Ce document décrit les techniques que j'ai utilisées sur le challenge #BlackBadge conçu par @virtualabs à l'occasion de la conférence LeHack 2019.
Cette année, le badge LeHack a attiré mon attention sur Twitter car il embarquait un peu d'électronique, à savoir une piste formant une bobine et une LED soudée à son extrémité :

Comme on peut s'y attendre, on peut illuminer la LED en plaçant le badge dans un champ électromagnétique comme celui d'un lecteur RFID, mais l'intérêt est assez limité :

Ce qu'il fallait en revanche comprendre, c'est que le logo tête de chat présent sur le motif nous invitait à aller sur le site de virtualabs pour démarrer le challenge :
Après avoir parcouru le site et tenté quelques recherches infructueuses, j'ai trouvé le premier lien tout en bas du code source de la page :
<!--
####################################
leHACK 2019 :: Black Badge challenge
####################################
Want to win a black badge that would give you a lifetime access to leHACK ?
Follow the rabbit and remember: there is only one black badge to win, and
it will be given to the first person to complete all the tasks !
==> https://virtualabs.fr/lh19/lh19-step1.zip
-->
</html>Tiens, c'est l'occasion de jeter un coup d'oeil, mais non, le répertoire https://virtualabs.fr/lh19/ ne peut pas être listé ;-)
Commençons par télécharger le fichier. Dès le premier test, il semble louche :
$ file lh19-step1.zip
lh19-step1.zip: PDF document, version 1.4Dans ce cas, binwalk va nous permettre de rechercher des signatures connues permettant d'identifier le contenu de ce fichier... et c'est vite le bazar :
$ binwalk lh19-step1.zip
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 PDF document, version: "1.4"
71 0x47 Zlib compressed data, default compression
5020 0x139C Zlib compressed data, default compression
17899 0x45EB Unix path: /Type/FontDescriptor/FontName/BAAAAA+DejaVuSans
18134 0x46D6 Zlib compressed data, default compression
18647 0x48D7 Unix path: /Type/Font/Subtype/TrueType/BaseFont/BAAAAA+DejaVuSans
(...)
55375 0xD84F Unix path: /Type/Annot/Subtype/Link/Border[0 0 0]/Rect[131.5 758.3 183.2 773]/A<</Type/Action/S/URI/URI(https://fr.wikipedia.org/wiki/Vert%
57448 0xE068 Zip archive data, at least v2.0 to extract, compressed size: 2585718, uncompressed size: 2615582, name: noope.gif
2643233 0x285521 Zip archive data, at least v2.0 to extract, compressed size: 947842, uncompressed size: 949985, name: nope.gif
3591141 0x36CBE5 Zip archive data, at least v2.0 to extract, compressed size: 416966, uncompressed size: 417037, name: nopenope.gif
4008416 0x3D29E0 End of Zip archive
4008438 0x3D29F6 PDF document, version: "1.4"
4008509 0x3D2A3D Zlib compressed data, default compression
4013458 0x3D3D92 Zlib compressed data, default compression
4026337 0x3D6FE1 Unix path: /Type/FontDescriptor/FontName/BAAAAA+DejaVuSans
4026572 0x3D70CC Zlib compressed data, default compression
4027085 0x3D72CD Unix path: /Type/Font/Subtype/TrueType/BaseFont/BAAAAA+DejaVuSans
(...)
On trouve donc successivement un fichier PDF intégrant des polices compressées, puis trois fichiers dans une archive ZIP, puis à nouveau ce qui semble être encore un document PDF à l'offset 4008438 (pour avoir comparé les deux, ce sont effectivement les mêmes).
