- SECTION - Javascript Paradigms, Design Patterns and Best Practices
- What are Javascripts Paradigms
- 1. Object Oriented Programming (OOP) Paradigms
- What is OOP?
- 1. Inheritance
- 2. Encapsulation
- 3. Polymorphism
- Functional Programming Design
- Higher-order functions (using first-class functions)
- Functional composition
- Recursion
- Pure functions
- Currying
- Functional Programming in the Wild
- Procedural Programming
- How does Design Patterns fit into this?
- Application Architecture
- Paradigms vs Design Patterns vs Application architecture
- Paradigm Chart - (including declartative, impearal ,mono
- Paradigms - Advantages of Object Oriented Programming
- Declarative vs Imperative
- What’s the Difference Between classical & Prototypal Inheritance? - When is prototypal inheritance an appropriate choice?
- Loss vs tight comping?
- Sington Design Pattern
- Observer Design Pattern
- Revealing Module Pattern.
- What are the pros and cons of functional programming vs object-oriented programming?
- When is classical inheritance an appropriate choice?
- When is prototypal inheritance an appropriate choice?
- What are two-way data binding and one-way data flow, and how are they different?
- What are the pros and cons of monolithic vs microservice architectures? - Good to hear:
- What is asynchronous programming, and why is it important in JavaScript?
- What is asynchronous programming, and why is it important in JavaScript?
- Right way to create objects in JavaScript
- Don’t you need a constructor function to specify object instantiation behavior and handle object initialization?
- Don’t you need constructor functions for privacy in JavaScript?
- Does
newmean that code is using classical inheritance? - Is There a Big Performance Difference Between Classical and Prototypal Inheritance?
- Is There a Big Difference in Memory Consumption Between Classical and Prototypal?
- The Native APIs use Constructors. Aren’t they More Idiomatic than Factories?
- Isn’t Classical Inheritance More Idiomatic than Prototypal Inheritance?
- Doesn’t the Choice Between Classical and Prototypal Inheritance Depend on the Use Case?
- ES6 Has the
classkeyword. Doesn’t that mean we should all be using it? - What’s the Difference Between Class & Prototypal Inheritance?
- Issues with Class Inheritance
- Is All Inheritance Bad?
- What does “favor object composition over (class) inheritance” mean?
- Composition over Inheritance
- Disadvantages of Inheritance
- What are two benefits of inheritance? (Subtyping & Subclassing)
- Explain How Inheritance Works.
- Procedural Code
- Explain Composition.
- What are the Three Different Kinds of Prototypal Inheritance? (Prototype delegation,Concatenative inheritance,Functional inheritance) - Concatenative inheritance: - Prototype delegation: - Functional inheritance:
- How do you Promise Error Handle?
- What is Promise Chaining?
- How Do Promises Work?
- SECTION - Javascript
- What is deep binding and shallow binding?
- "this" keyword
- Get Min and max from array
- Check if two objects are the same.
- 1. What is the difference between undefined and not defined in JavaScript ?
- 2. What is the drawback of creating true private methods in JavaScript?
- 3. What is a “closure” in JavaScript, and what are some pitfalls of using them? Provide an example.
- 4. What the difference between constructor functions and function literal and when should you choice on over the other?
- 5. What is Event Delegation?
- 6. hat is Event Bubbling? And give an example.
- event.preventDefault() vs. return false
- What does encapsulation mean?
- What does Polymorphism mean?
- Explain the encapsulated anonymous function syntax.
- Target Vs eventTarget
- promise Vs callback
- Expressions V Declarations?
- Navigator vs window?
- var vs let vs const
- What are First Class Functions
- What are Function Composition
- Anonomus functions
- What is Associative Array? How do we use it?
- What is difference between private variable, public variable and static variable? How we achieve this in JS?
- How to add/remove properties to object in run time?
- How to achieve inheritance?
- What Lexical scope?
- How to extend built-in objects?
- Why extending array is bad idea?
- Difference between browser detection, feature detection and user agent string
- DOM Event Propagation
- Event Delegation
- Event bubbling V/s Event Capturing
- Graceful Degradation V/s Progressive Enhancement
- 1. What are the primitive and non-primitive data types, What is the difference between undefined and null.
- 2. Arrays - push,pop,shift,unshift,splice,delete,remove. The difference between delete and remove with array.
- 3. Lexical Scope vs dyamnic scope
- 4. What is self invoking anonymous function? IIFE
- 5. What is anonymous function?
- 6. Why do we need IIFE?
- 7. What is event bubbling?
- 8. Explain the phases of event handler in JS? or How the events are handled in JS?
- 9. What is an object literal?
- 10. Do we have classes in JS? Till ECMA5, there is no keyword called class to create classes, but you can use constructor
- 11. Explain "this" keyword
- Event delegation - Event Listeners to ul/li
- Write a function that will loop through a list of integers and print the index of each element after a 3 second delay.
- debouncing/Throttling
- find duplicate values in array
- Palindrome
- Dups in string
- string repeating letters
- Min/Max
- 12. By default "this" keyword refers to which object? - Window
- 13. What is strict mode?
- 14. Explain the term DOM?
- 15. How will make an AJAX call from JS?
- 16. Explain what is AJAX? Which object do you use to implement AJAX in JS?
- 17. Explain the use addEventListener method What is the significance of true or false value as third argument?
- 18. What is the purpose of "arguments" object in a function?
- 19. Why do we use call or apply method to call the function?
- 20. Difference between object created using object literal and using constructor
- 21. Explain prototype property of function
- 22. try catch finally - throw - error handling
- 23. Java script design patterns - http://addyosmani. com/resources/essentialjsdesignpatterns/book/#designpatternsjavascript
- 24. What is a namespace? How will you create a namespace in javascript?
- 25. How will you create a module in javascript?
- 26. What are Promises? [Async call Promise] - resolve state. Various states of promise.
- 27. Explain the difference between JSON and JSONP. - cross domain-
- 28. What is the cross domain reference issue? CORS Enabled WEB API.
- 29. What are recursive functions?
- 30. What are call-back functions? - calling a function as a parameter of other function.
- 31. How will you implement inheritance in Javascript? var child = Object.create(parent); Though there are many way
- 32. Explain the term hoisting.
- 33. Pub/Sub
- 34. Getter/Setter
- 35. Debounce/Throttle - https://sking7.github.io/articles/1248932487.html
- 36. Function Currying
- 37. Function Generators
- 37. Meaning of semantic tag, using display:none, visibility,
- 38. What is CSS box model?
- 39. localStorage API, practical way of implementation
- localStorage and sessionStorage
- Cookies
- localStorage vs. sessionStorage vs. Cookies
- Client-side vs. Server-side
- 40. What is difference between fluid and responsive layout?
- 41. Do you write anything in meta-tag while implementing responsive layout?
- 42. How do you make your site responsive? (what property of css you use to do so?)
- 43. HTML5 - what and why semantic tags
- 44. Various selectors like class,element,id,universal(*) etc. and syntax of applying classes in CSS
- 45. What are At-Rules (@Rules) in CSS? Name at least 2 with explanation other than @media
- 46. Pseudo classes and elements -definition,difference and practical example for both.
- 47. What is container collapse (issue or problem) in CSS
- 48. What is CSS reset?
- 49. What is clearfix?
- 50. Explain cross browser compatibility? Have you faced any problem implementing CSS with any browser, how did you fix it?
- 51. Do we need to have Jquery to use bootstrap? Explain the reason.
- 52. Create the same layout in bootstrap which is created responsive in previous assignment
- 53. Explain Bootstrap frame work and the grid system
- 55. What is the difference between padding and margin?
- 56. Explain CSS short-hands with example.
- 58. Explain padding:10 20 30 40, padding 10 20 30 and padding:10 20
- 59. Create 1 sample page (same page) with Fluid layout and Responsive layout
- 60. What's a test pyramid? How can you implement it when talking about HTTP APIs?
- 61. What is Dynamic typing
- 62. What is the difference between undefined and not defined in JavaScript ?
- 63. What is the drawback of creating true private methods in JavaScript?
- 64. What is a “closure” in JavaScript, and what are some pitfalls of using them? Provide an example.
- 65. Event Delegation
- 66. event.preventDefault() vs. return false
- 67. Describe event bubbling
- 68. What are Static Methods
- What is deep binding and shallow binding?
- "this" keyword
- SECTION - ReactJS / ES6 Iterview Questions
- Angular V React
- When to use store V State
- Add Third Party Libraries
- 2. JSX?
- 16. in Production (How do you tell React to build in Production mode and what will that do?)
- 18. Events (Describe how events are handled in React)
- how do parents communication with child
- what is High-Order Component
- 11. Refs
- 12. Keys (What are keys in React and why are they important?)
- 13. Controlled Vs Uncontrolled Components
- 19. createElement VS cloneElement?
- 17. React.Children.map Vs this,props.children.map
- State vs Props
- How to call a Child method from Parent
- How to call a Parent method from Child
- State Vs Stateless Components
- 10. Class Component VS Stateless (Functional) Components
- Dumb Components
- What are Smart components
- function component and class component
- 7. Stateless Components
- Element Vs Component
- 28. Reacts LYFECYCLE LIFECYCLE
- 20. setState (What happens when you call it? What is the second argument?,cad u call setState in render?)
- 23. MVC Vs Flux/Redux?
- 22. Redux - "single source of truth"
- 24. Redux - Actions
- 25. Redux - Action Creator
- 25. Redux - Reducers
- 26. Redux - Store
- 27. Redux - State Change
- Redux - Provider Component?
- Redux - connect?
- Redux - Setting up the folder structure?
- how they separate actions, reducers
- Setting up webpack, hot reloader, styles?
- Deploying?
- Random React/JSX specific errors?
- Nesting components?
- Redux boilerplate?
- what are the parts of React they don't like.
- where do they prefer to dispatch actions
- how they prefer to deal with asynchronous actions.
- how they prefer to split up components
- what do they think makes React a good tool
- SECTION - React Native Mobile
- 1. What is React Native?
- 2. Why open source?
- 3. How did Facebook write React Native for Android?
- 4. What’s the Challenges with React Native?
- 5. Advantages of React Native?
- 6. Handling Multiple Platforms?
- 7. React Native – Differences between Android and IOS?
- 8. Are all React components usable in React Native?
- 9. Passing functions between components in React and React Native?
- 10. Difference between React Native and NativeScript, which one do you prefer and why?
- 11. Are there any disadvantages to using React Native for mobile development?
- 12. What is the difference between using constructor vs getInitialState in React / React Native?
- 13. Re-Render on Changes?
- 14. what is a prop?
- 15. What is the difference between using constructor vs getInitialState in React / React Native?
- 16. What is the difference between React and React Native?
- 17. Is React Native a native Mobile App?
- 18. Can we use React Native code alongside with react native?
- 19. Do we use the same code base for Android and IOS?
- 20. Is React Native like other Hybrid Apps which are actually slower than Native mobile apps?
- SECTION - NodeJs
- What is the difference between localStorage, sessionStorage, session and cookies?
- Mention the steps by which you can async ?
- pros and cons
- How Node.js overcomes the problem of blocking of I/O operations?
- What is JSONP?
- operational Vs programmer errors?
- How does Node.js handle child threads?
- What is an error-first callback?
- How can you avoid callback hells?
- How can you listen on port 80 with Node?
- What's the event loop?
- What tools can be used to assure consistent style?
- What's the difference between operational and programmer errors?
- Why npm shrinkwrap is useful?
- What's a stub? Name a use case.
- What's a test pyramid? How can you implement it when talking about HTTP APIs?
- What's your favourite HTTP framework and why?
- How does Node.js handle child threads?
- What is the preferred method of resolving unhandled exceptions ?
- How does Node.js support multi-processor platforms, and does it fully utilize all processor resources?
- What is typically the first argument passed to a Node.js callback handler?
- What are Promises?
- When are background/worker processes useful? How can you handle worker tasks?
- How can you secure your HTTP cookies against XSS attacks?
- How can you make sure your dependencies are safe?
- What is Node.js?
- Why to use Node.js?
- Who developed Node.js?
- What are the features of Node.js?
- Explain REPL ?
- Explain variables ?
- What is the latest version of Node.js available?
- List out some REPL commands ?
- Mention the command to stop REPL ?
- Explain NPM ?
- Mention command to verify the NPM version ?
- How you can update NPM to new version ?
- Explain callback ?
- How Node.js can be made more scalable?
- Explain global installation of dependencies?
- Explain local installation of dependencies?
- Explain Package.JSON?
- Explain “Callback hell”?
- What are “Streams” in Node.JS?
- What you mean by chaining in Node.JS?
- Explain Child process module?
- Why to use exec method for Child process module?
- List out the parameters passed for Child process module?
- What is the use of method – “spawn()”?
- What is the use of method – “fork()”?
- Explain Piping Stream?
- What would be the limit for Piping Stream?
- Explain FS module ?
- Explain “Console” in Node.JS?
- Explain – “console.log(data)” statement in Node.JS?
- What you mean by “process”?
- Explain exit codes in Node.JS? List out some exit codes?
- List out the properties of process?
- Define OS module?
- What is the property of OS module?
- Explain “Path” module in Node.JS?
- Explain “Net” module in Node.JS?
- List out the differences between AngularJS and NodeJS?
- NodeJS is client side server side language?
- What are the advantages of NodeJS?
- In which scenarios NodeJS works well?
- What you mean by JSON?
- aScript Object Notation (JSON) is a practical, compound, widely popular data exchange format. This will enable
- Explain “Stub”?
- List out all Node.JS versions available?
- Explain “Buffer class” in Node.JS?
- How we can convert Buffer to JSON?
- How to concatenate buffers in NodeJS?
- How to compare buffers in NodeJS?
- How to copy buffers in NodeJS?
- What are the differences between “readUIntBE” and “writeIntBE” in Node.JS?
- Why to use
__filenamein Node.JS? - Why to use “SetTimeout” in Node.JS?
- Why to use “ClearTimeout” in Node.JS?
- Explain Web Server?
- List out the layers involved in Web App Architechure?
- Explain “Event Emitter” in Node.JS?
- Explain “NewListener” in Node.JS?
- Why to use Net.socket in Node.JS?
- Which events are emitted by Net.socket?
- Explain “DNS module” in Node.JS?
- Explain binding in domain module in Node.JS?
- Explain RESTful Web Service?
- How to truncate the file in Node.JS?
- How node.js works?
- What do you mean by the term I/O ?
- What does event-driven programming mean?
- Where can we use node.js?
- What is the advantage of using node.js?
- What are the two types of API functions?
- What is the biggest drawback of Node.js?
- What is control flow function?
- Explain the steps how “Control Flow” controls the functions calls?
- Why Node.js is single threaded?
- Does node run on windows?
- Can you access DOM in node?
- Using the event loop what are the tasks that should be done asynchronously?
- Why node.js is quickly gaining attention from JAVA programmers?
- What are the two arguments that async.queue takes?
- Event loop?
- Node.js vs Ajax?
- Node.js Challenges?
- "non-blocking" in node.js
- command to import external libraries?
- node.js Callbacks (and Advantages)
- What and Why Express Js?
- Express core features?
- How to install expressjs?
- Get variables in GET Method?
- Get POST a query in Express.js?
- output pretty html
- Get full url
- How to remove debugging from an Express app?
- Route - 404 errors?
- How to download a file?
- next() parameter
- config view engine
- app.use Vs app.get
- Logging
- CORS
- Explain Event Emitters in NodeJS
- SECTION - Javascript CI / Unit Testing
- SECTION - GraphQL
JavaScript is a multi-paradigm language that allows you to freely mix and match the 3 main types Javascript Paradigms, these include: Object Oriented Programming, Functional Programming and Procedural Programming
Object Oriented Programming (OOP) refers to using self-contained pieces of code to develop applications. We call these self-contained pieces of code objects, better known as Classes in most OOP programming languages and Functions in JavaScript.
Objects can be thought of as the main actors in an application, or simply the main “things” or building blocks that do all the work. As you know by now, objects are everywhere in JavaScript since every component in JavaScript is an Object, including Functions, Strings, and Numbers.
Object Oriented programming the code is divided up into classes (sometimes a language feature, sometimes not (e.g. javascript)), and typically supports inheritance and some type of polymorphism. The programmer creates the classes, and then instances of the classes (i.e. the objects) to carry out the operation of the program.
Through object literals (Encapsulation)
var myObj = {name: "Richard", profession: "Developer"};or constructor functions (Inheritance)
function Employee () {}
Employee.prototype.firstName = "Abhijit";
Employee.prototype.lastName = "Patel";
Employee.prototype.startDate = new Date();
Employee.prototype.signedNDA = true;
Employee.prototype.fullName = function () {
console.log (this.firstName + " " + this.lastName);
};
|
var abhijit = new Employee () //
console.log(abhijit.fullName()); // Abhijit Patel
console.log(abhijit.signedNDA); // trueto create objects in the OOP design pattern
The Three tenets of Object Oriented Programming (OOP):
Parasitic Combination Inheritance
Inheritance (objects can inherit features from other objects)
Inheritance refers to an object being able to inherit methods and properties from a parent object (a Class in other OOP languages, or a Function in JavaScript).
Lets say we have a quiz application to make different types of Questions. We will implement a MultipleChoiceQuestion function and a DragDropQuestion function. To implement these, it would not make sense to put the properties and methods outlined above (that all questions will use) inside the MultipleChoiceQuestion and DragDropQuestion functions separately, repeating the same code. This would be redundant.
Instead, we will leave those properties and methods (that all questions will use) inside the Question object and make the MultipleChoiceQuestion and DragDropQuestion functions inherit those methods and properties.
This is where inheritance is important: we can reuse code throughout our application effectively and better maintain our code.
An instance is an implementation of a Function. In simple terms, it is a copy (or “child”) of a Function or object. For example:
// Tree is a constructor function because we will use new keyword to invoke it.
function Tree (typeOfTree) {}
// bananaTree is an instance of Tree.
var bananaTree = new Tree ("banana");In the preceding example, bananaTree is an object that was created from the Tree constructor function. We say that the bananaTree object is an instance of the Tree object. Tree is both an object and a function, because functions are objects in JavaScript. bananaTree can have its own methods and properties and inherit methods and properties from the Tree object, as we will discuss in detail when we study inheritance below.
using the Parasitic Combination Inheritance Using the *Object.create() Method
if (typeof Object.create !== 'function') {
Object.create = function (o) {
function F() {
}
F.prototype = o;
return new F();
};
}Let’s quickly understand it is doing.
Object.create = function (o) {
//It creates a temporary constructor F()
function F() {
}
//And set the prototype of the this constructor to the parametric (passed-in) o object
//so that the F() constructor now inherits all the properties and methods of o
F.prototype = o;
//Then it returns a new, empty object (an instance of F())
//Note that this instance of F inherits from the passed-in (parametric object) o object.
//Or you can say it copied all of the o object's properties and methods
return new F();
}Encapsulation (each object is responsible for specific tasks).
Combination Constructor/Prototype Pattern
Encapsulation refers to enclosing all the functionalities of an object within that object so that the object’s internal workings (its methods and properties) are hidden from the rest of the application.
This allows us to abstract or localize specific set of functionalities on objects.
To implement encapsulation in JavaScript, we have to define the core methods and properties on that object. To do this, we will use the best pattern for encapsulation in JavaScript: the Combination Constructor/Prototype Pattern.
function User (theName, theEmail) {
this.name = theName;
this.email = theEmail;
this.quizScores = [];
this.currentScore = 0;
}
User.prototype = {
constructor: User,
saveScore:function (theScoreToAdd) {
this.quizScores.push(theScoreToAdd)
},
showNameAndScores:function () {
var scores = this.quizScores.length > 0 ? this.quizScores.join(",") : "No Scores Yet";
return this.name + " Scores: " + scores;
},
changeEmail:function (newEmail) {
this.email = newEmail;
return "New Email Saved: " + this.email;
}
} when you want to create objects with similar functionalities (to use the same methods and properties), you encapsulate the main functionalities in a Function and you use that Function’s constructor to create the objects. This is the essence of encapsulation. And it is this need for encapsulation that we are concerned with and why we are using the Combination Constructor/Prototype Pattern.
Polymorphism (objects can share the same interface—how they are accessed and used—while their underlying implementation of the interface may differ)
In JavaScript it is a bit more difficult to see the effects of polymorphism because the more classical types of polymorphism are more evident in statically-typed systems, whereas JavaScript has a dynamic type system.
Polymorphism foster many good attributes in software, among other things it fosters modularity and reusability and make the type system more flexible and malleable
This is not simple to answer, different languages have different ways to implement it. In the case of JavaScript, as mentioned above, you will see it materialize in the form of type hierarchies using prototypal inheritance and you can also exploit it using duck typing.
What is polymorphism in Javascript? - https://stackoverflow.com/questions/27642239/what-is-polymorphism-in-javascript
functional languages, the state changes on the computer are very heavily controlled by the language itself. Functions are first class objects, although not all languages where functions are first class objects are functional programming language (this topic is one of good debate). Code written with a functional languages involves lots of nested functions, almost every step of the program is new function invocation.
The Five tenets of Functional Programming:
you could simulate first-class functions using anonymous classes. Those first-class functions are what makes functional programming possible in JavaScript.
We already know that JavaScript has first-class functions that can be passed around just like any other value. So, it should come as no surprise that we can pass a function to another function. We can also return a function from a function.
You're probably already familiar with several higher order functions that exist on the Array.prototype. For example, filter, map, and reduce, among others.
const vehicles = [
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
];
let Fords=vehicles.filter(x=>x.make==="Ford")
console.log(Fords) // [{'make':'Ford','model':'F-150','type':'truck','price':27110},{'make':'Ford','model':'Fusion','type':'sedan','price':22120},{'make':'Ford','model':'Explorer','type':'suv','price':31660}]"or
const averageSUVPrice = vehicles
.filter(v => v.type === 'suv')
.map(v => v.price)
.reduce((sum, price, i, array) => sum + price / array.length, 0);
console.log(averageSUVPrice); // 33399This just means your combining small function to make a large function
const vehicles = [
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
];
const Makes=(arr,make)=>arr.filter(x=>x.make===make)
const CarType=(arr,type)=>arr.filter(x=>x.type===type)
let ArrayOfAllFords=Makes(vehicles,"Fords")
let ArrayOfAllFordTrucks=Makes(vehicles,"trucks")
//OUTPUTS
// ArrayOfAllFords is => [{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 }, { make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 }, { make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }]
//ArrayOfAllFordTrucks is => [{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 }]Easy to isolate, test, reuse.
Let's say that you would like to implement a function that computes the factorial of a number. Let's recall the definition of factorial from mathematics:
n! = n * (n-1) * (n-2) * ... * 1.
That is, n! is the product of all the integers from n down to 1. We can write a loop that computes that for us easily enough.
function iterativeFactorial(n) {
let product = 1;
for (let i = 1; i <= n; i++) {
product *= i;
}
return product;
}to iterate over something until its done
A pure function must satisfy both of the following properties:
Referential transparency: The function always gives the same return value for the same arguments. This means that the function cannot depend on any mutable state. Side-effect free: The function cannot cause any side effects. Side effects may include I/O (e.g., writing to the console or a log file), modifying a mutable object, reassigning a variable, etc.
Things that are not pure are things that use:
- console.log
- element.addEventListener
- Math.random
- Date.now
- Data from Network / API Calls
TLDR; same thing in same thing out every time.
It's stateless, with no side-effects
see the filter methods in the "Functional composition" and "Higher-order functions" examples.
Easy to isolate, test, reuse.
and
** Immutability** - Immutability means "unchange". So if you put the same thing in you should get the same thing out every time. like in the "Functional composition" and "Higher-order functions" examples.
Currying is when you break down a function that takes multiple arguments into a series of functions that take part of the arguments.
Here's an example in JavaScript:
function add (a, b) {
return a + b;
}
add(3, 4); returns 7
This is a function that takes two arguments, a and b, and returns their sum. We will now curry this function:
function add (a) {
return function (b) {
return a + b;
}
}
This is a function that takes one argument, a, and returns a function that takes another argument, b, and that function returns their sum.
add(3)(4);
var add3 = add(3);
add3(4);
The first statement returns 7, like the add(3, 4) statement. The second statement defines a new function called add3 that will add 3 to its argument. This is what some people may call a closure. The third statement uses the add3 operation to add 3 to 4, again producing 7 as a result.
