-
-
Save elico/492d8f75f584ec1bed98b2a054a02cbb to your computer and use it in GitHub Desktop.
| #!/usr/bin/env bash | |
| DEST_NET="192.168.111.0/24" | |
| NEXT_HOPS="2" | |
| NEXT_HOP_1="192.168.126.202" | |
| NEXT_HOP_2="192.168.126.203" | |
| NEXT_HOP_1_TABLE="202" | |
| NEXT_HOP_2_TABLE="203" | |
| NFTABLES="/usr/sbin/nft" | |
| IPTABLES="/sbin/iptables" | |
| IP="/sbin/ip" | |
| LAN="eth0" | |
| WAN="eth1" | |
| ## Disabling Reverse path filter | |
| for i in /proc/sys/net/ipv4/conf/*/rp_filter | |
| do | |
| echo $i | |
| cat $i | |
| echo 0 > $i | |
| done | |
| DTABLE="${NEXT_HOP_1_TABLE}" | |
| $IP route del ${DEST_NET} | |
| $IP route flush table ${DTABLE} | |
| $IP route show | grep -Ev '^default' \ | |
| | while read ROUTE ; do | |
| $IP route add table ${DTABLE} ${ROUTE} | |
| done | |
| $IP route add default via ${NEXT_HOP_1} table ${DTABLE} | |
| DTABLE="${NEXT_HOP_2_TABLE}" | |
| $IP route flush table ${DTABLE} | |
| $IP route show | grep -Ev "^default" \ | |
| | while read ROUTE ; do | |
| $IP route add table ${DTABLE} ${ROUTE} | |
| done | |
| $IP route add default via ${NEXT_HOP_2} table ${DTABLE} | |
| $IP route add ${DEST_NET} via ${NEXT_HOP_1} | |
| #NAT | |
| ${NFTABLES} add table nat | |
| ${NFTABLES} add chain ip nat postrouting '{ type nat hook postrouting priority 100; policy accept; }' | |
| ${NFTABLES} add rule nat postrouting oif ${WAN} masquerade | |
| # MANGLE | |
| ${NFTABLES} add table mangle | |
| ${NFTABLES} add chain ip mangle prerouting '{ type filter hook prerouting priority -150; policy accept; }' | |
| ${NFTABLES} add chain ip mangle input '{ type filter hook input priority -150; policy accept; }' | |
| ${NFTABLES} add chain ip mangle forward '{ type filter hook forward priority -150; policy accept; }' | |
| ${NFTABLES} add chain ip mangle output '{ type route hook output priority -150; policy accept; }' | |
| ${NFTABLES} add chain ip mangle postrouting '{ type filter hook postrouting priority -150; policy accept; }' | |
| ${NFTABLES} add chain ip mangle wan1 | |
| ${NFTABLES} add rule ip mangle wan1 counter ct mark set 0x1 | |
| ${NFTABLES} add chain ip mangle wan2 | |
| ${NFTABLES} add rule ip mangle wan2 counter ct mark set 0x2 | |
| # 5-tuple/flow/PCC LOAD Balance | |
| ${NFTABLES} add chain ip mangle PCC_OUT_TCP | |
| ${NFTABLES} add rule ip mangle PCC_OUT_TCP counter jhash ip saddr . tcp sport . ip daddr . tcp dport mod 2 vmap { 0 : jump wan1, 1 : jump wan2 } | |
| ${NFTABLES} add chain ip mangle PCC_OUT_UDP | |
| ${NFTABLES} add rule ip mangle PCC_OUT_UDP counter jhash ip saddr . udp sport . ip daddr . udp dport mod 2 vmap { 0 : jump wan1, 1 : jump wan2 } | |
| ${NFTABLES} add chain ip mangle PCC_OUT_OTHERS | |
| ${NFTABLES} add rule ip mangle PCC_OUT_OTHERS counter ip protocol { tcp, udp } return | |
| ${NFTABLES} add rule ip mangle PCC_OUT_OTHERS counter jhash ip saddr . ip daddr mod 2 vmap { 0 : jump wan1, 1 : jump wan2 } | |
| ${NFTABLES} add rule ip mangle prerouting counter meta mark set ct mark | |
| ${NFTABLES} add rule ip mangle prerouting ct mark != 0x0 counter ct mark set mark | |
