- Deep Learning - Goodfellow, Bengio, Courville
- Section 1: ML basics (skipped)
- Section 2: DL
- Section 3: DL in practice & research
- Summary - Notes by someone
- ⭐ Deep Learning in Neural Networks: An Overview - Schmidhuber
- [ML yearning - Andrew Ng] (http://www.mlyearning.org/): general Machine Learning skills (not fully available yet)
- A Statistical View of Deep Learning (many blog posts)
- ⭐ CNN arquitectures comparison
- Neural networks class - Hugo Larochelle - Universite de Sherbrooke
- CS294 - Berkeley - Deep Reinforcement Learning - Levine, Schulman, Finn
- Oxford Deep NLP 2017 course
- ⭐ Adam: A Method for Stochastic Optimization
- Explaining and Harnessing Adversarial Examples - Goodfellow, Shlens, Szegedy Argues linearity is the cause behind missclassification of adversarial examples.
- Path-SGD: Path-Normalized Optimization in Deep Neural Networks - Neyshabur, Salakhutdinov, Srebro
- 1998 - Efficient Backprop - Le Cun
- 2010 - Deep learning via Hessian-free optimization - Martens
- ⭐ On the importance of initialization and momentum in deep learning - Sutskever, Martens, Dahl, Hinton
- 2010 - Understanding the difficulty of training deep feedforward neural networks - Glorot, Bengio
- ⭐ 2013 - On the difficulty of training Recurrent Neural Networks - Pascanu, Mikolov, Bengio
- ⭐ http://deepdish.io/2015/02/24/network-initialization/
- ⭐ Practical recommendations for gradient-based training of deep architectures - Bengio
- ⭐ Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) - Clevert, Unterthiner, Hochreiter
- ⭐ Simplifying neural nets by descovering flat minima (FMS) - Hochreiter, Schmidhuber
- ⭐ Self-Delimiting Neural Networks (with competing units (?)) - Schmidhuber, 2012
- ⭐ Understanding deep learning requires rethinking generalization - Zhang, S.Bengio, Hardt, Recht, Vinyals
- DEEP NETS DON’T LEARN VIA MEMORIZATION - Krueger et al.
- Bridging the Gaps Between Residual Learning, Recurrent Neural Networks and Visual Cortex - Liao, Poggio
- animal visual cortex, Hubel & Wiesel 1968
- Hippocampal replay in the awake state: a potential substrate for memory consolidation and retrieval
- Book - The Hippocampus as a Cognitive Map - O'Keefe, Nadel
- Book - Rhythms of the Brain - Buzsaki
- Collective behavior of place and non-place neurons in the hippocampal network - Meshulam, Gauthier, Brody, Tank, Bialek
- ⭐ Connecting Generative Adversarial Networks and Actor-Critic Methods - Pfau, Vinyals
- ⭐ Reinforcement Learning Neural Turing Machines - Revised - Zaremba, Sutskever
- Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning - Narasimhan, Yala, Barzilay
- Sergey Levine and Chelsea Finn: Robotic Visuomotor Learning
- Deep Reinforcement Learning for Tensegrity Robot Locomotion - Geng, Zhang, Bruce, Caluwaerts, Vespignani, SunSpiral, Abbeel, Levine
- Benchmarking Deep Reinforcement Learning for Continuous Control - Duan, Chen, Houthooft, Schulman, Abbeel
- Learning Deep Neural Network Policies with Continuous Memory States - Zhang, McCarthy, Finn, Levine, Abbeel
- End-to-End Training of Deep Visuomotor Policies - Levine, Finn, Darrell, Abbeel
- Simulation-to-Real Robot Learning from Pixels with Progressive Nets - Rusu, Vecerik, Rothoerl, Heess, Pascanu, Hadsell
- Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates - Gu, Holly, Lillicrap, Levine
- Collective Robot Reinforcement Learning with Distributed Asynchronous Guided Policy Search - Yahya, Li, Kalakrishnan, Chebotar, Levine
- Asynchronous Methods for Deep Reinforcement Learning - Mnih, Puigdomenech, Mirza, Graves, Lillicrap, Harley, Silver, Kavukcuoglu
- ⭐ Reddit discussion on this topic
- ⭐ Memory-based control with recurrent neural networks - Heess, Hunt, Lillicrap, Silver
- ⭐ Reinforcement Learning with Long Short-Term Memory - Bakker
- ⭐ On Learning to Think: Algorithmic Information Theory for Novel Combinations of Reinforcement Learning Controllers and Recurrent Neural World Models - Schmidhuber
- x ⭐ Deep Visual Foresight for Planning Robot Motion - Finn, Levine
- RECURRENT NEURAL NETWORKS AND OTHER MACHINES THAT LEARN ALGORITHMS
- Fast Reinforcement Learning via Slow Reinforcement Learning
- Vinyals - Recurrent nets frontiers (empty)
- ... (Missing content, look for it speaker by speaker)
- ⭐ Training recurrent neural networks (Theis) - Sutskever
- A Critical Review of Recurrent Neural Networks for Sequence Learning - Lipton, Berkowitz, Elkan
- ⭐ (2012 textbook) Supervised Sequence Labelling with Recurrent Neural Networks - Graves
- ⭐ Generating Sequences with Recurrent Neural Networks - Graves
- ⭐ Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks - Graves, Fernandez, Gomez, Schmidhuber
- How to Construct Deep Recurrent Neural Networks - Pascanu, Gulcehre, Cho, Bengio
- ⭐ Schmidhuber 1992b
- ⭐ A Clockwork RNN - Koutnik, Greff, Gomez, Schmidhuber
- ⭐ Sequence labelling in structured domains with hierarchical recurrent neural networks - Fernandez, Graves, Schmidhuber
- ⭐ Visualizing and Understanding Recurrent Networks - Karpathy, Johnson, Fei-Fei
- Recurrent Highway Networks - Zilly, Srivastava, Koutnik, Schmidhuber
- Long-term Recurrent Convolutional Networks for Visual Recognition and Description - Donahue, Hendricks, Rohrbach, Venugopalan, Guadarrama, Saenko, Darrell CNN+LSTM (?)
- Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling - Sak, Senior, Beaufays
- ⭐ Recurrent Models of Visual Attention - Mnih, Heess, Graves, Kavukcuoglu
- ⭐ Multiple Object Recognition with Visual Attention - Ba, Mnih, Kavukcuoglu
- DRAW: A Recurrent Neural Network For Image Generation - Gregor, Danihelka, Graves, Jimenez, Wierstra
- ⭐ Unsupervised Learning of Video Representations using LSTMs - Srivastava, Mansimov, Salakhutdinov
- ⭐ Video Pixel Networks - Kalchbrenner, van den Oord, Simonyan, Danihelka, Vinyals, Graves, Kavukcuoglu
- ⭐ Delving Deeper into Convolutional Networks for Learning Video Representations - Ballas, Yao, Pal, Courville
- Semantic Object Parsing with Graph LSTM - Liang, Shen, Feng, Lin, Yan
- Associative Long Short-Term Memory - Danihelka, Wayne, Uria, Kalchbrenner, Graves - Extend memory with complex-valued vectors.
- Contextual LSTM (CLSTM) models for Large scale NLP tasks - Ghosh, Vinyals, Strope, Roy, Dean, Heck - Input words & topics instead of words.
- Multiplicative LSTM for sequence modeling - Krause, Lu, Murray, Renals - Transitions are a function of inputs.
