Hirokazu SUZUKI (@heronshoes) March 20th, 2023
I am developing a data frame library named RedAmber, based on Red Arrow which is a Ruby implementation of Apache Arrow (on memory columnar data processing framework). This is the final report of RedAmber development for Ruby Association Grant 2022, through October 2022 to March 2023.
In this period I released 4 versions. The changelogs and release notes are below.
I will report the activities in these sections.
- New features
- Feedbacks for Red Arrow project
- Improvement in performance
- Imporvement in code quality
- Improvement in documentation
- Promotional activities
I implemented the operations of joining a dataframe to other dataframe in DataFrameCombinable module.
- Introduced in v0.2.3 .
- Added to specify keys by a Hash in v0.3.0 .
- Added sorting after join by the option
:force_order.

I built an R-like style join functions using Red Arrow's Table#join, by implementing methods such as #left_join with the :type option preset.
Since Red Arrow keeps the left and right columns, I used :left_outputs and :right_outputs options to left only the columns needed and merged them together to leave a single column if necessary.
Red Arrow allows duplicate column names, but duplicate column names (keys) are generally not allowed in data frames or RDB tables. RedAmber also implements a feature to rename duplicated keys with suffixes. The default suffix is suffix: '.1', and only the column name of the other data frame is renamed, and if it still duplicates, succ is used. This is because renaming both self and other is excessive, and also because it is a method call to self in Ruby .
If join_key is omitted, it will automatically join using common column names (Natural join). This has been proposed and merged(GH-15088) into Red Arrow's Table.
Set operations and binding operations (vertical and horizontal) are also constructed by Arrow''s Table#join`.
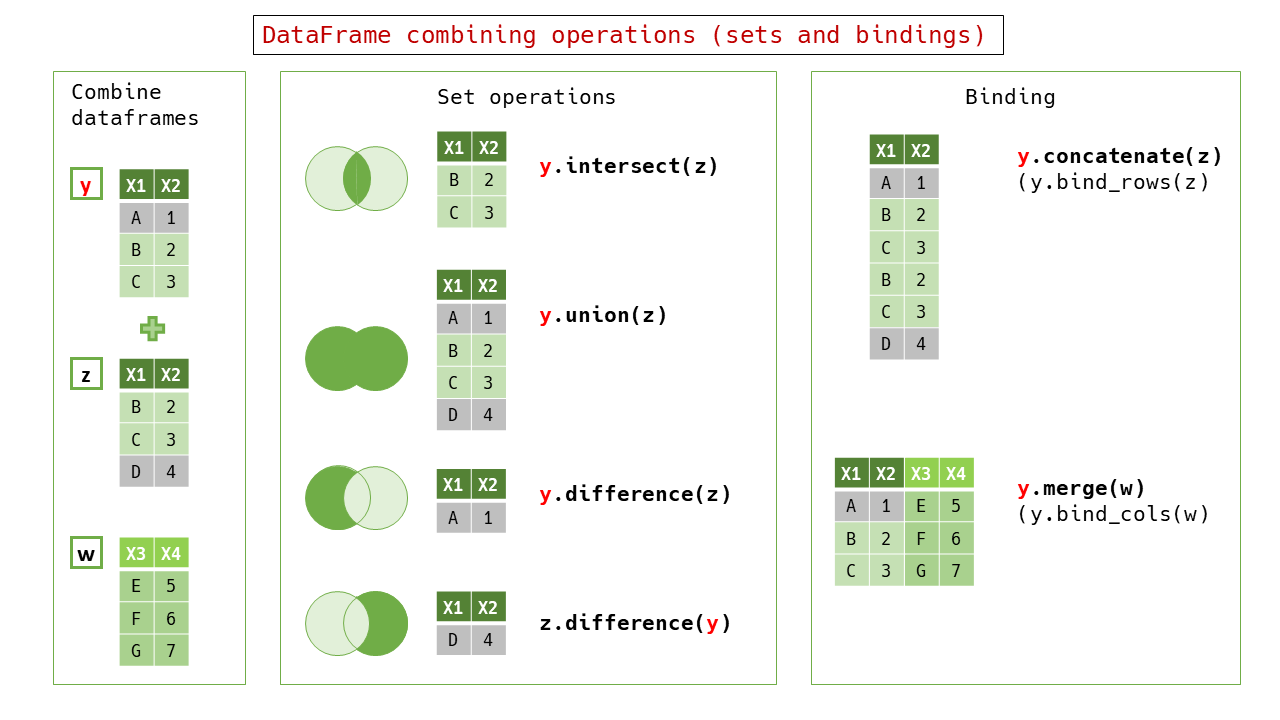
Although generally similar to the R vocabulary, the difference operation uses #difference as the primary method name instead of #setdiff, which is the same as Ruby's Array. The #concatenate is assigned to the column-lengthening concatenation, and the #merge to the row-lengthening concatenation.
In Arrow's implementation, the order of records (rows) after merging is undefined. This is more obvious when the number of records becomes large (the result is different for each execution). This is advantageous in execution speed, but conventional data frame libraries and database systems seem to give priority to the left table to maintain the order of rows, so the indefinite order may not be intuitive. Also, when writing tests, it is inconvenient if the order is indefinite.
Polars, a Rust's data frame library based on another implementation of Arrow (Arrow2) that can handle Arrow format, has an option to keep the original row order. RedAmber also adopted this feature in v0.4.0. The left and right dataframes are pre-loaded with index columns, and sorted after merging to remove the index columns, which is not very fast, but I set the sorting to the default behavior in RedAmber because it provides clear results. In 0.4.1, sorting is enabled for all join-based methods in mutating joins and filtering joins.
A function Vector#split_* is implemented to split an element of a vector by a space character or an arbitrary character, to divide it into multiple vectors, or to generate vectors aligned in length direction (implemented in v0.3.0). Also, a method Vector#merge is implemented to generate a vector whose elements are strings concatenated with vector elements or scalars (implemented in v0.3.0).
- Divide the elements of a vector into multiple vectors by whitespaces or characters.
vector = RedAmber::Vector.new(['a b', 'c d', 'e f'])
vector
#=>
#<RedAmber::Vector(:string, size=3):0x0000000000050014>
["a b", "c d", "e f"]
vector.split_to_columns
#=>
[#<RedAmber::Vector(:string, size=3):0x0000000000058cc8>
["a", "c", "e"]
,
#<RedAmber::Vector(:string, size=3):0x0000000000058cdc>
["b", "d", "f"]
]This method can be used to split a column of data frames by a specific character.
RedAmber::DataFrame.new(year_month: %w[2023-01 2023-02 2023-03])
.assign(:year, :month) { year_month.split_to_columns('-') }
#=>
#<RedAmber::DataFrame : 3 x 3 Vectors, 0x0000000000078ed8>
year_month year month
<string> <string> <string>
0 2023-01 2023 01
1 2023-02 2023 02
2 2023-03 2023 03If sep is omitted, this method uses Arrow's ascii_split_whitespace() to split elements of Arrow::StringArray with whitespace characters at high speed. On the other hand, if sep' is specified, Ruby's String#sep` is used to perform flexible division by specifying a regular expression.
RedAmber::DataFrame.new(yearmonth: %w[202301 202302 202303])
.assign(:year, :month) { yearmonth.split_to_columns(/(?=..$)/) }
#=>
#<RedAmber::DataFrame : 3 x 3 Vectors, 0x0000000000078eec>
yearmonth year month
<string> <string> <string>
0 202301 2023 01
1 202302 2023 02
2 202303 2023 03- The elements of a vector are divided by whitespace or arbitrary characters to produce a vector aligned in the length direction.
vector
#=>
#<RedAmber::Vector(:string, size=3):0x0000000000050014>
["a b", "c d", "e f"]
vector.split_to_rows
#=>
#<RedAmber::Vector(:string, size=6):0x00000000000809d0>
["a", "b", "c", "d", "e", "f"]- Generate a vector whose elements are strings or vectors concatenated element by element into self.
vector = RedAmber::Vector.new(%w[a c e])
other = RedAmber::Vector.new(%w[b d f])
vector.merge(other)
#=>
#<RedAmber::Vector(:string, size=3):0x00000000000a530c>
["a b", "c d", "e f"]
vector.merge('x', sep: '')
#=>
#<RedAmber::Vector(:string, size=3):0x00000000000b1008>
["ax", "cx", "ex"]As a new concept not found in conventional data frames, the SubFrames class was designed and implemented as an experimental feature.