| ${NFTABLES} add rule ip mangle prerouting iifname "${LAN}" ip protocol tcp ct state new counter jump PCC_OUT_TCP | |
| ${NFTABLES} add rule ip mangle prerouting iifname "${LAN}" ip protocol udp ct state new counter jump PCC_OUT_UDP | |
| ${NFTABLES} add rule ip mangle prerouting iifname "${LAN}" ct state new counter jump PCC_OUT_OTHERS | |
| ${NFTABLES} add rule ip mangle prerouting ct mark 0x1 counter meta mark set 0x1 | |
| ${NFTABLES} add rule ip mangle prerouting ct mark 0x2 counter meta mark set 0x2 | |
| ${NFTABLES} add rule ip mangle postrouting counter ct mark set mark | |
| $IP rule|grep "from all fwmark 0x1 lookup ${NEXT_HOP_1_TABLE}" >/dev/null | |
| if [ "$?" -eq "1" ]; then | |
| $IP rule add fwmark 1 table ${NEXT_HOP_1_TABLE} | |
| fi | |
| $IP rule|grep "from all fwmark 0x2 lookup ${NEXT_HOP_2_TABLE}" >/dev/null | |
| if [ "$?" -eq "1" ]; then | |
| $IP rule add fwmark 2 table ${NEXT_HOP_2_TABLE} | |
| fi |
Hey @cyayon,
I am trying to understand what are your rules compared to mine?
These example rules were converted from a similar iptables ruleset.
In any case of ROUTING based LB the packet itself should never be changed or "mangled".
And when thinking about it, really routing is a calculated "mangling" in the lower levels of the packets ie L2(Mac address).
I am using Connection Tracking for "flow" routing consistency.
Let me try to think how to calculate a route verbally for a packet: new connection on interface $LAN from 192.168.125.100 to 8.8.8.8
For the LB logic to be applied the kernel(we) need to know the source and destination to apply our desired and proper route.
any mark ie CT or Route is only on the router\switch runtime code and memory.
Technically there shouldn't be any change to on-the-wire packet what so ever else then the L2 mac address and(with) proper Ingress/Egress interfaces.
My ruleset only writes the "first" calculated CT meta mark into the CT table.
(the kernel itself assigns to all packets by default CT mark 0 and will only write different marks if exist)
So the first SYN packet on $LAN will be marked for let say meta 0x1 in the prerouting.
Then the routing decision will be done inside the "forward" part of the kernel.
When the packet is at the postrouting hook the first decision was used, however this mark would be "gone" after the packet is out of the postrouting hooks and is on the egress interface.
So for simplification I am using equal marks on both the CT and the packet routing meta mark and making sure on the postrouting hook that the mark is saved per CT connection.
Asking out loud: How would you mark a connection consistently in the packet level?
What I mean is, You must have some degree/definition of "connection" in a linux router.
I am not sure if the scenario is know or not but the generic scenario would be that the next hops are doing NAT on their out/egress interface.
I assume that in an automated system you would be able to change the relevant packet or CT marks and routing rules and tables so..
Maybe the only real thing in a real world ruleset would be performance wise, What do you think?