- Persistent RNNs
- Phased LSTM
- DizzyRNN: Reparameterizing Recurrent Neural Networks for Norm-Preserving Backpropagation - Dorobantu, Stromhaug, Renteria
- Memory Networks - Weston, Chopra, Bordes
- Learning to execute - Zaremba, Sutskever
- End-To-End Memory Networks - Sukhbaatar, Szlam, Weston, Fergus
- Classical neural network memory models such as associative memory networks aim to provide content-addressable memory, i.e., given a key vector to outputa value vector, see e.g., Haykin (1994) and references therein
- In particular (Das et al., 1992) designed differentiable push and pop actions called a neural network pushdown automaton. The work of Schmidhuber (1992) incorporated the concept of two neural networks where one has very fast changing weights which can potentially be used as memory. Schmidhuber (1993) proposed to allow a network to modify its own weights “selfreferentially” which can also be seen as a kind of memory addressing
- RNNSearch (Bahdanau et al., 2014) is a method of machine translation that uses a learned alignment mechanism over the input sentence representation while predicting an outputin order to overcomepoorperformanceonlongsentences. The workof(Graves, 2013) performshandwritingrecognitionby dynamically determining“an alignmentbetween the text and the pen locations” so that “it learns to decide which character to write next”. One can view these as particular variants of memory networks where in that case the memory only extends back a single sentence or character sequence.
- Neural Turing Machines - Graves, Wayne, Danihelka
- ⭐ 1992 reverted CNN - Reverse TDNN: An ARchitecture for Trajectory Generation - Simard, Le Cun
- ⭐ [WaveNet: A Generative Model for Raw Audio - van den Oord, Dieleman, Zen, Simonyan, Vinyals, Graves, Kalchbrenner, Senior, Kavukcuoglu](WaveNet: A Generative Model for Raw Audio)
- 😄 [NeuralStyle - A Neural Algorithm of Artistic Style - Gatys, Ecker, Bethge]
- 😄 RAISR: Rapid and Accurate Image Super Resolution - Romano, Isidoro, Milanfar
- ⭐ Reducing the Dimensionality of Data with Neural Networks - Hinton, Salakhutdinov
- ⭐ Google - Full Resolution Image Compression with Recurrent Neural Networks - Toderici, Vincent, Johnston, Hwang, Minnen, Shor, Covell
- ⭐ Early Visual Concept Learning with Unsupervised Deep Learning - Higgins, Matthey, Glorot, Pal, Uria, Blundell, Mohamed, Lerchner
- ⭐ Visualizing Data using t-SNE - van der Maaten, Hinton
- Deep Neural Networks are Easily Fooled: High Confidence Predictions for Unrecognizable Images - Nguyen, Yosinski, Clune
- Understanding Deep Image Representations by Inverting Them - Mahendran, Vedaldi
- Inverting Visual Representations with Convolutional Networks - Dosovitskiy, Brox
- Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps - Simonyan, Vedaldi, Zisserman
- Visualizing and Understanding Convolutional Networks - Zeiler, Fergus
- Striving for Simplicity: The All Convolutional Net - Springenberg, Dosovitskiy, Brox, Riedmiller
- Semi-Supervised Learning with Ladder Networks - Rasmus, Valpola, Honkala, Berglund, Raiko
- Delving Deep into GANs (Yet Another List)
- List of GAN papers
