This post originated from a number of discussions I have had in the last few months on how we run our cloud integration stack - Apache Camel deployed in the Google Kubernetes Engine. So I decided to summarise the thinking in one place, so I can reference it when needed.
The post will provide the outline over the Why and the How aspects of the implementation.
Apache Camel is a routing and mediation engine that can be considered a reference implementation for the majority of the Enterprise Integration Patterns defined by Gregor Hohpe and Bobby Woolf.
Being a top level Apache Project, it is well supported and comes with a generous Apache2.0 license, which is enterprise friendly.
It is easily extensible, provides a configuration DSL that conforms to the fluent interface principles as set by Martin Fowler and includes a gazillion of components and adapters.
For a more detailed review please check a very nice summary from Jonathan Anstey Open Source Integration with Apache Camel.
Why doing Containers and Kubernetes in the world where serverless computing is picking up steam?
As much as I like serverless architecture, the container based deployment is still perceived to be a bit more flexible. And this flexibility is quite important for the integration tasks, where requirements can be somewhat peculiar in terms of dependencies, latencies and execution times. As an example, the serverless deployments are not particularly friendly for the long running processes.
Docker containers, on the other hand, strike the balance between being stateless, being easily customisable and handling the unusual tasks rather well. And general adoption of Kubernetes as the emerging de-facto standard predefined the choice of the orchestrator.
Kubernetes is awesome - just follow a typical DevOps team for a day to see why.
Google Cloud Platform offers the easiest to use cloud Kuberenetes service. The new features are getting released there first. Fantastic support and great pricing make it one the best option from my perspective.
But GCP is not just about the Kubernetes. It is the whole plethora of the additional capabilities - Logging, Monitoring, Persistence, Pub/Sub, Analytics, etc - all these have been made easy to use for the developers.
Google offerings allow designs where the architect can just pick a set of the xPAAS capabilities and compose a business solution. Yet the infrastructure is operated by someone else and it is one of the cheaper options for the comparable performance, features and quality of support.
But is there a place for Apache Camel in the already rich Google Cloud Platform ecosystem? Is there a real need for its capabilities? Why not, for example, use Spark or Apache Beam? Both available as managed infrastructure - Dataproc and Dataflow respectively. Why not the latter one?
Indeed, Dataflow is a fantastic product. It is irreplaceable for the operations at scale where dynamic session calculations are a must and its pre integration with the rest of GCP technology is fantastic.
But let's consider simpler scenarios, where the focus is more on the message processing and orchestration, rather than the data handling, situations where there is only a few million exchanges a day to process, solutions where there is a number of the external systems need to be integrated. Dataflow would be coming as a tad too heavy and expensive.
The lowest deployment entity with Dataflow is a VM and there are at least three required per a job deployment. Half a dozen of Dataflow solutions would rake up a considerable cost overhead.
Plus there are not that many thrid party adaptors available for Dataflow as yet, so integrating would require effort and some custom, low level code.
That's where Camel on Kubernetes comes in shining. The lowest deployment entity is a container - multiple deployments would fit into a single VM, even with a handful of adapters and components configured.
The number of the Apache Camel components avalable out of the box make integration and orchestration tasks simple, and the Google ecosystem is enabled too - there are prepackaged adapters for Google PubSub and Bigquery.
So, from this perspective Apache Camel complements the GCP stack.
With Kubernetes being the de-facto standard for the containerised deployments, such setup can be replicated with Azure, AWS, IBM, RedHat, etc.
Combined with Kubernetes Cluster Federation it would also unlock the notion of a true Hybrid Integration Platform - a single control pane over many clusters.
But enough of the "Why?", let's get on with the "How?".
This section covers the configuration specifics that integrate Camel application into the Google Cloud Platform:
For details on the building and deploying the code referenced here please refer to GCP Project Setup, Toolstack and Build and Deploy sections of the project.
The blueprint presented here is based on a widely recognised Camel / Springboot combination that implements the following integration scenario:
- Camel consumes a message from Google PubSub subscription
- Transforms the data
- Updates the header to define the Bigquery table partition
- Writes to the Bigquery table

Every operation is recorded by Google Stackdriver Logging and operational metrics collected by Google Stackdriver Monitoring - both for JVM and Camel.