Reference diagram page: http://linux-ip.net/pages/diagrams.html#netfilter-kernel-packet-traversal
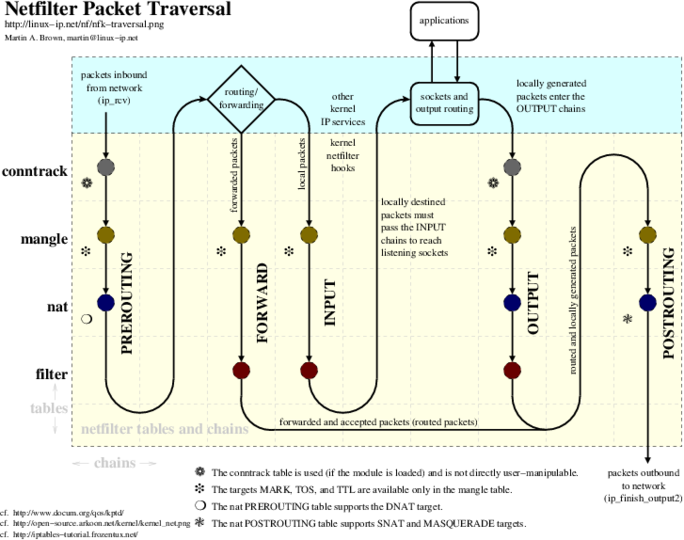
Hi,
Thanks for your answer and explanation. I agree.
Here is my nftables mangle and ip routes / rules. I have 8 wan interfaces, and i copy/paste for only 3 wan interfaces.
What do you think about that ?
`
table ip mangle {
chain PREROUTING {
type filter hook prerouting priority mangle; policy accept;
iifname <wan1> ct state new counter packets 4 bytes 220 jump MWAN1 comment "mwan1"
iifname <wan2> ct state new counter packets 2 bytes 92 jump MWAN2 comment "mwan2"
iifname <wan3> ct state new counter packets 2 bytes 92 jump MWAN3 comment "mwan3"
ct state new counter packets 203 bytes 10454 jump MWAN
ct mark != 0x00000000 counter packets 306 bytes 57663 meta mark set ct mark
}
chain INPUT {
type filter hook input priority mangle; policy accept;
}
chain FORWARD {
type filter hook forward priority mangle; policy accept;
}
chain OUTPUT {
type route hook output priority mangle; policy accept;
# some specific stuff to force dhclient process and its RENEW
udp sport 68 udp dport 67 meta skgid 100100 counter packets 0 bytes 0 jump MWAN1_SL comment "mwan1_dhcpc_skgid"
udp sport 68 udp dport 67 meta skgid 200200 counter packets 0 bytes 0 jump MWAN2_SL comment "mwan2_dhcpc_skgid"
udp sport 68 udp dport 67 meta skgid 200200 counter packets 0 bytes 0 jump MWAN3_SL comment "mwan3_dhcpc_skgid"
}
chain POSTROUTING {
type filter hook postrouting priority mangle; policy accept;
counter packets 834 bytes 102933 ct mark set meta mark
}
chain MWAN {
ip daddr { 10.0.0.0/8, 127.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 224.0.0.0-255.255.255.255 } counter packets 196 bytes 10034 return
counter packets 7 bytes 420 ct mark != 0x00000000 return
counter packets 1 bytes 108 ct state established,related return
ip protocol { tcp, udp } numgen random mod 100 < 40 counter packets 1 bytes 108 jump MWAN1 comment "mwan1_default"
ip protocol { tcp, udp } numgen random mod 100 < 0 counter packets 0 bytes 0 jump MWAN3 comment "mwan3_default"
ct mark 0x00000000 counter packets 0 bytes 0 jump MWAN2 comment "mwan2_default"
tcp dport { 80, 443 } counter packets 0 bytes 0 jump MWAN3 comment "mwanlb_http"
tcp dport { 80, 443 } numgen random mod 100 < 40 counter packets 0 bytes 0 jump MWAN1 comment "mwanlb_http"
tcp dport { 80, 443 } numgen random mod 100 < 30 counter packets 0 bytes 0 jump MWAN2 comment "mwanlb_http"
<some stuff below>
}
chain MWAN1 {
counter packets 5 bytes 328 ct mark set 0x00000100
}
chain MWAN2 {
counter packets 2 bytes 92 ct mark set 0x00000200
}
chain MWAN3 {
counter packets 0 bytes 0 ct mark set 0x00000300
}
chain MWAN1_SL {
counter packets 0 bytes 0 meta mark set 0x00000100
}
chain MWAN2_SL {
counter packets 0 bytes 0 meta mark set 0x00000200
}
chain MWAN3_SL {
counter packets 0 bytes 0 meta mark set 0x00000300
}
}
ip rule show
0: from all lookup local
100: from all fwmark 0x100 lookup 100
200: from all fwmark 0x200 lookup 200
