본 내용의 서론부분은 공식문서를 번역하여 제공하는 글임 https://nifi.apache.org/docs.html
★by SDI
나이파이는 Zero-Master 클러스터링 패러다임을 채용합니다. 클러스터의 각 노드는 데이터에서 동일한 작업을 수행하지만 각각 다른 데이터 집합에서 작동합니다. 노드들 중 하나는 Zookeeper에 의해 Cluster Coordinator로 자동으로 선출됩니다. 클러스터안에 있는 모든 노드들은 이 코디네이터 노드로 heartbeat/status 정보를 보내게 될 것입니다. 그리고 이 코디네이터 노드는 heartbeat/status 정보가 일정시간을 초과하여 넘어오지 않는 노드들의 연결을 해지할 책임을 가지게 됩니다. 추가적으로 새로운 노드가 클러스터에 합류하게 될 때, 새로운 노드는 가장 최근에 업데이트된 플로우를 얻기 위하여 우선 최근에 선출된 코디네이터 노드를 찾아 연결해야만 합니다. 코디네이터 노드가 노드가 합류하도록 결정을 내린다면 최근의 플로우가 그 노드로 보내지게 되며 그 노드는 클러스터에 합류할 수 있게 됩니다.
- 한개의 서버로는 많은 양의 데이터 감당 불가
- 데이터 흐름을 변경하고 데이터 흐름을 모니터링하는 단일 인터페이스와 함께 처리 능력을 향상시키기 위해
- NiFi Cluster Coordinator
- 새로이 합류하는 노드들에게 가장 최근의 플로우를 제공
- 클러스터에서 허용되는 노드를 관리
- 변경 사항은 클러스터의 모든 노드에 복제됨
- Nodes
- 실제로 데이터를 프로세싱하는 노드
- Primary Node
- 모든 클러스터는 하나의 Primary Node를 가짐
- 고립된 프로세서(Isolated Processor)를 실행시키는게 가능
- 주키퍼는 자동으로 Primary Node를 선출
- Primary Node가 죽으면 다른 노드가 새로이 Primary Node로 선출
- Isolated Processors
- 동일한 데이터플로우는 모든 노드들에서 실행됨
- 결과적으로 플로우상의 모든 컴포넌트들은 모든 노드들에서 동작하게 됨
- 하지만 그런 경우를 원치 않는 케이스가 있을 수 있음(확장성이 좋지 않은 프로토콜을 사용하는 외부 서비스와 통신할 경우)
- 원격 디렉토리에서 데이터를 땡겨오는 GetSFTP 프로세서를 예로 들 수 있음
- GetSFTP 프로세서를 클러스터의 모든 노드에서 동작시키고 같은 원격 디렉토리에서 동시에 데이터를 땡겨올때 경쟁상태(Race condition)가 발생할 수 있음.
- 결과적으로 DFM은 GetSFTP를 Primary Node에만 고립시켜 돌도록 설정 해줘야 함.
- 적절한 데이터 흐름 구성을 사용하면 데이터를 가져 와서 클러스터의 나머지 노드에서로드 균형을 조정할 수 있음
- 암튼 이러한 특성 때문에 Primary Node에서 데이터 땡겨온 후 각 클러스터에 데이터를 공급해 주는것이 아주 일반적