The solution Docker image is uploaded to the GCP Container Registry and deployed to the GCP Kubernetes Engine.
The source code for the demo is available in the GitHub Repository.
Out of the box Kubernetes provides two mechanisms to deliver configuration settings into the container: a configuration map or a secret. Once those have been defined within the cluster, their values can be made available to the applications either as files or as environmental variables.
The demo relies on Springboot Externalised Configuration options to ingest both types and that gives the flexibility to override them at any stage of CI/CD lifecycle.
The blueprint assumes that there are four places where a SpringBoot property can be configured:
- Springboot
application.properties. Values defined here can not be overridden. Generally used for Springboot configuration and hard, unchangeable standards. - Custom
default.properties. That's where usually the application specific defaults are defined by a developer. - Optional file pointed by the
${external.config}java property. The file is generally intended to be used by system administrators that would opt to use an external file instead of the environmental variables. - Environment variables defined through a Docker image or Kubernetes cluster, captured and converted into Java and Camel properties by Springboot.
Please note - the relationship between the last three is important.
Options 2 and 3 are explicitly configured in the ApplicationMain.java:
@SpringBootApplication
@PropertySources({
@PropertySource("classpath:default.properties"),
@PropertySource(value = "${external.config}", ignoreResourceNotFound = true)
})
public class ApplicationMain {and the their lisitng order defines the preference:
- Properties defined in the
default.properties(option no 2) - will be overriden by the values defined in the external file -${external.config}(option 3) - if the same key is defined in both. - Values defined through environmental variables - Option 4 - supercede the values from the both property files.
This way the developer has an option of falling back onto some well defined defaults, or to provide their own configurations as well as allowing the administrator to override any of these through an external config file or the environmental variables defined in the Kubernetes deployment config.