300: from all fwmark 0x300 lookup 300
1100: from <ip_wan1> lookup 100
1200: from <ip_wan2> lookup 200
1300: from <ip_wan3> lookup 300
32766: from all lookup main
32767: from all lookup default
ip route show table 100
default via <gw_wan1> dev
<subnet_wan1> dev proto kernel scope link src <ip_wan1>
<subnet_wan2> dev proto kernel scope link src <ip_wan2>
<subnet_wan3> dev proto kernel scope link src <ip_wan3>
ip route show table 200
default via <gw_wan2> dev
<subnet_wan1> dev proto kernel scope link src <ip_wan1>
<subnet_wan2> dev proto kernel scope link src <ip_wan2>
<subnet_wan3> dev proto kernel scope link src <ip_wan3>
ip route show table 300
default via <gw_wan3> dev
<subnet_wan1> dev proto kernel scope link src <ip_wan1>
<subnet_wan2> dev proto kernel scope link src <ip_wan2>
<subnet_wan3> dev proto kernel scope link src <ip_wan3>
`
thanks
@cyayon Your rules are great.
The iifname <wan1> ct state new counter packets 4 bytes 220 jump MWAN1 comment "mwan1" is a great rule.
It is useful when the LB box doesn't do NAT and the setup requires direct routing to the LAN from the WAN routers.
This is actually how I would have implemented a WAN LB, ie without NAT on the LB towards the WAN Routers.
In MWAN I think that there are rules which will probably won't hit:
tcp dport { 80, 443 } counter packets 0 bytes 0 jump MWAN3 comment "mwanlb_http"
tcp dport { 80, 443 } numgen random mod 100 < 40 counter packets 0 bytes 0 jump MWAN1 comment "mwanlb_http"
tcp dport { 80, 443 } numgen random mod 100 < 30 counter packets 0 bytes 0 jump MWAN2 comment "mwanlb_http"
since the earlier rules:
ip protocol { tcp, udp } numgen random mod 100 < 40 counter packets 1 bytes 108 jump MWAN1 comment "mwan1_default"
ip protocol { tcp, udp } numgen random mod 100 < 0 counter packets 0 bytes 0 jump MWAN3 comment "mwan3_default"
ct mark 0x00000000 counter packets 0 bytes 0 jump MWAN2 comment "mwan2_default"
Includes the same targets, ie ip protocol { tcp, udp } includes ports 0-65535 in them so tcp dport { 80, 443 } will never hit.
Also there is one possible "improvement you might be able to do with the numgen and jumps using a vmap.
something like: counter ip protocol { tcp, udp } numgen random mod 100 vmap { 0-50: jump MWAN1 , 51-100: jump MWAN2 }
Take a look at this automated MWAN flow based balancing code:
https://github.com/elico/mwan-nft-lb-example
This is from a lab on a machine that has 24 interfaces.(ether0-ether23)
https://github.com/elico/mwan-nft-lb-example/blob/main/nftables-lb-wan.rb
Output of nftables rules and ip route tables and rules:
https://github.com/elico/mwan-nft-lb-example/blob/main/rt-tables-output.txt
https://github.com/elico/mwan-nft-lb-example/blob/main/nftables-rules-dump-putput.txt
The idea of PCC\flow hash which I am using in my rules is to spread all connections on as many WAN connections as possible.
Not all Internet services likes this idea since it's possible that a single browser will reach the same service from different SRC ip addresses.