- 가용자원과 클러스터 구성을 고려하여 조정하도록 해야함
- 클러스터안의 노드들은 heartbeat를 통해 서로 통신함
- Cluster Coordinator가 선출되면 노드들이 어디로 heartbeat르 보내야 할지 알려주기위해 Zookeeper의 ZNode를 업데이트함
- 노드들중 하나의 전원이 내려가면 클러스터의 다른 노드들은 자동으로 전원이 내려간 노드의 로드를 가져오지 않음
- DFM이 우발상황에 대한 failover 데이터 흐름을 구성해야함
- 첨에 클러스터 설정할 때, 어떤 노드들이 올바른 플로우 버전을 가지고 있는지를 결정해야함.
- 이는 각 노드에있는 플로우에 대해 투표함으로써 수행됨.
- 한 노드가 클러스터에 연결할 때 Cluster Coordinator한테 로컬 플로우의 카피본을 전달함.
- 아직 어떤 플로우도 "올바른"플로우로 선택되지 않은 경우, 노드의 플로우는 다른 노드의 플로우 각각과 비교됨.
- 다른 노드의 플로우가 이 플로우와 일치하면 이 플로우에 대한 투표가 수행됨.
- 다른 노드들이 아직 동일한 플로우를 보고하지 않으면,이 플로우는 하나의 투표로 선택 될 수있는 플로우의 풀에 추가됨.
nifi.cluster.flow.election.max.wait.time에서 설정한 만큼의 시간이 경과하면nifi.cluster.flow.election.max.candidates에서 설정한 만큼의 수의 노드들이 후보들로 선정되고 하나의 노드만이 올바른 플로우로 선출됨.- 호환되지 않는 플로우가 있는 모든 노드는 클러스터에서 연결이 끊어지며 호환 가능한 플로우가있는 노드는 클러스터의 플로우를 상속
- 투표로 선정된 가장 인기있는 플로우는 모든 플로우가 비어잇지 않는 한 절대 빈 플로우가 될 수가 없음
- DFM은 임의로 클러스터에서 노드를 Disconnect 할 수 있음
- Disconnect의 이유는 다른 이유들이 있을수도 있음
- DFM 또는 관리자는 데이터 흐름을 새로 변경하기 전에 노드 문제를 해결하고 문제를 해결해야함
- Disconnect가 동작하지 않는다는 의미와 동치는 아님 (동작은 하는 중인데 그냥 Heartbeat가 안가서 그럴수도 있다는 말인듯)
- 임의로 Disconnect하려면 Discconnect 아이콘 누르면 됨
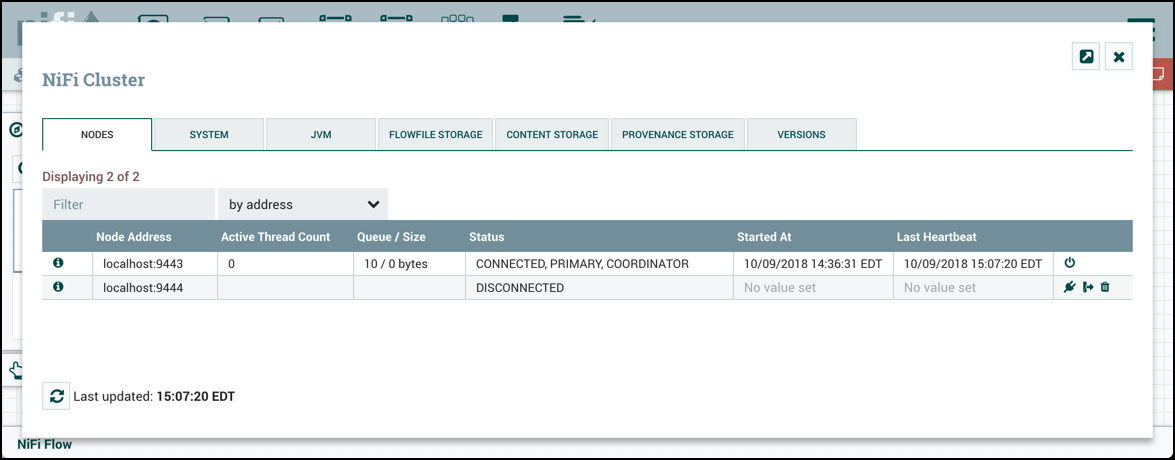
- Disconnected 노드의 플로우 파일을 Offload를 통해 다른 활성화노드로 재조정 시킬 수 있음
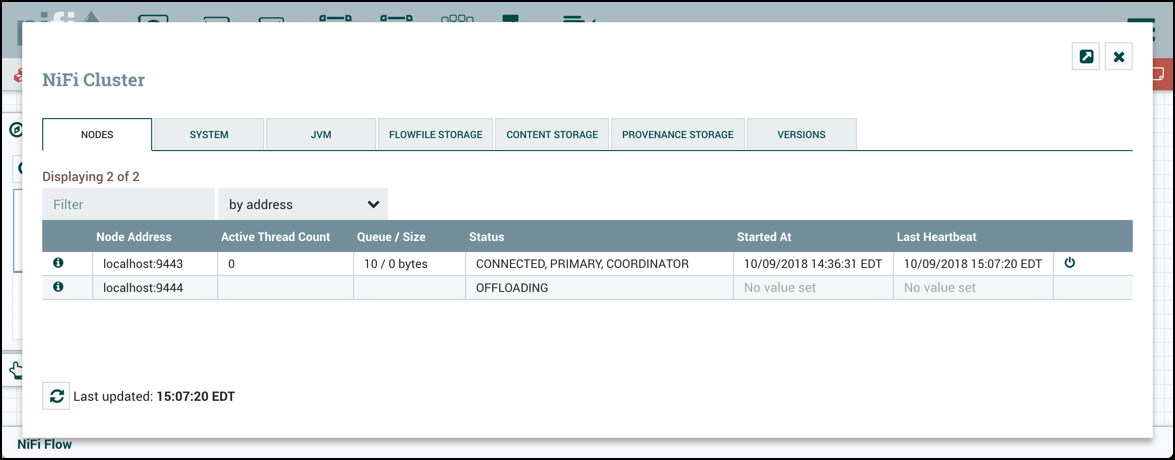
- 다음의 UI에서 Offload 아이콘을 클릭하여 Disconnect를 Offload로 바꿀 수 있음
