- gallery入库
- 测试query中每一类别图片与gallery中所有图片的特征相似度,保存gallery图片路径和相似度值
- 根据相似度排序检索的图片,并输出Top20图片到文件夹
- 统计检出的第一张图是同一类别,计数top1(不考虑阈值),计算相似度是否大于阈值,计数Top_One正确数
- 统计大于阈值的不是同一类别的图片数量,计算false_alarm_num虚警数
- 计算rank,统计底层中搜出同类别数量计数t,rank=rank+(float)t/(i+1)
- 检测精度rank/t,计入总mAP += rank/t
- 重复2-7,检索完成所有的query类别的所有图片
- 输出Top1检测数量top1,TOP1/Rank-1检出率top1/query_total_num,mAP平均均值精度mAP/query_total_num,余弦比对耗时,正确率Top_One/query_total_num,虚警数false_alarm_num,虚警率false_alarm_num/query_total_num
-
-
Save hewumars/d0629947e737426afa968eff579d8c76 to your computer and use it in GitHub Desktop.
1. 图像检索测试demo流程
2. 图像re-rank流程
3. delg模型感受野计算
4. attention模块
5. pca降维
6. BOF,KV,VLAD等局部聚合描述符
7. GeM聚合描述符
8. 相似度比对
//pHandle推理句柄,ppQuery查询图像buffer,nQuery查询图像数量,ppGallery底库图像buffer,nGallery底库图像数量,nTopK返回数量,pSimilarity、pIndex相似度及索引
int hz_reRank_By_Geometric_Verification(const void* pHandle,const char** ppQuery,const int nQuery,const char** ppGallery,const int nGallery,const int nTopK,float** pSimilarity, int** pIndex)RANSAC先验知识: OpenCV中滤除误匹配对采用RANSAC算法寻找一个最佳单应性矩阵H,矩阵大小为3×3。RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h3=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
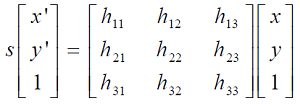
其中(x,y)表示目标图像角点位置,(x',y')为场景图像角点位置,s为尺度参数。
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。
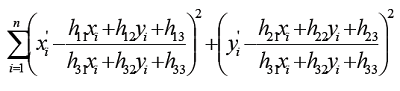
- 随机从数据集中随机抽出4个样本数据 (此4个样本之间不能共线),计算出单应矩阵H,记为模型M
- 计算数据集中所有数据与模型M的投影误差,若误差小于阈值,加入内点集 I
- 如果当前内点集 I 元素个数大于最优内点集 I_best,则更新 I_best = I,同时更新迭代次数k
- 如果迭代次数大于k,则退出 ; 否则迭代次数加1,并重复上述步骤
注:迭代次数k在不大于最大迭代次数的情况下,是在不断更新而不是固定的; 其中,p为置信度,一般取0.995;w为"内点"的比例 ; m为计算模型所需要的最少样本数=4;
通过空间验证GeometricVerification的Re-Rank步骤:
- 过滤输入得到参加排序的底库索引数组
- 加载查询图像关键点特征
- 初始化[N,2]数组M,包含内点数0和初始化相似度,N代表底库图像数量
- 循环浏览排序最高的底库图像
- 读取底库图像关键点特征
- 匹配查询图像和底库图像的特征得到内点数,并计入M[i][0]
- 重复4-6得到所有底库与查询图像特征的内点数,即M数组
- 以M数组的内点数重排序,内点最多为top1
- 得到重排序后的底库图像索引数组
其中步骤6,特征匹配通过cKDTree搜索查询图像和底库图像关键点特征相似度排序索引,然后得到查询图像关键点坐标和底库对应坐标,使用ransac匹配,得到内点数量
完整代码如下:
# Copyright 2019 The TensorFlow Authors All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Library to re-rank images based on geometric verification."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import io
import os
import matplotlib.pyplot as plt
import numpy as np
from scipy import spatial
from skimage import feature
from skimage import measure
from skimage import transform
from delf import feature_io
# Extensions.
_DELF_EXTENSION = '.delf'
