Author:
- (TG): @iiLap
- Cardano Forum Author's Ticker: UNDR
Pool operators' (with constructive feedbacks, ideas) Tickers, so if you're saturated pls promote them:
- AAA,
- ANP,
- CLIO1,
- DECO,
- LOVE,
- MOON (pool ID: 45d26131d8ac970a22ef9876f2dc31b5028f5fc33b77c321c11191ea46bb7092)
- He has nothing to do anything /w the other MOON Tickers.
- PARTY,
- PHX,
- RDLRT,
- STKH,
Note: if I've missed somebody just DM me.
UPDATED (on Dec/24/2019)
This is a not official recommendations for Linux based pool nodes.
This, is my node's config which runs on Ubuntu 18.04.3 LTS (Bionic Beaver) server (/w Jormungandr v0.8.4 at that time) and does not have any issues at all, since the changes.
Before the change of the settings to these below, my node was struggling and missed almost all of the leaders' time due to the forks that caused by not having the latest tip/blocks.
After, I changed the settings, I have not missed any schedule for creating blocks.
The changes made on the last green vertical line (6pm):

| Name | Min/Recommended | Beast mode | Comment |
|---|---|---|---|
| vCPU | 2/4 | 8-16 | |
| RAM | 2GB/4GB | 4-8GB | |
| Storage (SSD) | 20GB/40GB SSD | 40GB | |
| Network IN | ~2/10Mbps (1GB/hr i.e. ) | >20Mbps | |
| Network OUT | ~20/50Mbps (10GB/hr i.e. ) | >50Mbps | |
| Limits (-n) | 8192/16384 | 32768, 65536 or more | |
| max_conn (Jormungandr) | try 1024, 2048 or 4096 | 16384 | |
| max_unreachable_nodes_to_connect_per_event (jorm) | 64 | 128 or more | It helps to Daedalus users and to us of course* |
| log level (Jormungandr) | warn or off | warn or off | |
| proper time | use chrony/ntpd |
- Network latency depends on the location of the trusted peeers
- Same region: 1-30ms
- Other closer regions: 10-150ms
- Other remote regions: 200-350ms
For checking latency of the trusted peers install tcpping and run similar command:
sed -e '/ address/!d' -e '/#/d' -e 's@^.*/ip./\([^/]*\)/tcp/\([0-9]*\).*@\1 \2@' /<PATH>/<TO>/<JORM>/<CONFIG>/<FILE> | \
while read addr port
do
tcpping -x 1 $addr $port
done
seq 0: tcp response from ec2-52-9-132-248.us-west-1.compute.amazonaws.com (52.9.132.248) [open] 107.083 ms
seq 0: tcp response from ec2-52-8-15-52.us-west-1.compute.amazonaws.com (52.8.15.52) [open] 69.405 ms
seq 0: tcp response from ec2-52-28-91-178.eu-central-1.compute.amazonaws.com (52.28.91.178) [open] 125.428 ms
seq 0: tcp response from ec2-3-125-75-156.eu-central-1.compute.amazonaws.com (3.125.75.156) [open] 122.619 ms
seq 0: tcp response from ec2-13-114-196-228.ap-northeast-1.compute.amazonaws.com (13.114.196.228) [open] 197.174 ms
seq 0: tcp response from ec2-13-112-181-42.ap-northeast-1.compute.amazonaws.com (13.112.181.42) [open] 165.335 ms
seq 0: tcp response from ec2-3-124-116-145.eu-central-1.compute.amazonaws.com (3.124.116.145) [open] 122.184 ms
- Software Interrupts (for VMs), handle at least 2K
INT NAME RATE MAX
56 [MSI 5767168-edge ] 613 Ints/s (max: 613)
- IOPs, not too much, 50 is more than enough /w 250kB/s writes and 100kB/s for reads
Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 22.63 7.46 243.60 1016667 33183380
I think it helps for the directly connected passive nodes which are not publicly reachable (Daedalus wallets behind the NAT as an example) to receive events (e.g. messages, blocks), therefore became a part of the poldercast network and been synced.
Cos, they would not be anyway, as they cannot receive blocks after they have initially fetched the blockchain.
Means when Daedalus is started, it receives the genesis block and fetches the initial blockchain and it's happy. But, after the default 600 secs it stops and trying to sync, but wont, as no blocks are being received, then restarts it, it will fetch the blockchain and be happy for 600 secs again and it will continue.
So, I highly encourage for setting it to some high if you want a healthy network with happy delegates of which our pools depend on.
Here is the relevant code to this above
/// create a `RandomDirectConnections` layer that will select some
/// random nodes to propagate event. Nodes that are directly connected
/// to our node but without being publicly reachableThanks to @Eysteinh from Cardano Shelley Testnet & StakePool Best Practice Workgroup to make me to check time drifts in my node.
(UPDATE): use LovelyPool's chrony conf instead!!!