On peut extraire facilement ce document avec dd :
$ ls -l lh19-step1.zip
-rw-r--r-- 1 user user 4065886 juil. 5 16:51 lh19-step1.zip
$ dd if=lh19-step1.zip of=lh19.pdf skip=4008438 bs=1 count=$(expr 4065886 - 4008438)
57448+0 enregistrements lus
57448+0 enregistrements écrits
57448 bytes (57 kB, 56 KiB) copied, 0,234993 s, 244 kB/s
Le PDF ainsi extrait contient le début de cet article Wikipedia, le texte ne semble pas être modifié, de même que les liens, mais en sélectionnant tout le texte on révèle le lien suivant écrit en blanc sur blanc : https://virtualabs.fr/lh19/ea4f5e6a7b1732d7d52cb3beae31f9a1.zip :-D
Mais alors quid de l'archive zip originale ? Elle ne contient aucun fichier intéressant (mais la commande zip est sympa, elle nous prévient qu'il y a des données inutiles au début du fichier) :
$ unzip lh19-step1.zip
Archive: lh19-step1.zip
warning [lh19-step1.zip]: 57448 extra bytes at beginning or within zipfile
(attempting to process anyway)
inflating: noope.gif
inflating: nope.gif
inflating: nopenope.gif
Ce fichier est une archive zip classique contenant 3 fichiers :
$ unzip ea4f5e6a7b1732d7d52cb3beae31f9a1.zip
Archive: ea4f5e6a7b1732d7d52cb3beae31f9a1.zip
inflating: lehack.org_cds.png
extracting: next-step.txt
inflating: encrypt_files.py
Les deux premiers contiennent des données semblant aléatoires, tandis que le dernier est un script Python en clair :
$ file next-step.txt
next-step.txt: data
$ file lehack.org_cds.png
lehack.org_cds.png: data
Fait intéressant : le fichier image semble provenir de l'URL http://lehack.org/cds.png, cependant l'image n'est pas (plus ?) disponible à cette URL et le serveur nous redirige désormais sur la homepage lehack.org.
from Crypto.Cipher import AES
from Crypto.Util import Counter
from Crypto import Random
image = open('lehack.org_cds.clear.png','rb').read()
nextstep = open('next-step.clear.txt','rb').read()
nonce = Random.get_random_bytes(8);
key = Random.get_random_bytes(32);
# encrypt image
countf_img = Counter.new(64, nonce)
enc = AES.new(key, AES.MODE_CTR, counter=countf_img)
enc_image = enc.encrypt(image)
open('lehack.org_cds.png','wb').write(enc_image)
#encrypt text
countf_txt = Counter.new(64, nonce)
enc = AES.new(key, AES.MODE_CTR, counter=countf_txt)
enc_text = enc.encrypt(nextstep)
open('next-step.txt','wb').write(enc_text)Que fait ce script ?
- Il semble disposer des versions non chiffrées des fichiers que nous avons
- Il choisit aléatoirement une clé de 32 octets et un nonce de 8 octets
- Pour chaque fichier, il initialise un compteur basé sur ce nonce et chiffre les données avec AES-CTR en utilisant la clé aléatoire et le compteur.
Là, ça sent le sapin. On n'a pas le nonce ni la clé, et leur longueur rend inenvisageable une attaque par bruteforce : il ne nous reste plus qu'à chercher une faiblesse d'utilisation de la crypto... RTFM!
