-
-
Save erogol/97516ad65b44dbddb8cd694953187c5b to your computer and use it in GitHub Desktop.
It seems to run if you replace the second to last cell:
# load the default config file and update with the local paths and settings. import json from TTS.utils.io import load_config CONFIG = load_config('/content/TTS/TTS/tts/configs/config.json') CONFIG['datasets'][0]['path'] = '../LJSpeech-1.1/' # set the target dataset to the LJSpeech CONFIG['audio']['stats_path'] = None # do not use mean and variance stats to normalizat spectrograms. Mean and variance stats need to be computed separately. CONFIG['output_path'] = '../' with open('config.json', 'w') as fp: json.dump(CONFIG, fp)
With:
!python /content/TTS/TTS/bin/compute_statistics.py /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json /content/TTS/scale_stats.npy --data_path /content/LJSpeech-1.1/wavs/
And replace the last cell:
# pull the trigger !CUDA_VISIBLE_DEVICES="0" python TTS/bin/train_tacotron.py --config_path config.json | tee training.log
With:
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path /content/LJSpeech-1.1/ \ --coqpit.audio.stats_path /content/TTS/scale_stats.npy \The first line seems fine, but when I run the second line something goes wrong, I have get the following error message
Using CUDA: True
Number of GPUs: 1
Mixed precision mode is ON
fatal: not a git repository (or any of the parent directories): .git
Git Hash: 0000000
Experiment folder: DEFINE THIS/ljspeech-ddc-June-20-2021_02+22PM-0000000
fatal: not a git repository (or any of the parent directories): .git
Traceback (most recent call last):
File "/content/TTS/TTS/bin/train_tacotron.py", line 737, in
args, config, OUT_PATH, AUDIO_PATH, c_logger, tb_logger = init_training(sys.argv)
File "/content/TTS/TTS/utils/arguments.py", line 182, in init_training
config, OUT_PATH, AUDIO_PATH, c_logger, tb_logger = process_args(args)
File "/content/TTS/TTS/utils/arguments.py", line 168, in process_args
copy_model_files(config, experiment_path, new_fields)
File "/content/TTS/TTS/utils/io.py", line 42, in copy_model_files
copy_stats_path,
File "/usr/lib/python3.7/shutil.py", line 120, in copyfile
with open(src, 'rb') as fsrc:
FileNotFoundError: [Errno 2] No such file or directory: 'scale_stats.npy'But the file exists in the directory, how should I solve this problem?
Replace
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path /content/LJSpeech-1.1/ \ --coqpit.audio.stats_path /content/TTS/scale_stats.npy \
with
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path ./content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path ./content/LJSpeech-1.1/ \ --coqpit.audio.stats_path ./content/TTS/scale_stats.npy \
@gbvssd
It seems to run if you replace the second to last cell:
# load the default config file and update with the local paths and settings. import json from TTS.utils.io import load_config CONFIG = load_config('/content/TTS/TTS/tts/configs/config.json') CONFIG['datasets'][0]['path'] = '../LJSpeech-1.1/' # set the target dataset to the LJSpeech CONFIG['audio']['stats_path'] = None # do not use mean and variance stats to normalizat spectrograms. Mean and variance stats need to be computed separately. CONFIG['output_path'] = '../' with open('config.json', 'w') as fp: json.dump(CONFIG, fp)
With:
!python /content/TTS/TTS/bin/compute_statistics.py /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json /content/TTS/scale_stats.npy --data_path /content/LJSpeech-1.1/wavs/
And replace the last cell:
# pull the trigger !CUDA_VISIBLE_DEVICES="0" python TTS/bin/train_tacotron.py --config_path config.json | tee training.log
With:
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path /content/LJSpeech-1.1/ \ --coqpit.audio.stats_path /content/TTS/scale_stats.npy \The first line seems fine, but when I run the second line something goes wrong, I have get the following error message
Using CUDA: True
Number of GPUs: 1
Mixed precision mode is ON
fatal: not a git repository (or any of the parent directories): .git
Git Hash: 0000000
Experiment folder: DEFINE THIS/ljspeech-ddc-June-20-2021_02+22PM-0000000
fatal: not a git repository (or any of the parent directories): .git
Traceback (most recent call last):
File "/content/TTS/TTS/bin/train_tacotron.py", line 737, in
args, config, OUT_PATH, AUDIO_PATH, c_logger, tb_logger = init_training(sys.argv)
File "/content/TTS/TTS/utils/arguments.py", line 182, in init_training
config, OUT_PATH, AUDIO_PATH, c_logger, tb_logger = process_args(args)
File "/content/TTS/TTS/utils/arguments.py", line 168, in process_args
copy_model_files(config, experiment_path, new_fields)
File "/content/TTS/TTS/utils/io.py", line 42, in copy_model_files
copy_stats_path,
File "/usr/lib/python3.7/shutil.py", line 120, in copyfile
with open(src, 'rb') as fsrc:
FileNotFoundError: [Errno 2] No such file or directory: 'scale_stats.npy'But the file exists in the directory, how should I solve this problem?