SubFrames is an object that hold subsets of a DataFrame and have an iterator that returns the elements as DataFrames. SubFrames unifies the functions of existing dataframe/database's groups (e.g., group_by or groupby), rolling window functions (e.g., moving average), and window functions for element-by-element processing. SubFrames are characterized by a notation that can be applied as is to ordinary DataFrames through the use of Ruby-like iterators, as well as the unified handling of window functions that process each element.
The figure above shows an example of SubFrames for the grouping of dataframes. The left half is essentially the same as the existing group_by operation, which groups data frames according to the value of column y from the base data frame. SubFrames object returns each separated data frames. The right half is an aggregation of a single data frame into a single row. Operations on a single data frame element can be written as an aggregate operation for the entire data frame in SubFrames.
The conventional grouping operation is based on the idea of aggregation from the state of the original data frame through the "grouped state". The same is true for RedAmber's Group class which has an origin in Red Arrow table Group.

The figure above shows an example of aggregation by RedAmber's Group class, which maintains a dataframe-like state separated by column values, but with Group-specific behavior.
The following is a comparison of the conventional Group class and SubFrames.
- Group
- It is available for the information on the key column that was the source of the group partitioning.
- Grouping and aggregation are integrated and there is an engine to perform them efficiently (Acero)
- SubFrames
- A more generalized concept, the method of separation is not limited to grouping by value and has a wider range of applications.
- While it is possible to generate SubFrames from SubFrames, it is not possible to preserve information on the source key columns of grouping.
- Although it is necessary to explicitly write the source key in grouping when outputting, but it is simple to write the desired key name and column Vector to get the result. It is common notation with DataFrame's Rename and Assign.
R's tidyr introduces the concept of "nest" as shown below.

Nested dataframe is the concept of incorporating the original dataframe as nested rows in the form of an aggregated dataframe.
In Arrow's Compute Function, aggregate functions for normal tables (e.g., sum) are different from those for groups (e.g., hash_sum). In RedAmber, however, aggregate methods for Vectors in DataFrames can be used in SubFrames without modification. Also, if you write a new aggregation function for a Vector, it can be applied directly to SubFrames, making it easy to create your own aggregation process. This makes it possible to easily create your own aggregation processing.
The same concept can be applied to a rolling window where operations are performed by sequentially acquiring rows of the original data frame.

In the example above, a window of size 3 is applied to the original DataFrame to obtain SubFrames consisting of 4 DataFrames.
Next #aggregate is used to aggregate one DataFrame into a single row.
The x.mean is therefore a moving average operation. The process of obtaining a moving average consists with the operation of separating the data in the window and the calculation of the average with a Vector's function #mean.
Therefore, the function to calculate the mean does not need to be special. Unlike Grouping described above, the contents of SubFrames have overlaps from each other.
An example of an operation to create new SubFrames from SubFrames is shown below.

In this example, the sequential numbers starting from 1 for each group and the cumulative sum for each group are generated for the SubFrames generated by the Grouping by Value method already introduced.
Since #indeces and #cumsum are not an aggregate function method of Vector, but return values for each element, the result obtained is SubFrames.
The bottom left of the figure above is an example of the same operation on the entire data frame by DataFrame#assign.
Compared to SubFrames#assign on the right, the operation is performed in exactly the same way, not only in the method but also in the contents of the block. This consistency is the greatest feature of SubFrames.
SubFrames can also be generated from Ruby's Enumerator (left). They can also be generated from a masked window (called a kernel) (right). The kernel can be used, for example, to obtain pairs of data from daily data for "the same weekday of the previous week and today".

SubFrames can also be generated based on arrays of indices starting from 0.