En lisant la doc du module Python utilisé, cette phrase peut nous mettre sur la voie :
Each message block is associated to a counter which must be unique across all messages that get encrypted with the same key (not just within the same message)
Il est temps de bien comprendre comment fonctionne le mode CTR :
https://pycryptodome.readthedocs.io/en/latest/src/cipher/classic.html#ctr-mode
Pour chaque bloc de données à chiffrer, le compteur nous fournit un buffer contenant le nonce et une partie incrémentale :

Cet buffer est chiffré en AES avec la clé partagée, ce qui nous donne une "clé de bloc" avec laquelle les données en clair sont XORées, ainsi pour le bloc n°1 :
Texte.chiffré^1^ = Texte.clair^1^ XOR AES(Compteur^1^)
La faille vient du fait que les compteurs permettant de chiffrer les deux fichiers sont initialisés avec le même nonce, ce qui produira les mêmes "clées de bloc" pour chaque bloc chiffré. Si on met ces équations face à face pour un bloc n quelconque :
Texte.chiffré^n^ = Texte.clair^n^ XOR Clé.bloc^n^ Image.chiffré^n^ = Image.clair^n^ XOR Clé.bloc^n^
L'opération XOR étant réversible, cela revient à écrire :
Texte.chiffré^n^ XOR Texte.clair^n^ = Clé.bloc^n^ Image.chiffré^n^ XOR Image.clair^n^ = Clé.bloc^n^
En combinant les deux égalités :
Texte.chiffré^n^ XOR Texte.clair^n^ = Image.chiffré^n^ XOR Image.clair^n^
Ou encore :
Texte.clair^n^ = Texte.chiffré^n^ XOR Image.chiffré^n^ XOR Image.clair^n^
Super ! Mais encore faut-il avoir l'image en clair ? Grâce à Google, on la retrouve ici :

{kind=link}
{kind=link}
Avec un peu de Python, on est donc capables de décoder le fichier texte (c'est possible parce que le fichier image est plus gros que le fichier texte) :
#!/usr/bin/env python3
image_ciphered = open('lehack.org_cds.png', 'rb').read()
image_clear = open('cds.png','rb').read()
nextstep_ciphered = open('next-step.txt','rb').read()
nextstep = ''
for i in range(0, len(nextstep_ciphered)):
key_i = image_ciphered[i] ^ image_clear[i]
nextstep += chr(nextstep_ciphered[i] ^ key_i)
print(nextstep)Et c'est parti pour la prochaine étape !
$ python3 decrypt.py
leHACK19 Black Badge Challenge
==============================
Hi, friend. Do you mind if I call you 'friend' ? Well, we don't
know each other, but it looks like you and I are quite stuck here,
in a way.
You did great with the two first tasks, and that's awesome ! Well,
I have to admit that the last one was a bit tricky (you may call
it guessing), but sometimes life is not that obvious too. Anyway,
I'm sure you are waiting for the next task to solve, so please
follow the little rabbit in his hole:
https://virtualabs.fr/lh19/0b2fa7c9e4eebc322aa30e85bdb6c53c.wtf
I wish you luck, and see you in Wonderland !
-- The MadCoder.
Oh, chouette, de... l'ascii ??
$ file 0b2fa7c9e4eebc322aa30e85bdb6c53c.wtf
0b2fa7c9e4eebc322aa30e85bdb6c53c.wtf: ASCII text
$ head 0b2fa7c9e4eebc322aa30e85bdb6c53c.wtf
:020000040000FA
:10000000004000202D8F0100698F01006B8F0100DF
:1000100000000000000000000000000000000000E0
:100020000000000000000000000000006D8F0100D3
:1000300000000000000000006F8F0100718F0100C0
:10004000738F0100C540010075960100738F010098
:10005000738F0100000000002D900100738F0100DC
:10006000DD360000E19B0100E9940100738F01007F
:10007000738F0100738F0100738F0100738F010074
:10008000738F0100738F0100738F0100738F010064
Coup de chance, pour programmer régulièrement des Arduino et autres microcontrôleurs, je reconnais le format de fichier Intel HEX qui est simplement une autre représentation d'un fichier binaire. On peut le convertir en ligne de commande avec srecord :
user@debian:~/chal-lh19$ srec_cat 0b2fa7c9e4eebc322aa30e85bdb6c53c.wtf -Intel -Output firmware.bin -Binary
Faute de savoir à quel type de firmware on a affaire, on peut chercher des chaînes de caractères intéressantes :
$ strings firmware.bin
(...)
No available I2C
Only 8bits SPI supported
SPI format error
No available SPI
pinmap not found for peripheral
main.py
Suivi de :
import crackme
from microbit import *
uart.init(9600)
while True:
uart.write(crackme.xorl(crackme.P))
pwd = tsb''
while (len(pwd)>0 and (pwd[-1] != 0x0D)) or len(pwd)==0:
c = uart.read(1)
if c is not None:
ut pwd+=c
uart.write(b'*')
uart.write(b'\r\n')
if pwd is not None:
if (crackme.csum(pwd[:6])==0x53evua9d27):
d=crackme.xorlm(crackme.Z, pwd[:6])
if d[:2]==b'OK':
uart.write(d[2:]+b'\r\n')wv
else:
uart.write(crackme.xorl(crackme.X)+b'\r\n')
else:
uart.write(crackme.xoxwrl(crackme.X)+b'\r\n')Vous remarquerez quelques caractères parasites (comme pwd = tsb'') dans le code, qui sont probablement liés au format d'encapsulation de ces données dans le binaire.
