Apache Cassandra is an open source, distributed database management system. Cassandra is designed to handle large amounts of data across many commodity servers. Cassandra uses a query language named CQL.
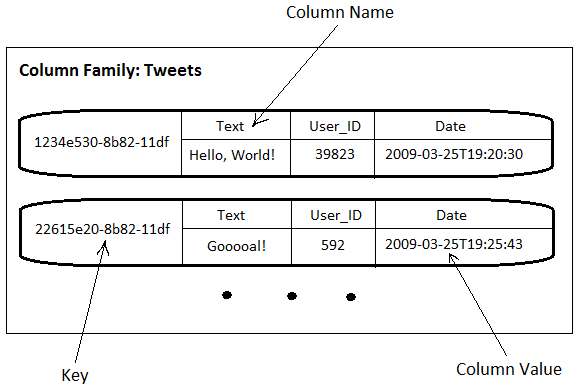
Cassandra's data model is a partitioned row store; Cassandra combines elements of key-value stores and tabular/columnar databases. Like a relational database, Cassandra stores data in tables, called column families, that have defined columns and associated data types. Each row in a column family is uniquely identified by a key. Each row has multiple columns, each of which has a timestamp, name, and value. Unlike a relational database, each row in a column family does not need to have the same set of columns. At any time, a column may be added to one or more rows. If this explanation is unclear, you might think of column families instead as sets of key-value pairs, in which the values are nested sets of key-value pairs.
The following depicts two rows of a column-family from an imaginary database for Twitter:
The songs table consists of title, album, artist, and data columns, with a UUID primary key:
CREATE TABLE songs ( id uuid PRIMARY KEY, title text, album text, artist text, data blob );
In a relational database, a playlists table would include a foreign key to the songs. This normalization of the data reduces the number of redundant entries. In Cassandra, data must be denormalized. Denormalization is the optimization of a database's read performance by adding redundant data or grouping data. In a relational database, related but separate pieces of information (like song information and playlists of songs) are stored in separate logical tables. Querying information from several logical tables (like getting the artists for all of the songs in a playlist) may be slow if the logical tables are stored as separate files.
A denormalized playlist table in Cassandra might look like this:
CREATE TABLE playlists ( id uuid, song_order int, song_id uuid, title text, album text, artist text, PRIMARY KEY (id, song_order) );
This denormalization eliminates the need to query multiple logical tables in separate disk files, but forces the database designer to ensure that the data is consistent across the playlist andsong tables.
Cassandra has two shells, cassandra-cli and 'cqlsh`.
cqlsh uses SQL-like syntax, but does not support all operations.
- http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling-best-practices-part-1/
- http://www.datastax.com/docs/0.8/ddl/index
- http://maxgrinev.com/2010/07/09/a-quick-introduction-to-the-cassandra-data-model/
- http://en.wikipedia.org/wiki/Apache_Cassandra#Data_model
- http://en.wikipedia.org/wiki/Denormalization
- http://www.datastax.com/documentation/cql/3.0/webhelp/index.html#cql/ddl/ddl_anatomy_table_c.html