The example above shows how to separate even-numbered rows from odd-numbered rows. And the example below shows how to randomly extract two adjacent rows. In this way, SubFrames can be applied to a large number of use cases.
(As a reference:) The example above can also be written as follows using Array#partition.
df.build_subframes do
(0...size).partition(&:odd?)
endChanging &:odd? to &:even? will reverse the order in SubFrames.
The current implementation of SubFrames is written in Pure Ruby, it actually generates sub data frames internally even it is partially using lazy generation. Therefore, it is more than 70 times slower than the Group class, which calls Acero in C++ for the same operation. In the future, I would like to work with the upstream side to speed up SubFrames. In this case, I would like to make it look to the user as if there is an internal data frame, while in reality it is represented by a Record Batch, or by using a set of index arrays.
Although modulo or remainder are relatively common functions, Arrow C++'s Compute function divmod() has been in a draft state for a long time and has not been implemented in RedAmber (it must use #map, Numeric#modulo and Numeirc#remainder in Pure Ruby).
So I combined existing #divide, #floor, #trunc, #multiply, and #subtract to create #modulo and #remainder.
integer = RedAmber::Vector.new(1, 2, 3)
divisor = RedAmber::Vector.new(2, 2, 2)
integer.modulo(divisor)
=>
#<RedAmber::Vector(:uint8, size=3):0x00000000002c46d8>
[1, 0, 1]There are differences among language systems in the handling of negative numbers, RedAmber's behavior is the same as that of Ruby i.e., #modulo and #% have the same sign as the divisor, and #remainder has the same sign as the divisor. This is not similar to Numo/NArray's #% (has the same sign as the divisor).
Introduced method #propagate to use aggregate functions as element-wise functions.
This is useful in combination with SubFrames.
import_cars
=>
#<RedAmber::DataFrame : 5 x 6 Vectors, 0x0000000000390af8>
Year Audi BMW BMW_MINI Mercedes-Benz VW
<int64> <int64> <int64> <int64> <int64> <int64>
0 2017 28336 52527 25427 68221 49040
1 2018 26473 50982 25984 67554 51961
2 2019 24222 46814 23813 66553 46794
3 2020 22304 35712 20196 57041 36576
4 2021 22535 35905 18211 51722 35215
import_cars
.to_long(:Year, name: :Manufacturer, value: :n_of_imported)
.sub_by_value(keys: :Year)
.assign do
{ sum_by_year: n_of_imported.propagate(:sum) }
end
=>
#<RedAmber::SubFrames : 0x000000000067ddd8>
@baseframe=#<Enumerator::Lazy:size=5>
5 SubFrames: [5, 5, 5, 5, 5] in sizes.
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067ddec>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2017 Audi 28336 223551
1 2017 BMW 52527 223551
2 2017 BMW_MINI 25427 223551
3 2017 Mercedes-Benz 68221 223551
4 2017 VW 49040 223551
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de00>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2018 Audi 26473 222954
1 2018 BMW 50982 222954
2 2018 BMW_MINI 25984 222954
3 2018 Mercedes-Benz 67554 222954
4 2018 VW 51961 222954
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de14>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2019 Audi 24222 208196
1 2019 BMW 46814 208196
2 2019 BMW_MINI 23813 208196
3 2019 Mercedes-Benz 66553 208196
4 2019 VW 46794 208196
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de28>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2020 Audi 22304 171829
1 2020 BMW 35712 171829
2 2020 BMW_MINI 20196 171829
3 2020 Mercedes-Benz 57041 171829
4 2020 VW 36576 171829
---
#<RedAmber::DataFrame : 5 x 4 Vectors, 0x000000000067de3c>
Year Manufacturer n_of_imported sum_by_Year
<uint16> <string> <uint32> <uint32>
0 2021 Audi 22535 163588
1 2021 BMW 35905 163588
2 2021 BMW_MINI 18211 163588
3 2021 Mercedes-Benz 51722 163588
4 2021 VW 35215 163588Vector#sample is a method that randomly samples the elements of a Vector and returns a new Vector.
#sample takes an Integer or Float argument as the sampling size.
- Integer (n) specifies the number of sampling.
