This is the story of what happened when I went down a rabbit hole.
It starts with k7. If you press Ctrl-] in the k7 WASM console, this appears:
x^x*/:x:2_!100
That's a prime number filter. There are faster ones - kparc.com's x,1_&&/80#'!:'x is beautiful - but this one is really short.
The above k7 snippet:
- gets the numbers 0 to 99 (
!100) - drops the first two (
2_), and assigns that tox(x:) - gets the product of each element in
xwith each element ofx, forming a table (x*/:x) - then removes the elements in that table from
x(x^). And we have it.
The snippet wasn't always so short: it relies on rank-sensitive 'except' (^), which Arthur introduced around 1 May 2019. Before then, it was this:
x^,/x*/:x:2_!100
This older version inserts a step between #3 and #4: it merges the result of multiply-each-right (*/:) into a single list via ,/, also known as 'raze'.
This raze bugs me. It's a workaround: we wanted a flat list of results from our multiply, but it came out nested, and we had to flatten it manually.
How could we have done this without using raze, and without rank-sensitivity?
Well, what if each-right isn't the right tool? How else could we have generated the products of pairs?
Here's another approach. We split the pair generation and multiplication:
x^*/x@!2##x:2_!100
The speed seems about the same, but it's more complicated because we have to manage the generation of indices - measuring how many we need (#), taking a copy (2#), generating index pairs using odometer (!), indexing in (x@), and then multiplying (*/).
Could we skip indexing? In an array language?
Well... there's another primitive that has a reputation of keeping data flat:
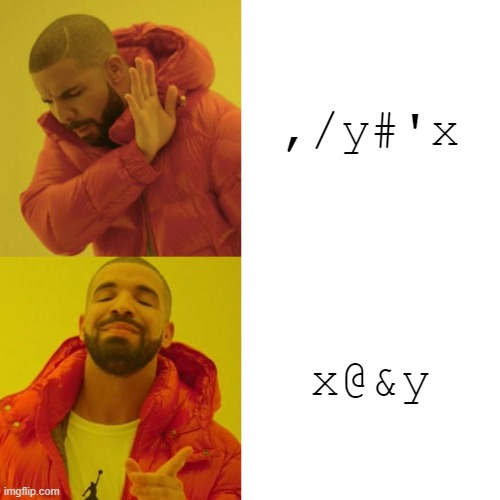
You'll know that many 'shallow' k verbs have deep equivalents.
- Range is just shallow odometer:
![3]~*!,3. - At
@is just shallow dot.:(list @ indices) ~ *list . ,indices.
Loosely speaking:
- Shallow verbs take a list in which each element represents an index, and are implicitly one-dimensional.
- Deep verbs take a list in which each element represents a dimension, and sub-elements represent indices.
For example, we can think of odometer ! m,n,... as generating all paths within a m*n*... matrix:
!2 3
(0 0 0 1 1 1 / dimension 1
0 1 2 0 1 2) / dimension 2
These can be fed to dot to do deep indexing. (This is what we did in the odometer-style primes generator above.)
(("abc";"def")').!2 3
"abcdef"
Where (&) is a shallow verb. When used on a list of positions it outputs the numbers at those positions. Its output is typically used for indexing, but it doesn't have to be.
& 0 1 0 2
1 3 3
"abcd" @& 0 1 0 2
"bdd"
Shallow where produces something like range, so a deep version of where should produce something like odometer.
And - critically - we can also use where on a dict to get a subset (or repeats) of its keys:
&`a`b`c!1 0 2 / or [a:1;b:0;c:2] in k9 dict literal syntax
`a`c`c
We're going to use deep where to generate the pairs. Call it ω for now.
- We'll create a matrix where the rows and columns are keyed by the numbers 2 to 99 (
2_!100) - also known as a key table. - We'll then use deep where on the keytable to get copies of each row and column key.
Here's the setup:
{keytable: x!/:x!1 / a matrix full of 1s with rows and columns keyed by 2, 3, ..., 99
pairs: ω keytable / the *flip* of pairs (2,2), (2,3), ..., (99,98), (99,99)
products: */pairs / 4, 6, ..., 9702, 9801
x^products}2_!100 / winning!
(Yes we use each-right when generating the keytable, but that's OK - we want nested data in that context.)
There's just one problem: at the time of writing, deep where isn't a k verb. But it is a verb in Dyalog APL (⍸: docs, wiki, video), and we can't let those bastards win.
Luckily, ngn has already implemented an experimental deep where verb in ngn/k, and put it on shallow where's character & (similar to how range and odometer share !).
&(1 1;2 0)
(0 0 1 1
0 1 0 0)
So we're good to go! Everything is going to turn out gre-
'typ
pairs: &keytable
Well, ngn did say it was experimental. We need to dig into the ngn/k deep where implementation to see what's going on.
ngn/k's source is available on Codeberg, and luckily for us deep where is implemented as a k-string here. I've broken it out for ease of reading:
{$[`A~@x / general list?