Currying is often used to do partial application, but it's not the only way. This makes testing easier and makes it more modular.
## Functional Programming in the Wild Recently there has been a growing trend toward functional programming. In frameworks such as Angular and React, you'll actually get a performance boost by using immutable data structures.
Resources: https://stackoverflow.com/questions/1112773/what-are-the-core-concepts-in-functional-programming
procedural programming, C programs and bash scripting are good examples, you just say do step 1, do step 2, etc, without creating classes and whatnot.
A design pattern is a useful abstraction that can be implemented in any language. It is a "pattern" for doing things. Like if you have a bunch of steps you want to implement, you might use the 'composite' and 'command' patterns so make your implementation more generic.
Think of a pattern as an established template for solving a common coding task in a generic way.
Application Architecture, rakes into consideration how you build a system to do stuff.
So, for a web application, the architecture might involve x number of gateways behind a load balancer, that asynchronously feed queues. Messages are picked up by y processes running on z machines, with 1 primary db and a backup slave. Application architecture involves choosing the platform, languages, frameworks used. This is different than software architecture, which speaks more to how to actually implement the program given the software stack.
Paradigms are all-encompassing views of computation that affect not only what kinds of things you can do, but even what kinds of thoughts you can have; functional programming is an example of a programming paradigm.
Design Patterns are simply well-established programming tricks, codified in some semi-formal manner.
Application architecture is a broad term describing how complex applications are organised.
Javascript is a multi-paradigm programming language that supports imperative/and procedural programs Paradigms include:
-
OOP - http://javascriptissexy.com/oop-in-javascript-what-you-need-to-know/
-
Functional - https://opensource.com/article/17/6/functional-javascript
-
Imperial
-
procedural
| Paradigms | Declarative (Better) | Imperative |
|---|---|---|
| Description | Declarative Programing is "The What". A way of doing something without explicitly saying what it is your doing as way to make something multi-use. | Imperative Programing is "The How" Uses sequences of implicit statements. |
| Examples / Related | Function Programming higher order functions - a function you can pass into another function to make a big function (functions compassion) functions compassion combining functions into small reusable components to create a big functions Micro-services - Apps that are built from small self contained apps that run in their own memory space. Cons (in Addition to Declarative Cons): *Cross Cutting Concerns - (eg. Logging HTTP calls) *Dependent on outside resources Loose Coupling(good) - A System or Pattern where components are self contained. |
OOP Monolithic (bad) - Apps written in one cohesive unit that share memory space and resources. Pros (in Addition to Imperative Pros): * Faster - because it uses a shared memory space. * Not Dependent on outside resources Tight Couplings (bad) - A System or Pattern where components are self contained. |
| Pros | Because it uses small self contained pieces it's: * Avoids shared state * Scalable * Easily Recomposed * Easy To Test * Better Organized * Easy to isolate * Uses Immutable (Not Changing) State *Encourages Decoupling (keeping things separate) |
Because imperative programming uses implicit instructions it's: * Readability * Straight-forward -Easy to understand |
| Cons | * Poor(er) Readability - Everything can become abstract as it can be more theoretical or academic | * Usually dependent on shared state * Gets tightly coupled * Difficult to scale *Difficult to test * Classes are dependent on each other and one failed component will bring the whole system down. * Objects are tacked together (OOP) |
OOP* - uses objects with prototypal inhieratice, data is one big object/function
pros:
- uses imperative style cons:
- depends on shared shtate
Function Programming - uses functions and avoids shared state. A method of transforming data through an expression with limited side effects, usually uses seperate functions for clariry pros: uses functions and avoids shared state. uses immutable data structures, encourages decouping, aviods shared state
One of the principal advantages of object-oriented programming techniques over procedural programming techniques is that they enable programmers to create modules that do not need to be changed when a new type of object is added. A programmer can simply create a new object that inherits many of its features from existing objects. This makes object-oriented programs easier to modify.
Functional programming is a declarative paradigm, meaning that the program logic is expressed without explicitly describing the flow control. Declarative/functional programming? Functional programming uses functions and avoids shared state & mutable data.
Declarative programs abstract the flow control process, and instead spend lines of code describing the data flow: What to do. The how gets abstracted away. Declarative code relies more on expressions. An expression is a piece of code which evaluates to some value. Expressions are usually some combination of function calls, values, and operators which are evaluated to produce the resulting value.
Imperative code frequently utilizes statements. A statement is a piece of code which performs some action. Examples of commonly used statements include for, if, switch, throw, etc… Imperative programs spend lines of code describing the specific steps used to achieve the desired results — the flow control: How to do things.
For example, this imperative mapping takes an array of numbers and returns a new array with each number multiplied by 2:
Class Inheritance: A class is like a blueprint — a description of the object to be created. Classes inherit from classes and create subclass relationships: hierarchical class taxonomies.
Instances are typically instantiated via constructor functions with the new keyword.
Prototypal Inheritance: A prototype is a working object instance. Objects inherit directly from other objects.
Instances may be composed from many different source objects, allowing for easy selective inheritance and a flat [[Prototype]] delegation hierarchy. In other words, class taxonomies are not an automatic side-effect of prototypal OO: a critical distinction. Instances are typically instantiated via factory functions, object literals, or Object.create().
There is more than one type of prototypal inheritance:
-
Delegation (i.e., the prototype chain). -
Concatenative (i.e. mixins, `Object.assign()`). -
Functional (Not to be confused with functional programming. A function used to create a closure for private state/encapsulation).
Each type of prototypal inheritance has its own set of use-cases, but all of them are equally useful in their ability to enable composition, which creates has-a or uses-a or can-do relationships as opposed to the is-a relationship created with class inheritance.
tight comping - Js only works Loose Coupling means reducing dependencies of a class that use a different class directly. So if you test in a Dif browser it won’t work
Tight coupling, classes and objects are dependent on one another.
A Singleton only allows for a single instantiation, but many instances of the same object. The Singleton restricts clients from creating multiple objects, after the first object created, it will return instances of itself.
There are many times when one part of the application changes, other parts needs to be updated. In AngularJS, if the $scope object updates, an event can be triggered to notify another component. The observer pattern incorporates just that - if an object is modified it broadcasts to dependent objects that a change has occurred.
The purpose is to maintain encapsulation and reveal certain variables and methods returned in an object literal.
OOP Pros: It’s easy to understand the basic concept of objects and easy to interpret the meaning of method calls. OOP tends to use an imperative style rather than a declarative style, which reads like a straight-forward set of instructions for the computer to follow. OOP Cons: OOP Typically depends on shared state. Objects and behaviors are typically tacked together on the same entity, which may be accessed at random by any number of functions with non-deterministic order, which may lead to undesirable behavior such as race conditions. FP Pros: Using the functional paradigm, programmers avoid any shared state or side-effects, which eliminates bugs caused by multiple functions competing for the same resources. With features such as the availability of point-free style (aka tacit programming), functions tend to be radically simplified and easily recomposed for more generally reusable code compared to OOP. FP also tends to favor declarative and denotational styles, which do not spell out step-by-step instructions for operations, but instead concentrate on what to do, letting the underlying functions take care of the how. This leaves tremendous latitude for refactoring and performance optimization, even allowing you to replace entire algorithms with more efficient ones with very little code change. (e.g., memoize, or use lazy evaluation in place of eager evaluation.) Computation that makes use of pure functions is also easy to scale across multiple processors, or across distributed computing clusters without fear of threading resource conflicts, race conditions, etc… FP Cons: Over exploitation of FP features such as point-free style and large compositions can potentially reduce readability because the resulting code is often more abstractly specified, more terse, and less concrete. More people are familiar with OO and imperative programming than functional programming, so even common idioms in functional programming can be confusing to new team members. FP has a much steeper learning curve than OOP because the broad popularity of OOP has allowed the language and learning materials of OOP to become more conversational, whereas the language of FP tends to be much more academic and formal. FP concepts are frequently written about using idioms and notations from lambda calculus, algebras, and category theory, all of which requires a prior knowledge foundation in those domains to be understood.
The answer is never, or almost never. Certainly never more than one level. Multi-level class hierarchies are an anti-pattern. I’ve been issuing this challenge for years, and the only answers I’ve ever heard fall into one of several common misconceptions. More frequently, the challenge is met with silence. “If a feature is sometimes useful and sometimes dangerous and if there is a better option then always use the better option.” ~ Douglas Crockford
There is more than one type of prototypal inheritance:
Delegation (i.e., the prototype chain).
Concatenative (i.e. mixins, Object.assign()).
Functional (Not to be confused with functional programming. A function used to create a closure for private state/encapsulation).
Each type of prototypal inheritance has its own set of use-cases, but all of them are equally useful in their ability to enable composition, which creates has-a or uses-a or can-do relationships as opposed to the is-a relationship created with class inheritance.
Good to hear:
In situations where modules or functional programming don’t provide an obvious solution.
When you need to compose objects from multiple sources.
Any time you need inheritance.
Two way data binding means that UI fields are bound to model data dynamically such that when a UI field changes, the model data changes with it and vice-versa. One way data flow means that the model is the single source of truth. Changes in the UI trigger messages that signal user intent to the model (or “store” in React). Only the model has the access to change the app’s state. The effect is that data always flows in a single direction, which makes it easier to understand. One way data flows are deterministic, whereas two-way binding can cause side-effects which are harder to follow and understand. Good to hear: React is the new canonical example of one-way data flow, so mentions of React are a good signal. Cycle.js is another popular implementation of uni-directional data flow. Angular is a popular framework which uses two-way binding.
A monolithic architecture means that your app is written as one cohesive unit of code whose components are designed to work together, sharing the same memory space and resources. A microservice architecture means that your app is made up of lots of smaller, independent applications capable of running in their own memory space and scaling independently from each other across potentially many separate machines. Monolithic Pros: The major advantage of the monolithic architecture is that most apps typically have a large number of cross-cutting concerns, such as logging, rate limiting, and security features such audit trails and DOS protection. When everything is running through the same app, it’s easy to hook up components to those cross-cutting concerns. There can also be performance advantages, since shared-memory access is faster than inter-process communication (IPC). Monolithic cons: Monolithic app services tend to get tightly coupled and entangled as the application evolves, making it difficult to isolate services for purposes such as independent scaling or code maintainability. Monolithic architectures are also much harder to understand, because there may be dependencies, side-effects, and magic which are not obvious when you’re looking at a particular service or controller. Microservice pros: Microservice architectures are typically better organized, since each microservice has a very specific job, and is not concerned with the jobs of other components. Decoupled services are also easier to recompose and reconfigure to serve the purposes of different apps (for example, serving both the web clients and public API). They can also have performance advantages depending on how they’re organized because it’s possible to isolate hot services and scale them independent of the rest of the app. Microservice cons: As you’re building a new microservice architecture, you’re likely to discover lots of cross-cutting concerns that you did not anticipate at design time. A monolithic app could establish shared magic helpers or middleware to handle such cross-cutting concerns without much effort. In a microservice architecture, you’ll either need to incur the overhead of separate modules for each cross-cutting concern, or encapsulate cross-cutting concerns in another service layer that all traffic gets routed through. Eventually, even monolthic architectures tend to route traffic through an outer service layer for cross-cutting concerns, but with a monolithic architecture, it’s possible to delay the cost of that work until the project is much more mature. Microservices are frequently deployed on their own virtual machines or containers, causing a proliferation of VM wrangling work. These tasks are frequently automated with container fleet management tools.
Positive attitudes toward microservices, despite the higher initial cost vs monolthic apps. Aware that microservices tend to perform and scale better in the long run. Practical about microservices vs monolithic apps. Structure the app so that services are independent from each other at the code level, but easy to bundle together as a monolithic app in the beginning. Microservice overhead costs can be delayed until it becomes more practical to pay the prive
Synchronous programming means that, barring conditionals and function calls, code is executed sequentially from top-to-bottom, blocking on long-running tasks such as network requests and disk I/O. Asynchronous programming means that the engine runs in an event loop. When a blocking operation is needed, the request is started, and the code keeps running without blocking for the result. When the response is ready, an interrupt is fired, which causes an event handler to be run, where the control flow continues. In this way, a single program thread can handle many concurrent operations. User interfaces are asynchronous by nature, and spend most of their time waiting for user input to interrupt the event loop and trigger event handlers. Node is asynchronous by default, meaning that the server works in much the same way, waiting in a loop for a network request, and accepting more incoming requests while the first one is being handled. This is important in JavaScript, because it is a very natural fit for user interface code, and very beneficial to performance on the server. Good to hear: An understanding of what blocking means, and the performance implications. An understanding of event handling, and why its important for UI code.
here are several right ways to create objects in JavaScript. The first and most common is an object literal. It looks like this (in ES6):
// ES6 / ES2015, because 2015.
let mouse = {
furColor: 'brown',
legs: 4,
tail: 'long, skinny',
describe () {
return `A mouse with ${this.furColor} fur,
${this.legs} legs, and a ${this.tail} tail.`;
}
};Of course, object literals have been around a lot longer than ES6, but they lack the method shortcut seen above, and you have to use var instead of let. Oh, and that template string thing in the .describe() method won’t work in ES5, either.
You can attach delegate prototypes with Object.create() (an ES5 feature):
let animal = {
animalType: 'animal',
describe () {
return `An ${this.animalType}, with ${this.furColor} fur,
${this.legs} legs, and a ${this.tail} tail.`;
}
};
let mouse = Object.assign(Object.create(animal), {
animalType: 'mouse',
furColor: 'brown',
legs: 4,
tail: 'long, skinny'
});Let’s break this one down a little. animal is a delegate prototype. mouse is an instance. When you try to access a property on mouse that isn’t there, the JavaScript runtime will look for the property on animal (the delegate).
Object.assign() is a new ES6 feature championed by Rick Waldron that was previously implemented in a few dozen libraries. You might know it as $.extend() from jQuery or _.extend() from Underscore. Lodash has a version of it called assign(). You pass in a destination object, and as many source objects as you like, separated by commas. It will copy all of the enumerable own properties by assignment from the source objects to the destination objects with last in priority. If there are any property name conflicts, the version from the last object passed in wins.
Object.create() is an ES5 feature that was championed by Douglas Crockford so that we could attach delegate prototypes without using constructors and the new keyword.
I’m skipping the constructor function example because I can’t recommend them. I’ve seen them abused a lot, and I’ve seen them cause a lot of trouble. It’s worth noting that a lot of smart people disagree with me. Smart people will do whatever they want.
Wise people will take Douglas Crockford’s advice:
“If a feature is sometimes dangerous, and there is a better option, then always use the better option.”
Don’t you need a constructor function to specify object instantiation behavior and handle object initialization?
No. Any function can create and return objects. When it’s not a constructor function, it’s called a factory function. The Better Option
I usually don’t name my factories “factory” — that’s just for illustration. Normally I just would have called it mouse().
No. In JavaScript, any time you export a function, that function has access to the outer function’s variables. When you use them, the JS engine creates a closure. Closures are a common pattern in JavaScript, and they’re commonly used for data privacy. Closures are not unique to constructor functions. Any function can create a closure for data privacy:
let animal = {
animalType: 'animal',
describe () {
return `An ${this.animalType} with ${this.furColor} fur,
${this.legs} legs, and a ${this.tail} tail.`;
}
};
let mouseFactory = function mouseFactory () {
let secret = 'secret agent';
return Object.assign(Object.create(animal), {
animalType: 'mouse',
furColor: 'brown',
legs: 4,
tail: 'long, skinny',
profession () {
return secret;
}
});
};
let james = mouseFactory();No.
The new keyword is used to invoke a constructor. What it actually does is:
Create a new instance
Bind this to the new instance
Reference the new object’s delegate [[Prototype]] to the object referenced by the constructor function’s prototype property.
Reference the new object’s .constructor property to the constructor that was invoked.
Names the object type after the constructor, which you’ll notice mostly in the debugging console. You’ll see [Object Foo], for example, instead of [Object object].
Allows instanceof to check whether or not an object’s prototype reference is the same object referenced by the .prototype property of the constructor.
instanceof lies
Let’s pause here for a moment and reconsider the value of instanceof. You might change your mind about its usefulness.
Important: instanceof does not do type checking the way that you expect similar checks to do in strongly typed languages. Instead, it does an identity check on the prototype object, and it’s easily fooled. It won’t work across execution contexts, for instance (a common source of bugs, frustration, and unnecessary limitations). For reference, an example in the wild, from bacon.js.
It’s also easily tricked into false positives (and more commonly) false negatives from another source. Since it’s an identity check against a target object’s .prototype property, it can lead to strange things:
> function foo() {}
> var bar = { a: ‘a’};
> foo.prototype = bar; // Object {a: “a”}
> baz = Object.create(bar); // Object {a: “a”}
> baz instanceof foo // true. oops.That last result is completely in line with the JavaScript specification. Nothing is broken — it’s just that instanceof can’t make any guarantees about type safety. It’s easily tricked into reporting both false positives, and false negatives.
Besides that, trying to force your JS code to behave like strongly typed code can block your functions from being lifted to generics, which are much more reusable and useful.
instanceof limits the reusability of your code, and potentially introduces bugs into the programs that use your code.
new is weird
WAT? new also does some weird stuff to return values. If you try to return a primitive, it won’t work. If you return any other arbitrary object, that does work, but this gets thrown away, breaking all references to it (including .call() and .apply()), and breaking the link to the constructor’s .prototype reference.
No.
You may have heard of hidden classes, and think that constructors dramatically outperform objects instantiated with Object.create(). Those performance differences are dramatically overstated.
A small fraction of your application’s time is spent running JavaScript, and a miniscule fraction of that time is spent accessing properties on objects. In fact, the slowest laptops being produced today can access millions of properties per second.
That’s not your app’s bottleneck. Do yourself a favor and profile your app to discover your real performance bottlenecks. I’m sure there are a million things you should fix before you spend another moment thinking about micro-optimizations.
Not convinced? For a micro-optimization to have any appreciable impact on your app, you’d have to loop over the operation hundreds of thousands of times, and the only differences in micro-optimization you should ever be concerned about are the ones that are orders of magnitude apart.
Rule of thumb: Profile your app and eliminate as many loading, networking, file I/O, and rendering bottlenecks as you can find. Then and only then should you start to think about a micro-optimization.
Can you tell the difference between .0000000001 seconds and .000000001 seconds? Neither can I, but I sure can tell the difference between loading 10 small icons or loading one web font, instead!
If you do profile your app and find that object creation really is a bottleneck, the fastest way to do it is not by using new and classical OO. The fastest way is to use object literals. You can do so in-line with a loop and add objects to an object pool to avoid thrashing from the garbage collector. If it’s worth abandoning prototypal OO over perf, it’s worth ditching the prototype chain and inheritance altogether to crank out object literals.
But Google said class is fast…
WAT? Google is building a JavaScript engine. You are building an application. Obviously what they care about and what you care about should be very different things. Let Google handle the micro-optimizations. You worry about your app’s real bottlenecks. I promise, you’ll get a whole lot better ROI focusing on just about anything else.
No.
Both can use delegate prototypes to share methods between many object instances. Both can use or avoid wrapping a bunch of state into closures.
In fact, if you start with factory functions, it’s easier to switch to object pools so that you can manage memory more carefully and avoid being blocked periodically by the garbage collector. For more on why that’s awkward with constructors, see the WAT? note under “Does new mean that code is using classical inheritance?”
In other words, if you want the most flexibility for memory management, use factory functions instead of constructors and classical inheritance.
“…if you want the most flexibility for memory management,
use factory functions…”
Factories are extremely common in JavaScript. For instance, the most popular JavaScript library of all time, jQuery exposes a factory to users. John Resig has written about the choice to use a factory and prototype extension rather than a class. Basically, it boils down to the fact that he didn’t want callers to have to type new every time they made a selection. What would that have looked like?
/**
classy jQuery - an alternate reality where jQuery really sucked and never took off
OR
Why nobody would have liked jQuery if it had exported a class instead of a factory.
**/
// This just looks stupid. Are we creating a new DOM element
// with id="foo"? Nope. We're selecting an existing DOM element
// with id="foo", and wrapping it in a jQuery object instance.
var $foo = new $('#foo');
// Besides, it's a lot of extra typing with literally ZERO gain.
var $bar = new $('.bar');
var $baz = new $('.baz');
// And this is just... well. I don't know what.
var $bif = new $('.foo').on('click', function () {
var $this = new $(this);
$this.html('clicked!');
});What else exposes factories?
React React.createClass() is a factory.
Angular uses classes & factories, but wraps them all with a factory in the Dependency Injection container. All providers are sugar that use the .provider() factory. There’s even a .factory() provider, and even the .service() provider wraps normal constructors and exposes … you guessed it: A factory for DI consumers.
Ember Ember.Application.create(); is a factory that produces the app. Rather than creating constructors to call with new, the .extend() methods augment the app.
Node core services like http.createServer() and net.createServer() are factory functions.
Express is a factory that creates an express app.
As you can see, virtually all of the most popular libraries and frameworks for JavaScript make heavy use of factory functions. The only object instantiation pattern more common than factories in JS is the object literal.
JavaScript built-ins started out using constructors because Brendan Eich was told to make it look like Java. JavaScript continues to use constructors for self-consistency. It would be awkward to try to change everything to factories and deprecate constructors now.
No.
Every time I hear this misconception I am tempted to say, “do u even JavaScript?” and move on… but I’ll resist the urge and set the record straight, instead.
Don’t feel bad if this is your question, too. It’s not your fault. JavaScript Training Sucks!
The answer to this question is a big, gigantic
No… (but)
Prototypes are the idiomatic inheritance paradigm in JS, and class is the marauding invasive species.
A brief history of popular JavaScript libraries:
In the beginning, everybody wrote their own libs, and open sharing wasn’t a big thing. And then Prototype came along. (The name is a big hint here). Prototype did its magic by extending built-in delegate prototypes using concatenative inheritance.
Later we all realized that modifying built-in prototypes was an anti-pattern when native alternatives and conflicting libs broke the internet. But that’s a different story.
Next on the JS lib popularity roller coaster was jQuery. jQuery’s big claim to fame was jQuery plugins. They worked by extending jQuery’s delegate prototype using concatenative inheritance.
Are you starting to sense a pattern here?
jQuery remains the most popular JavaScript library ever made. By a HUGE margin. HUGE.
This is where things get muddled and class extension starts to sneak into the language… John Resig (author of jQuery) wrote about Simple Class Inheritance in JavaScript, and people started actually using it, even though John Resig himself didn’t think it belonged in jQuery (because prototypal OO did the same job better).
Semi-popular Java-esque frameworks like ExtJS appeared, ushering in the first kinda, sorta, not-really mainstream uses of class in JavaScript. This was 2007. JavaScript was 12 years old before a somewhat popular lib started exposing JS users to classical inheritance.
Three years later, Backbone exploded and had an .extend() method that mimicked class inheritance, including all its nastiest features such as brittle object hierarchies. That’s when all hell broke loose.
~100kloc app starts using Backbone. A few months in I’m debugging a 6-level hierarchy trying to find a bug. Stepped through every line of constructor code up the super chain. Found and fixed the bug in the top level base class. Then had to fix a lot of child classes because they depended on the buggy behavior of the base class. Hours of frustration that should have been a 5 minute fix.
This is not JavaScript. I was suddenly living in Java hell again. That lonely, dark, scary place where any quick movements could cause entire hierarchies to shudder and collapse in coalescing, tight-coupled convulsions.
These are the monsters rewrites are made of.
But, squirreled away in the Backbone docs, a ray of golden sunshine:
// A ray of sunshine in the belly of
// the beast...
var object = {};
_.extend(object, Backbone.Events);
object.on("alert", function(msg) {
alert("Triggered " + msg);
});
object.trigger("alert", "an event");Our old friend, concatenative inheritance saving the day with a Backbone.Events mixin.
It turns out, if you look at any non-trivial JavaScript library closely enough, you’re going to find examples of concatenation and delegation. It’s so common and automatic for JavaScript developers to do these things that they don’t even think of it as inheritance, even though it accomplishes the same goal.
Inheritance in JS is so easy
it confuses people who expect it to take effort.