Before after, my node had a 1sec drift in every 30mins, which is huge and can affect the block creation of a pool, due to that fact that the block must be created and sent out in 2secs i.e. 2000ms and stealing half of its time can have a huge effects on it.
For config details check crhonic's FAQ
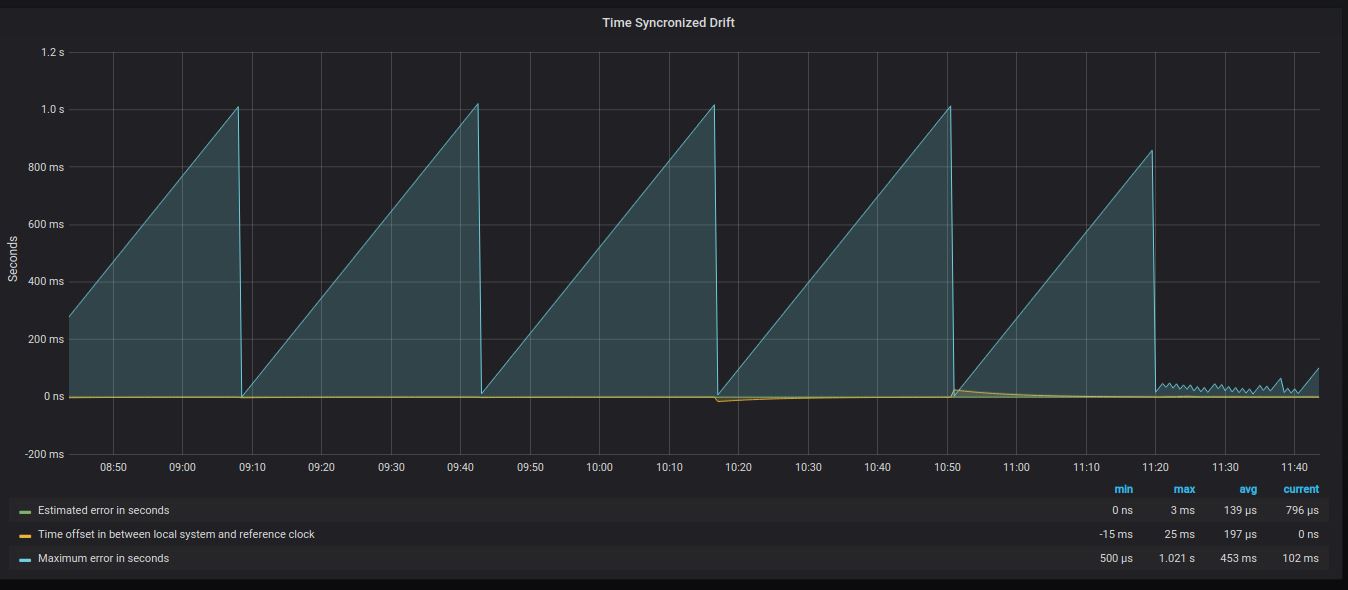
Install chrony, and edit /etc/chrony/chrony.conf then restart it systemctl restart chrony.
# 3 sources per time servers.
pool ntp.ubuntu.com iburst maxsources 3
pool time.nist.gov iburst maxsources 3
pool us.pool.ntp.org iburst maxsources 3
keyfile /etc/chrony/chrony.keys
driftfile /var/lib/chrony/chrony.drift
logdir /var/log/chrony
maxupdateskew 10.0
rtcsync
# Make steps in 100ms.
makestep 0.1 3
Also, a VM/VPS should not use local clock (e.g. 127.127.1.0) as a time source.
# chronyc sources
210 Number of sources = 10
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^- golem.canonical.com 2 6 17 55 +1805us[+1805us] +/- 63ms
^+ chilipepper.canonical.com 2 6 17 57 +1824us[+2012us] +/- 57ms
^- pugot.canonical.com 2 6 17 56 +1960us[+1908us] +/- 61ms
^+ ntpool0.603.newcontinuum> 2 6 17 56 -446us[ -446us] +/- 35ms
^+ 216.126.233.109 2 6 17 55 +104us[ +104us] +/- 21ms
^* hydrogen.constant.com 2 6 17 56 +333us[ +281us] +/- 19ms
^- 12.167.151.1 3 6 17 57 +5974us[+5922us] +/- 68ms
^- 44.190.6.254 2 6 17 56 +1591us[+1539us] +/- 58ms
^+ t2.time.bf1.yahoo.com 2 6 17 55 -1163us[-1163us] +/- 16ms
^- t2.time.gq1.yahoo.com 2 6 17 55 -2806us[-2806us] +/- 58ms
Edit /etc/sysctl.conf
fs.file-max = 10000000
fs.nr_open = 10000000
net.core.netdev_max_backlog = 100000
net.core.somaxconn = 100000
net.ipv4.icmp_echo_ignore_broadcasts = 1
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_keepalive_time = 300
net.ipv4.tcp_max_orphans = 262144
net.ipv4.tcp_max_syn_backlog = 100000
net.ipv4.tcp_max_tw_buckets = 262144
net.ipv4.tcp_mem = 786432 1697152 1945728
net.ipv4.tcp_reordering = 3
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_sack = 0
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_syn_retries = 5
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_wmem = 4096 16384 16777216
net.netfilter.nf_conntrack_max = 10485760
net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 30
net.netfilter.nf_conntrack_tcp_timeout_time_wait = 15
vm.swappiness = 10Assumed that the fs.file-max and fs.file_nr from above have been already applied.