# Pace to log.
_STATUS_CHECK_GV_ITERATIONS = 10
# Re-ranking / geometric verification parameters.
_NUM_TO_RERANK = 100
_NUM_RANSAC_TRIALS = 1000
_MIN_RANSAC_SAMPLES = 3
def MatchFeatures(query_locations,
query_descriptors,
index_image_locations,
index_image_descriptors,
ransac_seed=None,
descriptor_matching_threshold=0.9,
ransac_residual_threshold=10.0,
query_im_array=None,
index_im_array=None,
query_im_scale_factors=None,
index_im_scale_factors=None,
use_ratio_test=False):
"""Matches local features using geometric verification.
First, finds putative local feature matches by matching `query_descriptors`
against a KD-tree from the `index_image_descriptors`. Then, attempts to fit an
affine transformation between the putative feature corresponces using their
locations.
Args:
query_locations: Locations of local features for query image. NumPy array of
shape [#query_features, 2].
query_descriptors: Descriptors of local features for query image. NumPy
array of shape [#query_features, depth].
index_image_locations: Locations of local features for index image. NumPy
array of shape [#index_image_features, 2].
index_image_descriptors: Descriptors of local features for index image.
NumPy array of shape [#index_image_features, depth].
ransac_seed: Seed used by RANSAC. If None (default), no seed is provided.
descriptor_matching_threshold: Threshold below which a pair of local
descriptors is considered a potential match, and will be fed into RANSAC.
If use_ratio_test==False, this is a simple distance threshold. If
use_ratio_test==True, this is Lowe's ratio test threshold.
ransac_residual_threshold: Residual error threshold for considering matches
as inliers, used in RANSAC algorithm.
query_im_array: Optional. If not None, contains a NumPy array with the query
image, used to produce match visualization, if there is a match.
index_im_array: Optional. Same as `query_im_array`, but for index image.
query_im_scale_factors: Optional. If not None, contains a NumPy array with
the query image scales, used to produce match visualization, if there is a
match. If None and a visualization will be produced, [1.0, 1.0] is used
(ie, feature locations are not scaled).
index_im_scale_factors: Optional. Same as `query_im_scale_factors`, but for
index image.
use_ratio_test: If True, descriptor matching is performed via ratio test,
instead of distance-based threshold.
Returns:
score: Number of inliers of match. If no match is found, returns 0.
match_viz_bytes: Encoded image bytes with visualization of the match, if
there is one, and if `query_im_array` and `index_im_array` are properly
set. Otherwise, it's an empty bytes string.
Raises:
ValueError: If local descriptors from query and index images have different
dimensionalities.
"""
num_features_query = query_locations.shape[0]
num_features_index_image = index_image_locations.shape[0]
if not num_features_query or not num_features_index_image:
return 0, b''
local_feature_dim = query_descriptors.shape[1]
if index_image_descriptors.shape[1] != local_feature_dim:
raise ValueError(
'Local feature dimensionality is not consistent for query and index '
'images.')
# Construct KD-tree used to find nearest neighbors.
index_image_tree = spatial.cKDTree(index_image_descriptors)
if use_ratio_test:
distances, indices = index_image_tree.query(
query_descriptors, k=2, n_jobs=-1)
query_locations_to_use = np.array([
query_locations[i,]
for i in range(num_features_query)
if distances[i][0] < descriptor_matching_threshold * distances[i][1]
])
index_image_locations_to_use = np.array([
index_image_locations[indices[i][0],]
for i in range(num_features_query)
if distances[i][0] < descriptor_matching_threshold * distances[i][1]
])
else:
_, indices = index_image_tree.query(
query_descriptors,
distance_upper_bound=descriptor_matching_threshold,
n_jobs=-1)
# Select feature locations for putative matches.
query_locations_to_use = np.array([
query_locations[i,]
for i in range(num_features_query)
if indices[i] != num_features_index_image
])
index_image_locations_to_use = np.array([
index_image_locations[indices[i],]
for i in range(num_features_query)
if indices[i] != num_features_index_image
])
# If there are not enough putative matches, early return 0.
if query_locations_to_use.shape[0] <= _MIN_RANSAC_SAMPLES:
return 0, b''