To make it harder, we added class.
And how did we add class? We built it on top of prototypal inheritance using delegate prototypes and object concatenation, of course!
That’s like driving your Tesla Model S to a car dealership and trading it in for a rusted out 1983 Ford Pinto.
No.
Prototypal OO is simpler, more flexible, and a lot less error prone. I have been making this claim and challenging people to come up with a compelling class use case for many years. Hundreds of thousands of people have heard the call. The few answers I’ve received depended on one or more of the misconceptions addressed in this article.
I was once a classical inheritance fan. I bought into it completely. I built object hierarchies everywhere. I built visual OO Rapid Application Development tools to help software architects design object hierarchies and relationships that made sense. It took a visual tool to truly map and graph the object relationships in enterprise applications using classical inheritance taxonomies.
Soon after my transition from C++ and Java to JavaScript, I stopped doing all of that. Not because I was building less complex apps (the opposite is true), but because JavaScript was so much simpler, I had no more need for all that OO design tooling.
I used to do application design consulting and frequently recommend sweeping rewrites. Why? Because all object hierarchies are eventually wrong for new use cases.
I wasn’t alone. In those days, complete rewrites were very common for new software versions. Most of those rewrites were necessitated by legacy lock-in caused by arthritic, brittle class hierarchies. Entire books were written about OO design mistakes and how to avoid them or refactor away from them. It seemed like every developer had a copy of “Design Patterns” on their desk.
I recommend that you follow the Gang of Four’s advice on this point:
“Favor object composition over class inheritance.”
In Java, that was harder than class inheritance because you actually had to use classes to achieve it.
In JavaScript, we don’t have that excuse. It’s actually much easier in JavaScript to simply create the object that you need by assembling various prototypes together than it is to manage object hierarchies.
WAT? Seriously. Want the jQuery object that can turn any date input into a megaCalendarWidget? You don’t have toextend a class. JavaScript has dynamic object extension, and jQuery exposes its own prototype so you can just extend that — without an extend keyword! WAT?:
/*
How to extend the jQuery prototype:
So difficult.
Brain hurts.
ouch.
*/
jQuery.fn.megaCalendarWidget = megaCalendarWidget;
// omg I'm so glad that's over.The next time you call the jQuery factory, you’ll get an instance that can make your date inputs mega awesome.
Similarly, you can use Object.assign() to compose any number of objects together with last-in priority:
// I'm not sure Object.assign() is available (ES6)
// so this time I'll use Lodash. It's like Underscore,
// with 200% more awesome. You could also use
// jQuery.extend() or Underscore's _.extend()
var assign = require('lodash/object/assign');
var skydiving = require('skydiving');
var ninja = require('ninja');
var mouse = require('mouse');
var wingsuit = require('wingsuit');
// The amount of awesome in this next bit might be too much
// for seniors with heart conditions or young children.
var skydivingNinjaMouseWithWingsuit = assign({}, // create a new object
skydiving, ninja, mouse, wingsuit); // copy all the awesome to it.No, really — any number of objects:
import ninja from 'ninja'; // ES6 modules
import mouse from 'mouse';
let ninjamouse = Object.assign({}, mouse, ninja);This technique is called concatenative inheritance, and the prototypes you inherit from are sometimes referred to as exemplar prototypes, which differ from delegate prototypes in that you copy from them, rather than delegate to them.
No.
There are lots of compelling reasons to avoid the ES6 class keyword, not least of which because it’s an awkward fit for JavaScript.
We already have an amazingly powerful and expressive object system in JavaScript. The concept of class as it’s implemented in JS today is more restrictive (in a bad way, not in a cool type-correctness way), and obscures the very cool prototypal OO system that was built into the language a long time ago.
You know what would really be good for JavaScript? Better sugar and abstractions built on top of prototypes from the perspective of a programmer familiar with prototypal OO.
That could be really cool.
Class Inheritance: A class is like a blueprint — a description of the object to be created. Classes inherit from classes and create subclass relationships: hierarchical class taxonomies.
Instances are typically instantiated via constructor functions with the new keyword. Class inheritance may or may not use the class keyword from ES6. Classes as you may know them from languages like Java don’t technically exist in JavaScript. Constructor functions are used, instead. The ES6 class keyword desugars to a constructor function:
class Foo {}
typeof Foo // 'function'In JavaScript, class inheritance is implemented on top of prototypal inheritance, but that does not mean that it does the same thing:
JavaScript’s class inheritance uses the prototype chain to wire the child Constructor.prototype to the parent Constructor.prototype for delegation. Usually, the super() constructor is also called. Those steps form single-ancestor parent/child hierarchies and create the tightest coupling available in OO design.
“Classes inherit from classes and create subclass relationships: hierarchical class taxonomies.”
Prototypal Inheritance: A prototype is a working object instance. Objects inherit directly from other objects.
Instances may be composed from many different source objects, allowing for easy selective inheritance and a flat [[Prototype]] delegation hierarchy. In other words, class taxonomies are not an automatic side-effect of prototypal OO: a critical distinction.
Instances are typically instantiated via factory functions, object literals, or Object.create().
“A prototype is a working object instance. Objects inherit directly from other objects.”
Inheritance is fundamentally a code reuse mechanism: A way for different kinds of objects to share code. The way that you share code matters because if you get it wrong, it can create a lot of problems, specifically: Class inheritance creates parent/child object taxonomies as a side-effect. Those taxonomies are virtually impossible to get right for all new use cases, and widespread use of a base class leads to the fragile base class problem, which makes them difficult to fix when you get them wrong. In fact, class inheritance causes many well known problems in OO design: The tight coupling problem (class inheritance is the tightest coupling available in oo design), which leads to the next one… The fragile base class problem Inflexible hierarchy problem (eventually, all evolving hierarchies are wrong for new uses) The duplication by necessity problem (due to inflexible hierarchies, new use cases are often shoe-horned in by duplicating, rather than adapting existing code) The Gorilla/banana problem (What you wanted was a banana, but what you got was a gorilla holding the banana, and the entire jungle) I discuss some of the issues in more depth in my talk, “Classical Inheritance is Obsolete: How to Think in Prototypal OO”:
When people say “favor composition over inheritance” that is short for “favor composition over class inheritance” (the original quote from “Design Patterns” by the Gang of Four). This is common knowledge in OO design because class inheritance has many flaws and causes many problems. Often people leave off the word class when they talk about class inheritance, which makes it sound like all inheritance is bad — but it’s not. There are actually several different kinds of inheritance, and most of them are great.
This is a quote from “Design Patterns: Elements of Reusable Object-Oriented Software”. It means that code reuse should be achieved by assembling smaller units of functionality into new objects instead of inheriting from classes and creating object taxonomies. In other words, use can-do, has-a, or uses-a relationships instead of is-a relationships. Good to hear: Avoid class hierarchies. Avoid brittle base class problem. Avoid tight coupling. Avoid rigid taxonomy (forced is-a relationships that are eventually wrong for new use cases). Avoid the gorilla banana problem (“what you wanted was a banana, what you got was a gorilla holding the banana, and the entire jungle”). Make code more flexible.
It means assemble code in small reusable parts through functional programming instead of through inheritance Prefer composition over inheritance as it is more malleable / easy to modify later, but do not use a compose-always approach. With composition, it's easy to change behavior on the fly with Dependency Injection / Setters. Inheritance is more rigid as most languages do not allow you to derive from more than one type. So the goose is more or less cooked once you derive from TypeA.
Now say you want to create a Manager type so you end up with:
class Manager : Person, Employee {
...
}
This example will work fine, however, what if Person and Employee both declared `Title`? Should Manager.Title return "Manager of Operations" or "Mr."? Under composition this ambiguity is better handled:
```jsx
Class Manager {
public Title;
public Manager(Person p, Employee e)
{
this.Title = e.Title;
}
}The Manager object is composed as an Employee and a Person. The Title behaviour is taken from employee. This explicit composition removes ambiguity among other things and you'll encounter fewer bugs.
| Think of containment (composition) as a has a relationship. A car "has an" engine, a person "has a" name, etc.Think of inheritance as an is a relationship. A car "is a" vehicle, a person "is a" mammal, etc.
Think of inheritance as an is a relationship. A car "is a" vehicle, a person "is a" mammal, etc.
With all the undeniable benefits provided by inheritance, here's some of its disadvantages.
- You can't change the implementation inherited from super classes at runtime (obviously because inheritance is defined at compile time).
- Inheritance exposes a subclass to details of its parent's class implementation, that's why it's often said that inheritance breaks encapsulation (in a sense that you really need to focus on interfaces only not implementation, so reusing by sub classing is not always preferred).
- The tight coupling provided by inheritance makes the implementation of a subclass very bound up with the implementation of a super class that any change in the parent implementation will force the sub class to change.
- Excessive reusing by sub-classing can make the inheritance stack very deep and very confusing too.
On the other hand Object composition is defined at runtime through objects acquiring references to other objects. In such a case these objects will never be able to reach each-other's protected data (no encapsulation break) and will be forced to respect each other's interface. And in this case also, implementation dependencies will be a lot less than in case of inheritance.
-
Subtyping means conforming to a type (interface) signature, i.e. a set of APIs, and one can override part of the signature to achieve subtyping polymorphism.
-
Subclassing means implicit reuse of method implementations.
With the two benefits comes two different purposes for doing inheritance: subtyping oriented and code reuse oriented.
This encourages the use of classes. Inheritance is one of the three tenets of OO design (inheritance, polymorphism, encapsulation).
class Person {
String Title;
String Name;
Int Age
}
class Employee : Person {
Int Salary;
String Title;
}This is inheritance at work. The Employee "is a" Person or inherits from Person. All inheritance relationships are "is-a" relationships. Employee also shadows the Title property from Person, meaning Employee.Title will return the Title for the Employee not the Person.
An example of this is PHP without the use of classes (particularly before PHP5). All logic is encoded in a set of functions. You may include other files containing helper functions and so on and conduct your business logic by passing data around in functions. This can be very hard to manage as the application grows. PHP5 tries to remedy this by offering more object oriented design.
Composition is typically "has a" or "uses a" relationship. Here the Employee class has a Person. It does not inherit from Person but instead gets the Person object passed to it, which is why it "has a" Person.
Composition is favoured over inheritance. To put it very simply you would have:
class Person {
String Title;
String Name;
Int Age;
public Person(String title, String name, String age) {
this.Title = title;
this.Name = name;
this.Age = age;
}
}
class Employee {
Int Salary;
private Person person;
public Employee(Person p, Int salary) {
this.person = p;
this.Salary = salary;
}
}
Person johnny = new Person ("Mr.", "John", 25);
Employee john = new Employee (johnny, 50000);What are the Three Different Kinds of Prototypal Inheritance? (Prototype delegation,Concatenative inheritance,Functional inheritance)
The process of inheriting features directly from one object to another by copying the source objects properties. In JavaScript, source prototypes are commonly referred to as mixins. Since ES6, this feature has a convenience utility in JavaScript called Object.assign(). Prior to ES6, this was commonly done with Underscore/Lodash’s .extend() jQuery’s $.extend(), and so on… The composition example above uses concatenative inheritance.
In JavaScript, an object may have a link to a prototype for delegation. If a property is not found on the object, the lookup is delegated to the delegate prototype, which may have a link to its own delegate prototype, and so on up the chain until you arrive at Object.prototype, which is the root delegate. This is the prototype that gets hooked up when you attach to a Constructor.prototype and instantiate with new. You can also use Object.create() for this purpose, and even mix this technique with concatenation in order to flatten multiple prototypes to a single delegate, or extend the object instance after creation.
In JavaScript, any function can create an object. When that function is not a constructor (or class), it’s called a factory function. Functional inheritance works by producing an object from a factory, and extending the produced object by assigning properties to it directly (using concatenative inheritance). Douglas Crockford coined the term, but functional inheritance has been in common use in JavaScript for a long time.
As you’re probably starting to realize, concatenative inheritance is the secret sauce that enables object composition in JavaScript, which makes both prototype delegation and functional inheritance a lot more interesting.
When most people think of prototypal OO in JavaScript, they think of prototype delegation. By now you should see that they’re missing out on a lot. Delegate prototypes aren’t the great alternative to class inheritance — object composition is.
Note that promises have both a success and an error handler, and it’s very common to see code that does this:
save().then(
handleSuccess,
handleError
);But what happens if handleSuccess() throws an error? The promise returned from .then() will be rejected, but there’s nothing there to catch the rejection — meaning that an error in your app gets swallowed. Oops! For that reason, some people consider the code above to be an anti-pattern, and recommend the following, instead: Note that promises have both a success and an error handler, and it’s very common to see code that does this:
save()
.then(handleSuccess)
.catch(handleError)
//Note that promises have both a success and an error handler, and it’s very common to see code that does this:The difference is subtle, but important. In the first example, an error originating in the save() operation will be caught, but an error originating in the handleSuccess() function will be swallowed.
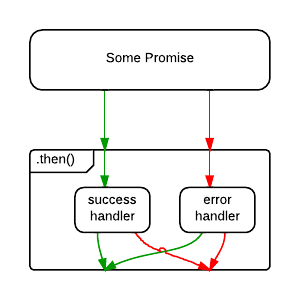
In the second example, .catch() will handle rejections from either save(), or handleSuccess().
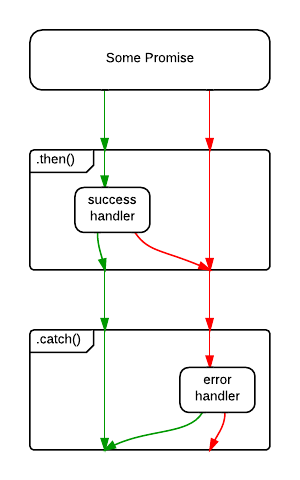
Of course, the save() error might be a networking error, whereas the handleSuccess() error may be because the developer forgot to handle a specific status code. What if you want to handle them differently? You could opt to handle them both:
save()
.then(
handleSuccess,
handleNetworkError
)
.catch(handleProgrammerError)Whatever you prefer, I recommend ending all promise chains with a .catch(). That’s worth repeating
Because .then() always returns a new promise, it’s possible to chain promises with precise control over how and where errors are handled. Promises allow you to mimic normal synchronous code’s try/catch behavior. Like synchronous code, chaining will result in a sequence that runs in serial. In other words, you can do: fetch(url) .then(process) .then(save) .catch(handleErrors) ; Assuming each of the functions, fetch(), process(), and save() return promises, process() will wait for fetch() to complete before starting, and save() will wait for process() to complete before starting. handleErrors() will only run if any of the previous promises reject. Here’s an example of a complex promise chain with multiple rejections:
A promise is an object which can be returned synchronously from an asynchronous function. It will be in one of 3 possible states: Fulfilled: onFulfilled() will be called (e.g., resolve() was called) Rejected: onRejected() will be called (e.g., reject() was called) Pending: not yet fulfilled or rejected A promise is settled if it’s not pending (it has been resolved or rejected). Sometimes people use resolved and settled to mean the same thing: not pending. Once settled, a promise can not be resettled. Calling resolve() or reject() again will have no effect. The immutability of a settled promise is an important feature. Native JavaScript promises don’t expose promise states. Instead, you’re expected to treat the promise as a black box. Only the function responsible for creating the promise will have knowledge of the promise status, or access to resolve or reject. Here is a function that returns a promise which will resolve after a specified time delay:
const wait = time => new Promise((resolve) => setTimeout(resolve, time));
wait(3000).then(() => console.log('Hello!')); // 'Hello!'Our wait(3000) call will wait 3000ms (3 seconds), and then log 'Hello!'. All spec-compatible promises define a .then() method which you use to pass handlers which can take the resolved or rejected value. The ES6 promise constructor takes a function. That function takes two parameters, resolve(), and reject(). In the example above, we’re only using resolve(), so I left reject() off the parameter list. Then we call setTimeout() to create the delay, and call resolve() when it’s finished. You can optionally resolve() or reject() with values, which will be passed to the callback functions attached with .then(). When I reject() with a value, I always pass an Error object. Generally I want two possible resolution states: the normal happy path, or an exception — anything that stops the normal happy path from happening. Passing an Error object makes that explicit.
A standard for promises was defined by the Promises/A+ specification community. There are many implementations which conform to the standard, including the JavaScript standard ECMAScript promises. Promises following the spec must follow a specific set of rules: A promise or “thenable” is an object that supplies a standard-compliant .then() method. A pending promise may transition into a fulfilled or rejected state. A fulfilled or rejected promise is settled, and must not transition into any other state. Once a promise is settled, it must have a value (which may be undefined). That value must not change. Change in this context refers to identity (===) comparison. An object may be used as the fulfilled value, and object properties may mutate. Every promise must supply a .then() method with the following signature: promise.then( onFulfilled?: Function, onRejected?: Function ) => Promise The .then() method must comply with these rules: Both onFulfilled() and onRejected() are optional. If the arguments supplied are not functions, they must be ignored. onFulfilled() will be called after the promise is fulfilled, with the promise’s value as the first argument. onRejected() will be called after the promise is rejected, with the reason for rejection as the first argument. The reason may be any valid JavaScript value, but because rejections are essentially synonymous with exceptions, I recommend using Error objects. Neither onFulfilled() nor onRejected() may be called more than once. .then() may be called many times on the same promise. In other words, a promise can be used to aggregate callbacks. .then() must return a new promise, promise2. If onFulfilled() or onRejected() return a value x, and x is a promise, promise2 will lock in with (assume the same state and value as) x. Otherwise, promise2 will be fulfilled with the value of x. If either onFulfilled or onRejected throws an exception e, promise2 must be rejected with e as the reason. If onFulfilled is not a function and promise1 is fulfilled, promise2 must be fulfilled with the same value as promise1. If onRejected is not a function and promise1 is rejected, promise2 must be rejected with the same reason as promise1.
Shallow binding binds the environment at the time the procedure is actually called. So for dynamic scoping with deep binding when add is passed into second the environment is x = 1, y = 3 and the x is the global x so it writes 4 into the global x, which is the one picked up by the write_integer.
In JavaScript, the thing called this, is the object that "owns" the JavaScript code. The value of this, when used in a function, is the object that "owns" the function. The value of this, when used in an object, is the object itself. The this keyword in an object constructor does not have a value. ... It is a keyword.
When a function is called with the new operator, this refers to the newly created object inside that function. When a function is called using call or apply, this refers to the first argument passed to call or apply. If the first argument is null or not an object, this refers to the global object.
How about augmenting the built-in Array object to use Math.max/Math.min instead:
Array.prototype.max = function() {
return Math.max.apply(null, this);
};
Array.prototype.min = function() {
return Math.min.apply(null, this);
};
Here is a JSFiddle.
Augmenting the built-ins can cause collisions with other libraries (some see), so you may be more comfortable with just apply'ing Math.xxx() to your array directly:
var min = Math.min.apply(null, arr),
max = Math.max.apply(null, arr);
Alternately, assuming your browser supports ECMAScript 6, you can use the spread operator which functions similarly to the apply method:
var min = Math.min( ...arr ),
max = Math.max( ...arr );
JavaScript has two different approaches for testing equality. Primitives like strings and numbers are compared by their value, while objects like arrays, dates, and user defined objects are compared by their reference. This means it compares whether two objects are referring to the same location in memory.
Equality check will check whether two objects have same value for same property. To check that, you can get the keys for both the objects. If the number of properties doesn't match, these two objects are not equal. Secondly, you will check each property whether they have the same value. If all the properties have same value, they are equal.
In JavaScript, if you try to use a variable that doesn't exist and has not been declared, then JavaScript will throw an error var name is not defined and script will stop executing. However, if you use typeof undeclared_variable, then it will return undefined.
Before getting further into this, let's first understand the difference between declaration and definition.
Let's say var x is a declaration because you have not defined what value it holds yet, but you have declared its existence and the need for memory allocation.
> var x; // declaring x
> console.log(x); //output: undefinedHere var x = 1 is both a declaration and definition (also we can say we are doing an initialisation). In the example above, the declaration and assignment of value happen inline for variable x. In JavaScript, every variable or function declaration you bring to the top of its current scope is called hoisting.
The assignment happens in order, so when we try to access a variable that is declared but not defined yet, we will get the result undefined.
var x; // Declaration
if(typeof x === 'undefined') // trueIf a variable that is neither declared nor defined, when we try to reference such a variable we'd get the result not defined.
> console.log(y); // Output: ReferenceError: y is not definedTLDR; Each instance has its own copy of the private methods.
One of the drawbacks of creating true private methods in JavaScript is that they are very memory-inefficient, as a new copy of the method would be created for each instance.
var Employee = function (salary) {
//Public attribute (default is null)
this.salary = salary || 5000;
// Private method
var increaseSalary = function () {
this.salary = this.salary + 1000;
};
// Public method
this.dispalyIncreasedSalary = function() {
increaseSlary();
console.log(this.salary);
};
};
// Create Employee class object
var sal = new Employee(3000);Here sal has its own copy of the increaseSalary private method.
Closure is when a function is able to remember and access its lexical scope even when that function is executing outside its lexical scope.
TLDR; Closures are something that retains its state and scope after it executes
function foo() { // 'scope of foo' aka lexical scope for bar
var memory = 'hello closure';
return function bar() {
console.log(memory);
}
}
var memory = null,
baz = foo();
baz(); // 'hello closure'when a function is defended inside a parent function that has access to the parent variable
DR; A closure is the combination of a function and the lexical environment within which that function was declared.
it's frequently used in JavaScript for object data privacy, in event handlers and callback functions, and in partial applications. */
// EXAMPLE 1
class Foo(){
constructor(){
this.x
}
}es5
// EXAMPLE 2
function Person() {
var name = 'Garrett';
function displayName(){ console.log(name);}
return displayName;
}Pitfalls are Side Effects.
with Side Effects: doesn't always return the same value
function counter() {
// globals are bad
return ++x;
}IF No Side Effects its a pure function
omitting calls to say change logging behavior
function say(x) {
console.log(x);
return x;
}4. What the difference between constructor functions and function literal and when should you choice on over the other?
object defined with a constructor lets you have multiple instances of that object.
// Function Constructor
function PersonObjConstr() {
var privateProp = "this is private";
this.firstname = "John";
this.lastname = "Doe";
}PersonObjConstr.prototype.greetFullName = function() {
return return `personObjectLiteral says: Hello ${this.firstname} ${this.lastname}`
};The function constructor has a special property named .prototype. This property will become the prototype of any objects created by the function constructor. All properties and methods added to the .prototype property of a function constructor will be available to all objects it creates.
A constructor should be used if you require multiple instances of the data or require behavior from your object. Note the function constructor is also best used when you want to simulate a private/public development pattern. Remember to put all shared methods on the .prototype so they wont be created in each object instance.
Creating objects with Object.create() utilizes an object literal as a prototype for the objects created by this method. All properties and methods added to the object literal will be available to all objects created from it through true prototypal inheritance. This is my preferred method.
Object literals are basically singletons with variables/methods that are all public.
Simple Example
//Simple Object Literal
var personObjectLiteralLite = {
name : "bob",
age : 90
}
//useage
var person = personObjectLiteralLite.name;//"Bob"The code below shows three methods of creating an object, Object Literal syntax, a Function Constructor and Object.create(). Object literal syntax simply creates and object on the fly and as such its prototype is the Object object and it will have access to all the properties and methods of Object. Strictly from a design pattern perspective a simple Object literal should be used to store a single instance of data.
Usage Example
// Object Literal
var personObjectLiteral = {
firstname : "John",
lastname: "Doe",
greetFullName : function() {
return `personObjectLiteral says: Hello ${this.firstname} ${this.lastname}`
}
}
//useage
var newName2 = Object.create(personObjectLiteral);It essentially boils down to if you need multiple instances of your object or not;
This is related to the Dom. When you attach an event listener to an element the listener is fires/and is listening to all it's children nodes
events on an element bubble up and fire on all parents
Event bubbling occurs when a user interacts with a nested element and the event propagates up (“bubbles”) through all of the ancestor elements.
<div class="ancestor">
<div class="parent">
<button> Click me! </button>
</div>
</div>When a user clicks the button the event first fires on the button itself, then bubbles up to the parent div, and then up to the ancestor div. The event would continue to bubble up through all the ancestors, until it finally reaches the document.
