Benchmark recovery from remote
We will use the existing workflow in: https://github.com/dliappis/stack-terraform/tree/ccr/projects/ccr
- ES: 3 node clusters, security enabled
- GCP: ES: custom-16-32768 16cpu / 32GB ram / min Skylake processor, Loaddriver: n1-standard-16 (16vcpu 60GB ram)
- AWS: ES: c5d.4xlarge 16vcpu / 32GB ram, Loaddriver: m5d.4xlarge (16vcpu 64GB ram)
- Locations:
- AWS: Leader: eu-central-1 (Frankfurt) Follower: us-east-2 (Ohio)
- GCP: Leader: eu-west-2 (Netherlands) Follower: us-central-1 (Iowa)
- Index settings: 3P/1R
- Rally tracks: geopoint / http_logs / pmc. Index settings (unless specifically changed): 3P/1R
- OS: Ubuntu 16.04
4.4.0-1061-aws - Java version (unless specifically changed):
OpenJDK 8 1.8.0_191
- metricbeat from each node (metricbeat enabled everywhere)
- recovery-stats (from
_recovery) every 1s - from some experiments: node-stats only for jvm/mem to provide heap usage and gc insights
- median indexing throughput and the usual results Rally provides in the summary
Criteria to compare runs:
- time taken to follower to complete recovery
- indexing throughput
- overall system usage (CPU, IO, Network)
- remote tcp compression off vs on
- Telemetry device collection frequency
- "recovery-stats-sample-interval": 1
Tracks: geopoint, http_logs, pmc Challenge: new challenge (to be created) executing in the following order: 1. Delete and create indices on leader 2. Index entire corpora 8 indexing clients using max performance (no target-throoughput set) and then stop (don't index any more) 3. Join follower, start recovery 4. Consider benchmark over when follower has recovered completely
Tracks: geopoint, http_logs, pmc Challenge: new challenge (to be created) executing in the following order: 1. Delete and create indices on leader 2. Index entire corpora 8 indexing clients using max performance (no target-throoughput set) and then stop (don't index any more) 3. Join follower, start recovery 4. Consider benchmark over when follower has recovered completely
Experiment 3: AWS, fully index corpora, initiate recovery, keep indexing at lower performance during recovery, remote tcp compression off
Tracks: geopoint, http_logs, pmc Challenge: new challenge (to be created) executing in the following order: 1. Delete and create indices on leader 2. Index some % of corpora, 8 indexing clients max performance (no target-throughput set) 3. Join follower, start recovery and keep indexing on leader at a lower throughput 4. Consider benchmark over when follower has recovered completely
Tracks: geopoint, http_logs, pmc Challenge: new challenge (to be created) executing in the following order: 1. Delete and create indices on leader 2. Index some % of corpora, 8 indexing clients max performance (no target-throughput set) 3. Join follower, start recovery and keep indexing on leader at a lower throughput 4. Consider benchmark over when follower has recovered completely












Experiment 1 results
All experiments included:
ccr.indices.recovery.max_bytes_per_sec: 0Conclusions:
1MBchunk size, 5 max concurrent file chunks (using smart file chunk fetching) is a good general default when no tcp compression has been enabled.Detailed results per track below.
Geopoint
Indexed corpus with 3 shards, 1 replica:
1. Using non-configurable chunk_size: 64KB
Replcation took
3:59:44.900002. Using PR for configurable chunk size
Tried with 1MB chunk size and 5MB chunk size with 0 replicas.
Detailed results and graphs in the links above, in summary:
0:14:04.3680000:04:47.4060003. Using parallel recovery PR
Given the slowness of results in 1. and 2., it became evident the high latency (~100ms) requires parallelization of operations.
Used the PR defaults:
Results
Recovery from remote took:
0:01:13.300900http_logs
All benchmarks used 3 primary shards and 0 replicas and targeted the 6.7 Elasticsearch branch.