# Perform geometric verification using RANSAC.
_, inliers = measure.ransac(
(index_image_locations_to_use, query_locations_to_use),
transform.AffineTransform,
min_samples=_MIN_RANSAC_SAMPLES,
residual_threshold=ransac_residual_threshold,
max_trials=_NUM_RANSAC_TRIALS,
random_state=ransac_seed)
match_viz_bytes = b''
if inliers is None:
inliers = []
elif query_im_array is not None and index_im_array is not None:
if query_im_scale_factors is None:
query_im_scale_factors = [1.0, 1.0]
if index_im_scale_factors is None:
index_im_scale_factors = [1.0, 1.0]
inlier_idxs = np.nonzero(inliers)[0]
_, ax = plt.subplots()
ax.axis('off')
ax.xaxis.set_major_locator(plt.NullLocator())
ax.yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
plt.margins(0, 0)
feature.plot_matches(
ax,
query_im_array,
index_im_array,
query_locations_to_use * query_im_scale_factors,
index_image_locations_to_use * index_im_scale_factors,
np.column_stack((inlier_idxs, inlier_idxs)),
only_matches=True)
match_viz_io = io.BytesIO()
plt.savefig(match_viz_io, format='jpeg', bbox_inches='tight', pad_inches=0)
match_viz_bytes = match_viz_io.getvalue()
return sum(inliers), match_viz_bytes
def RerankByGeometricVerification(input_ranks,
initial_scores,
query_name,
index_names,
query_features_dir,
index_features_dir,
junk_ids,
local_feature_extension=_DELF_EXTENSION,
ransac_seed=None,
descriptor_matching_threshold=0.9,
ransac_residual_threshold=10.0,
use_ratio_test=False):
"""Re-ranks retrieval results using geometric verification.
Args:
input_ranks: 1D NumPy array with indices of top-ranked index images, sorted
from the most to the least similar.
initial_scores: 1D NumPy array with initial similarity scores between query
and index images. Entry i corresponds to score for image i.
query_name: Name for query image (string).
index_names: List of names for index images (strings).
query_features_dir: Directory where query local feature file is located
(string).
index_features_dir: Directory where index local feature files are located
(string).
junk_ids: Set with indices of junk images which should not be considered
during re-ranking.
local_feature_extension: String, extension to use for loading local feature
files.
ransac_seed: Seed used by RANSAC. If None (default), no seed is provided.
descriptor_matching_threshold: Threshold used for local descriptor matching.
ransac_residual_threshold: Residual error threshold for considering matches
as inliers, used in RANSAC algorithm.
use_ratio_test: If True, descriptor matching is performed via ratio test,
instead of distance-based threshold.
Returns:
output_ranks: 1D NumPy array with index image indices, sorted from the most
to the least similar according to the geometric verification and initial
scores.
Raises:
ValueError: If `input_ranks`, `initial_scores` and `index_names` do not have
the same number of entries.
"""
num_index_images = len(index_names)
if len(input_ranks) != num_index_images:
raise ValueError('input_ranks and index_names have different number of '
'elements: %d vs %d' %
(len(input_ranks), len(index_names)))
if len(initial_scores) != num_index_images:
raise ValueError('initial_scores and index_names have different number of '
'elements: %d vs %d' %
(len(initial_scores), len(index_names)))
# Filter out junk images from list that will be re-ranked.
input_ranks_for_gv = []
for ind in input_ranks:
if ind not in junk_ids:
input_ranks_for_gv.append(ind)
num_to_rerank = min(_NUM_TO_RERANK, len(input_ranks_for_gv))
# Load query image features.
query_features_path = os.path.join(query_features_dir,
query_name + local_feature_extension)
query_locations, _, query_descriptors, _, _ = feature_io.ReadFromFile(
query_features_path)
# Initialize list containing number of inliers and initial similarity scores.
inliers_and_initial_scores = []
for i in range(num_index_images):
inliers_and_initial_scores.append([0, initial_scores[i]])
