from Haunting-Appeal-649 sent 9 days ago Hey, this is ridiculous to be dredging up an old post of yours, and I'm sure your sensibilities have changed since then, but I'm wondering what you meant by a certain quote from this post
The reason I do that, is that way, I separate the logic of querying the data I need out of the functions that operate on them. If I had a function take a User and do a get-in on it to grab say the username. If you do that, you've coupled your function to the User schema. If you restructure that, and the username moves to a submap, a vector, or changes key, etc., you broke all your code which was trying to grab it. What I do instead, is I have other functions whose job is to perform these queries. Or sometimes the query is just left in the top level function, the function that orchestrate a service process.
What's an example of how this is implemented? You mean if a function needed something out of user, instead of calling (get-in), you would define a new function called (get-username-from-user) or something, and call that instead? I'm having a hard time imagining how to sufficiently decouple database functions from other functions in a large clojure code base. I'm imagining a use case where there's basically a userRepository function (get-user) and it's being used in 500 other functions on a very large app. If the user map it returns changes, I've likely broken hundreds of parts of the app. Technically this wouldn't be solved in a statically-typed language, but it might be easier to refactor. I would still have an interface whose signature changed and would need to update every place that used that interface. I was just wondering if you found a good pattern for this in Clojure.
To Haunting-Appeal-649 I answer:
Hey, good question!
My answer will be long, so bear with me. The solution is quite holistic, you can't just structure the application any old way and expect to solve that problem, while it is true mandatory static types would solve it no matter how you designed the codebase, even in a big ball of mud way. In Clojure though, it all boils downs to a different way of modeling things which has some key properties:
- Shallow call-stack
- Star topology
- Independ units and data
Let me start with #1, we want to keep our call-stack shallow. That means, no function that calls another, and another, and another, and another, and etc., and especially not so where they pass through the chain top-level entities.
Think about it, say User is passed to the top function, and it passes User down to the second level, which passes it down to the third and then the fourth. Now your call-stack is 4-level deep, and User crosses down to the very bottom. You make a backward breaking change on User at the top? Well, all four levels are broken.
What if you had not passed in User all the way down? What if User was only used in the top function which extracted everything the next level needed from User, and put it into a new structure as defined by the second level function and passed that to it? Now if you change User in a backward breaking way, only the top-level is broken and needs to be refactored. The only thing broken is where the top-level function finds the data to create the new data-structure the second level wants. This should be your first eureka moment :p
This covers the rule that we don't want to pass down top-level entities, which is the first thing I mean by shallow call-stack, but the second thing I imply is also to simply not have so many levels to begin with. This leads us to point #2, star topology.
Topology is a fancy word that makes me sound smart :p, but it is also a cool concept that I'm borrowing from network engineering.
What I just described is a line topology, or it can grow to a tree topology if your levels branch out: https://upload.wikimedia.org/wikipedia/commons/9/97/NetworkTopologies.svg see the line and tree from that diagram. In terms of function calls, the line topology would be:
{kind=link}
A -> B -> C -> D
A calls B, that calls C, that calls D.
That is a deep call-stack. This is bad, too many dependencies, A depends on B,C,D, B depends on C,D, C depends on D. The only independent unit here is D which has no dependencies.
That means if you break C, you've broken A and B. If you break D, you've broken A, B and C.
This is a brittle topology. Break one thing, and you find yourself with a lot of cascading breakage.
Even worse is if it was a tree topology, you'd just have even more dependencies on your hand, and breaking one thing would have even bigger cascading breakages.
So how can we keep the call-stack shallow? Refactor to use a star topology (refer to the diagram again). In function calls it would look like:
A -> B
A -> C
A -> D
Or if I could do a better diagram:
B
^
|
D <- A -> C
Which looks more like a star.
A calls B, calls C, calls D.
I've also heard people call this orchestration vs choreography. In the star topology, A orchestrates between B, C and D. Where-as in the line or tree, or even worse if a graph, all the functions are choreographed to know about each other and figure out who to call next to deliver the app behavior.
