프로세서를 동작하는데 필요한 프로퍼티들을 설정합니다. 모든 프로퍼티들이 설정될 필요는 없으므로 이 문서에서는 필수적이거나 해당 플로우에서 불가피하게 사용될 수 밖에 없는 프로퍼티들을 위주로 설명합니다.
-
Database Connection Polling Service Polling할 DB 커넥션풀을 설정합니다. DB커넥션풀 객체는 Controller Service 에서 DB에 대한 접속정보를 입력하여 만들수가 있습니다. 해당 옵션에서는 만들어진 DB커넥션풀을 지정하도록 합니다. Controller Service에 대한 설명은 다음으로 미루겠습니다.
-
Database Type Polling 할 DB 커넥션풀의 DB 타입을 지정합니다. 해당 플로우는 MySQL을 사용하므로 MySQL을 지정해주도록 합시다.
-
Table Name 정보를 가져올 DB의 테이블 이름을 입력합니다.
-
Columns to Return 정보를 가져올 컬럼명들을 콤마(,)로 구분하여 입력합니다.
-
Additional WHERE clause Query문의 WHERE 문에 해당하는 조건들을 입력합니다. 해당 옵션에 컬럼명과 논리,비교 연산자를 조합하여 가져올 레코드들에 조건을 줄 수 있습니다.
-
Custom Query Query문을 직접 입력하여 데이터를 가져올 수도 있습니다. 위에 있는 Columns to Return 옵션과 이 옵션중에 양자택일 하여 선택하여 작업을 수행합니다.
-
Maximum-value Columns 테이블에 값이 계속하여 증가하는 Sequence의 역할을 하는 컬럼을 지정하여 데이터를 폴링할때마다 그 컬럼의 최대값을 가져옵니다. 다음 폴링시에 폴링된 데이터의 지정된 컬럼과 바로 전의 값의 크기를 비교하여 해당 크기보다 큰 레코드들만 폴링 할 수 있습니다. 결과적으로 Polling된 레코드들 중 기존에 Polling하지 않은 새로 갱신된 레코드들만을 가져오기 위함입니다.
 COMMENTS 탭입니다.
다른 NiFi유저들에게 정보를 주기 위한 목적으로 프로세서를 설명하기 위해 문구를 넣을 수가 있습니다.
COMMENTS 탭입니다.
다른 NiFi유저들에게 정보를 주기 위한 목적으로 프로세서를 설명하기 위해 문구를 넣을 수가 있습니다.
 구성된 RecordReader 및 RecordWriter Controller Service를 사용하여 하나의 데이터 형식에서 다른 데이터 형식으로 레코드를 변환합니다. 이 플로우에서는 QueryDatabaseTable 프로세서에서 나온 Avro 형식의 레코드들을 CSV로 변환하기 위해 사용됩니다.
구성된 RecordReader 및 RecordWriter Controller Service를 사용하여 하나의 데이터 형식에서 다른 데이터 형식으로 레코드를 변환합니다. 이 플로우에서는 QueryDatabaseTable 프로세서에서 나온 Avro 형식의 레코드들을 CSV로 변환하기 위해 사용됩니다.
 PROPERTIES 탭의 설정입니다.
PROPERTIES 탭의 설정입니다.
-
Record Reader 변환 대상의 기존 레코드 타입을 읽을 Controller Service를 등록합니다.
-
Record Writer 변환 대상의 목표 변환 타입을 쓸 Controller Service 를 등록합니다.
 원래 Processor Type은 UpdateAttribute입니다. 하나의 프로세서에서 다른 프로세서에 전달되는 Flowfile은 Contents와 Attribute로 구성되어 있습니다. Contents 는 데이터 자체이고 Attribute는 데이터의 속성이나 메타데이터를 나타내며 다음 프로세서로 전달되어 가공하는데 정보를 제공 할 수 있습니다. UpdateAttribute는 Flowfile 안에 있는 Attribute를 추가 및 수정 하기 위해 사용됩니다. 해당 플로우에서는 Flowfile마다 파일이름을 지정하여 최종 endpoint에 저장될 파일이름을 제공하기 위해 사용되었습니다.
원래 Processor Type은 UpdateAttribute입니다. 하나의 프로세서에서 다른 프로세서에 전달되는 Flowfile은 Contents와 Attribute로 구성되어 있습니다. Contents 는 데이터 자체이고 Attribute는 데이터의 속성이나 메타데이터를 나타내며 다음 프로세서로 전달되어 가공하는데 정보를 제공 할 수 있습니다. UpdateAttribute는 Flowfile 안에 있는 Attribute를 추가 및 수정 하기 위해 사용됩니다. 해당 플로우에서는 Flowfile마다 파일이름을 지정하여 최종 endpoint에 저장될 파일이름을 제공하기 위해 사용되었습니다.
