- interactive shell --
kubebash <namespace> <deployment> - live colored logs streaming --
kubelogs <namespace> <deployment> - deployments dockertag table --
kubebranch <namespace> [<partial deployment name>]
A customized subset of kubectl commands. See also: official kubectl cheatsheet
I just want plug&play bash functions
Set up kubectl and add these functions to .bashrc:
kubelogs() {
# View logs as they come in (like in Rancher) using mktemp and less -r +F.
# Use ctrl+c to detach from stream (enter scrolling mode)
# Use shift+f to attach to bottom of stream
# Use ? to perform a backward search (regex possible)
# Use N or n to find resp. next or previous search match
# Set KUBELOGS_MAX to change amount of previous lines to fetch before streaming
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -ne 2 ]; then
echo "Usage: kubelogs <your-namespace> <podname-prefix>"
return
fi
local namespace=$1
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
local tmpfile=`mktemp`
local log_tail_lines=${KUBELOGS_MAX:-10000}
local sleep_amount=$((7 + log_tail_lines / 20000))
echo "kubectl logs --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} --since 24h --tail ${log_tail_lines} -f ${podname} > ${tmpfile}"
kubectl logs --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} --since 24h --tail ${log_tail_lines} -f ${podname} > ${tmpfile} &
local k8s_log_pid=$!
echo "Waiting ${sleep_amount}s for logs to download"
sleep ${sleep_amount} && less -rf +F ${tmpfile} && kill ${k8s_log_pid} && echo "kubectl logs pid ${k8s_log_pid} killed"
}
kubebash() {
# Execute a bash shell in a pod
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -ne 2 ]; then
echo "Usage: kubebash <your-namespace> <podname-prefix>"
return
fi
local namespace=$1
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
kubectl exec -ti --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} ${podname} bash
}
kubebranch() {
# View a list of current branch[es] deployed for namespace [+ pod]
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -gt 2 ]; then
echo "Usage: kubebranch <your-namespace> [<partial-podname>]"
return
fi
if [ $# -lt 1 ]; then
echo "Usage: kubebranch <your-namespace> [<partial-podname>]"
return
fi
local namespace=$1
if [ $# -eq 2 ]; then
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
kubectl get deployments --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | sed -n '1!p' | awk '{print $1 "\t" $8}' | uniq | tr ":" "\t" | column -t | grep ${pod}
else
kubectl get deployments --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | sed -n '1!p' | awk '{print $1 "\t" $8}' | uniq | tr ":" "\t" | column -t
fi
}View
In order to use kubectl from your machine (cluster specific), write the kubeconfig file to ~/.kube:
mkdir ~/.kube
nano ~/.kube/config
# paste kubeconfig (see image) and write out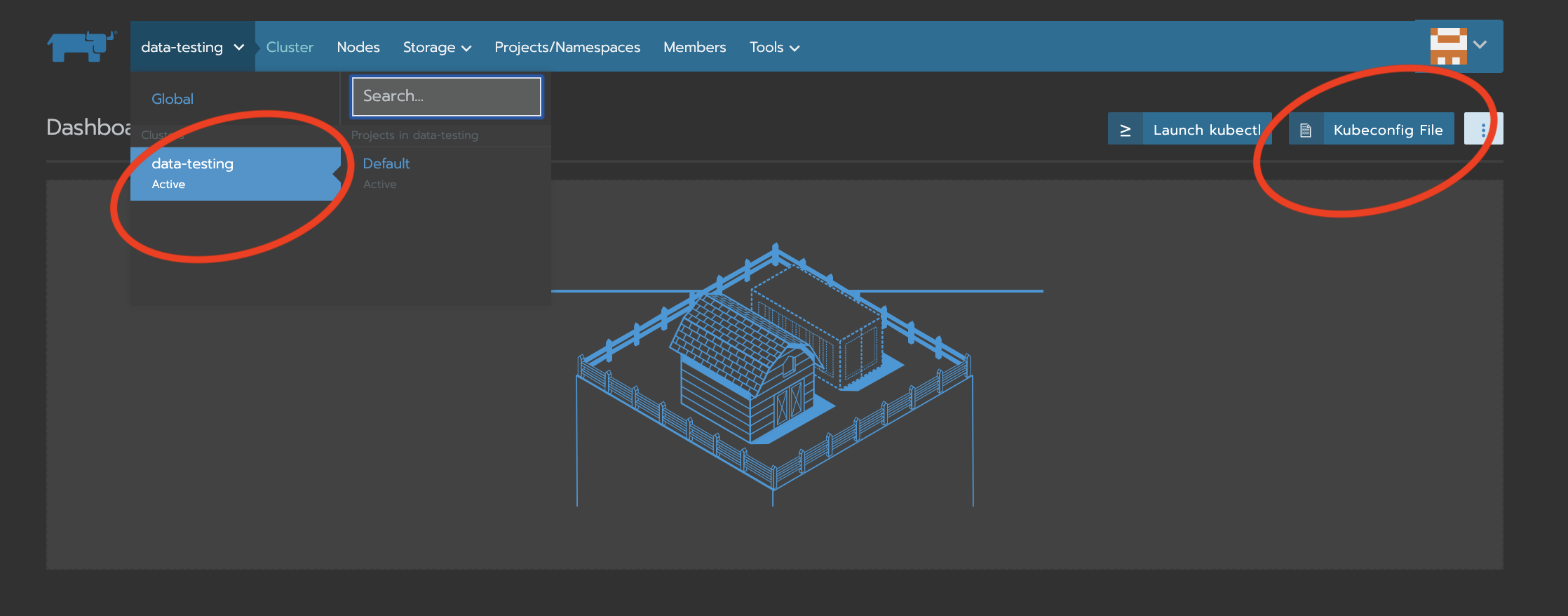
View
Might fail if there are missing permissions for namespaces
# list full podnames in a namespace
kubectl get pods --namespace <your-namespace> -o wide
# list all namespaces in the cluster (will error if there are missing permissions for some namespace)
kubectl get namespaces
# list all pods in all namespaces in the cluster (will error if there are missing permissions for some namespace)
kubectl get pods --all-namespaces -o wide
# execute e.g. `ls -l /code`
kubectl exec -ti --namespace <your-namespace> <full-podname> -- ls -l /codeView
To view the last 25 lines in the past 24h, plus all new messages, use:
