Well, Because in past years, most of AI researchers didn't talk about this. Majority was focused on increasing 1% imagenet accuracy even if it makes model size 3x (It have its own advantages). But now, we have good accuracy with models in GBs and we can't deploy them (more problematic for edge devices).
Umm.. Yes. While designing models, one thing researchers find particularly interesting is that most of the weights in neural networks are redundant. They don't contribute in increasing accuracy (sometimes even decrease).
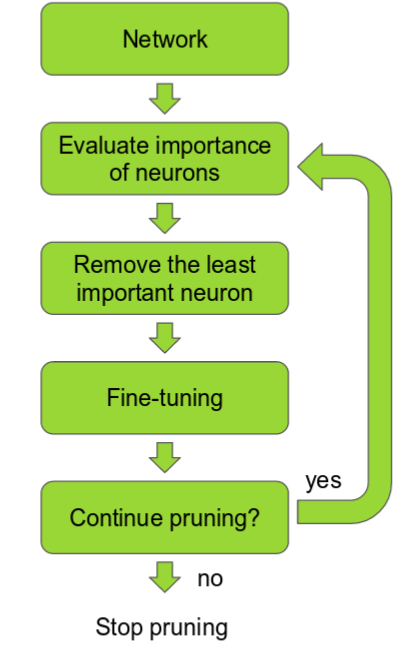
In Pruning, we rank the neurons in the network according to how much they contribute. The ranking can be done according to the L1/L2 mean of neuron weights, their mean activations, the number of times a neuron wasn’t zero on some validation set, and other creative methods. The simplest method being ranking by sorting absolute values of weights. Then remove the low ranking neurons from the network, resulting in a smaller and faster network.
You might not believe it but it works exceptionally well.🔥 Even simplest methods can remove 90% connections. More attentive approaches can remove even upto 95% weights without any significant accuracy loss (sometimes even gain). That's crazy I know.
Well, if you look into implementations of major Deep learning frameworks, you will find they make heavy use of GEMM operations through BLAS libraries. These libraries are very efficient in computing dense matrix multiplications. But, when, we start removing weights by pruning, it creates sparsity in matrices. Even after 90% less calculations, sparse matrices takes more time for matrix multiplication.
To overcome this problem, research have been splitted in mainly two directions.
- Creating efficient sparse algebra libraries.
- Structured Pruning - Pruning whole layers, filters or channels instead of particular weights.
Actually, I haven't seen much progress in the 1st approach but a lot of papers are getting published improving 2nd approach. For the time being, pruning whole filters and channels is better if you want to compress your models.
Although almost all big players are working on this, I find Tencent's Pockeflow and Intel's Distiller are only working frameworks (Upto my knowledge. Let me know if you know some better tools).
Here are some good links:
https://jacobgil.github.io/deeplearning/pruning-deep-learning
https://github.com/Eric-mingjie/rethinking-network-pruning
https://www.youtube.com/watch?v=s7DqRZVvRiQ
https://eng.uber.com/deconstructing-lottery-tickets/
https://github.com/he-y/Awesome-Pruning
https://github.com/memoiry/Awesome-model-compression-and-acceleration