Replace
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path /content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path /content/LJSpeech-1.1/ \ --coqpit.audio.stats_path /content/TTS/scale_stats.npy \
with
!CUDA_VISIBLE_DEVICES="0" python /content/TTS/TTS/bin/train_tacotron.py --config_path ./content/TTS/recipes/ljspeech/tacotron2-DDC/tacotron2-DDC.json \ --coqpit.output_path ./Results \ --coqpit.datasets.0.path ./content/LJSpeech-1.1/ \ --coqpit.audio.stats_path ./content/TTS/scale_stats.npy \@gbvssd
I have tried the above command line but it does not work either. I think it is not the file path problem, but more like some argument parsing problem, that the audio.stats_path do not parsing correctly, because in the code the attribute "config.audio.stats_path" is "scale_stats.npy" not the "/content/TTS/scale_stats.npy ".
I have tried the above command line but it does not work either. I think it is not the file path problem, but more like some argument parsing problem, that the audio.stats_path do not parsing correctly, because in the code the attribute "config.audio.stats_path" is "scale_stats.npy" not the "/content/TTS/scale_stats.npy ".
Sorrry, I missed that. You can double check if this "/content/TTS/scale_stats.npy exists or not if if doesn't. Don't use config.audio.stats_path aurguments.
@gbvssd
The file scale_stats.npy exists and the file path is correct. Is the -- coqpit.addio.stats_path argument set the state file path? And I track the error to the "utils/io.py" file and test the value of "config.audio.stats_path", I assume it should be "/content/TTS/scale_stats.npy " but it is "scale_stats.npy".
@Sadam1195
The file scale_stats.npy exists and the file path is correct. Is the
-- coqpit.addio.stats_pathargument set the state file path? And I track the error to the "utils/io.py" file and test the value of "config.audio.stats_path", I assume it should be "/content/TTS/scale_stats.npy " but it is "scale_stats.npy".
then may be you are not using the right version of repo. Let's get in touch on discussion or gitter as this conversation will spam the gist.
@gbvssd
Hello guys , I have some errors can anyone guide me to solve this
First Try:

Second Try:

Third Try :
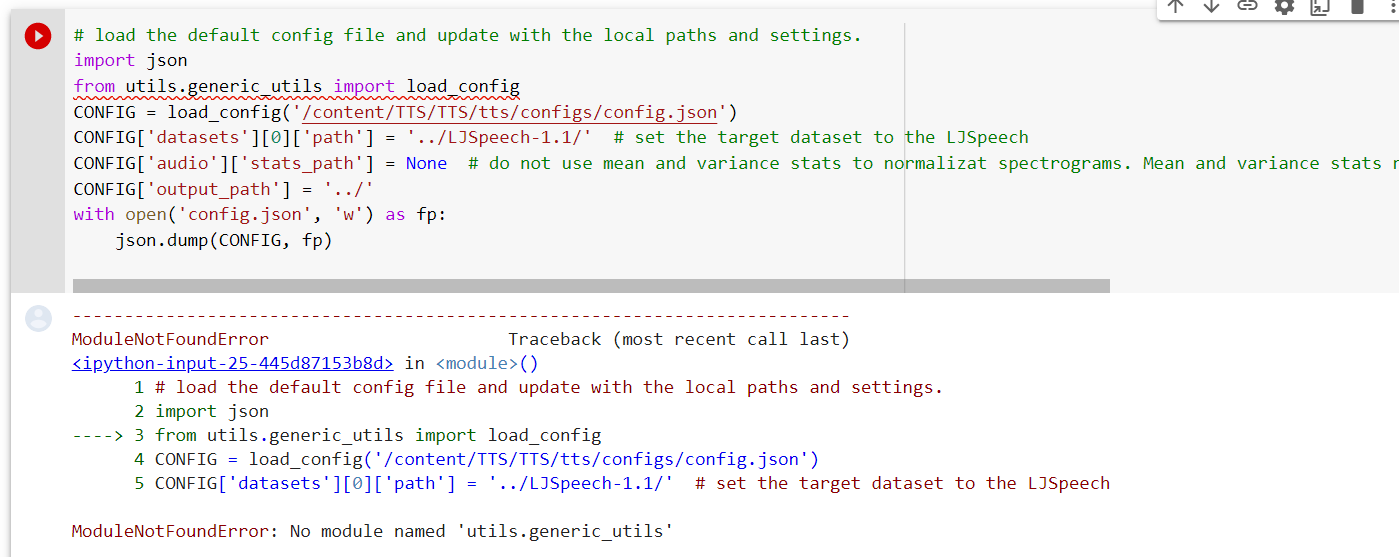
What should I do Now ?