This flexibility, though rarely required, came quite useful in a few less than usual situations.
On the surface logging looks super easy - Kubernetes Engine sends the container standard output stream to Stackdriver Logging automatically. No configuration required. Simple!
There is, however, a couple of gotchas. The first one - every line collected becomes a separate log entry. What's wrong with that? Well, java exceptions are usually multiline stack traces - reading those across multiple log entries can be a bit confusing.
The other interesting point is that these entries would be logged as INFO. Google Kubernetes logging agent - FluentD - does not know how to parse them to get the severity right. There is a number of different formats out there, so one size fits all automatic solution is indeed a hard problem.
However the application CAN provide the output in the format that FluentD can understand. The format is defined in logback.xml - a JSON string where the field names configured as FluentD parser requires. And thanks to the Elastic.co team there is also an awesome Logstash component that encolses a multilne stack trace into a single entry!
<!-- To be able to manage the log levels through Hawtio console -->
<jmxConfigurator/>
<!-- Enclosing stacktrace into a single log entry -->
<conversionRule conversionWord="stack"
converterClass="net.logstash.logback.stacktrace.ShortenedThrowableConverter"/>
<!-- Formatting the output as a JSON string, parseable by FluentD -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<mdc/>
<pattern>
<pattern>
<!-- timestamp is collected automatically by fluentd -->
{ "severity": "%level", "message" : "%logger | %message%stack{30,30,2048,rootFirst}" }
</pattern>
</pattern>
</providers>
</encoder>
</appender>Checking output:
kubectl logs -f deploy/gke-camel-template{"severity":"INFO","message":"org.foo.ApplicationMain | Starting ApplicationMain v1.0.0-SNAPSHOT on gke-camel-template-7b4bd9ccdb-dns4l with PID 1 (/u00/lib/gke-camel-template-1.0.0-SNAPSHOT.jar started by root in /u00)"}Severity has been parsed correctly. Let's check the Stackdriver Logging UI:
