Dark Coder codewithdark-git
- Ahsan Umar,
- Email: ahsanumar.dev@gmail.com
- LinkedIn: Ahsan Umar
The Hybrid Vision Transformer (HVT) architecture represents a transformative advancement in the field of computer vision by seamlessly integrating the computational efficiency and localized feature extraction strengths of convolutional neural networks (CNNs) with the global contextual modeling capabilities of vision transformers (ViTs). This synthesis allows HVT to leverage the hierarchical feature extraction characteristic of CNNs while incorporating the ViT's capacity for capturing long-range dependencies, thus addressing inherent limitations present in standalone architectures. This paper offers a comprehensive and rigorous analysis of the HVT repository, emphasizing its architectural intricacies, theoretical foundations, and implementation strategies. By uniting local and global feature representations,
Class that implements the scaled dot-product multi-head self-attention mechanism, similar to the previous implementation but with NumPy instead of PyTorch. Let's break down the key parts of this code and explain the functionality with clarity.

The SelfAttention class is responsible for computing attention scores based on input embeddings, then applying multi-head attention, and projecting the output back to the original embedding space.
In this notebook, we develop and train a Convolutional Neural Network (CNN) for skin cancer detection, specifically using the melanoma dataset. The primary goal is to build a model that can accurately classify skin lesions as either malignant or benign based on images. This is a crucial step in automating skin cancer detection, assisting healthcare professionals in diagnosing melanoma at an early stage.
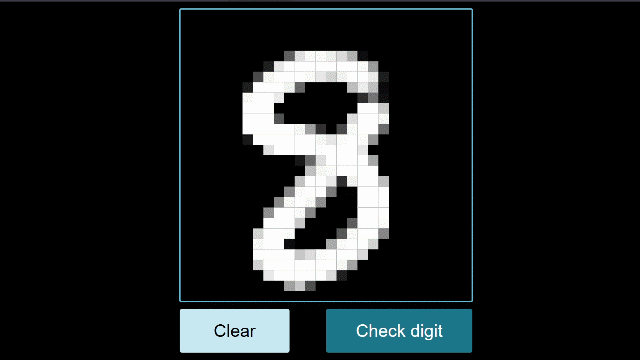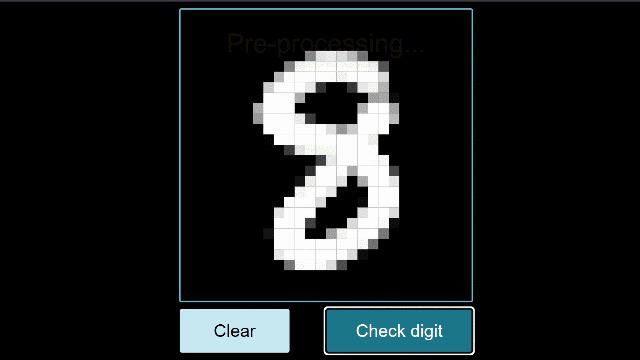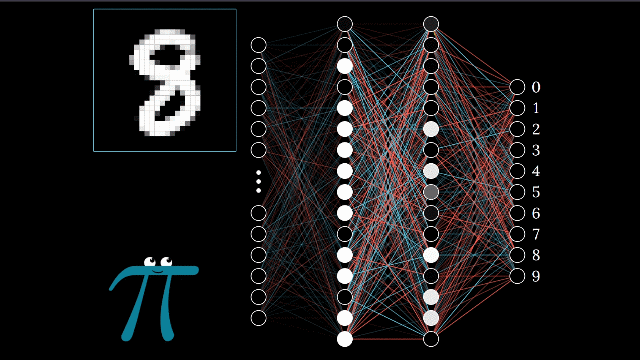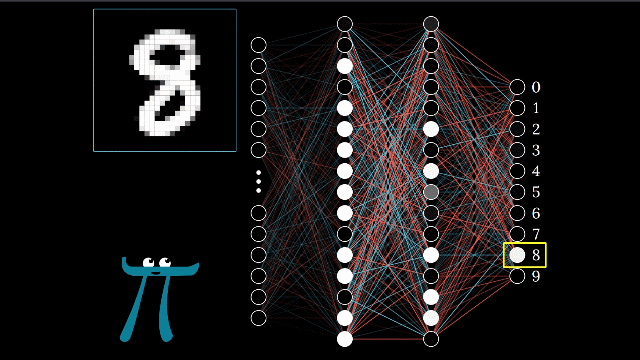
Ever wondered how neural networks actually work under the hood? While frameworks like PyTorch make it easy to create neural networks with just a few lines of code, understanding the underlying mechanics is crucial for any machine learning practitioner. In this guide, we'll demystify neural networks by building one from scratch and comparing it with a PyTorch implementation.