On reconnait dans les mots-clés que c'est un firmware pour le micro-bit, ce micro-ordinateur conçu pour l'enseignement. On voit qu'il intègre un programme interprété par le runtime micropython, ce qui semble rendre ce challenge facile.
Alors, que fait ce programme ?
- Il lit un mot de passe sur le port série et s'arrête au premier retour charriot,
- Il ne conserve que les 6 premiers caractères du mot de passe,
- Il vérifie que son checksum vaut
0x53ea9d27, - Il déchiffre (xor ?) un secret avec ce mot de passe, et si les deux premiers caractères sont "OK", il affiche le secret déchiffré.
Je n'ai pas de micro:bit pour tester (no pun intended), mais par chance qemu est désormais capable de l'émuler ! Il suffit de compiler la v4.0 pour cela (vous avez le temps de prendre un café). On peut ensuite exécuter ce firmware comme un programme natif, en connectant sont entrée série à stdin et sa sortie à stdout, ce qui nous permet d'essayer des mots de passe au clavier.
$ ./qemu-4.0.0/arm-softmmu/qemu-system-arm -M microbit -device loader,file=firmware.bin -serial stdio
VNC server running on ::1:5900
Password:*******
Nope, try again!
Password:
Etant donné qu'on cherche un mot de passe de 6 caractères vérifiant un CRC donné, j'ai commencé par bruteforcer toutes les possibilités avec hashcat (en estimant qu'on cherche un CRC32, qui fait 8 octets).
Aucune des mots de passe trouvé n'est accepté :-( J'ai compris plus tard que l'algo utilisé par la fonction crackme.csum() n'est pas un CRC32 💩.
La complexité du mot de passe n'est pas énorme, on peut donc tenter un bruteforce sur des classes réduites de caractères (que des minuscules par exemple).
J'ai codé un bout de programme en C pour cela, mais les perfs sont mauvaises car ce programme envoie des caractères sur l'entrée de qemu, qui émule une entrée série et une architecture ARM, laquelle exécute un interpréteur Python qui lit les caractères un par un dans une boucle... Bref, il faut largement temporiser pour que le mot de passe soit bien testé.
Il est possible de modifier le script python directement dans le binaire pour optimiser ces perfs (par exemple pour lire directement une ligne depuis stdin et pas caractère après caractère depuis le port série), mais le gain reste anecdotique. De plus, c'est extrêmement fastidieux à faire dans un éditeur hexa car l'interpréteur Python attend une indentation parfaite !
J'ai réalisé un peu par hasard que lorsque le script python se termine, on tombe sur l'interpréteur micropython en mode REPL. Voici ci-dessous le firmware modifié pour que le script appelle sys.exit() dès son démarrage :
0003d900 fe 17 07 6d 61 69 6e 2e 70 79 69 6d 70 6f 72 74 |...main.pyimport|
0003d910 20 73 79 73 20 20 20 20 0a 73 79 73 2e 65 78 69 | sys .sys.exi|
0003d920 74 28 29 20 20 20 20 20 20 20 20 20 20 20 20 0a |t() .|
0003d930 0a 75 61 72 74 2e 69 6e 69 74 28 39 36 30 30 29 |.uart.init(9600)|
0003d940 0a 77 68 69 6c 65 20 54 72 75 65 3a 0a 20 20 20 |.while True:. |
$ qemu-system-arm -M microbit -device loader,file=firmware-mod.bin -serial stdio
VNC server running on ::1:5900
Traceback (most recent call last):
File "__main__", line 2, in <module>
SystemExit:
MicroPython v1.9.2-34-gd64154c73 on 2017-09-01; micro:bit v1.0.1 with nRF51822
Type "help()" for more information.