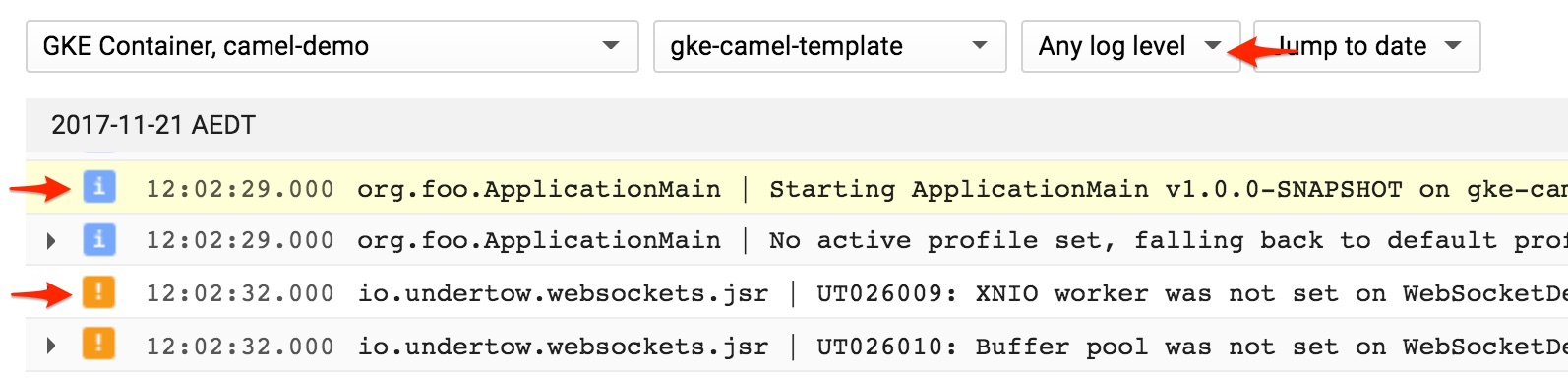
That allows for a nice and easy filtering, which also works in the streaming mode, where the log entries are displayed as they come in the [real] time:
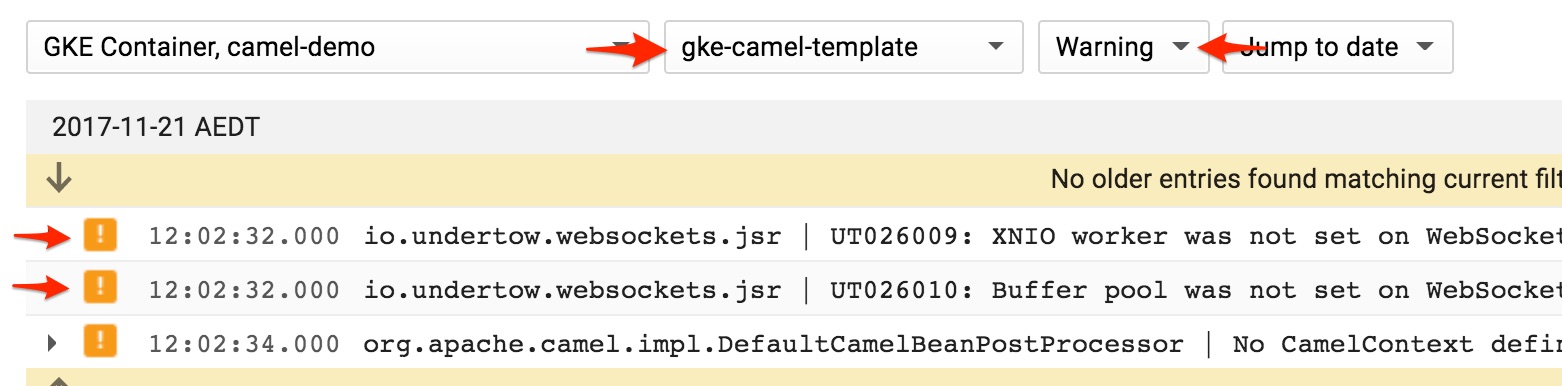
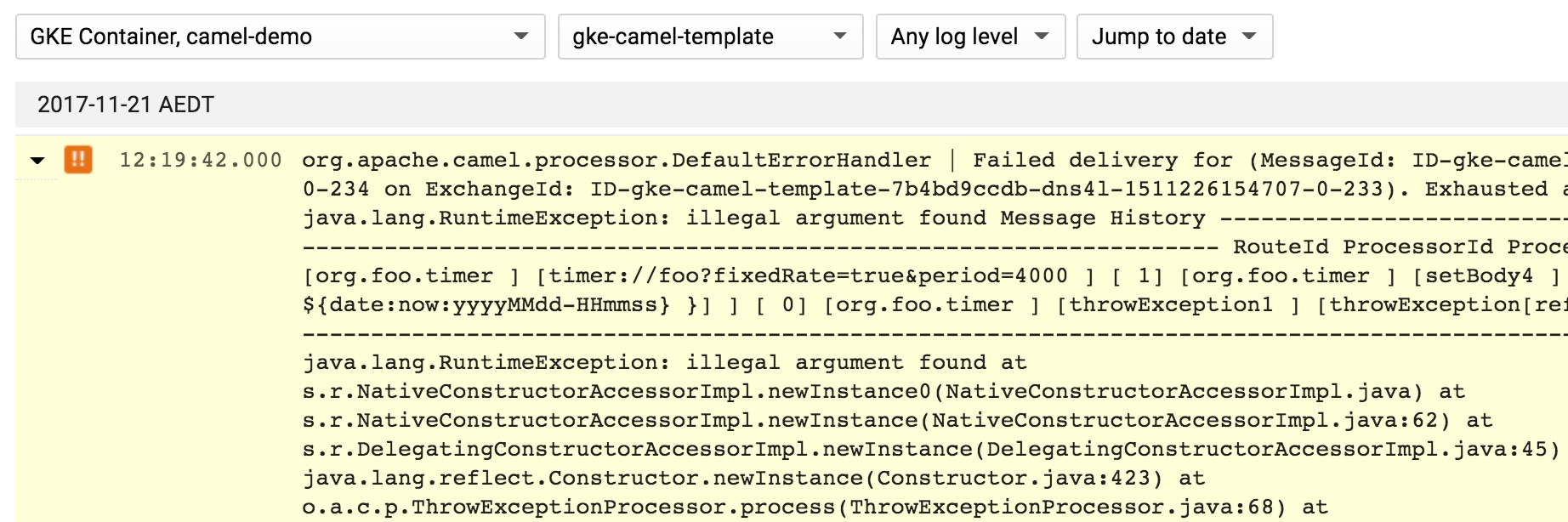
Notice how the exception is trimmed down to a single entry:
Another interesting point is that Google Stackdriver Logging also permits log based metric colelction, having the sevirity available as a selection condition makes the process much faster.
Now lets have a look inside the running container.
Quoting Lord Kelvin:
If you can not measure it, you can not improve it.
Leaving aside the philisophical contention around the essence of the expression, I hope that there is a general agreement that tracking the application performance metrics is of paramount importance.
There have been two general approaches around capturing the metrics from a containerised application - either an external collection crawler (a sidecar container, node service, etc) or the application itself reporting in.
The option presented here can be considered to be the middleway between the two.
Even though it is the "reporting in" pattern, it is implemented by the underlying JVM and not by the application itself.
The code includes Jmxtrans Agent - a java agent that periodically inspects the running application through JMX and reports the metrics to the collection point through a specific writer. Goggle Cloud Platform is supported by Google Stackdriver Writer - the component responsible for writing to Google Stackdriver Metrics API.
The java agent is completely dependency free, and while it is loaded before the application it will not interfere with the app libraries. It is a generic java agent - can be used with any JVM based application as far one supports JMX.
While for the presentation purposes the metrics collector and the config file are included within the project itself, the preferred way would be to bake these into the base Docker image.
This way, while a reasonable default configuration is provided for collecting JVM and Apache Camel metrics it still can be superseded by a a different config file if a bit more granular introspection is required by the developer or the admin.