Before diving into the code, let's understand what happens inside a neural network. Imagine your neural network as a complex system of interconnected nodes, similar to neurons in a human brain. Each connection has a weight, and each node has a bias - these are the parameters that your network learns during training.
Gradient descent is the workhorse of modern machine learning, powering everything from simple linear regression to complex neural networks. In this comprehensive guide, we'll dive deep into batch gradient descent, understanding how it works, its advantages and limitations, and when to use it.
Batch gradient descent is an optimization algorithm used to find the parameters (weights and biases) that minimize the cost function of a machine learning model. The term "batch" refers to the fact that it uses the entire training dataset to compute the gradient in each iteration.





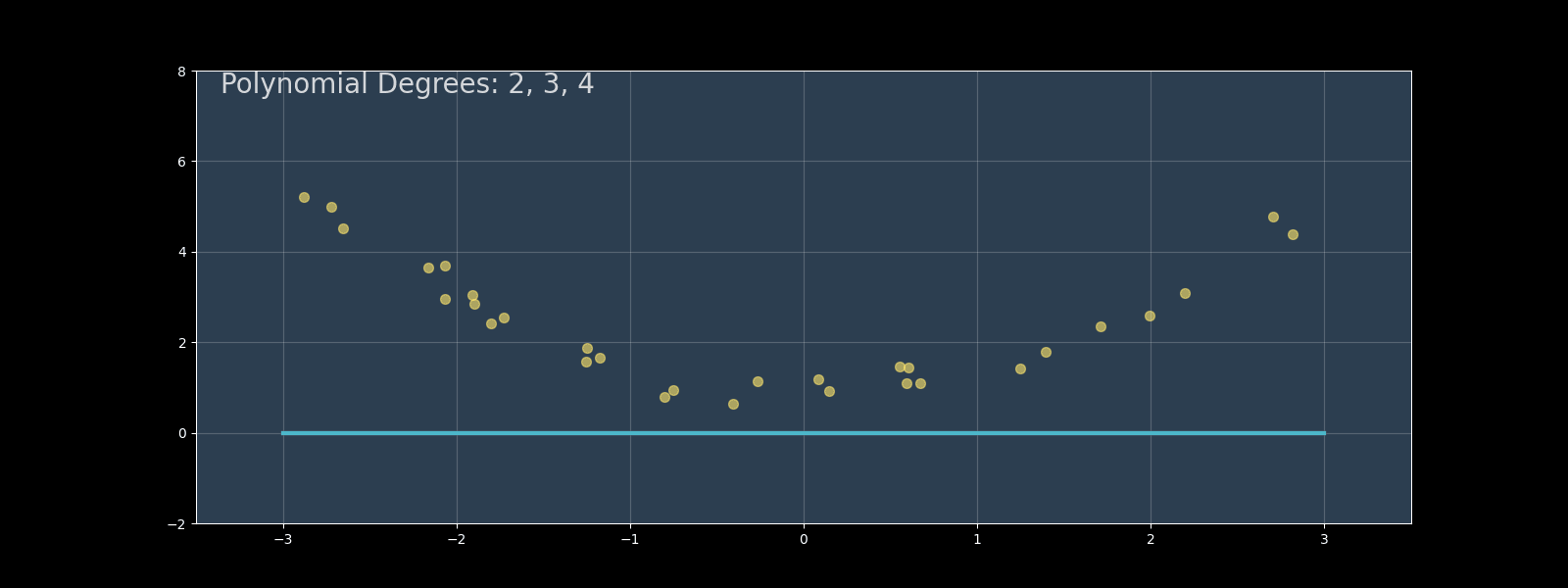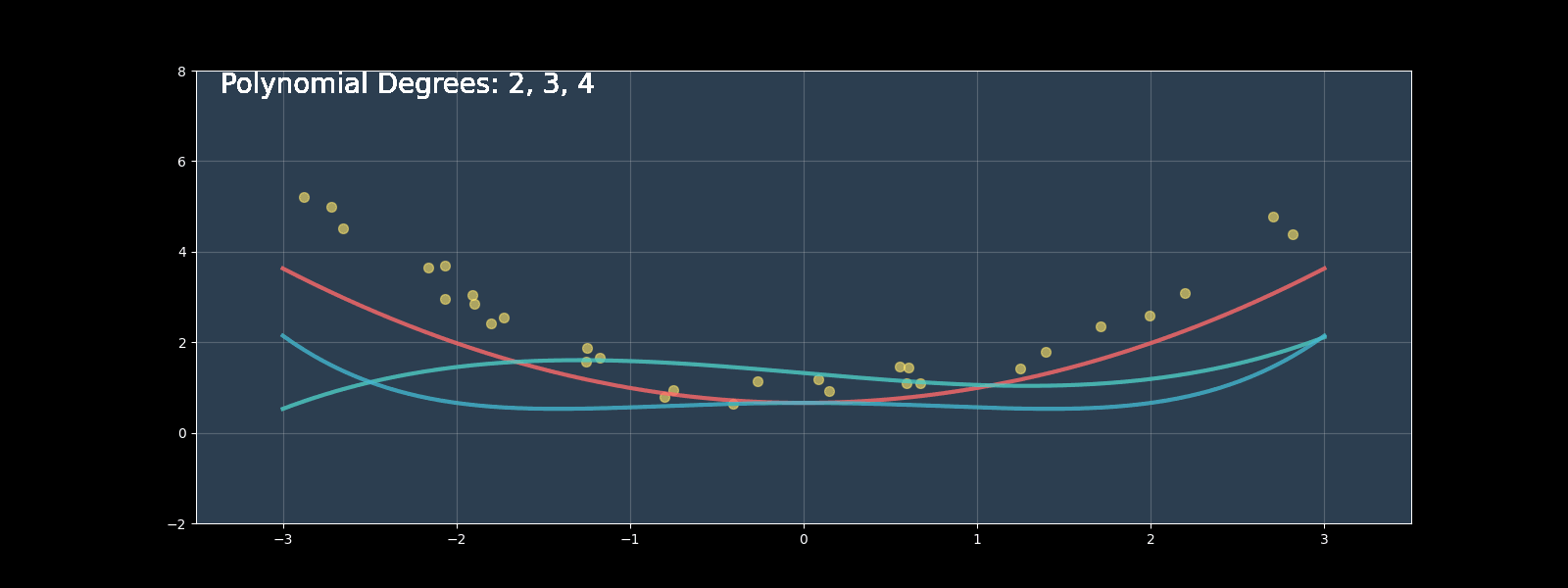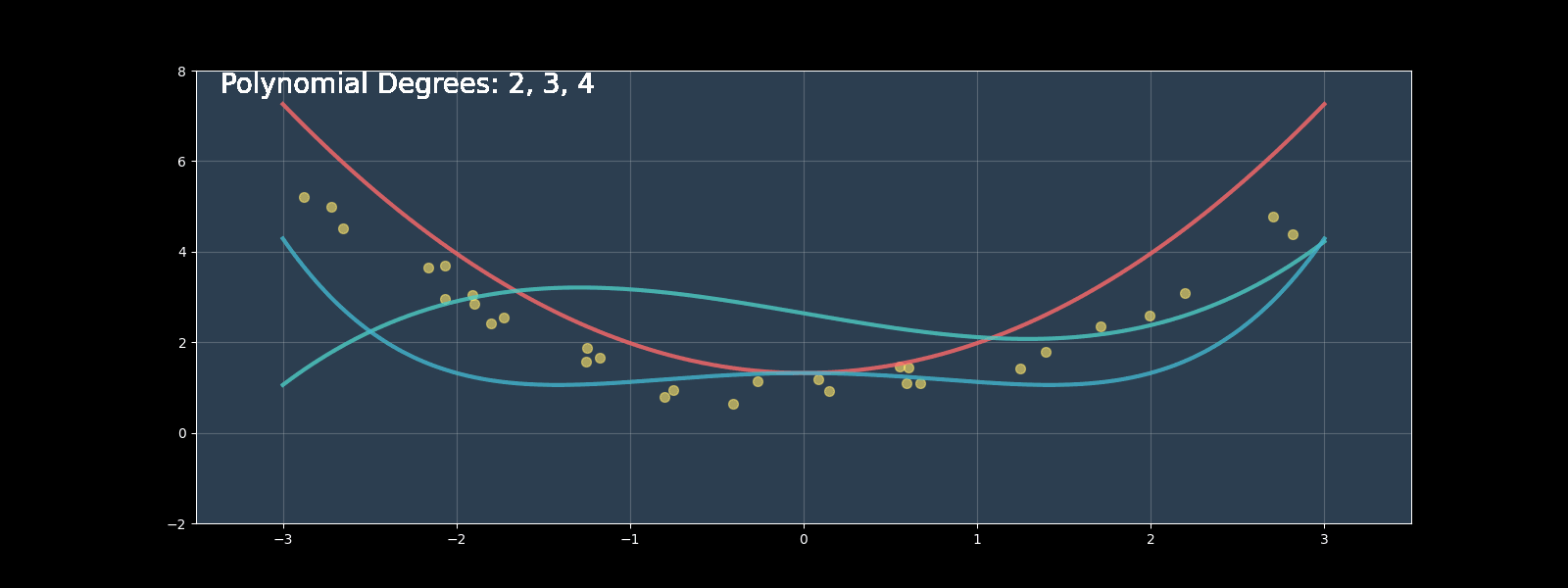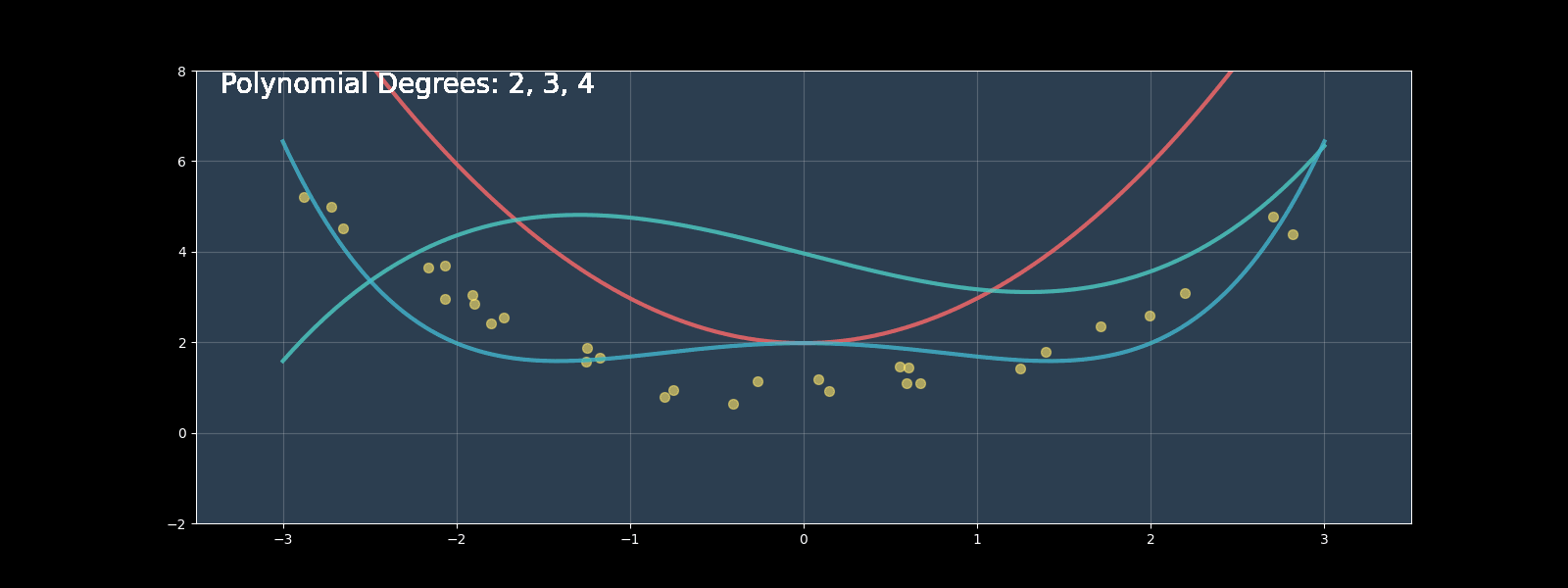
Polynomial regression extends linear regression by modeling nonlinear relationships using polynomial terms. In this comprehensive guide, we'll implement polynomial regression from scratch, compare it with scikit-learn's implementation, and explore optimization techniques.