Now in this new star topology, B, C and D are independent units (our property #3 hehe). Here too, you don't pass to them the top-level User entity, they are still "second-level", even though you only have two levels instead of four now. Which means that if User is broken, only A is broken. If B is broken, only A is broken. If C is broken, only A is broken. If D is broken, only A is broken.
And now we've achieved #1, #2 and #3. We have shallow call-stacks of independent units and data, in a star topology.
We still don't have nice mandatory static types that can give us squiggly lines where things got broken when we break some data-schema or function input/output schema. But we've dramatically reduced the breakage area of a breaking change, so managing without them will be much easier, and the entire code base is just in a better shape overall.
If you break a top-level entity, you only need to care about refactoring top-level functions. If you break a second-level function, you only need to care about refactoring the top-level functions that used it. If you break a top-level function, well you need to refactor that top-level function only. And that's it. That's all the refactoring you'll ever need.
Now, as your application accrues more and more behavior, those top-level functions might start to get pretty big, if there's say 50 connected functions to it in the star, that starts to be a lot of things to orchestrate for one function. My advice at first though, don't be afraid of large top-level function, it might trigger your old OOP advice of nothing should be more than 50 loc, but if all it does is orchestrate, and it gets to be 300 loc, or 700 loc, it's still not that bad, it should look very much like a recipe: do this, take that, send it to that, take both those things, get this and that, pass it to this other thing... With comments along the way so it reads like a book if you want.
Still, at some point, you might want to factor those, or start to share some chunk of the orchestration between top-level functions that use similar chunk of functionality.
When this happens, you keep the same principles, but you evolve to a star-bus topology, or tiered-star topology. See: https://www.conceptdraw.com/How-To-Guide/picture/star-network-topology-diagram.png and https://study.com/cimages/multimages/16/99115d4e-f3cb-4ec8-9d91-66e6f923591f_figure_2.png for what that looks like. Just replace all those "computers" with functions and you get what I'm talking about.
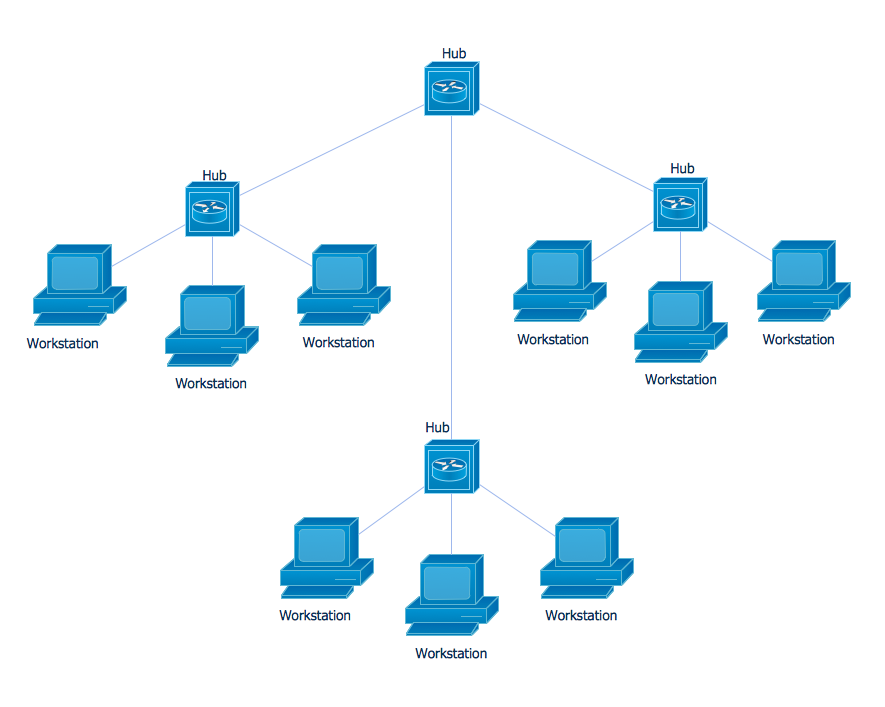{kind=link}
{kind=link}
Basically, we expend #3, so we will have independent stars, that form their own units with their own data. Each star has all the benefits I described and follow the same principles. And they themselves are orchestrated together in a star as well. It's a star of stars.