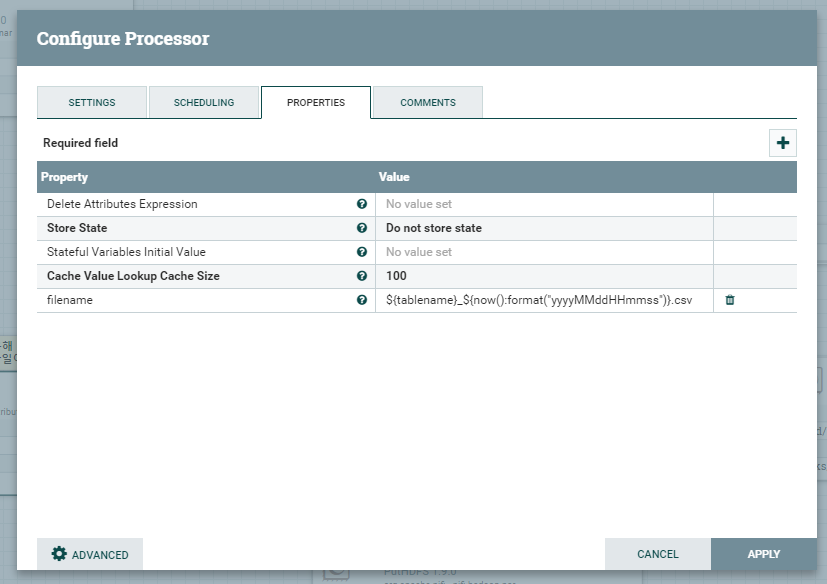 PROPERTIES 탭의 설정입니다.
PROPERTIES 탭의 설정입니다.
- filename filename 은 모든 Flowfile의 공통 Attributes중 하나입니다. 해당 Attributes(filename)은 따로 값을 주지 않을시에 유니크한 임의 숫자로 된 값이 할당됩니다. 해당 플로우에서는 NiFi Expression Language 를 사용하여 테이블이름과 현재 시간을 조합하여 파일이름을 결정하도록 설정하였습니다. NiFi Expression Language는 Flowfile의 Attribute들을 사용하여 원하는 값을 구하도록 도와주는 NiFi 내장 언어입니다. 자세한 문법의 내용은 방대하므로 공식 문서 https://nifi.apache.org/docs/nifi-docs/html/expression-language-guide.html 를 참조하십시오.
 최종적인 Endpoint인 HDFS에 데이터를 푸시하는 프로세서입니다.
최종적인 Endpoint인 HDFS에 데이터를 푸시하는 프로세서입니다.
 PROPERTIES 탭의 설정입니다.
PROPERTIES 탭의 설정입니다.
-
Hadoop Configuration Resources 하둡이 설치되지 않은 서버에서 원격지에 있는 하둡에 접속하기 위해서는 두 가지의 XML 설정파일이 필요합니다. 두 가지의 XML 설정 파일은 core-site.xml, hdfs-site.xml 이며 이 파일들은 하둡이 설치되어 있는 서버의 하둡 디렉토리의 설정 디렉토리에서 구할 수 있습니다. 하둡이 설치되어있는 서버에서 NiFi가 설치된 서버로 가져온 core-site.xml, hdfs-site.xml 파일들의 절대경로들을 콤마로 구분하여 입력하여 줍니다.
-
Directory 생성된 파일들을 푸시할 HDFS 내의 경로를 입력하여 줍시다.
-
Conflict Resolution Strategy 경로내에 푸시할 파일의 이름과 같은 파일이 이미 존재할 시에 어떤 대처를 할지 정책을 결정합니다. replace, ignore, append, fail 네 가지의 정책을 제공해줍니다.

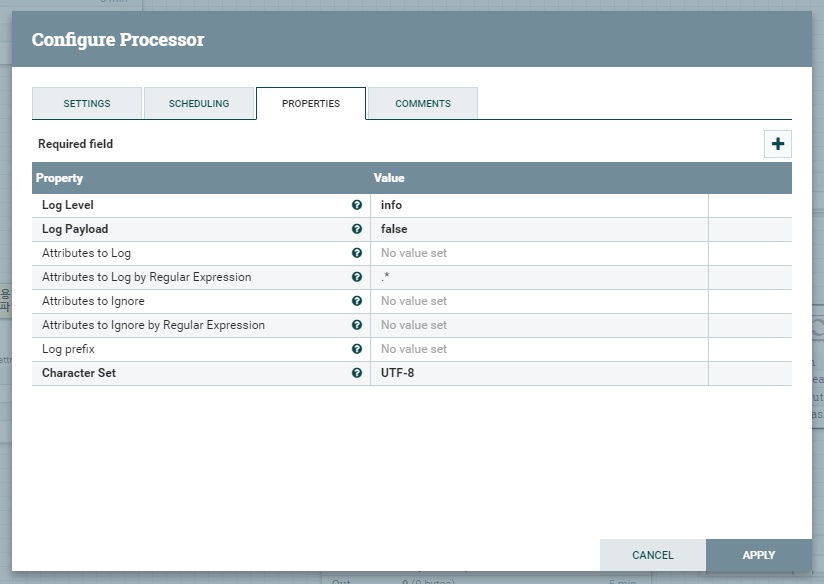
프로세서에서 작업한 로그들을 남기기 위해 사용되는 프로세서입니다. 프로세서에서 지정된 작업이 실패하였을 경우(Connection이 FAIL 인 곳으로 분기 될 경우를 의미합니다)에 주로 사용하게 됩니다. 이 프로세서를 사용하여 실패한 파일에 대한 로그를 확인하고 재처리를 고려할 수 있습니다.
-
Log Level 로그 레벨을 결정합니다. 설정된 로그레벨 이상의 레벨의 로그만 출력하도록 할 수 있습니다.
-
Attributes to Log 현재 프로세서가 작업하고 있는 Flowfile의 Attribute들의 값을 Log로 선택적으로 남길 수 있습니다.
-
Character Set 인코딩값을 지정할 때 사용하게 됩니다.