Indexed corpus:
Iteration 1: using commit
808db1fResults
Recovery from remote took:
0:05:53.016000Network usage:
JVM Heap usage:
GC Usage:
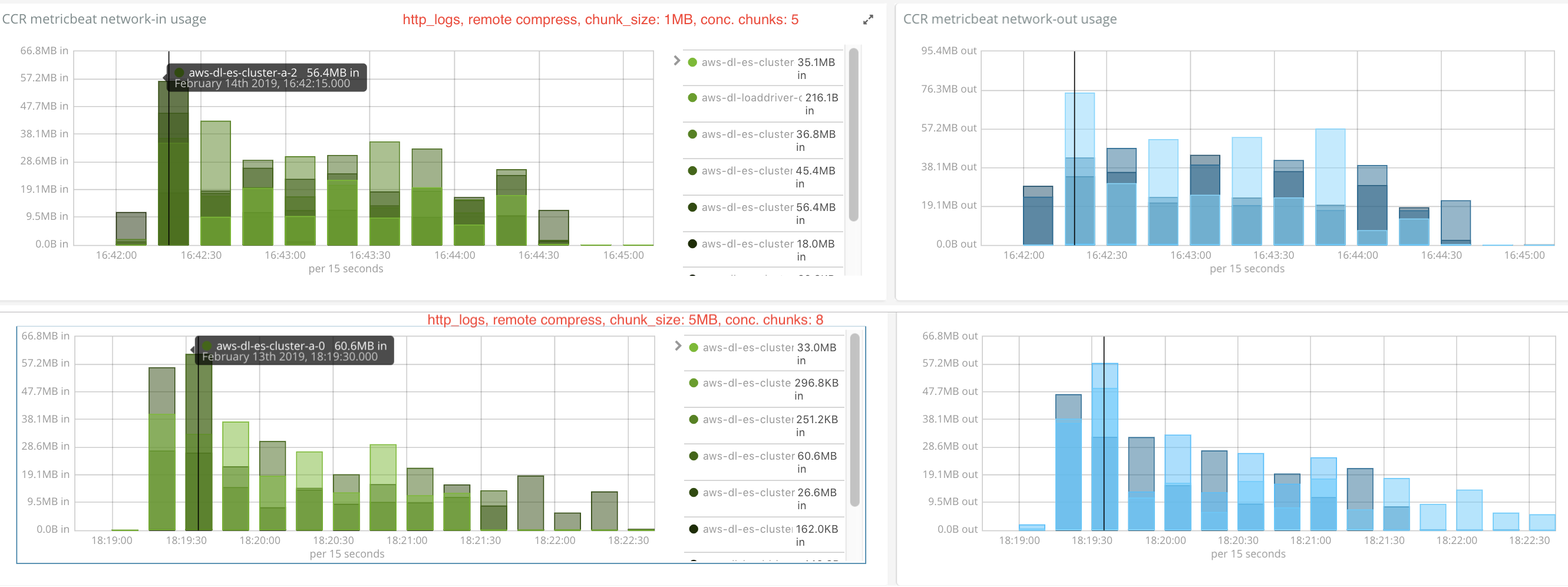
Iteration 2: same commit as iter. 1, double chunk size: 5MB
Results
Recovery from remote took:
0:05:12.449000(40seconds faster)Network usage comparison against 1MB chunk size:
Iteration 3: using commit
38416aaUsed the changes introduced in PR#38841 for smarter CCR concurrent file fetch.
Used defaults:
1MBchunk size,5max concurrent file chunksResults
Recovery from remote took:
0:03:05.924000,47.3%drop compared to iteration 1Network usage comparison against iteration 1:
Iteration 4: same commit as iter 3, higher defaults
Used:
5MBchunk size, default max concurrent file chunks: 5Recovery from remote took:
0:02:40.525000Network usage comparison against iteration 3:
Iteration 5: same commit as iter 3, higher defaults
Used:
1MBchunk size, increased max concurrent file chunks:10Recovery from remote took:
0:02:34.672000Network usage comparison against iteration 3:
Iteration 6: same commit as iter 3, even higher defaults
Used:
5MBchunk size, max concurrent file chunks:8Recovery from remote took:
0:03:38.003000Iteration 7: same commit and params as iteration 6, using java-11 with AVX enabled
Used:
5MBchunk size, max concurrent file chunks:8Recovery from remote took:
0:02:36.914000