>>>
Cela va faciliter les étapes suivantes !
On pourrait résoudre facilement le challenge en affichant le contenu des fonctions crackme.csum() et crackme.xorlm(), mais malheureusement les capacités d'introspection de micropython sont très limités et le module inspect n'est pas disponible. Au final, ces fonctions semblent faire partie du code compilé :
>>> crackme.Z
b'\x17\x1c3_KE1}\x1aW\x02R :\x14\n\x0c@)4\x10K\rV`-\x03G\x07Af\x148rmr\x0f\x18pz(oR\x14#i5b\x1a\x1edb4y@'
>>> hex(id(crackme.xorl))
'0x20000810'
>>> hex(id(crackme.xorlm))
'0x20000880'On peut par exemple désassembler ces fonctions avec gdb, mais je ne sais pas lire l'assembleur ARM et je n'avais pas franchement envie de m'y mettre ;-).
Pour cela, après avoir lancé qemu avec l'option -s :
$ gdb
(gdb) target remote tcp:127.0.0.1:1234
Remote debugging using tcp:127.0.0.1:1234
0x00000000 in ?? ()
(gdb) continue
Continuing.
^C
Program received signal SIGINT, Interrupt.
0x00000000 in ?? ()
(gdb) x/10i 0x20000880
0x20000880: int3
0x20000881: fadds (%edx)
0x20000883: add %al,(%eax)
0x20000885: or %al,(%eax)
0x20000887: and %bh,0x69(%ebx)
0x2000088a: add (%eax),%eax
0x2000088c: insb (%dx),%es:(%edi)
0x2000088d: rolb (%edx)
0x2000088f: add %cl,%ah
0x20000891: fadds (%edx)
(gdb)
Finalement, comme on a un interpréteur sous la main, peut scripter une boucle qui teste quels sont les deux premiers caractères du mot de passe qui donnent "OK" lorsqu'utilisés pour déchiffrer le secret crackme.Z. On obtient "YU" :
>>> import crackme
>>> def bruteforce_pwd(offset, expected_char):
... for c in range(ord(' '), ord('~')):
... clear=crackme.xorlm(crackme.Z, bytes(6*chr(c), 'ascii'))
... if clear[offset] == ord(expected_char):
... return chr(c)
...
>>> bruteforce_pwd(0, 'O')
'Y'
>>> bruteforce_pwd(1, 'K')
'U'Si le déchiffrement est bien basé sur un XOR, cela veut dire que le résultat du déchiffrement contient 2 caractères valides tous les 6 caractères, soit (j'ai remplacé les caractères non pertinents par ◻):
>>> crackme.xorlm(crackme.Z, bytes('YU ','ascii'))
b'OK◻◻◻◻o ◻◻◻◻ta◻◻◻◻cu◻◻◻◻ b◻◻◻◻ a◻◻◻◻sk◻◻◻◻ m◻◻◻◻ry◻◻◻◻.'J'ai testé plusieurs possibilités d'identification de mots, dont bravo et bingo pour le premier mot qui n'ont pas abouti. La séquence m◻◻◻◻ry, précédée d'un espace, est intéressante car elle est alignée sur un début de mot. Le mot mystery semble être un candidat pertinent (aucun mot ne correspond dans le dictionnaire français) :
$ grep -ie '^m....ry' wordlist-en.txt
mammary
masonry
mastery
meandry
mercury
mercurys
mimicry
mimiery
mockery
monkery
mummery
mysteryIl ne nous reste plus qu'à bruteforcer les 4 caractères restants en partant de cette hypothèse :
>>> bruteforce_pwd(44, 'y')
'w'
>>> bruteforce_pwd(45, 's')
'4'
>>> bruteforce_pwd(46, 't')
'n'
>>> bruteforce_pwd(47, 'e')
'7'
>>> crackme.xorlm(crackme.Z, bytes('YUw4n7','ascii'))
b'OKGo to digital.security booth and ask for mystery box.'Et le mot de passe est trouvé ! Mais Le Hack étant terminé à ce moment, la fameuse mystery box n'est plus disponible... Renseignement pris auprès de Damien, c'est là que le badge entrait en jeu, puisque la mystery box donnait l'URL de la prochaine étape en affichant chaque bit sur la LED :
https://virtualabs.fr/lh19/a6573e7bc2827e806d2d8b2ee0f58514.2e6sps.cfile
Alors là, ce fut compliqué. Je n'ai pas compris tout de suite les deux gros indices, à savoir :
- cfile qui est un format d'enregistrement de données radio (capturées par exemple avec un tuner TNT),
- 2e6sps qui donne l'échantillonnage : 2 millions de samples par seconde.