- Offload는 모든 프로세스를 중단하고 종료함. 그리고 모든 Remote Process Group으로의 전송도 취소하고 클러스터에 연결된 다른 클러스터들로 플로우파일들을 재조정함
- 노드에서 NiFi를 재시작하면 Offload에서 Connected 상태로 변경 가능
- UI상에서 재시작하거나 서버에서
nifi.sh start로 재시작 하거나 뭘로든 Reconnect 될 수 있음 - 제거하는것도 물론 가능
- 노드가 클러스터에 연결되어 있지 않아도 DFM이 플로우를 계속 변경하고자하는 경우가 있음.
- Delete 아이콘을 클릭하여 Disconnected거나 Offloaded 된 노드를 제거 가능
- 한번 삭제되면 재시작 되기전까지 클러스터에 재합류가 불가능
Decommission하려면 다음의 절차를 따라야 함
- Node를 Disconnect 해주기
- Disconnect 되면 Offload 해주기
- Offload 되면 Node delete하기
- delete 되면 제거 해당 호스트에서 NiFi 서비스를 stop/remove
전에 포스팅한 글을 보면 이러한 패턴을 써서 클러스터링을 하면 가용성을 높일수 있다고 주장하지만..
결론적으로 보면 가용성은 높지만 이 패턴은 많은 단점들을 피해갈 수가 없다. 단점들은 다음과 같다.
- 설정할게 많고 복잡함
- 루트 그룹 레벨과 그 사이 모든 레벨에 입력 포트가 필요 -> 다중 사용자 환경에서 문제 야기
- 연결이 끊어진 그래프가 그려짐
- 재사용하기 힘듬
- 동일한 데이터를 동일한 노드로 보낼수가 없다캄
- 글쓴이도 어떻게 하는지 안해봐서 모르겠음. 해보려 했는데 뭔가 잘 안됨.
사실 애초에 Remote Process Group은 데이터들을 클러스터링 하기위해 만들어진 목적이 아님. 원래는 그냥 NiFi 인스턴스에서 다른 NiFi 인스턴스로 데이터를 전송하기 위한것
마침 NiFi 1.8 버전부터 Connection level에서 여러 클러스터에 걸쳐 로드밸런싱을 허용하게 함. 이게 제공되지 않던 전의 버전과 비교했을 때 가히 혁명적임. 두 프로세서 사이에 Connection을 만들면 그 Connection 설정에서 몇가지 옵션이 제공됨.
저기 보이는 Load Balance Starategy가 바로 그것★ 옵션에는 다음이 있음
- Do not load balance: 로드밸런스 안함.
- Round-Robin : 라운드로빈 방식
- Parition by attribute : 플로우파일에 있는 특정 attribute를 지정하여 그게 같은 값들은 같은 노드로 보내게 해보림
- Single Node: 원래 쓰던 그 노드로 계속 쓰게 해보림
다음의 차이를 확인해보자
다음은 임의로 플로우파일을 생성하여 애트리뷰트만 추가하는 프로세스이다. 확인 차 최소한의 프로세스만 구성하였다. 이 플로우에서는 아무런 로드밸런싱 설정을 하지않았을 때의 결과를 보여주게 된다.