# Loop over top-ranked images and get results.
print('Starting to re-rank')
for i in range(num_to_rerank):
if i > 0 and i % _STATUS_CHECK_GV_ITERATIONS == 0:
print('Re-ranking: i = %d out of %d' % (i, num_to_rerank))
index_image_id = input_ranks_for_gv[i]
# Load index image features.
index_image_features_path = os.path.join(
index_features_dir,
index_names[index_image_id] + local_feature_extension)
(index_image_locations, _, index_image_descriptors, _,
_) = feature_io.ReadFromFile(index_image_features_path)
inliers_and_initial_scores[index_image_id][0], _ = MatchFeatures(
query_locations,
query_descriptors,
index_image_locations,
index_image_descriptors,
ransac_seed=ransac_seed,
descriptor_matching_threshold=descriptor_matching_threshold,
ransac_residual_threshold=ransac_residual_threshold,
use_ratio_test=use_ratio_test)
# Sort based on (inliers_score, initial_score).
def _InliersInitialScoresSorting(k):
"""Helper function to sort list based on two entries.
Args:
k: Index into `inliers_and_initial_scores`.
Returns:
Tuple containing inlier score and initial score.
"""
return (inliers_and_initial_scores[k][0], inliers_and_initial_scores[k][1])
output_ranks = sorted(
range(num_index_images), key=_InliersInitialScoresSorting, reverse=True)
return output_rankshttps://airaria.github.io/2017/10/28/CNN%20RF%20calculator/
CNNCalculator
width: 321
kernel_size,stride,padding
7,2,3 size: 161 Rf: 7 stride: 2
3,2,1 size: 81 Rf: 11 stride: 4
1,1,0 size: 81 Rf: 11 stride: 4
3,1,1 size: 81 Rf: 19 stride: 4
1,1,0 size: 81 Rf: 19 stride: 4
1,1,0 size: 81 Rf: 19 stride: 4
3,1,1 size: 81 Rf: 27 stride: 4
1,1,0 size: 81 Rf: 27 stride: 4
1,1,0 size: 81 Rf: 27 stride: 4
3,1,1 size: 81 Rf: 35 stride: 4
1,1,0 size: 81 Rf: 35 stride: 4
1,2,0 size: 41 Rf: 35 stride: 8
3,1,1 size: 41 Rf: 51 stride: 8
1,1,0 size: 41 Rf: 51 stride: 8
1,1,0 size: 41 Rf: 51 stride: 8
3,1,1 size: 41 Rf: 67 stride: 8
1,1,0 size: 41 Rf: 67 stride: 8
1,1,0 size: 41 Rf: 67 stride: 8
3,1,1 size: 41 Rf: 83 stride: 8
1,1,0 size: 41 Rf: 83 stride: 8
1,1,0 size: 41 Rf: 83 stride: 8
3,1,1 size: 41 Rf: 99 stride: 8
1,1,0 size: 41 Rf: 99 stride: 8
1,2,0 size: 21 Rf: 99 stride: 16
3,1,1 size: 21 Rf: 131 stride: 16
1,1,0 size: 21 Rf: 131 stride: 16
1,1,0 size: 21 Rf: 131 stride: 16
3,1,1 size: 21 Rf: 163 stride: 16
1,1,0 size: 21 Rf: 163 stride: 16
1,1,0 size: 21 Rf: 163 stride: 16
3,1,1 size: 21 Rf: 195 stride: 16
1,1,0 size: 21 Rf: 195 stride: 16
1,1,0 size: 21 Rf: 195 stride: 16
3,1,1 size: 21 Rf: 227 stride: 16
1,1,0 size: 21 Rf: 227 stride: 16
1,1,0 size: 21 Rf: 227 stride: 16
3,1,1 size: 21 Rf: 259 stride: 16
1,1,0 size: 21 Rf: 259 stride: 16
1,1,0 size: 21 Rf: 259 stride: 16
3,1,1 size: 21 Rf: 291 stride: 16
1,1,0 size: 21 Rf: 291 stride: 16
1,2,0 size: 11 Rf: 291 stride: 32
static float vRfStridePadding[3] = {291.0f, 32.0f, 145.0f};
std::vector<cv::Rect> CalculateReceptiveBoxes(int width,int height,float rf,float stride,float padding){
std::vector<cv::Rect> boxes;
float bias[4] = {-padding,-padding,-padding+rf-1,-padding+rf-1};
for (int i = 0; i < height; ++i) {