It turns out Clojure is really good for this type of code architecture. Since there are no "Class" or "Types", taking a top-level data-structure and passing to the next level a new data-structure in the shape that next level want is trivial, it doesn't force you in declaring the second level "Class" or "Type", etc. That makes it very low friction, quick and painless to have each function take its own data-structure, and have the top-level functions quickly transform data back and forth between them as needed.
This helps not get lazy with the architecture, in OOP with Classes, I'm too lazy to design the code this way, so I'll quickly start passing the User class everywhere, because creating UserForFn1, UserForFn2, etc. it's too cumbersome. Ounce I've done that, I've quickly coupled everything together through this shared data schema. Even worse, in OO, which is normally mutable, I've even coupled it all to the actual data, not just the schema, but they're literally mutating the same thing as it's going around everywhere.
Immutable data is obviously the next big one which makes this design work. If you passed something to B, it can't mess it up for C without A being aware of it.
And the data-oriented nature of Clojure is well suited, with its powerful data manipulation APIs, so transforming the top-level structure into the one each point of the star wants and returns is also straightforward.
Finally, you technically don't even need to use different data-structures, you can do so only when breakage is introduced. But you need to make sure you declare what each function will use, at the field level. So don't call your parameters User in B,C and D. Instead use destructuring: {:keys [name email]}. And never use :as user unless you are doing something generic, as in you don't actually use any fields, but instead to something using keys or vals, or something generic to a map. And like I said, if you :as user, don't pass that user down to another function, then you've coupled yourself and now will wish you had types again.
Here's a small example:
(defn prepare-update-profile-input
"I don't normally extract this, but you could, its so quick in Clojure
to transform data that I normally inline it all, but as I said, you could
move it out if you prefer, it does mean these functions also break now though
if some of the top-level entities break, but they'd still be pretty simple
to identify and fix."
[user]
{:name (-> user :profile :username)
:bio (-> user :profile :biography)})
(defn update-profile
[{:keys [name bio]}]
(let [profanity? (or (contains-profanity? name) (contains-profanity? bio))]
(if profanity?
(throw (ex-info "You can't update your profile to that, please be respectful" {:name name :bio bio}))
{:name (sanitize name)
:bio (sanitize bio)})))
(defn is-user-active?
[last-updated last-login is-frauded]
(if ;; last updated more than a year ago
;; has not logged in more than a month
;; or is frauded
false
true))
(defn update-profile
[user-id]
(let [user (repo/get-user db user-id)
is-user-active? (is-user-active? (:last-updated-date user) (:last-login user) (:frauded? user))]
(if is-user-active?
(let [updated-profile (update-profile (prepare-update-profile-input user))
updated-user (-> user
(assoc-in [:profile :username] (:name updated-profile))
(assoc-in [:profile :biography] (:bio updated-profile)))]
(repo/update-user db user-id updated-user))
(throw (ex-info "Can't update the profile of an inactive user" {:user user})))))
This is a bit of a stupid example, and I'm all over the place with it, but it shows the point.
There's an alternative to this, which is a bit of a compromise, where you take a bit more coupling for a bit more convenience, but it is otherwise pretty similar in keeping things shallow, and in a star topology, and as independent units and data. The difference it you couple to a bit more top-level data in each star, for convenience. When I do this, I go full domain driven design though, where the principle is that you need to think carefully about your domain model upfront, because you know you will couple a lot too it, and that being the most central and shared part of it all, it will be hardest to refactor, so you want to try and get it as right as you can.
I've used both approaches quite successfully. For the other approach, I recently wrote a more complete example here: https://github.com/didibus/clj-ddd-example but I explain more the DDD and functional core / imperative shell aspect of it. That said, you can see, it keeps things pretty shallow, and it is all modeled as a star topology. More importantly, in DDD, each bounded context would be a star and the whole set of all bounded contexts would be like your star of stars, when the system would grow really big. That said, you take on a bit more coupling on your domain entities, which saves you a bit of having to map back and forth. Like I said though, I've been successful with both approaches, and the DDD can be heavy handed if you don't have complex domains with lots of invariants.