어랍쇼? 클러스터중 한놈만 큐만 쌓이고 열일하고 있는걸 볼 수가 있다.

따라서 동작을 중지하고 모든 큐를 비운 후 UpdateAttribute 바로 밑의 큐를 더블클릭하여 다음과 같이 설정을 바꿔보자.

결과가 균등하게 분배되는 모습이다. 드디어 우리가 원하는 이상적인 Load Balance의 모습을 보여주고 있는 것 같다.

주의해야 할 것은 앞에서도 설명했다시피 외부 서비스와 통신하여 데이터를 땡겨오는 부분이다.
다음의 설정으로 GenerateFlowFile을 실행시켜보겠다.

바로 밑에 붙어있는 커넥션의 컨피그는 다음과 같다.

???

어랍쇼?? 전 Back Pressure Object Threshold를 10000으로 설정했는데요?? 왜 30000개가??

그렇다. 모든 클러스터가 한꺼번에 같은 데이터를 동시다발적으로 땡겨옴을 볼 수 있다. 위에서 명시했다시피 이러한 작업은 불필요 할 수 있을 뿐더러 Concurrent Issue를 야기 할 수 있다.

데이터를 땡겨오는 프로세서에서는 이 부분을 반드시 Primary node로 설정하도록 하자.

실제로 NiFi 공식문서도 이러한 방법을 권하고 있으며 클러스터에 데이터를 피딩하는 가장 일반적인 방법이라 하고있다.

큐가 정상적으로 10000개가 쌓였다.

Primary Node만 가용되는 모습이다.

데이터를 땡겨올때는 Primary Node 밖에 가용할 수가 없지만 Concurrent문제를 해결하기 위해서는 어쩔수 없다.
난 클러스터가 100퍼센트 균등하게 가용되길 바라! 난 이게 싫어!
그러면 복잡하고 귀찮으며 재사용 불가능한 List/Fetch 패턴을 써서 데이터를 땡겨오자.
ERROR [main] o.a.nifi.controller.StandardFlowService Failed to load flow from cluster due to: org.apache.nifi.controller.UninheritableFlowException: Failed to connect node to cluster because local flow is different than cluster flow.
org.apache.nifi.controller.UninheritableFlowException: Failed to connect node to cluster because local flow is different than cluster flow.
at org.apache.nifi.controller.StandardFlowService.loadFromConnectionResponse(StandardFlowService.java:937)
이제 실패 시나리오에서 어떤 일이 일어나는지 생각해 봅시다. 특히 노드가 클러스터에서 연결이 끊어 지거나 노드 A가 단순히 노드 B와 통신 할 수없는 경우 어떻게됩니까?이 경우 노드 B를 기다리는 동안 대기중인 데이터는 어떻게됩니까? 데이터가 대기열에 올라가거나 다른 노드로 장애 조치됩니까?
로드 밸런싱 전략이 구성되어 있는지 여부에 따라 다릅니다. "라운드 로빈"을 사용하고 장애가 발생하면 데이터가 다른 노드로 재조정됩니다. 이 경우 데이터는 상당히 느리게 재조정됩니다. 최대 1,000 개의 FlowFiles 또는 10MB의 데이터가 초당 재조정됩니다. 이는 노드가 클러스터에 다시 연결되거나 일시적으로 다시 통신 할 수있는 경우 데이터가 다른 노드로 즉시 재분배되지 않도록하기 위해 수행됩니다. 그러나 그러한 일이 발생하지 않는다면, 데이터는 적시에 클러스터 전체에 재분배됩니다.
"속성 별 파티션"또는 "단일 노드"전략을 사용하면 노드가 다시 연결되어 통신 할 수있을 때까지 데이터가 대기열에 대기하고 전송 대기 상태가됩니다. 이는 이러한 전략이 데이터의 특정 부분이 특정 노드로 이동하는 것을 예상하기 때문입니다. 반면 "라운드 로빈 (Round Robin)"은 데이터가 클러스터 전반에 퍼지기를 기대하기 때문입니다.
이 기능은 제공되는 사용자 환경을 크게 개선 할 수있는 매우 강력한 기능이지만,이 기능은 다른 매우 흥미로운 기능에 대한 토대가됩니다. 새로 추가 된 "오프로드"기능은이 메커니즘을 사용하여 클러스터의 노드를 연결 해제 한 다음 오프로드 할 수있게합니다. 이렇게하면 해당 노드에서 모든 프로세서를 중지하고 클러스터의 모든 데이터를 정지 된 노드에 배포 할 수 있습니다. 이는 NiFi 노드의 손쉬운 폐기와 진정한 탄력적 클러스터링 기능을 가능하게합니다.
안녕하세요, 데이터를 땡겨올 때는 무조건 노드 1개만 사용해야하는건가요? 큐에 담은 다음에 분배하는 플로우로 해야하는거죠?