for (int j = 0; j < width; ++j) {
float x1 = stride*j+bias[0], y1 = stride*i+bias[1], x2 = stride*j+bias[2], y2 = stride*i+bias[3];
boxes.push_back(cv::Rect(cv::Point2f(x1,y1),cv::Point2f(x2,y2)));
}
}
return boxes;
}
std::vector<cv::Point2f> CalculateKeypointCenters(std::vector<cv::Rect> boxes){
cv::vector<cv::Point2f> centerPoints;
for (int i = 0; i < boxes.size(); ++i) {
cv::Point2f point;
point.x = (boxes[i].tl().x+boxes[i].br().x)/2.0;
point.y = (boxes[i].tl().y+boxes[i].br().y)/2.0;
centerPoints.push_back(point);
}
return centerPoints;
}def CalculateReceptiveBoxes(height, width, rf, stride, padding):
"""Calculate receptive boxes for each feature point.
Args:
height: The height of feature map.
width: The width of feature map.
rf: The receptive field size.
stride: The effective stride between two adjacent feature points.
padding: The effective padding size.
Returns:
rf_boxes: [N, 4] receptive boxes tensor. Here N equals to height x width.
Each box is represented by [ymin, xmin, ymax, xmax].
"""
x, y = tf.meshgrid(tf.range(width), tf.range(height))
coordinates = tf.reshape(tf.stack([y, x], axis=2), [-1, 2])
# [y,x,y,x]
point_boxes = tf.cast(
tf.concat([coordinates, coordinates], 1), dtype=tf.float32)
bias = [-padding, -padding, -padding + rf - 1, -padding + rf - 1]
rf_boxes = stride * point_boxes + bias
return rf_boxes
def CalculateKeypointCenters(boxes):
"""Helper function to compute feature centers, from RF boxes.
Args:
boxes: [N, 4] float tensor.
Returns:
centers: [N, 2] float tensor.
"""
return tf.divide(
tf.add(
tf.gather(boxes, [0, 1], axis=1), tf.gather(boxes, [2, 3], axis=1)),
2.0)graph LR;
A(input)-->B[conv1x1-bn-relu channel512];
B-->C[conv1x1 channel:1];
C--score-->D[softplus];
A-->E[L2-Normalize];
E-->F((X));
D--prob-->F;
F-->G[H,W,1]
G--feat-->output

class AttentionModel(tf.keras.Model):
"""Instantiates attention model.
Uses two [kernel_size x kernel_size] convolutions and softplus as activation
to compute an attention map with the same resolution as the featuremap.
Features l2-normalized and aggregated using attention probabilites as weights.
"""
def __init__(self, kernel_size=1, decay=_DECAY, name='attention'):
"""Initialization of attention model.
Args:
kernel_size: int, kernel size of convolutions.
decay: float, decay for l2 regularization of kernel weights.
name: str, name to identify model.
"""
super(AttentionModel, self).__init__(name=name)
# First convolutional layer (called with relu activation).
self.conv1 = layers.Conv2D(
512,
kernel_size,
kernel_regularizer=reg.l2(decay),
padding='same',
name='attn_conv1')
self.bn_conv1 = layers.BatchNormalization(axis=3, name='bn_conv1')
# Second convolutional layer, with softplus activation.
self.conv2 = layers.Conv2D(
1,
kernel_size,
kernel_regularizer=reg.l2(decay),
padding='same',
name='attn_conv2')
self.activation_layer = layers.Activation('softplus')
def call(self, inputs, training=True):
x = self.conv1(inputs)
x = self.bn_conv1(x, training=training)
x = tf.nn.relu(x)
score = self.conv2(x)
prob = self.activation_layer(score)