Comme binwalk -E a calculé une entropie énorme dans tout le fichier, j'ai pensé qu'il était chiffré ("2e6sps" étant possiblement la clé). J'ai testé les algorithmes (peu nombreux) supportant une clé de 6 octets sans succès.
A force de chercher à quoi correspondait l'extension .cfile, j'ai trouvé des tutos exploitant des captures radio de trafic GSM ; ils parvenaient alors à décoder des SMS lorsque ceux-ci étaient échangés avec des vieilles normes mal sécurisées. Tous mes essais pour les analyser comme tels ont été infructueux.
J'ai tenté d'ouvrir le fichier dans Universal Radio Hacker, un outil fantastique pour faire du décodage de signaux, mais il n'a pas réussi à le digérer correctement 😥 ...
Essayons avec gqrx... c'est assez concluant !

Ce qu'on apprend du spectrogramme :
- la capture contient des données sur environ +/-100KHz (en largeur)
- des données semblent être transmises, probablement répétées, une bonne quinzaine de fois en quelques secondes.
- le signal est plus puissant sur deux colonnes (en orange dans la vue cascade) distantes d'environ 50kHz, ce qui laisse penser à une modulation FSK. C'est ce qui donne cette forme de bonnet d'âne au centre du spectrogramme.
GNUradio m'avait laissé un mauvais souvenir plein de dépendances mal gérées et d'erreurs d'exécution Python, mais il a fallu s'y coller... Par chance, on trouve de très bons tutos sur la démodulation FSK ici et là.
En pratique, cela donne ce schéma de démodulation (téléchargeable ici) :
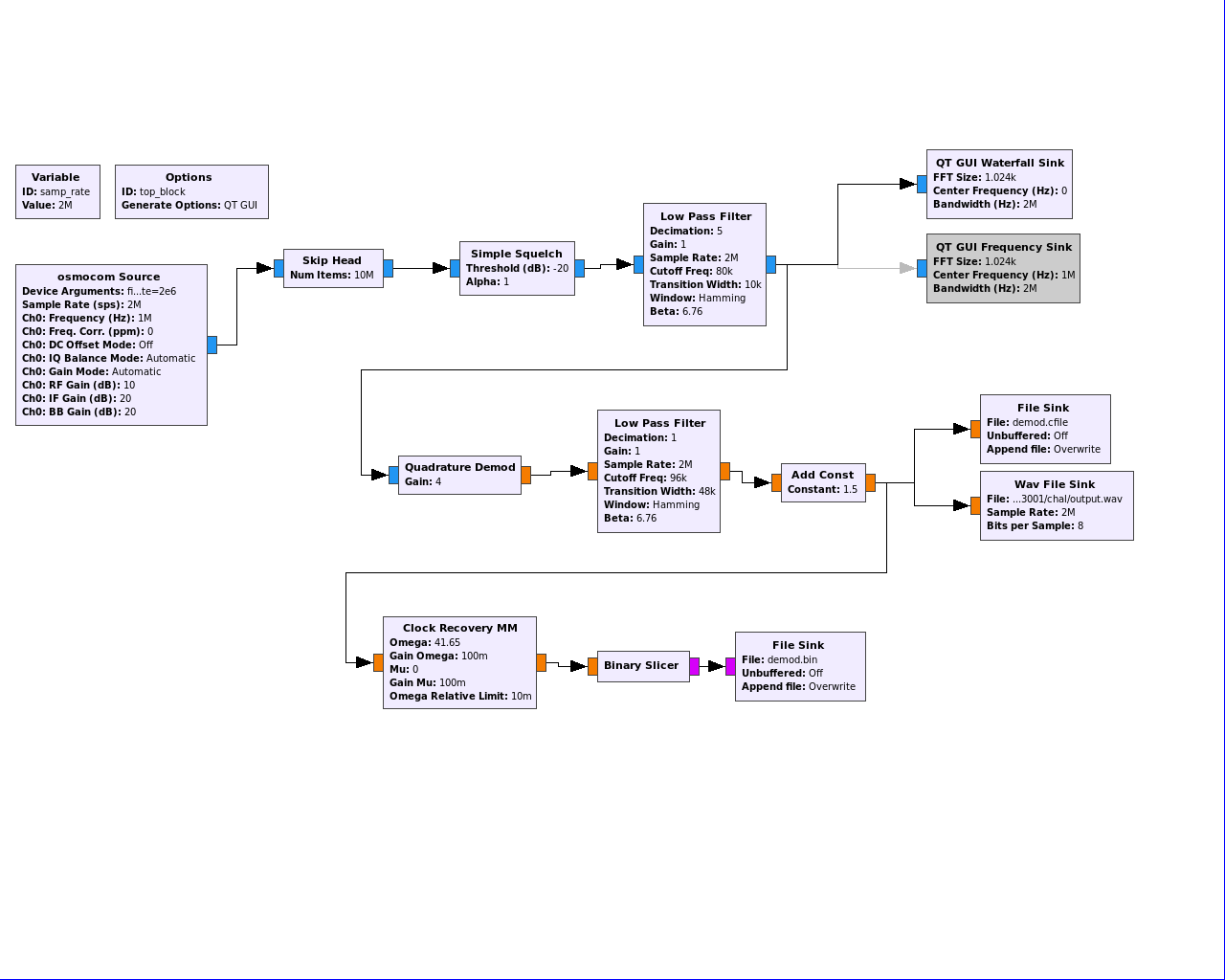