Dockerfile example:
ENTRYPOINT exec java -cp "/u00/lib/*" \
-javaagent:/u00/jmxtrans-agent.jar=classpath:metrics.xml \
org.foo.ApplicationMainAnd a couple of examples from the metrics.xml:
<!-- Single JVM metric -->
<query objectName="java.lang:type=Memory" attribute="HeapMemoryUsage" key="used" type="GAUGE:By" resultAlias="jvm.memory.HeapMemoryUsage:used"/>
<!-- Single Apache Camel metric -->
<query objectName="org.apache.camel:context=*,type=routes,name=*" attribute="ExchangesCompleted" type="CUMULATIVE:1" resultAlias="camel.route.exchanges:%name%:#attribute#"/>The Camel metric declaration above is a template that instructs the agent to capture the count of the completed Exchanges for all routes across all Camel contexts in the JVM. Please check the Jmxtrans Agent documentation for the more information on the placeholders and the configuration in general.
The only thing the application is required to provide is the APM_META_NAME environment variable - to group the metrics under umbrella of the originating deployment, similar to how logging does it. At present there is no way for a Kubernetes container to infer the entity that has created it - being it a Deployment, a Job or a CronJob - so the appication needs to provide this explicitly.
The parameter is usually included in the Kubernetes deployment YAML:
# [ Environmental Variables ]
env:
- name: GOOGLE_APPLICATION_CREDENTIALS
value: "/etc/keys/demo-cluster-key.json"
# [ Monitoring Designator ]
- name: APM_META_NAME
value: "gke-camel-template"The metrics collected this way are classified as Custom Metrics and are available through Stackdriver Monitoring Dashboard.
Please note how the attributes and the meta name permit the granular selection:
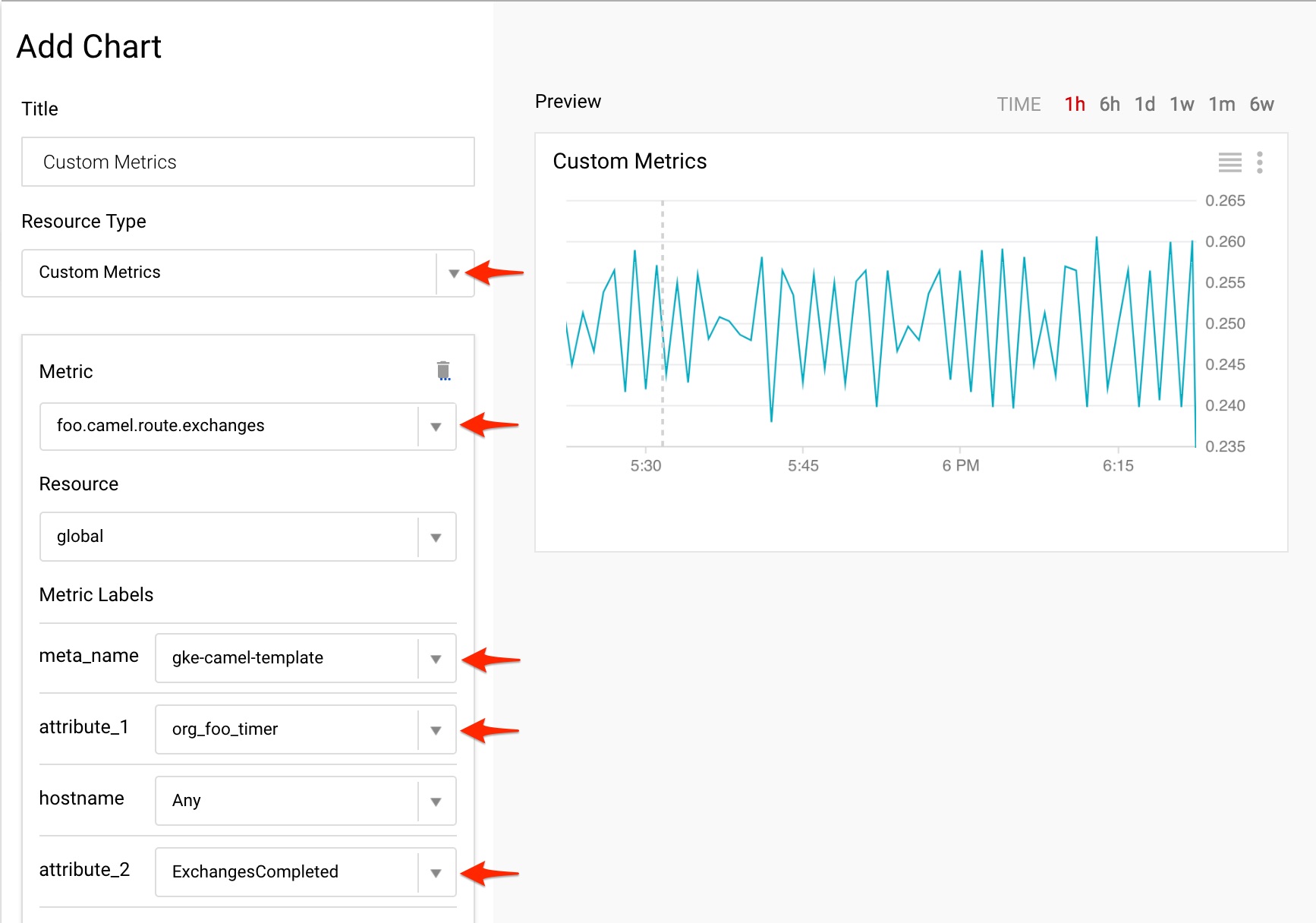
Thers is also a possibility to prefix the custom metric names. In that case it is "foo" and it has been defined explicitly in the metrics.xml configuration file:
<namePrefix>foo.</namePrefix>Important!