Javascript
$( "button" ).click(function(event) {
console.log( "button was clicked!" );
});
$( ".parent" ).click(function(event) {
console.log( "child element was clicked!" );
});
$( ".ancestor" ).click(function(event) {
console.log( "descendant element was clicked!" );
});When the user clicks the button the events starts at the button element, so button was clicked! is logged to the console. Then child element was clicked! and finally descendant element was clicked! are logged as well.
Stopping event bubbling
What if you don’t want the event to bubble up?
A fair question. Often you only want the event to trigger on the element itself, without bothering all its ancestors. Consider the following JS (with the same HTML as above):
$( "button" ).click(function(event) {
console.log( "button was clicked!" );
});
$( ".parent, .ancestor" ).click(function(event) {
console.log( "don't click me!" );
});As it stands, the don't click me! will get logged when the user clicks on the button, even though they haven’t actually clicked on the parent or ancestor element.
You have to explicitly stop event propagation (bubbling) if you don’t want it.
$( "button" ).click(function(event) {
event.stopPropagation(); // <-- this line here!
console.log( "button was clicked!" );
});
$( ".parent, .ancestor" ).click(function(event) {
console.log( "don't click me!" );
});Now the event propagation stops on the first element of the bubbling sequence. You can also stop the bubbling later on if you'd like, it doesn’t have to be on the first element.
return false from within a jQuery event handler is effectively the same as calling both e.preventDefault and e.stopPropagation on the passed jQuery.Event object.
e.preventDefault() will prevent the default event from occuring, e.stopPropagation() will prevent the event from bubbling up and return false will do both. Note that this behaviour differs from normal (non-jQuery) event handlers, in which, notably, return false does not stop the event from bubbling up.
With modern object oriented programming, one of the core principles to reduce complexity is the use of Encapsulation. By hiding private data and functions inside an object (a process known an Encapsulation), we reduce the possible interactions between objects, therefore reducing the complexity of our code
Polymorphism is one of the tenets of Object Oriented Programming (OOP). It is the practice of designing objects to share behaviors and to be able to override shared behaviors with specific ones
Can you explain the reasoning behind the syntax for encapsulated anonymous functions in JavaScript? Why does this work: (function(){})(); but this doesn't: function(){}();?
when you wrap the function in parentheses, it becomes a function expression.
This (function(){})(); is a Function Expression
This function(){}(); is a Function Declaration
Function Declaration, and the name identifier of function declarations is mandatory.
with Function Expression is optional, therefore we can have a function expression without a name defined:
(function () {
alert(2 + 2);
}());Or named function expression:
(function foo() {
alert(2 + 2);
}());Target was actually declared, eventTarget is what you attach to the event listender
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures
async methods now synchronously return Promise objects, which the client sets a callback on.
Expressions start with the word function. Trigger at compile time
function(){}Declarations starts with var
var function asdf(){}Triggered at parse time.
Navigator about machine window about browser window
var is scoped to the nearest function block let is scoped to the nearest enclosing block
Both are global if outside any block. However, global variables defined with let will not be added as properties on the global windowobject like those defined with var
'use strict'; let me = 'foo'; let me = 'bar'; // SyntaxError: Identifier 'me' has already been declared
'use strict';
var me = 'foo';
var me = 'bar'; // No problem, me is replaced.
variable declared in the global scope always becomes a property of the global object. (Not hoisted)
They can become properties of the global object, but you can assign another value to your variable. Since JavaScript is loosely typed, your function could be replaced by a string, a number, or anything else. (not hoisted)
they do not become properties of the global object and you cannot change them through re-assignment. (not hoisted)
First Class Functions are functions that can be passing functions as arguments to other functions (callbacks), returning them as the values from other functions, and assigning them to variables or storing them in data structures.
const firstClassFunctionFilter = (o) => o.isActive
let ppl=[{"id":1,isActive:true,"name":"Bernie Sanders"},{"id":2,isActive:false,"name":"Al Frankin"},{"id":3,isActive:false,"name":"Elizabeth Warren"},{"id":4,isActive:false,"name":"Cory Booker"}]
let person=ppl.filter(p=>firstClassFunctionFilter(p))
console.log(" person: ",person);the act of combining functions to make a larger function
let foo =()=>a function without a name, that can be assigned to something esle used in higher order functions
Many programming languages support arrays with named indexes.
Arrays with named indexes are called associative arrays (or hashes).
JavaScript does not support arrays with named indexes.
In JavaScript, arrays always use numbered indexes.
https://www.w3schools.com/js/js_arrays.asp
What is difference between private variable, public variable and static variable? How we achieve this in JS?
private variables - are declared with the 'var' keyword inside the object, and can only be accessed by private functions and privileged methods. closures It makes it possible for a function to have "private" variables. private functions - are declared inline inside the object's constructor (or alternatively may be defined via var functionName=function(){...}) and may only be called by privileged methods (including the object's constructor).
privileged methods - are declared with this.methodName=function(){...} and may invoked by code external to the object.
public properties - are declared with this.variableName and may be read/written from outside the object.
public methods - are defined by Classname.prototype.methodName = function(){...} and may be called from outside the object.
prototype properties - are defined by Classname.prototype.propertyName = someValue
static properties - are defined by Classname.propertyName = someValue
classical or protoypal
Lexical scope means that a function looks up variables in the context where it was defined, and not in the scope immediately around it.
prototyle
When you add functionality to an object using the prototype. An example looks like this:
Array.prototype.first = function(){
return this[0];
}
var temp = [1, 2, 3];
temp.first(); // returns 1The main argument against doing this is: if, in future, a browser decides to implement its own version of your method, your method might get overridden (silently) and the browser’s implementation (which is probably different from yours) would take over. So not extending in the first place is future proofing your code.
On the flip side, if you decide to overwrite the browsers definition, any future developer working on your code won’t know about the change. They'll have a harder time getting up to speed.
Generally it’s safer to move your particular changes into a library (as with underscore.js). That way your particular methods are clearly marked and there’s no chance of conflict.
Feature Detection
Feature detection is just a way of determining if a feature exists in certain browsers. A good example is a modern HTML5 feature ‘Location’.
so actually checking that the feature exists
if (navigator.geolocation) {
// detect users location here B-) and do something awesome
}Feature Inference
Feature inference is assuming that because you've detected one feature that you can use other features. It's usually bad to assume so you're much better off just using feature detection for each feature you want to take advantage of, and have a fallback strategy in place in the event a feature isn't available.
User Agent String
UA String or User Agent String is a string text of data that each browsers send and can be access via navigator.userAgent. These “string text of data” contains information of the browser environment you are targeting. If you open your console and run navigator.userAgent You’ll see it outputs a “string text of data” containing complete information of the environment you are currently using. Since this is an old way of doing detection, this method can be easily spoofed, thus, may not be the best route to take
Event bubbling and capturing are two ways of event propagation in the HTML DOM API, when an event occurs in an element inside another element, and both elements have registered a handle for that event. The event propagation mode determines in which order the elements receive the event.
Event delegation refers to the process of using event propagation (bubbling) to handle events at a higher level in the DOM than the element on which the event originated. It allows us to attach a single event listener for elements that exist now or in the future. Inside the Event Handling Function.
Event bubbling and capturing are two ways of event propagation in the HTML DOM API, when an event occurs in an element inside another element, and both elements have registered a handle for that event. ... IE < 9 uses only event bubbling, whereas IE9+ and all major browsers support both.
1. What are the primitive and non-primitive data types, What is the difference between undefined and null.
The latest ECMAScript standard defines seven data types:
Six data types that are primitives: Boolean Null Undefined Number String Symbol (new in ECMAScript 6) and Object Primitive valuesEdit
All types except objects define immutable values (values, which are incapable of being changed). For example and unlike to C, Strings are immutable. We refer to values of these types as "primitive values".
2. Arrays - push,pop,shift,unshift,splice,delete,remove. The difference between delete and remove with array.
push() - pushs to end unshift() - pushs to front shift() - removes first pop() - removes end (last)
var array = [2, 5, 9]; var index = array.indexOf(5); actually removes the element from the array: delete will delete the object property, but will not reindex the array or update its length. This makes it appears as if it is undefined: The difference between delete and remove with array.
delete array.splice(start, deleteCount, item1, item2, ...) splice() method changes the contents of an array by removing existing elements and/or adding new elements shift
The scope of variables is defined by their position in source code. In order to resolve variables, JavaScript starts at the innermost scope and searches outwards until it finds the variable it was looking for. Lexical scoping is nice, because we can easily figure out what the value of a variable will be by looking at the code; whereas in dynamic scoping, the meaning of a variable can change at runtime, making it more difficult.
Shortly, just before execution, the source code is sent by the engine trough a compiler, in which, during an early phase called lexing (or tokenizing), scope get defined. This doesn’t just tell us what’s in a name, but also remember us that lexical scope is based on where variables and blocks of scope have been authored in the source code. In other words, lexical scope is defined by you during author time and frozen by the lexer during compilation.
var outerFunction = function(){
if(true){
var x = 5;
//console.log(y); //line 1, ReferenceError: y not defined
}
//inside function
var nestedFunction = function() {
if(true){
var y = 7;
console.log(x); //line 2, x will still be known prints 5
}
if(true){
console.log(y); //line 3, prints 7
}
}
return nestedFunction;
}
var myFunction = outerFunction();
myFunction();In this example, the variable x is available everywhere inside of outerFunction(). Also, the variable y is available everywhere within the nestedFunction(), but neither are available outside of the function where they were defined. The reason for this can be explained by lexical scoping.
one that is wrapped that invokes itself.One common use for anonymous functions is as arguments to other functions. Another common use is as a closure, for which see also the Closures chapter. To avoid global declarations/leakages
One common use for anonymous functions is as arguments to other functions. Another common use is as a closure, for which see also the Closures chapter.
An anonymous function is a function that was declared without any named identifier to refer to it. As such, an anonymous function is usually not accessible after its initial creation.
To avoid global declarations/leakages
Extras: What Are Events Events occur when some sort of interaction takes place in a web page. This can be the end user clicking on something, moving the mouse over a certain element or pressing down certain keys on the keyboard. An event can also be something that happens in the web browser, such as the web page completing the loading of a page, or the user scrolling or resizing the window.
Event Description onchange An HTML element has been changed onclick The user clicks an HTML element onmouseover The user moves the mouse over an HTML element onmouseout The user moves the mouse away from an HTML element onkeydown The user pushes a keyboard key onload The browser has finished loading the pag When events happen to an HTML element in a web page, it checks to see if any event handlers are attached to it. If the answer is yes, it calls them in respective order, while sending along references and further information for each event that occurred. The event handlers then act upon the event.
There are two types of event order: event capturing and event bubbling.
Event capturing starts with the outer most element in the DOM and works inwards to the HTML element the event took place on and then out again. For example, a click in a web page would first check the HTML element for onclick event handlers, then the body element, and so on, until it reaches the target of the event.
Event bubbling works in exactly the opposite manner: it begins by checking the target of the event for any attached event handlers, then bubbles up through each respective parent element until it reaches the HTML element.
Events occur when some sort of interaction takes place in a web page. This can be the end user clicking on something, moving the mouse over a certain element or pressing down certain keys on the keyboard. An event can also be something that happens in the web browser, such as the web page completing the loading of a page, or the user scrolling or resizing the window. Explain the phases of event handler in JS?
Event Description onchange An HTML element has been changed onclick The user clicks an HTML element onmouseover The user moves the mouse over an HTML element onmouseout The user moves the mouse away from an HTML element onkeydown The user pushes a keyboard key onload The browser has finished loading the page When a user clicks the button the event first fires on the button itself, then bubbles up to the parent div, and then up to the ancestor div. The event would continue to bubble up through all the ancestors, until it finally reaches the document.
Javascript events on an element bubble up and fire on all parents
Event bubbling occurs when a user interacts with a nested element and the event propagates up (“bubbles”) through all of the ancestor elements. avoid colliding with global variables declared elsewhere in your JavaScript code. IIFE Why do we need IIFE? Breakdown of the above anonymous statements:
10. Do we have classes in JS? Till ECMA5, there is no keyword called class to create classes, but you can use constructor
On the other hand, any function can be used as a constructor in Javascript. You just invoke the function with the keyword new in front of it. The arbitrary function becomes a constructor on the spot. So, it’s not the function, it’s how you invoke it.
function Person(name, adr) {
this.name = name;
this.address = adr;
}
var person = new Person('John Doe', '1 Main St.');
<ul id="todo-app">
<li class="item">Walk the dog</li>
<li class="item">Pay bills</li>
<li class="item">Make dinner</li>
<li class="item">Code for one hour</li>
</ul>document.addEventListener('DOMContentLoaded', function() {
let app = document.getElementById('todo-app');
let items = app.getElementsByClassName('item');
l(typeof items)
// attach event listener to each item
for (let item of items) {
item.addEventListener('click', function() {
alert('you clicked on item: ' + item.innerHTML);
});
}
});better to actually attach one event listener to the whole container, and then be able to access each item when it’s actually clicked.
document.addEventListener('DOMContentLoaded', function() {
let app = document.getElementById('todo-app');
// attach event listener to whole container
app.addEventListener('click', function(e) {
if (e.target && e.target.nodeName === 'LI') {
let item = e.target;
alert('you clicked on item: ' + item.innerHTML);
}
});
});Write a function that will loop through a list of integers and print the index of each element after a 3 second delay.
const arr = [10, 12, 15, 21];
for (var i = 0; i < arr.length; i++) {
setTimeout(function() {
console.log('The index of this number is: ' + i);
}, 3000);
}This is a closure question.
If you run this you’ll see that you actually get the 4 printed out every time instead of the expected 0, 1, 2, 3 after a 3 second delay.
const arr = [10, 12, 15, 21];
for (var i = 0; i < arr.length; i++) {
// pass in the variable i so that each function
// has access to the correct index
setTimeout(function(i_local) {
return function() {
console.log('The index of this number is: ' + i_local);
}
}(i), 3000);
}
//or
const arr = [10, 12, 15, 21];
for (let i = 0; i < arr.length; i++) {
// using the ES6 let syntax, it creates a new binding
// every single time the function is called
// read more here: http://exploringjs.com/es6/ch_variables.html#sec_let-const-loop-heads
setTimeout(function() {
console.log('The index of this number is: ' + i);
}, 3000);
}If you attach an event listener to the window scroll event for example, and the user continuously scrolls down the page very quickly, your event may fire thousands of times within the span of 3 seconds. This can cause some serious performance issues.
If you’re discussing building an application in an interview, and events like scrolling, window resizing, or key pressing come up, make sure to mention debouncing and/or throttling as a way to improve page speed and performance.
debouncing is waiting for some time to pass by before calling a function.
Throttling is another technique that’s is similar to debouncing, except that instead of waiting for some time to pass by before calling a function, throttling just spreads the function calls across a longer time interval. So if an event occurs 10 times within 100 milliseconds, throttling could spread out each of the function calls to be executed once every 2 seconds instead of all firing within 100 milliseconds.
// debounce function that will wrap our event
function debounce(fn, delay) {
// maintain a timer
let timer = null;
// closure function that has access to timer
return function() {
// get the scope and parameters of the function
// via 'this' and 'arguments'
let context = this;
let args = arguments;
// if event is called, clear the timer and start over
clearTimeout(timer);
timer = setTimeout(function() {
fn.apply(context, args);
}, delay);
}
}If you attach an event listener to the window scroll event for example, and the user continuously scrolls down the page very quickly, your event may fire thousands of times within the span of 3 seconds. This can cause some serious performance issues.
// function to be called when user scrolls
function foo() {
console.log('You are scrolling!');
}
// wrap our function in a debounce to fire once 2 seconds have gone by
let elem = document.getElementById('container');
elem.addEventListener('scroll', debounce(foo, 2000));You could sort the array and then run through it and then see if the next (or previous) index is the same as the current. Assuming your sort algorithm is good, this should be less than O(n2):
var names = ['Mike', 'Matt', 'Nancy', 'Adam', 'Jenny', 'Nancy', 'Carl']
var uniq = names
.map((name) => {
return {count: 1, name: name}
})
.reduce((uniqueNamesObj, currentItem) => {
// l(uniqueNamesObj)
//uniqueNamesObj - first loop {Mike: 1}
//uniqueNamesObj - last loop {Adam: 1,Jenny: 1,Matt: 1,Mike: 1,Nancy: 2}
// currentItem - eg {Mike: 1}
uniqueNamesObj[currentItem.name] = (uniqueNamesObj[currentItem.name] || 0) + currentItem.count
return uniqueNamesObj
}, {})
//results:
// uniq "{'Mike':1,'Matt':1,'Nancy':2,'Adam':1,'Jenny':1,'Carl':1}"
var duplicates = Object.keys(uniq).filter((a) => uniq[a] > 1)
console.log(duplicates) //["Nancy"]
// or
var names = ["Mike","Matt","Nancy","Adam","Jenny","Nancy","Carl"];
let uniqueArray = names.filter(function(item, pos) {
// l(names.indexOf(item)+" / "+pos)
return names.indexOf(item) == pos;
})
//...... or
function uniq(a) {
var seen = {};
return a.filter(function(item) {
return seen.hasOwnProperty(item) ? false : (seen[item] = true);
});
}
l(uniqueArray)
//...... or
var arr = [9, 9, 111, 2, 3, 4, 4, 5, 7];
var sorted_arr = arr.slice().sort(); // You can define the comparing function here.
// JS by default uses a crappy string compare.
// (we use slice to clone the array so the
// original array won't be modified)
var results = [];
for (var i = 0; i < arr.length - 1; i++) {
if (sorted_arr[i + 1] == sorted_arr[i]) {
results.push(sorted_arr[i]);
}
}function checkPalindrome(str) {
return str == str.split('').reverse().join('');
}function removeDuplicateCharacters(string) {
return string
.split('')
.filter(function(item, pos, self) {
return self.indexOf(item) == pos;
})
.join('');
}
console.log(removeDuplicateCharacters('baraban'));function isIsogram(str){
var chars = str.toLowerCase().split(''), found = {};
for (var i=0,l=chars.length; i<l; i++){
if (typeof found[chars[i]] === 'undefined')
found[chars[i]] = true;
else return false;
}
return true;
}
//or
return !/(\w).*\1/i.test(str);var min = Math.min( ...arr ),
max = Math.max( ...arr );In JavaScript, the thing called this, is the object that "owns" the JavaScript code. The value of this, when used in a function, is the object that "owns" the function.The value of this, when used in an object, is the object itself. The this keyword in an object constructor does not have a value.
using XMLHttpRequest
example
<script type="text/javascript">
function loadXMLDoc() {
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange = function() {
if (xmlhttp.readyState == XMLHttpRequest.DONE ) {
if (xmlhttp.status == 200) {
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
else if (xmlhttp.status == 400) {
alert('There was an error 400');
}
else {
alert('something else other than 200 was returned');
}
}
};
xmlhttp.open("GET", "ajax_info.txt", true);
xmlhttp.send();
}
</script>using XMLHttpRequest
17. Explain the use addEventListener method What is the significance of true or false value as third argument?
The 3rd param called useCapture indicates on which of the two phases you want your handler to handle the event.
useCapture = true
The handler is set on the capturing phase. Events will get to it before getting to its children.
useCapture = false.
The handler is set on the bubbling phase. Events will get to it after getting to its children.
which means that if you write code like this:
child.addEventListener("click", second);
parent.addEventListener("click", first, true);
when clicking child element, first method will be called before second.
By default, the useCapture flag is set to false which means you handler will only be called during event bubbling phase.
apply is very similar to call() , except for the type of arguments it supports. ... arguments is a local variable of a function. It can be used for all unspecified arguments of the called object. Thus, you do not have to know the arguments of the called object when you use the apply method
If you don't have behaviour associated with an object (i.e. if the object is just a container for data/state), I would use an object literal.
var data = {
foo: 42,
bar: 43
};
Apply the KISS principle. If you don't need anything beyond a simple container of data, go with a simple literal.
If you want to add behaviour to your object, you can go with a constructor and add methods to the object during construction or give your class a prototype.
function MyData(foo, bar) {
this.foo = foo;
this.bar = bar;
this.verify = function () {
return this.foo === this.bar;
};
}
// or:
MyData.prototype.verify = function () {
return this.foo === this.bar;
};
A class like this also acts like a schema for your data object: You now have some sort of contract (through the constructor) what properties the object initializes/contains. A free literal is just an amorphous blob of data.
You might as well have an external verify function that acts on a plain old data object:
var data = {
foo: 42,
bar: 43
};
function verify(data) {
return data.foo === data.bar;
}
However, this is not favorable with regards to encapsulation: Ideally, all the data + behaviour associated with an entity should live together.
All JavaScript objects inherit the properties and methods from their prototype. Objects created using an object literal, or with new Object(), inherit from a prototype called Object.prototype. ... All JavaScript objects (Date, Array, RegExp, Function, ....) inherit from the Object.prototype.
23. Java script design patterns - http://addyosmani. com/resources/essentialjsdesignpatterns/book/#designpatternsjavascript
A namespace in computer science (sometimes also called a name scope), is an abstract container or environment created to hold a logical grouping of unique identifiers or symbols (i.e. names). An identifier defined in a namespace is associated only with that namespace.
In order to approach to Modular design pattern, you need to understand these concept first:
Immediately-Invoked Function Expression (IIFE):
(function() {
// Your code goes here
}());
There are two ways you can use the functions. 1. Function declaration 2. Function definition. Here are using function definition expression.
What is namespace? Now if we add the namespace to the above piece of code then
var anoyn = (function() {
}());
What is closure in JS?
It means if we declare any function with any variable scope/inside another function (in JS we can declare a function inside another function!) then it will count that function scope always. This means that any variable in outer function will be read always. It will not read the global variable (if any) with the same name. This is also one of the objective of using modular design pattern avoiding naming conflict.
var scope = "I am global";
function whatismyscope() {
var scope = "I am just a local";
function func() {return scope;}
return func;
}
whatismyscope()()
Now we will apply these three concepts I mentioned above to define our first modular design pattern:
var modularpattern = (function() {
// your module code goes here
var sum = 0 ;
return {
add:function() {
sum = sum + 1;
return sum;
},
reset:function() {
return sum = 0;
}
}
}());
alert(modularpattern.add()); // alerts: 1
alert(modularpattern.add()); // alerts: 2
alert(modularpattern.reset()); // alerts: 0
The objective is to hide the variable accessibility from the outside world.
Hope this helps. Good Luck.
JSONP is a simple way to overcome browser restrictions when sending JSON responses from different domains from the client. But the practical implementation of the approach involves subtle differences that are often not explained clearly. Here is a simple tutorial that shows JSON and JSONP side by side
CORS Enabled WEB API.
If the resource being requested resides on a different domain, then the Referer header is still generally included in the cross-domain request.
A recursive function (DEF) is a function which either calls itself or is in a potential cycle of function calls. As the definition specifies, there are two types of recursive functions. Consider a function which calls itself: we call this type of recursion immediate recursion.
31. How will you implement inheritance in Javascript? var child = Object.create(parent); Though there are many way
The publish-subscribe pattern (or pub/sub, for short) is a Ruby on Rails messaging pattern where senders of messages (publishers), do not program the messages to be sent directly to specific receivers (subscribers). Instead, the programmer “publishes” messages (events), without any knowledge of any subscribers there may be.
Similarly, subscribers express interest in one or more events, and only receive messages that are of interest, without any knowledge of any publishers.
To accomplish this, an intermediary, called a “message broker” or “event bus”, receives published messages, and then forwards them on to those subscribers who are registered to receive them.
In other words, pub-sub is a pattern used to communicate messages between different system components without these components knowing anything about each other’s identity.
Defining getters and setters. A getter is a method that gets the value of a specific property. A setter is a method that sets the value of a specific property. You can define getters and setters on any predefined core object or user-defined object that supports the addition of new properties. A getter is a method that gets the value of a specific property. A setter is a method that sets the value of a specific property. You can define getters and setters on any predefined core object or user-defined object that supports the addition of new properties. The syntax for defining getters and setters uses the object literal syntax.
The following illustrates how getters and setters could work for a user-defined object o.
var o = { a: 7, get b() { return this.a + 1; }, set c(x) { this.a = x / 2; } };
console.log(o.a); // 7 console.log(o.b); // 8 o.c = 50; console.log(o.a); // 25 The o object's properties are:
o.a — a number o.b — a getter that returns o.a plus 1 o.c — a setter that sets the value of o.a to half of the value o.c is being set to Please note that function names of getters and setters defined in an object literal using "[gs]et property()" (as opposed to define[GS]etter ) are not the names of the getters themselves, even though the [gs]et propertyName(){ } syntax may mislead you to think otherwise. To name a function in a getter or setter using the "[gs]et property()" syntax, define an explicitly named function programmatically using Object.defineProperty (or the Object.prototype.defineGetter legacy fallback).
The following code illustrates how getters and setters can extend the Date prototype to add a year property to all instances of the predefined Date class. It uses the Date class's existing getFullYear and setFullYear methods to support the year property's getter and setter.
These statements define a getter and setter for the year property:
var d = Date.prototype; Object.defineProperty(d, 'year', { get: function() { return this.getFullYear(); }, set: function(y) { this.setFullYear(y); } }); These statements use the getter and setter in a Date object:
var now = new Date(); console.log(now.year); // 2000 now.year = 2001; // 987617605170 console.log(now); // Wed Apr 18 11:13:25 GMT-0700 (Pacific Daylight Time) 2001 In principle, getters and setters can be either
defined using object initializers, or added later to any object at any time using a getter or setter adding method. When defining getters and setters using object initializers all you need to do is to prefix a getter method with get and a setter method with set. Of course, the getter method must not expect a parameter, while the setter method expects exactly one parameter (the new value to set). For instance:
var o = { a: 7, get b() { return this.a + 1; }, set c(x) { this.a = x / 2; } }; Getters and setters can also be added to an object at any time after creation using the Object.defineProperties method. This method's first parameter is the object on which you want to define the getter or setter. The second parameter is an object whose property names are the getter or setter names, and whose property values are objects for defining the getter or setter functions. Here's an example that defines the same getter and setter used in the previous example:
var o = { a: 0 };
Object.defineProperties(o, { 'b': { get: function() { return this.a + 1; } }, 'c': { set: function(x) { this.a = x / 2; } } });
o.c = 10; // Runs the setter, which assigns 10 / 2 (5) to the 'a' property console.log(o.b); // Runs the getter, which yields a + 1 or 6 Which of the two forms to choose depends on your programming style and task at hand. If you already go for the object initializer when defining a prototype you will probably most of the time choose the first form. This form is more compact and natural. However, if you need to add getters and setters later — because you did not write the prototype or particular object — then the second form is the only possible form. The second form probably best represents the dynamic nature of JavaScript — but it can make the code hard to read and understand.
35. Debounce/Throttle - https://sking7.github.io/articles/1248932487.html
Throttling enforces a maximum number of times a function can be called over time. As in "execute this function at most once every 100 milliseconds." Say under normal circumstances you would call this function 1,000 times over 10 seconds. If you throttle it to only once per 100 milliseconds, it would only execute that function at most 100 times
(10s * 1,000) = 10,000ms 10,000ms / 100ms throttling = 100 maximum calls
Debouncing enforces that a function not be called again until a certain amount of time has passed without it being called. As in "execute this function only if 100 milliseconds have passed without it being called." Perhaps a function is called 1,000 times in a quick burst, dispersed over 3 seconds, then stops being called. If you have debounced it at 100 milliseconds, the function will only fire once, at 3.1 seconds, once the burst is over. Each time the function is called during the burst it resets the debouncing timer.
What's the point? One major use case for these concepts is certain DOM events, like scrolling and resizing. For instance, if you attach a scroll handler to an element, and scroll that element down say 5000px, you're likely to see 100+ events be fired. If your event handler does a bunch of work (like heavy calculations and other DOM manipulation), you may see performance issues (jank). If you can get away with executing that handler less times, without much interruption in experience, it's probably worth it.
Quick hit examples:
Wait until the user stops resizing the window Don't fire an ajax event until the user stops typing Measure the scroll position of the page and respond at most every 50ms Ensure good performance as you drag elements around in an app
Currying is when you break down a function that takes multiple arguments into a series of functions that take part of the arguments. Here's an example in JavaScript:
function add (a, b) {
return a + b;
}
add(3, 4); returns 7
This is a function that takes two arguments, a and b, and returns their sum. We will now curry this function:
function add (a) {
return function (b) {
return a + b;
}
}
This is a function that takes one argument, a, and returns a function that takes another argument, b, and that function returns their sum.
add(3)(4);
var add3 = add(3);
add3(4);
The first statement returns 7, like the add(3, 4) statement. The second statement defines a new function called add3 that will add 3 to its argument. This is what some people may call a closure. The third statement uses the add3 operation to add 3 to 4, again producing 7 as a result.
Semantic HTML is the use of HTML markup to reinforce the semantics, or meaning, of the information in webpages and web applications rather than merely to define its presentation or look. Semantic HTML is processed by traditional web browsers as well as by many other user agents.
The key difference seems to be that hidden elements are always hidden regardless of the presentation:
The hidden attribute must not be used to hide content that could legitimately be shown in another presentation. For example, it is incorrect to use hidden to hide panels in a tabbed dialog, because the tabbed interface is merely a kind of overflow presentation — one could equally well just show all the form controls in one big page with a scrollbar. It is similarly incorrect to use this attribute to hide content just from one presentation — if something is marked hidden, it is hidden from all presentations, including, for instance, screen readers. http://dev.w3.org/html5/spec/Overview.html#the-hidden-attribute
Since CSS can target different media/presentation types, display: none will be dependent on a given presentation. E.g. some elements might have display: none when viewed in a desktop browser, but not a mobile browser. Or, be hidden visually but still available to a screen-reader.
The CSS Box Model. All HTML elements can be considered as boxes. In CSS, the term "box model" is used when talking about design and layout. The CSS box model is essentially a box that wraps around every HTML element. It consists of: margins, borders, padding, and the actual content.
This is an extremely broad scope question, and a lot of the pros/cons will be contextual to the situation.
In all cases these storage mechanisms will be specific to an individual browser on an individual computer/device. Any requirement to store data on an ongoing basis across sessions will need to involve your application server side - most likely using a database, but possibly XML or a text/CSV file.
localStorage, sessionStorage and cookies are all client storage solutions. Session data is held on the server where it remains under your direct control.
localStorage and sessionStorage are relatively new APIs (meaning not all legacy browsers will support them) and are near identical (both in APIs and capabilities) with the sole exception of persistence. sessionStorage (as the name suggests) is only available for the duration of the browser session (and is deleted when the tab or window is closed) - it does however survive page reloads (source DOM Storage guide - Mozilla Developer Network).
Clearly, if the data you are storing needs to be available on an ongoing basis then localStorage is preferable to sessionStorage - although you should note both can be cleared by the user so you should not rely on the continuing existence of data in either case.
localStorage and sessionStorage are perfect for persisting non-sensitive data needed within client scripts between pages (for example: preferences, scores in games). The data stored in localStorage and sessionStorage can easily be read or changed from within the client/browser so should not be relied upon for storage of sensitive or security related data within applications.
This is also true for cookies, these can be trivially tampered with by the user, and data can also be read from them in plain text - so if you are wanting to store sensitive data then session is really your only option. If you are not using SSL, cookie information can also be intercepted in transit, especially on an open wifi.
On the positive side cookies can have a degree of protection applied from security risks like Cross-Site Scripting (XSS)/Script injection by setting an HTTP only flag which means modern (supporting) browsers will prevent access to the cookies and values from JavaScript (this will also prevent your own, legitimate, JavaScript from accessing them). This is especially important with authentication cookies, which are used to store a token containing details of the user who is logged on - if you have a copy of that cookie then for all intents and purposes you become that user as far as the web application is concerned, and have the same access to data and functionality the user has.
As cookies are used for authentication purposes and persistence of user data, all cookies valid for a page are sent from the browser to the server for every request to the same domain - this includes the original page request, any subsequent Ajax requests, all images, stylesheets, scripts and fonts. For this reason cookies should not be used to store large amounts of information. Browser may also impose limits on the size of information that can be stored in cookies. Typically cookies are used to store identifying tokens for authentication, session and advertising tracking. The tokens are typically not human readable information in and of themselves, but encrypted identifiers linked to your application or database.
In terms of capabilities, cookies, sessionStorage and localStorage only allow you to store strings - it is possible to implicitly convert primitive values when setting (these will need to be converted back to use them as their type after reading) but not Objects or Arrays (it is possible to JSON serialise them to store them using the APIs). Session storage will generally allow you to store any primitives or objects supported by your Server Side language/framework.
As HTTP is a stateless protocol - web applications have no way of identifying a user from previous visits on returning to the web site - session data usually relies on a cookie token to identify the user for repeat visits (although rarely URL parameters may be used for the same purpose). Data will usually have a sliding expiry time (renewed each time the user visits), and depending on your server/framework data will either be stored in-process (meaning data will be lost if the web server crashes or is restarted) or externally in a state server or database. This is also necessary when using a web-farm (more than one server for a given website).
As session data is completely controlled by your application (server side) it is the best place for anything sensitive or secure in nature.
The obvious disadvantage with server side data is scalability - server resources are required for each user for the duration of the session, and that any data needed client side must be sent with each request. As the server has no way of knowing if a user navigates to another site or closes their browser, session data must expire after a given time to avoid all server resources being taken up by abandoned sessions. When using session data you should therefore be aware of the possibility that data will have expired and been lost, especially on pages with long forms. It will also be lost if the user deletes their cookies or switches browsers/devices.
Some web frameworks/developers use hidden HTML inputs to persist data from one page of a form to another to avoid session expiration.
localStorage, sessionStorage and cookies are all subject to "same-origin" rules which means browsers should prevent access to the data except from the domain that set the information to start with.
For further reading on client storage technologies see Dive Into Html 5.
The main difference is that Fluid Layouts (also called Liquid Layouts) are based on proportionally laying out your website so elements take up the same percent of space on different screen sizes, while Responsive Design uses CSS Media Queries to present different layouts based on screen sizes/type of screen.
Mobile browsers render pages in a virtual "window" (the viewport), usually wider than the screen, so they don't need to squeeze every page layout into a tiny window (which would break many non-mobile-optimized sites). Users can pan and zoom to see different areas of the page.
Mobile Safari introduced the "viewport meta tag" to let web developers control the viewport's size and scale. Many other mobile browsers now support this tag, although it is not part of any web standard. Apple's documentation does a good job explaining how web developers can use this tag, but we had to do some detective work to figure out exactly how to implement it in Fennec. For example, Safari's documentation says the content is a "comma-delimited list," but existing browsers and web pages use any mix of commas, semicolons, and spaces as separators.
Logo for thesitewizard.com How to Make a Mobile-Friendly Website: Responsive Design in CSS Using Media Queries and Viewport for a Mobile-Ready Design
How to Make a Mobile-Friendly Website: Responsive Design in CSS by Christopher Heng, thesitewizard.com With so many people in the world using smartphones to surf the web, more and more webmasters are looking for ways in which they can make their websites mobile-friendly. This usually means modifying their sites for the smaller screen size found on such devices, either by providing a separate page that can be viewed comfortably there, or, more commonly, making their websites automatically adapt by shrinking things and moving stuff around. The latter method, often referred to as "responsive web design", is described in this tutorial series.
Prerequisites Since this tutorial deals with the changes you need to make to your website's low level code, you will need to know some HTML and CSS. You do not need to be an expert or anything like that, but some knowledge is necessary, otherwise this tutorial will be opaque to you.
Incidentally, if you are here because you thought this article is about designing a website from scratch, please read How to Create a Website instead.
Responsive Web Design In responsive design, we will present the same web page that desktop or laptop computer users see to your mobile audience. Only the Cascading Style Sheets, or CSS, will be different. That is, browsers on desktop/laptop computers will render the page using one set of CSS instructions, while those on mobile phones another.
This method of working not only saves you the labour of creating a different set of pages for each type of user, but also the hassle of maintaining those 2 sets over the years, trying to keep them in sync.
Overcoming the Mobile Device's Defaults: Viewport For the purpose of this article, to avoid having to qualify everything I say, making things even more wordy than it needs to be, I will use the following shorthand. When I say either "desktop" or "computer" here, I mean a desktop or laptop computer, and not a smartphone or tablet (even though the latter two are actually computers too). And when I say a "mobile device", I mean a smartphone, a tablet with a small screen, and the like, and not a laptop computer (even though the latter is also portable). Without this shorthand, the article is going to be even more difficult to read than it already is, with multiple sentences just to explain what I mean when I say these terms. I also tend to use "smartphone" synonymously with "mobile device" here, so that the article doesn't sound too monotonous.
The browsers of modern smartphones are written with the knowledge that websites are traditionally designed for computer monitors. As such, it adapts by pretending to the website that it has a computer-sized screen and scaling everything to fit in it. For example, Safari on the iPhone 5 pretends that it has a screen width of 980 pixels by default, even though its real size is 320 pixels (in portrait mode). So if you were to design a website with a fixed width of (say) 730 pixels, its entire width will fit into your mobile phone's screen, even though the latter isn't that wide. The browser accomplishes this by shrinking your website so that everything becomes really small. If the user needs to read anything, they will have to zoom in the relevant portions. You can see this effect by going to the fixed width demo page with your smartphone. That particular page has a fixed width of 730 pixels, and is deliberately designed not to adapt to your use of a mobile phone.
Since this default of pretending that the device has a width of 980 pixels and automatically scaling content defeats our attempt to manually create a comfortable experience for mobile users, we have to override it before we can do anything meaningful. To do this, add the following HTML tag to the section of your web page:
The viewport meta tag above instructs the browser to use the actual device width with a scaling factor of 1. That is, it is not to pretend that it has some other width, nor is it to scale the content so that it fits into the existing window. Everything is to be used as-is. This instruction makes mobile browsers behave exactly like their desktop counterpart.The Key that Unlocks a Responsive Design in CSS: Media Queries Now that we have got the mobile phone's browser to refrain from resizing things behind our back, we have to adapt to its small screen manually. While this seems like a step backward, it actually allows us to do things in a more appropriate way than the phone's automated facility: for example, we can resize the things that can be resized (eg, images), while leaving alone others that shouldn't be resized (like the words). To make space for this, we can send elements that are not so crucial to the bottom of the screen. For example, if you were to read any article on thesitewizard.com, including this one, on a mobile phone, you will find that my navigation menu (ie, the list of buttons) that is normally in the left column in a desktop browser, is positioned at the bottom of the page on a smartphone. I figured that since the user is on this page, his/her primary purpose is to read the article. As such, I put the article at the top so that visitors can get to it immediately.
To accomplish magic like this, we need some way to detect the screen size. Modern browsers provide this facility in the form of a "media query".
A media query in a style sheet looks something like this:
@media screen and (max-width:320px) { /* CSS for screens that are 320 pixels or less will be put in this section */ } Any CSS enclosed within the curly brackets of that "@media screen and (max-width:320px)" test will only apply to screens that have a maximum width of 320 pixels. You are, of course, not restricted to testing for a width of 320 pixels. The latter is merely a figure I picked for this example. You can test for min-width and max-width of any size. You can even test for range of sizes as well, such as in the following code.
@media screen and (min-width:320px) and (max-width:640px) { /* for screens that are at least 320 pixels wide but less than or equal to 640 pixels wide */ } CSS rules that are not enclosed within a "@media" section apply to everyone. And code that is enclosed within a specific "@media" section will only be used when the conditions of the query are met.
A CSS Reset (or “Reset CSS”) is a short, often compressed (minified) set of CSS rules that resets the styling of all HTML elements to a consistent baseline. In case you didn't know, every browser has its own default 'user agent' stylesheet, that it uses to make unstyled websites appear more legible.
A clearfix is a way for an element to automatically clear its child elements, so that you don't need to add additional markup. It's generally used in float layouts where elements are floated to be stacked horizontally. The clearfix is a way to combat the zero-height container problem for floated elements.
50. Explain cross browser compatibility? Have you faced any problem implementing CSS with any browser, how did you fix it?
https://stackoverflow.com/questions/565641/what-cross-browser-issues-have-you-faced
No Jquery is a js lib and bootstrap is a css lib that can be used with any
Shorthand properties are CSS properties that let you set the values of several other CSS properties simultaneously. Using a shorthand property, a Web developer can write more concise and often more readable style sheets, saving time and energy.
background-color: red;
background: url(images/bg.gif) no-repeat left top;see https://developer.mozilla.org/en-US/docs/Web/CSS/Shorthand_properties
'padding-top', 'padding-right', 'padding-bottom', and 'padding-left'
means that different sections of the site are defined relatively (eg, an element is 50% of the page width). No matter what browser you're using: Smartphone, Tablet, Desktop, the site will look (mostly) the same and have the same proportions (this element will take up half the screen). This is because in your CSS, everything is defined in terms of percent, or ems, or some other metric that scales nicely from device to device (Whereas defining fixed sizes in pixels might make and element take up half the screen on a desktop, the whole screen on a tablet, and be bigger than the screen on a smartphone).
is usually more on the programming side, where you detect the user's browser (via useragent) or the size of their screen, and actually show them a different view based on the size of their device. For example, you might use a three column layout for desktops, a two column layout for tablets, and a single column layout on smartphones. In this case, the view on each device looks very different, because you are actually changing the view based on the device.
Twitter Bootstrap can do both of these, and they have some nice examples on their site:
Fluid Grid Responsive Design
A test pyramid describes that when writings test cases there should be a lot more low-level unit tests than high level end-to-end tests.
JavaScript is a loosely typed or a dynamic language. That means you don't have to declare the type of a variable ahead of time. The type will get determined automatically while the program is being processed. That also means that you can have the same variable as different types:
var foo = 42; // foo is now a Number var foo = 'bar'; // foo is now a String var foo = true; // foo is now a Boolean
In JavaScript, if you try to use a variable that doesn't exist and has not been declared, then JavaScript will throw an error var name is not defined and script will stop executing. However, if you use typeof undeclared_variable, then it will return undefined.
Before getting further into this, let's first understand the difference between declaration and definition.
Let's say var x is a declaration because you have not defined what value it holds yet, but you have declared its existence and the need for memory allocation.
> var x; // declaring x
> console.log(x); //output: undefinedHere var x = 1 is both a declaration and definition (also we can say we are doing an initialisation). In the example above, the declaration and assignment of value happen inline for variable x. In JavaScript, every variable or function declaration you bring to the top of its current scope is called hoisting.
The assignment happens in order, so when we try to access a variable that is declared but not defined yet, we will get the result undefined.
var x; // Declaration
if(typeof x === 'undefined') // trueIf a variable that is neither declared nor defined, when we try to reference such a variable we'd get the result not defined.
> console.log(y); // Output: ReferenceError: y is not definedTLDR; Each instance has its own copy of the private methods.
One of the drawbacks of creating true private methods in JavaScript is that they are very memory-inefficient, as a new copy of the method would be created for each instance.
var Employee = function (salary) {
//Public attribute (default is null)
this.salary = salary || 5000;
// Private method
var increaseSalary = function () {
this.salary = this.salary + 1000;
};
// Public method
this.dispalyIncreasedSalary = function() {
increaseSlary();
console.log(this.salary);
};
};
// Create Employee class object
var sal = new Employee(3000);Here sal has its own copy of the increaseSalary private method.
64. What is a “closure” in JavaScript, and what are some pitfalls of using them? Provide an example.
TLDR; Closures are something that retains its state and scope after it executes
when a functoin is definded inside a parent functoin that has access to the parent varaible
DR; A closure is the combination of a function and the lexical environment within which that function was declared.
it's frequently used in JavaScript for object data privacy, in event handlers and callback functions, and in partial applications. */
// EXAMPLE 1
class Foo(){
constructor(){
this.x
}
}es5
// EXAMPLE 2
function Person() {
var name = 'Garrett';
function displayName(){ console.log(name);}
return displayName;
}Pitfalls are Side Effects.
with Side Effects: doesn't always return the same value
function counter() {
// globals are bad
return ++x;
}IF No Side Effects its a pure function
omitting calls to say change logging behavior
function say(x) {
console.log(x);
return x;
}This is related to the Dom. When you attach an event listener to an element the listener is fires/and is listening to all it's children nodes
return false from within a jQuery event handler is effectively the same as calling both e.preventDefault and e.stopPropagation on the passed jQuery.Event object.
e.preventDefault() will prevent the default event from occuring, e.stopPropagation() will prevent the event from bubbling up and return false will do both. Note that this behaviour differs from normal (non-jQuery) event handlers, in which, notably, return false does not stop the event from bubbling up.
events on an element bubble up and fire on all parents
Event bubbling occurs when a user interacts with a nested element and the event propagates up (“bubbles”) through all of the ancestor elements.
<div class="ancestor">
<div class="parent">
<button> Click me! </button>
</div>
</div>When a user clicks the button the event first fires on the button itself, then bubbles up to the parent div, and then up to the ancestor div. The event would continue to bubble up through all the ancestors, until it finally reaches the document.
Javascript
$( "button" ).click(function(event) {
console.log( "button was clicked!" );
});
$( ".parent" ).click(function(event) {
console.log( "child element was clicked!" );
});
$( ".ancestor" ).click(function(event) {
console.log( "descendant element was clicked!" );
});When the user clicks the button the events starts at the button element, so button was clicked! is logged to the console. Then child element was clicked! and finally descendant element was clicked! are logged as well.
Stopping event bubbling
What if you don’t want the event to bubble up?
A fair question. Often you only want the event to trigger on the element itself, without bothering all its ancestors. Consider the following JS (with the same HTML as above):
$( "button" ).click(function(event) {
console.log( "button was clicked!" );
});
$( ".parent, .ancestor" ).click(function(event) {
console.log( "don't click me!" );
});As it stands, the don't click me! will get logged when the user clicks on the button, even though they haven’t actually clicked on the parent or ancestor element.
You have to explicitly stop event propagation (bubbling) if you don’t want it.
$( "button" ).click(function(event) {
event.stopPropagation(); // <-- this line here!
console.log( "button was clicked!" );
});
$( ".parent, .ancestor" ).click(function(event) {
console.log( "don't click me!" );
});Now the event propagation stops on the first element of the bubbling sequence. You can also stop the bubbling later on if you'd like, it doesn’t have to be on the first element.
Static method calls are made directly on the class and are not callable on instances of the class. Static methods are often used to create utility functions.
Shallow binding binds the environment at the time the procedure is actually called. So for dynamic scoping with deep binding when add is passed into second the environment is x = 1, y = 3 and the x is the global x so it writes 4 into the global x, which is the one picked up by the write_integer.
In JavaScript, the thing called this, is the object that "owns" the JavaScript code. The value of this, when used in a function, is the object that "owns" the function. The value of this, when used in an object, is the object itself. The this keyword in an object constructor does not have a value. ... It is a keyword.
When a function is called with the new operator, this refers to the newly created object inside that function. When a function is called using call or apply, this refers to the first argument passed to call or apply. If the first argument is null or not an object, this refers to the global object.
www.interviewquestionspdf.com/2017/02/top-120-reactjs-real-time-interview.html
http://www.interviewquestionspdf.com/2017/02/top-120-reactjs-real-time-interview.html
Backbone/Angular use a more imperative style of coding
React use a more declarative coding.
Imperative is "how" to do something. When a model updates, you tell the view to listen to that model, and then in the view you tell the HTML what to do.
Declarative is "what" to do. It takes away the "how" allowing you to focus on what's most important.
| React | Angular |
|---|---|
| 3 yrs | 7 yrs |
| JSX | CSS/HTML/JS |
| View Layer Only | MV* |
| Encourages Reusability (All about Components) | View, Models, controllers |
| Library | Framework |
| Small | Big |
| Virtual DOM | Regular DOM |
| Abstraction- Weak | Abstraction- Strong |
| Fails When? - Compile Time | Fails When? - Runtime |
React is a UI library only. As such when building something with React you will have to include other libraries to handle other parts of an application, such as application state.
When comparing it to a monolithic framework such as AngularJS, you will find that there is no predefined way to structure your app (such as services, controllers & views in Angular). This means that it is the responsibility of the developer to find his/her own ways to effectively manage several parts of the application without a predefined structure.