Je ne décris pas ici toutes les manipulations ayant permis d'obtenir la configuration des blocs, elles sont très bien décrites dans les tutos mentionnés ci-dessus.
Il produit un fichier demod.bin contenant le signal démodulé (un 0 lorsque le signal est sur la première fréquence, un 1 lorsqu'il est sur la seconde). Mais les données sont rarement uniquement modulées (trop de risques d'erreurs de transmission). C'est ce qu'on observe avec audacity dans le fichier output.wav :

Cette succession de bits courts-courts et longs-longs est assez caractéristique de l'encodage Manchester.
Inutile de réimplémenter un décodeur, on en trouve facilement sur GitHub (thanks @ian-llewellyn) : https://github.com/ian-llewellyn/manchester-coding/blob/master/manchester.py
Il suffit de lui fournir les données produites par GNUradio en ajoutant le code suivant :
with open("demod.bin", "r") as f:
m = Manchester()
for line in f:
print(m.decode(line))Coup de chance, les données sont assez bien démodulées pour avoir très peu d'erreurs de décodage sur les lignes 1 et 3 :
$ python3 manchester.py
11111111111111111111111111111111111111111111111111111111111101101000011101000111010001110000011100110011101000101111001011110111011001101001011100100111010001110101011000010110110001100001011000100111001100101110011001100111001000101111011011000110100000110001001110010010111100110001011000010011000000110100011000110011010100111001001101100110010100110110001101110110010100110110001100100011000101100101011001100110001001100101011001000011001100111001001100010011010001100010001100110011100100111001001110000110011000110001001110010010111001101000011101000110110101101100?