(,&#'*'x),,'/x@\\:!0|/#'x:o'x / get dwhere of inner lists; pad short paths; merge paths;
/ replicate this dimension's keys and put that on top
,&x]} / apply shallow where, and nest it
I tried modifying this so that it works for dicts and keytables and didn't get far, though it probably can be done.
Instead, I went in a different direction:
When you look at the deep verb variants, it's as if they were the shallow variant working on an 'exploded' dict form of the data. That dict has:
- keys representing the paths to each element, and
- values representing a 'flat' view of the data's atoms.
For example, if we take [a:"AB";b:"CD"], an exploded version looks like this:
`a 0 -> "A"
`a 1 -> "B"
`b 0 -> "C"
`b 1 -> "D"
Once exploded, we can use @ to get something like what . gives us, if we first flip the indices from dimension space into index space:
data:`a`b!("AB";"CD")
indices:(`a`b;1 0)
(data') . indices
"BC"
explode[data]@+indices
"BC"
It's not a perfect model - for example the real dot would let us get a projection:
(2 3#!2*3) . ,1
3 4 5
Nevertheless, in many cases, a shallow verb can act similar to a deep verb if it's working on this exploded form of the data.
So let's make life easier by implementing an explode verb. Here's a rough model - note m is the type of dicts in ngn/k.
key:{!$[`m~@x;x;#x]}
val:{$[`m~@x;. x;x]}
explode:{k:{$[&/{x~*x}'x; ,'key[x]; ,/key[x],/:'o'x]}x
v:{$[x~*x; x; ,/val@o'x]}x
k!v}
And we can now write deep where as an application of shallow where: +&explode@.
That gives us our razeless and index-free prime generator. Try it here!
f:{keytable: x!/:x!1 / a matrix of 1s with rows and cols keyed by 2, 3, ..., 99
pairs: dwhere keytable / the *flip* of pairs (2,2), (2,3), ..., (99,98), (99,99)
products: */pairs / 4, 6, ..., 9702, 9801
x^products} / winning!
f:{x^*/&x!/:x!1} / compressed
g:{x^,/x*/:x} / f is a bit longer than the raze-y original... and ~twice as slow
f 2_!100
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
We can now define deep forms of other shallow verbs such as group = and find ?. Note deep find is defined as ƒ so that we can use it infix - ngn/k lets us define infix dyads if they use certain symbols. Try it here.
matrix:(1 0 2;0 1 0)
dgroup:+'=explode@
dgroup matrix
1 0 2!((0 1;0 1);(0 1 1;1 0 2);(,0;,2))
(ƒ):{+explode[x]?y} / deep find
matrix ƒ 2 0
(0 0
2 1)
We could also define an implode verb that takes a path map and turns it into a deep structure. Something like:
implode: {indices:!x
shape:1+|/'+indices
matrix:shape#1
pairs:+(+','indices;val[x])
matrix{.[x;*y;:;:/y]}/pairs}
x~implode explode x:(1 2 3;4 5 6)
1
I liked that reshape becomes a flipped odometer strapped to a value list coupled with an implode:
("abc";"def")~implode(+!2 3)!"abcdef"
We could always assign this to the inverse of explode if it were a symbol verb, ie `explode?.
Finally, some thoughts on these tools:
- Will deep where sometimes offer a performance boost?
- For example the
x*/:xapproach doubles up on pairings, but the deep where approach could avoid this by generating pairs using a triangular matrix. - And could there be an advantage to doing
+/explodeinstead of+//to sum all elements in a nested structure?
- For example the
- If
explodeandimplodewere verbs (or possibly adverbs), we could eliminate duplicate forms of shallow and deep verbs: range and odometer, at and dot, where and deep where, etc. - I wonder if
explodeis better suited to being a 'depth' adverb:- The verb form loses info about whether the data structure is a list or a dict.
- A verb round-trip (
implode explode x) would lose info about empty lists. - As currently implemented the verb round-trip involves two flips - better if the computer can do that translation itself.
In k7 we could also have rewritten the primes generator - without indexing or each-right - as:
{x ^ */ + -2 cmb x}2_!100 / -i cmb is with replacement
{x^*/+-2 cmb x} / condensed
But perhaps 'deep where' would assist in implementing cmb or prm... here could be a good place to start.
Also, ngn/k's 'filter' (f)# is implemented to model {y@&x y}. If we take that & literally, then if f returns a list of lists, it will act as 'deep where' and so we'd get a 'deep replicate'. We could use that to write our expression a little more tacitly (and without resorting to dicts) as:
{x^*/&x!/:x!1} / before (dicts; three `x`)
{x^*/+(1|=#:)#x} / after (no dicts; two `x`)
^/(;*/+(1|=#:)#)@\: / hypothetical full-tacit approach
Next up - the War on Lambdas.
If you liked this, follow @kcode on Bluesky.
oantolin below found a nice way to do it without razing: {x^/x*/:x}
I don't know anything about k, but this example seems to have a typo in the result.