React also uses a virtual DOM and was a functional transformation from data received to create that whereas Angular has more tools/directives and may or may not be used the same way. I would use React for applications where the data is primarily coming from the backend/server and Angular if there was a need for heavy front-end calculations.
React can be difficult for you if you have extensive experience using other methods, such as MVC. You basically have to avoid falling back into old thought patterns because they most likely don’t work effectively with React.
Flux pattern encourages the use of immutable data. Because the store is the central authority on all data, any mutations to that data must occur within the store. The risk of data pollution is greatly reduced.
AngularJS typically rely on some internal $scope to store their data. This data can be directly mutated.
A risky situation for any part of the component or greater application which relies on that data.
if the data we are persisting is needed outside the component itself or by its children. If multiple components need to keep track of the same information, we should consider using a state manager like Redux at the application level.
Option 1: Include the library in your index.html file
Option 2: Install the library using npm install -S and import the library into relevant project files.
JSX is a syntax extension for JavaScript. Basically HTML that goes into a js file to be compiled into real HTML. A JSX expression must have exactly one outermost element. Every JSX element is secretly a call to React.createElement(). Example:
var h1 = <h1>Hello, World!</h1>Examples of JSX elements with the attributes:
<a href="http://www.yahoo.com">Welcome to the Yahoo</a>; var title = <h1 id="title">Introduction to React.js: Part I</h1>;An example of a nested JSX expression being saved as a variable:
var theFacebook = ( <a href="https://www.facebook.com"> <h1> Click me </h1> </a> );If a JSX expression takes up more than one line, then you should wrap the multi-line JSX expression in parentheses.
Typically you’d use Webpack’s DefinePlugin method to set NODE_ENV to production. This will strip out things like propType validation and extra warnings. On top of that, it’s also a good idea to minify your code because React uses Uglify’s dead-code elimination to strip out development only code and comments, which will drastically reduce the size of your bundle.
In order to solve cross browser compatibility issues, your event handlers in React will be passed instances of SyntheticEvent, which is React’s cross-browser wrapper around the browser’s native event. These synthetic events have the same interface as native events you’re used to, except they work identically across all browsers.
What’s mildly interesting is that React doesn’t actually attach events to the child nodes themselves. React will listen to all events at the top level using a single event listener. This is good for performance and it also means that React doesn’t need to worry about keeping track of event listeners when updating the DOM.
through props
A higher-order component (HOC) is an advanced technique in React for reusing component logic. ... They are a pattern that emerges from React's compositional nature. Concretely, a higher-order component is a function that takes a component and returns a new component.
Refs are an escape hatch which allow you to get direct access to a DOM element or an instance of a component. In order to use them you add a ref attribute to your component whose value is a callback function which will receive the underlying DOM element or the mounted instance of the component as its first argument.
Keys are what help React keep track of what items have changed, been added, or been removed from a list.
A large part of React is this idea of having components control and manage their own state. What happens when we throw native HTML form elements (input, select, textarea, etc) into the mix? Should we have React be the “single source of truth” like we’re used to doing with React or should we allow that form data to live in the DOM like we’re used to typically doing with HTML form elements? These two questions are at the heart of controlled vs uncontrolled components.
A controlled component is a component where React is in control and is the single source of truth for the form data. As you can see below, username doesn’t live in the DOM but instead lives in our component state. Whenever we want to update username, we call setState as we’re used to.
An uncontrolled component is where your form data is handled by the DOM, instead of inside your React component.
You use refs to accomplish this.
Though uncontrolled components are typically easier to implement since you just grab the value from the DOM using refs, it’s typically recommended that you favor controlled components over uncontrolled components. The main reasons for this are that controlled components support instant field validation, allow you to conditionally disable/enable buttons, enforce input formats, and are more “the React way”.
createElement is what JSX gets transpiled to and is what React uses to create React Elements (object representations of some UI). cloneElement is used in order to clone an element and pass it new props. They nailed the naming on these two 🙂.
Why would you use React.Children.map(props.children, () =>..) instead of props.children.map(() => ,..)
It’s not guaranteed that props.children will be an array.
Take this code for example,
<Parent>
<h1>Welcome.</h1>
</Parent>Inside of Parent if we were to try to map over children using props.children.map it would throw an error because props.children is an object, not an array.
React only makes props.children an array if there are more than one child elements, like this
<Parent>
<h1>Welcome.</h1>
<h2>props.children will now be an array</h2>
</Parent>This is why you want to favor React.Children.map because its implemention takes into account that props.children may be an array or an object.
Use state to store the data your current page needs in your controller-view.
Use props to pass data & event handlers down to your child components.
with refs.
ex1
//in parent
<View ref={i=>this.child=i} onPress={()=>this.child.open()}/>
//in child
open(){}ex2
class Parent extends Component {
render() {
return (
<div>
<Child ref="child" />
<button onClick={() => this.refs.child.getAlert()}>Click</button>
</div>
);
}
}
class Child extends Component {
getAlert() {
alert('clicked');
}
render() {
return (
<h1>Hello</h1>
);
}
}though props
eg1
//in parent
_onPressParent(){}
onPressParent={this._onPressParent.bind(this)}
//in child
this.props.onPressParent()eg2
//in parent
//-------in paraent---------
class ClassName {
constructor() {
this.state = {
show: false
};
}
this.updateState=this.updateState.bind(this)
}
updateState = () => {
this.setState({show: !this.state.show});
}
<View updateState={this.updateState}/>
//--------in child--------
//in child
handleClick = () => {
this.props.updateState();
}
onPress={this.handleClick}These stateless components may also be referred to as Pure Components, or even Dumb Components, and are meant to represent any React Component declared as a function that has no state and returns the same markup given the same props.
If your component has just a render method (and no state), you can simply create your component as a Stateless Functional Component and your function will be passed props as its first argument.
const FunctionalComponent = (o) => {
return (<View/>)
}If your component has state or a lifecycle method(s), use a Class component.
Otherwise, use a Functional component for speed
(NO STATE) Dumb components are the most reusable components available, because they have a know-nothing approach to the application in which they are used. Think of simple HTML DOM elements: an anchor tag knows nothing about the app using it and relies on the app passing prop like href, title, and target. These are examples of dumb components.
Dumb components are incredibly reusable because they are not specific to any one use case or application.
Smart components may bind to Flux actions or stores in order to directly integrate with business logic and react to changes. Whenever possible, you should favor creating dumb components and reduce the surface area of components which bind to application logic.
use function component (pure functions) if your component doesn't do much more than take in some props and render, behave the same, given the same props. Because they're lightweight, writing these simple components as functional components is pretty standard.
use **function component** (pure functions) if your component doesn't do much more than take in some props and render If your components need more functionality, like keeping state, use classes instead.
Stateless components are “reusable” components or pure functions that render DOM based solely on the properties provided to them.
Simply put, a React element describes what you want to see on the screen. Not so simply put, a React element is an object representation of some UI.
A React component is a function or a class which optionally accepts input and returns a React element (typically via JSX which gets transpiled to a createElement invocation).
https://facebook.github.io/react/docs/react-component.html
Their are 3 parts of a react life cycle:
These methods are called when an instance of a component is being created and inserted into the DOM:
constructor()
componentWillMount()
render()
componentDidMount()is executed just before rendering both on client and server-side componentDidMount is executed after first render only on the client side. This is where AJAX requests and DOM or state updates should occur. It is preferable to use modules like axios or superagent for handling ajax requests
An update can be caused by changes to props or state. These methods are called when a component is being re-rendered:
componentWillReceiveProps()
shouldComponentUpdate()
componentWillUpdate()
render()
componentDidUpdate()is invoked as soon as the props are received from parent class before another render is called. Use this as an opportunity to perform preparation before an update occurs. This method is not called for the initial render. Note that you cannot call this.setState() here. If you need to update state in response to a prop change, use componentWillReceiveProps() instead.
returns true or false value based on certain conditions. This will determine if component will be updated or not. This is set to true by default. If you are sure that component doesn’t need to render after state or props are updated, you can return false value.It can be used performance optimization to prevent unwanted renders.
When setState is called React’s goes through reconciliation algorithm. What shouldComponentUpdate does is it’s a lifecycle method that allows us to opt out of this reconciliation process for certain components (and their child components). Why would we ever want to do this? As mentioned above, “The end goal of reconciliation is to, in the most efficient way possible, update the UI based on new state”. If we know that a certain section of our UI isn’t going to change, there’s no reason to have React go through the trouble of trying to figure out if it should. By returning false from shouldComponentUpdate, React will assume that the current component, and all its child components, will stay the same as they currently are.
is called just before rendering. The componentWillUpdate gives you control to manipulate the component just before it receives new props or state. I generally use it to do animations.
is called just after rendering. AJAX requests should go in the componentDidMount lifecycle event.
There are a few reasons for this,
Fiber, the next implementation of React’s reconciliation algorithm, will have the ability to start and stop rendering as needed for performance benefits. One of the trade-offs of this is that componentWillMount, the other lifecycle event where it might make sense to make an AJAX request, will be “non-deterministic”. What this means is that React may start calling componentWillMount at various times whenever it feels like it needs to. This would obviously be a bad formula for AJAX requests.
You can’t guarantee the AJAX request won’t resolve before the component mounts. If it did, that would mean that you’d be trying to setState on an unmounted component, which not only won’t work, but React will yell at you for. Doing AJAX in componentDidMount will guarantee that there’s a component to update.
This method is called when a component is being removed from the DOM:
componentWillUnmount()is called after the component is unmounted from the dom. You can free allocated variables and datastructures in this method to free up memory.

https://facebook.github.io/react/docs/react-component.html
20. setState (What happens when you call it? What is the second argument?,cad u call setState in render?)
What happens when you call it?
The first thing React will do when setState is called is merge the object you passed into setState into the current state of the component. This will kick off a process called reconciliation. The end goal of reconciliation is to, in the most efficient way possible, update the UI based on this new state. To do this, React will construct a new tree of React elements (which you can think of as an object representation of your UI). Once it has this tree, in order to figure out how the UI should change in response to the new state, React will diff this new tree against the previous element tree. By doing this, React will then know the exact changes which occurred, and by knowing exactly what changes occurred, will able to minimize its footprint on the UI by only making updates where absolutely necessary.
Second Argument
A callback function which will be invoked when setState has finished and the component is re-rendered.
this.setState(
{ username: 'tylermcginnis33' },
() => console.log('setState has finished and the component has re-rendered.')
)setState is asynchronous, which is why it takes in a second callback function. Typically it’s best to use another lifecycle method rather than relying on this callback function, but it’s good to know it exists.
What is wrong with this code?
this.setState((prevState, props) => {
return {
streak: prevState.streak + props.count
}
})Nothing is wrong with it 🙂. It’s rarely used and not well known, but you can also pass a function to setState that receives the previous state and props and returns a new state, just as we’re doing above. And not only is nothing wrong with it, but it’s also actively recommended if you’re setting state based on previous state.
can we call setState in render function?
No, Calling setState in render causes infinite loop
In classical widely known MVC architecture, there is a clear separation between data (model), presentation (view) and logic (controller). There is one issue with this, especially in large-scale applications: The flow of data is bidirectional. This means that one change (a user input or API response) can affect the state of an application in many places in the code — for example, two-way data binding. That can be hard to maintain and debug.
Flux is very similar to Redux. The main difference is that Flux has multiple stores that change the state of the application, and it broadcasts these changes as events. Components can subscribe to these events to sync with the current state. Redux doesn’t have a dispatcher, which in Flux is used to broadcast payloads to registered callbacks. Another difference in Flux is that many varieties are available, and that creates some confusion and inconsistency.
The state of your whole application is stored in an object tree within a single store. This makes it easy to create universal apps, as the state from the server can be serialized and hybridized into the client with no extra coding effort. A single state tree also makes it easier to debug or introspect an application; it also enables persisting the app's state in development, for a faster development cycle.
In a nutshell, actions are events. Actions send data from the application (user interactions, internal events such as API calls, and form submissions) to the store. The store gets information only from actions. Internal actions are simple JavaScript objects that have a type property (usually constant), describing the type of action and payload of information being sent to the store.
{
type: LOGIN_FORM_SUBMIT,
payload: {username: 'alex', password: '123456'}
}Actions are created with action creators. That sounds obvious, I know. They are just functions that return actions.
function authUser(form) {
return {
type: LOGIN_FORM_SUBMIT,
payload: form
}
}Calling actions anywhere in the app, then, is very easy. Use the dispatch method, like so:
dispatch(authUser(form));
it is good practice to encapsulate behavior, separate concerns, and keep code duplication to a minimum. We'd also like to keep our code as testable as possible.
To me, there are five primary reasons to use action creators rather than putting all your logic directly into a component:
Basic abstraction: Rather than writing action type strings in every component that needs to create the same type of action, put the logic for creating that action in one place.
Documentation: The parameters of the function act as a guide for what data is needed to go into the action.
Brevity and DRY: There could be some larger logic that goes into preparing the action object, rather than just immediately returning it.
Encapsulation and consistency: Consistently using action creators means that a component doesn't have to know any of the details of creating and dispatching the action, and whether it's a simple "return the action object" function or a complex thunk function with numerous async calls. It just calls this.props.someBoundActionCreator(arg1, arg2), and lets the action creator worry about how to handle things.
Testability and flexibility: if a component only ever calls a function passed in as a prop rather than explicitly referencing dispatch, it becomes easy to write tests for the component that pass in a mock version of the function instead. It also enables reusing the component in another situation, or even with something other than Redux.
http://blog.isquaredsoftware.com/2016/10/idiomatic-redux-why-use-action-creators/
In Redux, reducers are functions (pure) that take the current state of the application and an action and then return a new state. Understanding how reducers work is important because they perform most of the work. Here is a very simple reducer that takes the current state and an action as arguments and then returns the next state:
function handleAuth(state, action) {
return _.assign({}, state, {
auth: action.payload
});
}For more complex apps, using the combineReducers() utility provided by Redux is possible (indeed, recommended). It combines all of the reducers in the app into a single index reducer. Every reducer is responsible for its own part of the app's state, and the state parameter is different for every reducer. The combineReducers() utility makes the file structure much easier to maintain.
If an object (state) changes only some values, Redux creates a new object, the values that didn’t change will refer to the old object and only new values will be created. That's great for performance. To make it even more efficient you can add Immutable.js.
const rootReducer = combineReducers({
handleAuth: handleAuth,
editProfile: editProfile,
changePassword: changePassword
});Store is the object that holds the application state and provides a few helper methods to access the state, dispatch actions and register listeners. The entire state is represented by a single store. Any action returns a new state via reducers. That makes Redux very simple and predictable.
import { createStore } from ‘redux’;
let store = createStore(rootReducer);
let authInfo = {username: ‘alex’, password: ‘123456’};
store.dispatch(authUser(authInfo));The only way to change the state is to emit an action, an object describing what happened. This ensures that neither the views nor the network callbacks will ever write directly to the state. Instead, they express an intent to transform the state. Because all changes are centralized and happen one by one in a strict order, there are no subtle race conditions to watch out for. As actions are just plain objects, they can be logged, serialized, stored, and later replayed for debugging or testing purposes.
Provider is a React component given to us by the “react-redux” library. It serves just one purpose : to “provide” the store to its child components.
There is no way anyone can directly modify the store. The only way to do so is through reducers, and the only way to trigger reducers is to dispatch actions. So ultimately :
To change data, we need to dispatch an action
there is no way to directly interact with the store. We can either retrieve data by obtaining its current state, or change its state by dispatching an action
This is precisely what connect does. Consider this piece of code, which uses connect to map the stores state and dispatch to the props of a component :
import {connect} from 'react-redux'
const TodoItem = ({todo, destroyTodo}) => {
return (
<div>
{todo.text}
<span onClick={destroyTodo}> x </span>
</div>
)
}
const mapStateToProps = state => {
return {
todo : state.todos[0]
}
}
const mapDispatchToProps = dispatch => {
return {
destroyTodo : () => dispatch({
type : 'DESTROY_TODO'
})
}
}
export default connect(
mapStateToProps,
mapDispatchToProps
)(TodoItem)mapStateToProps and mapDispatchToProps are both pure functions that are provided the stores “state” and “dispatch” respectively. Furthermore, both functions have to return an object, whose keys will then be passed on as the props of the component they are connected to.
In this case, mapStateToProps returns an object with only one key : “todo”, and mapDispatchToProps returns an object with the destroyTodo key.
The connected component (which is exported) provides todo and destroyTodo as props to TodoItem.
To obtain data we need to get the current state of the store


http://www.sohamkamani.com/assets/images/posts/react-redux-explanation/react-flow.svg
Developing React application from scratch without Redux - benefits? How would I do it? How do I use hot-loader? Thought process behind this and while implementing uniquire Redux architecture
- short term state, not persistant
- use state instead
- when you dont need to track changes to state.
- Don’t use Redux unless you tried local component state and were dissatisfied.
Creat a Wrapper Component. It's used for holding state and calling Rest API methods to update its state. I decided to keep only a single app state in the outer-most parent
Why would you use React.Children.map(props.children, () =>..) instead of props.children.map(() => ,..)
It’s not guaranteed that props.children will be an array.
Take this code for example,
<Parent>
<h1>Welcome.</h1>
</Parent>Inside of Parent if we were to try to map over children using props.children.map it would throw an error because props.children is an object, not an array.
React only makes props.children an array if there are more than one child elements, like this
<Parent>
<h1>Welcome.</h1>
<h2>props.children will now be an array</h2>
</Parent>This is why you want to favor React.Children.map because its implemention takes into account that props.children may be an array or an object.
Code Structure
What should my file structure look like? How should I group my action creators and reducers in my project? Where should my selectors go?
Since Redux is just a data store library, it has no direct opinion on how your project should be structured. However, there are a few common patterns that most Redux developers tend to use:
Rails-style: separate folders for “actions”, “constants”, “reducers”, “containers”, and “components” Domain-style: separate folders per feature or domain, possibly with sub-folders per file type “Ducks”: similar to domain style, but explicitly tying together actions and reducers, often by defining them in the same file It's generally suggested that selectors are defined alongside reducers and exported, and then reused elsewhere (such as in mapStateToProps functions, in async action creators, or sagas) to colocate all the code that knows about the actual shape of the state tree in the reducer files.
While it ultimately doesn't matter how you lay out your code on disk, it's important to remember that actions and reducers shouldn't be considered in isolation. It's entirely possible (and encouraged) for a reducer defined in one folder to respond to an action defined in another folder.
Further information
Documentation
actions/
CommandActions.js
UserActions.js
components/
Header.js
Sidebar.js
Command.js
CommandList.js
CommandItem.js
CommandHelper.js
User.js
UserProfile.js
UserAvatar.js
containers/
App.js
Command.js
User.js
reducers/
index.js
command.js
user.jshttps://robots.thoughtbot.com/setting-up-webpack-for-react-and-hot-module-replacement
https://gaearon.github.io/react-hot-loader/getstarted/
dispatching actions from within the reducer is an anti pattern.
The recommended way as dispatch in the action creator. Then you would probably want to attach the action creators as prop and pass it down to the container using mapDispatchToProps l
React Native is the next generation of React – a Javascript code library developed by Facebook and Instagram, which was released on Github in 2013. Native app creation means writing apps for a specific operating system.
React Native helps developers reuse code across the web and on mobile. Engineers won’t have to build the same app for iOS and for Android from scratch – reusing the code across each operating system.
Android and iOS have very different codebases and startups and businesses often struggle to hire – or afford- engineers for both. Now just one developer can write across different mobile operating systems.
Facebook opened up React in 2013 and has been using its proprietary React Native code for iOS app development for over a year.
“If we work together in the open, we can advance the state of technology together,” Facebook said in a blog post yesterday evening.
Altruism aside, opting to open source code is a tricky decision. Keeping a businesses infrastructure under-wraps has commercial advantages, especially when your technology is your business model.
But the developer community is loyal to those who open up. Web engineers across the world are quick to point out a bug in the code for free.
Developing open source projects helps keep Facebook one of the most coveted companies to work for. Developers want a challenge, and a sense of giving back – and Facebook wants a large pool of talented engineers to pick its employees from.
Plus, it saves on training. If every engineer Facebook hires already knows how to write in React Native, they have a running start.
Facebook has a culture of maturing its development. Over ten years’ it has scaled to serve one billion users, thousands of developers and three major platforms – iOS, Android and Web.
It’s a considerable development from when the fledgling startup copied Facebook code on Harvard University’s server for releases and, “poke on it to see if it was still working every day at 10am,” mobile engineering manager Bryan O’Sullivan joked earlier this year.
The first cross-platform React Native app – ads manager – was developed by the London-based dev team, who were in the US to announce the Android release yesterday evening. Ads manager lets businesses that advertise on the social network manage their accounts and create new adverts.
React Native has only recently been proven in production and building a new app based on the framework carried some risk.
Three product engineers familiar with React set about to create an app for Android and predicted problems with the logic necessary to understand differing time zones, date formats, currencies and ad formats across the world.
This business logic was already written in JavaScript, and the team knew it wouldn’t be efficient to build it all again in Objective-C to do it again in Java for Android.
Now this project has been released on Github, developers can use a single workflow to develop for iOS and Android. This means you can use the same editor and propagate it to both the iOS simulator and Android emulator at the same time.
Airbnb, Box, Facebook, GitHub, Google, Instagram, LinkedIn, Microsoft, Pinterest, Pixar Animation Studios, Twitter, Uber, and WhatsApp all use React code.
Working across separate iOS and Android codebases is challenging.
“When we were building the app, Facebook used this model, and all our build automation and developer processes were set up around it. However, it doesn’t work well for a product that, for the most part, has a single shared JavaScript codebase,” wrote Daniel Witte and Philipp von Weitershausen, engineers at Facebook in a blog yesterday.
Developers who often struggle to figure out where the master code exists and whether bugs have been fixed in all platforms may want to hold out for when Facebook opens up its unified repository. It is moving all of its code from Git to Mercurial, and will be one of the largest codebases of its kind.
Google is another web giant that understands the power of open source, recently committing to OpenStack and creating an enitrely open source container management project, Kubernetes. The project seems at odds with its own Google cloud business, but again, it knows that the benefits outweigh any loss of Google cloud customers.
The fact that React Native actually renders using its host platform’s standard rendering APIs enables it to stand out frommost existing methods of cross-platform application developement ,like Cordova or Ionic. Existing methods of writing mobile applications using combinations of JavaScript,HTML,and CSS typically render using webviews.While this approach can work, it also comes with drawbacks,especially around performance. Additionally,they do not usually have access to the host platform’s set of native UI elements.When these frame works do try to mimic native UI elements,the results usually “feel” just a little off; reverse-engineering all the fine details of things like animations takes an enormous amount of effort,and they can quickly become out of date.
In contrast, Reactive Native actually translates your markup to real,native UI elements,leveraging existing means of rendering views of whatever platform you are working with. Additionally,React works separately from the main UI thread,so your application can maintain high performance without sacrificing capability.The update cycle in React Native is the same as in React :when props or state change,React Native re-renders the views.The major differnce between React Native and React in the browser is that React Native does this by leveraging the UI libraries of its host platform, rather than using HTML and CSS markup.
For developers accustomed to working on the Web with React,this means you can write mobile apps with performance and look and feel of anative application,while using familiar tools. React Native also represents an improvement over normal mobile development in two other areas:the developer experience and cross-platform development potential.
React Native gracefully handles multiple platforms. The vast majority of the React Native APIs are cross-platform, so you just need to write one React Native component, and it will work seamlessly on both iOS and Android. Facebook claims that their Ad Manager application has 87% code reuse across the two platforms, and I wrote a flashcard app without any platform-specific code at all.
If you do want to write platform-specific code — due to different interaction guidelines on iOS and Android, for instance, or because you want to take advantage of a platform-specific API — that’s easy, too. React Native allows you to specify platform-specific versions of each component, which you can then integrate into the rest of your React Native application.
The base setup for building with Android and iOS are the same, but once you start getting into the development of your app, there are a few differences. From what I’ve experienced, we can probably bet on using about 80% of our code cross platform. I’ve heard of others using up to 90%, and I’ve normally heard the number being around 85%.
To use the code cross platform, you would just copy the code from your .ios.js or .android.js file, and copy it into the other. As long as there are not platform specific components, it should work.
Also:
There are a few modules that were build specifically for iOS, and there are a few that were specifically built for Android, and some of them work cross platform. For example, ActivityIndicatorIOS (https//facebook.github.io/react-native/docs/activityindicatorios.html#content) is an iOS styled element, but if you look in the component itself, you will see both ActivityIndicatorIOS.android.js and ActivityIndicatorIOS.ios.js, so it should at least work cross platform, but UI will probably not be what you would be looking for in Android.
If you install any plugins that need to access any native functionality, for example using a custom font, you will need to do a bit of work separately (on each platform) to get them working for each platform and it will not work cross platform.
Bridging will be entirely different for each platform, though this may not be something you would even have to worry about unless you needed to do something that React Native does not support out of the box. To build in IOS, you will need a Mac and Xcode. To build in Android, you will need the android SDK and some type of emulator (I use Genymotion). But keep in mind that as of now, you can’t develop iOS on a Windows machine unless you use something like ExponentJS, but if you have a Mac, you can develop cross platform.
Web React components use DOM elements to display (ex. div, h1, table, etc) but these are not supported by React Native. You’ll need to find libraries/components made specifically for React Native.
I doubt there are components that supports both, thus it should be fairly easy to figure out if it’s made for React Native or not. As of now, if the creator does not specifically say that they made for React Native, it probably does not work on React Native.
I would stay away from such passing functions between components. I always use Flux architecture with ReactJs and React Native.
Keep components just to render stuff by properties and sending new actions.
You have hard dependency between components. This stuff does not scale. It will be hard to maintaine such code.
What i personally do is just write actions, stores, dispatcher and don’t use any dependency on stuff like redux, because React Native is envolving rapidly and you never know if your dependencies will do it at same speed.
React JS for the web is fantastic. But when it comes to React Native – i felt i was boxed or caged to Reacts way of creating the views and constructing the screen there after.
With NativeScript that’s not the case. The UI definition follows XML syntax. I know XML so easy to follow. When it comes to application logic – it allows ES5, TypeScript – again which i already know so i can reuse my skill. You use a subset of CSS to style your app. Again big plus point here – if you know CSS3, NS allows you to use most of the basic rule sets to style your app. Basically NS is all about open standards – you don’t have to learn anything new. you use what you all ready know.
Having played around with it for a few weeks, I’ve found React Native to be fairly buggy. I don’t think it’s anywhere near production ready. A lot of features are currently still missing, for example, pin annotations for maps. Being that it’s open source, there’s nothing stopping you from building the feature yourself, but if you’re trying to get something created quickly / for production, you’re better off using developing directly for iOS or Android.
The two approaches are not interchangeable. You should initialize state in the constructor when using ES6 classes, and define the getInitialState method when using React.createClass.
class MyComponent extends React.Component {
constructor(props) {
super(props);
this.state = { /* initial state */ };
}
}is equivalent to
var MyComponent = React.createClass({
getInitialState() {
return { /* initial state */ };
},
});In addition to props, components can also have an internal state. The most prominent example of that behavior would be a click counter that updates its value when a button is pressed. The number of clicks itself would be saved in the state.
Each of the prop and state change triggers a complete re-render of the component.
A good analogy to define “what is a prop?” has been likened to the real life situation of when a person moves from one home to another. A moving van pulls up and all the contents of the home are loaded in the van and it drives off to be unloaded into the new house. The house is the scenery. The scenery includes the actual walls, floors, ceilings, doors- the architecture of the house. This does not move. It is stationary and permanent. The items boxed up, covered in pads, and carried out to the moving van when a person is changing residences would all be considered the props.
The two approaches are not interchangeable. You should initialize state in the constructor when using ES6 classes, and define the getInitialState method when using
React.createClass.
class MyComponent extends React.Component {
constructor(props) {
super(props);
this.state = { /* initial state */ };
}
}is equivalent to
var MyComponent = React.createClass({
getInitialState() {
return { /* initial state */ };
},
});ReactJs is a JavaScript Library used for developing apps in HTML5 using JavaScript as the developing language and React Native is used to develop native mobile apps using JavaScript as the development language.
Yes, React Native Compiles a native mobile app using native app components. It’s neither a Hybrid Mobile app that uses WebView to run the HTML5 app or a mobile web app. React Native builds a real mobile app that’s indistinguishable from an app built using Objective-C or Java
Yes, we can use Native code alongside JavaScript to get our tasks done, so the limitations in previous such platforms such as Titanium will be no more.
Yes, we use the same code base for Android and IOS and React take cares of the native components translations. For example: A React Native ScrollView uses native UiScrollView on IOS and ScrollView on Android.
React Native compiles a real mobile and is engineered for high performance, a good example of a high performance app is Facebook IOS app; it uses React Native and IOS users have a pretty good idea of how smoothly the Facebook app works on IOS devices. (Showcase)
https://www.tutorialspoint.com/nodejs/nodejs_callbacks_concept.htm http://www.w3ii.com/en-US/nodejs/nodejs_express_framework.html https://www.tutorialspoint.com/nodejs/nodejs_questions_answers.htm
By following steps you can async Node.js
-
First class functions -
Function composition -
Callback Counters -
Event loops
Pros:
-
If your application does not have any CPU intensive computation, you can build it in Javascript top to bottom, even down to the database level if you use JSON storage object DB like MongoDB. -
Crawlers receive a full-rendered HTML response, which is far more SEO friendly rather than a single page application or a websockets app run on top of Node.js.
Cons:
-
Any intensive CPU computation will block node.js responsiveness, so a threaded platform is a better approach. -
Using relational database with Node.js is considered less favourable
Node.js solves this problem by putting the event based model at its core, using an event loop instead of threads.
JSONP (JSON with Padding) is a method commonly used to bypass the cross-domain policies in web browsers. (You are not allowed to make AJAX requests to a web page perceived to be on a different server by the browser.)
JSON and JSONP behave differently on the client and the server. JSONP requests are not dispatched using the XMLHTTPRequest and the associated browser methods. Instead a script tag is created, whose source is set to the target URL. This script tag is then added to the DOM (normally inside the head element).
Operation errors are not bugs, but problems with the system, like request timeout or hardware failure.
On the other hand programmer errors are actual bugs.
Node.js, in its essence, is a single thread process. It does not expose child threads and thread management methods to the developer. Technically, Node.js does spawn child threads for certain tasks such as asynchronous I/O, but these run behind the scenes and do not execute any application JavaScript code, nor block the main event loop.
If threading support is desired in a Node.js application, there are tools available to enable it, such as the ChildProcess module.
Error-first callbacks are used to pass errors and data. The first argument is always an error object that the programmer has to check if something went wrong. Additional arguments are used to pass data.
fs.readFile(filePath, function(err, data) {
if (err) {
//handle the error
}
// use the data object
});To do so you have more options:
modularization: break callbacks into independent functions use Promises use yield with Generators and/or Promises
Trick question! You should not try to listen with Node on port 80 (in Unix-like systems) - to do so you would need superuser rights, but it is not a good idea to run your application with it.
Still, if you want to have your Node.js application listen on port 80, here is what you can do. Run the application on any port above 1024, then put a reverse proxy like nginx in front of it.
Node.js runs using a single thread, at least from a Node.js developer's point of view. Under the hood Node.js uses many threads through libuv.
Every I/O requires a callback - once they are done they are pushed onto the event loop for execution. If you need a more detailed explanation, I suggest viewing this video:
You have plenty of options to do so:
JSLint by Douglas Crockford JSHint ESLint JSCS These tools are really helpful when developing code in teams, to enforce a given style guide and to catch common errors using static analysis.
Operation errors are not bugs, but problems with the system, like request timeout or hardware failure.
On the other hand programmer errors are actual bugs.
This command locks down the versions of a package's dependencies so that you can control exactly which versions of each dependency will be used when your package is installed. - npmjs.com
It is useful when you are deploying your Node.js applications - with it you can be sure which versions of your dependencies are going to be deployed.
Stubs are functions/programs that simulate the behaviours of components/modules. Stubs provide canned answers to function calls made during test cases. Also, you can assert on with what these stubs were called.
A use-case can be a file read, when you do not want to read an actual file:
var fs = require('fs');
var readFileStub = sinon.stub(fs, 'readFile', function (path, cb) {
return cb(null, 'filecontent');
});
expect(readFileStub).to.be.called;
readFileStub.restore(); A test pyramid describes that when writings test cases there should be a lot more low-level unit tests than high level end-to-end tests.
When talking about HTTP APIs, it may come down to this:
a lot of low-level unit tests for your models less integration tests, where your test how your models interact with each other a lot less acceptance tests, where you test the actual HTTP endpoints
answer 2 A test pyramid describes the ratio of how many unit tests, integration tests and end-to-end test you should write.

An example for an HTTP API may look like this:
lots of low-level unit tests for models (dependencies are stubbed), fewer integration tests, where you check how your models interact with each other (dependencies are not stubbed), less end-to-end tests, where you call your actual endpoints (dependencies are not stubbed).
There is no right answer for this. The goal here is to understand how deeply one knows the framework she/he uses, if can reason about it, knows the pros, cons.
Node.js, in its essence, is a single thread process. It does not expose child threads and thread management methods to the developer. Technically, Node.js does spawn child threads for certain tasks such as asynchronous I/O, but these run behind the scenes and do not execute any application JavaScript code, nor block the main event loop.
If threading support is desired in a Node.js application, there are tools available to enable it, such as the ChildProcess module.
Unhandled exceptions in Node.js can be caught at the Process level by attaching a handler for uncaughtException event.
process.on('uncaughtException', function(err) {
console.log('Caught exception: ' + err);
});However, uncaughtException is a very crude mechanism for exception handling and may be removed from Node.js in the future. An exception that has bubbled all the way up to the Process level means that your application, and Node.js may be in an undefined state, and the only sensible approach would be to restart everything.
The preferred way is to add another layer between your application and the Node.js process which is called the domain.
Domains provide a way to handle multiple different I/O operations as a single group. So, by having your application, or part of it, running in a separate domain, you can safely handle exceptions at the domain level, before they reach the Process level.
How does Node.js support multi-processor platforms, and does it fully utilize all processor resources?
Since Node.js is by default a single thread application, it will run on a single processor core and will not take full advantage of multiple core resources. However, Node.js provides support for deployment on multiple-core systems, to take greater advantage of the hardware. The Cluster module is one of the core Node.js modules and it allows running multiple Node.js worker processes that will share the same port.
Node.js core modules, as well as most of the community-published ones, follow a pattern whereby the first argument to any callback handler is an optional error object. If there is no error, the argument will be null or undefined.
A typical callback handler could therefore perform error handling as follows:
function callback(err, results) {
// usually we'll check for the error before handling results
if(err) {
// handle error somehow and return
}
// no error, perform standard callback handling
}Promises are a concurrency primitive, first described in the 80s. Now they are part of most modern programming languages to make your life easier. Promises can help you better handle async operations.
An example can be the following snippet, which after 100ms prints out the result string to the standard output. Also, note the catch, which can be used for error handling. Promises are chainable.
new Promise((resolve, reject) => {
setTimeout(() => {
resolve('result')
}, 100)
})
.then(console.log)
.catch(console.error)Worker processes are extremely useful if you'd like to do data processing in the background, like sending out emails or processing images.
XSS occurs when the attacker injects executable JavaScript code into the HTML response.
To mitigate these attacks, you have to set flags on the set-cookie HTTP header:
HttpOnly - this attribute is used to help prevent attacks such as cross-site scripting since it does not allow the cookie to be accessed via JavaScript. secure - this attribute tells the browser to only send the cookie if the request is being sent over HTTPS. So it would look something like this: Set-Cookie: sid=; HttpOnly. If you are using Express, with express-cookie session, it is working by default.
When writing Node.js applications, ending up with hundreds or even thousands of dependencies can easily happen. For example, if you depend on Express, you depend on 27 other modules directly, and of course on those dependencies' as well, so manually checking all of them is not an option!
The only option is to automate the update / security audit of your dependencies. For that there are free and paid options:
npm outdated Trace by RisingStack NSP GreenKeeper Snyk
Node.js is a very powerful JavaScript based platform or framework which is built on Google Chrome's JavaScript V8 Engine.
It is used to develop I/O intensive web applications like video streaming sites, single page applications (SPA) and other web applications. Node.js is open source and used by thousands of developers around the world.
Node.js was developed in 2009 by Ryan Dahl.
Below are the features of Node.js –
Very Fast Event driven and Asynchronous Single Threaded but highly Scalable
REPL stands for Read Eval Print Loop. Node.js comes with bundled REPL environment which performs the following desired tasks –
Eval Print Loop Read
Variables are used to store values and print later like any conventional scripts. If “var” keyword is used then value is stored in variable. You can print the value in the variable using - console.log().
Eg: $ node
a = 30 30 var b = 50 undefined a + b 80 console.log("Hi") Hi undefined
Latest version of Node.js is - v0.10.36.
Below are the list of REPL commands –
Ctrl + c - For terminating the current command. Ctrl + c twice – For terminating REPL. Ctrl + d - For terminating REPL. Tab Keys - list of all the current commands. .break - exit from multiline expression. .save with filename - save REPL session to a file.
Command - ctrl + c twice is used to stop REPL.
stands for Node Package Manager (npm) and there are two functionalities which NPM takes care of mainly and they are –
Online repositories for node.js modules or packages, which can be searched on search.nodejs.org Dependency Management, Version Management and command line utility for installing Node.js packages.
Below command can be used to verify the NPM version –
$ npm --version
Below commands can be used for updating NPM to new version –
$ sudo npm install npm -g /usr/bin/npm -> /usr/lib/node_modules/npm/bin/npm-cli.js npm@2.7.1 /usr/lib/node_modules/npm
Callback is called once the asynchronous operation has been completed. Node.js heavily uses callbacks and all API’s of Node.js are written to support callbacks.
Node.js works good for I/O bound and not CPU bound work. For instance if there is a function to read a file, file reading will be started during that instruction and then it moves onto next instruction and once the I/O is done or completed it will call the callback function. So there will not be any blocking.
Globally installed dependencies or packages are stored in /npm directory and these dependencies can be used in Command Line Interface function of any node.js.
By default npm will install the dependency in the local mode. Here local mode refers to the package installation in node_modules directory lying in the folder where Node application is present. “require ()” is used to access the locally deployed packages.
This will be present in the root directory of any Node module/application and will be used to define the properties of a package.
“Callback hell” will be referred to heavily nested callbacks which has become unreadable or unwieldly.
“Streams” are objects which will let you read the data from source and write data to destination as a continuous process.
It’s a mechanism in which output of one stream will be connected to another stream and thus creating a chain of multiple stream operations.
Child process module has following three major ways to create child processes –
spawn - child_process.spawn launches a new process with a given command. exec - child_process.exec method runs a command in a shell/console and buffers the output. fork - The child_process.fork method is a special case of the spawn() to create child processes.
“exec” method runs a command in a shell and buffers the output. Below is the command –
child_process.exec(command[, options], callback)
Below are the list of parameters passed for Child Process Module –
child_process.exec(command[, options], callback) command - This is the command to run with space-separated arguments. options – This is an object array which comprises one or more following options – cwd uid gid killSignal maxBuffer encoding env shell timeout callback – This is the function which is gets 2 arguments – stdout, stderr and error.
This method is used to launch a new process with the given commands. Below is the method signature –
child_process.spawn(command[, args][, options])
This method is a special case for method- “spawn()” for creating node processes. The method signature –
child_process.fork(modulePath[, args][, options])
This is a mechanism of connecting one stream to other and this is basically used for getting the data from one stream and pass the output of this to other stream.
There will not be any limit for piping stream.
Here FS stands for “File System” and fs module is used for File I/O. FS module can be imported in the following way –
var test = require("fs")
“Console” is a global object and will be used for printing to stderr and stdout and this will be used in synchronous manner in case of destination is either file or terminal or else it is used in asynchronous manner when it is a pipe.
This statement is used for printing to “stdout” with newline and this function takes multiple arguments as “printf()”.
“process” is a global object and will be used to represent a node process.
Exit code will be used when the process needs to be ended with specified code. Below are the list of exit codes in Node.JS – Fatal Error Non-function Internal Exception Handler Internal JavaScript Parse Error Uncaught Fatal Exception Unused Internal JavaScript Evaluation Failure Internal Exception Handler Run-Time Failure
Below are the useful properties of process – Platform Stdin Stdout Stderr execPath mainModule execArgv config arch title version argv env exitCode
OS module is used for some basic operating system related utility functions. Below is the syntax for importing OS module –
var MyopSystem = require("os")
os.EOL – Constant for defining appropriate end of line marker for OS.
“Path” module will be used for transforming and handling file paths. Below is the syntax of path module –
var mypath = require("path")
“Net” module is being used for creating both clients and servers. It will provide asynchronous network wrapper. Below is the syntax of Net module –
var mynet = require("net")
AngularJS is a web application development framework. It’s a JavaScript and it is different from other web app frameworks written in JavaScript like jQuery. NodeJS is a runtime environment used for building server-side applications while AngularJS is a JavaScript framework mainly useful in building/developing client-side part of applications which run inside a web browser.
NodeJS is a runtime system, which is used for creating server-side applications.
Below are the list of advantages of NodeJS –
Javascript – It’s a javascript which can be used on frontend and backend. Community Driven - NodeJS has great open source community which has developed many excellent modules for NodeJS to add additional capabilities to NodeJS applications.
NodeJS is not appropriate to use in scenarios where single-threaded calculations are going to be the holdup.
aScript Object Notation (JSON) is a practical, compound, widely popular data exchange format. This will enable
< JavaScript developers to quickly construct APIs.hr>
Stub is a small program, which substitutes for a longer program, possibly to be loaded later and that is located remotely. Stubs are functions/programs that simulate the behaviors of components/modules.
Below are the list of all NodsJS versions supported in operating systems –
OperatingSystem Node.js version Windows node-v0.12.0-x64.msi Linux node-v0.12.0-linux-x86.tar.gz Mac node-v0.12.0-darwin-x86.tar.gz SunOS node-v0.12.0-sunos-x86.tar.gz
It is a global class which can be accessed in an application without importing buffer modules.
The syntax to convert Buffer to JSON is as shown beow
buffer.toJSON()
The syntax to concatenate buffers in NodeJS is var MyConctBuffer = Buffer.concat([myBuffer1, myBuffer2]);
To compare buffers in NodeJS, use following code – Mybuffer1.compare(Mybuffer2);
Below is the syntax to copy buffers in NodeJS – buffer.copy(targetBuffer[, targetStart][, sourceStart][, sourceEnd])
readUIntBE - It’s a generalized version of all numeric read methods, which supports up to 48 bits accuracy. Setting noAssert to “true” to skip the validation. writeIntBE - This will write the value to the buffer at the specified byteLength and offset and it supports upto 48 bits of accuracy.
__filename is used to represent the filename of the code which is being executed. It used to resolve the absolute path of file. Below is the sample code for the same –
console.log(__filename);
This is the global function and it is used to run the callback after some milliseconds.
Syntax of this method –
setTimeout(callbackmethod, millisecs)This is the global function and it is used to stop a timer which was created during “settimeout()”.
It is a software app which will handle the HTTP requests by client (eg: browser) and will return web pages to client as a response. Most of web server supports – server side scripts using scripting languages. Example of web server is Apache, which is mostly used webserver.
Below are the layers used in Web Apps –
Client - Which makes HTTP request to the server. Eg: Browsers. Server – This layer is used to intercept the requests from client. Business – It will have application server utilized by web servers for processing. Data – This layer will have databases mainly or any source of data.
It is a part of Events module. When instance of EventEmitter faces any error, it will emit an 'error' event. “Event Emitters” provides multiple properties like – “emit” and “on”.
“on” property is used for binding the function with event. “emit” property is used for firing an event.
This event is being emitted whenever any listener is added. So when event is triggered the listener may not have been removed from listener array for the event.
This object is an abstraction of a local socket or TCP. net.Socket instances implement a duplex Stream interface. These can be created by the user and used as a client (with connect() function) or they can be created by Node and can be passed to the user through the 'connection' event of a server.
Below are the list of events emitted by Net.socket –
Connect Lookup End Data Close Drain Timeout Error
This module is used for DNS lookup and to use underlying OS name resolution. This used to provide asynchronous network wrapper. DNS module can be imported like –
var mydns = require("dns")
Below are the bindings in domain modules –
External Binding Internal Binding
Web services which uses REST architecture will be known as RESTful Web Services. These web services uses HTTP protocol and HTTP methods.
Below command can be used for truncating the file –
fs.ftruncate(fd, len, callback)
Node.js works on a v8 environment, it is a virtual machine that utilizes JavaScript as its scripting language and achieves high output via non-blocking I/O and single threaded event loop.
I/O is the shorthand for input and output, and it will access anything outside of your application. It will be loaded into the machine memory to run the program, once the application is started.
NodeJS
In computer programming, event driven programming is a programming paradigm in which the flow of the program is determined by events like messages from other programs or threads. It is an application architecture technique divided into two sections 1) Event Selection 2) Event Handling
Node.js can be used for the following purposes
-
Web applications ( especially real-time web apps ) -
Network applications -
Distributed systems -
General purpose applications
-
It provides an easy way to build scalable network programs -
Generally fast -
Great concurrency -
Asynchronous everything -
Almost never blocks
The two types of API functions in Node.js are
-
Asynchronous, non-blocking functions -
Synchronous, blocking functions
The biggest drawback is the fact that it is challenging to have one process with a single thread to scale up on multi core servers.
A generic piece of code which runs in between several asynchronous function calls is known as control flow function.
-
Control the order of execution -
Collect data -
Limit concurrency -
Call the next step in program
For async processing, Node.js was created explicitly as an experiment. It is believed that more performance and scalability can be achieved by doing async processing on a single thread under typical web loads than the typical thread based implementation.
Yes – it does. Download the MSI installer from http://nodejs.org/download/
No, you cannot access DOM in node.
-
I/O operations -
Heavy computation -
Anything requiring blocking
Node.js is quickly gaining attention as it is a loop based server for JavaScript. Node.js gives user the ability to write the JavaScript on the server, which has access to things like HTTP stack, file I/O, TCP and databases.
The two arguments that async.queue takes
-
Task function -
Concurrency value
To process and handle external events and to convert them into callback invocations an event loop is used. So, at I/O calls, node.js can switch from one request to another .
The difference between Node.js and Ajax is that, Ajax (short for Asynchronous Javascript and XML) is a client side technology, often used for updating the contents of the page without refreshing it. While,Node.js is Server Side Javascript, used for developing server software. Node.js does not execute in the browser but by the server.
Emphasizing on the technical side, it’s a bit of challenge in Node.js to have one process with one thread to scale up on multi core server.
In node.js “non-blocking” means that its IO is non-blocking. Node uses “libuv” to handle its IO in a platform-agnostic way. On windows, it uses completion ports for unix it uses epoll or kqueue etc. So, it makes a non-blocking request and upon a request, it queues it within the event loop which call the JavaScript ‘callback’ on the main JavaScript thread.
Command “require” is used for importing external libraries, for example, “var http=require (“http”)”. This will load the http library and the single exported object through the http variable.
Callback is an asynchronous equivalent for a function. A callback function is called at the completion of a given task. Node makes heavy use of callbacks. All the APIs of Node are written in such a way that they support callbacks.
For example, a function to read a file may start reading file and return the control to the execution environment immediately so that the next instruction can be executed. Once file I/O is complete, it will call the callback function while passing the callback function, the content of the file as a parameter. So there is no blocking or wait for File I/O. This makes Node.js highly scalable, as it can process a high number of requests without waiting for any function to return results.
What
Express JS is a framework which helps to develop web and mobile applications. Its works on nodejs plateform. Its sub part of node.js.
What type of web application can built using Express JS? you can build single-page, multi-page, and hybrid web applications.
Why
Express 3.x is a light-weight web application framework to help organize your web application into an MVC architecture on the server side.