It is expected that the same 5-tuple(srcip+sport+dstip+dport+protocol) will always be routed via the same WAN router\gw.
It is possible to tweak this logic a bit so to some degree the same client(srcip) and service(dstip+dstport) will always be routed via the same WAN router\gw which will reduce the chance of specific services to reject clients sessions based on their srcip fast change/shifting.
Hi,
Thanks for your comments !
I have some questions about your rules.
Why do you put "meta mark set ct mark" and "ct mark != 0x0 counter ct mark set mark" in the begining of prerouting ? In my case i put them on the end.
The first pool of rules (mwanX_default) load-balance packets for tcp/udp (all ports).
The goal of second pool of rules are dedicated to (mwanlb_http) load-balance differently packets for http/s only.
The MWANX chains mark all packets (including already marked packet by any previous rule), because i use : ct mark set 0xXXX (and not : ct state new mark set 0xXXX). I am wrong ?
I would like to load-balance http/s differently than others protocols.
I will study vmap instead of numgen. Do you think it's more optimized ?
The problem for vmap in my specific case, it's that i have a small daemon in the background which monitor each link/interface and update on the fly my route tables and nft rules.
For example if the WAN1 go down, my daemon will update default route table, remove all static routes with WAN1, and finally remove all MWAN1 nft rules. If I use vmap, i think my monitoring script will be more complicated...
Your links are very interesting, i will have a look. There isn't lot of available documentation about nft wan load-balancing...
I had issues with some websites (pcloud for example) which don't like to have requests from differents IP sources. For those site (ip destination), i have some rules to force the wan interface. It is not clean and i will have a lookup for your n-tuple algo, but in this case, there will be no load-balancing ?
@cyayon Hi,
Thanks, Due to your questions I had to think this script to find out if there is a better way to implement this ruleset or another.
So I have updated the example repository at: https://github.com/elico/mwan-nft-lb-example
The reason I am using meta mark set ct mark and ct mark != 0x0 counter ct mark set mark is for a counter.
The real one that we need at the beginning is only the:
ct mark != 0x0 counter ct mark set mark
For the marking to work persistently we need to first create a CT mark, then stamp a mark on the packet so it would be routed properly.
However we don't want to do this LB again from 0, on the postrouting we save the mark into the CT table.
The above was for the first packet of a "connection" ie in the new state. So let say a three way handshake in nft should be like this:
lan client(syn) -> [prerouting -> Calculate LB mark and save in CT -> write LB mark from CT to packet ] -> routing By the packet FW mark -> [ postrouting -> Save the CT mark into the CT table ] -> wan GW ->(cloud) -> server
server(syn-ack) -> (cloud) -> wan GW -> [prerouting -> Restore the saved mark from CT -> write LB mark from CT to packet ] -> routing By the packet FW mark - >[ postrouting -> Save the CT mark into the CT table ] -> lan client
lan client(ack) -> [prerouting -> Restore the saved mark from CT -> write LB mark from CT to packet ] -> routing By the packet FW mark -> [ postrouting -> Save the CT mark into the CT table ] -> wan GW ->(cloud) -> server
The restore mark should be the first rule in the prerouting or else the connection mark will not be attached to the packet.
In your ruleset you are using:
ip daddr { 10.0.0.0/8, 127.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 224.0.0.0-255.255.255.255 } counter packets 196 bytes 10034 return
counter packets 7 bytes 420 ct mark != 0x00000000 return
counter packets 1 bytes 108 ct state established,related return
Which might be good enough in many scenarios to avoid remarking etc.
I don't know why the counters for the counter packets 1 bytes 108 ct state established,related return in the MWAN is in 1 exactly but never mind this.