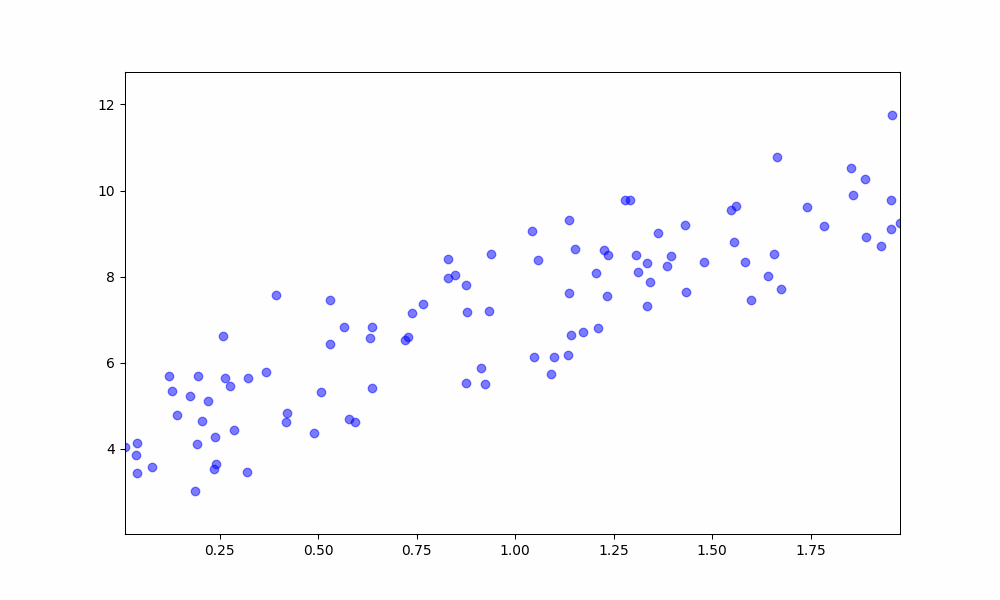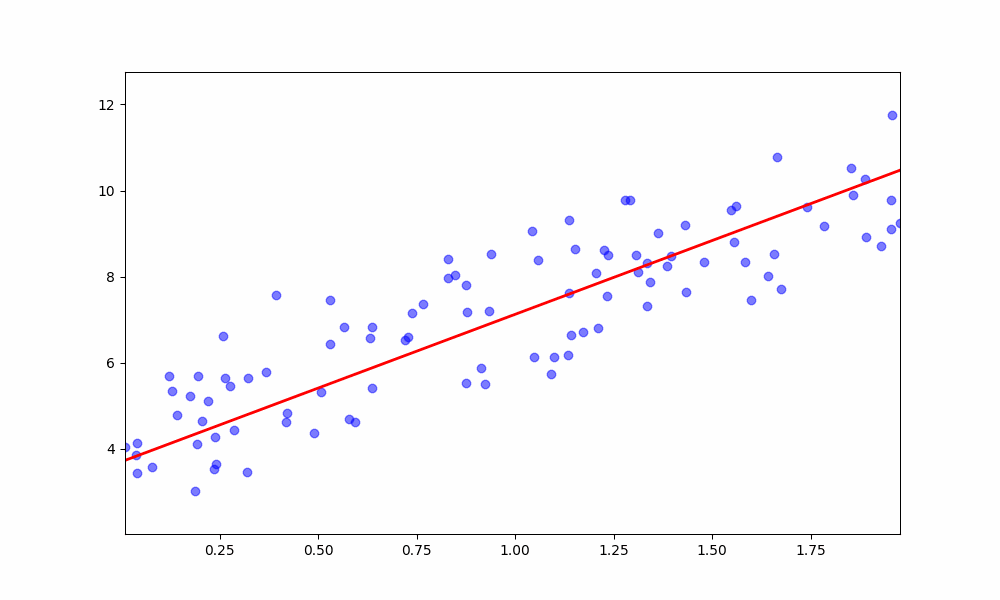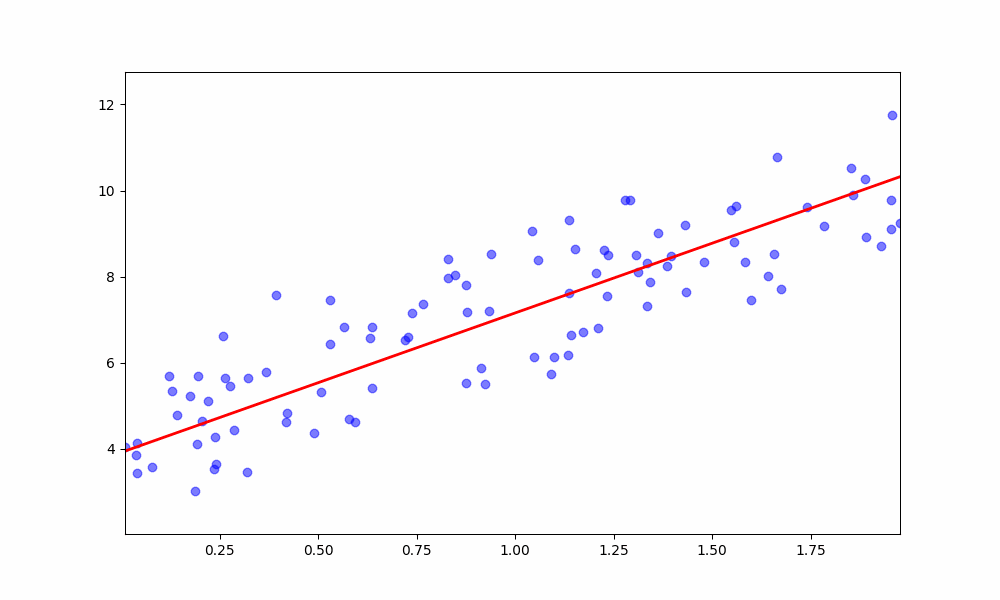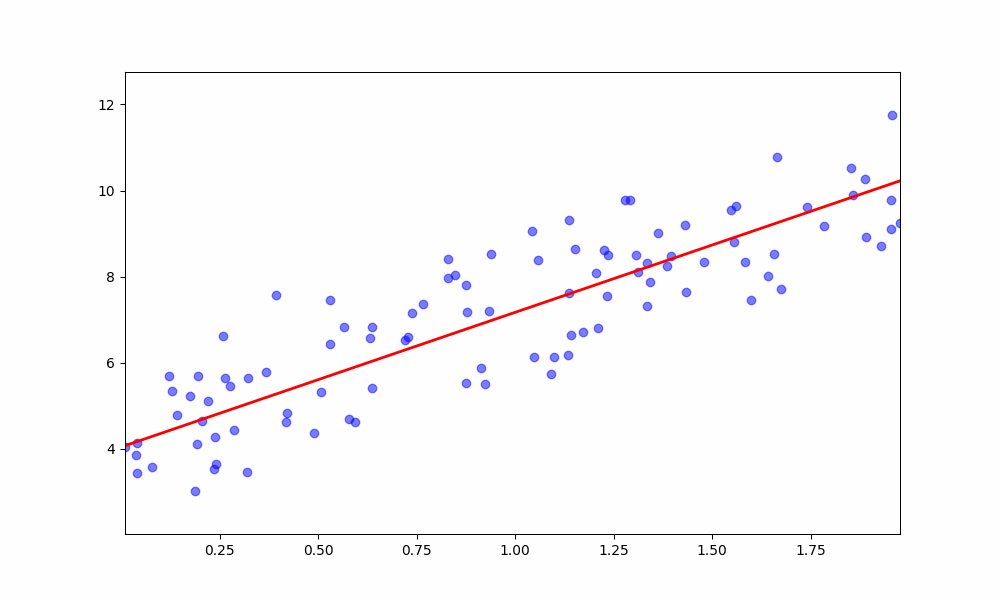
Multiple Linear Regression (MLR) is a statistical method that models the relationship between a dependent variable and multiple independent variables. It extends simple linear regression, which uses a single feature to predict the outcome, to handle multiple features. The general form of the MLR equation is: