Supercharge your work with Aubai: real-time knowledge and data Insights – All with a Dash of Aubergine Flair!
This gist focuses on core concepts that will help you to build and connect any type of application around LLMs. I have taken a specific use case of a chatbot for policy documents, but developers can apply the same foundational concepts to their unique use cases. The principles discussed here provide a versatile framework applicable across various scenarios.
Imagine you have questions about your company's leave policy. Who do you turn to? For many, it might be a colleague or an HR representative. But what if there were an even easier way—a way that didn't involve waiting for email replies or tracking someone down at their desk? Enter Aubai, an advanced chatbot powered by the latest AI technologies that can answer all your policy-related queries instantly. Let's dive into the world of Aubai and explore how it's built to make your life easier.
Constructing a chatbot like Aubai isn't overly complex, yet it involves integrating six crucial components at its core.
- Large Language model(LLM)
- Conversational Memory
- Prompt Engineering
- Function Calling
- Vector Embeddings
- Vector Database
Our journey begins with understanding the brain behind Aubai—the Large Language Model (LLM). An LLM is like a vast library of information and conversations, all bundled into a digital brain. Aubai is built on state-of-the-art LLMs such as OpenAI's GPT-3.5 Turbo and the even more advanced GPT-4-Turbo. Large language models, when implemented as chatbots, offer incredible versatility. They can handle various tasks such as answering questions, summarizing information, translating languages, and completing sentences in a conversational manner. By integrating LLMs into chatbots, we can transform the way users interact with virtual assistants, enhancing their ability to engage in natural and dynamic conversations. GPT models by OpenAI provides out-of-the-box functions accessible through APIs like Function calling and JSON response. To use the LLM for the chatbot use case we have to understand a little bit about the input of the model. Let's quickly go through the concept of context window and tokens.
Think of a conversation you've been a part of. Remembering what was said a few sentences ago helps you keep track of the discussion. For Aubai, the chatbot's ability to "remember" is defined by what's called the Context Window. It's the span of the conversation that the AI can keep in mind when crafting its responses.
Why does this matter? If the context window is too small, Aubai might "forget" earlier parts of the conversation, which isn't ideal when you need coherent, consistent help. That's why the GPT models are equipped with pretty large context windows—GPT-3.5 Turbo can handle up to 4,096 tokens of text, while the newer GPT-4 Turbo can consider a massive 128,000 tokens at once!
So, what's a token? In the language of LLMs, tokens are like puzzle pieces of language—they can be whole words, parts of words, or even punctuation. When you're chatting with Aubai, it slices your sentences into these tokens to process and understand what you're saying.
Here's a cool analogy: think of tokens as ingredients in a recipe. Your sentence, in this context, is the dish. Each token, much like different ingredients, plays a role in contributing to the overall flavor and meaning of the conversation. Head over to the OpenAI tokenizer page to learn more about the tokens.
One of the critical features of Aubai is its conversational memory. Think of it as the chatbot being able to "remember" past interactions, much like a human conversation partner would. This continuity is essential for a chatbot, so it doesn't treat each new question as if it's the first time you've talked. Here’s a peek at how developers help Aubai remember using Python:
# An example snippet from Aubai's memory system
from brain import Brain
# Example conversation history
conversation_history = [
{"role": "system", "content": "LeaveBot"},
{"role": "user", "content": "Hey"},
{"role": "assistant", "content": "Hello there! How can I assist you today?
If you have any questions related to Aubergine Solutions company's policy or guidelines, feel free to ask!"},
]
# Instantiate the Brain
leave_bot = Brain()
# User interacts with the chatbot
user_query_1 = "How many leave days am I entitled to per year?"
user_query_2 = "Can I take a leave for more than 10 days consecutively?"