kubectl logs --namespace <your-namespace> --since 24h --tail 25 -f <full-podname> | less +FTo automate finding full podname and viewing logs, add the following function to .bashrc and execute kubelogs <your-namespace> <podname-prefix>
kubelogs() {
# View logs as they come in (like in Rancher) using mktemp and less -r +F.
# Use ctrl+c to detach from stream (enter scrolling mode)
# Use shift+f to attach to bottom of stream
# Use ? to perform a backward search (regex possible)
# Use N or n to find resp. next or previous search match
# Set KUBELOGS_MAX to change amount of previous lines to fetch before streaming
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -ne 2 ]; then
echo "Usage: kubelogs <your-namespace> <podname-prefix>"
return
fi
local namespace=$1
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
local tmpfile=`mktemp`
local log_tail_lines=${KUBELOGS_MAX:-10000}
local sleep_amount=$((7 + log_tail_lines / 20000))
echo "kubectl logs --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} --since 24h --tail ${log_tail_lines} -f ${podname} > ${tmpfile}"
kubectl logs --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} --since 24h --tail ${log_tail_lines} -f ${podname} > ${tmpfile} &
local k8s_log_pid=$!
echo "Waiting ${sleep_amount}s for logs to download"
sleep ${sleep_amount} && less -rf +F ${tmpfile} && kill ${k8s_log_pid} && echo "kubectl logs pid ${k8s_log_pid} killed"
}Notes:
- grep stops after first matching podname is found (
-m 1) - the
--timestampsoption forkubectl logsis also noteworthy. - Without sleep,
--tail 100will already become slow if lines are extremely long. Useless -S +Fto truncate instead of wrap long lines. Withmktempandsleep, the logs will be loaded before calling less, and even--tail 1000can be viewed 'instantly'.
View
To execute a bash shell in a pod, use:
kubectl exec -ti --namespace <your-namespace> <full-podname> bashTo automate finding full podname and executing shell, add the following function to .bashrc and execute kubebash <your-namespace> <podname-prefix>
kubebash() {
# Execute a bash shell in a pod
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -ne 2 ]; then
echo "Usage: kubebash <your-namespace> <podname-prefix>"
return
fi
local namespace=$1
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
kubectl exec -ti --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} ${podname} bash
}Notes:
- grep stops after first matching podname is found (
-m 1)
View
To get an overview of the branches currently deployed in a namespace [for pods containing some string], add the following function to .bashrc and execute kubebranch <your-namespace> [<partial-podname>]
kubebranch() {
# View a list of current branch[es] deployed for namespace [+ pod]
# Set $KUBECONFIG to deviate from "$HOME/.kube/config"
if [ $# -gt 2 ]; then
echo "Usage: kubebranch <your-namespace> [<partial-podname>]"
return
fi
if [ $# -lt 1 ]; then
echo "Usage: kubebranch <your-namespace> [<partial-podname>]"
return
fi
local namespace=$1
if [ $# -eq 2 ]; then
local pod=$2
local podname=`kubectl get pods --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | grep Running | grep -o -m 1 "^${pod}[a-zA-Z0-9\-]*\b"`
if [[ ${podname} != ${pod}* ]]; then
echo "Pod \"${pod}\" not found in namespace \"${namespace}\""
return
fi
kubectl get deployments --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | sed -n '1!p' | awk '{print $1 "\t" $8}' | uniq | tr ":" "\t" | column -t | grep ${pod}
else
kubectl get deployments --kubeconfig ${KUBECONFIG:-"$HOME/.kube/config"} --namespace ${namespace} -o wide | sed -n '1!p' | awk '{print $1 "\t" $8}' | uniq | tr ":" "\t" | column -t
fi
}Notes:
- partial podnames can be used
👍