UPDATE: A faster (20x) approach for running Stable Diffusion using MLIR/Vulkan/IREE is available on Windows:
conda create --name sd39 python=3.9 -y
conda activate sd39
pip install diffusers==0.3.0
pip install transformers
pip install onnxruntime
pip install onnxYou can download the nightly onnxruntime-directml release from the link below
Run python --version to find out, which whl file to download.
- If you are on Python3.7, download the file that ends with **-cp37-cp37m-win_amd64.whl.
- If you are on Python3.8, download the file that ends with **-cp38-cp38m-win_amd64.whl
- and likewise
pip install ort_nightly_directml-1.13.0.dev20220908001-cp39-cp39-win_amd64.whl --force-reinstallThis apporach is faster than downloading the onnx models files.
- Download diffusers/scripts/convert_stable_diffusion_checkpoint_to_onnx.py to your working directory. You can try the command below to download the script.
wget https://raw.githubusercontent.com/huggingface/diffusers/main/scripts/convert_stable_diffusion_checkpoint_to_onnx.py- Run
huggingface-cli.exe loginand provide huggingface access token. - Convert the model using the command below. Models are stored in
stable_diffusion_onnxfolder.
python convert_stable_diffusion_checkpoint_to_onnx.py --model_path="CompVis/stable-diffusion-v1-4" --output_path="./stable_diffusion_onnx"Here is an example python code for stable diffusion pipeline using huggingface diffusers.
from diffusers import StableDiffusionOnnxPipeline
pipe = StableDiffusionOnnxPipeline.from_pretrained("./stable_diffusion_onnx", provider="DmlExecutionProvider")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")



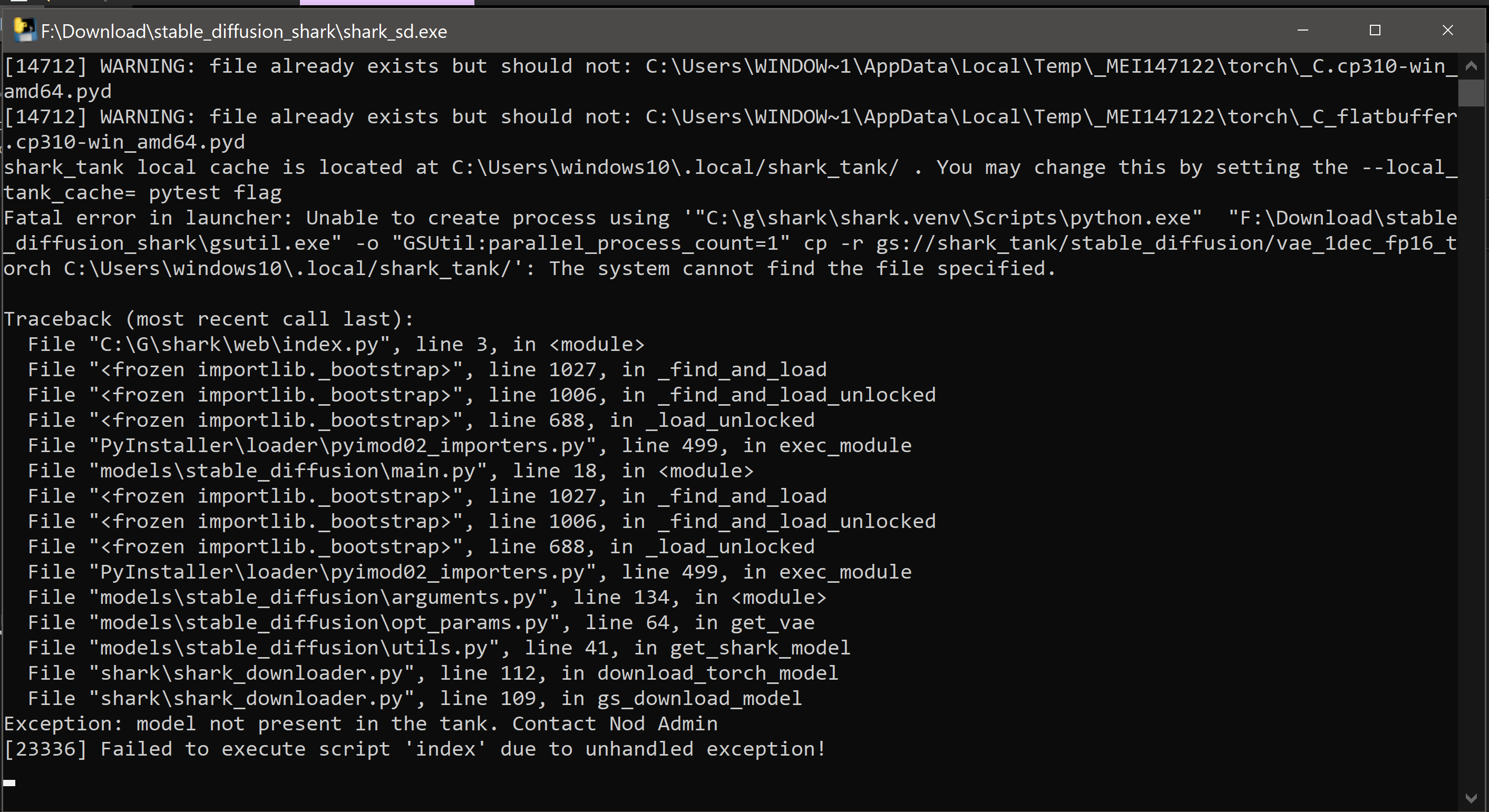
Hi, i love how you made me able to finally use Stable Diffusion on Windows.
I wanted to try out the seed option explained here:
https://colab.research.google.com/github/pcuenca/diffusers-examples/blob/main/notebooks/stable-diffusion-seeds.ipynb
and i just can't get it to work. error is:
(1, pipe.unet.in_channels, height // 8, width // 8), AttributeError: 'OnnxRuntimeModel' object has no attribute 'in_channels'i've tried different things but unfortunately to no avail. do you have any idea how this could work?
cheers!