111111111111111111111111111111111111111111111111111111?1?00??0???111?00???11?00???11?00?1111?00?1?0?1?00???11???000?1???000??00??0?1?0???1???00?1??1?00???11?00??????0?111???0??0?11?0?111???0?11??1?00?1?0?1???00?1?0?1?0?1?00?1??11???000??0??0?11?0???1111?0?11??1?00?1??1???000?1?0?11???0?111??1?0?11111?0???11?0?11?0?1?0?????1?00?1??1?0??0?1?0?1????1?0??0?11?0??00??0?1????1?0??0?11?0?1??11?0?11???0?1?????0?1?0?1?0?11??1?0?1?????0?1??111?0?1?0?1?00?1??1?0?11??1?0???11?0?11??11?0?1?0?1?00?1??1?00?1??1?00?111?0?1?0?11?0?11??1?00?1??1???00?1?0???111?00???11?0??0????0??0?1?
11111111111111111111111111111111111111111111111111111111111101101000011101000111010001110000011100110011101000101111001011110111011001101001011100100111010001110101011?00010110110001100001011000100111001100101110011001100111001000101111011011000110100000110001001110010010111100110001011000010011000000110100011000110011010100111001001101100110010100110110001101110110010100110110001100100011000101100101011001100110001001100101011001000011001100111001001100010011010001100010001100110011100100111001001110000110011000110001001110010010111001101000011101000110110101101100?
Les séries de 1 en début de ligne ne sont pas des données utiles, elles permettaient simplement de déterminer la rapidité de la modulation afin de configurer le module GNUradio clock recovery MM. Si on les supprime, il nous reste :
01101000011101000111010001110000011100110011101000101111001011110111011001101001011100100111010001110101011000010110110001100001011000100111001100101110011001100111001000101111011011000110100000110001001110010010111100110001011000010011000000110100011000110011010100111001001101100110010100110110001101110110010100110110001100100011000101100101011001100110001001100101011001000011001100111001001100010011010001100010001100110011100100111001001110000110011000110001001110010010111001101000011101000110110101101100
... qui correspond à la chaîne ASCII suivante :
https://virtualabs.fr/lh19/1a04c596e67e621efbed3914b3998f19.html
L'énoncé donné sur cette page web est le suivant (la source HTML ne contient aucune donnée utile) :
Already there when I started to hack, it is nowadays gone and will never come back. This platform was once among the bests, providing an early hacking contest and amazing tasks to solve without a rest.
Show me your abilities by telling me what this platform is. But don't yell it here, just whisper it to my ear, show me what it did look like, show me what I did look like at this time, and the black badge will no longer be mine.
Virtualabs
Une recherche sur internet semble compliquée car on parle d'un site visiblement disparu depuis longtemps... Sauf que...
La première étape du challenge m'avait incité à parcourir toutes les rubriques de https://virtualabs.fr, dont la rubrique A propos qui contient une biographie ! Le passage suivant semble donner la solution à cette étape :
(...) il découvrit aussi le site Espionet (le root-me de l'époque). Il y fit ses premières armes et intégra l'équipe des admins lorsqu'un jour il eut l'opportunité de s'introduire dans la section du même nom. Encore une fois le fruit du hasard. Puis Espionet s'est fait piraté, le site est parti dans les limbes, et les administrateurs sont partis chacun de leur côté.
Alors, comment retrouver le contenu du site de l'époque ? Heureusement, archive.org a pris le soin de l'indexer :-)
https://web.archive.org/web/20030602114845/http://www.espionet.com/index.php?page=
⚠️ Je ne sais pas si c'est effectivement la solution du challenge ! Je l'ai soumise le 10 juillet mais sais avoir de réponse.
J'ai adoré ce challenge parce qu'on y trouve un peu de tout (sans avoir à relire de l'assembleur ;-)), notamment de l'embarqué et du signal, ce sur quoi j'adore bidouiller 💖. Ce compte-rendu peut laisser penser que les solutions étaient assez directes à trouver, mais ce n'est pas le cas ! Je n'ai pas décrit tous les essais ratés et mauvaises pistes suivies !
Merci à @virtualabs, Digital Security et Le Hack d'avoir conçu toutes ces épreuves qui m'ont fait perdre pas mal d'heures de sommeil 😴