Even though GOOGLE_APPLICATION_CREDENTIALS environment variable is explicitly configured, the Jmxtrans Agent Google Stackdriver Writer will ignore it when executed within the Google Kubernetes Engine, as it is easier to authenticate via Kubernetes Engine cluster service account which is available to the pods through an Kubernetes internal API. Stackdriver Writer checks if one available when started. If the internal API is found the Kubernetes Cluster service account will be given preference.
This way both logging and monitoring operations are authorised by the same cluster account, leaving GOOGLE_APPLICATION_CREDENTIALS key to be used only by the application.
To illustrate the pattern, the key referenced by the GOOGLE_APPLICATION_CREDENTIALS will be granted access to PubSub and Bigquery ONLY - see the GCP Setup Script for details.
Yet when the agent runs outside the Kubernetes cluster (i.e. there is no internal API available) it will use the default key configured through GOOGLE_APPLICATION_CREDENTIALS.
Access to the Camel context in production can be the key to a quick issue resolutioin. Hawtio UI offers such possibility through its Camel plugin (and even allows route modifications!).
Yet it would be impractical to package Hawtio component with every deployment.
Luckily, Hawtio can also operate as a standalone application - it just needs the access to Jolokia JMX endpoint. Which already has been enabled in the application - by Springboot!
build.grade excerpt:
// Logging and Monitoring
compile "org.jolokia:jolokia-core:1.3.7"
compile "net.logstash.logback:logstash-logback-encoder:4.9"
Springboot application.properties:
server.port = 8091
camel.springboot.jmxEnabled=true
# No need to protect - the port is not exposed outside the container
endpoints.jolokia.sensitive=false
endpoints.health.sensitive=false
Since the port is not exposed outside the container one needs a tunnel into the container. Kubernetes provides such tunnel with its port-forward command:
kubectl port-forward <pod_name> <port>
# Executable example
kubectl port-forward $(kubectl get po | grep gke-camel | cut -d" " -f1) 8091That would effectively map the port 8091 on the local machine to the one in the container.