Let me walk throw the MWAN rules and see
1 ip daddr { 10.0.0.0/8, 127.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 224.0.0.0-255.255.255.255 } counter packets 196 bytes 10034 return
2 counter packets 7 bytes 420 ct mark != 0x00000000 return
3 counter packets 1 bytes 108 ct state established,related return
4 ip protocol { tcp, udp } numgen random mod 100 < 40 counter packets 1 bytes 108 jump MWAN1 comment "mwan1_default"
5 ip protocol { tcp, udp } numgen random mod 100 < 0 counter packets 0 bytes 0 jump MWAN3 comment "mwan3_default"
6 ct mark 0x00000000 counter packets 0 bytes 0 jump MWAN2 comment "mwan2_default"
7 tcp dport { 80, 443 } counter packets 0 bytes 0 jump MWAN3 comment "mwanlb_http"
8 tcp dport { 80, 443 } numgen random mod 100 < 40 counter packets 0 bytes 0 jump MWAN1 comment "mwanlb_http"
9 tcp dport { 80, 443 } numgen random mod 100 < 30 counter packets 0 bytes 0 jump MWAN2 comment "mwanlb_http"
let say to port 22 and port 80
new connection to port 22 will hit { 4 or 5 or 6 }
new connection to port 80 will hit { 4 or 5 or 6 or 7 or 8 or 9 }
The last hit..
I believe the vmap solution is the best since it guarantees a hit without any misses.
Another good thing would be that in a case of a link down you only need to replace one thing, the vmap content.
You can leave the routing mark rules and tables as is but change the vmap to use only the links/gw which are in UP state.
I don't know what daemon you have but you can simplify it like this:
Run a ping\else monitoring daemon per GW\interface, every deamon will have a "state" file like:
/var/run/wan_monitor/up/{wan1,wan2,wan3..}
if the wan interface is down then remove the state file, if it's up touch the file.
and a simple text file at:
/var/run/wan_monitor/status
The main daemon will do something like this in any language you want:
#!/usr/bin/env bash
WAN_STATE_FILE="/var/run/wan_monitor/status"
touch "${WAN_STATE_FILE}"
# initialize nftables with vmap with ${CURRENT_WAN_STATE}
# in my case: ruby nftables-lb-wan.rb
while true; do
LAST_WAN_STATE=$(cat ${WAN_STATE_FILE} |xargs)
CURRENT_WAN_STATE=$(ls /var/run/wan_monitor/up/ |xargs)
if [ "${LAST_WAN_STATE}" == "${CURRENT_WAN_STATE}" ];then
echo "No Change"
sleep 1
else
echo "Changed from: \"${LAST_WAN_STATE}\" => \"${CURRENT_WAN_STATE}\""
# regenerate vmap with ${CURRENT_WAN_STATE}
# in my case: ruby nftables-lb-wan.rb
echo "${CURRENT_WAN_STATE}" > "${WAN_STATE_FILE}"
fi
donefor sites/systems like pcloud which requires the same srcip you would probably want to balance with a:
srcip+dstip or srcip+dstip+port
It will balance out connections however only to the same exact destination.
For example 8.8.8.8 and 8.8.4.4 and 1.1.1.1 will probably be balanced across 3 wan connections for the same client.
However it's possible that a VOD service has a multiple subnets and their redirector and auth service is on x.1.z.1 while the streaming service is on x.2.y.1.
The vod auth service knows about the client ip of wan1 and when the client access x.2.y.1 it will be routed via wan2 or up.
The auth token to the streaming service contains information on the client IP of wan1 and might block access since the request is from wan2.
For regular users persistence wan out-band interface for 30 minutes per client srcip is acceptable.
There are other techniques to LB and I cannot answer since it requires actual sys/net admin hours and I cannot just give them freely.. food.. car.. apartment etc.
Anyway my email and mobile are available publicly: ngtech1ltd@gmail.com , +972-5-28704261
Hi,
thanks for your answer.
Could you please update your nftables-rules-dump-putput.txt with your last rule set ? I think you have only updated you .rb script... Does your final rule set change ?
I have some services on firewall/router itself (openvpn for example), and i have to begin my mangle / OUTPUT chain with : "ct mark != 0x0 counter meta mark set ct mark" to allow this services to work as expected.