- Float (prop) specifies the number of sampling as a ratio to the size of Vector.
- If
n <= self.sizeorprop <= 1.0, sampling is done without repetition.
v = RedAmber::Vector.new('A'..'H')
v
=>
#<RedAmber::Vector(:string, size=8):0x0000000000011b20>
["A", "B", "C", "D", "E", "F", "G", "H"]When n == size, n elements are randomly arranged without repetition.
v.sample(8)
=>
#<RedAmber::Vector(:string, size=8):0x000000000001bda0>
["H", "D", "B", "F", "E", "A", "G", "C"]If n > size or prop > 1.0, sampling with repetition.
v.sample(2.0)
# =>
#<RedAmber::Vector(:string, size=16):0x00000000000233e8>
["H", "B", "C", "B", "C", "A", "F", "A", "E", "C", "H", "F", "F", "A", ... ]- A scalar is returned without arguments.
v.sample # => "C"Bugs encountered while developing RedAmber and suggestions for functional improvements are fed back to Red Arrow as needed. I would like to actively transfer basic functionality to Red Arrow.
- Bug Reports
- Bug reports and fixes in CI's homebrew (GH-15093):Merged
- Suggestions for improvements to features used in RedAmber
- Feature/Improvement Suggestions
- Reduce waiting time in REPL environment by returning self when saving csv with Table#save(GH-15289):Merged
- [GLib] Propose support for 'MatchSubstringOptions' (GH-15285):Suggested improvements
- GLib] Proposed support for 'IndexOptions' (GH-15286:Suggested improvements
- [GLib] Proposed support for 'RankOptions' (GH-34425:Implemented by @kou and merged into 12.0.0.
- [C++] 'rank()' does not support ChunkedArray (GH-34426):Issue reported
- Review.
RecordBatch{File,Stream}Reader#eachsupports the case where there is no block (GH-34440) Suggest additional feature thatEnumerator#sizecan return a non-nil value if the number of iterations is known: merged.
I am especially grateful to Sutou Kouhei(@kou) for his generous support in this activity.
As the first step, a benchmark was created in v0.2.3 to allow performance comparisons between versions of the main methods.
Benchmarks were created using benchmark_driver, and data was mainly from the nycflights13 dataset from RDataset, which has a relatively large data size.
In the second step, the code was completely revised to improve the processing speed by refactoring, such as replacing faster processes, changing the order of processes, and removing unnecessary processes. The following is a version-by-version comparison: v0.3.0 is the version after refactoring, v0.2.3 is the previous version with almost the same functionality and v0.2.0 is the reference version before the development grant period.
Measurements were taken in the following environment.
- distro: Ubuntu 20.04.5 LTS on Windows 11 x86_64
- kernel: 5.15.79.1-microsoft-standard-WSL2
- cpu: Intel i7-8700K (12) @ 3.695GHz
- memory: 30085MiB
- Ruby: ruby 3.2.0 (2022-12-25 revision a528908271) +YJIT [x86_64-linux]
- Arrow: 10.0.0
3.1 Basic benchmark: Tests for basic data frame operations
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 | 0.1.5 |
|---|---|---|---|---|---|
| B01 | Pick([]) by a key name | 434,783 | 8,759 | 9,357 | 202,703 |
| B02a | Pick([]) by key names | 2,530 | 897 | 1,898 | 2,276 |
| B03 | Pick by key names | 2,783 | 653 | 4,374 | 2,311 |
| B04 | Drop by key names | 694 | 352 | 761 | 675 |
| B05 | Pick by booleans | 792 | 383 | 1,094 | 1,005 |
| B06 | Pick by a block | 920 | 386 | 1,346 | 1,091 |
| B07 | Slice([]) by an index | 597 | 445 | 798 | 1,934 |
| B08 | Slice by indeces | 51.4 | 47.1 | 51.7 | 56.2 |
| B09 | Slice([]) by booleans | 54.7 | 2.3 | 2.3 | 0.3 |
| B10 | Slice by booleans | 103.3 | 2.3 | 2.2 | 3.0 |
| B11 | Remove by booleans | 78.6 | 2.2 | 2.4 | 2.7 |
| B12 | Slice by a block | 100.9 | 2.4 | 2.3 | 3.0 |
| B13 | Rename by Hash | 804 | 508 | 853 | 737 |
| B14 | Assign an existing variable | 3.2 | 3.2 | 3.3 | 3.4 |
| B15 | Assign a new variable | 3.3 | 3.4 | 3.3 | 3.5 |
| B16 | Sort by a key | 18.5 | 19.3 | 20.0 | 18.4 |
| B17 | Sort by keys | 11.8 | 11.6 | 12.0 | 12.1 |
| B18 | Convert to a Hash | 2.8 | 2.3 | 2.4 | 2.3 |
| B19 | Output in TDR style | 1.3 | 1.3 | 1.3 | 1.3 |
| B20 | Inspect | 17.0 | 14.7 | 16.6 | 1.7 |