# Initial interaction
conversation_history.append({"role": "user", "content": user_query_1})
response_1 = leave_bot.llm_call(chain=conversation_history)
conversation_history.append({"role": "assistant", "content": response_1})
# User's next query
conversation_history.append({"role": "user", "content": user_query_2})
response_2 = leave_bot.llm_call(chain=conversation_history)
conversation_history.append({"role": "assistant", "content": response_2})To see the full implementation, make sure to check out the Brain class in Aubai Github repo.
Prompt engineering is a fresh field that focuses on creating and fine-tuning prompts to make language models (LMs) more efficient across various applications. Having prompt engineering skills helps in understanding what large language models (LLMs) can and cannot do.
At its core, it is about arranging text in a way that an AI model can understand what a user wants to accomplish. A prompt is the task described in plain language that the AI needs to do. prompt engineering is a must to enhance the performance of LLMs in tasks like question answering and Chatbots and to keep the bot in restricted constraint. You do not want your domain specific bot to answer the question which is outside of your domain to your user even if user asks.
To chat effectively, Aubai needs clear instructions—this is where prompt engineering comes into play. It's all about framing questions and prompts in a way that guides the AI to respond correctly. For instance, we might use a method called Chain of Thought to solve problems step-by-step:
User Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:LLM Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.You can perform the above similarly with the Zero-shot COT Prompt technique,
User Prompt:
Note: 'Let's Think step by step' <---- add this special prompt.
Question: A juggler can juggle 16 balls. Half of the balls are golf balls, and half of the golf balls are blue. How many blue golf balls are there?
Answer:LLM Output:
There are 16 balls in total. Half of the balls are golf balls. That means that there are 8 golf balls. Half of the golf balls are blue. That means that there are 4 blue golf balls.by adding this prompt 'Think step by step' in your query. LLM will solve the given task in a step-by-step manner. These types of techniques shape how Aubai understands and tackles the task at hand. To understand different prompting techniques please refer: https://www.promptingguide.ai/
Aubai needs to access real-time data or specific document details, that's where function call comes into the picture. Aubai doesn’t make the calls itself—it generates JSON objects that your software can use to make those calls and retrieve the information needed to respond accurately to your queries. Here’s a glance at how Aubai breaks down the task:
sequenceDiagram
User ->> Aubai: Can I take 13 days' leave in one go?
Aubai-->>Aubai: Analysed the query, need to call a function to get the information related to leave policy.
Aubai ->> ChromaDB Query Engine: query: can an employee take leaves for more than 10 days?
ChromaDB Query Engine ->> Vector Database: Get a list of related documents that are most similar and near to the query in vector space
Vector Database ->> Aubai: <list of related documents which are most similar and near to the query in vector space>
Aubai -->> Aubai: Curate the answer based on the user's query and database information
Aubai ->> User: You cannot take 13 days' leave in one go.
checkout the Function calling implementation on Aubai GitHub
You might wonder how Aubai understands the meaning behind words or sentences stored in the policy documents. The secret lies in vector embeddings. Vector embeddings, in terms of Large Language Models (LLMs), are numerical representations of words, phrases, or even entire documents in a multi-dimensional space. These embeddings capture the semantic meaning of the text, allowing the LLM to understand and process language. Each point in the space represents a different word or text snippet. The distance or angle between points reflects the similarity between their meanings. Embeddings enable the LLM to perform tasks such as classification, translation, and question answering more accurately.
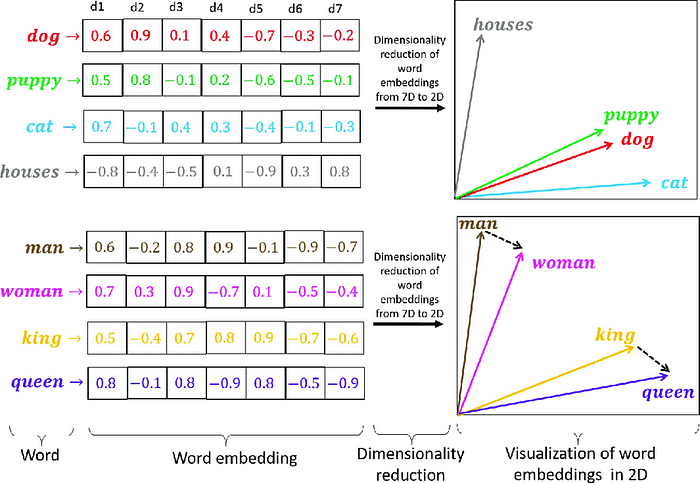
There are different models available to generate vector embeddings from the text.