My complete mangle / OUTPUT chain is :
chain OUTPUT {
type route hook output priority mangle; policy accept;
# necessary for local services (ovpn)
ct mark != 0x0 counter meta mark set ct mark
# force reroute-check DHCPC RENEW skgid process via its own iface
udp sport 68 udp dport 67 meta skgid $skgid_wan1 counter jump MWAN1_SL comment "mwan1_dhcpc_skgid"
udp sport 68 udp dport 67 meta skgid $skgid_wan2 counter jump MWAN2_SL comment "mwan2_dhcpc_skgid"
#udp sport 68 udp dport 67 meta skgid $skgid_wan3 counter jump MWAN3_SL comment "mwan3_dhcpc_skgid"
}
Moreover, if i don't have "ct mark != 0x0 counter meta mark set ct mark" at the END of mangle / PREROUTING, the packets from internet clients to router/firewall itself services (openvpn), are NOT marked as expected (but it works). I think it is not clean... Finally, my complete mangle / PREROUTING is :
chain PREROUTING {
type filter hook prerouting priority mangle; policy accept;
iifname $iface_wan1 ct state new counter jump MWAN1 comment "mwan1_orange1"
iifname $iface_wan2 ct state new counter jump MWAN2 comment "mwan2_orange2"
iifname $iface_wan3 ct state new counter jump MWAN3 comment "mwan3_lte"
iifname $iface_beta ct state new counter jump MWAN5 comment "mwan5_beta"
iifname $iface_vanisher1 ct state new counter jump MWAN6 comment "mwan6_vanisher_orange1"
iifname $iface_vanisher2 ct state new counter jump MWAN7 comment "mwan7_vanisher_orange2"
iifname $iface_vanisher3 ct state new counter jump MWAN9 comment "mwan9_vanisher_lte"
ct state new counter jump MWAN
ct mark != 0x0 counter meta mark set ct mark
}
I do not understand why is required to begin mangle / PREROUTING with "ct mark != 0x0 counter ct mark set mark"...
Finally, i have a very (too much) complicated daemon script to monitor nft tables, i will simplify and refactor it following your recommendations :)
Do you prefer to continue this on your email ?
thanks.
@cyayon it's up to you if email or not.
I will try later to upgrade the nftables-rules-dump-putput.txt in the repo.
Since netfilter(nftables/iptables) have jumps and goto you can partition the tables and update only specific parts of it using a nft script.
Since nftables nft does atomic changes(compared to iptables which is not) you are guaranteed that once you change a vmap or another part it will not affect traffic and will not cause distribution of service.
I don't know how you check or how you do things and feel free to share more if you would like on email.
The main difference can be seen at:
elico/mwan-nft-lb-example@22e6eb2#diff-68054fdcdf4d0108a2b62e83360a742fb3b8334f4bb93b6f285ca27403eca11a
For a simple ruleset with 10-50 +- commands you can use a single nft add rule or any similar single command action.
But when you have 150 commands it takes a lot of time to run and is also prune to time race conditions.
With 1000+ nft commans you must use a nft script to be performance wise.
Comparing the 100 rules/commands to 1.2 k commands which I used, it took more then 30 seconds compared to 1-2 seconds inside a nft script.
Be in touch!
thanks.
@cyayon I updated the rules.
Take a peek at:
https://github.com/elico/mwan-nft-lb-example/blob/main/run-lab.sh
It creates a full lab in Linux Namespaces.
You might need to tune the code a bit to make it work on you environment.
The scripts create multiple routers and a client that simulates a network with 10 GWs.
thanks !
Hello,
why do you use : ${NFTABLES} add rule ip mangle postrouting counter ct mark set mark
instead of ${NFTABLES} add rule ip mangle postrouting ct mark != 0x00000000 counter meta mark set ct mark
your rule store / restore marking in the conntrack and my rule store in the packet itself.
In your opinion, which one is better ?
thanks