There are several cases where the latest version is slower, and I believe this is due to the following:
- The early versions were not balanced in terms of processing speed. (e.g., indexing is fast, but filtering is extremely slow)
- Branching in operation took more time as more features were added.
Example: Pick can accept index, column name, or boolean filter now.
(Indexes and column names can be mixed, e.g.
penguins.pick(0..2, -5, :year))
3.2 Combine benchmark: Tests for joining operations
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 |
|---|---|---|---|
| C01 | Inner join on flights_Q1 by carrier | 106.3 | 0.9 |
| C02 | Full join on flights_Q1 by planes | 0.9 | 0.6 |
| C03 | Left join on flights_Q1 by planes | 70.6 | 0.6 |
| C04 | Semi join on flights_Q1 by planes | 103.9 | 100.5 |
| C05 | Anti join on flights_Q1 by planes | 244.2 | 230.4 |
| C06 | Intersection of flights_1_2 and flights_1_3 | 46.8 | 0.2 |
| C07 | Union of flights_1_2 and flights_1_3 | 0.07 | 0.07 |
| C08 | Difference between flights_1_2 and flights_1_3 | 51.5 | 53.1 |
| C09 | Concatenate flight_Q1 on flight_Q2 | 7,393 | 2,903 |
| C10 | Merge flights_Q1_right on flights_Q1_left | 0.6 | 0.6 |