Edit /etc/security/limits.conf
root soft nofile 32768
<CHANGE TO THE USERNAME WHO RUNS JORMUNGANDR> soft nofile 32768
<CHANGE TO THE USERNAME WHO RUNS JORMUNGANDR> hard nofile 1048576
If your service starts with systemctl then edit /etc/systemd/system/<YOURSTARTUPSCRIPT>.service file for example shelley.service and run
systemctl daemon-reload && systemctl enable shelley && systemctl start shelley:
IMPORTANT:
limitNOFILE was demonstrated here as LimitNOFILE=16384 # or more
BUT, you need to remove the comment as it won't be parsed as number and will revert back to the default.
I did not have that in my conf file just put here as comment.
[Unit]
Description=Shelley Staking Pool
After=multi-user.target
[Service]
Type=simple
ExecStart=<YOUR_NODE_START_SCRIPT>
# 16K Or more
LimitNOFILE=16384
Restart=on-failure
RestartSec=5s
User=<CHANGE TO THE USER ID WHO RUNS JORMUNGANDR>
Group=users
[Install]
WantedBy=multi-user.target
An example of a start script:
#!/bin/bash
CONF_DIR=/<path>/<to>/<the>/<jormungandr>/<configfiles>
JORMUNGANDR=/<path>/<to>/<the>/<jormungandr>/<binaries>/jormungandr
# ITN V1 Block hash
BLOCK_HASH="8e4d2a343f3dcf9330ad9035b3e8d168e6728904262f2c434a4f8f934ec7b676"
LOGLEVEL="--log-level warn"
LOGOUTPUT="--log-output syslog"
export BLOCK_HASH PATH=${CONF_DIR}:${PATH}
${JORMUNGANDR} --config ${CONF_DIR}/config.yaml --secret ${CONF_DIR}/secret.yaml --genesis-block-hash $BLOCK_HASH ${LOGLEVEL} ${LOGOUTPUT} max_connections: 1024 # Try with 1024 first and then 2048, 4192 or even 16384 (for the beast nodes)
max_unreachable_nodes_to_connect_per_event: 128
topics_of_interest:
blocks: high
messages: high
Disable intensive logging on production servers, so set the log level in the config.yaml file to either to "warn" or "off".
Sort them by your location, and comment out the others for fetching the initial Block0, and for bootstrapping. As they reandomly selected in jormungandr.
# IOHK US West - San francisco, California
- address: "/ip4/52.9.132.248/tcp/3000"
id: 671a9e7a5c739532668511bea823f0f5c5557c99b813456c
# IOHK US West - San francisco, California
- address: "/ip4/52.8.15.52/tcp/3000"
id: 18bf81a75e5b15a49b843a66f61602e14d4261fb5595b5f5
## IOHK EU Central - Frankfurt, Germany
- address: "/ip4/52.28.91.178/tcp/3000"
id: 23b3ca09c644fe8098f64c24d75d9f79c8e058642e63a28c
# IOHK EU Central - Frankfurt, Germany
- address: "/ip4/3.125.75.156/tcp/3000"
id: 22fb117f9f72f38b21bca5c0f069766c0d4327925d967791
## IOHK AP North East - Tokyo, Japan
- address: "/ip4/13.114.196.228/tcp/3000"
id: 7e1020c2e2107a849a8353876d047085f475c9bc646e42e9
# IOHK AP North East - Tokyo, Japan
- address: "/ip4/13.112.181.42/tcp/3000"
id: 52762c49a84699d43c96fdfe6de18079fb2512077d6aa5bc
# IOHK EU Central - Frankfurt, Germany
- address: "/ip4/3.124.116.145/tcp/3000"
id: 99cb10f53185fbef110472d45a36082905ee12df8a049b74
These are just the bare minimum recommendations, more sophisticated hardening is REQUIRED and HIGHLY EXPECTED.
- Only acces by normal user using SSH keys, so no password login allowed.
- Root should only have access to the
consoleand not to the virtual terminals.
Only the really necessary ports should be exposed to the outside world.
ufw allow <YOUR_NODE_LISTENING_PORT: default: 3000>/tcp
ufw allow <WHERE YOUR SSH SRV IS LISTENING default:22>/tcp
Note: It will allow connection from both IP protocol (IPv4/IPv6).
Update this solved it:
@iilap how the restart script look ?
systemctl restart shelley.servicewill this work ?