Aubai utilizes multi-qa-mpnet-base-dot-v1 for sentence-to-vector embeddings.
multi-qa-mpnet-base-dot-v1 is a sentence-transformers model. It maps sentences & paragraphs to a 768-dimensional dense vector space and was designed for semantic search. The reason we chose this model is that It has been trained on 215M (question, answer) pairs from diverse sources which match our use case that is in the form of Q&A. You can check out the other models by sentence transformers and their implementations.
Now, where does Aubai store all this information? In a vector database. A vector database is a type of database that indexes and stores vector embeddings for fast retrieval and similarity search, with capabilities like CRUD operations, and metadata filtering. We use ChromaDB. Which is an open-source vector database.
A core component of the building Aubai involves Loading the policy data into the vector database without losing the meaning. First, we load and parse company policies, chunk them into digestible pieces, and then convert them into vector embeddings. Next, we create a collection in ChromaDB for these vectors, like how a librarian might catalog new books.
import os
from decouple import config
from chromadb.utils import embedding_functions
from long-chain.text_splitter import RecursiveCharacterTextSplitter
from pdf import PdfReader
def data_loader():
# Set the directory path where PDF files are stored
data_dir = 'data/policy'
# Check if the directory exists
if not os.path.exists(data_dir) or not os. path.isdir(data_dir):
print("The 'data' directory does not exist in the current working directory.")
return
# Initialize an empty list to store data
all_data = []
# Loop through each file in the directory
for file in os.listdir(data_dir):
if file.endswith(".pdf"):
# Extract the file name without the extension
file_name = file.split(".")[0]
# Construct the full PDF file path
pdf_url = os.path.join(data_dir, file)
# Read the PDF file
pdf_reader = PdfReader(pdf_url)
# Extract text from each page, remove spaces, and join lines
pdf_texts = [" ".join(page.extract_text().replace(" ", "").split('\n')) for page in pdf_reader.pages]
# Remove empty texts
pdf_texts = [text for text in pdf_texts if text]
# Initialize a text splitter
character_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ". ", " ", ""],
chunk_size=1000,
chunk_overlap=0
)
# Split text into chunks
character_split_texts = character_splitter.split_text('\n\n'.join(pdf_texts))
# Display the total number of chunks
print(f"\nTotal chunks: {len(character_split_texts)}")
# Append each chunk to the data list with an associated topic
for chunk in character_split_texts:
all_data.append({"topic": file_name, "content": chunk})Explanation:
- A function
data_loaderto load data from PDF files, parse the text, and split it into chunks. - It iterates through each PDF file in the specified directory, extracts text from each page, and joins the text.
- The text is then split into chunks using a
RecursiveCharacterTextSplitterwith specified separators and chunk size. - The resulting chunks are stored in a list (
all_data) along with the associated topic.
# Get the collection name and Chroma client host from environment variables
collection_name = config('COMPANY_POLICY_DATA')
chroma_client_host = config('CHROMA_CLIENT_HOST')
# Initialize a ChromaDB HTTP client
chroma_client = chromadb.HttpClient(host=chroma_client_host, port=8000)
# Try to delete the existing collection (if any)
try:
chroma_client.delete_collection(name=collection_name)
except:
pass
# Define distance functions for indexing
distance_functions = ["l2", "ip", "cosine"]
# Initialize a SentenceTransformer embedding function
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="multi-qa-mpnet-base-dot-v1")
# Create a new ChromaDB collection with specified metadata
collection = chroma_client.create_collection(
name=collection_name, embedding_function=sentence_transformer_ef, metadata={"hnsw:space": distance_functions[0]})Explanation:
- Initializes a ChromaDB collection by creating a connection to ChromaDB, deleting any existing collection with the same name, and creating a new one.
- Defines a collection name, Chroma client host, and distance functions for indexing.
- The
SentenceTransformerEmbeddingFunctionis used for embedding text, and a new collection is created with specified metadata.
# Initialize lists to store documents, metadata, and document IDs
documents = []
metadata = []
ids = []
n = 1
# Iterate through each data chunk and extract content and topic
for data in all_data:
documents.append(data['content'])
metadata.append({"topic": data['topic']})
ids.append(f"{data['topic']}_{n}")
n += 1
# Add documents, metadata, and IDs to the ChromaDB collection
collection.add(
documents=documents,
metadatas=metadata,
ids=ids
)
# Return True indicating successful data loading
return TrueExplanation:
- prepare data for storage by iterating through each chunk and extracting content, topic, and unique IDs.
- It then adds the documents, metadata, and IDs to the ChromaDB collection using the
collection.addmethod. - Finally, the function returns
Trueto indicate successful data loading into the database.
Full code:
import chromadb
import os
from decouple import config
from pypdf import PdfReader
from chromadb.utils import embedding_functions
from langchain.text_splitter import RecursiveCharacterTextSplitter
def data_loader():
data_dir = 'data/policy'
if not os.path.exists(data_dir) or not os.path.isdir(data_dir):
print("The 'data' directory does not exist in the current working directory.")
return
all_data = []
for file in os.listdir(data_dir):
if file.endswith(".pdf"):
file_name = file.split(".")[0]
pdf_url = os.path.join(data_dir, file)
pdf_reader = PdfReader(pdf_url)
pdf_texts = [" ".join(page.extract_text().replace(" ", "").split('\n')) for page in pdf_reader.pages]
pdf_texts = [text for text in pdf_texts if text]
character_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ". ", " ", ""],
chunk_size=1000,
chunk_overlap=0
)
character_split_texts = character_splitter.split_text('\n\n'.join(pdf_texts))
print(f"\nTotal chunks: {len(character_split_texts)}")
for chunk in character_split_texts:
all_data.append({"topic": file_name, "content": chunk})
collection_name = config('COMPANY_POLICY_DATA')
chroma_client_host = config('CHROMA_CLIENT_HOST')
chroma_client = chromadb.HttpClient(host=chroma_client_host, port=8000)
try:
chroma_client.delete_collection(name=collection_name)
except:
pass
distance_functions = ["l2", "ip", "cosine"]
sentence_transformer_ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="multi-qa-mpnet-base-dot-v1")
collection = chroma_client.create_collection(
name=collection_name, embedding_function=sentence_transformer_ef, metadata={"hnsw:space": distance_functions[0]})
documents = []
metadata = []
ids = []
n=1
for data in all_data:
documents.append(data['content'])
metadata.append({"topic": data['topic']})
ids.append(f"{data['topic']}_{n}")
n+=1
collection.add(
documents=documents,
metadatas=metadata,
ids=ids
)
return TrueOnce indexed in our vector database, these embeddings are ready for Aubai to search through. This means when you ask about the number of leave days you can take, Aubai consults its digital library to fetch the most accurate and relevant policy details to answer your question.
Aubai isn’t just a chatbot; it’s a sophisticated AI assistant, ready to guide you through the maze of company policies with ease. By integrating cutting-edge AI technologies, such as LLMs, vector databases, and prompt engineering, we’ve crafted an assistant that’s knowledgeable, efficient, and incredibly user-friendly. So, the next time you’ve got a question about your company’s policies, turn to Aubai and chat away—getting the answers you need has never been easier.