3.3 Group benchmark: Tests for grouping operations
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.2 |
|---|---|---|---|---|
| G01 | sum distance by destination | 119.9 | 122.5 | 120.3 |
| G02 | sum arr_delay by month and day | 168.4 | 155.8 | 140.8 |
| G03 | sum arr_delay, mean distance by flight | 29.6 | 25.6 | 27.8 |
| G04 | mean air_time, distance by flight | 110.5 | 102.0 | 102.9 |
| G05 | sum dep_delay, arr_delay by carrer | 123.6 | 121.3 | 111.0 |

3.4 Reshape benchmark: Tests for the reshaping operations
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.2 |
|---|---|---|---|---|
| R01 | Transpose a DataFrame | 3.8 | 3.4 | 3.7 |
| R02 | Reshape to longer DataFrame | 1.5 | 1.6 | 1.6 |
| R03 | Reshape to wider DataFrame | 0.7 | 0.6 | 0.7 |

3.5 Vector benchmark: Tests for Vector functions
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 |
|---|---|---|---|---|
| V01 | Vector.new from integer Array | 7.2 | 6.0 | 6.4 |
| V02 | Vector.new from string Array | 1.6 | 1.7 | 1.7 |
| V03 | Vector.new from boolean Vector | 1,220,000 | 6.6 | 6.7 |
| V04 | Vector#sum | 11,256 | 11,624 | 10,823 |
| V05 | Vector#* | 1,397 | 1,527 | 1,466 |
| V06 | Vector#[booleans] | 4.8 | 6.8 | 6.8 |
| V07 | Vector#[boolean_vector] | 22.2 | 6.6 | 6.7 |
| V08 | Vector#[index_vector] | 22.0 | 28.0 | 27.6 |
| V09 | Vector#replace | 0.4 | 0.4 | 0.4 |
| V10 | Vector#replace with broad casting | 0.4 | 0.4 | 0.4 |

3.6 DataFrame benchmark: Tests for series of data frame operation
Iteration per second (i/s): (The bigger the faster)
| # | Benchmark name | 0.3.0 | 0.2.3 | 0.2.0 |
|---|---|---|---|---|
| D01 | Diamonds test | 189.8 | 14.5 | 14.5 |
| D02 | Starwars test | 143.6 | 78.8 | 107.0 |
| D03 | Import cars test | 141.4 | 141.9 | 125.6 |
| D04 | Simpsons paradox test | 45.4 | 3.1 | 3.1 |