Thanks in Advance
all the community members
Anyone figure this out yet?
Anyone figure this out yet?
I encountered the same issue, instead of !git clone https://github.com/coqui-ai/TTS do this !git clone https://github.com/mozilla/TTS although you can make the json file, you still gonna have another problem.
Updated the notebook based on the latest version of 🐸TTS
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
I am receiving such an error:
File "train.py", line 13, in <module> from TTS.datasets.TTSDataset import MyDataset ModuleNotFoundError: No module named 'TTS'Where I might be doing a mistake?
I am in TTS project directory, LJSpeech is in subfile in that directory
run it again it will be ok
training worked fine after replacing the name= argument to BaseDatasetConfig with formatter=:
--- a/tts_example.ipynb
+++ b/tts_example_new.ipynb
@@ -139,7 +139,7 @@
"\n",
"# init configs\n",
"dataset_config = BaseDatasetConfig(\n",
- " name=\"ljspeech\", meta_file_train=\"metadata.csv\", path=os.path.join(output_path, \"/content/LJSpeech-1.1\")\n",
+ " formatter=\"ljspeech\", meta_file_train=\"metadata.csv\", path=os.path.join(output_path, \"/content/LJSpeech-1.1\")\n",
")\n",
"\n",
"audio_config = BaseAudioConfig(\n",Seems like this notebook is creating train-val splits in metadata_train.csv and metadata_val.csv, but then they're not using in the dataset config. Shouldn't it be
dataset_config = BaseDatasetConfig(
formatter ="ljspeech", meta_file_train="metadata_train.csv", meta_file_val="metadata_val.csv", path=os.path.join(output_path, "/content/LJSpeech-1.1")
)When I try to install -e, it gives me an error:
import os
os.chdir('/content/coqui-TTS')
!pip install -e .[all]
I got those error:
Failed to build TTS
ERROR: Could not build wheels for TTS, which is required to install pyproject.toml-based projects
Can anyone help?
@ZeLiu1 The error "Failed to build TTS" and "ERROR: Could not build wheels for TTS" during the installation with -e (editable) option indicates missing dependencies or build requirements for the TTS package. Ensure all dependencies are installed, check Python version compatibility, and have necessary build tools. Consider using a virtual environment or building from the source repository to resolve the issue.
Hi all,
I have launched the google colab: TTS_example.ipynb
But when Train Tacotron DCA starts i get the follow issue:
TypeError Traceback (most recent call last)
in <cell line: 18>()
16
17 # init configs
---> 18 dataset_config = BaseDatasetConfig(
19 name="ljspeech", meta_file_train="metadata.csv", path=os.path.join(output_path, "/content/LJSpeech-1.1")
20 )
TypeError: BaseDatasetConfig.init() got an unexpected keyword argument 'name'
try installing Visual Studio Build Tools 2022 Microsoft C++ Build Tools and make sure you check the box for the "Desktop development with C++" Install option
Hi guys, I'm trying to run this notebook, but " from TTS.tts.datasets import load_tts_samples" - there are not any "load_tts_samples". Could someone give me a clue? Will be greatful...
The first line seems fine, but when I run the second line something goes wrong, I have get the following error message
But the file exists in the directory, how should I solve this problem?