Allows to set up middlewares to respond to HTTP Requests Defines a routing table which can works as per HTTP Method and URL. Dynamically render HTML Pages
http://expressjs.com/en/starter/installing.html
var express = require('express');
var app = express();
app.get('/', function(req, res){
/* req have all the values **/
res.send('id: ' + req.query.id);
});
app.listen(3000);var bodyParser = require('body-parser') app.use( bodyParser.json() ); // to support JSON-encoded app.use(bodyParser.urlencoded({ // to support URL-encoded extended: true }));
app.set('view options', { pretty: true });
var port = req.app.settings.port || cfg.port;
res.locals.requested_url = req.protocol + '://' + req.host + ( port == 80 || port == 443 ? '' : ':'+port ) + req.path;var io = require('socket.io').listen(app, { log: false }); io.set('log level', 1);
app.get('*', function(req, res){
res.send('what???', 404);
});app.get('/download', function(req, res){
var file = __dirname + '/download-folder/file.txt';
res.download(file);
});app.get('/userdetails/:id?', function(req, res, next){
});req and res which represent the request and response objects nextIt passes control to the next matching route.
With the Angular 2.0 the MEAN stack has a huge changes. These are the following steps to create an application using MEAN stack.
Install Node.js. Create an express application using express generator. Use the view engine as ejs, therefore, install ejs.
npm install –save ejs 1 npm install –save ejs Set view engine in app.js.
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
app.engine('html', require('ejs').renderFile);
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
app.engine('html', require('ejs').renderFile);
Set the static folder.
// Set Static Folder
app.use(express.static(path.join(__dirname, 'public')));
1
2
// Set Static Folder
app.use(express.static(path.join(__dirname, 'public')));
Create the config file inside public folder following the Getting started from angular.io.app.use
is intended for binding middleware to your application. The path is a "mount" or "prefix" path and limits the middleware to only apply to any paths requested that begin with it. It can even be used to embed another application:
// subapp.js
var express = require('express');
var app = modules.exports = express();
// ...
// server.js
var express = require('express');
var app = express();
app.use('/subapp', require('./subapp'));
// ...
By specifying / as a "mount" path, app.use() will respond to any path that starts with /, which are all of them and regardless of HTTP verb used:
GET /PUT /fooPOST /foo/bar- etc.
app.get(), on the other hand, is part of Express' application routing and is intended for matching and handling a specific route when requested with the GET HTTP verb:
GET /
And, the equivalent routing for your example of app.use() would actually be:
app.all(/^\/.*/, function (req, res) {
res.send('Hello');
});app.use is the "lower level" method from Connect, the middleware framework that Express depends on.
Here's my guideline:
Use app.get if you want to expose a GET method. Use app.use if you want to add some middleware (a handler for the HTTP request before it arrives to the routes you've set up in Express), or if you'd like to make your routes modular (for example, expose a set of routes from an npm module that other web applications could use).
With Express 4.0, the application can be generated using express-generator and it includes morgan as the logger:
Create express app using express generator. The middleware in app.js is already added.
var logger = require('morgan');Create the local middleware.
var logger = require('morgan');var logger = morgan('combined');Otherwise, If logging is need to be added to a log file. Add fs to app.js
Add the file
var fs = require('fs')var log_file = fs.createWriteStream(path.join(__dirname, log.log'), {flags: 'a'})var log_file = fs.createWriteStream(path.join(__dirname, log.log'), {flags: 'a'})
Create the middleware
Var logger = morgan('combined', {stream: log_file})
Var logger = morgan('combined', {stream: log_file})
Make sure logging will be enabled only in development environment.
app.use(logger('dev'));
app.use(logger('dev'));
Now if we run from the browser we can see that every request is being logged.
GET /dsfsdf 500 387.461 ms - 1144
GET /stylesheets/style.css 304 3.383 ms - -
GET / 304 40.564 ms - -
GET /stylesheets/style.css 304 1.791 ms - -
GET /todos 200 1.397 ms - 51
GET /todos/new 304 62.912 ms - -
GET /stylesheets/style.css 304 0.397 ms - -
1in order to allow CORS in Express.js, add the following code in server.js:
app.all('*', function(req, res, next) {
res.set('Access-Control-Allow-Origin', '*');
res.set('Access-Control-Allow-Methods', 'GET, POST, DELETE, PUT');
res.set('Access-Control-Allow-Headers', 'X-Requested-With, Content-Type');
if ('OPTIONS' == req.method) return res.send(200);
next();
});or
var cors = require('cors')
var app = express()
app.use(cors())Many objects in a Node emit events, for example, a net.Server emits an event each time a peer connects to it, an fs.readStream emits an event when the file is opened. All objects which emit events are the instances of events.EventEmitter.
EventEmitter Class As we have seen in the previous section, EventEmitter class lies in the events module. It is accessible via the following code −
// Import events module var events = require('events');
// Create an eventEmitter object var eventEmitter = new events.EventEmitter(); When an EventEmitter instance faces any error, it emits an 'error' event. When a new listener is added, 'newListener' event is fired and when a listener is removed, 'removeListener' event is fired.
EventEmitter provides multiple properties like on and emit. on property is used to bind a function with the event and emit is used to fire an event.
Methods
| S.No. | Method & Description |
|---|---|
| 1 | addListener(event, listener)Adds a listener at the end of the listeners array for the specified event. No checks are made to see if the listener has already been added. Multiple calls passing the same combination of event and listener will result in the listener being added multiple times. Returns emitter, so calls can be chained. |
| 2 | on(event, listener)Adds a listener at the end of the listeners array for the specified event. No checks are made to see if the listener has already been added. Multiple calls passing the same combination of event and listener will result in the listener being added multiple times. Returns emitter, so calls can be chained. |
| 3 | once(event, listener)Adds a one time listener to the event. This listener is invoked only the next time the event is fired, after which it is removed. Returns emitter, so calls can be chained. |
| 4 | removeListener(event, listener)Removes a listener from the listener array for the specified event. Caution − It changes the array indices in the listener array behind the listener. removeListener will remove, at most, one instance of a listener from the listener array. If any single listener has been added multiple times to the listener array for the specified event, then removeListener must be called multiple times to remove each instance. Returns emitter, so calls can be chained. |
| 5 | removeAllListeners([event])Removes all listeners, or those of the specified event. It's not a good idea to remove listeners that were added elsewhere in the code, especially when it's on an emitter that you didn't create (e.g. sockets or file streams). Returns emitter, so calls can be chained. |
| 6 | setMaxListeners(n)By default, EventEmitters will print a warning if more than 10 listeners are added for a particular event. This is a useful default which helps finding memory leaks. Obviously not all Emitters should be limited to 10. This function allows that to be increased. Set to zero for unlimited. |
| 7 | listeners(event)Returns an array of listeners for the specified event. |
| 8 | emit(event, [arg1], [arg2], [...])Execute each of the listeners in order with the supplied arguments. Returns true if the event had listeners, false otherwise. |
Create a js file named main.js with the following Node.js code −
var events = require('events'); var eventEmitter = new events.EventEmitter();
// listener #1 var listner1 = function listner1() { console.log('listner1 executed.'); }
// listener #2 var listner2 = function listner2() { console.log('listner2 executed.'); }
// Bind the connection event with the listner1 function eventEmitter.addListener('connection', listner1);
// Bind the connection event with the listner2 function eventEmitter.on('connection', listner2);
var eventListeners = require('events').EventEmitter.listenerCount (eventEmitter,'connection'); console.log(eventListeners + " Listner(s) listening to connection event");
// Fire the connection event eventEmitter.emit('connection');
// Remove the binding of listner1 function eventEmitter.removeListener('connection', listner1); console.log("Listner1 will not listen now.");
// Fire the connection event eventEmitter.emit('connection');
eventListeners = require('events').EventEmitter.listenerCount(eventEmitter,'connection'); console.log(eventListeners + " Listner(s) listening to connection event");
console.log("Program Ended."); Now run the main.js to see the result −
$ node main.js Verify the Output.
2 Listner(s) listening to connection event listner1 executed. listner2 executed. Listner1 will not listen now. listner2 executed. 1 Listner(s) listening to connection event Program Ended.
Travis CI (continuous itegratoin) CI/CD pipeline - Software is being adopted at unprecedented rates which is putting a strain on traditional software development processes. Test automation and Continuous Integration / Continuous Deployment (CI-CD) are part of the answer. TTD - test driven env BDD - behaiveral driven development IOT - internet of things QA - quality assurance engineer oversees the entire development process, which includes software testing, from start to finish.
Tools:
semantic-releaseistabul- code coveragecommitizen-cz-convenvecinal-changelog-
Continuous Integration is the practice of merging in small code changes frequently - rather than merging in a large change at the end of a development cycle. The goal is to build healthier software by developing and testing in smaller increments. This is where Travis CI comes in.
As a continuous integration platform, Travis CI supports your development process by automatically building and testing code changes, providing immediate feedback on the success of the change. Travis CI can also automate other parts of your development process by managing deployments and notifications.
| Tool | About |
|---|---|
| Enzyme | (React) Enzyme is AirBnB’s library for unit testing React components. It’s great because it makes it easy to simulate the context of a React component without actually having to spin up a browser, and you can still perform CSS selection and simulate user events. |
| Protractor | (Angular) |
| Cha | i is a BDD / TDD assertion library for node and the browser that can be delightfully paired with any javascript testing framework. |
| Functions | Details |
|---|---|
| describe | starts a test suite or is what gives structure to your test suite. |
| id | starts a single test case or call identifies each individual tests but by itself it does not tell Mocha anything about how your test suite is structured. |
Mocha | In Mocha, describe starts a test suite, and it starts a single test case. For our first test, we’re using the simplest possible structure. Note that the contents of describe and it are just functions, so we can do things like exit early to force the tests to only run on the client side.
Setup. First we create the data to render, which in this case is a Javascript object. Easy peasy. Exercise. Next use the shallow function to render the data into a component. This rendering is what we’re actually testing, so that’s why it’s part of the exercise phase rather than setup. Calling shallow returns an Enzyme wrapper object that contains the rendered component instance, as well as a bunch of utility functions to simulate user events like mouse clicks and query the UI state. Verify. Next, we use hasClass, find, and prop to query the UI state to verify that the component has rendered properly. All TodoItem instances should have the list-item class, and checked items should have the checked class. Finally we make sure that the default value of the input is “Embrace the Ecosystem” as we’d expect. Teardown. In many tests there’s also some cleanup to do, but in this case there’s nothing to clean up since all the variables are temporary.
A Jasmine spec represents a test case inside the test suite. This begins with a call to the Jasmine global function it with two parameters – first parameter represents the title of the spec and second parameter represents a function that implements the test case.
In practice, spec contains one or more expectations. Each expectation represents an assertion that can be either true or false. In order to pass the spec, all of the expectations inside the spec have to be true. If one or more expectations inside a spec is false, the spec fails.
(Jasmine Methods)
For setup and tear down purpose, Jasmine provides two global functions at suite level i.e. beforeEach() and afterEach().
beforeEach()
The beforeEach function is called once before each spec in the describe() in which it is called.
afterEach()
The afterEach function is called once after each spec.
In practice, spec variables (is any) are defined at the top-level scope — the describe block — and initialization code is moved into a beforeEach function. The afterEach function resets the variable before continuing. This helps the developers in not to repeat setup and finalization code for each spec.
In Jasmine, describe function is for grouping related specs. The string parameter is for naming the collection of specs, and will be concatenated with specs to make a spec’s full name. This helps in finding specs in a large suite.
Good thing is, you can have nested describe blocks as well. In case of nested describe, before executing a spec, Jasmine walks down executing each beforeEach function in order, then executes the spec, and lastly walks up executing each afterEach function.
Let’s understand it by an example. Replace the content in MathUtilSpecs.js will following code:
| MATCHER | PURPOSE |
|---|---|
| toBe() | passed if the actual value is of the same type and value as that of the expected value. It compares with === operator |
| toEqual() | works for simple literals and variables;should work for objects too |
| toMatch() | to check whether a value matches a string or a regular expression |
| toBeDefined() | to ensure that a property or a value is defined |
| toBeUndefined() | to ensure that a property or a value is undefined |
| toBeNull() | to ensure that a property or a value is null. |
| toBeTruthy() | to ensure that a property or a value is true |
| ToBeFalsy() | to ensure that a property or a value is false |
| toContain() | to check whether a string or array contains a substring or an item. |
| toBeLessThan() | for mathematical comparisons of less than |
| toBeGreaterThan() | for mathematical comparisons of greater than |
| toBeCloseTo() | for precision math comparison |
| toThrow() | for testing if a function throws an exception |
| toThrowError() | for testing a specific thrown exception |
Many times, for various reasons, you may want to disable suites – for some time. In this case, you need not to remove the code – rather just add char x in start of describe to make if xdescribe.
These suites and any specs inside them are skipped when run and thus their results will not appear in the results.
describe("MathUtils", function() {
//Some code
});
xit("should be able to calculate the sum of two numbers", function() {
expect(10).toBeSumOf(7, 3);
});
});describe("MathUtils", function() {
//Spec for sum operation
xit("should be able to calculate the sum of two numbers", function() {
expect(10).toBeSumOf(7, 3);
});
});Jasmine has test double functions called spies. A spy can stub any function and tracks calls to it and all arguments. A spy only exists in the describe or it block in which it is defined, and will be removed after each spec. To create a spy on any method, use spyOn(object, 'methodName') call.
There are two matchers toHaveBeenCalled and toHaveBeenCalledWith which should be used with spies. toHaveBeenCalled matcher will return true if the spy was called; and toHaveBeenCalledWith matcher will return true if the argument list matches any of the recorded calls to the spy.
When there is not a function to spy on, jasmine.createSpy can create a bare spy. This spy acts as any other spy – tracking calls, arguments, etc. But there is no implementation behind it. Spies are JavaScript objects and can be used as such. Mostly, these spies are used as callback functions to other functions where it is needed.
| TRACKING PROPERTY | PURPOSE |
|---|---|
| .calls.any() | returns false if the spy has not been called at all, and then true once at least one call happens. |
| .calls.count() | returns the number of times the spy was called |
| .calls.argsFor(index) | returns the arguments passed to call number index |
| .calls.allArgs() | returns the arguments to all calls |
| .calls.all() | returns the context (the this) and arguments passed all calls |
| .calls.mostRecent() | returns the context (the this) and arguments for the most recent call |
| .calls.first() | returns the context (the this) and arguments for the first call |
| .calls.reset() | clears all tracking for a spy |
Here are some of the things that using describe to structure your test suite does for you. Here's an example of a test suite, simplified for the purpose of discussion:
function Foo() {
}
describe("Foo", function () {
var foo;
beforeEach(function () {
foo = new Foo();
});
describe("#clone", function () {
beforeEach(function () {
// Some other hook
});
it("clones the object", function () {
});
});
describe("#equals", function () {
it("returns true when the object passed is the same", function () {
});
it("returns false, when...", function () {
});
});
afterEach(function () {
// Destroy the foo that was created.
// foo.destroy();
});
});
function Bar() {
}
describe("Bar", function () {
describe("#clone", function () {
it("clones the object", function () {
});
});
});Imagine that Foo and Bar are full-fledged classes. Foo has clone and equals methods. Bar has clone. The structure I have above is one possible way to structure tests for these classes.
(The ## notation is used by some systems (like for instance, jsdoc) to indicate an instance field. So when used with a method name, it indicates a method called on an instance of the class (rather than a class method, which is called on the class itself). The test suite would run just as well without the presence of #.)
In the example above the beforeEach and afterEach calls are hooks. Each hook affects the it calls that are inside the describe call which is the parent of the hook. The various hooks are:
| TRACKING PROPERTY | PURPOSE |
|---|---|
| beforeEach | which runs before each individual it inside the describe call. |
| afterEach | which runs after each individual it inside the describe call. |
| before | which runs once before any of the individual it inside the describe call is run. |
| after | which runs once after all the individual it inside the describe call are run. |
These hooks can be used to acquire resources or create data structures needed for the tests and then release resources or destroy these structures (if needed) after the tests are done.
The snippet you show at the end of your question won't generate an error but it does not actually contain any test, because tests are defined by it.
| Details | URL |
|---|---|
| Compare | https://raygun.com/blog/javascript-unit-testing-frameworks/ |
| detail on each | http://developmentnow.com/2015/02/05/make-your-node-js-api-bulletproof-how-to-test-with-mocha-chai-and-supertest/ |
| mocha docs | http://mochajs.org/ |
| iterview quesont | http://www.ezdev.org/view/jasmine/7038 |
| medium qs | https://medium.com/javascript-scene/what-every-unit-test-needs-f6cd34d9836d |
What is a non-null type modifier in GraphQL?
Non-null type modifier is used to define an argument as non-null. The GraphQL server will send one validation error if we pass null for a non-null argument. “!” sign is used to mark one argument as non-null.
What are object types in GraphQL ?
Objects are resources that a client can access. It can contain a list of GraphQL fields.
What is an interface in GraphQL ?
Interface is used to list down common fields of a GraphQL object. Other objects can inherit these properties from an interface.
What are unions in GraphQL ?
Union is used to represent multiple objects in GraphQL. We can define more than one type as return type using union.
What is the validation step in GraphQL ?
Validation step is used to check wheather a GraphQL query is in valid format or not. It can inform on the client side if a query is invalid before the runtime check.
What is the execution step in GraphQL ?
Execution step is used to execute a GraphQL query. This step runs after the validation step.
What is a resolver ?
Resolver is used to produce a response to a GraphQL query. Resolver is used to handle queries.
What is a Type System? Pros/Cons?
Can you opt out of a type check?
with a custom scalar
What are GraphQL Interfaces?
Like many type systems, GraphQL supports interfaces. An Interface is an abstract type that includes a certain set of fields that a type must include to implement the interface.
For example, you could have an interface Character that represents any character in the Star Wars trilogy with diff properties.
What is introspection in GraphQL?
Introspection. It's often useful to ask a GraphQL schema for information about what queries it supports. GraphQL allows us to do so using the introspection system! ... Query, Character, Human, Episode, Droid - These are the ones that we defined in our type system.
Is a stateless GraphQL gateway a single point of failure?
we're afraid of turning the original GraphQL layer on a monolith that would behave as a single point of failure in case of a disaster, for instance.
My personal opinion is that stateless GraphQL gateway is not a single point of failure since you can reset it or scale to more machines.
If you use rest graphql wrappers what would that do to performance?
Bad
Does GraphQL support server-side caching?
No, GraphQL doesn’t support server-side caching.
What are the operations GraphQL supports?
GraphQL supports query, mutation and subscription. Queries are used for the read operation, mutation is for a write operation and subscription is used to listen for any changes.
What is a query language?
In simple words, a query language uses queries to fetch data from a database. GraphQL is a query language and it uses queries for APIs.
How can you avoid Superfluous Database Calls? (not caching)
Solution: Dataloader Dataloader will let you batch and cache database calls.
- Batching means that if Dataloader figures out that you’re hitting the same database table multiple times, it’ll batch all calls together. In our example, the 10 post authors’ and 50 comment authors’ calls would all be batched into a single call.
- Caching means that if Dataloader detects that two posts (or a post and a comment) have the same author, it will reuse the user object it already has in memory instead of making a new database call.
Where __typename is used ?
typename is a meta field. If the client doesn’t know the type getting back from a GraphQL service, GraphQL allows us to use typename to get the name of the object type.
Is GraphQL an ORM
GraphQL is not an ORM, because it doesn't understand the concept of DBs. It just gets the data from a "data source", which could be static, from a file, etc. Nor can it figure out how to get data once you point the source at it.
What is your ideal experience service layer with graphql?
Build Graphql over may diff micro services in Business logic verticals (product, catalog)

What are the seperations of concerns and what your seperating with micro services?
| micro services | The Problems when vericalizing your app into Business logic verticals (product, catalog) accross business logic domains |
|---|---|
| business logic verticals | disrobuted monolith. when you attempt to decouple that which is acctually coupled. You created a distributed monolith. |
| repositories | folders work |
| organizational boundaries | What if product changes or teams change, now what teams own what? |
| language choice | Dont want too many teams creating same biz logic |
| Technology/scaling constriants | God forbid you try to debug accross service boundaries |
Micro services are a tool, not a goal. They have cost and concerns
Your desire for graphql is your subconscuios tellking you want the good parts of a monolith back

Summeries
Nike
Nike Job FINAL INTERVIEW MONDAY AT 3PM
Nick discussed a lot about testing and workflow. How I manage things from development to production. And if I use plugins or right stuff myself and what my preference was? They focus on chat app pushing stuff to their phone team. So he said he'll set up something on Monday or Tuesday for a technical screening so I would learn more about testing environments, and what the f*** spring, scrum, spring reviewing, AWS flow, Spring boot and how sales force works. I TOLD HIM IM USING TRAVIS.
TEAM
https://www.linkedin.com/in/stevenjbennett/
https://www.linked.com/in/saisaripalli/
https://www.linkedin.com/in/nick-nepokroeff-57a2054/
Lululemon
This calendar invite is confirming your Phone call w/ Brian Westendorf (Principal Consultant - Mobile Architect at AIM Consulting). Below are more details and the job description.
Inside Tech Scoop on Lulu's Stack:
This team in Portland are OSS zealots.
Our "backend" language of choice is Python. (Some deprecated Ruby (Sinatra) in play also).
Our "front end" in this case is React that is Service Side Render (Node) enabled.
Extensive AWS experience is a BIG plus. Our CI/CD pipeline (which every dev is expected in integrate with) is primarily CloudFormation based with a custom Python wrapper used for orchestrating deployments.
We also heavily leverage Lambda.
Little Back Story:
AIM will provide 6 dev. resources to Lululemon. Details of resource is broken down below. Jamie needs to transition the current vendor out of Lulu ASAP and is looking for AIM to come in to provide the transition support. Resources will be located out of AIM office and temp space that Lulu has in Seattle.
Develop features which align to the project roadmap
Perform activities with broad independence
Deliver on Project milestones
Complete tasks assigned by manager on schedule while communicating progress regularly
Work closely with CLIENT’s architecture teams to understand various integration points and best practices
Job Summary:
We are looking for a motivated engineer to become a core member of our team building Digital Products here at lululemon. We work in a cloud native environment where “automation” and “Infrastructure as Code” are guiding principles and necessary for the development of high-quality and resilient software systems. A key component of these systems is the end-user experience, which you will help craft by contributing to the development of high-performing, well-tested, and thoughtfully architected JavaScript based web apps.
Core Accountabilities:
Build and extend Digital Product web applications in a cloud environment.
Ensure that customer facing applications are designed to be highly available, observable, and durable via software engineering best practices.
Work with Product Owners to understand end-user requirements, formulate user stories and then translate those into pragmatic and effective technical solutions.
Work closely with onsite and remote frontend, backend and operations engineers to ensure deliverables are well-documented, secure and resilient.
Required Skills, Experience:
Minimum 3 years of real-world experience developing, deploying, scaling and maintaining JavaScript based web apps. A good portion of this experience should come from developing web experiences in and around cloud-based services and/or service oriented architectures.
Productive in contemporary JavaScript development environments. Qualified candidates have real-world experience in the development life-cycles of complex single page applications and are comfortable working with modern frameworks like React, Ember, and AngularJS.
Experience with unit testing frameworks.
Experience with data management strategies in browser environments.
Strong software development fundamentals including automated testing, source control (Git), continuous integration in addition to continuous delivery and/or deployment. Experience integrating web frontends with complex multi-tier applications.
Excellent written and verbal communication skills and a strong willingness to learn and teach.
A passion for solving problems and desire to understand how things work.
Ability to help troubleshoot and resolve production system issues.
Ability to author well designed, testable, efficient code. We always prefer clarity over clever.
Nice to Haves:
Experience building and deploying Progressive Web Apps.
Experience designing browser based applications that interact with JSON-API compliant APIs.
Direct experience with AWS services and/or experience building on top of so-called "solutions platforms" — think "auth as a service", "images as a service", etc.
Our “must haves”:
Proven work ethic with utmost integrity
Desire to excel and succeed
Actively live and breathe the lululemon culture and lifestyle
Self-awareness, with a desire for constant self-improvement (goal –oriented)
Entrepreneurial spirit and an egoless nature
Self-motivated, passionate, empathetic, approachable
Outgoing, energetic, upbeat and fun!