- Diamonds test : It is used in RedAmber's README
- Starwars test : It is used in RedAmber's README
- Import cars test : It is used in RedAmber's document (With some arrangement in DataFrame.md)
- Simpsons paradox test : Introduced by the post in Qiita 「RedAmber - Ruby's data frame library (in japanese)
The number of iterations (per second) of these four comprehensive tests is converted to execution time to obtain the total execution time, and RedAmber performs the operation to determine the rate of change in execution speed.
require 'red_amber'
df = RedAmber::DataFrame.load(Arrow::Buffer.new(<<CSV), format: :csv)
test_name,0.3.0,0.2.3,0.2.0
D01: Diamonds test,189.817,14.531,14.540
D02: Starwars test,143.570,78.772,107.044
D03: Inport cars test,141.395,141.861,125.560
D04: Simpsons paradox test,45.353,3.105,3.133
CSV
df
#=>
#<RedAmber::DataFrame : 4 x 4 Vectors, 0x000000000007e8d8>
test_name 0.3.0 0.2.3 0.2.0
<string> <double> <double> <double>
0 D01: Diamonds test 189.82 14.53 14.54
1 D02: Starwars test 143.57 78.77 107.04
2 D03: Inport cars test 141.4 141.86 125.56
3 D04: Simpsons paradox test 45.35 3.11 3.13
versions = df.keys[1..]
#=> [:"0.3.0", :"0.2.3", :"0.2.0"]
versions.map { |ver| (1 / df[ver]).sum } => a
#=> [0.04135511938110967, 0.41062359984495833, 0.4052649554075024]
a[2] / a[0]
#=>
9.799632100508957Based on the above, I achieved a speedup of 980% over v0.2.0, far exceeding my initial target of 20% performance improvement over v0.2.0 for a basic set of data frame operations for the benchmark.
On a relatively slow machine, such as:
- OS: macOS 11.7.2 20G1020 x86_64
- Machine: MacBookPro11,1 (Retina, 13-inch, Late 2013)
- CPU: Intel i5-4258U (4) @ 2.40GHz
- Memory: 5554MiB / 8192MiB
the improvement was even higher, at a ratio of 1175% over v0.2.0 .
Processes equivalent to the DataFrame benchmark in above were written in other languages and the execution times were compared.
It was performed with Python's pandas and R's tiryverse (dplyr or tidyr) as commonly used libraries.
The dataframe operations were assumed to yield the same results as in the DataFrame benchmark above, but they differ from the tests in Section 3.6 because they include deserialization, which reads locally available csv or tsv files.
If there is no corresponding process for a given processor, an equivalent process is used instead. (In R, there is no transpose, so the operation from long to wide on a different axis is performed instead, etc.)
| test_name | red_amber | pandas | tidyverse | (Ref) Dataset size |
|---|---|---|---|---|
| Diamonds_test | 28.2 | 80.9 | 243.0 | 53940 x 10 |
| Starwars_test | 19.1 | 19.5 | 43.3 | 87 x 12 |
| Import_cars_test | 17.4 | 18.3 | 48.4 | 5 x 6 |
| Simpsons_paradox_test | 58.0 | 201.0 | 653.5 | 268166 x 4 |

At the very least, it has an advantage over traditional data frames. The use of Apache Arrow makes data deserialization particularly fast, and the larger the data set, the more likely the difference is to be noticeable. Future comparisons using the Arrow extension are needed for both R and Python.
As a large and general dataset that can also be used for scalability evaluation, I am trying with the "Wisconsin Benchmark" machine synthesis dataset, which has been used for database evaluation in the past, but RedAmber is still insufficient for handling large datasets.
The demand for well-designed benchmarks for data frames is expected to increase in the future for the following reasons.
- It is more important to compare the entire dataframe processing workflow, not just individual processing nodes.
- Unified evaluation of common dataframe and database processing is needed.
- Demand for comparison of scalability of processing systems due to increasing data volume.
- Benchmarks that automatically generate workloads are useful for testing and identifying bottlenecks.
(Reference:FuzzyData: A Scalable Workload Generator for Testing Dataframe Workflow Systems)
To measure Test coverage, simplecov was introduced in v0.2.3. The coverage was 98.54% with 43 uncovered lines at the time of introduction.
I worked on improving the coverage as well as refactoring the code, and achieved 100% coverage in v0.3.0. I will maintain the coverage in the future.
Rubocop was introduced to ensure code quality, and rubocop-performance and rubocop-rubycw are also enabled to ensure consistency.
Although many of the metrics exceed the default values, I do not turn them off globaly but I ignore them for each method and file so that I can see which part is the target of refactoring.
YARD document coverage was 73.1% when I started measuring at the beginning of the project.
In the latter half of the project period, special effort was dedicated to document maintenance, achieving 100% YARD document coverage. The latest release continues to achieve 100% coverage even most of the methods has @examples.
DataFrame.md and Vector.md have been completed as markdown documentation for all methods, and the latest methods continue to be added.
Functional methods of Vector, such as #mean, #abs, #>, are generated dynamically by define_method using Arrow's Compute function.
At first I did not know how to efficiently add documentation in such cases, but finally I arrived at the following method.
Create method generator as class methods, and individual method definitions are written in DSL style.
class Vector
class << self
private
def define_unary_aggregation(function)
define_method(function) do |**options|
datum = exec_func_unary(function, options)
get_scalar(datum)
end
end
end
define_unary_aggregation :approximate_median
end-
Common documents are attached to class methods with
@!macro[attach]. (1). -
Macros that are not common to all but used as needed should be defined above instance methods (2).
-
Method-specific documentation should be written right above the method definition (3).
-
Write arguments and options with
@!method(4). -
Alias names of methods are written with
alias_method(5). Methods can also be written as class methods, which will be correctly displayed in the documentation asAlso known as:.class Vector class << self private # @!macro [attach] define_unary_aggregation # (1) # [Unary aggregation function] Returns a scalar. # def define_unary_aggregation(function) define_method(function) do |**options| datum = exec_func_unary(function, options) get_scalar(datum) end end end # @!macro scalar_aggregate_options # (2) # @param skip_nulls [true, false] # If true, nil values are ignored. # Otherwise, if any value is nil, emit nil. # @param min_count [Integer] # if less than this many non-nil values are observed, emit nil. # If skip_nulls is false, this option is not respected. # Approximate median of a numeric Vector with T-Digest algorithm. # (3) # # @!method approximate_median(skip_nulls: true, min_count: 1) # (4) # @macro scalar_aggregate_options # (2) # @return [Float] # median of self. # A nil is returned if there is no valid data point. # define_unary_aggregation :approximate_median alias_method :median, :approximate_median # (5) end
Created document is in RedAmber YARD Vector#approximate_median.
The corresponding YARD document is YARD document.
The RedAmber documentation uses @example to display many code examples, but by default they are displayed in a proportional font.
I arrived at the following method to work around this.
Add custom template path in .yardopts
--template-path doc/yard-templates
Put customized css below in doc/yard-templates/default/fulldoc/html/css/common.css.
/* Use monospace font for code */
code {
font-family: "Courier New", Consolas, monospace;
}
Result:

When customizing this template, it must be placed in the same directory structure as the YARD standard template YARD document.
I have been gradually increasing the number of examples of RedAmber operations in Jupyter Notebook. 100 or more was our goal at the start of the RA Grant, and we have achieved 106 as of v0.4.0.
https://github.com/heronshoes/docker-stacks/blob/RedAmber-binder/binder/examples_of_red_amber.ipynb
We have created a table comparing the functionality of RedAmber with dataframe libraries in other languages. The column about Julia data frames was contributed by Benson Muite.
https://github.com/heronshoes/red_amber/blob/main/doc/DataFrame_Comparison.md
- Article posted to the web
- RedAmber - Ruby's new data frame library (November 28, 2022, note)
- RedAmber - Ruby's new data frame library, (December 04, 2022, Qiita)
- What we are trying to do with RedAmber](https://qiita.com/heronshoes/items/b0ae1f4c23decd8c261b), (December 18, 2022, Qiita)
- Youtube streaming
- I have been participating in the monthly streaming of Red-data-tools as a questioner since November.
- We were able to develop a data frame library that can directly handle Arrow data in Ruby which has been behind in the development.
- We achieved "data frame processing that can be written like Ruby" through block and use of Ruby's collection classes.
- Almost all major functions of data frames were covered.
- Documentation with rich examples of operations was prepared.
- The difference between the code of October 4 (v0.2.2) and March 11 (v0.4.1) was that 77 files were changed, 14702 lines were added, and 2637 lines were deleted. (documentation contributed significantly).
- The code was revised to improve speed since the start of grant..
- Test coverage was increased to 100% to ensure a certain level of code quality.
- Introduced a new concept "SubFrames" not found in other data frame libraries and implemented it as an experimental feature. I showed that groups and windows can be handled in a simple and consistent manner by Ruby. Improving speed is an issue for the future.
- I made suggestions to enhance necessary functions for upstream Red Arrow and contributed to the improvement of table join operations.
- Andrew Kane, the author of Rover (the library that inspired the development of Red Amber), created Polars-ruby. Polars-ruby is a library based on Rust's Polars, which can read and write the Arrow Format. It is characterized by its high speed and has a very promising future. I hope to introduce its advanced features such as LazyFrame in RedAmber.
I would like to thank my mentor of RA grant, Kenta Murata (@mrkn), for his constant advice and warm support throughout this project. I would also like to thank Sutou Kouhei (@kou) his wide-ranging advice on Red Arrow commits and RedAmber bugs as well as his support in monthly streaming of Red Data Tools. Benson Muite (@bkmgit) added the Fedra testing workflow and the Julia section of the comparison table with other data frames. @kojix2 contributed to the code by adding the YARD documentation generation workflow and modifying the documentation. I appreciated to their contributions. I would also like to thank the members of Red Data Tools Gitter for their valuable comments and suggestions on method name discussions and other issues. Finally, I would like to express my deepest gratitude to Ruby Assciation for giving me this opportunity and to Matz and everyone in the Ruby community for creating and growing Ruby.
To create the bar chart for benchmark comparison, the data was read as a RedAmber's DataFrame using the following procedure, converted to longer data, and plotted in Charty to create the chart.



Below is a summary of the Jupyter Notebook used for benchmark comparisons with other language libraries.