- ⭐ Generative Adversarial Networks - Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio
- MNIST Generative Adversarial Model in Keras - O'Shea
- Image Completion with Deep Learning in TensorFlow - B. Anos
- Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks - Denton, Chintala, Szlam, Fergus
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks - H.Zhang, Xu, Li, S.Zhang, Huang, Wang, Metaxas
- Generative Adversarial Text to Image Synthesis - Reed, Akata, Yan, Logeswaran, Schiele, Lee
- Image-to-Image Translation with Conditional Adversarial Nets - Isola, Zhu, Zhou, Efros
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks - Radford, Metz, Chintala
- DeepMind Lab
- 🕐 (White paper) TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
- Deep Learning Papers Reading Roadmap
- https://github.com/ujjwalkarn/Machine-Learning-Tutorials
- https://github.com/hangtwenty/dive-into-machine-learning
- http://karpathy.github.io/neuralnets/
- https://github.com/sjchoi86/dl_tutorials
- ⭐ RNN resources https://github.com/kjw0612/awesome-rnn
- List of DL resources https://github.com/gdb/kaggle#kaggle-solutions
- Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data - Papernot, Abadi, Erlingsson, Goodfellow, Talwar
- Deep Learning with Differential Privacy - Abadi, Chu, Goodfellow, McMahan, Mironov, Talwar, Zhang
- ⭐ The Predictron: End-To-End Learning and Planning - Silver, van Hasselt, Hessel, Schaul, Guez, Harley, Dulac-Arnold, Reichert, Rabinowitz, Barreto, Degris
- ⭐ Auto-Encoding Variational Bayes - Kingma, Welling
- ⭐ Spatial Transformer Networks - Jaderberg, Simonyan, Zisserman, Kavukcuoglu
- Neural networks with differentiable structure - Miconi
- Goedel Machines
- Learning with Hierarchical-Deep Models - Salakhutdinov, Tenenbaum, Torralba
- Neural Machine Translation - NIPS 2016 - Luong, Cho, Manning
- Faster R-CNN (Region-based CNN) Pedestrian and Car Detection
- Matching Networks for One Shot Learning - Vinyals, Blundell, Lillicrap, Kavukcuoglu, Wierstra
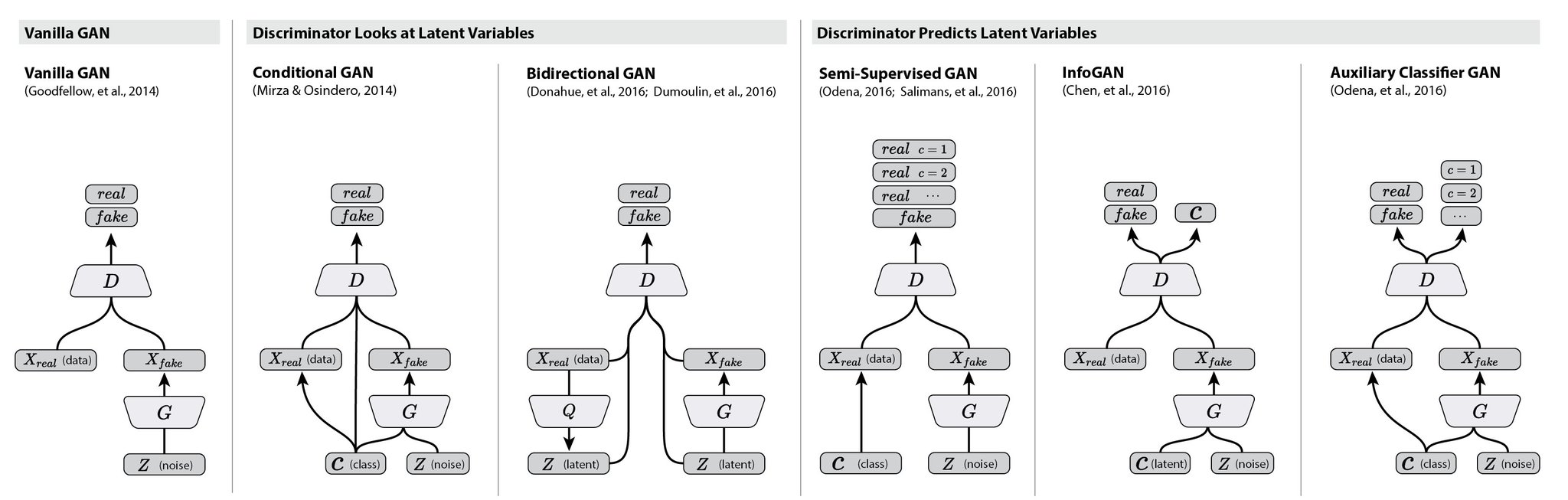
- Comparison of different GANs - C. Olah
- Video - Deep Unsupervised Learning - Salakhutdinov
- Slides
- Check related talks in video description
- Slides - Learning Deep Generative Models - Salakhutdinov
- Restricted Boltzmann Machines Hinton et al. 2006 & youtube from TUM DL event
{kind=link}
- Slides - Policy Optimization Tutorial - Abbeel, Schulman
- 😄 Slides - Towards biologically plausible deep learning - Bengio
- Slides - The Nuts and Bolts of Deep RL Research (no math) - Schulmann
- ⭐ Slides - Predictive Learning - Le Cun
Semi supervised learning - Chapelle et al. 2006. Also Laserre et al. 2006 & Larroselle and Bengio 2008
Boosting
What My Deep Model Doesn't Know... http://mlg.eng.cam.ac.uk/yarin/blog_3d801aa532c1ce.html by cambridge traditional ML person
Video captioning, attention over input frames: Yao et al, "Describing Videos by Exploiting Temporal Structure" -> Elegibility Traces
Attention: DRAW MNIST numbers. Better newer: DeepMind Jaderberg "Spatial Transformer Networks"
Multiple Object Recognition with Visual Attention (RNN policy instead of CNN) Ba et al.
Visual attention (Xu et al.)
Pointer networks (Vinyals)
Perpetual Learning Machines
Yoshua Bengio: segregated RNN modules with different timings (1995)?
https://www.quora.com/What-do-you-think-is-the-most-puzzling-thing-about-Deep-Learning-that-has-not-been-researched-enough-yet (time and brain)
Curriculum learning http://www.machinelearning.org/archive/icml2009/papers/119.pdf (teach first simple concepts)
Show and Tell: A Neural Image Caption Generator
Hinton's best for NLP in 2015: NiPS paper by Sutskever, Vinyals and Le (2014) and the papers from Yoshua Bengio's lab on machine translation using recurrent nets.
Investigate this source http://www.computervisiontalks.com
MIT autoencoder 3d angles rendering
NLP almost from scratch
Best --> “Glove: Global Vectors for Word Representation” by Pennington et al. (2014)
“Distributed Representations of Words and Phrases and their Compositionality” (Mikolov et al. 2013)
NNLM, HLBL, RNN, Skip-gram/CBOW, (Bengio et al; Collobert & Weston; Huang et al; Mnih & Hinton; Mikolov et al; Mnih & Kavukcuoglu)
Sequence-to-Sequence
1. MT Kalchbrenner et al, EMNLP 2013][Cho et al, EMLP 2014][Sutskever & Vinyals & Le, NIPs2014] Luong et al, ACL 2015][Bahdanau et al, ICLR 2015]
2. Image captions [Mao et al, ICLR 2015]IVinyals et al, CVPR 2015] Donahue et al, CVPR2015][Xu et al, ICML 2015]
3. Speech (Chorowsky et al, NIPS DL 2014][Chan et al, arxiv 2015]
4. Parsing [Vinyals & Kaiser et al, NIPs 2015]
5. Dialogue [Shang et al, AcL2015 Sordoni et al, NAACL 2015 Vinyals & Le, ICML DL 2015h
6. Video Generation Srivastava et al. ICML 201 Unive
7. Geometry Minyals & Fortunato & Jaitly, NIPs 2015]
Related Memory Models
* RNNSearch (Bahdanau et al.) for Machine Translation
+ Can be seen as a MemNN where memory goes back only
one sentence (writes embedding for each word).
+ At prediction time, reads memory and performs a soft max
to find best alignment (most useful words).
* Generating Sequences With RNNs (Graves, '13)
+ Also does alignment with previous sentence to generate
handwriting (so RNN knows what letter it's currently on)
* Neural Turing Machines (Graves et al., 14)
[on arxiv just 5 days after MemNNs!l
+ Has read and write operations over memory to perform
tasks (e.g. copy, sort, associative recall).
+ 128 memory slots in experiments; content addressing
computes a score for each slot 3 slow for large memory
*Earlier work by (Das '92), (Schmidhuber et al., 93),
DISCERN (Miikkulainen, '90) and others...
Information theory book http://www.inference.phy.cam.ac.uk/mackay/itila/ by MacKay and https://www.quora.com/What-is-a-good-explanation-of-Information-Theory refers to Shannon's book
Echo state networks - Jaeger, Herbert, and Harald Haas. “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.” science 304.5667 (2004): 78-80.
Kohonen, Teuvo. “Self-organized formation of topologically correct feature maps.” Biological cybernetics 43.1 (1982): 59-69.
Meetings?, EAMT, PhD, ListsOfLinks http://www.cis.uni-muenchen.de/~davidk/deep-munich/ http://www.cis.uni-muenchen.de/~fraser/nmt_seminar_2016_SS/nmt_reading_list.txt