Now start Hawtio in a standalone mode and select "Connect" tab. Change the port to 8091 and click Connect:

That gets us Hawtio Console for the remote Camel context:
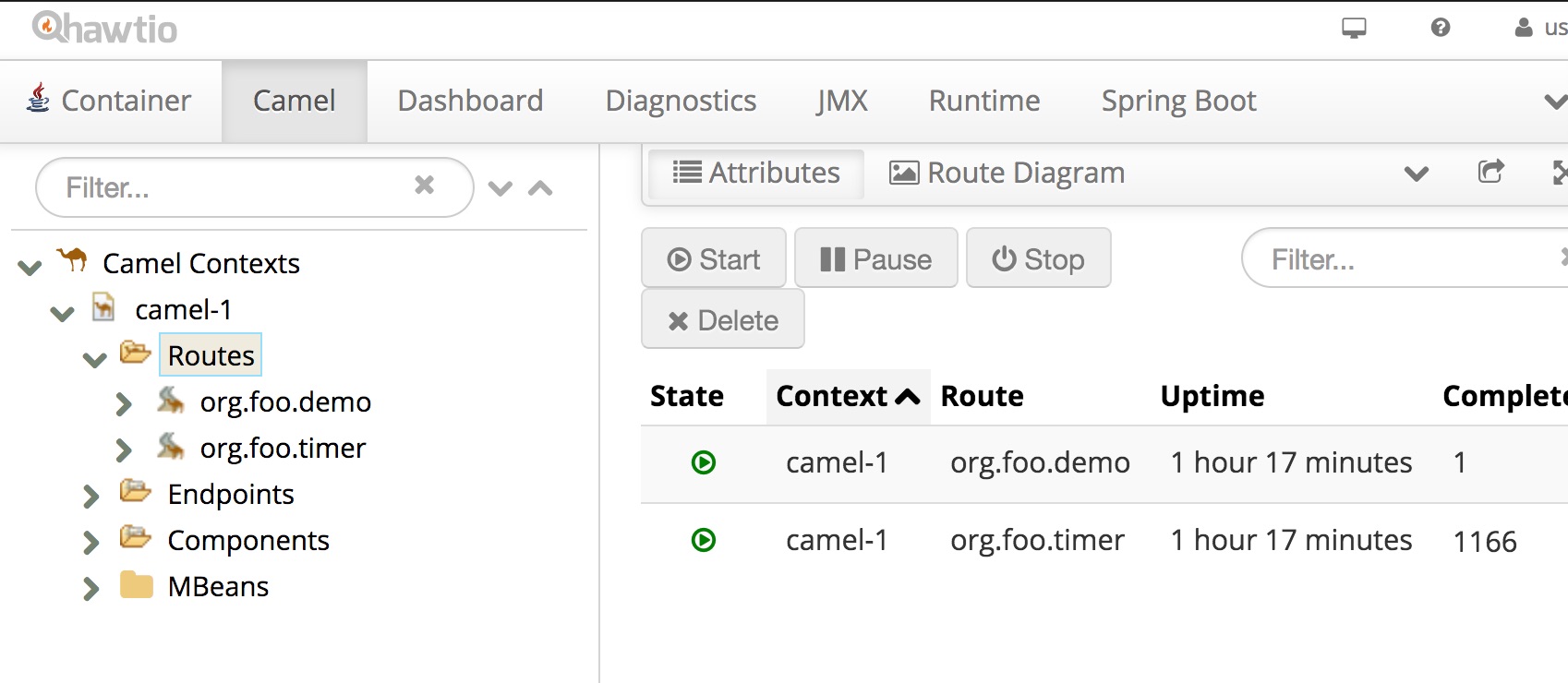
Look around - debugging, tracing, route updates - it is very powerful.
This demo demonstrated how Camel application can be configured for the Google Kubernetes Engine, integrating PubSub and Bigquery and sending logs and operational metrics to Google Stackdriver.
The blueprint presents a flexible, resilient and yet scalable approach, battle tested across tens of integration deployments in production.
Yet the foundation of the blueprint is pretty generic. Any JVM based application can be deployed in this manner - ourselves we have been using it for both Apache Camel and Clojure based solutions.
This pattern presented here comes with no warranty of any kind and any real use comes at on your own risk.
Yet if one requires piece of mind, I would suggest considering Apache Camel support subscription through RedHat.
Having access to the awesome teams in Australia, UK and Denmark can be priceless. Their deep understanding and hands on experience has proven to be invaluable on a quite a few occasions.