# L2-normalize the featuremap before pooling.
inputs = tf.nn.l2_normalize(inputs, axis=-1)
feat = tf.reduce_mean(tf.multiply(inputs, prob), [1, 2], keepdims=False)
return feat, prob, score #feat为[H,W]排序得出哪些关键点需要保留,prob为局部特征,score为中间featuremapPCA的求解步骤:
- 求X均值
- 将X减去均值
- 计算协方差矩阵
- 对协方差均值C特征值分解
- 从大到小排列C的特征值
- 取前k个特征值对应的特征向量按行组成矩阵即为变换矩阵
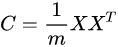
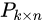
主成分析PCA(principle component analysis)与奇异值分解SVD(singular value decomposition)等价,只是解决的问题不一样 参考https://zhuanlan.zhihu.com/p/58064462
- PCA求解关键在于求解协方差矩阵
的特征值分解
- SVD关键在于
的特征值分解。
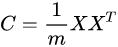
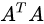
3.白化是在PCA变换出来的新数据基础上做标准差归一化
生成PCA白化的代码参考get_whiten
应用PCA白化的代码参考ApplyPcaAndWhitening

def gem_pooling(feature_map, axis, power, threshold=1e-6):
"""Performs GeM (Generalized Mean) pooling.
See https://arxiv.org/abs/1711.02512 for a reference.
Args:
feature_map: Tensor of shape [batch, height, width, channels] for
the "channels_last" format or [batch, channels, height, width] for the
"channels_first" format.
axis: Dimensions to reduce. default [H1,W2]
power: Float, GeM power parameter.
threshold: Optional float, threshold to use for activations.
Returns:
pooled_feature_map: Tensor of shape [batch, 1, 1, channels] for the
"channels_last" format or [batch, channels, 1, 1] for the
"channels_first" format.
"""
return tf.pow(
tf.reduce_mean(tf.pow(tf.maximum(feature_map, threshold), power),
axis=axis,
keepdims=False),
1.0 / power)def gem(x, p=3, eps=1e-6):
return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1./p)
# return torch.mean(x.clamp(min=eps).pow(p), dim=[-2, -1]).pow(1./p) # export onnx squeeze failed, modified ok
# return F.lp_pool2d(F.threshold(x, eps, eps), p, (x.size(-2), x.size(-1))) # alternativescores = torch.mm(torch.from_numpy(vecs).t(),torch.from_numpy(qvecs))
scoresT,rank = torch.sort(s, dim=0,descending=True)
scoresT = scores.T
ranksT = ranks.T
top1 = 0
top_one = 0
mAP = 0.0
false_alarm_num = 0
for i in range(ranksT.shape[0]):
t = 0
rank = 0.0
query_id0 = qimages[i][qimages[i].rfind('/')-4:qimages[i].rfind('/')]
gallery_id0 = images[ranksT[i][0]][images[ranksT[i][0]].rfind('/')-4:images[ranksT[i][0]].rfind('/')]
if query_id0 == gallery_id0:
top1 += 1
if query_id0 == gallery_id0 and scoresT[i][ranksT[i][0]] > 0.6:
top_one += 1
query_id = qimages[i][qimages[i].rfind('/')-4:qimages[i].rfind('/')]
for j in range(ranksT.shape[1]):
gallery_id = images[ranksT[i][j]][images[ranksT[i][j]].rfind('/')-4:images[ranksT[i][j]].rfind('/')]
if query_id == gallery_id:
t += 1
rank += t/(j+1)
if query_id != gallery_id and scoresT[i][ranksT[i][j]] > 0.6:
false_alarm_num += 1
if t == 0:
continue
mAP += rank / t
print('{}.{} AP = {}%'.format(i, query_id, rank / t * 100))
query_num = len(qimages)
print('TOP1 num: {}'.format(top1))
print('TOP1 recall: {}%'.format(top1 / query_num * 100))
print('mAP = {}%'.format(mAP / query_num * 100))
print('accuray: {}%'.format(top_one / query_num * 100))
print('false num: {}'.format(false_alarm_num))
print('false rate: {}%'.format(false_alarm_num / query_num * 100))
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment