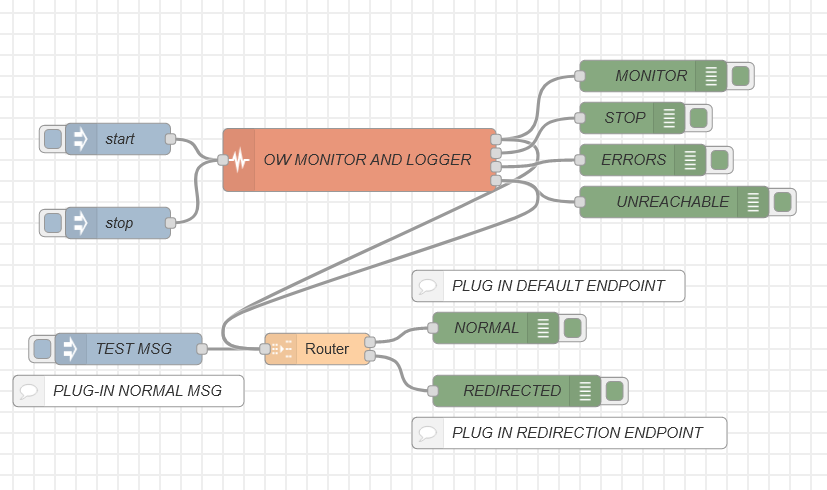
The goal of this subflow is to enable the use of dynamically located Openwhisk action invocations in hybrid cloud/edge or multi-cloud scenarios, in which the location of the target function is not known at design time.

Its main operation is rather simple, it exploits incoming information from the message in order to adapt the url to which the function invocation will be performed. The incoming message to the Dynamic OW Action needs to include the action name in the node UI as well as the following fields in the msg.payload.value:
-__<action_name>_HOST
-___NAMESPACE